An effective estimation of distribution algorithm for parallel litho machine scheduling with reticle constraints①
2016-12-06ZhouBinghai周炳海ZhongZhenyi
Zhou Binghai (周炳海), Zhong Zhenyi
(School of Mechanical Engineering, Tongji University, Shanghai 201804, P.R.China)
An effective estimation of distribution algorithm for parallel litho machine scheduling with reticle constraints①
Zhou Binghai (周炳海)②, Zhong Zhenyi
(School of Mechanical Engineering, Tongji University, Shanghai 201804, P.R.China)
In order to improve the scheduling efficiency of photolithography, bottleneck process of wafer fabrications in the semiconductor industry, an effective estimation of distribution algorithm is proposed for scheduling problems of parallel litho machines with reticle constraints, where multiple reticles are available for each reticle type. First, the scheduling problem domain of parallel litho machines is described with reticle constraints and mathematical programming formulations are put forward with the objective of minimizing total weighted completion time. Second, estimation of distribution algorithm is developed with a decoding scheme specially designed to deal with the reticle constraints. Third, an insert-based local search with the first move strategy is introduced to enhance the local exploitation ability of the algorithm. Finally, simulation experiments and analysis demonstrate the effectiveness of the proposed algorithm.
semiconductor manufacturing, parallel machine scheduling, auxiliary resource constraints, estimation of distribution algorithm
0 Introduction
The manufacturing of integrated circuits (ICs) on silicon wafers is a complex production process. Photolithography is one of the main production process steps in the wafer fabrications. 35% to 45% of work-in-process (WIP) of a wafer fabrication system typically resides in the photolithography area[1]. As the bottleneck process of fabricating complex wafers with the most expensive equipment, the photolithography almost determines the throughput and the cost of semiconductor manufacturing[2].
A mould used to produce chips is called a reticle, which must be on the litho machine for the duration of a wafer lot’s processing. Reticles can be thought of as auxiliary resource constraints in the photolithography process. ICs are built by repeatedly constructing layers with desired properties on the silicon wafer’s surface. Every layer of each product can require its own unique reticle and a set of reticles for a single product can cost well over MYM150 K. In this paper, photolithography scheduling motivates our investigation into parallel litho machine scheduling in the presence of reticle constraints to minimize total weighted completion time, thus improving the scheduling efficiency of photolithography and leading to financial gains.
The scheduling problem of the photolithography area has aroused much attention from home and abroad researchers and has become an issue of concern in our country recently. Ref.[1] investigated scheduling rules to assign WIP to litho machines to maximize production volume. Ref.[3] described several heuristics for litho machine and reticle scheduling based on appropriate modifications of the apparent tardiness cost (ATC) dispatching rule. Ref.[4] proposed two heuristics and a tabu search-based post processing algorithm. Ref.[5] investigated the problem of the load balancing among litho machines and presented a novel model. Ref.[6] solved the photolithography production control problem based on process capability indices. Ref.[7] established a multistage mathematical programming based scheduling approach with the objected goal of maximization of throughput, minimization of setup cost and a balancing of machine utilization. Ref.[8] put forward a time window rolling- and GA-based method for the dynamic dispatching problem in photolithography area. Ref.[9] introduced discrete event simulation (DES) and mathematical programming techniques into semiconductor manufacturing. This DES model allows a detailed problem description. Ref.[10] studied non-identical parallel machines with time constraints in semiconductor manufacturing and developed simple heuristics. Ref.[11] solved a litho machine scheduling formulation by using the branch-and-cut method.
A review of the available literature indicates that there is a dearth of research that explicitly considers auxiliary resource constraints in photolithography. Furthermore, in previous research, the general approach for managing reticles is that the number of reticles available is assumed to be infinite or that the number of reticles available is assumed to be finite while only one unique reticle is available for each type. However, in fact, most of wafer fabs have multiple reticles available for each type of reticle so as to provide creation of more effective production schedules. In this study, each reticle type has multiple reticles available and jobs are investigated with non-zero ready times—both of these characteristics are inherent in semiconductor wafer fabs.
