CRF与规则相结合的维吾尔文地名识别研究
2017-03-12买合木提买买提卡哈尔江阿比的热西提艾山吾买尔吐尔根依布拉音王路路
买合木提·买买提,卡哈尔江·阿比的热西提,艾山·吾买尔,吐尔根·依布拉音,王路路
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2. 新疆多语种信息技术实验室,新疆 乌鲁木齐 830046)
0 引言
随着互联网技术的迅速发展,各类信息巨增,网上每天都有海量信息在生成、存储和传播,人类面临前所未有的信息膨胀。如何从海量信息中快速寻找并抽取所需信息是当今信息处理领域面临的一个重要问题,其中命名实体识别是信息抽取的重要部分。因为命名实体识别的性能,对句法分析、语义分析、关系抽取等具有极其重要的影响。
命名实体(named entity,NE)是文本信息中的基本单位,是文本中的固有名称、缩写及其他唯一标识,是正确理解文本的基础[1]。狭义上,可把命名实体分为人名、 地名、组织名等。广义上,命名实体包括时间表达式、数值表达式等,在不同的应用领域,还可以根据具体的需要定义其他类型的命名实体。例如,在某个具体应用中,可能需要把住址、电子信箱、电话号码、会议名称等作为命名实体。
目前命名实体识别方法分为三种: 基于规则的方法[2]、基于统计的方法[3]及基于神经网络的方法[4]。基于规则的命名实体识别的基本思路是人工编写上下文敏感的产生式,使用普通的NE数据库,将不同的权值赋给不同的规则,以便在产生规则冲突时可以选择具有最大权值的规则。基于统计的方法将专名识别看作一般模式识别中分类问题的一个特例,利用字标注的方法来进行命名实体识别。其基本步骤包括特征选择、机器学习、标注、后处理。基于深度学习的方法通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示,需要比较大的数据规模。
目前,维吾尔文命名实体识别研究处于起步阶段,国内有关维吾尔文命名实体识别主要集中在人名识别[5-8]、时间表达式识别与抽取[9]、基于规则的机构名[10]、地名[11]识别方面。未有见到使用统计的方法研究维吾尔文地名识别有关的报道。
维吾尔文地名识别具有独特的词法、语言特点,所以直接套用英语和汉语的方法并不合适。目前,还没有公开的维吾尔语地名标注语料,因此本文通过人工标注建立了1.3余万句子的维吾尔文地名标注语料库。在深入分析维吾尔文地名语法和语义特征的基础上,鉴于条件随机场在序列标注任务中的优异表现,首次使用条件随机场模型实现了维吾尔文地名自动识别方法。在特征模板的设计上,我们使用词、音节、词性标注、分布式向量表示[12]等不同特征,分析了它们对地名识别的影响。实验结果表明,我们的方法在测试数据上的F值达到92.03%。
1 维吾尔文地名特点及识别难点
维吾尔文地名像中文、英文地名一样,具有数量庞大、音译地名较多、地名用词比较自由、地名词长没有限制、多词地名结尾经常有地名特征词出现、不同词性的词(如形容词、人名、实物名、方位词、连词等)经常出现在多词地名的首词或中间词位置等共同特点,如表1所示。
