基于分写增强字符向量和LSTM-CRF的朝鲜语自动分写方法
2017-03-12金国哲崔荣一
金国哲,崔荣一
(1.延边大学 计算机科学与技术学院,吉林 延吉 133002;2. 吉林大学 计算机学院,吉林 长春 130012)
0 引言
朝鲜语分写法(也被称作隔写法),是朝鲜语语法中最基本的原则。例如,中文“我喜欢读书”的正确分写方式为:
正确的朝鲜语分写有助于快速、准确地理解文章的含义。反观,糟糕的分写方式直接影响到句义。例如,
这两句由相同的字符序列构成,而且两种分写方式在语法角度上都是合法的,但是根据分写方式的不同表现出不同的含义。第一句表示“爸爸进屋了”,第二句则是“爸爸进包里了”。上述例子虽然有些极端,但也可以反映出朝鲜语分写的重要性。
正规的书籍、报纸、期刊等出版物中,由于进行细致的人工校对,朝鲜语分写错误相对较少。然而网络环境下使用的朝鲜语中存在大量的分写错误,这些错误不仅影响对文章的理解,而且不利于朝鲜语规范化使用。因此,有必要引入朝鲜语自动分写系统,帮助用户纠正分写错误。朝鲜语自动分写系统的作用是: 读入含有错误分写的句子或未分写的句子,输出准确分写的朝鲜语句子。
朝鲜语自动分写系统的主要用途有: ①文档的自动化分写纠错; ②词性标注、命名实体识别等其他朝鲜语自然语言处理的预处理模块; ③朝鲜语OCR或语音识别系统的后处理模块。
朝鲜语自动分写是典型的序列标注问题,本文将分写增强字符向量(KWSE)与双向长短时记忆循环神经网络-条件随机场 (LSTM-CRF)模型结合来解决这一问题。后续章节中统一使用KWSE-LSTM-CRF代表这种方法。
后续内容安排如下: 第一节介绍朝鲜语自动分写相关的研究,第二节详细描述基于KWSE-LSTM-CRF的朝鲜语自动分写模型,第三节是实验过程及实验结果分析,第四节是结论。
1 相关研究
现有的朝鲜语分写方法可以归类到以下两大类: 第一类是基于规则的方法;第二类是基于统计的方法。
基于规则的方法主要是利用语言学家建立的专家级规则库与目标句子进行匹配,进而完成朝鲜语自动分写。Kim and Lee等人基于规则的方法根据启发式规则进行句子分写,并用句子形态分析的方法验证分写结果[1]。Kang等人利用双向最大匹配的启发式规则进行了朝鲜语自动分写[2];该方法在分写过程中使用了语言学家手工构建的分写规则,因此获得了较高的分写准确率。这种方式虽然可以在局部获得相当高的分写性能,但缺点是泛化能力差、分写准确率严重依赖于规则库。
基于统计的方法将分写问题转化为在未分写句子的适当位置插入空格的问题,其基本思路是通过分析原始语料库中的字符级n-gram信息获取字符间分写概率,并通过这些概率值决定是否进行分写[3-5]。文献[6]将朝鲜语自动分写问题归类到序列标注问题,并提出用隐马尔科夫模型HMM解决该问题。文献[7]则提出基于条件随机场(CRF)的朝鲜语自动分写方法。条件随机场被认为是解决序列标注问题的一个有效模型,在中文分词等领域同样表现出了优异的性能。文献[8]尝试用Structured SVM解决朝鲜语分写问题。文献[9]等人提出了BWSM方法,该方法在Structured SVM的基础上融入人工分写标注信息,用于提高单词级分写准确率。文献[10]等人提出了基于GRU-CRF的朝鲜语分写方法,该方法利用循环神经网络(采用GRU单元)计算朝鲜语分写标注的概率分布,同时利用CRF求全局最优的分写标注序列。
