基于分组的多级随机数RFID标签并行识别算法
2016-12-14段力畑王子中
段力畑,王子中,2,段 富
(1.太原理工大学 a.信息工程学院,b.计算机科学与技术学院,太原030024;2.弗吉尼亚卫斯理学院,Norfolk,USA)
基于分组的多级随机数RFID标签并行识别算法
段力畑1a,王子中1a,2,段 富1b
(1.太原理工大学 a.信息工程学院,b.计算机科学与技术学院,太原030024;2.弗吉尼亚卫斯理学院,Norfolk,USA)
为了提高大规模RFID系统中的被动标签识别率,在分析已有基于帧时隙ALOHA标签识别算法的基础上,结合分组算法和多级随机数算法的思想,将多级随机数分别部署在不同组的标签中,使用动态帧时隙ALOHA算法框架,提出基于分组的多级随机数并行识别算法框架,推导出多级随机数适时选择机制的计算公式。针对并行识别过程中的负载不均衡问题,提出了3种负载均衡策略及其形式化描述,设计了与之相应的3种算法并进行了性能分析和仿真。结果表明,所提算法可以有效地将部分非成功时隙转化为成功时隙,提高了标签识别率、标签识别速度和时隙利用率:平均识别率均在70%以上,最高可达76.77%;标签识别速度较单随机数的算法提高了66%;时隙利用率达51.02%,约为单随机数算法的2倍。所提算法具有并行、高效、轻量等特点,适用于大规模被动式RFID系统的应用场合。
大规模RFID系统;动态帧时隙ALOHA;被动式标签;多级随机数;并行识别
无线射频识别技术(Radio Frequency Identification, RFID)是一种非接触式自动识别技术,它能够利用射频信号进行空间耦合而实现信息交互[1],识别过程也无需人工干预,因此在供应链管理、仓库管理和访问控制等领域应用广泛,出现了相应的大规模RFID应用系统。该系统主要由大量的标签、多阅读器和系统服务(如数据库)组成,阅读器与标签之间使用EPC global Class-1 Gen-2协议[2],并通过基于帧时隙ALOHA的算法(FSA)识别被动式标签。针对FSA中帧长度固定的问题,研究人员又提出了根据估算当前未读标签数而动态确定帧长的动态帧时隙ALOHA(DFSA)及其改进算法。估算的方法除了比较经典的最小值方法[3]、泊松分布方法[4]、碰撞因子方法[5]外,也出现了适用于标签量较大的采样和复合估算方法:文献[6]提出的基于采样的线性标签数估算方法,通过i个时隙的估算值等比地计算出实际未读标签数;文献[7]提出了时隙结果采样统计的分情况标签数估算方法,通过采样结果中空闲、碰撞和成功时隙之间关系的不同而采用不同的估算方法;文献[8]提出的一种时隙数选择方法能够基于碰撞时隙的个数动态调整当前帧长;文献[9]中总结并列出不同帧长时理想的标签数范围,通过查表的方式动态调整当前帧长;文献[10-11]以354作为标签数分组的门限值并对应帧长256。上述所有算法的识别率均未突破FSA类算法识别率36.8%的瓶颈。
