MapReduce框架下的优化高维索引与KNN查询
2016-11-17梁俊杰李凤华刘琼妮
梁俊杰,李凤华,刘琼妮,尹 利
(1.湖北大学计算机与信息工程学院,湖北武汉 430062;2.中国科学院信息工程研究所信息安全国家重点实验室,北京 100093;3.北京电子科技学院,北京 100070)
MapReduce框架下的优化高维索引与KNN查询
梁俊杰1,李凤华2,3,刘琼妮1,尹 利1
(1.湖北大学计算机与信息工程学院,湖北武汉 430062;2.中国科学院信息工程研究所信息安全国家重点实验室,北京 100093;3.北京电子科技学院,北京 100070)
针对大规模高维数据近似查询效率低下的问题,利用MapReduce编程模型在大规模集群上的数据与任务的并行计算与处理优势,提出MapReduce框架下大规模高维数据索引及KNN查询方法(iPBM),重点突破MapReduce数据块(block)的优化划分与各数据块对计算的共同贡献两大难题,利用两阶段数据划分策略并依据相关性与并行性原则将数据均匀分配到各数据块中,设计分布式的双层空间索引结构与并行KNN查询算法,检索时利用全局索引、局部索引与二维位码索引实现三层数据过滤,大幅缩小搜索范围并降低高维向量计算代价,实验表明iPBM对大规模高维数据的近似查询具有准确性、高效性和扩展性.
云计算;MapReduce;KNN查询;高维索引
电子学报URL:http://www.ejournal.org.cn DOI:10.3969/j.issn.0372-2112.2016.08.015
1 引言
随着下一代互联网、物联网和云计算[1]等信息技术的创新发展和重点应用,用户面临海量数据或大数据诸多挑战,很多领域数据呈现高维表现形态,如金融交易数据、多媒体数据、航天数据、生物数据等,维度高达几十维甚至上百维.高维空间数据应用常见以近似查询(similarity query)为主,如何提高大规模高维数据近似查询效率已成为学术界的研究热点.
为适应大数据使用管理需求,Google公司提出了MapReduce计算模型[2,3],将运行于大规模集群上的复杂并行计算过程高度地抽象为两个函数:Map和Reduce.一个Map/Reduce作业(Job)通常会把输入的数据集切分为若干独立的数据块,由Map任务(Task)以完全并行的方式处理它们,结果输入给Reduce任务.MapReduce框架由一个单独的Master和集群节点上的Slave共同组成.Master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上.这种框架的设计可以充分利用整个集群的网络带宽,同时保障了系统可靠性和容错性,是目前云计算环境的核心计算模式.
高效的数据存取策略是提高高维数据查询性能的关键,为了避免不必要的数据存取普遍做法是利用索引技术.在大数据时代,如何将高维索引技术和并行计算模型有机结合是一个新的研究方向,最近几年针对云计算环境下的索引技术研究受到学者的广泛关注[4~8].Dittrich等人分别在2010年和2012年VLDB会议上提出了Hadoop++[9]和HAIL[10].Hadoop++系统使用了一种称为Trojan的索引结构,将描述输入片段(input splits)的索引信息写入片段中,在一个片段中可以有多个局部索引(partial index),每个局部索引只描述片段中部分数据信息,在这些局部索引中有一个主索引(primary index),查询时根据需要查找相应的索引.Trojan索引的创建过程是在数据加载阶段完成,因此不影响查询效率.HAIL是为缩短Hadoop++索引构造时间,对每个Hadoop备份数据创建了一个聚类索引,检索时选择最佳的索引而提高查询效率.Hadoop++和HAIL都是在Hadoop默认的数据块划分基础上建立索引,需要进一步考虑查询需求和数据分布对数据划分的影响.Eltabakh等人对Hadoop进行扩展提出了CoHadoop[11],定义文件级属性(file-level property)概念称为locator,在NameNode上新增一个locator数据表,将locator属性值相同的文件存储到同一个DataNode上,达到将相关数据存储在同一节点上的目的,但是如何实现系统自动判断两个文件是否相关是CoHadoop的难点.Zaschke发表在2014年SIGMOD会议上的论文,描述了一种多维数据存储和索引结构称为PH树[12],为减少存储空间在索引结构中共享二进制描述前缀,PH树支持点查询和范围查询时快速数据存取,但PH树如何扩展到MapReduce框架有待进一步研究.文献[13~15]是在MapReduce框架的计算节点上建立局部B+-Tree、R-Tree或四叉树索引,并基于局部索引构造全局索引,查询时依据查询模型动态选择合适的索引,这些方法都是基于MapReduce默认的数据划分无法保障数据块对计算共同贡献.Wei等人提出了基于Voronoi图数据划分的knnJ查询的MapReduce算法,将不同Voronoi图的对象分配到不同的组内,但是算法效率对Voronoi图支点选择策略具有很强的依赖性[16].Doulkeridis等探讨了利用MapReduce处理Top-K查询的一些基本问题,但是缺少对问题的深入分析和实验验证[17].国内,刘义等人在2013年发表论文[18,19],提出了一种采样算法以快速确定空间划分函数,构建了符合MapReduce计算模型的索引结构,并利用分布式R-树索引实现K-近邻连接查询,该方法主要限定于地理空间的knnJ查询,没有测试高维空间对算法性能的影响.
针对目前鲜有人研究MapReduce框架下的高维数据索引及KNN检索方法[20],MapReduce框架自身缺少数据分块划分优化策略以及无法保证每个数据分块对计算共同贡献的缺陷,本文提出了一种新的MapReduce框架下的高维索引(Index Partition Bitcodes in MapReduce,简称iPBM).充分利用MapReduce框架在大规模集群上的数据和任务的并行计算与处理能力,基于高维数据分布和近似查询特点优化高维空间数据块的划分机制,设计可扩展的、分布式的双层空间索引以及KNN并行查询算法,检索过程实现了数据快速筛选避免了大量数据无效计算,实验表明iPBM在提高高维数据查询效率和扩展性方面都具有明显优势.
2 问题描述和背景知识
为了简化问题阐述,本文引用的符号和含义如表1所示,并作如下合理的假设:
(1)针对分析型应用环境,数据集相对稳定.因此,索引只需一次构建,用于多次查询.
(2)MapReduce始终保持负载均衡,当数据量发生变化时,MapReduce可以适当增加或减少服务器数量或者调整配置参数.
(3)高维向量相似性用相应的空间点距离来表示.不失一般性,本文采用欧氏(Euclidean)距离.
(4)文中以KNN查询为例介绍高维数据近似查询实现过程,其他种类的近似查询可以依此类推,限于篇幅不做详述.

