基于端系统应用的分组I/O加速技术*
2016-12-23李世星龙永新刘三毛
李世星,杨 惠,龙永新,刘三毛
(1.湖南工业大学 计算机与通信学院,湖南 株洲 412000;2.国防科学技术大学 计算机学院,湖南 长沙 410073)
基于端系统应用的分组I/O加速技术*
李世星1,杨 惠2,龙永新1,刘三毛1
(1.湖南工业大学 计算机与通信学院,湖南 株洲 412000;2.国防科学技术大学 计算机学院,湖南 长沙 410073)
在网络系统中,优化端系统的数据路径能够使数据在网络接口和应用程序之间快速移动。因此,研究基于端系统应用的分组I/O加速技术,对分组I/O的发送和接收路径分别优化,有助于提高数据移动效率,减少CPU停滞,实现内存并行处理。本文提出分组I/O接收端流亲和技术, 分组I/O发送端链式发送技术。基于通用多核处理器和FPGA搭建端系统实验环境,并对分组I/O加速后的端系统进行性能测试,实验结果表明,采用分组I/O加速技术的端系统,能够使报文收发性能提升2.14倍。
端系统;多核;数据路径;FPGA
0 引言
包含多核处理器的端系统,随着多核处理器处理性能的不断提升,运行的应用越来越复杂[1]。然而拥有多核、高速处理能力的端系统,并没有对数据的接收与发送路径进行优化,端系统接收数据包、发送数据包占据大量的处理时间,数据吞吐率成为制约端系统性能的瓶颈。Intel[2]指出当前多核处理器设计时并未考虑到网络处理中分组I/O的问题,在获得了高效网络处理性能的同时,也伴随着分组I/O带来的处理时间长和网卡设计复杂的问题。为了降低网络应用带来的I/O开销,本文提出了基于端系统的分组I/O加速技术。其主要思想是接收数据路径实现流亲和技术,发送数据路径实现链式发送技术。
1 相关研究
针对多核网络分组处理系统的分组I/O开销大的问题,Intel为通用多核处理平台提出了数据平面开发工具套件DPDK[2],为高速网络设计了一套数据平面库,提供了统一的处理器软件编程模式,从而帮助应用程序有效地接收和发送数据,提高分组I/O性能。Packetshader则采用大报文缓冲区的方式[3],静态地预分配两个大的缓冲区(SKB控制信息缓冲区和分组数据缓冲区),通过连续存储每个接收分组的SKB控制信息和分组数据,避免缓冲区申请、释放以及描述符的转换操作,有效降低分组I/O开销和访存开销。Netmap[4]通过预分配固定大小缓冲区,采用批处理和并行数据路径的方法,实现了内存映射,存储信息结构简单高效,能够实现报文的高速转发。DCA通过处理器硬件支持,将接收网络分组直接写入LLC cache,减小CPU访问分组描述符的延时[5]。而PFQ[6]接收的报文不需要通过标准协议栈处理,直接送入批处理队列进行批处理。现有研究采用内存映射的零拷贝技术,只能解决拷贝的开销,不能解决报文缓冲区分配和释放开销。
2 分组I/O接收端流亲和技术
流亲和技术通过构造和维护多个动态链表,对端系统应用中报文数据进行处理、传输,并以DMA方式写入内存。
2.1 分组I/O接收端流亲和加速模型
