基于双语主题和因子图模型的汉语-越南语双语事件关联分析
2017-03-12唐莫鸣朱明玮余正涛唐培丽高盛祥
唐莫鸣,朱明玮,余正涛,唐培丽,高盛祥
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
互联网技术的快速发展使得信息的采集和传播速度达到了空前的水平,网络舆情分析逐渐成为网络信息监测、监控及预警分析的重要手段,互联网上每天都有大量的新闻事件报道,事件通过互联网进行快速的传播,如何快速地掌握互联网新闻事件动态,把握事件间的关联,分析事件间内在关系,已经逐渐成为政府、企业和社会共同关注的问题。越南与我国毗邻,在国家一带一路战略大环境下,越南与国内日益交流密切,相关的新闻事件越来越多,而这些报道分布在国内及越南相关网站及媒体上,呈现为中文或者越南文,如何能够及时有效了解国内及越南的新闻事件动态,掌握事件间的关系,正确做出有效应对措施,处理好与越南的国际关系,对区域经济发展、政治稳定、文化交流及商务合作等方面有着重要的作用。
新闻对事件的描述中包含了很多事件要素——时间、地点、人物等。事件关联是事件之间的逻辑关系, 是事件之间固有的一种客观存在。新闻事件关联分析通常被看作融合上下文信息和知识库的相似度计算问题,其中事件可以用词、句子或者文本进行表征。事件间关联分析涉及很多层次,现有研究对事件关系进行了初步的定义和类别划分,其中事件关系识别是一种针对“事件间逻辑关系存在与否”进行自动判定的浅层事件关系检测任务。文献[1]对两个包含对事件关系描述的句子进行依存句法分析,根据子句间的依存关系判断两个事件是否有联系。事件关联分析中的因果关系的研究由来已久,科学家在哲学与逻辑学上均围绕着这个问题进行了更深入的探讨,但直到近代因果关系才在计算机领域中有了定性和定量的研究。文献[2]利用上下文中的词语对事件进行表征,根据词语所在的上下文对事件间的因果关系进行判断,将事件之间的因果关系识别视为序列标注问题,利用CRF进行识别。文献[3]解决的问题同文献[1], 将因果关系的识别看成二分类问题,根据上下文中的词采用有监督学习的方式对因果关系进行识别。文献[4]将对事件进行描述的句子看成一个事件,根据不同句子中包含的不同事件要素之间的PMI值来计算不同事件之间因果关系的关联强度,但计算事件间的PMI值非常耗时,而且事件对可能是通过主事件关联的,单独计算这两个事件的PMI值意义不大。文献[5]将因果关系识别形式化为约束优化问题,将描述不同事件的句子之间事件触发词的语义联系和因果关系指示词融入整数线性规划(ILP)框架,对两个事件间存在因果关系的可能性进行计算。文献[6]将名词作为事件指示词,并将之看作事件。采用关系抽取的方法对文本中词语之间因果关系进行抽取。文献[7]将新闻中所包含的事件分为粗粒度事件和细粒度事件,结合浅层语义分析方法和知识库对细粒度事件的因果关系进行识别,并以此推断粗粒度事件的因果关系。但事件间的关联关系不仅仅是因果关系,为了更准确地量化事件间的关联程度,文献[8]用词语来表征一个事件,通过词语共现的方式衡量事件间的关联强度。但这种方法非常耗时,并且容易引入一些琐碎的没有价值的事件对。文献[9]借助互信息分析不同新闻事件中所描述的参与者、时间、地点等事件要素之间的关联强度,在此基础上融合新闻的时序关系及新闻文本内容的相似度,计算新闻事件间的相互影响力。文献[10]利用两个对事件进行描述的句子中谓词在因果语料库中的共现次数来判断事件间的因果关系。文献[11]根据对不同事件进行描述的句子中包含的谓词、共同实体以及谓词与实体之间的关系,利用语义角色标注的方法对事件因果关系进行识别。