为了进一步提高标签的识别率,研究者提出基于多级随机数的算法。该类算法充分利用了非成功时隙,使识别效率达到45%以上。文献[12]中标签生成两个随机数并划分优先级,将部分空闲时隙转化为成功时隙而将识别效率提高到45.3%。文献[13]中,提出了多级随机数选择的数学模型,计算出第i级的识别率Si,通过将3级随机数部署在单个标签上,将部分空闲和碰撞时隙转化为成功时隙,识别率达到69.35%。然而该算法未充分考虑被动式标签有限的存储和计算能力以及阅读器较强的计算能力。
随着RFID技术的进步和应用系统规模的扩展,需要研究一种适合于大规模被动式RFID系统使用的轻量、并行、高效识别算法。为此,笔者结合基于分组和多级随机数标签识别算法的设计思想,将多级随机数分别部署在不同组的标签中,以动态帧时隙ALOHA(DFSA)算法框架为基础,提出了基于分组的多级随机数并行识别算法。针对算法中负载不均衡的问题,实现了3种采用不同负载均衡策略的模式,并对其性能进行了理论分析和仿真实验,验证了该算法的有效性。
1 算法设计
为了满足大规模RFID系统中高效识别被动式标签的需求,本文结合分组和多级随机数的思想,在大量标签分组的基础上,将多级随机数依次部署在不同的标签组上,设计了一种在DFSA框架内按多级随机数适时选择机制一次处理多个标签组的并行算法,由于轮询次序影响了标签组的识别率,使对应的标签组内未识别标签数不尽相同,出现了并行算法的负载不均衡问题。因此,还需要解决标签组的负载不均衡问题。
本算法由标签数估计与分组、识别过程和负载均衡3部分组成,算法流程如图1所示。图中,T表示所有标签的集合,G表示所有组的集合,P表示所有并行组的集合。
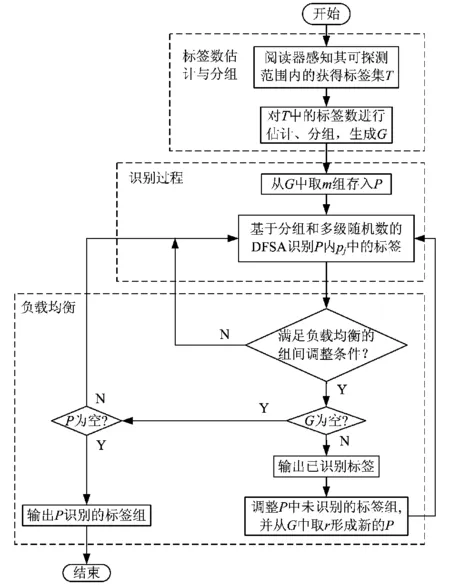
图1 基于分组的多级随机数并行识别算法框架Fig.1 The frame of Parallel Identification Algorithm for RFID tags with Group-based Multiple-random Numbers
由于阅读器在一个帧时隙内按多级随机数的级次对相应的标签组进行轮询,直到有一个标签被成功识别或轮询完所有相应的标签组。那么,对第i级随机数的轮询,是在前i-1个随机数的轮询没有成功识别标签的条件下发生的,其成功识别一个标签的概率。第i级随机数的识别率Si可用条件概率计算,由此推出计算Si公式(1);相应的总识别率S可通过公式(2)计算。由公式(1),公式(2)计算5级随机数的Si及相应级别的总识别率S,结果如图2所示。
(1)
S=∑Si,1≤i≤m (m为随机数的级数) .
(2)
由图2可知,从5级开始Si小于1%,并且S的增长逐渐放缓并趋于平稳;考虑到DFSA框架的帧长是以2的整数次幂,所以算法取随机数的级数m=4 .
1.1 分组与初始化
在阅读器感知到其覆盖范围内的标签集合定义为T,使用文献[7]中的算法估算出标签数量nt并分为大小相等的ng组,得到分组标签集合G={gi|i∈[1, ng]},其中|gi|=⎣nt/ng」+1, ng为m的整数倍;从G取出前m个放入P={pj| j∈[1, m]};初始化P内各组内已读标签的数目集合为S={sj| j∈[1, m]}=ø,未读标签的数目集合为U={uj| j∈[1, m]}=|P| .