本文采取接收报文缓冲区流亲和加速模型。将缓冲区描述符分配、回收交由硬件处理,以实现报文零中断处理。为每一个线程分配一个存储区链表,减少上下文切换开销,减少线程乱序存储造成的TLB表频繁缺失。报文缓冲区描述符管理机制、DMA接收机制将对本文提出的流亲和技术具体实现做出详细说明。
2.1.1 流亲和报文缓冲区描述符管理机制
以多核处理器提供线程数是m为例。如图1所示,先由软件初始化数据至m个缓冲区块描述符FIFO,每个内核缓冲区内地址连续,地址大小相等,地址块大小相等。每个块地址包含k个地址。在每一个内核缓冲区内通过块描述符FIFO和偏移计数器分配地址。
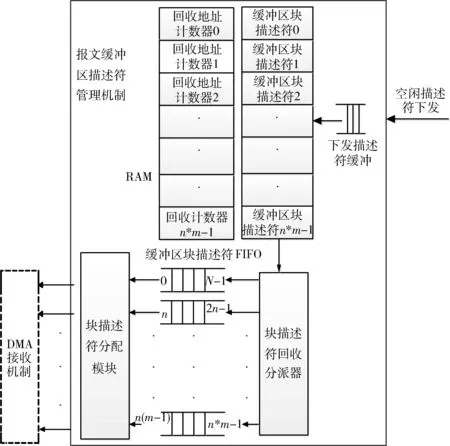
图1 报文缓冲区描述符管理机制结构示意图
描述符初始化流程:系统驱动给每个内核缓冲区块描述符FIFO分配描述符块地址。每个内核缓冲区分配n个块地址,内核缓冲区的个数等于CPU提供的线程数m。并给释放计数器RAM和缓冲区块描述符RAM中的值都赋0。
描述符回收流程:当空闲描述符下发时,取块索引号,读缓冲区块地址RAM和回收地址计数RAM,当回收地址计数RAM的值为块地址可存放地址数量的最大值时,回收该块地址并将计数表的值赋0,否则将计数表的值加1。
描述符分配流程:为m个内核缓冲区实例化m个块描述符分配模块。在每个块描述符分配模块中,当分配地址偏移计数器的值为k时,从缓冲区块描述符FIFO中重新取一个块地址送至块描述符分配模块。否则将当前地址寄存器中的地址加1后发送至分配地址缓冲区。m个块描述符分配模块可以同时分配地址。
2.1.2 DMA接收机制
接收到下行部件报文时,如图2所示,根据报文头部线程号信息获取地址,如线程号为1,则从1号当前描述符SRAM中取出当前地址,并从1号待分配报文描述符FIFO中取出下一跳地址。将接收的报文与描述符(包括当前地址、下一跳地址)合并,传送至共享缓冲区。传输完成时会保留该线程尾的下一跳地址。下一个报文到达时,将下一跳地址更新为当前地址,通过下一跳地址轮询处理下一个报文。
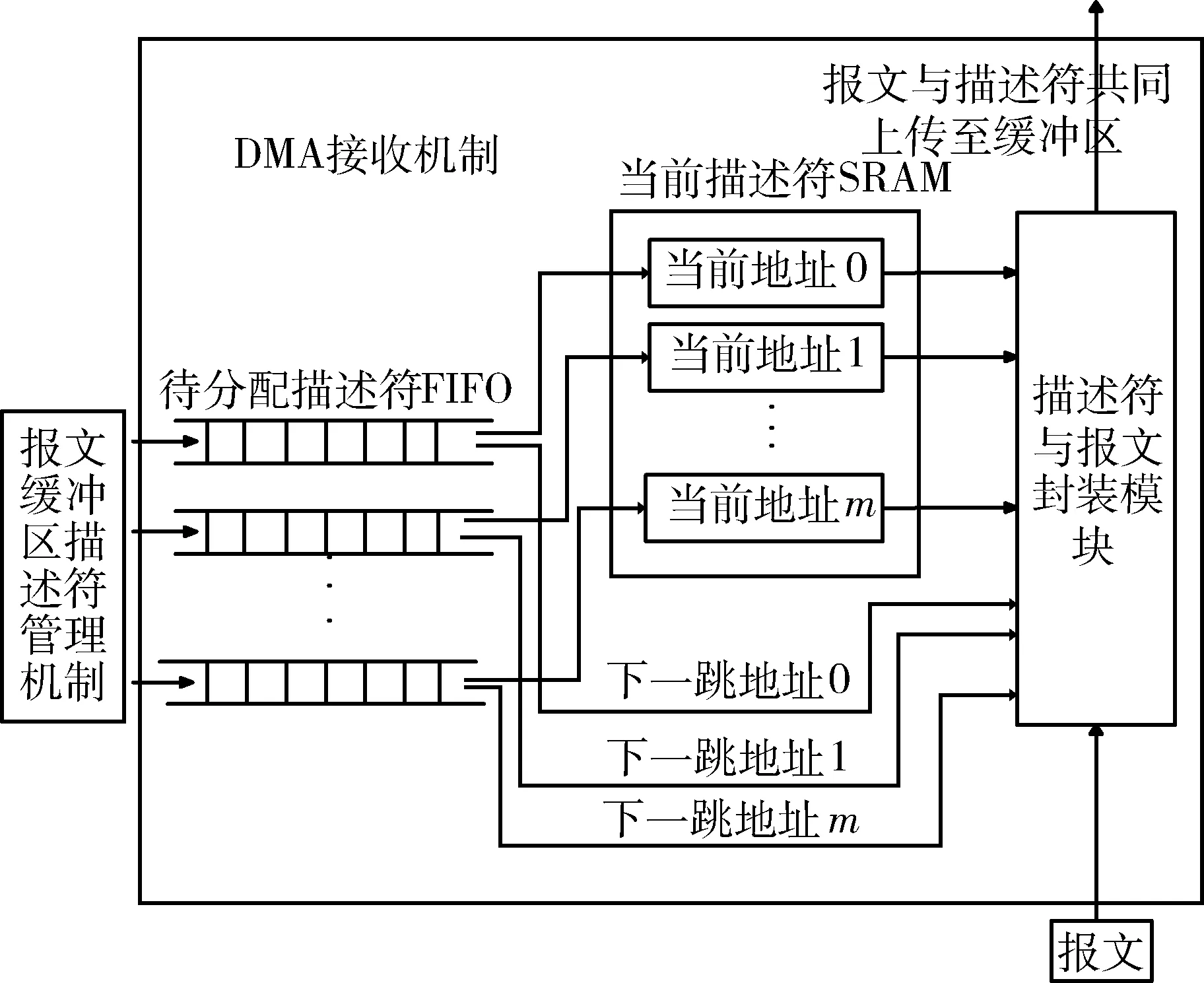
图2 DMA接收机制结构示意图
2.2 分组I/O接收端流亲和技术数据通路流程伪代码
(1)初始化
begin
系统驱动将描述符信息写入m个块描述符队列中,将块地址索引号写到描述符RAM中,回收地址计数器都置0;
end
(2)从端接收报文到主机流程
begin
if (收到下行部件报文&&待分配报文描述符FIFO不为空)
begin
取出当前地址RAM中的地址作为当前地址,取出待分配描述符FIFO中的地址作为下一跳地址,封装后上传;
end
else return;
end
(3)描述符回收流程
begin
if (有空闲描述符下发)
begin
回收块地址的计数器置0;
清除对应描述符RAM中的地址;
end
else begin
回收块地址计数器累加;
end
end
3 分组I/O发送端链式发送技术
在实现操作系统指定的任意存储区域报文链式发送中,链式发送指的是一次DMA读,读出一块描述符,不再是每次DMA读,读出一个描述符。这样可以减少多次DMA读的开销,提高发送效率。

图3 分组I/O发送端数据通路加速结构图