现有事件关联关系分析方法大多是将文章中的词和句看作事件,用机器学习的方法对同一篇文档中词与词、句与句之间的事件关联进行分析,但对不同文档中事件关联关系分析涉猎较少。而且很多方法基于词法、句法、篇章结构、文本线索提取事件的因果关系。但仅仅提取事件因果关系是不够的,因为事件关联不仅局限于因果关系,而且基于文本的方法也很难发现事件间隐含的关联。事件的发生和演化具有关联性,新闻事件的影响力具有传播特性。两个事件是否关联往往受到与这两个事件相关联的其他事件的影响。在社交网络的影响力分析中,某一用户的行为可能导致他的朋友以类似的方式表现某种现象,这与事件关联分析类似。文献[12]提出的“Measure Influence via Reachability”,利用用户之间的关注关系,借助随机游走算法构建用户关联图,通过图上的路径计算用户之间的相互影响力,但该方法只考虑了社交网络的结构。文献[13]将用户看成节点,使用simRank的算法用同样的方法构建图模型,根据用户的近邻节点计算任意两个节点的相似度,即任意两个节点的相似度都跟它们两个任意两个邻居的相似度成正比,但该方法同样只考虑了社交网络的结构。文献[14]提出基于因子图的社交网络影响力分析方法,将用户之间的关注关系和用户文本内容的主题及不同主题下微博内容之间的联系同时融入因子图模型中进行影响力计算,取得了非常好的效果。
新闻事件关联分析与社交网络类影响力分析类似,事件同样不是孤立存在的。一个事件的发生会在一定程度上影响另一事件的发生,或者说以某种形式控制另一件事的发生。但是很多情况下新闻事件之间的关联没有显式表现出来,需要我们根据事件上下文进行分析。因此我们在双语事件的关联分析中借用社交网络影响力分析方法,参考文献[14]提出的社交网络影响力传播分析方法进行事件间的关联分析。抽取双语事件的共享主题,利用描述事件的文本间的相似度构建因子图模型,求解不同主题下事件间的相互影响。
1 跨语言主题提取
文献[15]通过双语词典为传统PLSA算法的似然函数添加软约束,从未对齐的双语文本中抽取双语文档共享的主题,以及文档在主题上的概率分布。PLSA算法的似然函数如式(1)所示。
其中,d表示文档,θj表示文档d的主题。P(θj|d)表示以概率P(θj|d)选中文档d的主题θj。w表示文档d的主题词。P(w|θj)表示以概率P(w|θj)产生主题θj的主题词w。c(w|d)表示单词w在文档d中出现的概率。我们利用双语词典构建汉语-越南语的词汇二部图Gcv=(Vcv,Ecv),其中c表示汉语,v表示越南语。如果汉语词汇Vc和越南语词汇Vv语义相关,则将这两个单词以边ecv、边上的权重为w(c,v)。我们通常用最大似然估计来估计L(C)的参数并获取主题。我们为PLSA的似然函数添加双语约束R(C),如式(2)所示。