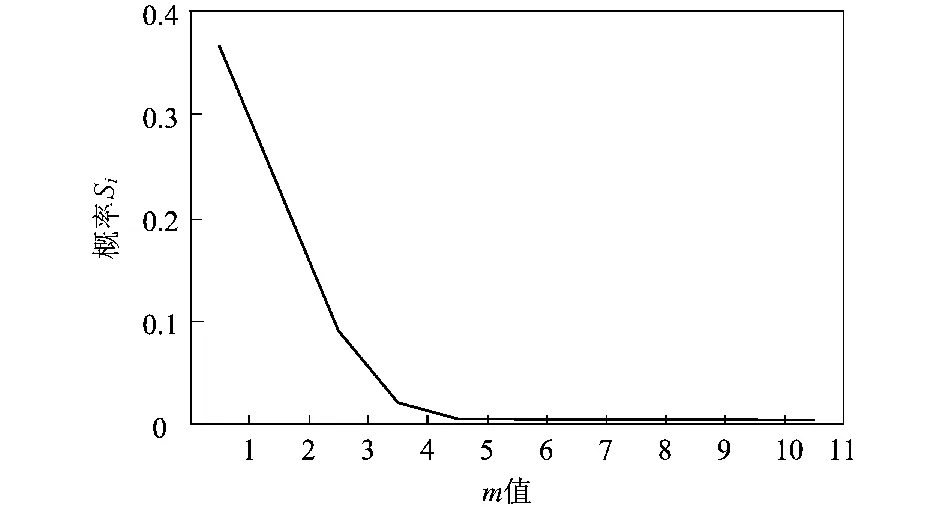
图2 级数m对应的识别率SiFig.2 The Si for different m-values
1.2 识别过程
通过分组和初始化过程,按照DFSA的框架以P为负载开始一个识别过程,阅读器确定合适的帧长按时隙对标签组进行轮询。首先轮询p1中的标签,如果在当前时隙内没有标签成功响应则轮询p2内的标签并以此类推至p4,直至有一个标签成功响应或者轮询完所有标签组,开始下一个时隙轮询;当一帧结束后,估计P内当前未读标签数后动态确定最优帧长开始下一次盘存周期至P中所有标签识别完毕。在识别过程中,由于每个时隙中按照固定顺序轮询而造成P中每组未读标签数不尽相同,所以当满足一定条件时需要进行组间负载的调整,开始新一轮的识别过程。识别过程流程图如图3所示。
1.3 负载均衡
在识别的过程中,由于轮询的次序对标签组的识别率有影响,在m=4级随机数中各级的识别率依次为36.8%,23.26%,9.29%和2.35%,这使对应的U(j)不尽相同,出现了并行算法的负载不均衡问题。针对P中成功识别1组标签、2组标签和4组标签的情况,提出了3种基于组粒度的负载均衡调整策略。
定义1P中负载均衡
若并行集中标签组的个数等于4,即P={pj|j∈[1,4]},且第j个标签组的未读标签数U(j)与当前Q所对应的标签数上界L(Q)、下界R(Q)之间满足关系:L(Q)≤U(j)≤R(Q),其中Q∈[2,8],j∈[1,4]。那么,P被认为在当前Q下是负载均衡的。
Q值所对应的标签数上界L(Q)、下界R(Q)参考自文献[14],列于表1。
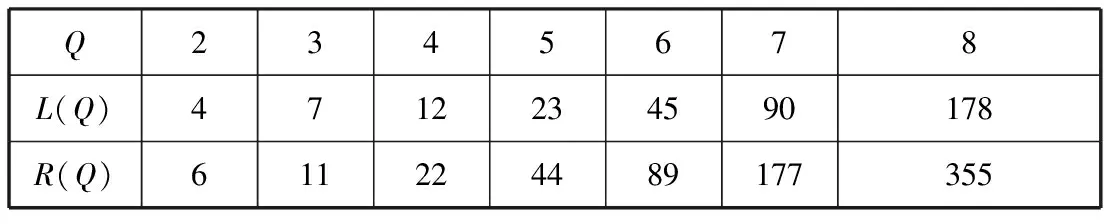
表1 Q值对应标签上、下界
策略1(PMould 1) 若s1和s2之和大于一个组所包含的数量时,则输出p1和p2中已识别的标签(约1组),并将p1中未识别的标签合并至p2,然后从G={gi|i∈[1,ng]}中取出新的1组补充到P中作为p1,将更新后的P作为并行算法的负载,开始下一轮识别过程。算法如下:

PMould1intk=1,n;∥n为组内标签数输入:G={gi|i∈[1,ng]}intm=4;for(j=1;j<=m;j++)pj=gk;k++;输出:P={pj|j∈[1,4]}输入:P={pj|j∈[1,4]}for(j=1;j<=4;j++)if(阅读器成功识别pj一个标签)S(j)++;if(S(1)+S(2)>n)p1=gk;输出:P={pj|j∈[1,4]}
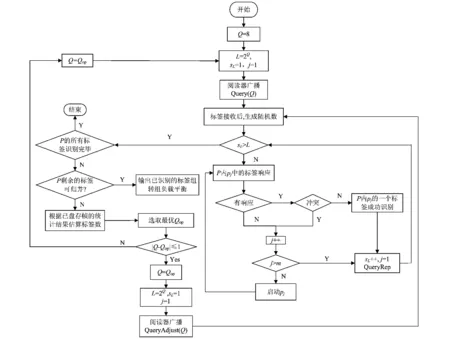
图3 基于分组的多级随机数DFSA识别流程Fig.3 The flowchart for proposed algorithm
策略2( PMould2 ) 当|S|大于两个组所包含的数量时,输出P已识别的标签(约2组),将p1中未识别的标签合并至p4,将p2中未识别的标签合并至p3,然后从G={gi|i∈[1,ng]}中取出新的2组补充到P中作为新p1和p2,将更新后的P作为并行算法的负载,开始下一轮识别。算法如下:

PMould2intk=1,n;∥n为组内标签数输入:G={gi|i∈[1,ng]}intm=4;for(j=1;j<=m;j++)pj=gk;k++;输出:P={pj|j∈[1,4]}输入:P={pj|j∈[1,4]}for(j=1;j<=4;j++)if(阅读器成功识别pj一个标签)S(j)++;if(S(1)+S(4)>n&&S(2)+S(3)>n)pj=gk;k++;pj=gk;k++;输出:P={pj|j∈[1,4]}
策略3(PMould 3) 在阅读器轮询完每一帧之后,按照S(j),j∈[1, 4]的大小降序排序,并按更新后的次序开始下一帧的轮询,直至|U|=ø或帧长L≤8(Q≤3)为止。输出P已识别的标签(约4组),并从G取4组分别与P内各组剩余的未识别标签合并,更新后的P作为并行算法的负载,开始下一轮识别。算法如下:

PMould3intk=1,n;∥n为组内标签数输入:G={gi|i∈[1,ng]}intm=4;for(j=1;j<=m;j++)pj=gk;k++;输出:P={pj|j∈[1,4]}输入:P={pj|j∈[1,4]}for(j=1;j<=4;j++)if(阅读器成功识别pj一个标签)S(j)++;SortingpjbyS(j)descendingorderinanewarrayA[];for(j=1;j<=4;j++)pj=A[5-j];输出:P={pj|j∈[1,4]}
1.4 算法性能分析
