应用Q-gram命中特征优化的近似串匹配算法
2016-11-22王晓霞孙德才
王晓霞,孙德才
(渤海大学 辽宁 锦州 121013)
应用Q-gram命中特征优化的近似串匹配算法
王晓霞,孙德才
(渤海大学 辽宁 锦州 121013)
近似串匹配是文本检索、生物信息学和信号处理等领域的研究基础。为提高近似串匹配速度,采用分块的方法从匹配串中提取了新的q-gram命中特征,结合新特征提出了一种新的近似串匹配算法。实验数据表明新算法消耗了少量的过滤时间就获得了较高的过滤效率,结果显示新算法在各种匹配错误率下的匹配速度一直比经典的SWIFT算法快。
近似串匹配;过滤算法;q-gram过滤;q元语法
近似串匹配(Approximate String Matching)[1]是允许有“错误”发生的字符串匹配,它在文本串中查找所有与模式串之间错误数不大于一定阈值的所有匹配串。字符串间的错误数可采用编辑距离、汉明距离、最长公共子串等表示。编辑距离[2]是指把一个字符串经过插入、修改或删除3种编辑操作转变成字符串所要进行的最小操作次数,常用表示。近似串匹配技术在众多研究领域都有广泛的应用,如文本检索、生物信息学、信号处理和模式识别等。
基于Off-line模式的过滤算法[3-4]是一种采用先过滤再验证的二阶段近似串匹配方法。过滤算法因采用过滤技术能在前期快速去除大量文本区域,适合Off-line模式下的大文本库匹配。目前,过滤算法可归为二类:精确匹配子串法和近似匹配子串法。精确匹配子串法通过定位无错误的模式串子串进行过滤,如文献[5-11]。而近似匹配子串法通过定位允许有错误的模式串子串进行过滤,如文献[12]。精确匹配子串法中因子串匹配过程简单、过滤速度快而得到广泛研究。如文献[5]把模式串分成部分,在文本串中至少出现s部分且位置正确的文本区域才被验证,这里称为KS算法。Burkhardt对Jokinen和 Ukkonen[8]的工作进行了改进,提出一个近似串局部匹配算法QUASAR[7]。Rasmussen从基因检索算法FASTA中受到了启发提出一个近似串局部匹配算法SWIFT[9]。
本研究主要解决的是在大文本库中快速查找与模式串间错误率不大于的所有匹配串的问题。文中将结合KS算法和q-gram命中特征,设计一个新的无损过滤算法,拟通过牺牲一定过滤时间来换取较大过滤效率的提升,最终达到提高算法整体匹配速度的目的。
1 基础知识
KS算法的核心思想是把模式串分割成k+s个不重叠的子串,如果文本串中存在与模式串编辑距离不大于k的匹配串,那么文本串中一定存在至少s个完整匹配的模式串子串。该过滤准则最早由Wu和Manber提出,其算法中采用了s=1,这里称为KS1算法,具体过滤定理参考文献[5]。
Q-gram是长度为q的字符串,其位置用其首字符在模式串或文本串中的偏移量表示。Q-gram拆分方法是在串首放置一个长度为q的移动窗口,每次从窗口中提取一个qgram,根据窗口的移动距离d不同切分的方式也不同。Q-gram索引[13-14]主要包括2部分:词汇表和倒排列表。词汇表是q-gram项的集合,常采用哈希表或B*树。每个q-gram项后连有一个存储该索引项在文本中出现的地址集合,称为倒排列表。
最早提出基于q-gram命中的过滤定理的是Jokinen和Ukkonen,该基础过滤定理描述了一个存在匹配串的文本区域具有的最基本的q-gram命中特征,具体定理参考文献[8]。
错误率描述一个字符串与模式串间的近似程度,定义为编辑距离与模式串长度的比值,。匹配错误率(Matching Error Ratio)是近似串匹配中界定哪些是匹配串的参数,匹配串是与模式串之间错误率不大于匹配错误率的字符串。
过滤效率(Filtration efficiency)是描述算法过滤阶段抛弃无关片段的能力,定义为fe=(n-nf)/(n-nt),其中n表示整个文本库的长度,即,nf表示过滤算法在本次匹配中未过滤掉的文本区域的总长度,而表示本次匹配文本库中真实存在的所有匹配串的长度总和。
