随机森林在医院感染预测中的探讨
2016-12-23王健祖晓玲王常武李立平
王健,祖晓玲,王常武,李立平
1秦皇岛市第一医院;2燕山大学信息科学与工程学院
随机森林在医院感染预测中的探讨
王健1,祖晓玲2,王常武2,李立平1
1秦皇岛市第一医院;2燕山大学信息科学与工程学院
目前,医院感染已经成为医疗行业最突出的焦点问题。由于医院感染相当不容易控制,一旦发生,将会对患者的预后和转归造成较大的影响,不仅会加重患者的经济负担,还会给社会带来巨大的经济损失,严重时甚至会导致患者残疾或死亡。--《某大型综合医院医院感染预警预测——以血液病患者为例》针对医院感染的监测,国内相关软件公司推出了医院感染预警系统,通过对患者的医嘱信息、检查检验结果、电子病历等相关数据的抓取,结合预先设置的规则,对存在医院感染风险的患者预警。但是,预警系统只是对医院目前感染情况的反映,且准确性与预先设置的规则紧密相关。本文应用随机森林算法,通过对算法的训练,达到了对医院感染的预测目的,让医院感染科工作人员变治疗为预防性干预,避免或减少潜在感染的发生,减少患者痛苦,减轻患者费用负担,具有较大的社会效益和经济效益。
医院感染;预测;随机森林
注:本文系秦皇岛科技支撑课题课题编号201401A088。
1 研究目的
对于每棵树而言,对其所使用的训练集都需要从总的训练集中放回采样出来的。这就表示,总的训练集中的有些样本会不至一次地出现在一棵树的训练集中,可能多次出现,也可能从未出现过。在训练每棵树的节点时,其所使用的特征将会从所有特征中按照一定比例随机实行无规律、无放回地抽取的,假设总的特征数量为M,这个比例可以是sqrt(M),1/2sqrt(M),2sqrt(M)。
通过医院医疗过程中产生的数据,对随机森林算法进行不断的训练,找到一个适用于预测医院感染的模型,提高了医院对感染的控制能力,减轻患者治疗痛苦和经济压力。
2 研究方法
随机森林是一种集成机器学习方法,它首先需要利用节点随机分裂技术以及随机重采样技术,来建构出多棵决策树,然后再通过投票的方式得到最终分类结果。其中RF还具有分析复杂相互作用分类特征的能力,所以其对于噪声数据和存在缺失值的数据都具有相当好的鲁棒性。同时,其还具有较快的学习速度,它的变量重要性度量被视为是高维数据的特征选择工具。随着科技的不断发展,其目前已经被广泛应用于各种分类、特征选择、预测以及异常点检测问题之中[2,3,4,5],并取得了一定的成果。
2.1 随机森林的数学定义
定义1随机森林[3]可以看成是由一组决策树分类器,如:{h( X,θk),k=1,2,…,K}所组成的集成分类器。在这组决策树分类器中,{θk}用来表示服从独立同分布的随机向量,K则用来表示随机森林中决策树的个数,X代表给定的自变量,每个决策树分类器将通过投票的方式来获得最优的分类结果。
随机森林的生成过程:
1)首先,采取bootstrap方法从原始训练数据集中有放回地随机抽取K个新的自助样本集,然后再根据这些自助样本集构建K棵分类回归树,同时还会将每次未被抽到的样本组合在一起,形成K个袋外数据(Out-of-bag,OOB);
2)如果设定其有n个特征,就需要在每一棵树的每个节点处随机抽取m try个特征,同时要满足m try≤n,然后开始计算每个特征蕴含的信息量,在其中选择一个最具有分类能力特征的进行节点分裂;
3)要保证每棵树最大限度地生长,不做对其做任何剪裁;
4)需要将所生成的多棵树组成随机森林,然后再利用随机森林对新的数据进行分类,最后按树分类器的投票多少来确定分类结果。
定义2边缘函数(Margin Function)
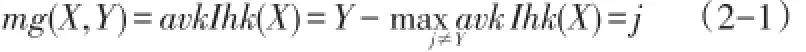
其主要用来表示平均正确分类数所超过平均错误分类数的程度,它们之间的余量值越大,则最终的分类预测越可靠。
2.2 随机森林的性能指标
随机森林分类性能受内外两方面因素影响,从外部因素看,主要来自训练样本的情况,包括训练样本的正负类样本分布,即训练样本的平衡;训练样本的规模,即样本的大小、样本的变量个数及变量的类型。从内部因素看,主要包括单棵树的分类强度和树之间的相关度。衡量随机森林性能的主要指标有2种,一是分类效果指标,二是泛化误差。
2.2.1 分类效果指标
定义5随机森林算法的分类准确率

式中∶TP所代表的是正确分类的正类;TN所代表的是负类的样本数量;
FN所代表的是错误分类的正类;FP所代表的是负类的样本数量。
2.2.2 泛化误差
这是一个反应泛化能力的指标,当泛化误差越小时,代表其学习性能越好,反之则代表其学习性能性能越差。在随机森林算法中,使用OOB估计泛化误差[1]。
2.3 算法描述
本文所采用的是由Mahout提供的随机森林法,通过采用随机森林算法可以对未知变量进行分类,同时还可以计算分类正确率。具体过程如算法1所示。
算法1随机森林算法RF
训练阶段:
输入:训练数据集D,决策树个数N,选择特征值属性个数M,特征属性集S。
输出:N棵决策树,即随机森林R。
步骤∶
1.初始化
1.1 读入训练数据集D,决策树个数N,选择特征值属性个数M,特征属性集S。
输出结果,迭代执行,直至所有的决策树构建完毕。
测试阶段:
输入:未分类数据集x,随机森林R。
输出:x的标签Y。
步骤∶
1.初始化
1.1 读入未分类数据集x,随机森林R
2.For each decision tree Ti
2.1 Ti为x进行分类,得到标签Yi
2.2 End For
输出结果
计算频数最大的Yi,并输出
3 实验与分析
本文搜集数据共30500条,其中5000例为院内感染,25500例为非感染。本次实验的硬件配置为Intel Core2.33GHz的CPU,4GB内存,500G硬盘的PC机。
4结论
1.本文采用了随机森林算法预测医院院内感染现状,并进行了实验,得到了较好的预测结果。
2.该方法具有很好地普适性、扩展性,能很好地容忍噪声、不易过拟合、需调节参数较少等优点。
3.实验结果表明,随机森林对医院院内感染能够进行有效的分类识别,它可以为医生辅助决策提供有力的基础保障。
[1]Breiman L.Random forests[J].Machine Learning,2001,45(1)∶5-32.
[2]Strobl Carolin,Boulesteix Anne-Laure,Kneib Thomas,et al. Conditional variable importance for random forests[J].BMC Bioinfor⁃matics,2008,9(1)∶1-11.
[3]Reif David M,Motsinger Alison A,McKinney Brett A,et al. Feature selection using a rand om forests classifier for the integrated analysis of multiple data types[C],IEEE Symposium on Computational Intelligence and Bioinformatics and Computational Biology,2006∶171-178.
王健,秦皇岛市第一医院,信息管理处工程师,硕士研究生学历,主要从事医院软件项目管理、质量控制,信息标准化研究等。
祖晓玲,燕山大学信息科学与工程学院,硕士研究生;
王常武,燕山大学信息科学与工程学院,教授;
李立平,秦皇岛市第一医院,信息管理处助理工程师。