What’s more, some of those methods adopted in photolithography such as discrete event simulation are expensive and time-consuming to develop and run while the solutions of those simple scheduling rules are not so promising. Therefore, this paper seeks to find an effective algorithm aiming at keeping a balance between time and solution quality. As a relatively new population-based optimization algorithm, estimation of distribution algorithm (EDA) has been successfully developed to solve a variety of optimization problems in academic and engineering fields[12-14]. But there has been no research about EDA on auxiliary resource constraints so far. Besides, the general method to deal with constraint violations is that a penalty function is added to the objective function or that infeasible solutions are simply removed. However, in this article, a specially designed decoding scheme is proposed to deal with the reticle constraints to transform infeasible solutions into feasible solutions. In addition, an insert-based local search with the first move strategy is introduced to exploit the neighborhood of the best individuals. Simulation results indicate that the proposed algorithm can lead to satisfactory results.
1 Problem statements
The problem assumptions and notations of parallel litho machines with reticle constraints are given as follows.
The assumptions are given as follows: (1) There are a total of n independent jobs (wafer lots) and m identical litho machines. (2) Jobs can be assigned to each of the m available litho machines. (3) Each litho machine can only process one job at most once. In addition, once a job starts to be processed on a litho machine, it can’t be interrupted until it is finished. (4) Each job has its own processing time, release time and weight. (5) Each job should be processed on a certain layer. (6) One type of reticle can only process one certain layer. (7) The same reticle is not allowed to be used on different litho machines in overlapping time periods. (8) The same reticle is allowed to be used on different litho machines in non-overlapping time periods.
In order to establish a mathematical model, the following notations are given.

J Thesetofjobsorproductionlots;L Thesetofprocessinglayers;δl Thesetofjobswhichrequirelayerl∈Lprocess-ing;nl Numberofreticlesavailableforprocessinglayerl∈L; Jobj∈Jhasthefollowingparameters:pj Theprocessingtimeofjobj∈J;rj Thereleasetimeofjobj∈J;wj Theweight(priority)ofjobj∈J;Cj Thetimeatwhichjobj∈Jfinishesitsrequiredprocessing;m Thetotalnumberoflithomachines; Binaryvariables:xij Ifjobiimmediatelyprecedesjobjonthesamelithomachine,xij=1;otherwise,xij=0.eij Ifjobiimmediatelyprecedesjobjonthesamereticle,eij=1;otherwise,eij=0.∀i∈δl,∀j∈δl,∀l∈L:i≠j Dummyvariable:job0 Ajobwhoseprocessingtime,readytime,andweightaresetequalto0each.Thus,itcanindi-cateboththestartingandfinishingofjobpro-cessingoneachlithomachineandeachreticle.
According to the above assumptions and notations, the following mathematical model is given.
An objective of the scheduling problem is to minimize total weighted completion time (TWCT):
Eqs(1) and (2) indicate that jobs are assigned to each of the m available litho machines:
(1)
(2)
Eqs(3) and (4) indicate litho machine assignment and job sequencing for jobs on the same litho machine:
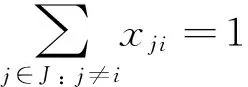
(3)
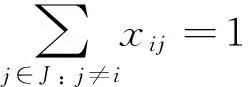
(4)
Eqs(5) and (6) indicate that jobs require layer l∈L processing are assigned to each of the nlavailable reticles:
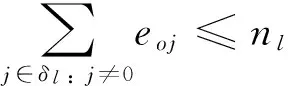
(5)
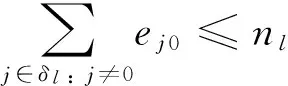
(6)
Eqs(7) and (8) indicate reticle assignment and job sequencing for jobs on the same reticle:
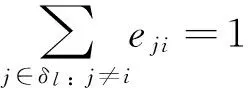
(7)

(8)
Eq.(9) shows how jobi’s completion time Ciis determined:
∀i∈J,∀j∈J: j≠0, i≠j
(9)
(i.e. big M)
Eq.(10) ensures that if two jobs require the same reticle, one of the jobs should complete its processing before the other job starts its processing
∀i∈δl, ∀j∈δl, ∀l∈L: i≠j
(10)
2 Proposed estimation of distribution algorithm
As a relatively new paradigm in the field of evolutionary computation, estimation of distribution algorithm employs explicit probability distributions in optimization[15].