L(C)表示汉语词和越南词的语义差异,其中Deg(u)代表单词u的所有入度边的权重和,将之看作损失函数来优化PLSA特征函数的求解,PLSA获得的双语主题是语义相关的。
O(c,G)=(1-λ)L(C)-λR(C),λ∈(0,1)
(3)
我们使用EM算法求式(3)目标函数的参数极大似然估计。在EM算法E步的时候我们使用式(4)估计事件文本的主题及主题概率分布。
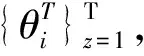
2 汉语-越南语双语事件关联关系分析
事件关联分析就是分析描述不同事件的文本以获取事件之间的关系。其中事件可以用词、句子或者文本进行表征。本文针对汉语、越南语双语进行的新闻事件关系识别,是对“事件间逻辑关系存在与否以及关联程序强弱”进行自动判定和计算的关系检测任务。
双语新闻事件之间的关联关系可以通过新闻文本的文本相似性度量。但是由于相互关联的双语事件间往往通过某种主题进行关联,而且在该主题下两个事件是否关联往往受到与这两个事件相关联的其他新闻事件的影响。因此,我们计算相同主题下两个双语新闻事件关联时,不仅要考虑新闻文本之间的相似度,还要考虑这两个事件受到与之关联的其他新闻事件的影响。同一主题下双语事件关联计算与社交网络中用户影响力传播的问题相似。在社交网络影响力传播的计算中,认为用户的影响力通过用户之间的关注关系传播,利用社交网络中用户之间的关注关系构建基于用户的因子图模型,将用户视为因子图中的节点,用户之间存在关注关系表示在两个节点之间存在一条边。在因子图模型上通过用户之间的关注关系计算社交网络中节点之间影响力传播的问题。相比于传统图模型,因子图模型考虑了节点自身的属性、节点之间的关联信息及全局约束信息,利用因子图模型的这些优势可以使我们计算事件之间关联强度时充分利用新闻事件影响力传播特性。因此,我们基于因子图模型构建事件间的影响力传播模型,通过新闻事件文本的相似性构建事件因子图,即文本相似度大于一定阈值则认为两事件之间存在关联。将新闻事件表征为因子图上的节点,相互关联的两事件的节点之间存在一条边关联。利用事件因子图中节点的特征函数,使用社交网络中的局部密切度传播算法,计算图中相互关联的节点之间的影响力,最终得到不同主题下事件间影响力传播拓扑图。
主题相似度越高的新闻,所报道和关注事件越接近,这些事件的发生和发展往往是由主题相关其他事件导致的。因此主题相近的新闻所报道的事件的关联程度比主题不同的新闻报道的事件高。因此本文是利用主题模型分析出来的主题词来表征新闻事件,利用新闻文本间的主题相似性来度量两个新闻事件的文本相似性。两个新闻的主题相似性越低,新闻文本相似性也就越高。如果新闻主题相似性越疏远,新闻文本相似性也就越低。本文使用JSD(Jensen-Shannon Divergence)距离的倒数来度量事件间的主题相似性。如果两个新闻文本主题分布的sim越大,主题之间的相似度也就越高,新闻报道的事件存在关联性的可能性越大。我们选取阈值ε,通过阈值来判断不同新闻事件是否存在关联关系。即两新闻文本的主题相似度大于ε,则两新闻事件存在关联;若两新闻文本的主题相似度小于ε,则两新闻事件之间不存在关联。文本主题相似度计算公式如式(5)~(8)所示。
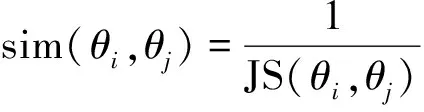