表1 相关符号描述
定义1 KNN查询 假设高维向量对象集DS={P1,P2,…,Pn},查询点Q,则KNN查询返回DS中与Q距离最近的k个对象,并按距离升序排列:KNN(DS,Q,k)={Pr,Pt,…,Ps|Pr,Pt,Ps∈DS}.
3 MapReduce框架下的高维索引
iPBM是在MapReduce的开源框架Hadoop平台下实现的,KNN查询分为两个阶段:
(1)索引构建阶段:对海量高维数据进行聚类和分区划分,针对Master和Slave分别设计不同的索引结构.(2)KNN查询阶段:利用双层索引确定候选点对象集和任务划分,执行并行KNN查询.
3.1 数据划分
MapReduce框架由一个提供元数据服务的Master节点和若干个提供存储的Slave节点组成,适合大规模数据并行计算和任务处理.为了适应这种机制,创建索引之前有必要对数据集进行必要的预处理,使得数据应尽可能均匀地划分到多个数据块中,并对最终结果均有贡献.
3.1.1 聚类划分
数据划分首先是对数据集DS进行聚类分析.不失一般性,我们采用K-means聚类方法[21]对d维空间数据进行全局分析,得到数据簇C={C1,C2,…,Cm}及质心O={O1,O2,…,Om}.
3.1.2 分区划分
数据空间聚类划分后,对各个数据簇按其数据分布特征做进一步的分区划分,得到数据簇的分区AS={A1,A2,…,A2d}.为方便描述,本文将数据簇质心作为簇的参考点用于计算分区和点对象的位码索引值,也可以选择其他点作为参考点.
定理1 划分分区的维数 假设数据簇的大小Size(C)、点对象的大小Size(P)以及查询结果集K值,则划分数据簇分区的维数:
公式中c是常量(c≥1),它的作用是使划分后的分区内包含的点对象数量至少是K的c倍,这样每个候选簇只需确定一个候选分区就能基本满足查询结果对象个数要求,避免了搜索多个分区的计算复杂性.以我们的实验数据二十维向量空间为例,数据集DS大小540MB,点对象大小为104Byte.根据K-means聚类算法DS被划分成4个数据簇A、B、C、D,其中数据簇B大小为250MB.假设K=10,c=20,根据定理1计算用于划分数据簇B分区的维数为13,簇B被划分为213个分区.
定义2 分区位码A(b1,b2,…,bd′) 假设整数变量i代表维标(1≤i≤d′),则bi表示分区A的第i维位码、oi表示质心O的第i维位码、pi表示任意点P的第i维位码,假设A所在的数据簇质心为O(o1,o2,…,od′),由于同一分区内所有点对象具有相同的位码值,因此可以由区内任意一点P(p1,p2,…,pd′)的位码值得到分区A的位码:
由定义2可以看出,一个分区的位码表达该分区相对簇参考点的位置关系,在数据簇内任一分区均可用长度为d′的唯一位码字符串来表示.以二维向量空间为例,各个分区的位码表示如图1所示.