2.1 Encoding schemes
Every individual of the population denotes a solution, which is represented by a sequence of all the job numbers as π={π1,π2,…,πi,…,πn} to determine the schedule order of all the jobs where πi∈J is theith job in π. For example, a solution π={1,2,5,4,3,0} implies that job 1 is scheduled first, and next are job 2, job 5, job 4 and job 3 in sequence. Job 0 is the last job to be scheduled.
2.2 Decoding schemes
To decode a sequence is to arrange the machines for all the jobs and determine the processing order in each machine. In this paper, a schedule is feasible only if the auxiliary resource constraints are not violated.
The following variables and definitions are used for the method.


s: the first machine completes its required workload.
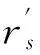
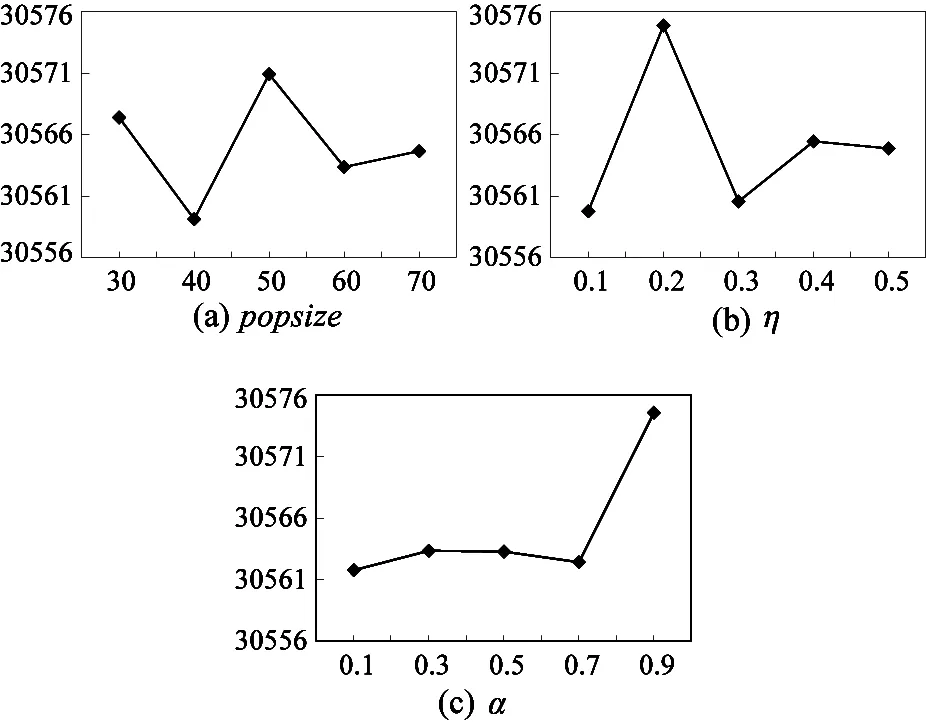
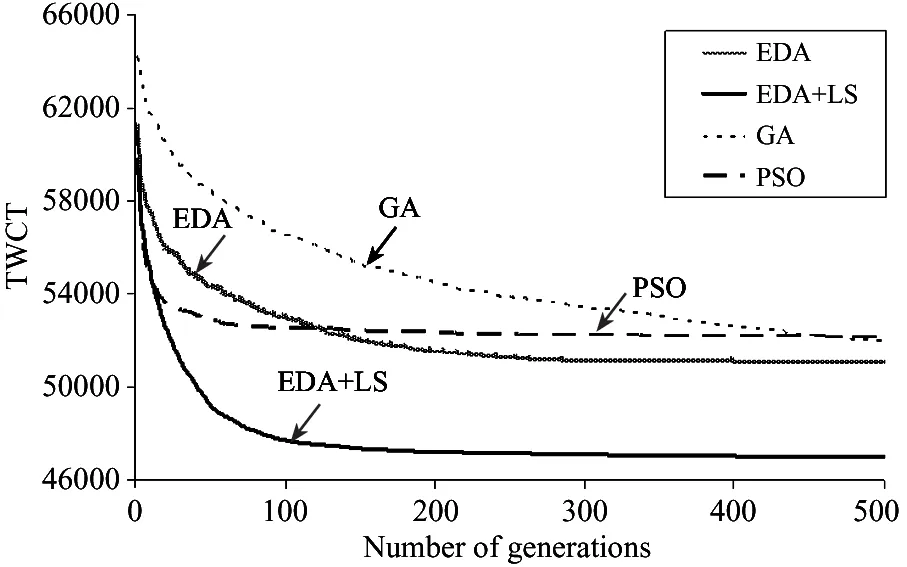
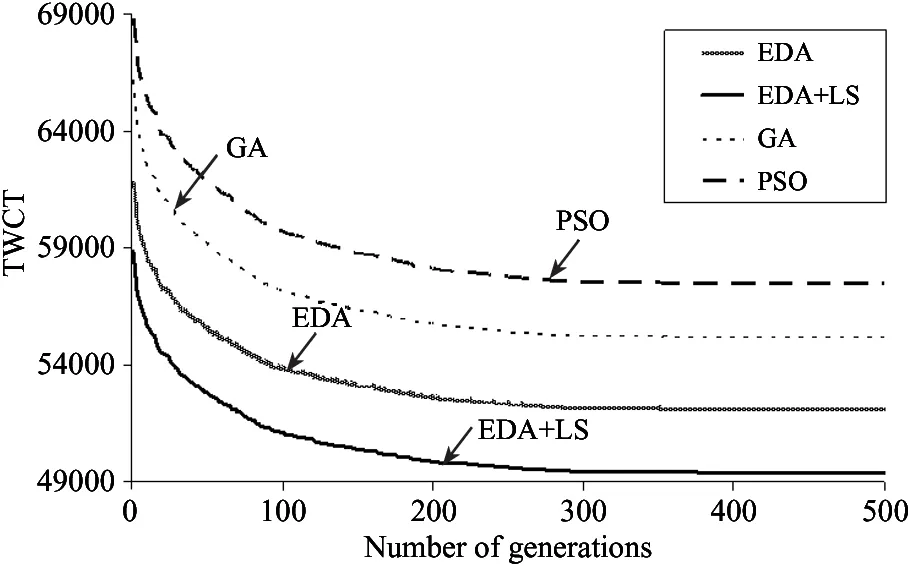
J′={πj|1≤j N(Iπj): the number of reticles occupied during Iπj. Based on the above variables, definitions and sequence π, the decoding heuristic is described as follows. Step 2: Initialize I=[a,a+pπi], Iπj=[Cπj-pπj, Cπj] and N(Iπj)=0. According to the above definition of the intersection, for each πj∈J′, if Iπj∩I≠φ, update Iπj=Iπj∩I, N(Iπj)=N(Iπj)+1. Step 3: For each πj∈J′, define K={πk|j Step 4: For each πk∈K, if Iπj∩Iπk≠φ, update Iπj=Iπj∩Iπk, N(Iπj)=N(Iπj)+1. Step 7: Cπi=a+pπi, J=J/πiand go to step 9. Step 9: If J≠φ, go to step 1. Otherwise, stop. 2.3 Population initialization In order to guarantee the diversity of the initial population, initial random population of popsize individuals are used which are distributed uniformly. 2.4 Probability model Different from the Genetic algorithm (GA) that produces offspring through crossover and mutation operators, EDA does it by sampling according to a probability model. So, the probability model has a great effect on the performance of EDA. In this paper, the probability model is designed as a probability matrix P. The element pij(gen) of the probability matrix P represents the probability that job j appears before or in position i of the solution sequence at generation gen. The value of pijrefers to the importance of a job when deciding the scheduling order. The initial population with popsize individuals determines the superior sub-population that consists of the best SP solutions, where SP=η×popsize, and η is a parameter representing the proportion of the superior sub-population in the whole population. Then the probability matrix P is initialized according to (11) In each generation of EDA, the new individuals are generated via sampling the solution space according to the probability matrix P. For every position i, job j is selected with a probability pij. If job j has already appeared, it means that job j has been scheduled. Then, the wholejth column of probability matrix P will be set as zero and all the elements of P will be normalized to maintain that each row sums up to 1. In such a way, an individual is constructed until all the jobs appear in the sequence. In EDA, a population with popsize individuals is generated. 