(5)
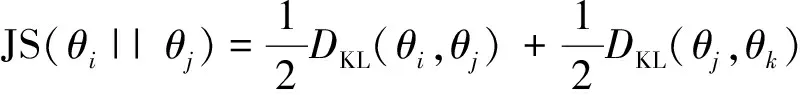
(6)
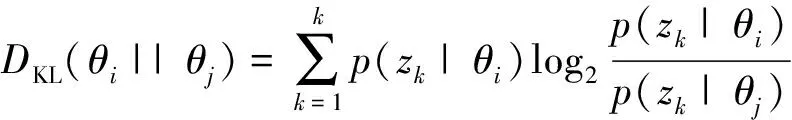
(7)
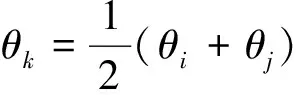
(8)
θi、θj表示事件i、j的主题概率分布。JS(θi||θj)是事件i、j的JS距离。DKL(θi||θj)是事件i、j的KL距离。θk是θi、θj的均值。

表1 符号说明
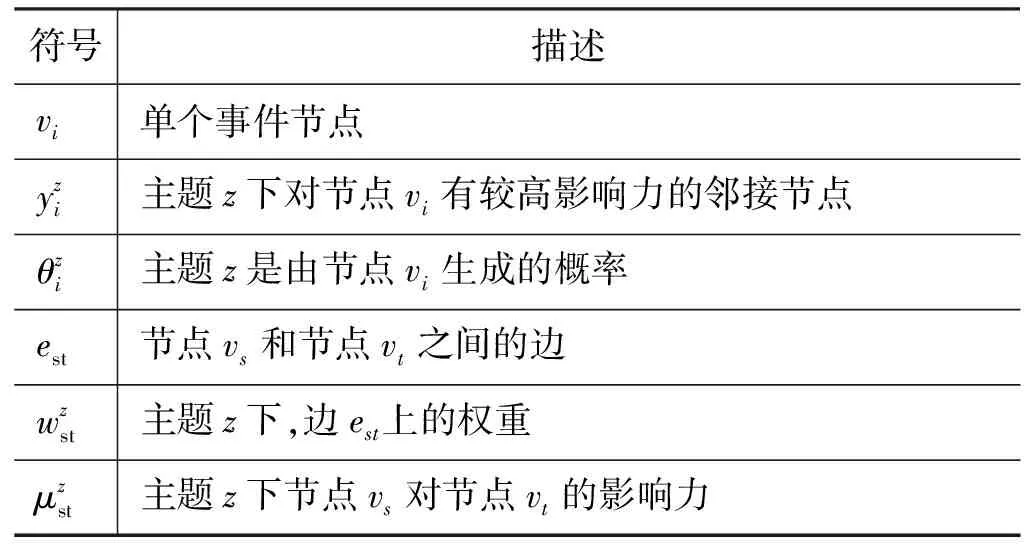
续表
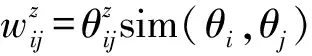
图1中,主题1下事件因子图{v1,v2,v3,v4}节点代表事件,{y1,y2,y3,y4}是分别对应节点{v1,v2,v3,v4}的隐含变量,集合{y1,y2,y3,y4}中的每个元素对应从双语文档中抽取的双语主题的主题概率分布。g(vi,yi,z)对应节点vi在主题z下的特征函数。g(vi,yi,z)是在主题z下定义在节点vi上的特征函数,描述节点的基本信息。这里我们将节点定义为g(vi,yik,z),如式(9)所示。
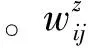
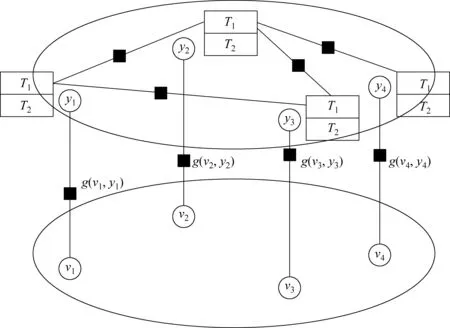
图 1 主题T1下事件的因子图模型
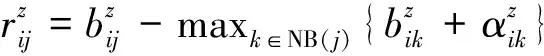
(11)
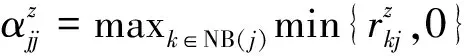
(12)
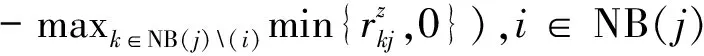
(13)
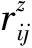
件间影响力分数如式(14)所示。
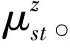

表2 相同主题新闻事件关联算法
3 实验与分析
3.1 实验数据获取与预处理
由于目前还未曾见到汉语-越南语事件影响力分析的相关语料。因此本文通过人工方式构建了一定量的语料。该数据集中包含了600个显式相关新闻事件对和600个无关的新闻事件对。每个新闻对包含两篇新闻A和B,分别报道了两个不同的事件。本文就在这1 200个新闻对中进行了实验。其中中文-中文、越南语-越南语、中文-越南语的相关和无关新闻对各200个。本文采用识别结果的准确率P、召回率R、以及F值作为评价指标。F值越高效果越好。它们的计算方式如式(15)~(17)所示。
(15)
(16)
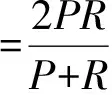
(17)
3.2 实验环境
本文的实验环境为: Intel G620 2.6GHz的CPU、4GB的内存、320GB的硬盘、Windows XP的操作系统。开发工具为My Eclipse 10。
3.3 实验1 节点相似度阈值ε对实验结果的影响