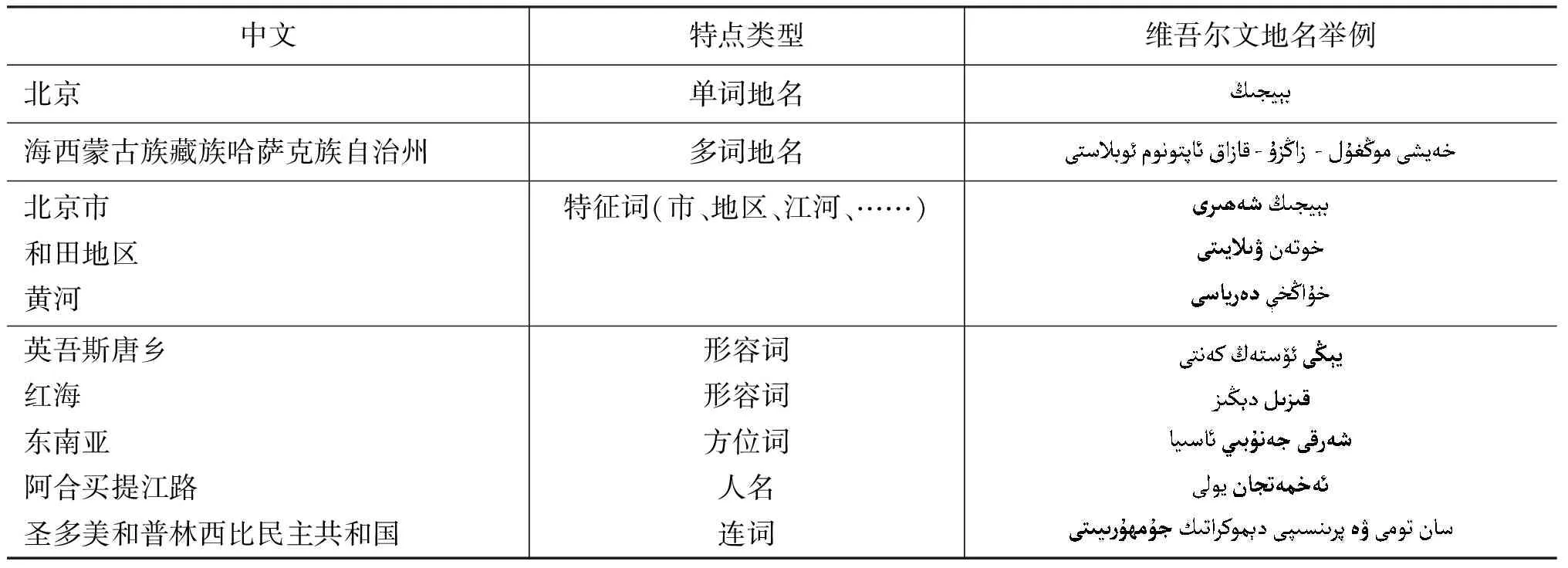
表1 维吾尔文地名与其他语言地名的共有特点
除共有特点之外,维吾尔文地名也有以下比较独特特点,这也是维吾尔文地名识别所面临的挑战。
(1) 维吾尔语的黏着性、元音弱化等特性导致数据稀疏,地名可以连接名词格词缀,维吾尔语名词格词缀有24种,这样一个地名可能会出现24中形态变化,降低词汇重复率,引发统计模型中的未登录词问题,示例如表2所示。
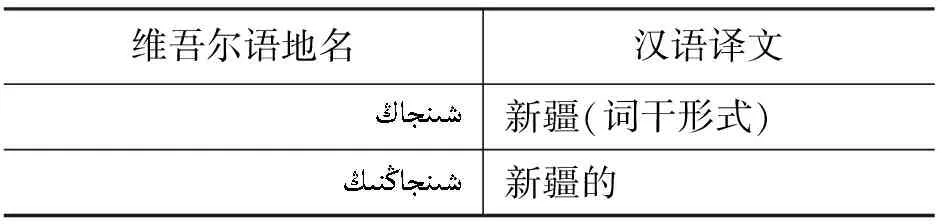
表2 维吾尔语地名黏着性示例(单词地名)
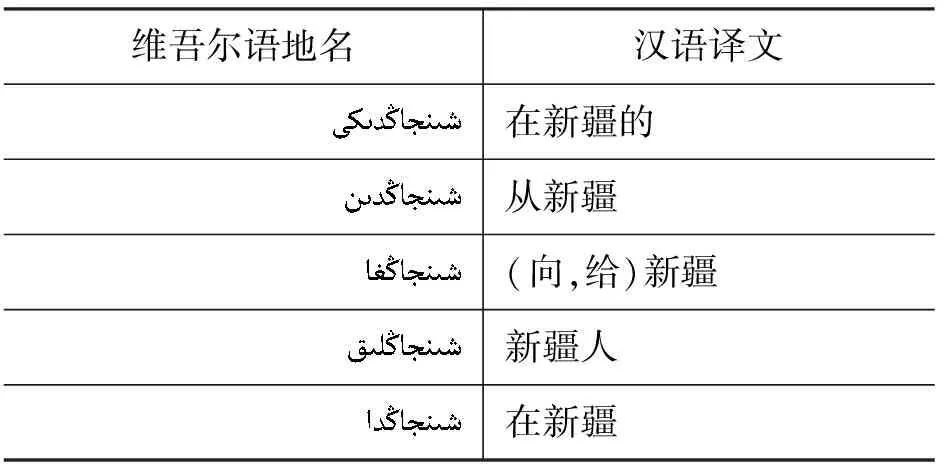
续表
值得注意的是,大多数情况下,多词地名的最后一个词(或特征词)才会连接附加成分,该地名中的其余词语一般不会连接附加成分,如表3所示。
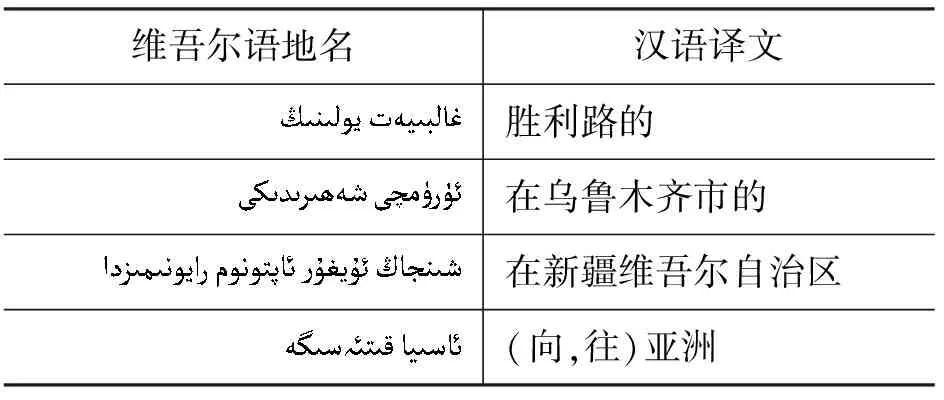
表3 维吾尔语地名黏着性示例(多词地名)


表4 维吾尔语地名元音弱化示例
(2) 由于地名词长一般没有严格的限制,单词地名又可以作为多词地名的一部分出现,多词地名又可以根据文本中的上下文描述需要,忽略其中的中间词或特征词或者只用特证词代替整个地名来使用其简称,再加上黏着性,使得数据更加稀疏,导致识别更加困难,如下例所示。

(3) 新涌现的地名大多数以音译为主,相对维吾尔文中的自然地名,这类外来词地名不受严格的维吾尔语拼写规则的限制,部分中间词和特征词也有这种情况出现,从而会导致以下两种情况: 一是字母连接不同寻常,音节特殊;二是经常出现拼写错误,示例如表5所示。

表5 维吾尔语外来音译地名示例
(4) 部分单词地名具有共同的特征词缀,示例如表6所示。
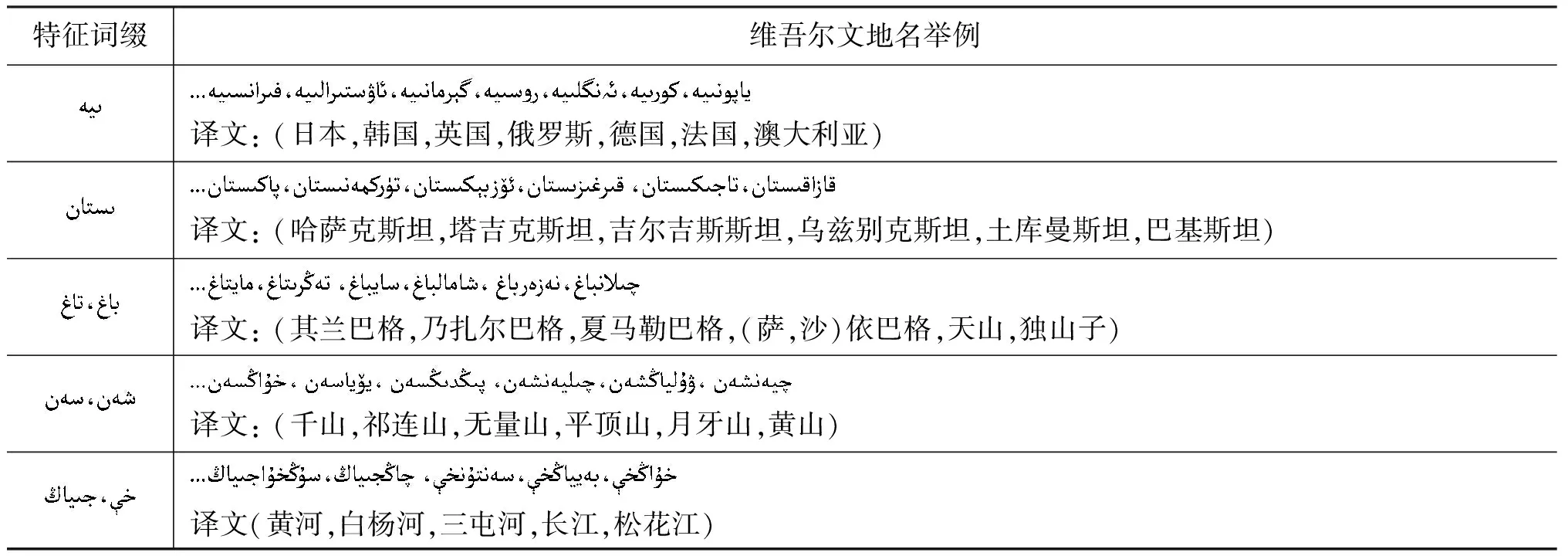
表6 维吾尔文共同词缀地名示例
2 基于条件随机场的维吾尔语地名识别
2.1 条件随机场模型
条件随机场模型是在给定输入节点条件下计算输出节点的条件概率的无向图模型,定义W=w1w2…wn为给定的n个输入节点的值,比如一个句子。定义O为有限状态机的状态,O=o1o2…oN为一个长度为N的输出节点的值。对于一个带有参数Θ=θ1θ2…θk的线性链,将给定的序列W得到的状态序列的条件概率定义为式(1)、式(2)。
其中,ZW是归一化参数,它使得给定输入的所有可能状态序列的概率之和为1。fk(On-1,On,W,n)是对于整个观察序列W,标记位于N和N-1之间的特征函数,特征函数可以是0、1值,也可以是任意实数。Θ=θ1θ2…θk是特征函数对应的权重。对于W来说,目标是搜索概率最大的O*=argmaxP(W|O)。
2.2 分布式向量表示
在自然语言处理过程(NLP)中,首先需要考虑的问题是如何对自然语言进行建模,使得计算机可以处理自然语言。目前常用的表示方法主要有两种: “one-hot”表示和分布式向量表示(word embedding)。分布式向量表示是Mikolov在2013年提出的[12]。