上述基于统计的方法无需人工构建分写规则库,且该方法从原始语料库中获取分写概率,因此比基于规则的方法具有更好的泛化能力,并且对未知语句进行分写时具有更好的鲁棒性。然而,上述基于统计的方法存在一些问题: 基于HMM的方法需要大量的训练参数,CRF和Structured SVM方法则依赖于特定的特征,并且未能充分利用好句子的全局上下文信息。为了克服上述问题,本文将尝试用KWSE-LSTM-CRF方法解决朝鲜语自动分写问题。
2 朝鲜语自动分写方法
2.1 朝鲜语分写标注
本文将朝鲜语自动分写问题归类为序列标注问题。标注集的选择上借鉴了汉语分词领域中常用的四词位标注法,即标注集定义为T={B,M,E,S},其中B表示单词的起始字符,M表示单词的中间字符,E表示单词的结束字符,S表示单字符单词。例如,朝鲜语:

对应的标注如表1所示。

表1 朝鲜语句子分写标注实例
本文用X=〈x1,x2,…,xn〉表示一个句子序列,其中xi表示句子中的字符,Y=〈y1,y2,…,yn〉表示该句对应的分写标注序列,其中yi表示xi对应的分写标注。
2.2 分写增强字符向量
本节提出朝鲜语分写增强字符向量的训练模型KWSE。KWSE模型在Mikolov等人的CBOW[11]模型基础上,增加了分写标注信息,目的是让训练得到的字符向量同时具有语义和分写倾向信息。CBOW模型借鉴了C&W[12]模型中以上下文中间单词作为预测单词的做法,同时简化了神经网络语言模型,去掉了隐藏层。CBOW模型的优化目标为最大化,如式(1)所示。
其中V表示词表大小,context(t)为单词t的上下文窗口,通常单词t的前后各c个单词作为context(t)。CBOW模型用softmax函数定义概率p(t|s),,如式(2)所示。
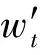
CBOW模型中训练出的词向量富含语义信息,即语义相似的单词向量之间的距离也会较近。而在朝鲜语分写问题中,我们希望字符向量含有一部分分写倾向性信息,具体如下:
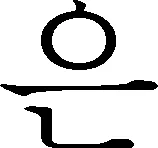
(1) 同一字符向量在不同的上下文环境中表现出不同的分写倾向性,例如,

基于以上分析,我们提出了一种朝鲜语分写增强字符向量的训练模型。该模型以目标字符的上下文字符及其标注信息作为输入,输出目标字符的分写标注。KWSE模型结构如图1所示。
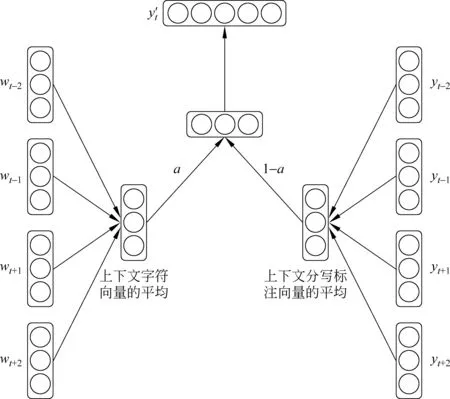
图1 KWSE模型
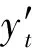