2 新过滤特征提取
提取新过滤特征时为便于表达,这里设q为q-gram索引中q-gram项的长度,e为过滤算法的匹配错误率,则匹配串与模式串P间的最大编辑距离k可通过计算。
定理1对字符串S进行任意分区,并任选一个编辑不动点(任二字符间),如图1。如在字符串S上任意位置施加k次编辑操作后(分区边界不随字符移动),则任意分区内原来的q-gram数量减少的数目都不超过kq。

图1 字符串分区示意
证明以下分2种情况进行讨论:
1)包含不动点的分区si:si分区内不论在不动点的左或右,一个修改操作最多改变个q-gram;一个删除操作最多改变q个q-gram,如编辑发生在不动点左侧则左侧有新的qgram被移入,如在右侧则右侧有新的移入,但新的移入不会影响原来的q-gram;一个插入操作最多改变个q-gram,同时引起q-1个q-gram外移(编辑发生在不动点左侧则左移出,在右侧则右移出),即至多影响q个q-gram。因此,si分区内k个编辑操作最多影响kq个q-gram。
2)不包含不动点的分区sj:sj设分区在不动点的左侧,如此影响sj区q-gram数的编辑操作或发生在sj区内,或发生在sj区的右侧与不动点之间。如全发生在sj区内则与1)情况类似,最多影响kq个q-gram;如编辑发生在sj区的右侧与不动点之间,修改操作不影响sj区内的q-gram,一个插入操作最多使得原sj区内的一个q-gram左移出,一个删除操作最多使得区sj内的一个q-gram右移出。综上所述,影响最多的是编辑操作发生在区内,因此原sj区经过编辑操作后最多影响kq个q-gram。分区的位置在不动点右侧情况类似,这里不再讨论。
结合情况1)和2)可知,定理1证毕。
定义1对模式串P进行连续但不重叠的等大小分割,把P分割成k+1个模式块,分别称为P0,P1,…Pk,则前k块的长度,这里称为完整模式块,最后一个pk块的长度为l,l≥b,称为尾模式块。Pi+1块为Pi块的右连续块,对Pi+1块向左扩展 q-1个字符得到 P(i+1)块,称 P(i+1)块为Pi+1块的模式修正块。称 P0,P1,…,Pi,P(i+1),…Pk为模式块序列,如图2。如模式串P中一个q-gram项Q的首字符落在模式块Pj中,则称为Q在模式块Pj内。, 0≤j<i。从串向右进行k-i次扩展则得到,,…,块,且
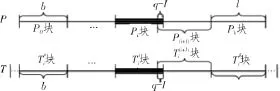
图2 模式串分割与文本块序列
定义2设Pi,0≤i≤k是模式串P根据定义1进行分块后的第i个模式块,设是文本串的一个子串,且串和Pi完全匹配(相等),则称块为Pi块的一个命中文本块。在T中从向左进行i次扩展则得到,,…,块,且 。则从块首字符向左拓展k个字符位置开始到块尾字符向右扩展k个字符位置结束的区域称为模式串P的一个潜在匹配区域。块为块的右连续串,把串向左扩展q-1个字符得到块(对应 P(j+1)),称为块的文本修正块。称为模式串P的P0,P1,…,Pi,P(i+1),…,Pk的一个对应文本块序列,如图2。文本串T中一个q-gram项Q的首字符落在模式块Tj中,则称为Q在文本块内。
情况a):当,1)且j=i时,Tji块内与Pj块内共享的q-gram项数等于b-q+1;2)且0≤j<i或j=(i+1)或i+1<j<k时,块内Pj块内共享的q-gram项数不小于且j=k时,块内与Pj块内共享的q-gram项数不小于t,如k≠i+1则t=l+1-(k+1)q,如则t=l-kq。
情况a):当0≤i<k,表明命中文本块不是尾文本块,即i≠k,此时,
2)且0≤j<i或j=(i+1)或i+1<j<k时,因命中文本块非尾文本块,所以满足条件的模式块Pj除第i+1块进行了左扩q-1字符外其他长度都为b,长度用表示,块内共有个 q-gram。又据基础过滤定理可知,Tji块内和Pj块内共享的qgram项数不小于个。