2.5 Updating mechanism A new population with popsize individuals determines the superior sub-population that consists of the best SP solutions. And then probability matrix P is updated according to (12) where α∈(0,1) is the learning rate of P. The updating process can be regarded as a kind of increased learning, where the second term on the right hand side of the equation represents learning information from the superior sub-population. 2.6 Insert-based local search with the first move strategy As EDA pays more attention to global exploration while its exploitation capability is relatively limited, an effective EDA should balance the exploration and the exploitation abilities. In order to enhance the local exploitation ability of the algorithm, an insert-based local search with the first move strategy is introduced. Step 2: iter=1; Step 2.1: Choose u and v randomly (u≠v), πA_1=Insert(πA,u,v); Step 2.3: If f(πA_1) Step 2.4: iter=iter+1; Step 2.5: If iter≤(n·(n-1)), then go to step 2.1; otherwise, stop. 2.7 Procedure of proposed EDA Step 1: Initialize the population according to 2.3 and initialize the probability matrix P according to 2.4. Step 2: Sample the probability model to generate new population according to 2.4 and select superior sub-population. Step 3: Update the probability matrix P according to 2.5. Step 4: Perform the local search according to 2.6. Step 5: If the termination criterion is not met, go to step 2; otherwise, stop. In this section, in order to evaluate the computational results of EDA and EDA with the local search, the two algorithms are compared with GA and the particle swarm optimization (PSO). The performance measure employed in our numerical study is the average value of TWCT. All the algorithms are run on a 1.86GHz portable computer with 896MB of RAM running Windows XP professional. The codes are written in C++ language. 3.1 Datasets Since there are no standard test data in the open literature, the test problems are randomly generated on the basis of the following factors: 1. number of jobs or wafer lots (n), 2. number of machines (m), 3. number of reticles available for processing layer l (nl). For the set of test instances, the level settings for each factor are: 3 levels forn, 2 form, and 2 for nl. For instance, a problem denoted as n10m2a represents n=10, m=2 and nl=[Rl/3]+1, while a problem denoted as n10m2b representsn=10,m=2 and nl=[Rl/5]+1. And for each parameter combination, 10 instances will be generated randomly according to the parameter settings in Table1. This results in a total of 120 test problems. Table 1 Parameters for the test data 3.2 Parameters setting EDA contains several key parameters: popsize (the population size), η (the parameter associated with the superior sub-population), α (the learning rate). To investigate the influence of these parameters on the performance of EDA, the Taguchi method of design of experiment is implemented by using a moderate-scale problem n20m4a. For each parameter combination, EDA with local search