3.1 分组I/O链式发送技术数据通路加速模型
本文提出的每次DMA读,读出一块描述符,读出的描述符可能大于四拍。这种情况下无法和TCP/IP数据报文区分。本文采取的方法是每次发送DMA读请求时,写一个标识存入FIFO,在读出数据时,同时读出该FIFO的值,区分是描述块还是TCP/IP报文,实现链式发送。
链式发送的实现步骤如下:(1)系统驱动将携带21位或者28位DMA地址的描述符,以PCIE写寄存器的方式写入FPGA内部逻辑。其中,携带21位地址的描述符用于流亲和机制中回收基地址,携带28位地址的描述符用于构造DMA读请求,每次DMA读请求,读出多个携带64位地址的描述符。(2)构造21位、28位、64位DMA地址TLP报文读请求,每构造一次DMA读请求往FIFO中写一次标识。(3)解析、定序PCIE核下发的TLP报文。(4)读取标识FIFO,区分描述符和数据报文。数据报文直接下发至网络接口,描述符则将其缓存,再构造TLP报文内存读请求。分组I/O链式发送技术数据通路加速模型如图3所示。以下将介绍链式发送的四个机制。3.1.1 PCIE接收机制
PCIE接收机制为PCIE 应用层I/O部分,将送往系统驱动的数据解析并转换成相应格式的TLP报文,构造TLP报文读请求。
3.1.2 PCIE发送机制
PCIE发送机制为PCIE 应用层I/O部分,将从内存读出的数据解析并转换成规定格式的报文。
3.1.3 DMA转发机制
接收PCIE发送机制报文,根据控制位(Ctrl)判断是描述符还是普通报文。普通报文直接转发给下行模块,描述符则转发给描述符管理机制进行处理。
3.1.4 DMA描述符管理机制
按照信仰观念和仪式这两个层面来研究各地的庙会或者叫地方保护神的祭祀民俗,先将它们分开来进行描述,然后再合并为一个事象给予议论,这种做法在以往的博硕士学位论文里经常出现。比如我们研究泰山庙会信仰时,我们可能会先写关于泰山奶奶是怎么回事儿,与古老的西王母有没有什么关系,与碧霞元君等其他女神有什么关系,等等。这种考证性研究可能存在着问题,因为对于一般老百姓来说,他们可能并不关心这些神祇之间有没有关系,他们关心的是我今天来求神,神祇对我来说到底灵验不灵验。
描述符管理机制为链表回收部分,系统驱动以写寄存器的方式,写描述符至DMA描述符管理机制。回收21位DMA地址,其他描述符形成特定格式,转发至PCIE接收机制进行处理。
3.2 分组I/O链式发送数据通路流程伪代码
begin
if(报文发送描述符缓冲不为空)
begin
将描述符控制块的28位地址、长度以及控制信息(共128位),以写寄存器的方式写入发送引擎中,不回收该描述符;
end
if(根据控制信息判断发送描述符对应报文为普通报文)
begin
end
else begin
计数器累加并判断;
构造21位或者28位DMA读请求;
end
if(Completion报文返回)
begin
判别为普通数据,则转发至网络接口;
end
else
begin
构造成64位DMA读请求;
end
else return;
end
4 性能评估