3)且j=k时,表示命中文本块非尾文本块,要计算qgram数目的为尾文本块。因尾文本块不能进行右扩展,如k≠i+1时,块长为l,内含l-q+1个q-gram。根据基础过滤定理可知块内与Pk块内共享的q-gram项数不小于l+1-(k+1)q。如k≠i+1时,则尾文本块刚好也是第i+1块,串长为l+q-1,内含l个q-gram。根据基础过滤定理可知块内与Pk块内共享的q-gram项数不小于l-kq。
情况b):当i=k,表明命中文本块为尾文本块,且不存在第i+1块,此时,
结合情况a)和b)可知定理2成立,证毕。
3 用q-gram命中特征改进的KS1算法
定理2描述了一个含有匹配串的文本区域具有的qgram命中特征,包括:1)包含至少一个完全匹配的模式块;2)模式块与对应文本块间共享的q-gram数目满足一定的阈值;3)文本块序列构成的文本区域与模式串间总共享q-gram数目也满足一定的阈值。反过来说,一个满足上述特征的文本区域内包含匹配串的概率也非常高。本节将介绍一个用定理2新特征优化的KS1算法 (Counter KS,CKS),简称CKS算法,用于解决大文本库的近似串全局匹配问题。该算法包括文本库预处理、输入、过滤、验证和输出5部分。文本库预处理中采用q-gram索引结构。输入阶段需要给定模式串和匹配错误率。过滤阶段包括KS1过滤和q-gram命中过滤,是本文算法的核心,将进行详细介绍。验证阶段采用Smith-Waterman算法[15]进行验证。输出阶段则输出匹配结果。
过滤阶段的主要任务是尽可能地用过滤条件剔除那些一定不包含匹配串的文本区域。好的过滤器能在较短的过滤时间内抛弃大量的无关文本区域。本文的CKS算法过滤器包含KS1过滤器和q-gram命中数过滤器,二个过滤器的过滤过程是互相交叉的。CKS算法过滤阶段的主要思路是:首先采用KS1过滤器抛弃那些不含命中文本块的文本区域,然后用q-gram命中数除去那些虽然存在命中文本块但命中数目不满足要求的文本区域。这里分配一个长度为的一位数组H来存储这些命中位置信息。如数组中H[i]=1则代表P中存在q-gram命中T中第i个位置,相反值为0时代表无命中。数组H中每个元素因只需存储1或0,所以可用一个二进制位存储,且每32个二进制位为一组。CKS过滤器的过滤过程如下:
步骤2)处理q-gram项Qj,从q-gram索引中取出Qj的倒排列表,并依次读取倒排列表中的q-gram项地址,同时置H数组。例如,t是倒排列表中一个q-gram地址,即Qj命中了文本的位置t,即置H[t]=1。当Qj的倒排列表处理完毕后,j=j+ 1,转2)处理下一个q-gram。直到模式串的所有q-gram都处理完毕时,转3)。
步骤3)按定义1和定义2在逻辑上把模式串在分割成k+1个连续但不重叠的模式块P0,P1,…,Pk。从0到k依次处理每个模式块Pi,0≤i≤k,一个模式块的处理过程如4)。
步骤4)处理模式块Pi,首先从模式串中提取出Pi块的内容,对其进行滑动距离为q的q-gram拆分。最后可能剩余不足长度q的剩余串,此时从Pi块后向前取q个字符构成一个q-gram项,最后得到模式块Pi的所有q-gram项,转5)。
步骤5)为确定模式块Pi在文本串T中所有的命中文本块,首先按顺序依次从q-gram索引中提取出各q-gram的倒排列表;然后按倒排列表长度从小到大进行排序;接着从长度小到大顺序依次对倒排列表进行地址交运算(以第一个qgram项为基地址)。如运算过程中列表出现空集,则可确定模式块Pi在文本串中无命中文本块,i=i+1转步骤4),否则将得到模式块Pi在文本串T中的命中文本块集合。最后依次处理集合中的每一个命中文本块,处理过程如6)。