为有效克服高维空间“维数灾难[22]”影响,iPBM综合利用近似向量表示法和一维向量转换法的优点,利用二维的位码索引值压缩高维向量表示.
定义3 位码索引值 高维向量点对象P(p1,p2,…,pd)的位码索引值为P(Dp,Bp),其中Dp是P与所属簇参考点间的距离;Bp是P与参考点间的近似位置关系,即P的位码值.
由定义3 可知,位码索引值的主要作用体现在检索过程中不仅可以根据Bp过滤候选分区,而且可以根据Dp进一步过滤候选分区环,从而在没有任何高维欧氏距离计算情况下就能实现搜索范围两级过滤,大大缩小搜索范围从而降低高维向量距离计算代价.3.2 数据存储
在数据存储时为了兼顾相关性和并行性两方面原则,iPBM将一个簇数据的所有Block放在一个Slave节点上,一个Slave节点可以存储多个簇的数据,同时将簇中所有分区的数据均匀分配到该簇的每个Block中.这样做的好处是,查询时筛选出候选分区后,根据候选分区的对象信息存储在多个Block中的特点,可以利用多个Map任务并行计算,提高查询并行性和查询效率.在本文第四章KNN查询算法介绍中,可以看出这种数据划分和存储的好处.
在iPBM中,在Master节点上设计了一个定位表存储各个数据簇在Slave节点上的分布信息.如图2和图3所示,定位表指示簇A和簇D存储在Slave1上,簇B存储在Slave2上,簇C存储在Slave3上,则簇A的数据块A1和A2以及簇D的数据块D1存放在Slave1上,簇B的数据块B1、B2和B3存放在Slave2上,簇C的数据块C1和C2存放在Slave3上.另外的3个Slave节点存储这些簇的备份.


3.3 索引结构
依据iPBM的数据划分和存储结构,为KNN查询设计基于高维空间位置编码的双层索引G-L(图4),包含全局索引G-Index和局部索引L-Index.全局索引存放在Master节点上负责数据定位.局部索引存放在Slave节点上负责数据存取.

定义4 全局索引G-Index以键值对形式存储数据簇元数据信息,表示为
定义5 局部索引L-Index以键值对形式存储数据簇内的分区和点对象信息,表示为
以图1数据划分示意图,双层索引G-L结构如图4所示.
4 基于G-L索引的KNN查询
4.1 数据筛选
定义6 候选分区环 假设查询点Q在候选簇C
由定义6可以看出,在不需要高维向量距离计算情况下,根据点对象的位码索引值就可以判断该点是否属于候选点,从而降低高维计算代价,有效克服“维数灾难”影响.候选分区环内的点对象即为最终的KNN查询结果候选点对象.以二维空间为例,假设两个查询Q1和Q2,Q1查询的候选分区为数据簇B的A3区和数据簇D的A2区(图5中分别用深灰和灰色表示),Q2查询的候选分区为数据簇C的A1区(图5中浅灰表示),各自对应的候选分区环如图6所示.