模型首先通过查询表把上下文字符转化成低维实数向量,查询表大小为|V|×d,其中|V|为字典大小,d为字符向量的维数。另外,分写标注通过类似的查询表转化成d维实数向量,分写标注查询表大小为|M|×d,其中|M|为分写标注集大小,d为分写标注向量维数。
下一步计算上下文字符的平均向量vs,计算方法与式(3)相同,而上下文分写标注的平均向量us的计算如式(4)所示。
下一步是求vs和us的加权和,并通过softmax函数输出模型预测的分写标注,如式(5)所示。
其中α为超参,表示语义信息和分写倾向信息的比例,实验中设置为0.6(通过多次的对比实验得到的经验值),f表示softmax函数,wout∈d×|M|,bout∈|M|为全连接映射权值和偏置。
模型采用标准的BP算法进行训练,并在训练完成后提取字符查询表,作为LSTM-CRF朝鲜语分写模型的字符查询表的初始化参数。
2.3 LSTM
循环神经网络(RNN[13])可以记住序列数据的历史信息,并根据历史信息和当前的输入预测当前的输出,因此适合对序列标注问题进行建模。然而,传统的RNN在实际训练过程中存在梯度消失和梯度爆炸的问题。
LSTM[14]属于改进版的循环神经网络(RNN),相比于传统的RNN模型,LSTM可以更好地对长距离依赖关系进行建模, 同时可以很好地解决梯度消失和梯度爆炸问题。图2是一个典型的LSTM单元结构。
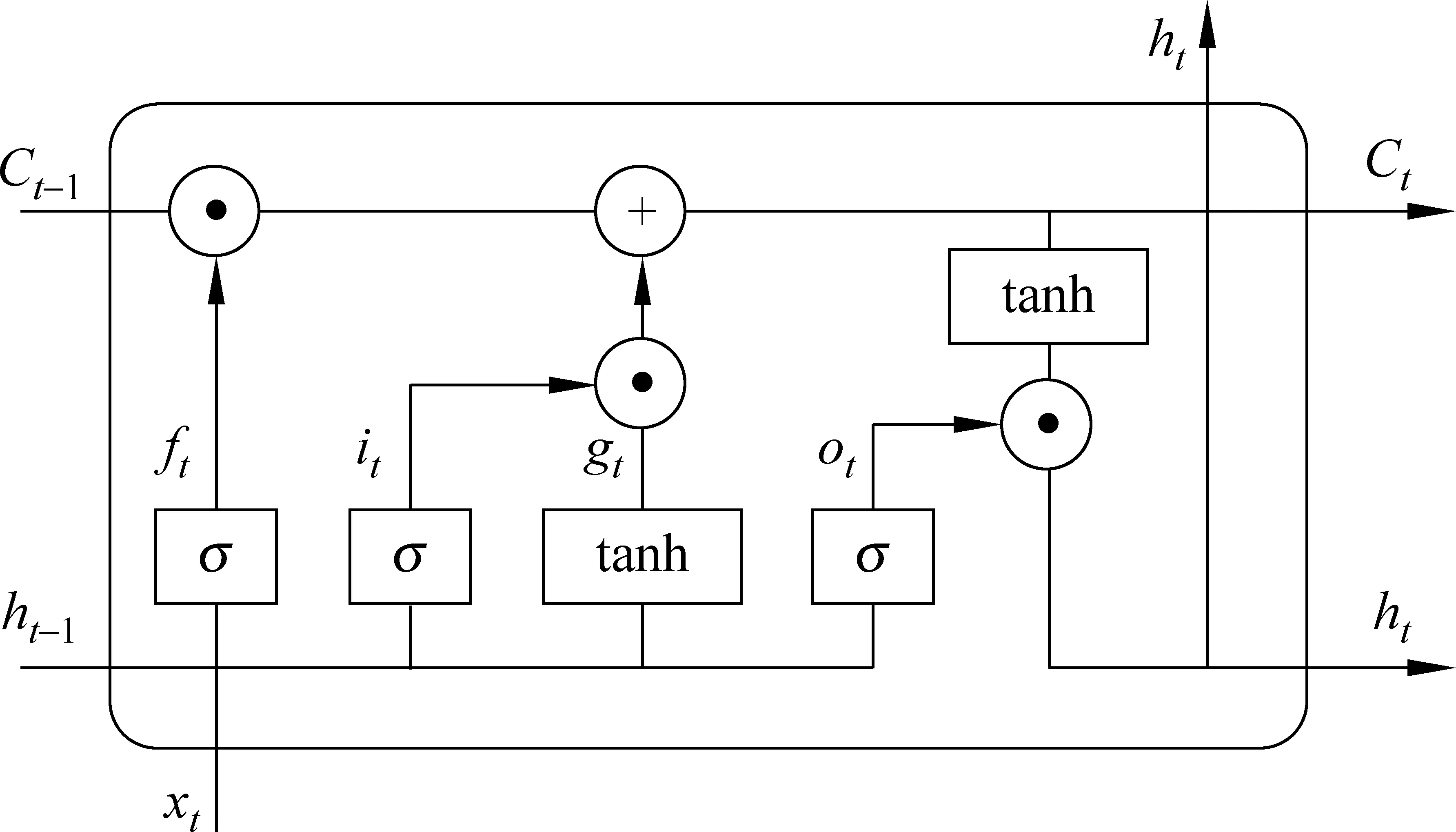
图2 LSTM单元
LSTM的隐藏层由特殊构建的记忆单元Cell构成。每个Cell由以下四个部分组成: ①循环连接的Cell;②用于控制输入信号流量的输入控制门i;③用于控制流向下一个单元的信号强度的输出门o;④用于控制遗忘之前Cell状态的遗忘门f。 下面给出每个时刻t各个单元的计算公式。
其中,⊙表示元素级乘法计算,σ表示sigmoid函数,Wi、Wf、Wo、bi、bf、bo分别为输入门、遗忘门、输出门的权值矩阵。
2.4 基于LSTM-CRF[15]的朝鲜语分写方法
本文采用基于LSTM-CRF的朝鲜语分写模型,其结构如图3所示。我们用X=〈x1,x2,…,xn〉表示一条朝鲜语句子,其中xi为代表第i个字符的索引值,Y=〈y1,y2,…,yn〉为一个句子的分写标注序列。模型首先把X输入到字符查询表(lookup table),通过查询将每个字符xi转化成固定长度的低维实数向量。本文采用通过KWSE模型预先训练好的分写增强字符向量作为lookup table的初始值,训练过程中将lookup table当做可训练参数,进行动态更新。我们用LT(X)表示经过向量化的输入句。
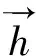
图3 基于LSTM-CRF的朝鲜语分写模型
模型的最后一层通过CRF预测全局最优的分写标注序列,计算如式(12)~(13)所示。
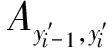
3 实验
3.1 实验数据集
在训练模型之前,首先针对原始语料库进行预处理,其过程如下。