步骤6)处理模式块Pi命中的文本块,首先按定义1和定义 2进行扩展,得到对应的文本块序列;然后访问q-gram命中数组H统计各个文本块中的q-gram命中数目。由于H中每32个二进制位为一组,每个二进制位代表一个q-gram是否命中,所以只需统计文本块范围内二进制位中1的个数。CKS采用快速算法处理文本块的组,时间复杂度与1个数有关,而与二进制位数无关。对于完整的组直接处理,而不完整的组则要辅以移位和取低位等运算。如某个文本块内的q-gram命中数目不满足定理2条件,则该命中无效,转6)处理下一个命中。如每个文本块内q-gram命中都符合要求则转8)。
步骤8)i=i+1,转4)处理下一个模式分块,直到所有模式块都被处理完毕时,算法结束。
4 实验
4.1 实验环境
文中实验数据来源于美国国家生物技术信息中心NCBI的人类不同完整基因序列 (ftp.ncbi.nih.gov//repository/Uni-Gene/Homo_sapiens/Hs.seq.uniq.gz),共约164 MB基因序列文本,共123,252个完整人类不同基因序列。因SWIFT,QUASAR中的值都为11,这里也取11。文中实验中参加对比的算法有 KS1[5]、QUASAR[7]、SWIFT[9]以及本文的 CKS。QUASAR算法中的块大小设置为,SWIFT算法中的Bin大小设置为。本实验的模式串集合为500个长度为2,000基因子序列。文中所有实验都在同一硬件和软件环境下进行的,实验硬件环境是:处理器AMD X4 630和主存4 GB;实验软件环境是:WINDOWS XP SP3和VISUAL C++6.0。
4.2 CKS算法性能表现
为对比分析各个算法在不同匹配错误率下的性能差异,实验中对模式串集分别采用KS1、QUASAR、SWIFT和CKS算法进行批量匹配实验,匹配错误率分别采用 0,0.005,0.01,0.02,0.03,0.04。实验中统计了不同匹配错误率下各算法的过滤时间、过滤效率、验证时间和匹配时间的平均值,如图3所示。
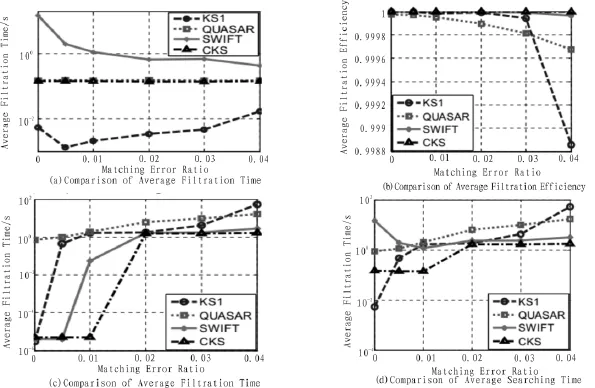
图3 算法性能对比
从图3(a)的平均过滤时间对比可知,CKS算法的过滤时间消耗要少于SWIFT算法,接近QUASAR,但要多于KS1算法。KS1算法的过滤时间最短,因其过滤过程最简单。从图3(b)的平均过滤效率对比可知,CKS算法在匹配错误率较低时与SWIFT、KS1等算法的过滤效率接近。当匹配错误率较高时,CKS算法的过滤效率最高,这是因为其过滤条件的选择更能体现匹配区域特征。从图3(c)的平均验证时间对比可知,KS1、SWIFT和CKS算法在匹配错误率较低时都较好,且当匹配错误率升高时,CKS、SWIFT逐渐占据优势。从总体而言,CKS算法因其过滤效率较高而使其验证时间都较短。从图3(d)的平均匹配时间对比可知,QUASAR算法的匹配时间一直都较长;KS1算法当匹配错误率为0时匹配速度最快,而当匹配错误率较高时效果变差;SWIF算法当匹配错误率较低时因过滤时间较长而总时间较长,而当匹配错误率较高时速度逐渐变快。CKS算法的匹配时间都较稳定性,算法除精确匹配要比KS1算法差一点外,在其他匹配错误率下都较快,这主要源于CKS算法的过滤时间较短而验证时间又不太长。根据以上分析可得出如下结论:
1)CKS算法的整体性能稳定,对匹配错误率的改变不敏感,相对于其他算法更具通用性。
2)CKS算法除进行精确匹配外,相对于其他算法其匹配速度一直都最快。
5 结论
文中为解决从大文本库中查找模式串的所有匹配串问题,提出了一种用q-gram命中特征优化的近似串匹配算法。文中给出了q-gram命中特征的提取过程和新算法的匹配详细流程。最后实验数据表明改进算法通过使用新过滤特征在较短的过滤时间内就获得了较高的过滤效率,加快了总的匹配速度。理论分析和实验结果显示,新算法的整体性能较好,稳定性高,适合各种匹配错误率下的近似匹配。
虽然新算法提高了算法的过滤效率,但算法还存在精确匹配效果不好、随匹配错误率逐渐升高逐步退化等问题。文中下一步的工作将继续研究减少过滤时间,提高过滤效率等相关方法和技术,并进一步优化本文算法。