本文在构建因子图模型时,如果在主题z下,任意两个事件节点的相似度大于给定的阈值ε,则认为在主题z下节点i、j相互关联。由于ε是判断事件节点是否存在边关联起来的阈值,ε设置过高可能会过拟合,ε设置过低可能引入大量噪声。因此本实验考察不同的ε是否会对实验结果造成影响,如果有影响则选取最佳ε值。分别在ε=0.2,0.3,0.4,0.5,0.6,0.7,0.8 时,在测试数据上进行了实验,表3所示为ε取不同值时的结果对比。
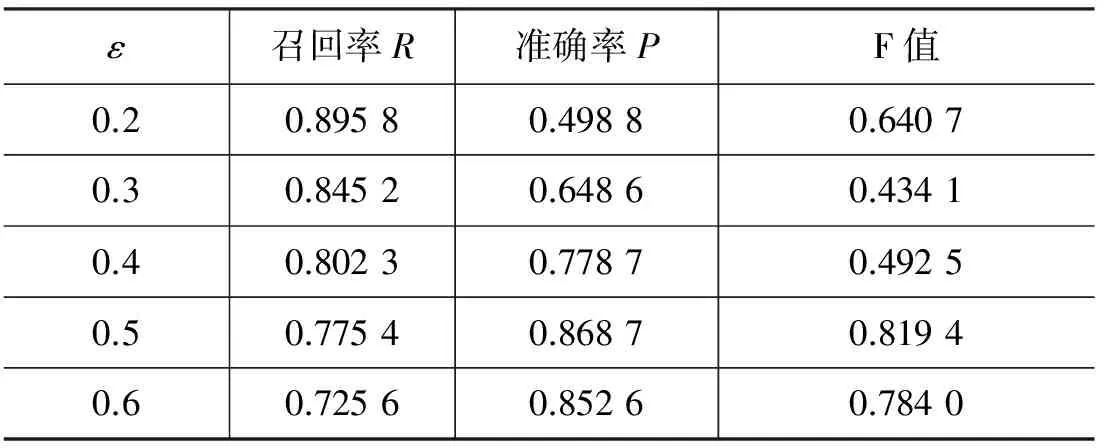
表3 不同判定节点相似度阈值对实验结果的影响
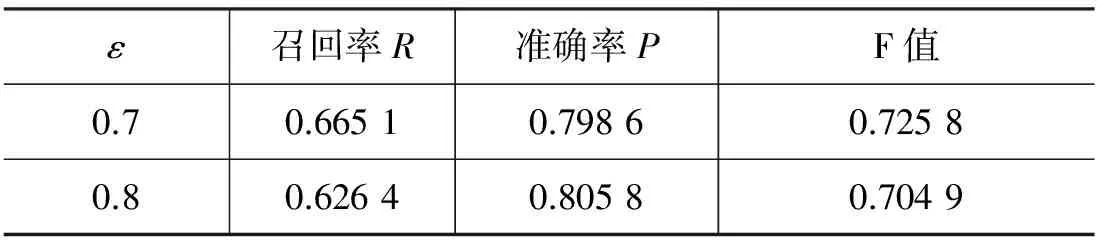
续表
实验结果说明: 当ε值越低,由于事件间相似性较低引入大量噪声,导致大量不相关事件被识别为相关,影响结果准确性。当ε越高,可能过拟合,导致原本相关的事件被判定为不相关。因此ε过高、过低都会影响实验结果,所以根据实验数据,本文所有的实验选择ε=0.5。
3.4 实验2 跨语言相关事件识别方法实验
本文所采用的方法是基于影响力传播模型的。因此本文在构建的测试数据集上,分别针对单语和双语新闻对,进行了相关事件识别方法的实验。单语环境下我们选取LDA主题抽取模型。为了达到最优的实验结果,本文经过多次实验对识别过程中参数的取值进行了调整,获得了一组的最优的参数取值,如表4所示。
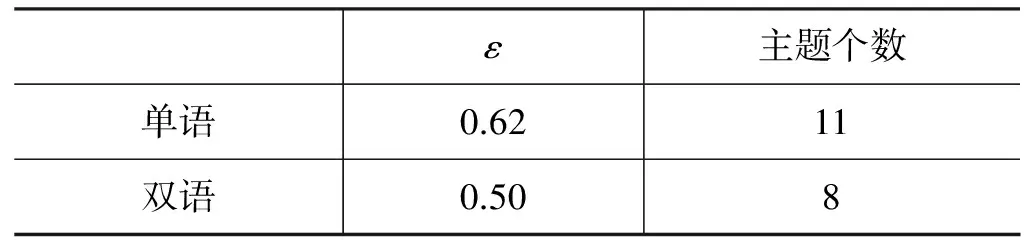
表4 单语和双语环境下识别方法的参数选择
通过该参数得到在单语和跨语言环境下的识别效果,如表5所示。
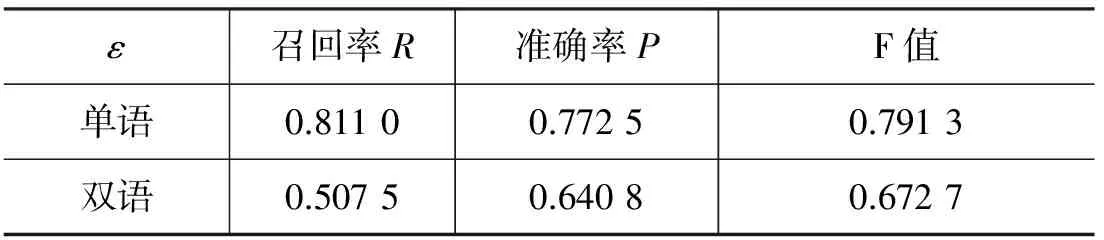
表5 单语和双语环境下相关事件识别方法实验结果
实验结果表明,本文所提出的相关事件识别方法,在单语环境下和多语环境下都取得了不错的识别效果。说明两种方法都能比较准确地识别出测试数据中相关事件。此外,通过两种方法共同使用时的实验结果可以发现,两种方法具有一定的互补性,如果将两种方法同时使用,能够有效提高识别召回率。
3.5 实验3 不同事件相关度计算方法对比
本文提出的方法利用新闻事件的文本相似性和新闻事件影响力传播来判断双语事件是否相关。为了验证本文做法的有效性。本文还利用收集到的汉语和越南语新闻,对不同事件主题词之间的PMI(point wise mutual information)值进行统计,利用PMI值来度量事件之间的相关度。PMI计算如式(18)所示。
其中,n(ti,tj)表示词ti和词tj共同在新闻中出现的次数,n(ti)和n(tj)则分别表示词ti和tj词单独在新闻中出现的次数。
本文对这两种方法都进行了实现,并在测试数据上进行了对比实验。表6所示为两种方法的结果对比。其中A为本文所采用的方法,B则是通过计算新闻主题词PMI值进行相关事件识别的。
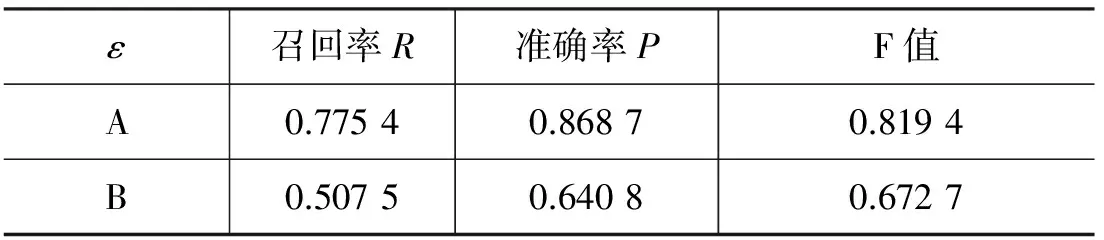
表6 不同事件相关度计算方法对比
实验结果表明,A的识别效果较B有较大幅度的提升。说明在考虑新闻事件的影响力传播时,对于相关事件进行识别是十分必要的。通过分析实验数据发现: B的效果不够理想,是因为忽略了两个新闻事件是否相关,跟与这两个新闻事件关联的其他新闻事件有很大关系,因而会忽略很多相关信息,从而影响了识别效果。
4 总结