4.2 KNN查询
我们设计了MapReduce框架下基于G-L索引的并行KNN查询方法,以图6中的Q1查询为例,KNN查询过程如图7所示.

5 实验结果与分析
5.1 实验环境
实验由4台HP刀片服务器搭建了一个内部网络,组成4个节点的Hadoop集群,其中 1 个节点作为 Master,其余3 个节点作为 Slave,网络内的各个节点通过100M网卡相互访问.Master节点服务器CPU:Inter(R) Xeon(R) E5620 2.4GHz 4*4核,Memory:8GB,Disk:300G*8.Salve节点服务器CPU:Inter(R) Xeon(TM) 3.00GHZ 4核,Memory:1GB,Disk:146.8G*2.每台服务器上安装OS:64bit CentOS6.2,Hadoop 版本1.0.3和Eclipse版本4.3.1.Hadoop默认参数配置block为64M,数据备份数为3.
由于没有合适规模的真实数据集,本文按照表2的数据格式生成了一批聚类数据,其中每类数据的基准维度为 20,所有值均为 0-10000之间的整数,以2000万条记录为标准,大约2G的数据量.

表2 数据格式
MapReduce框架下默认的分区划分是通过HashPartitioner类实现,HashPartitioner继承的是Partitioner类,是Mapper作业使用key的hashCode对数据进行均匀划分的方法.为了实现iPBM的分区划分,实验中利用eclipse向MapReduce框架源码中增加新的分区划分类,命名为BitCodePartitioner并继承Partitioner类,再修改MapReduce配置文件使默认分区方式指向BitCodePartitioner,使BitCodePartitioner代替HashPartitioner成为默认分区划分类,将修改后的MapReduce源码利用Ant Builder 进行重新打包编译成为新的MapReduce框架,即iPBM框架.
5.2 实验结果与分析
影响实验运行时间的因素有:数据规模、数据维度、查询K值、服务器数量等.因此,在研究某一因素对执行时间的影响时,需要保证其他因素固定不变,以保证实验数据的可靠性.由于本文中数据划分和索引构建是预处理过程,一次预处理可以为后续的多次查询提供服务,因此预处理时间未计入总时间.
5.2.1 数据规模变化对查询时间的影响
图8展示了数据维度为20维,K=20,集群节点数为4,数据规模分别为2千万、4千万、6千万、8千万、1亿、2亿条记录时,KNN查询执行时间的变化情况.从实验结果来看:当数据维度、K值、服务器数量等固定时,执行时间随着数据规模的增加而近似线性增长,即本文方法对数据规模的变化不敏感.通过分析可知iPBM设计的大规模高维数据预处理和索引机制,有效地抑制了查询时间随数据规模急剧增长.聚类预处理将相关数据分布在同一Salve上,使得查询操作集中在Map阶段而非Reduce阶段,从而避免了网络传输代价;分区预处理使得分区数据均匀分配到多个block中,这样可以充分利用Map任务在集群上分布式计算和任务处理能力;同时KNN查询通过双层索引实现了三级过滤过程进一步缩小实际需要搜索的范围,因此数据规模变化对查询时间的影响不大.

5.2.2 扩展性
从两个方面考察iPBM方法的扩展性:

(1)数据维度变化效果:图9 展示了数据规模为2千万,K=20,集群节点数为4,数据维度分别为10、20、30、40、50、100时,KNN查询执行时间的变化情况.
从实验结果来看:当数据规模、K值、服务器数量等固定时,执行时间随着数据维度的增加呈上升趋势且上升的幅度相对稳定,基本保持在43.7%的水平,未出现随着维度的增加计算时间大幅增加的情况.同时实验数据表明,随维度不断增大而查询时间增长放缓(从10维到50维,查询时间增长率分别为71.3%,56.8%,18.8%,7.8%),说明iPBM对高维数据具有很好的抗压性.在iPBM中使用了三层数据过滤技术,包括聚类、分区以及候选分区环,大大降低了数据搜索范围,同时利用数据位码索引值压缩表示形式,降低了高维向量距离计算代价,这是维度对查询时间影响不大的主要原因.特别需要说明的是,实验中为了降低MapReduce框架下数据传输代价的影响,我们通过调整Hadoop参数配置(如表3所示),使得在不同维度下数据划分的block数量尽量保持一致,这样实验结果更能反映维度变化对查询时间的影响.
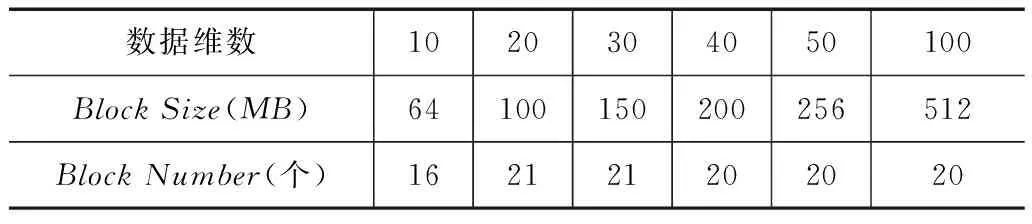
表3 不同数据维数下的Hadoop参数配置
(2)集群节点数量变化效果:图10展示了数据规模为2000万,维度为20,K=20,Slave节点数分别为3、6、9、12、15时,KNN查询执行时间的变化情况.从实验结果来看:当数据规模、数据维度、K值等固定时,执行时间随着服务器数量增加而减少的趋势很明显,平均降幅接近1/3.随着集群节点数量增多,通过iPBM方法将数据均分到更多的服务器上参与计算和任务处理,增大数据处理能力从而减少查询时间.
以上两个方面都说明了iPBM方法具有较好的可扩展性.

5.2.3 K值变化对查询时间的影响

图11展示了数据规模为2000万,维度为20,集群节点数为4,K值分别为10、20、30、40、50时,KNN查询执行时间的变化情况.从实验结果来看:当数据规模、数据维度、服务器数量等固定时,k值的变化对执行时间基本没有影响.分析可知iPBM在数据划分时将分区包含对象数量保持为K的数倍,使得每个分区的记录数足够满足KNN检索结果的需要,因此不同K值筛选出的候选分区和对应的block集合基本一致,即不同K值需要计算的数据基本相同,从而KNN查询消耗时间差距不大.
5.2.4 iPBM与非优化的MapReduce方法对比
(1)高效性:由于iPBM是在MapReduce框架下对数据划分做了优化处理,同时利用分布式双层索引提高查询效率.为了体现这些策略的优势,我们将iPBM与传统MapReduce模型的查询效率进行对比分析.图12 展示了数据维度为20维,K=20,集群节点数为4,数据规模分别为2千万、4千万、6千万、8千万、1亿、2亿条记录时,iPBM与未经任何优化处理的MapReduce模型的性能对比.从实验结果来看,同等条件下iPBM查询花费时间只有传统MapReduce模型的45.6%左右,效率提升的效果非常明显.充分说明iPBM采用的兼顾相关性和并行性的数据分块方式,较MapReduce默认的数据分块方式,能够更好地适应大规模数据应用环境.同时也说明了iPBM将高维向量转换为二维位码索引值降低了高维距离计算复杂性,以及双层索引机制大大缩小了搜索范围,这些策略对提升查询效率发挥了重要作用.

(2)准确性:iPBM是在MapReduce框架下修改了数据划分方式,为了验证新的划分方式下KNN查询结果的准确性,我们将iPBM与传统MapReduce模型进行了对比分析,图13展示了数据维度为20维,K=20,集群节点数为4,数据规模分别为2千万、4千万、6千万、8千万、1亿、2亿条记录时两者的准确度.由于非优化的MapReduce框架下KNN查询是对所有的数据进行全范围扫描,因此能够保障查询准确性.而从实验结果来看,同等条件下iPBM准确性与非优化MapReduce相当,这是因为iPBM在KNN查询时既考虑了单一簇范围内的结果查询,也考虑了跨簇范围下结果查询,不存在范围漏查的可能性,因此iPBM能够保证较高的查询准确性.