目前Word2vec已经在众多NLP领域得到应用,如词性标注[13]、命名实体识别[14]、聚类和情感分析[15]等。Word2vec内置两种训练模型,CBOW模型和Skip-gram模型。CBOW 模型是根据输入当前词的上下文来预测当前词,如图1所示。Skip-gram 模型是根据输入的当前词去预测当前词的上下文,如图2所示。
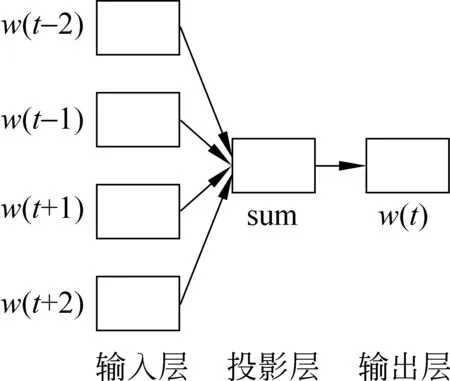
图 1 CBOW 模型结构
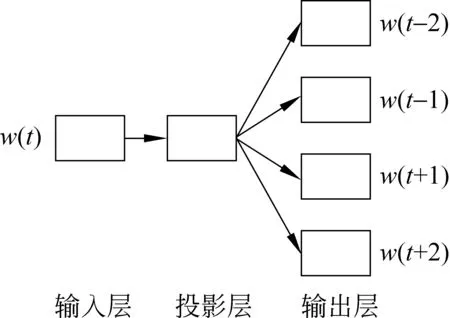
图 2 Skip-gram 模型结构
2.3 特征描述
CRFs模型的性能取决于特征,因此我们根据命名实体识别领域常用特征,增加了Word Embedding特征,我们以容易获得为主要特征选择原则,所选择的特征如下。
(1)单词特征(Fw) 即tokens特征,我们分别选择当前token及其前后的一个token(Fw1),两个token(Fw2)和三个token(Fw3)来分析tokens的不同窗口大小对地名识别的影响,并确认了最佳窗口大小为5(Fw2)。
(2)音节特征(Fs) 从第一节中描述的维吾尔语地名特点可知,大多数地名词语的最后一个或两个音节对识别该地名的影响比较大,因此我们从单词后缀部分摘取一个或两个音节作为特征。当单词音节数小于等于2时,取一个音节;当单词音节数大于2时,取两个音节。单词特征确认后,我们又分别选择当前token及其前后的一个token的音节(Fs1),两个token的音节(Fs2)和三个token的音节(Fs3)来分析音节的不同窗口大小对地名识别的影响,并确认了最佳窗口大小为3(Fs1)。
(3)词性特征(Fp) 单词特征确认后,我们又分别选择当前token及其前后的一个token的词性(Fp1)、两个token的词性(Fp2)和三个token的词性(Fp3)来分析词性的不同窗口大小对地名识别的影响,并确认了最佳窗口大小为3(Fp1)。
(4)Wordembedding特征(Few) 我们在词向量特征的选择上,分别选择了与当前token最相似的一个词(Few1)、两个词(Few2)、三个词(Few3)、四个词(Few4)和五个词(Few5)来进行实验分析。选择相似词的时候,分别通过CBOW和Skip-gram获取的词加在一起,根据相似度进行排序,然后提取相似度最高的前五个词。WordEmbedding特征的窗口大小设置为3,即只考虑当前词的前后词。
(5)词典特征(Fdic) 根据地名特点,我们主要建立了三种词典,分别是常用地名词典(Floc)、地名特征词词典(Ffw)及地名共同词缀词典(Fsfx)。
常用地名词典(Floc) 该词典收录了世界各国家及其主要城市名、中国省份及主要城市等,共3 013个。当前词在常用地名词典内则其特征值为D-Loc,否则为D-No。

地名词缀特征(Fsfx) 从表6可知,维吾尔语有部分地名具有共同词缀,因此我们收集了经常作为地名词缀的字符序列作为地名词缀特征表,共29个,其示例见表6。特征生成时,如果当前词词缀在词缀特征表里,则对应特征值为SFX-Y,否则为SFX-N。