为了全面准确地识别出汉语-越南语新闻相关事件,本文针对新闻相关事件识别方法展开研究,将对事件进行报道的所有不同语言新闻作为判断事件之间相关性的依据。本文构建双语主题模型,从双语新闻文档中抽取双语主题,将双语文档通过主题关联起来。针对新闻事件影响力传播特性,构建因子图模型,通过因子图模型上事件影响力传播计算不同主题下双语事件关联强度。实验结果表明: 本文所采用的识别方法,能够有效识别汉语、越南语双语相关事件。但是本文没有考虑汉语、越南语双语新闻事件之间要素的关联对双语事件关联的影响。我们将在今后的工作中将事件要素融入双语事件关联分析的方法中。
[1] 马彬, 洪宇, 杨雪蓉,等. 基于语义依存线索的事件关系识别方法研究[J]. 北京大学学报(自然科学版), 2013, 49(1):109-116.
[2] 付剑锋, 刘宗田, 刘炜,等. 基于层叠条件随机场的事件因果关系抽取[J]. 模式识别与人工智能, 2011, 24(4):567-573.
[3] Bethard S, Martin J H. Learning semantic links from a corpus of parallel temporal and causal relations[C]//Proceedings of the Meeting of the Association for Computational Linguistics, June 15-20, 2008, Columbus, Ohio, USA, Short Papers. 2008:177-180.
[4] 杨竣辉, 刘宗田, 刘炜,等. 基于语义事件因果关系识别[J]. 小型微型计算机系统, 2016, 37(3):433-437.
[5] Do Q X, Chan Y S, Roth D. Minimally supervised event causality identification[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, 27-31 July 2011, John Mcintyre Conference Centre, Edinburgh, Uk, A Meeting of Sigdat, A Special Interest Group of the ACL. DBLP, 2011:294-303.
[6] Paramita Mirza, Sara Tonelli. An analysis of causality between events and its relation to temporal information[C]//Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. Dublin, Ireland, 2014: 23-29 2014
[7] Mulkar-Mehta R, Welty C A, Hobbs J R, et al. Using part-of relations for discovering causality[C]//Proceedings of the 24th International Florida Artificial Intelligence Research Society Conference, May 18-20, 2011, Palm Beach, Florida, USA. 2011.