(1) 朝鲜语句子的tokenize: 根据语料库中的句子生成字符序列,同时用
(2) 生成字典: 按照字符频率从高到低进行排序,取前1 000个字符作为字典,未出现在字典中的字符用
(3) 索引化: 根据字典将第一步中的字符序列转化成对应字符的整型数字序列。另外,为了训练固定步长的LSTM网络,将每一条句子的长度截断为40个字符,小于40个字符的句子用
本文采用了HANTEC-2.0语料库,其中包含社会科学、自然科学、一般综合等三大分类的共12 000篇文档。该语料库的文档均为带标签的结构化数据,因此首先抽取了带
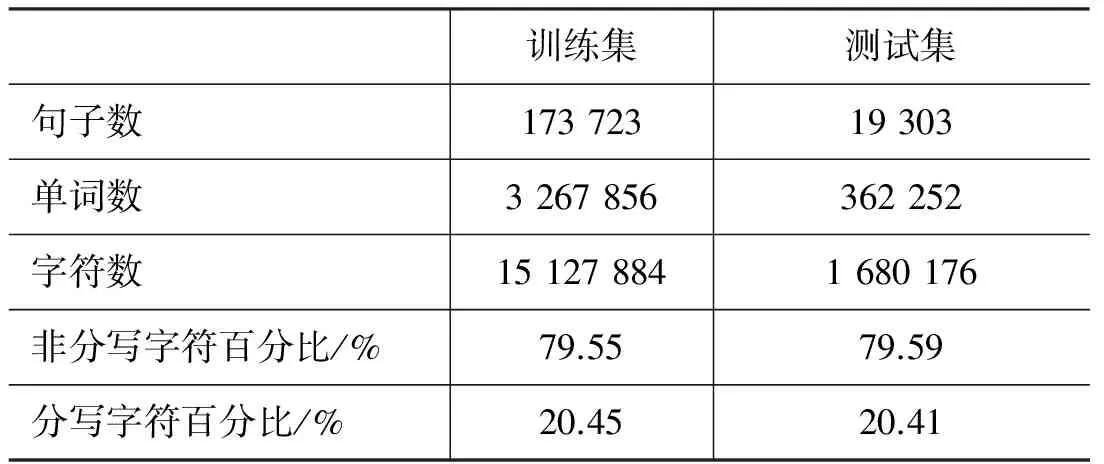
表2 数据集结构
3.2 实验设置
实验中采用了TensorFlow1.0框架,并用NVIDIA的1080GPU进行了加速。具体的模型参数配置如下。
(1) 获取朝鲜语分写增强字符向量: 将训练集和测试集中193 026条句子及对应的分写标注作为输入,训练朝鲜语分写增强字符向量。朝鲜语单词大部分都由四个以内的字符构成,因此模型中参数c设置为2,即目标字符的左右各取两个字符作为上下文窗口,batch size设置为128,学习率为0.001,字符向量的维度d设置为 128。朝鲜语分写标注法采用了四位标注法,即输出向量yt的大小为4。模型通过随机梯度下降法进行优化,经过50个epoch的训练,最终得到大小为1 000×128的朝鲜语分写增强字符向量。
(2) 训练Bi-LSTM-CRF模型: 模型的查询表初始化为上述第一步中预训练得到的字符向量。其他参数均采用均匀分布的随机函数初始化成较小的实数。模型中双向LSTM网络的输入是大小为(128×40×128)的张量,其中第一维代表batch size,第二维表示LSTM网络的长度,第三维表示字符向量的大小。LSTM网络的输出部分将生成(128×40×256)的张量,其中256是前向和后向两个LSTM的Cell拼接而成的向量大小。最后通过全连接及softmax函数得到(128×40×4)的张量,其中Wout大小为256×4,bout大小则是4。
3.3 实验结果及分析
本文采用了如下四种评估指标: 字符级准确率(Pchar)、单词级准确率(Pword)、单词级召回率(Rword)、单词级F1值(F1word),各评估指标的计算方法如式(14)~(17)所示。
实验中复现了相关研究中的几种典型的朝鲜语分写模型,分别是Lee, Rim 2007年提出的基于HMM的分写模型[6]、Shim等人2011年提出的基于CRF的模型[7]、Lee和Kim等人2013年提出的基于Structured SVM的分写模型[8]。另外,为了验证本文提出的朝鲜语分写增强字符向量的有效性,实现了三种模型: 随机初始化的查询表+LSTM+CRF(LSTM-CRF),用CBOW模型预训练的字符向量+LSTM+CRF(CBOW-LSTM-CRF),朝鲜语分写增强字符向量+LSTM+CRF(KWSE-LSTM-CRF)。表3给出了各个模型的实验结果。
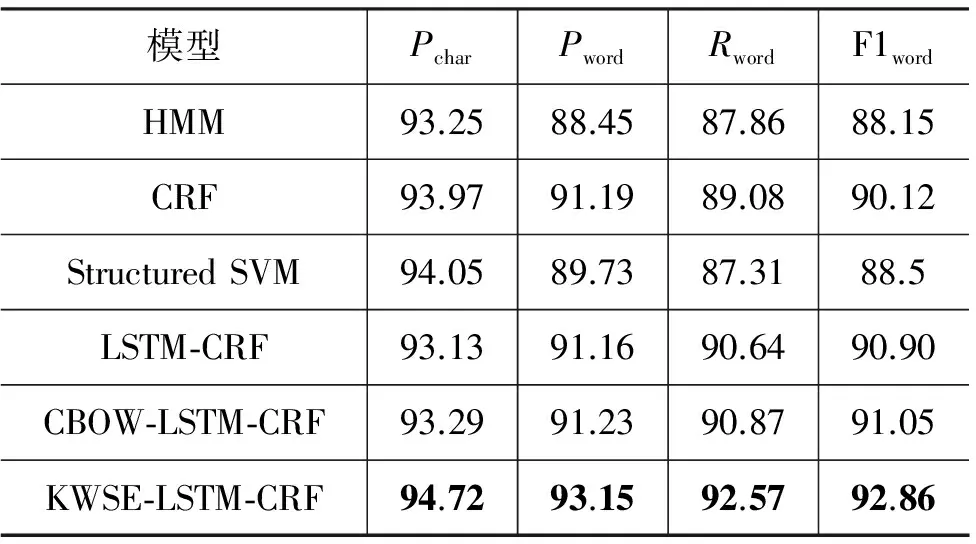