实验的所有数据均使用新疆多语种信息技术实验室自然语言处理组维吾尔语自然语言处理工具包(网络服务)*http://202.201.255.248:8088/xjuapi/uyghurtext/。进行分词、分音节、词性标注处理。使用400万句单语语料进行词向量训练,工具使用Txt2Vec*https://github.com/zhongkaifu/Txt2Vec。,分别基于Skip-gram模型和CBOW模型训练tokens的Embedding。本实验设置窗口的大小为5,Embedding的维度为200。
数据通过处理之后,每行有12列,包括词、音节、词性标注、相似词、地名词典特征、地名特征词词典特征、地名词缀特征及地名标注符号等。其中地名标注符号列的标记有三种(使用IOB2[16]标记),分别是:O—非地名标记,B-Location—地名首词标记,I-Location—地名非首词标记。经过这种标记标注后,一个单独的B-Location标记表示单词地名。B-Location+I-Location+ [I-Location]…标记表示双词或多词地名。
2.4 基于规则的后处理
基于规则的方法可以有效地弥补机器学习不能表达语言的确定性的缺点,因此为了进一步提高识别性能,我们通过分析CRF对真实语料错误识别的示例,归纳出了修正规则。下面是部分规则的描述。


规则3当前词被标注为地名,且其前后有“‘”符号,则该词后面的“‘”符号后的词识别为一个单词地名。

3 实验
3.1 实验数据集及评价方法
由于目前尚没有公开的地名标注数据,本文手工建立了一个维吾尔文地名标注语料库。我们根据汉语命名实体从新疆多语种信息技术实验室自然语言处理组汉维新闻对齐语料中随机抽取了1.5万条句子进行人工标注后,过滤掉其中没有地名或质量不高的句子,挑选了13 385条句子,数据集的主要情况如表7所示。
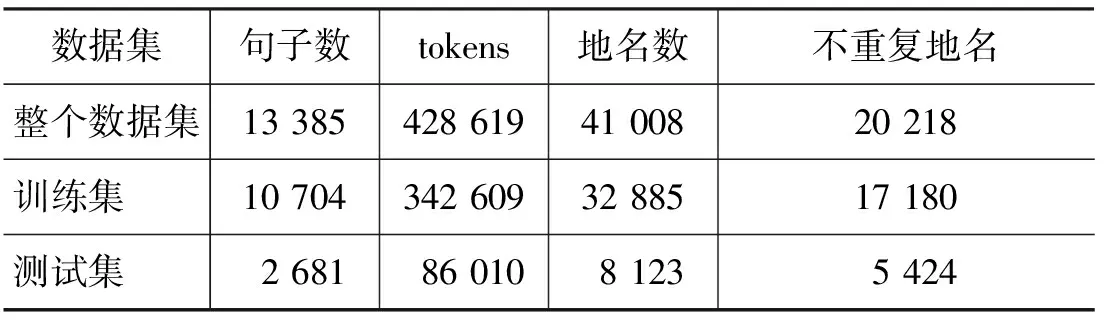
表7 维吾尔地名标注语料库
本文将采用准确率(P),召回率(R)和F值等三个指标来评价实验的性能,计算公式如式(3)~(5)所示。

(3)

(4)
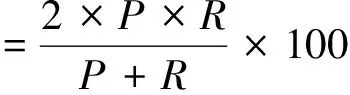
(5)
3.2 实验结果与分析
3.2.1 单词窗口大小对识别性能的影响
首先验证不同单词窗口大小对测试结果的影响,选取最优的单词窗口进行下一步的实验。在选取窗口大小时,分别选择窗口大小为3(Fw1)、5(Fw2)、7(Fw3),进行了不同窗口大小实验,结果如表8所示。可以看到,F值并未随着窗口大小的增加而呈现上升趋势,单词窗口大小为5(Fw2)的时候性能最好,F值为81.86%。除此之外,该实验又证明,单词特征对地名识别非常重要,只根据单词特征也可以达到比较高的识别效率。
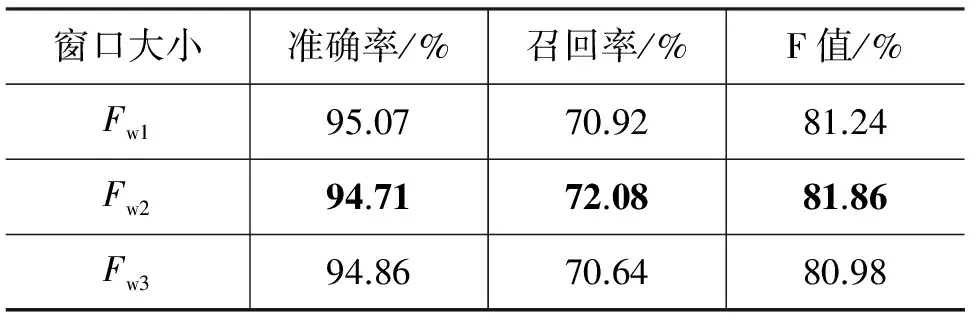
表8 单词窗口大小对识别性能的影响
单词窗口大小确定后(Fw2),我们接着考察特征频率对识别性能的影响,如表9所示。实验结果表明,随着特征频率的增加,准确率逐步下降,反而召回率和F值有比较明显的提高,当特征频率大于等于2的时候系统性能最佳。