[8] 仲兆满, 刘宗田. 利用事件影响关系识别文本集合中重要事件的方法[J]. 模式识别与人工智能, 2010, 23(3):307-313.
[9] 孙涛. 面向市场情报分析的Web实体事件融合问题研究[D]. 济南: 山东大学博士学位论文, 2014.
[10] Abe S, Inui K, Matsumoto Y. Two-phased event relation acquisition: Coupling the relation-oriented and argument-oriented approaches[C]//Proceedings of the COLING 2008, International Conference on Computational Linguistics, 18-22 August 2008, Manchester, UK. 2008:1-8.
[11] Chambers N, Dan J. Unsupervised learning of narrative schemas and their participants[C]//Proceedings of the Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing of the Afnlp, 2-7 August 2009, Singapore, 2009:602-610.
[12] Jeh G, Widom J. Scaling personalized Web search[C]//Proceedings of the International Conference on World Wide Web. ACM, 2003:271-279.
[13] Jeh G, Widom J. SimRank: A measure of structural-context similarity[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2002:538-543.
[14] Tang J, Sun J, Wang C, et al. Social influence analysis in large-scale networks[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2009:807-816.
[15] Zhang D, Mei Q, Zhai C X. Cross-lingual latent topic extraction[C]//Proceedings of the ACL 2010, Proceedings of the Meeting of the Association for Computational Linguistics, July 11-16, 2010, Uppsala, Sweden, 2010:1128-1137.