6 结束语
针对MapReduce数据和任务并行处理机制,提出了一种适用于MapReduce框架下的高维数据近似查询方法.针对大规模高维向量空间分布特点、近似查询需求以及MapReduce编程模式,设计了基于聚类和分区的数据划分优化策略,将整个数据集均匀划分到集群中各个数据块(block)并共同承担计算任务,有利于充分发挥MapReduce任务并行处理优势;基于划分思想构建分布式双层索引,全局索引位于Master节点上用于KNN查询时对候选数据簇的筛选,局部索引位于Slave节点上用于进一步确定候选分区和候选点对象,实现三层过滤过程大大缩小需要搜索的范围;同时利用二维位码索引值压缩高维向量表示以降低维数灾难影响.实验表明基于MapReduce编程模型的高维数据近似查询方法iPBM对查询效率具有明显的提升效果,同时具有良好的扩展性.本文的研究工作主要是针对高维数据集比较稳定,索引一次构建多次使用的环境,没有考虑索引更新维护代价.下一步需要研究在数据更新比较频繁的应用场景下,如何提升查询性能.
[1]黄震华.云环境下Top-n推荐算法[J].电子学报,2015,43(1):54-61.
Huang Zhenhua.Top-n recommendation algorithms for cloud data[J].Acta Electronica Sinica,2015,43(1):54-61.(in Chinese)
[2]李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
Li Jianjiang,Cui Jian,Wang Dan,et al.Survey of MapReduce parallel programming model[J].Acta Electronica Sinica,2011,39(11):2635-2642.(in Chinese)
[3]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Proceedings of Operating Systems Design and Implementation ,2004,51(1):107-113.
[4]Zhang C,Li F,Jestes J.Efficient parallel kNN joins for large data in MapReduce[A].Proceedings of the 15th International Conference on Extending Database Technology[C].ACM,2012.38-49.
[5]Doulkeridis C,Nφrvåg K.A survey of large-scale analytical query processing in MapReduce[J].Vldb Journal,2014,23(3):355-380.
[6]Vlachou A,Doulkeridis C,Nφrvåg K.Distributed top-k query processing by exploiting skyline summaries[J].Distributed & Parallel Databases,2012,30(3-4):1-33.
[7]Vlachou A,Doulkeridis C,Kjetil G,et al.On efficient top-k query processing in highly distributed environments[A].ACM Sigmod International Conference on Management of Data[C].ACM,2008.753-764.
[8]史英杰,孟小峰.云数据管理系统中查询技术研究综述[J].计算机学报,2013,36(2):209-225.
Shi Yingjie,Meng Xiaofeng.A survey of query techniques in cloud data management systems[J].Chinese Journal of Computers,2013,36(2):209-225.(in Chinese)
[9]Dittrich J,Quiané-Ruiz J A,Jindal A,et al.Hadoop++:making a yellow elephant run like a cheetah (Without It Even Noticing)[J].Proceedings of the Vldb Endowment,2010,3(12):518-529.
[10]Dittrich J,Quiané-Ruiz J A,Richter S,et al.Only aggressive elephants are fast elephants[J].Infection,2012,5(11):243.
[11]Eltabakh M Y,Tian Y,Zcan F,et al.CoHadoop:flexible data placement and its exploitation in Hadoop[J].Proceedings of the Vldb Endowment,2011,4(9):575-585.
[12]Zåschke T,Zimmerli C,Norrie M C.The ph-tree:A space-efficient storage structure and multi-dimensional index[A].Proceedings of the 2014 ACM Sigmod International Conference on Management of Data[C].ACM,2014:397-408.
[13]Wu S,Jiang D,Ooi B C,et al.Efficient B-tree based indexing for cloud data processing[J].Proceedings of the VLDB Endowment,2010,3(1-2):1207-1218.
[14]Wang J,Wu S,Gao H,et al.Indexing multi-dimensional data in a cloud system[A].Proceedings of the 2010 ACM Sigmod International Conference on Management of Data[C].ACM,2010:591-602.
[15]Ding L,Qiao B,Wang G,et al.An efficient Quad-Tree Based Index Structure for Cloud Data Management[M].Springer Berlin Heidelberg,2011.238-250.
[16]Lu W,Shen Y,Chen S,et al.Efficient processing of k nearest neighbor joins using mapreduce[J].Proceedings of the VLDB Endowment,2012,5(10):1016-1027.
[17]Doulkeridis C,Nφrvåg K.On saying enough already in MapReduce[A].Proceedings of the 1st International Workshop on Cloud Intelligence[C].ACM,2012:7.
[18]刘义,景宁,陈荦,等.MapReduce框架下基于R-树的k-近邻连接算法[J].软件学报,2013,24(8):1836-1851.Liu Yi,Jing Ning,Chen Luo,et al.Algorithm for processing k-nearest join based on R-tree in MapReduce[J].Journal of Software,2013,24(8):1836-1851.(in Chinese)
[19]Liu Yi,Jing Ning,Chen Luo,et al.Parallel bulk-loading of spatial data with MapReduce:An R-tree case[J].Wuhan University Journal of Natural Sciences,2011,16(6):513-519.
[20]乔玉龙,潘正祥,孙圣和.一种改进的快速k-近邻分类算法[J].电子学报,2005,33(6):1146-1149.
Qiao Yulong,Pan Zhengxiang,Sun Shenghe.Improved K nearest neighbors classification algorithm[J].Acta Electronica Sinica,2005,33(6):1146-1149.(in Chinese)
[21]付宁,乔立岩,彭喜元.基于改进K-means聚类和霍夫变换的稀疏源混合矩阵盲估计算法[J].电子学报,2009,37(4):92-96.
Fu Ning,Qiao Liyan,Peng Xiyuan.Blind recovery of mixing matrix with sparse sources based on improved K-means clustering and hough transform[J].Acta Electronica Sinica,2009,37 (4):92-96.(in Chinese)
[22]杨静,赵家石,张健沛.一种面向高维数据挖掘的隐私保护方法[J].电子学报,2013,41(11):2187-2192.Yang Jing,Zhao Jiashi,Zhang Jianpei.A privacy preservation method for high dimensional data mining[J].Acta Electronica Sinica,2013,41(11):2187-2192.(in Chinese)

