大数据处理平台Spark基础实践研究
2017-02-23邱丽娟
邱丽娟
(厦门南洋职业学院,福建 厦门 361102)
大数据处理平台Spark基础实践研究
邱丽娟
(厦门南洋职业学院,福建 厦门 361102)
Spark是主流的大数据并行计算框架。文章将通过几段Scala脚本,演示在Spark环境下通过Map-Reduce框架处理大数据。
大数据;Spark;Map-Reduce 框架
Spark基于内存计算,提高了在大数据环境下数据处理的实时性。与很多分布式软件系统相同,用户可以将Spark部署在大量廉价的Linux硬件之上,形成性价比很高的计算集群。Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。在100 TB Daytona GraySort比赛中,Spark战胜了Hadoop,它只使用了十分之一的内在,但运行速度提升了3倍。Spark也已经成为针对PB级别数据排序的最快的开源引擎。
理解Spark大数据处理,一个关键概念便是RDD。由于Map-Reduce Schema on Read处理方式会引起较大的处理开销。Spark抽象出分布式内存存储结构弹性分布式数据集RDD进行数据的存储。RDD模型很适合粗粒度的全局数据并行计算,但不适合细粒度的、需要异步更新的计算。RDD是Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
Spark的整体工作流程为:客户端提交应用,主节点找到一个工作节点启动Driver,Driver向主节点或者资源管理器申请资源,之后将应用转化为RDD Graph,再由DAGScheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。
1 计算圆周率

2 单词计数
单词计数是最常见的大数据处理场景,也是理解Map-Reduce的最佳范例。
所谓Map-Reduce,就是指把任意复杂的计算任务,分解为两个函数:(1)map函数:接受一个键值对,值是一行数据,键是根据值计算获得的哈希。map函数产生一组中间键值对,Map-Reduce框架会将map函数产生的中间键值对当中的键相同的值传递给reduce函数。(2)reduce函数:接受一个中间键值对,键是唯一的,值是一个数组。reduce对值进行归并。
正是借助Map-Reduce框架,才解决了把计算任务“切片”交给大规模集群的问题,任务得以并行计算,最后汇总结果。这里为简化起见,不考虑标点符号对计算结果的影响,并假设所有的单词之间以空格间隔。

3 倒排索引
倒排索引(inverted index)源于实际应用中需要根据属性的值来查找记录。在索引表中,每一项均包含一个属性值和一个具有该属性值的各记录的地址。由于记录的位置由属性值确定,而不是由记录确定,因而称为倒排索引。
搜索引擎的关键步骤便是建立倒排索引。相当于为海量的网页做了一个索引,用户想看与哪一个主题相关的内容,直接根据索引即可找到相关的页面。
假设存在6篇文章,每篇文章的ID已知,文章ID与文章内容之间以Tab建间隔:

对以上文章创建倒排索引的Scala程序如下:
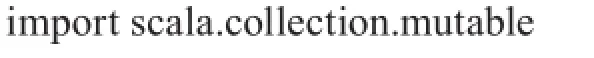
/*读取数据,数据格式为一个大的HDFS文件中用 分隔不同的文件,用 分隔文件ID和文件内容,用" "分隔文件内的词汇*/

/*将(词,文档ID)的数据进行聚集,相同词对应的文档ID统计到一起,形成(词,"文档ID1,文档ID2,文档ID3……”),形成简单的倒排索引*/
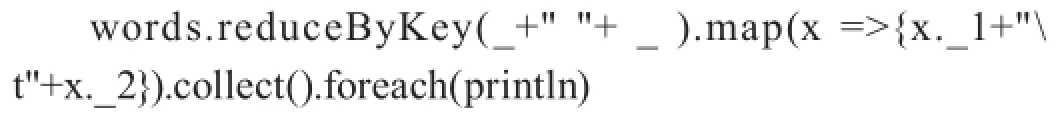
4 计算中位数
统计海量数据时,经常需要预估中位数,由中位数大致了解某列数据,做机器学习和数据挖掘的很多公式中也需要用到中位数。
假设数据按照下面的格式存储:1 2 3 4 5 6 8 9 11 12 13 15 18 20 22 23 25 27 29
计算中位数的思路是:将整体的数据分为K个桶,统计每个桶内的数据量,然后统计整个数据量;根据桶的数量和总的数据量,可以判断数据落在哪个桶里以及中位数的偏移量;取出这个中位数。Scala脚本如下:
Research on Spark basis practice of big data processing platform
Qiu Lijuan
(Xiamen Nanyang University, Xiamen 361102, China)
Spark is the major framework of parallel computing of big data. This article will illustrate how to process big data through Map-Reduce framework under the background of Spark by several Scala scripts.
big data; Spark; Map-Reduce framework


邱丽娟(1978— ),女,江西南昌,本科,讲师;研究方向:程序设计。