为有效验证基于端系统应用的分组I/O加速技术的性能,实验原型基于国产的高性能通用64位CPU与可编程FPGA实现,分组I/O加速的核心部件在FPGA器件上实现,FPGA型号采用Stratix IV EP4SGX230KF40C2。Ixia网络测试仪连续发送大小为64 B的报文。由一个万兆端口接收和发送报文,端系统配置为单线程、双线程、四线程、八线程四种模式。测试结果如图4所示,可以看出支持流亲和和链式发送后,64 B报文吞吐率有明显的提升,性能最高提升2.14倍。
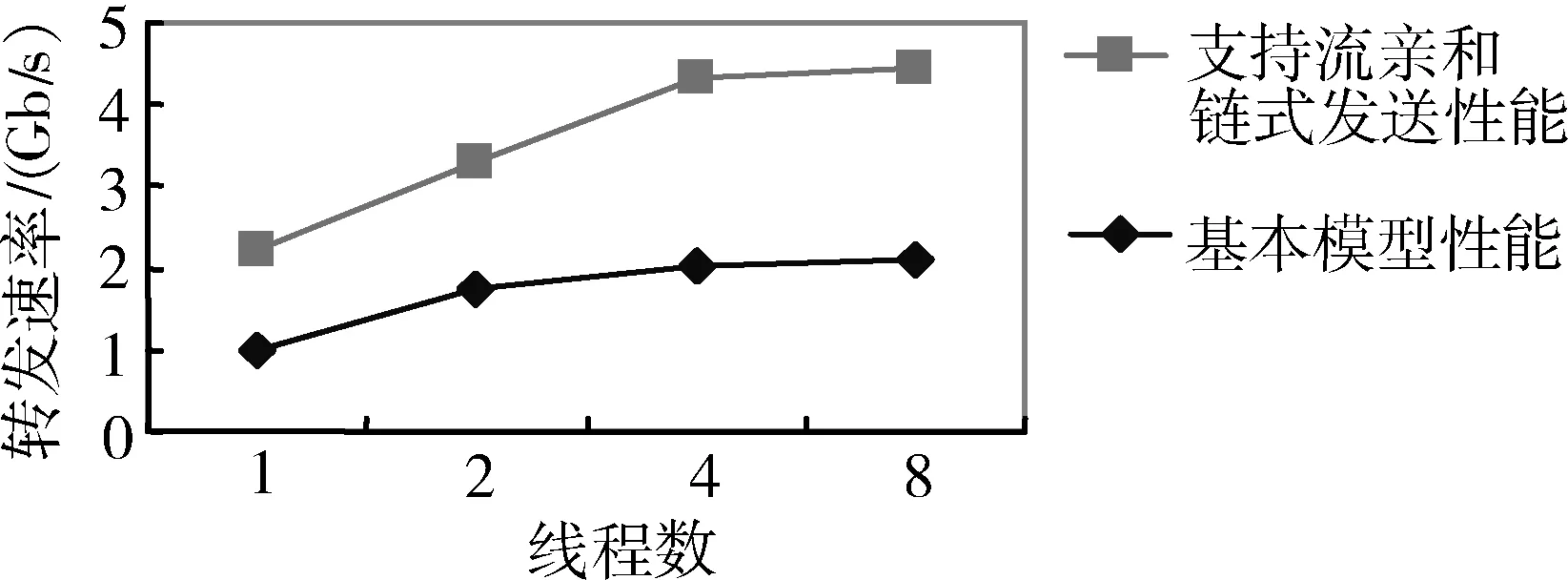
图4 性能加速比对图
5 结束语
为了优化端系统数据路径,使得数据在网络接口和应用程序之间快速移动,降低分组I/O开销,本文基于多核处理器和FPGA平台实现端系统,提出了分组I/O接收端流亲和与发送端链式发送两种技术。实验结果显示,经由
分组I/O加速后,端系统对于报文吞吐率有明显的提升,性能最高提升2.14倍。
[1] HAN S, JANG K, PARK K S, et al. PacketShader: a GPU-accelerated software router[C]. ACM SIGCOMM Computer Communication Review,2010:195-206.
[2] Intel. High-performance multi-core networking software design options[R/OL]. [2016-01-06]www.intel.com.
[3] GARC′LA-DORADO J L, MATA F, RAMOS J, et al. High-performance network traffic processing systems using commodity hardware[C]. Data Traffic Monitoring and Analysis, LNCS 7754, 2013: 3-27.
[4] RIZZO L. Netmap: a novel framework for fast packet I/O[C]. In 2012 USENIX Annual Technical Conference, 2012: 2-12.
[5] RIZZO L, Deri L, CARDIGLIANO A. 10 Gbit/s line rate packet processing using commodity hardware: survey and new proposals[EB/OL].[2016-01-06] http://luca.ntop.org/10g.pdf.
[6] BONELLI N, PIETRO A D, GIORDANOS S, et al. On multi-gigabit packet capturing with multi-core commodity hardware[C]. N. Taft and F. Ricciato (Eds.), PAM 2012, LNCS 7192, 2012: 64-73.