本节从标签识别率、时隙碰撞率、时隙利用率等指标对所提算法进行算法性能分析,结果如表2所示。由于多级随机数的识别率服从条件概率的计算条件,因此标签识别率S可通过公式(2)计算,相应的可计算出时隙碰撞率。识别标签所需平均时隙(Aslot)可通过公式(3)计算,标签响应的平均时隙数(Tslot)由公式(4)计算,时隙利用率(Eslot)由公式(5)得出。
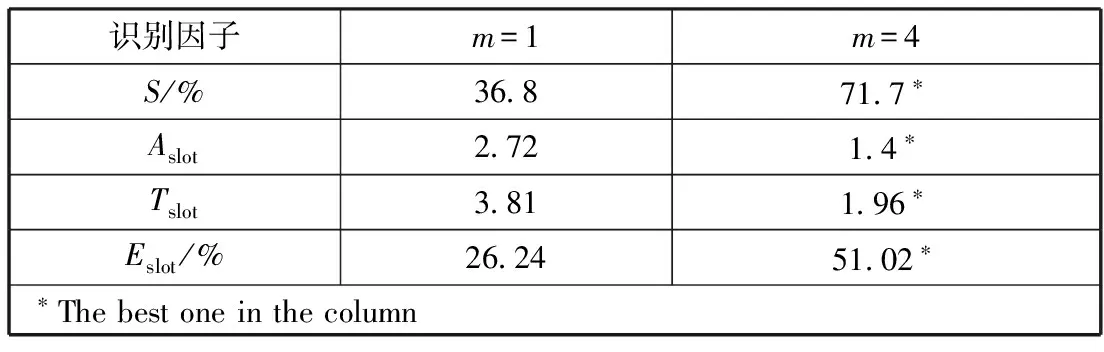
表2 性能分析
通过与单随机数性能比较,利用4级随级数后,标签识别率大幅度提高,识别单个标签所需的平均时隙个数降低,标签的响应率提高,时隙利用率提高约1倍。
(3)
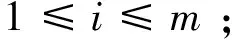
(4)
(5)
2 仿真结果分析和比较
在MATLAB环境中,标签规模从6 000到12 000间隔200,对所提出的算法(PMould1,PMould2,PMould3以及没有负载均衡的算法)进行了仿真,其中分组估计采用和文献[7]中相同的程序。重复仿真5次后取平均值,图4为识别效率的比较曲线,图5为算法在分组数(图5(a))、组合并次数(图5(b))和帧调整次数(图5(c))的比较曲线。
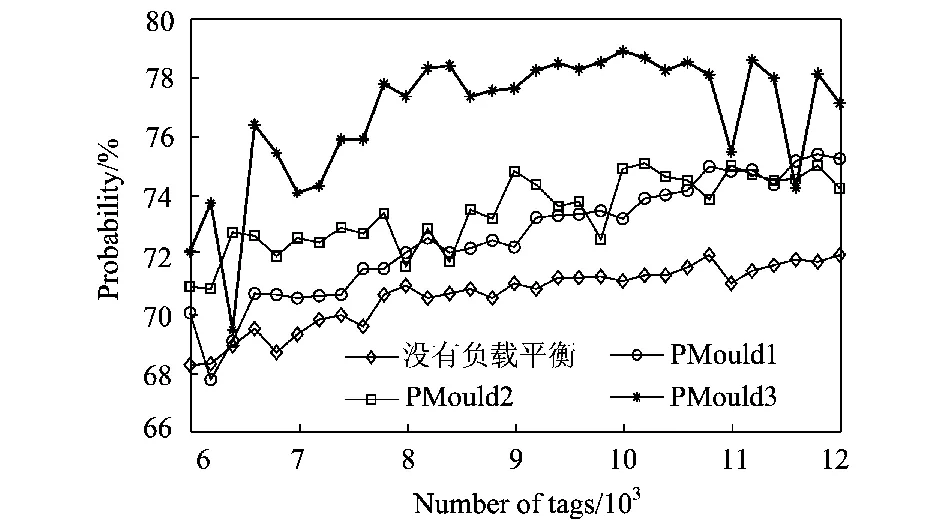
图4 识别效率结果Fig.4 The throughput for identification
从图中可以看出,PMould1,PMould2和PMould3的平均识别效率在72%以上,均高于没有负载均衡的算法(70.6%),PMould3平均效率最高(76.7%)。其中,PMould1和PMould2需要PGT内的组间合并保持其识别效率,而PMould3需要频繁调整Q值保持其识别效率。因此可根据不同的工作环境选择不同的算法。
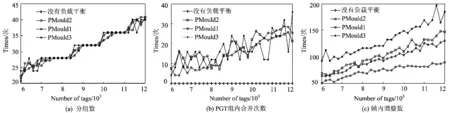
图5 基本算法与负载均衡调整方法Fig.5 The comparison results in (a) Grouping numbers; (b) Merging times; (c) Frame adjusting times