operator is run 20 times independently and the average response variable (ARV) value is the average value of TWCT obtained by the proposed EDA. According to the number of parameters and the number of factor levels, the orthogonal array L25(53) is chosen. That is, the total number of treatment is 25, the number of parameters is 3, and the number of factor levels is 5. Different combinations of these parameter values are listed in Table 2. The orthogonal array and the obtained ARV values are listed in Table 3. Table 2 Parameter levels Table 3 Orthogonal table and ARV values According to the orthogonal table and the ARV values, the response values of each parameter listed in Table 4 can be obtained. Then, according to the response values, the trend of each factor level is illustrated in Fig.1. Table 4 Response table Fig.1 Factor level trend of the parameters According to the above analysis, a good choice of parameter combination is suggested as popsize=40, η=0.1, α= 0.1. 3.3 Computational results The average TWCT value and CPU time of 10 instances under 12 problems obtained by the four algorithms after 500 generations are listed in Table 5, where EDA represents the general EDA algorithm and EDA+LS stands for EDA with the local search operator. Both GA and PSO are of general procedure with the decoding scheme the same as the one proposed in this paper. The parameters for GA and PSO are set as follows: (1) For GA, popsize=60, crossover probability Pc=0.6, mutation probability Pm=0.25, where the parameters are also set by the Taguchi method of design of experiment using the problem n20m4a. (2) For PSO, popsize=70, learning factorsc1=c2=0.2, inertia weight w is initially set as 0.9 and then linearly decreased to 0.4 according to the number of iterations, where popsize is set by experiment and the other parameters are set according to general conditions[16]. As can be seen from Table 5, although GA and PSO appear more efficient in terms of CPU time because it requires a linear time to create new individuals for GA and PSO while this task requires O(N2) time for EDA, EDA is better than GA and PSO in terms of solution quality. Besides, the solution quality of GA and PSO can be hardly improved even if they use the same CPU time as EDA does because their convergence curves become flat after 500 generations as presented in Fig.2 and Fig.3. Furthermore, the performance of EDA can be greatly improved by adding the local search to it. Obviously, EDA+LS performs the best for all the problems and its CPU time is still acceptable. Fig.2 Convergence curves in solving nl=[Rl/3]+1 Fig.3 Convergence curves in solving nl=[Rl/5]+1 Fig.2 and Fig.3 depict the convergence curves obtained by the four algorithms for the 60 problems with nl=[Rl/3]+1 and nl=[Rl/5]+1 respectively. The vertical axis shows the average TWCT value of 60 instances for each algorithm. It can be seen from Fig.2 that although PSO evolves faster than the other algorithms at first, it turns out with a premature convergence. Fig.3 shows that the four algorithms are nearly of the same convergence