梁俊杰 女,1974年出生,湖北武汉人.教授、硕士生导师、CCF会员.研究方向为大数据、高维索引、数据库管理系统.
E-mail:ljjhubu@163.com

李凤华(通信作者) 男,1966年生,湖北浠水人,博士,中国科学院信息工程研究所副总工、研究员、博士生导师,研究方向为网络与系统安全、隐私保护、可信计算.
E-mail:lfh@iie.ac.cn
Optimized High-Dimensional Index and KNN Query in MapReduce
LIANG Jun-jie1,LI Feng-hua2,3,LIU Qiong-ni1,YIN Li1
(1.DepartmentofComputerScienceandTechnology,HubeiUniversity,Wuhan,Hubei430062,China;2.StateKeyLaboratoryofInformationSecurity,InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093,China;3.BeijingElectronicScience&TechnologyInstitute,Beijing100070,China)
To address the low efficiency problem caused by the approximate large-scale high-dimensional data query,we propose a novel high-dimensional index and KNN query method,called iPBM,which exploits two main problems,including the optimal division on the MapReduce’s data block and their contributions to the computing.Specifically,based on the principles of relativity and parallelity,iPBM employs a two-phase partitioning scheme of clustering and zoning to equally split the data to the available blocks,then we design a distributed two-layer index structure and parallel KNN query algorithm.With fully considering the global index,local index and two-dimensional bitcode property,iPBM achieves triple-layers filtering,and thus the number of queried area and the computing cost on the high-dimensional data is minimized.The accuracy,efficiency and scalability of the proposed iPBM are thoroughly evaluated via detailed simulations.
cloud;MapReduce;KNN query;high-dimensional index
2014-12-31;
2015-11-08;责任编辑:诸叶梅
国家发改委2012年信息安全专项(No.发改办高技[2013]1309);国家自然科学基金(No.61170251);湖北省自然科学基金重点项目(No.2013CFA115);武汉市科技攻关计划(No.2013012401010851)
TP301
A
0372-2112 (2016)08-1873-08