表3 实验结果
从表3中可以看出,我们提出的KWSE-LSTM-CRF方法的字符级准确率、单词级准确率、召回率以及F1值均高于其他现有的方法,其中F1值相比于现有最好的CRF方法提高了2.74%。
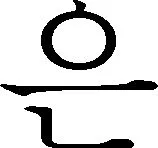
在同样采用LSTM-CRF模型的后三种方法之间的对比中可以看到: 随机初始化字符查询表的方法与CBOW预训练的方法相差无几,说明在朝鲜语分写标注问题上CBOW预训练的字符向量虽然富含字符的语义信息,但是对于分写标注帮助不大。而我们提出的分写增强字符向量由于提前融入了朝鲜语分写倾向性信息,因而有利于LSTM-CRF模型做出更为准确的分写预测。
4 结论
本文提出了一种朝鲜语分写增强字向量模型KWSE,并将KWSE预训得到的字向量应用于基于LSTM-CRF的朝鲜语分写模型中。实验结果表明本文提出的KWSE-LSTM-CRF方法的字符级分写准确率优于现有方法HMM、CRF、Structured-SVM。单词级准确率上,相比于现有最好的CRF模型,本文提出的KWSE-LSTM-CRF方法将F1值提高了2.74%。未来工作中我们希望统计和分析高频分写错误,并分析出与之关联的特定字符或单词,从这方面入手,进一步提高模型的性能。
[1] Kim K S, Lee H J, Lee S J. Three-stage spacing system for Korean in sentence with no word boundaries[J]. Journal of the Korea Information Science Society, 1998, 25(12): 1838-1844.
[2] Kang S S. Eojeol-block bidirectional algorithm for automatic word spacing of Hangul sentences[J]. Journal of KIISE: Software and Applications, 2000, 27(4): 441-447.
[3] Chung Y M, Lee J Y. Automatic word-segmentation flatline-breaks for Korean text processing[C]//Proceedings of the 6th Conference of Korea Society for Information Mangement, 1999: 21-24.
[4] Jeon N Y, Park H R. Automatic word-spacing of syllable bi-gram information for Korean OCR postprocessing[C]//Proceedings of the Annual Conference on Human and Language Technology. Human and Language Technology, 2000.