Packet I/O acceleration technology based on terminal system application
Li Shixing1,Yang Hui2,Long Yongxing1,Liu Sanmao1
(1.School of Computer and Communication, Hunan University of Technology, Zhuzhou 412000, China;2.School of Computer, National University of Defense Technology, Changsha,410073, China)
In network system, studying on acceleration technology based on packet I/O for terminal system application, optimizing the transfer data paths of packet I/O, will improve the data transfer rate between network interface and program space of user application, reduce the CPU stall and realize high efficient parallel processing. In this paper, we use streaming affinity technology for the packet I/O receiver, and use the chain transmission technology in the packet I/O sender. We develop a common platform with multicore processor and FPGA for terminal system, and make some experiments on sending and receiving packet performance with packet I/O acceleration technology. The experimental results show that the proposed scheme can achieve to 2.14x packet throughput.
terminal system; multicore; data path; FPGA
国家自然科学基金(61170102)
TP393.0
A
1674-7720(2016)07- 0063- 04
李世星,杨惠,龙永新,等. 基于端系统应用的分组I/O加速技术[J].微型机与应用,2016,35(7):63-66.
2016-01-06)
李世星(1990-),男,硕士研究生,主要研究方向:高性能网络体系和高性能网络设备研制。
杨惠(1987-),女,博士,助理研究员,主要研究方向:高性能网络体系和高性能网络设备研制。
龙永新(1966-),男,副研究员,主要研究方向:信号处理。