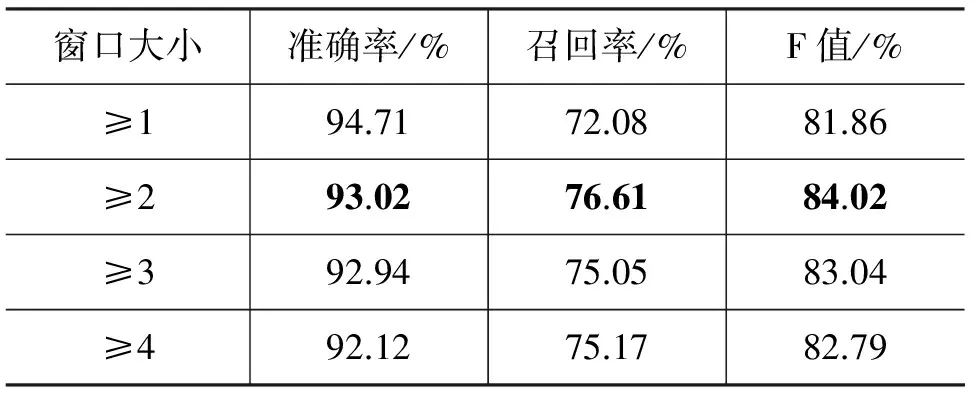
表9 特征频率对识别性能的影响
3.2.2 不同特征及其窗口大小对识别性能的影响
在3.2.1节中确定单词特征为Fw2且特征频率大于等于2时性能最佳,因此下面在此实验基础上,分别加入音节特征(Fs)、词性特征(Fp),word embedding特征(Few)及词典特征(Fdic),进行不同特征在不同窗口下的实验。
音节及其窗口大小对识别性能的影响如表10所示。从中可以看出,一方面,音节窗口的增加并未导致F值的上升,反而逐步下降,当音节窗口大小为3(Fs1)时,系统的F值达到了最佳值88.16%,其原因可能为当前词的最后音节或后缀受到前一个词的影响,或它影响下一个词的音节或后缀;另一方面,无论音节窗口大小取为何值,加入音节特征后系统的性能比仅考虑单词特征时要好,F值提高了4.14%,这说明音节特征对地名识别具有重要的影响。
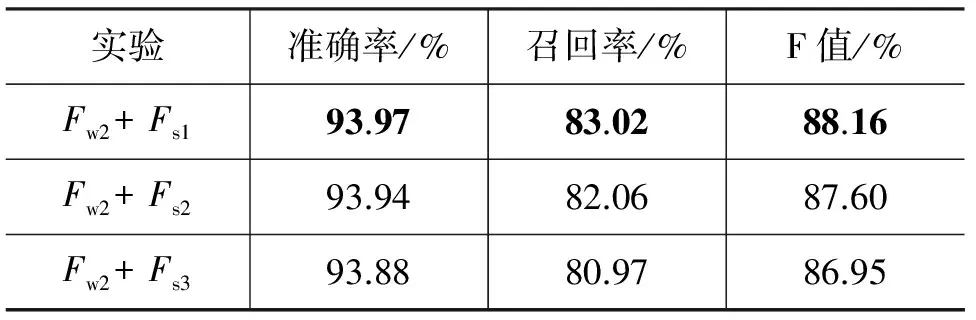
表10 音节及其窗口大小对识别性能的影响
词性及其窗口大小对识别性能的影响如表11所示。从中可以看出,一方面,词性窗口的增加并未导致F值的上升,反而在下降,在三种不同窗口下加入词性后的系统性能差别不是很明显,其原因可能为受到了词性标注准确率的影响;另一方面,无论词性窗口大小取为何值,加入词性特征后系统的性能比仅考虑单词特征时要好,当词性窗口大小为 3(Fp1)时F值最好,提高了2.25%,这说明词性特征对地名识别也有重要的影响。
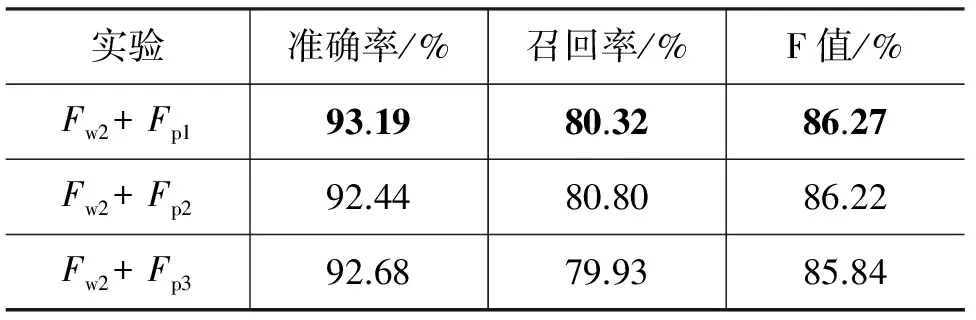
表11 词性及其窗口大小对识别性能的影响
通过词向量获取的与当前词最相似的前五个词分别加入到特征后的实验结果如表12所示。从实验结果可以看出,随着相似词数量的增加,F值也逐步提高,其原因可能为训练词向量语料规模不够,从而对一些低频词的表示不太准确。无论选取的相似词数量多或者少,加入词表示特征后系统的性能比仅考虑单词特征时要好,最好时F值提高了4.2%,这说明通过使用词表示方法来获取相似词作为特征引入可以提高识别性能。

表12 基于word embedding的相似词对识别性能的影响
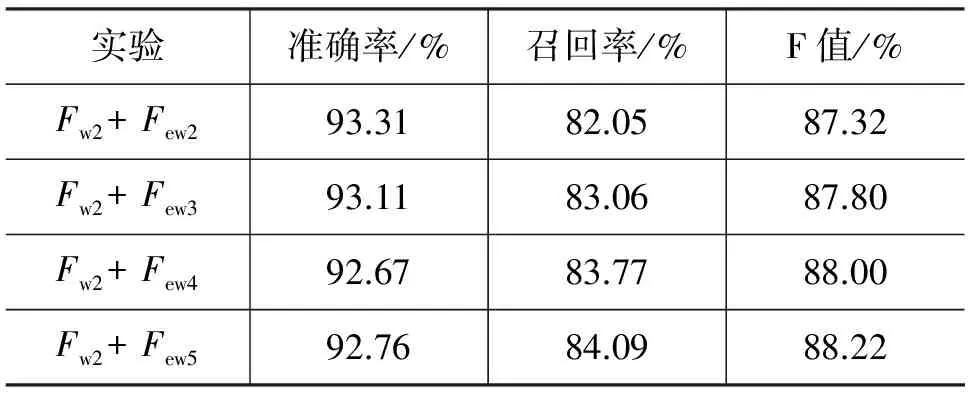
续表
总结以上几个实验可以看出,音节、词性及word embedding都对维吾尔语地名识别性能的提高起比较重要的作用,其中word embedding和音节的影响最大,F值分别提高了4.2%和4.14%,其次为词性,F值提高了2.25%。当word embedding的相似词数量大于等于2的时候,音节特征和word embedding特征的影响不分上下,差别比较小,word embedding特征的召回率比音节特征稍高,音节特征的准确率均高于word embedding特征,因此在没有音节切分工具或词性标注系统的情况下,可以考虑使用词表示来构造特征是可行的。当单词特征选取最佳的Fw2(窗口大小为5)时,词性和音节可以选取Fs1和Fp1(窗口大小均为3),基于word embedding的相似词取Few3(3个)及以上来达到最好的系统性能。