表3列出了在标签总数为273 000的情况下,PMould 1,PMould 2,PMould 3与分组算法[11]和多级随机数算法[13]在识别效率和花费时间上的比较。总体来说,所提出的算法均超过分组识别算法和多级随机数识别算法的识别效率。运行时间上,PMould 3花费的时间最短,相比于分组算法可以节省66%左右,PMolud1和PMould2也有相应提高,分别为22%和14%。
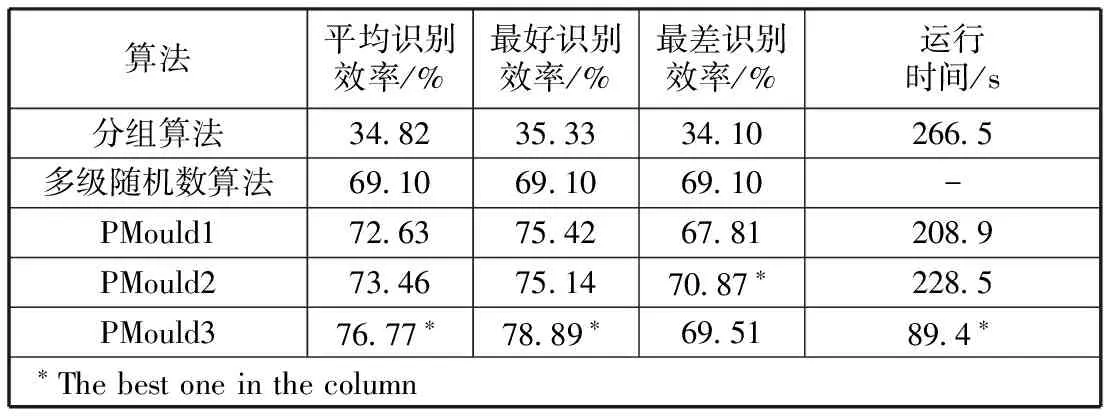
表3 识别效率对比
3 结论
本文以动态帧时隙ALOHA(DFSA)为基础,提出了一种基于分组的多级随机数并行识别算法框架。根据并行识别过程中组间负载不均衡的问题,设计了3种采用不同负载均衡策略的算法,并对其性能进行了理论分析和仿真实验。结果表明,平均识别率在70.65%以上,其中使用负载均衡策略调整的算法平均识别率在72%以上并最高可达到76.77%。本文算法的识别速度均高于分组算法。其中基于次序调整的组粒度负载均衡策略的算法识别率最高,速度最快,适用于大规模被动式RFID系统使用。今后的工作将继续针对更细粒度的识别算法进行研究。
[1] 梁雪萍,马存庆,梁颖升.基于帧时隙ALOHA的RFID标签集合检测协议框架[J].计算机应用研究,2015(3):1-6.
[2] EPC Radio-Frequency Identity Protocols,Class-1 Generation-2 UHF RFID Protocol for Communications at 860 MHz—960 MHz, Version 2.0.0[S].USA:Springer,2013.
[3] VOGT H.Efficient object dentification with passive RFID tags[C]∥IEEE.First International Conference on Pervasive Computing Pervasive 2002,Zurich,Switzerland,2002:26-28.
[4] 颜元,武岳山,熊立志.一种新型多标签估算方法[J].计算机应用研究,2012(3):930-932.
[5] 贺洪江,丁晓叶,翟耀绪.一种基于碰撞因子的RFID标签估算方法[J].计算机应用研究,2011(11):4131-4133.
