基于Hadoop的海量数据存储技术的研究
2016-11-03袁丽娜
袁丽娜
【摘要】 随着社会信息化程度的不断提高,传统的数据存储技术已经不能满足需求。本文基于Hadoop平台,对其海量存储技术进行了专门研究分析,从海量数据存储的容错性、可扩展性和延迟性、实时性、性能等四个方面对目前海量数据存储技术进行了分析评价。
【关键词】 Hadoop 海量数据处理 分布式存储技术
引言
随着社会信息化程度的不断提高,互联网应用的多元化及快速发展,传统的数据存储技术在处理能力和存储容量的可扩展性已经不能完全满足需求。如今大数据时代下的海量数据存储出现了新的特点:(1)数据规模巨大,且增长快速。(2)访问并发程度高。(3)数据结构及处理需求的多样化。在线数据访问和离线数据分析的应用,对系统可靠性的要求也越来越高。在这种情况下,基于Hadoop的分布式存储技术应运而生。
一、Hadoop概述
1.1 简介
随着海量数据的不断快速增长,各大公司纷纷对其相关技术进行研究。Google在开发了MapReduce、GFS和BigTable等技术之后,开源组织Apache模仿并发布了开源的Hadoop分布式计算框架和分布式文件系统。
Hadoop是一个开源的分布式计算平台,其核心是分布式计算框架MapReduce和分布式文件系统HDFS,主要用于处理海量数据,能在大量计算机组成的集群中运行海量数据并进行分布式计算。
1.2 体系结构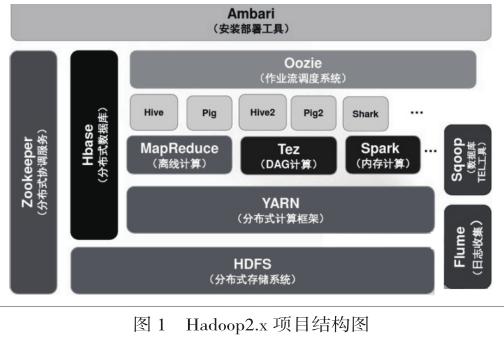
Hadoop主要设计用来在由通用计算设备组成的大型集群上执行分布式应用的框架。经过多年的发展,逐步形成了其应用程序生态系统,以Hadoop2.x版本为例,其族群中包括很多子项目:分布式文件系统HDFS、分布式并行编程模型和程序执行框架MapReduce、资源管理器YARN、配置管理工具Ambari、分布式且按列存储的数据库Hbase、数据仓库Hive、数据流语言和运行环境Pig、数据挖掘Mahout、分布式且可用性高的协调服务ZooKeeper、关系型数据库同步工具Sqoop、日志收集工具Flume等,其中MapReduce和HDFS最重要,在核心层上提供了更高层的互补性服务。Hadoop2.x的项目结构如图1所示。
MapReduce是一种简化并行计算的编程模型,用来解决大规模数据处理的问题。其主要思想是将需要自动分割执行的任务拆解成映射Map和简化Reduce的方式。Map主要负责把单个任务分解成多个任务,Reduce则负责把分解后的多任务处理结果进行汇总。MapReduce任务由一个JobTracker节点和多个TaskTracker节点控制。JobTracker主要负责和管理TaskTracker,而TaskTracker具体负责这些任务的并行执行。
HDFS分布式文件系统可以和MapReduce编程模型很好地结合,用于存储海量数据。HDFS采用主从模式的结构,HDFS集群由一个名字节点NameNode和若干个数据节点DataNode所组成。NameNode是主服务器,主要负责管理文件系统的命名空间和客户端对文件的访问操作,而DataNode主要负责节点数据的存储。
YARN是Hadoop 2.x中新引入的资源管理系统,它的引入使得Hadoop不再局限于MapReduce一类计算,而是支持多样化的计算框架。它由两类服务组成,分别是ResourceManager和NodeManager。
二、海量数据存储技术研究
分布式文件系统HDFS是Hadoop的核心技术之一,是基于Hadoop的分布式存储架构中数据存储的基础。Hadoop2. x中HDFS体系结构如图2所示。