3.2.3 不同词典对识别性能的影响
不同词典及其组合对识别性能的影响如表13所示。实验结果表明,常用地名词典、特征词词典及地名词缀词典都有助于提高系统的识别性能,其中常用地名词典的影响最大,其次为地名特征词词典,最后为地名词缀词典。地名词缀词典性能相对低的主要原因是因为,很多地名在文中往往有附加成分连接,此时无法有效提取地名共同词缀特征。三种词典相组合时系统性能最佳,F值比仅考虑单词特征时提高了4.52%。
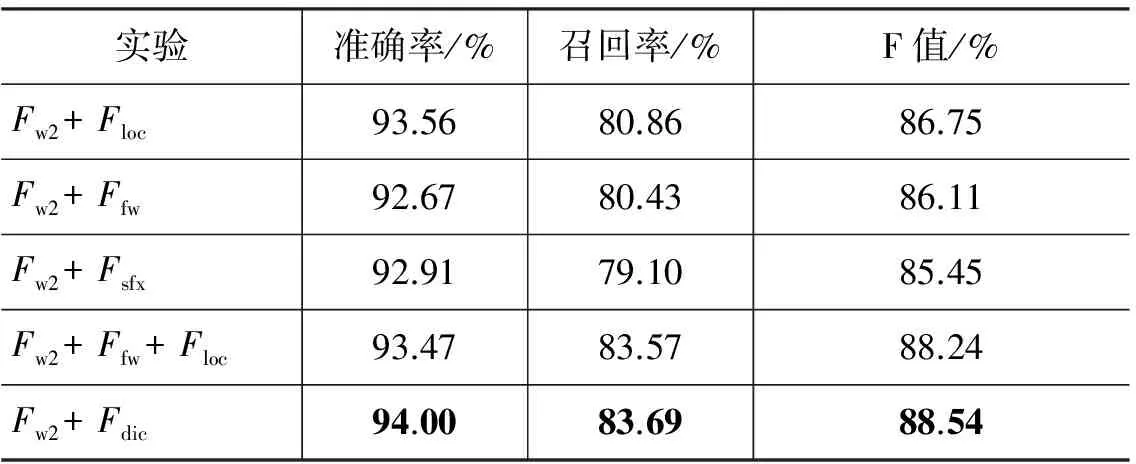
表13 不同词典及其组合对识别性能的影响
3.2.4 不同特征组合对识别性能的影响
在3.2.2节实验的基础上,我们继续组合不同特征进行实验。鉴于Fw2+Fs1的F值最好,我们在此组合基础上分别增加了词性特征和word embedding 特征,实验结果如表14所示。从实验结果可知,分别增加这两种特征后,F值均有提高,增加word embedding的性能优于增加词性特征。增加词性特征时,随着词性特征窗口的变大,系统性能反而下降;增加word embedding特征时,随着相似词数量的增加,系统性能并没有一直上升,甚至出现下降现象,但是总体来看呈上升趋势(特别是召回率),因此继续增加相似词数量可能有助于提高系统性能。
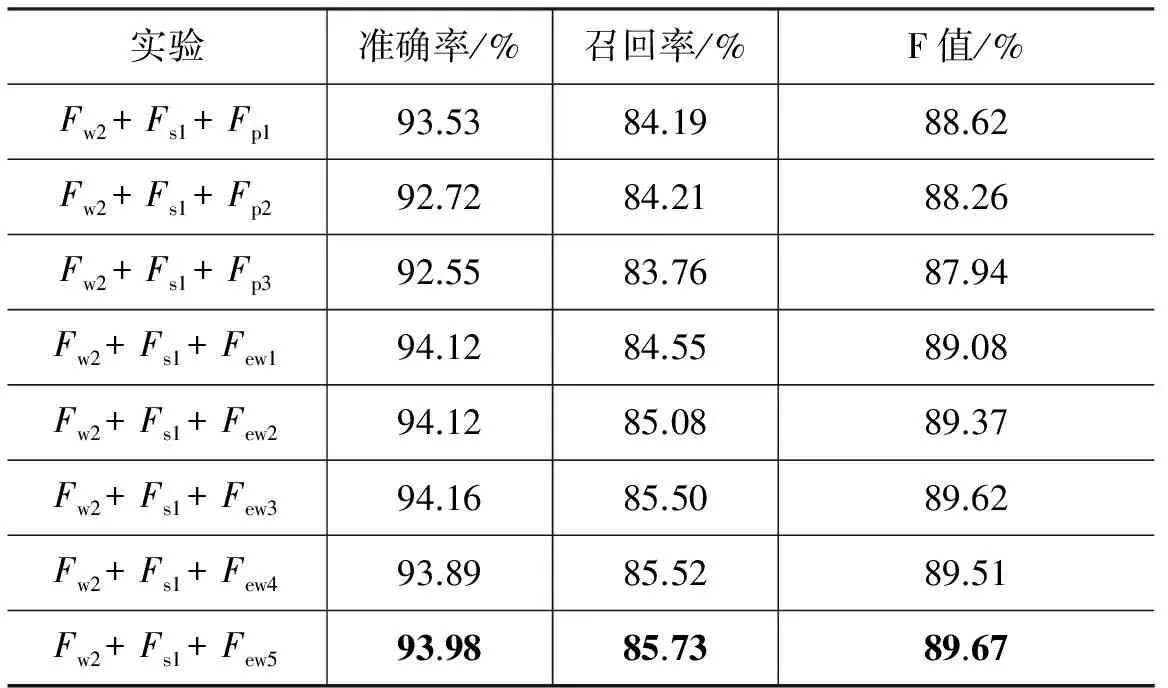
表14 三种特征组合对比实验
接下来我们在上一步实验的基础上,对它的特征模板进行了扩充,即使用了一些混合特征,分别增加了当前词及其词性、当前词及其音节,以及当前词及其前后词的音节和词性(Fp12)等unigram特征,并与word embedding特征组合进行实验,结果如表15所示。四种特征组合后,随着word embedding的相似词数量的增加,F值并没有一直呈上升趋势,反而性能差别非常小,由此可以看出四种特征组合进行实验时,相似词数量对系统性能影响很小,这可能是因为音节特征和词性特征已经覆盖了大多数语言特征。四种特征组合实验中,当选择Fw2+Fs1+Fp12+Few5特征组合时,F值达到了90.15%,比上一步实验提高了0.48%。
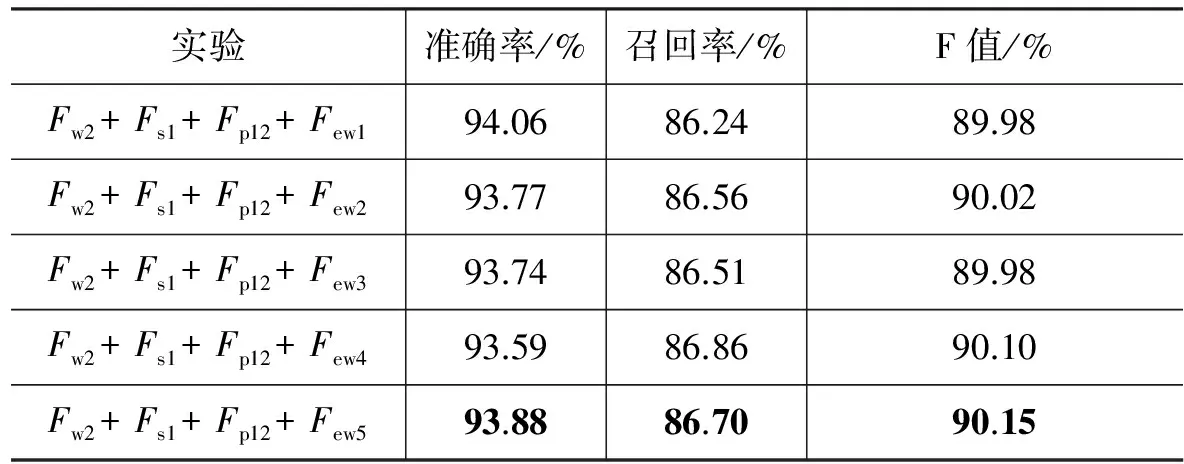
表15 四种特征组合对比实验
为了考察词典特征Fdic对识别性能的影响,我们对以上各类实验中性能最好的特征组合上词典特征分别进行了对比实验,结果如表16所示。实验结果表明,加入词典特征后,系统性能得到非常显著的提高,特别是召回率比,准确率提高得更为明显。
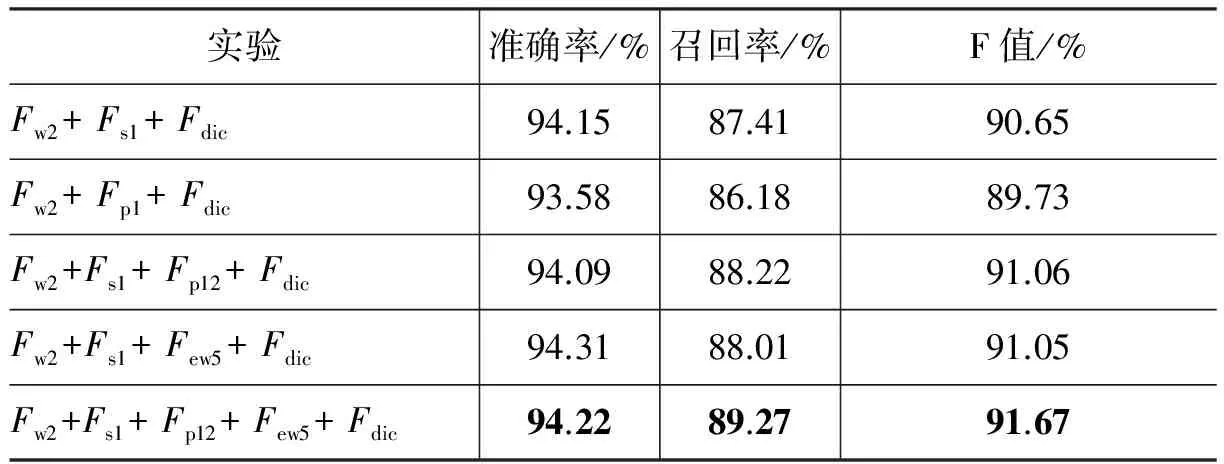
表16 词典特征对识别性能的影响
3.2.5 基于规则的后处理对识别性能的影响
从上一节实验结果可知,基于CRF模型的维吾尔语地名识别方法可以得到非常不错的识别结果,但是结果中还存在一些漏掉的、识别错误的地名,因此我们对这些情况使用规则进行了修正,从而进一步提高了系统性能,实验结果如表17所示。