[5] Kang S S, Woo C W. Automatic segmentation of words using syllable bigram statistics[C]//Proceedings of the NLPRS, 2001: 729-732.
[6] Lee D G, Rim H C, Yook D. Automatic word spacing using probabilistic models based on character n-grams[J]. IEEE Intelligent Systems, 2007, 22(1), 28-35.
[7] Shim K S. Automatic word spacing based on conditional random fields[J]. Korean Journal of Cognitive Science, 2011, 22(2): 217-233.
[8] Lee C, Kim H. Automatic Korean word spacing using Pegasos algorithm[J]. Information Processing & Management, 2013, 49(1): 370-379.
[9] Lee C, Choi E, Kim H. Balanced Korean word spacing with structural SVM[C]//Proceedings of the EMNLP, 2014: 875-879.
[11] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[12] Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C]//Proceedings of the 25th International Conference on Machine Learning. ACM, 2008: 160-167.
[13] Mikolov T, Karafit M, Burget L, et al. Recurrent neural network based language model[C]//Proceedings of the Interspeech, 2010: 2,3.
[14] Hochreiter S, Schmidhuber J. LTSM can solve hard time lag problems[C]//Proceedings of the Advances in Neural Information Processing Systems: Proceedings of the 1996 Conference, 1997: 473-479.
[15] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