speed, but they end with obvious difference in solution quality due to different solutions at the first generation. It’s apparent from both Fig.2 and Fig.3 that EDA outperforms GA and PSO in terms of solution quality. Furthermore, EDA+LS can provide even higher quality solutions than EDA. What’s more, the superiority of EDA and EDA+LS to GA and PSO in solution quality is more significant in Fig.3 compared with that in Fig.2, which indicates that EDA and EDA +LS may perform much better than GA and PSO when the auxiliary resources are more tightly constrained as the number of reticles of each type affects the availability of the auxiliary resources. All in all, the results show that the proposed EDA is effective, especially in solving scarce auxiliary resources problems. In this paper, an estimation of distribution algorithm is developed to solve the scheduling problem of parallel litho machines with reticle constraints by considering multiple reticles available for each reticle type. An effective decoding scheme is designed for the auxiliary resource constraints and an insert-based local search with the first move strategy is introduced which has been proved to be very useful. Comparisons to GA and PSO demonstrate the effectiveness of the proposed EDA in solving the scheduling problem in photolithography, especially when the auxiliary resources are constrained more tightly. [ 1] Lee Y H, Park J, Kim S. Experimental study on input and bottleneck scheduling for a semiconductor fabrication line.IIEtransactions, 2002, 34(2): 179-190 [ 2] Wang S, Zhang P, Qin W. Composite dispatching rule design for photolithography area scheduling in wafer manufacturing system with multiple objectives.AppliedMechanicsandMaterials, 2013, 252: 418-426 [ 3] de Diaz S L M, Fowler J W, Pfund M E, et al. Evaluating the impacts of reticle requirements in semiconductor wafer fabrication.IEEETransactionsonSemiconductorManufacturing, 2005, 18(4): 622-632 [ 4] Cakici E, Mason S J. Parallel machine scheduling subject to auxiliary resource constraints.ProductionPlanningandControl, 2007, 18(3): 217-225 [ 5] Shr A M D, Liu A, Chen P P. Load balancing among photolithography machines in the semiconductor manufacturing system.JournalofInformationScienceEngineering, 2008, 24(2): 379-391 [ 6] Pearn W L, Kang H Y, Lee A H I, et al. Photolithography control in wafer fabrication based on process capability indices with multiple characteristics.IEEETransactionsonSemiconductorManufacturing, 2009, 22(3): 351-356 [ 7] Klemmt A, Lange J, Weigert G, et al. A multistage mathematical programming based scheduling approach for the photolithography area in semiconductor manufacturing. In: Proceedings of the 2010 Winter Simulation Conference, Baltimore, USA, 2010. 2474-2485 [ 8] Yang F C, Kuo C N. A time window rolling-and GA-based method for the dynamic dispatching problem in photolithography area. In: Proceedings of the 40th IEEE International Conference on Computers and Industrial Engineering, Awaji Island, Japan, 2010. 