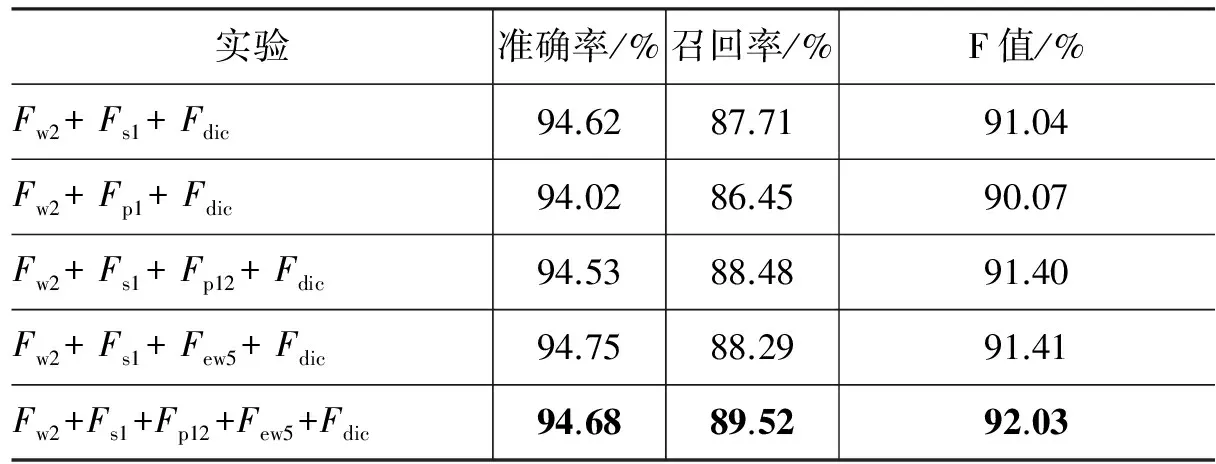
表17 基于规则进行后处理的实验结果
4 结论
本文利用地名人工标注语料和大规模单语语料数据,采用CRFs结合规则的方法对维吾尔文地名识别进行了研究,通过选取单词、音节、词性、基于词向量的相似词、词典等不同的特征及其组合,在不同的窗口大小下,对维吾尔文地名识别进行了实验。实验结果表明,单词特征、词性特征、音节特征对地名识别具有重要影响;同时引入词表示特征后,也可以提高系统性能,可以将比较难的维吾尔语词性特征由词表示特征来代替,从而可以减少识别工作的复杂度;再通过引入词典特征(常用地名词典、地名特征词词典、地名特征后缀词典等)和基于规则的后处理,有效地提高了识别性能。这说明本文所提出的不同特征窗口大小的选择、特征的组合方式、词表示特征的应用方法、词典特征以及基于规则的后处理对维吾尔语等资源匮乏、自然语言处理水平较低的语言具有一定的意义。
除了取得比较好的结果以外,本文还有一些局限性。例如,有些地名连接附加成分后会出现元音弱化现象,导致无法提取词典特征,容易出现漏识,在以后的研究中需要进一步改进。因此,下一步工作中,我们将本文的成果与人工标注相结合,尝试采用深度学习方法对维吾尔文地名识别做进一步研究;此外,我们将地名识别和其他命名实体识别任务,比如人名识别、机构名识别等相结合,进行多类命名实体识别研究。
[1] Nadeau D, Sekine S. A survey of named entity recognition and classification [J]. Lingvisticae Investigationes, 2007, 30(1): 3-26.
[2] Mikheev A, Moens M, Grover C. Named entity recognition without gazetteers[C]//Proceedings of the ninth Conference on European Chapter of the Association for Computational Linguistics, Association for Computational Linguistics, 1999: 1-8.
[3] 黄德根, 岳广玲, 杨元生. 基于统计的中文地名识别 [J]. 中文信息学报, 2003,17(02): 36-41.
[4] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[C]//Proceedings of NAACL 2016.
[5] 加日拉·买买提热衣木, 吐尔根·依布拉音, 艾山·吾买尔. 基于统计和规则混合策略的维吾尔人名识别研究[J]. 新疆大学学报(自然科学版), 2014, 31(03): 319-324.
[6] 艾斯卡尔·肉孜, 宗成庆, 姑丽加玛丽·麦麦提艾力,等. 基于条件随机场的维吾尔人名识别方法[J]. 清华大学学报(自然科学版), 2013(6):873-877.