接下来,本文基于Hadoop的海量数据存储技术,从容错性、可扩展性和延迟性、实时性以及性能这4个方面对海量数据存储技术进行研究分析。
2.1海量数据存储的容错性
目前海量数据存储系统中,为获取较高可靠性,通常使用完全的数据复制技术和磁盘冗余阵列技术(RAID)两种冗余容错方法。RAID 技术在传统关系数据库及文件系统中应用比较广发,但不太适用于NoSQL数据库及分布式文件系统。
Hadoop使用HDFS存储海量数据。文件通常被分割成多个块进行存储,每个块至少被复制成三个副本存储在各个数据节点中。HDFS可以部署在大量廉价的硬件上,因此一个或多个节点失效的可能性很大,所以HDFS在设计时采用了多种机制来保障其高容错性,但有些也存在着一些问题。
1、HDFS中NameNode
NameNode是HDFS集群中的主节点,也是中心节点,它的可靠性直接关系到整个集群的可靠性。对于不同版本的Hadoop对此也有不同的处理机制。Hadoop1中只有一个NameNode节点,所以存在单节点故障问题,而在Hadoop2.x中通过HA策略大致解决了NameNode的单点问题。即存在两个NameNode,一个是状态为活动的 active namenode,另一个是状态为停止的standy namenode,两者可以进行切换,但是有且只有一个属于活动状态。目前,Hadoop 2.x中提供了两种HA方案,一种是基于NFS共享存储的方案。此方案中,NFS作为active namenode和standy namenode之间数据共享的存储,但若active namenode 或者standy namenode中有一个和nfs之间发生网络故障,将会造成数据同步不一致。另一种是基于Paxos算法的方案Quorum Journal Manager(QJM),它的基本原理就是用2N+1台JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据即不会丢失,可以实现namenode单点故障自动切换。
2、HDFS数据块副本机制
HDFS中一个文件由多个数据块组成,每个数据块包含多个副本,副本的数量可以通过参数设置。副本是一种能够提高数据访问效率和容错性能的技术。Hadoop在数据存储方面可以自动将数据保存到不同机架的多个副本中,在数据计算方面也可以自动将失败的任务重新分配到其他的节点上。Hadoop2.x版本对于数据副本存放磁盘选择策略有两种方式,一种是低版本中的磁盘目录轮询方式,另外一种是选择可用空间足够多的磁盘方式。
3、HDFS心跳机制
HDFS中的NameNode通过心跳机制掌握整个集群的工作状态。DataNode通过周期性向NameNode发送心跳信息,即NameNode通过DataNode的心跳信息来获知DataNode的存在、其上的磁盘容量、已用剩余空间和负载等信息。
2.2海量数据存储的可扩展性和延迟性
可扩展性和延迟性是分布式文件系统评判性能的两个重要指标。Hadoop 的HDFS 分布式文件系统的设计主要用于处理大文件,以流式方式访问数据,一次写入,多次读写。对于HDFS,读取整个数据集要比读取一条记录更加高效。所以HDFS不合适处理处理小文件,即大小小于HDFS块大小的文件。这样的小文件会给Hadoop的扩展性和性能带来严重问题。因为并行的I /O 接口并不支持小文件的处理,所以读写延迟时间比较长,且主节点很难在云存储系统中进行扩展。因此,文献[1]提出了一种基于混合索引的HDFS小文件存储策略,采用应用分类器分类标记小文件,在存储节点根据小文件大小建立不同的块内索引,用以提高小文件访问效率。文献[2]提出一种基于多维列索引的小文件管理方案,且提出了小文件合并方案。文献[3]提出了一种面向低延迟的内存HDFS数据存储策略,提出了基于HDFS的内存分布式文件系统架构Mem-HDFS,且利用集群数据节点的内存和磁盘存储数据,并提出一种并行读取算法,该算法能较好降低读取访问延迟。