1-6 [ 9] Klemmt A, Weigert G. An optimization approach for parallel machine problems with dedication constraints: Combining simulation and capacity planning. In: Proceedings of the 2011 Winter Simulation Conference, Phoenix, USA, 2011. 1986-1998 [10] Obeid A, Dauzère-Pérès S, Yugma C. Scheduling job families on non-identical parallel machines with time constraints. In: Proceedings of the 2011 Winter Simulation Conference, Phoenix, USA, 2011. 1994-2005 [11] Yan B, Chen H Y, Luh P B, et al. Litho machine scheduling with convex hull analyses.IEEETransactionsonAutomationScienceandEngineering, 2013, 10(4): 928-937 [12] Zhang Y, Li X. Estimation of distribution algorithm for permutation flow shops with total flowtime minimization.Computers&IndustrialEngineering, 2011, 60(4): 706-718 [13] Wang L, Wang S, Xu Y, et al. A bi-population based estimation of distribution algorithm for the flexible job-shop scheduling problem.Computers&IndustrialEngineering, 2012, 62(4): 917-926 [14] Wang S, Wang L, Liu M, et al. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem.InternationalJournalofProductionEconomics, 2013, 145(1): 387-396 [15] Larranaga P, Lozano J A. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Netherlands: Springer, 2002 [16] Liu Z X, Liang H. Parameter setting and experimental analysis of the random number in particle swarm optimization algorithm.ControlTheory&Applications, 2010, 27(11): 1489-1496 Zhou Binghai, was born in 1965. He received Ph.D and M.S. degrees respectively from School of Mechanical Engineering, Shanghai Jiaotong University in 2001 and 1992. He is a professor, a Ph.D supervisor in School of Mechanical Engineering, Tongji University. He is the author of more than 140 scientific papers. His current research interests are scheduling, modeling, simulation and control for manufacturing systems, integrated manufacturing technology. 10.3772/j.issn.1006-6748.2016.01.007 ① Supported by the National High Technology Research and Development Programme of China (No. 2009AA043000) and the National Natural Science Foundation of China (No. 61273035, 71471135). ② To whom correspondence should be addressed. E-mail: bhzhou@tongji.edu.cnReceived on Jan. 28, 2015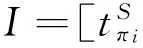
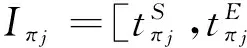

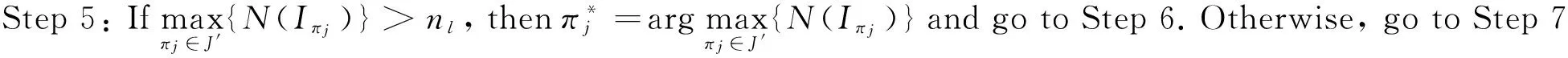
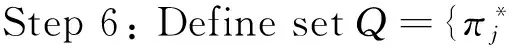
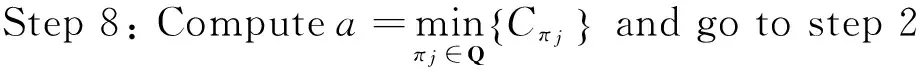
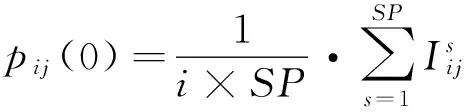

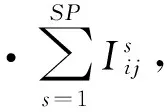


3 Simulation and analysis



4 Conclusion
杂志排行

High Technology Letters的其它文章
- Time difference based measurement of ultrasonic cavitations in wastewater treatment①
- Research on the adaptive hybrid search tree anti-collision algorithm in RFID system①
- An improved potential field method for mobile robot navigation①
- Robust SLAM using square-root cubature Kalman filter and Huber’s GM-estimator①
- CSMCCVA: Framework of cross-modal semantic mapping based on cognitive computing of visual and auditory sensations①
- Mixing matrix estimation of underdetermined blind source separation based on the linear aggregation characteristic of observation signals①