[7] 热合木·马合木提, 于斯音·于苏普, 张家俊, 等. 基于模糊匹配与音字转换的维吾尔语人名识别[J]. 清华大学学报(自然科学版), 2017(02): 188-196.
[8] 李佳正, 刘凯, 麦热哈巴·艾力, 等. 维吾尔语中汉族人名的识别及翻译[J]. 中文信息学报, 2011, 25(04): 82-87.
[9] 阿依古丽·哈力克, 艾山·吾买尔, 吐尔根·伊布拉音, 等. 汉维时间数字和量词的识别与翻译研究[J]. 中文信息学报, 2016,30(06): 190-200.
[10] 麦合甫热提, 米日姑·肉孜, 麦热哈巴·艾力, 等. 基于语法语义知识的维吾尔文机构名识别[J].计算机工程与设计, 2014, 35(08): 2944-2948.
[11] 木合塔尔·艾尔肯, 艾斯卡尔·艾木都拉, 地里木拉提·吐尔逊. 基于规则的维吾尔地名识别[J]. 通信技术, 2013(7):103-105.
[12] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the Advances in Neural Information Processing Systems, 2013: 3111-3119.
[13] Santos C D, Zadrozny B. Learning character-level representations for part-of-speech tagging[C]//Proceedings of the 31st International Conference on Machine Learning (ICML-14), 2014: 1818-1826.
[14] Demir H, Özgür A. Improving named entity recognition for morphologically rich languages using word embeddings[C]//Proceedings of the Machine Learning and Applications (ICMLA), 13th International Conference on, IEEE, 2014: 117-122.
[15] Tang D, Wei F, Yang N, et al. Learning sentiment-specific word embedding for twitter sentiment classification[C]//Proceedings of the ACL (1), 2014: 1555-1565.
[16] Tjong K S E F, Buchholz S. Introduction to the CoNLL-2000 shared task: chunking[C]//Proceedings of The Workshop on Learning Language in Logic and the Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2000:127-132.