[1]Navarro G.A guided tour to approximate string matching[J].ACM Computing Surveys,2001,33(1):31-88.
[2]Levenshtein V.Binary codes capable of correcting deletions,insertions,and reversals[J].Soviet Physics Doklady,1966,10(8):707-710.
[3]Burkhardt S.Filter algorithms for approximate string matching:[D].Saarland:Department of Computer Science,Saarland University,2002.
[4]Hu HJ,Zheng K,Wang XL,et al.GFilter:A General Gram Filter for String Similarity Search[J].IEEE Transactions on Knowledge and Data Engineering,2015,27(4):1005-1018.
[5]Wu S,Manber U.Fast text searching allowing errors[J].Communications of the ACM,1992,35(10):83-91.
[6]Chang YI,Chen JR,Hsu MT.A hash trie filter method for approximate string matching in genomic databases[J].Applied Intelligence,2010,33(1):21-38.
[7]Burkhardt S,Crauser A,Ferragina P,et al.Q-gram based database searching using a suffix array[C].//Proceedings of the AnnualInternationalConference on Computational Molecular Biology,RECOMB 99.New York,USA:ACM,1999:77-83.
[8]Jokinen P,Ukkonen E.Two algorithms for approximate string matching in static texts[C].//16th International Symposium Proceedings on Mathematical Foundations of Computer Science.Berlin,Germany:Springer-Verlag,1991: 240-248.
[9]Rasmussen KR,Stoye J,Myers EW.Efficient q-gram filters for finding all epsilon-matches over a given length[J].Journal of Computational Biology,2006,13(2):296-308.
[10]Lu,CW,Lu CL,and Lee,RCT.A new filtration method and a hybrid strategy for approximate string matching[J].Theoretical Computer Science,2013,481(0):9-17.
[11]Egidi L,Manzini G.Better spaced seeds using Quadratic Residues[J].Journal of Computer and System Sciences,2013,79(7):1144-1155.