经研究发现,现有的对分布式文件系统处理海量小文件中所遇到的瓶颈问题,其改进大致包括以下两种方式,第一种方式是通过建立索引的方式,把小文件合并成大文件;第二种方式是建立缓存机制,从而减少文件访问次数。
2.3海量数据存储的实时性
Hadoop 最初被设计为解决大量数据离线情况下批量计算的问题,是为了处理大型数据集分析任务的,是为了达到高的数据吞吐量,因此,需要延迟性作为代价。对于大多数反馈时间要求不是特别高的应用,比如离线统计分析、机器学习、推荐引擎的计算等,都可以采用Hadoop进行离线分析的方式。基于Hadoop 的分布式文件系统能够很好地完成海量数据存储的要求,但还是缺乏了实时文件获取的考虑。因此,海量数据存储的实时性还有待提高,目前主要通过和传统关系型数据库相结合,实现其实时性。文献[4]提出了一种自定义的内存处理引擎,通过把基于Hadoop 的分析平台和数据流处理引擎进行结合,实现海量数据环境下实时处理数据的构想。
2.4海量数据存储的性能
HDFS在选择数据存放节点时,并没有考虑到集群中各数据节点的性能、网络状况和存储空间的差异性,从而很容易造成集群整体负载不均衡,数据节点的资源不能合理利用等。因此,文献[5]提出了确定环境下多阶段多目标CMM决策模型,此模型以内存、CPU和磁盘的剩余负载能力作为决策条件,以负载均衡效果、数据传输代价和负载迁移代价作为决策目标,根据决策节点间的影响关系来构建有向无环图,通过多个决策阶段的决策及计算方案效果来确定最优均衡方案。
三、结束语
本文针对最新Hadoop框架下的海量数据存储技术,分别从海量存储技术的容错性、可扩展性和延迟性、实时性及性能等四个方面进行了深入的研究,分析概括了目前Hadoop的分布式文件系统在存储海量数据时所遇到的一些问题及挑战,并对现有的存储改进方式进行了综述。
在海量数据存储的容错方面,目前Hadoop2.x最新版本的HA策略已经解决了NameNode的单点问题,但新引入的YARN同样存在单点故障及性能问题,对于HDFS如何能更高效更好地动态分配数据块副本机制,相关文献提出了多目标优化的局部最佳副本分布策略,提出了基于范德蒙码的HDFS分散式动态副本存储优化策略;在海量数据的可扩展性和延迟性方面,主要是小文件的存储策略问题,相关文献主要提出采用索引方式将小文件合并为大文件进行读取,通过缓冲机制减少访问次数;海量数据存储的实时性方面,目前主要通过和传统关系型数据库相结合,通过缓存机制实现实时读取;在海量数据存储的性能方面,主要是负载均衡问题,相关文献主要提出通过采集数据节点的各方面负载,通过计算成本来选择最优数据节点存储[9]。
目前,基于Hadoop的海量存储技术在如何高效存储及读取小文件,如何实现数据的实时分析,数据节点的负载均衡问题等方面依旧是将来研究的热点。
参 考 文 献
[1]王海荣等. 基于Hadoop的海量数据存储系统设计[J].科技通报,2014.30(9):127-130
[2]尹颖等. HDFS中高效存储小文件的方法[J]. 计算机工程与设计,2015.36(2):406-409
[3]英昌甜等. 一种面向低延迟的内存HDFS数据存储策略[J]. 微电子学与计算机,2014.31(11):160-166
[4]张柄虹等. 空间高效的分布式数据存储方案[J].计算机应用研究,2015.32(5):1508-1511
[5]卢美莲等. 基于CMM模型的HDFS负载均衡策略[J]. 北京邮电大学学报,2014.37(5):20-25