[6] CHEN W.A feasible and easy-to-implement anticollision algorithm for the EPCglobal UHF class-1 generation-2 RFID protocol[J].IEEE Transactions on Automation Science and Engineering,2014,11(2):485-491.
[7] DUAN Litian,WANG Zizhong,JOHN,et al.An identification algorithm in grouping and paralleling for data-intensive RFID systems[C]∥Springer.First International Conference on Big Data Computing and Communications 2015,Taiyuan,China,2015:1-3.
[8] DANESHMAND M,WANG C,SOHRABY K.A new slot-count selection algorithm for RFID protocol[C]∥IEEE.The Second International Conference on Communications and Networking in China,Shanghai,China,2007:22-24.
[9] MYUNG J,LEE W J, SRIVASTAVA J.Adaptive binary splitting for efficient RFID tag anti-collision[J].IEEE Communications Letters,2006(10):144-146.
[10] LEE S R,JOO S D,LEE C W.An enhanced dynamic framed slotted ALOHA algorithm for RFID tag identification[C]∥IEEE Computer Society. Proceedings of 2nd Annual International Conference on Mobile and Ubiquitous Systems:Networking and Services,Washington D C,USA,2005:166-174.
[11] WANG Hui,XIAO Shengliang.Group improved enhanced dynamicframe slotted ALOHA anti-collision algorithm[J].The Journal of Supercomputer,2014,69(3):1235-1253.
[12] 史长琼,肖瑞强,吴丹.改进的动态帧时隙ALOHA防碰撞算法[J].计算机工程与设计,2014,35(6):1897-1900,1910.
[13] 杜永兴,白文浩,李宝山.RFID系统动态帧时隙ALOHA算法的改进[J].高技术通讯,2015,25(3):313-318.
[14] DUAN Litian,PANG Wenwen,Duan Fu.An enhanced posterior probability anti-collision algorithm based on dynamic frame slotted ALOHA for EPCglobal Class1 Gen2[J].Journal of Communications,2013,9(10):798-804.
(编辑:贾丽红)
A Parallel Identification Algorithm for RFID tags with Group-based Multiple-random Numbers
DUAN Litian1a,WANG Zizhong1a,2,DUAN Fu1b
(1a.College of Information Engineering,b.College of Computer Science and Technology,TaiyuanUniversityofTechnology,Taiyuan030024;2.VirginiaWesleyanCollege,Norfolk,USA)
To enhance the efficiency for identifying passive tags in large-scale RFID systems, a parallel identification framework based on group algorithms and multiple-random numbers algorithms is proposed, which is implemented by putting multiple-random numbers into different groups,The calculation formula for multiple-random numbers is also provided in this paper. This parallel identification framework is under the dynamic frame slotted ALOHA framework. Additionally, there are three adjustment strategies to keep the load balance during parallel identification process. As a result, the proposed algorithms can efficiently transfer part of collision or empty slots into successful slots to improve the utilization.Simulation results present that the average efficiency of identification is over 70% and maximizes to 76.77%, the identification speed is increased by 66%, and the utilization for slots is 51.02% which is approximate 2 times that of single random number algorithm.The proposed algorithms are suitable for large-scale RFID systems with the characters of parallel, high efficiency and lightweight in computation and storage cost.
large-scale RFID System;dynamic frame slotted ALOHA;passive tags;multiple-random numbers;parallel identification
1007-9432(2016)04-0495-06
2016-03-19
国家自然科学基金资助项目:大型采煤设备异常追踪检测与诊断的免疫智能方法研究 (61472271);国家自然科学青年基金资助项目:层次粒化的不确定多态网络重叠社区发现办法研究 (61503273)
段力畑(1989-),男,太原人,博士生,主要从事RFID识别技术研究,(E-mail)dylann@yeah.net
段富,博导,教授,主要从事物联网、人工智能、计算机网络等的研究,(E-mail)duanfu@tyut.edu.cn
TP301.6
A
10.16355/j.cnki.issn1007-9432tyut.2016.04.012