[12]Baeza-YatesR, Navarro G.Fasterapproximate string matching[J].Algorithmica,1999,23(2):127-158.
[13]Navarro G,Baeza-Yates R,Sutineny E,et al.Indexing methods for approximate string matching[J].IEEE Data Engineering Bulletin,2001,24(4):19-27.
[14]Navarro G,Baeza-yates R.A practical q-gram index for text retrieval allowing errors[J].CLEI Electronic Journal,1998,1(2):1-16.
[15]Smith TF, Waterman MS, Identification ofcommon molecular subsequences[J].Journal of Molecular Biology,1981,147(1):195-197.
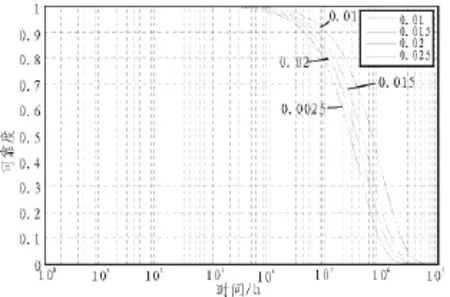
图4 不同的λk所对应的掺铒光纤光源可靠度曲线
4 结论
文中针对光纤陀螺用掺铒光纤光源高可靠性、长寿命的特点提出了无失效数据下基于贝叶斯理论的可靠性评估方法,通过分析掺铒光纤光源失效模式给出了威布尔分布作为其寿命分布,结合先验信息和少量的试验数据估计出了可靠性模型参数,并通过仿真分析说明所得掺铒光纤光源可靠性模型是合理的,且算法具有较好的稳健性。为实际应用中光纤陀螺及惯导系统的可靠性评估提供了依据。但处理先验信息相对保守,有待进一步研究得出更精确的可靠性模型。
参考文献:
[1]王瑞.应用于高精度光纤陀螺的掺铒光纤光源研究[D].哈尔滨:哈尔滨工程大学,2008.
[2]金少华.电工产品可靠性评估方法与贝叶斯理论的应用[D].天津:河北工业大学,2002.
[3]刘海涛,张志华.威布尔分布无失效数据的贝叶斯可靠性分析[J].系统工程理论与实践,2008(11):103-108.
[4]李承剑,慕晓冬,张华鹏.基于贝叶斯理论的航空电子设备可靠性评估[J].火力与指挥控制,2009(1):139-140.
[5]马静,王大海,晁代宏,陈淑英.基于关键器件的光纤陀螺可靠性评估[J].中国惯性技术学报,2009(5):618-621.
[6]姚淼,宋家友,张俊丽.基于贝叶斯理论的ATS测量不确定度评定[J].计算机测量与控制,2015,23(6):2053-2055.
Approximate string matching algorithm optimized with q-gram hit features
WANG Xiao-xia,SUN De-cai
(Bohai University,Jinzhou 121013,China)
Approximate string matching is a widely used in Text Retrieval,Computational Biology and Signal Processing,etc.To enhance the performance of approximate string matching,some new features based on q-gram hit are extracted from true match by using partition and a new approximate string matching algorithm based these features is proposed.The experimental results demonstrate that the proposed algorithm achieves high filtration efficiency in a short filtration time by using new features and the new algorithm's matching speed is always faster than that of SWIFT on condition of various matching error ratio.
Approximate string matching;filter algorithm;q-gram filter;q-gram
TN91
A
1674-6236(2016)15-0149-05
2016-01-16 稿件编号:201601127
教育部人文社会科学研究青年基金项目(15YJC870021;15YJC870028);辽宁省博士科研启动基金计划项目(201411 38);辽宁省教育厅科学研究项目(L2015010;L2014451);辽宁省自然科学基金(2015020009)。
王晓霞(1977—),女,辽宁葫芦岛人,硕士,讲师。研究方向:近似串匹配、近似重复检测、入侵检测等。
