基于多特征匹配和Bloom filter的重复数据删除算法
2016-10-21张宗华叶志佳牛新征
张宗华,屈 英,叶志佳,牛新征
1)国家电网公司北京电力医院信息通讯部,北京 100073;2)电子科技大学计算机科学与工程学院,四川成都 611731

基于多特征匹配和Bloom filter的重复数据删除算法
张宗华1,屈英2,叶志佳2,牛新征2
1)国家电网公司北京电力医院信息通讯部,北京 100073;2)电子科技大学计算机科学与工程学院,四川成都 611731
针对EB(extreme binning)算法重复数据删除率低,磁盘I/O开销大的缺陷,提出基于多特征匹配和Bloom filter的重复数据删除算法DBMB(deduplication based on multi-feature matching and Bloom filter). 将小文件聚合为局部性文件单元,作为一个整体进行去重处理,采用最大、最小以及中间数据块ID的多重相似性特征进行匹配,并基于Bloom filter优化磁盘数据块的查找和匹配过程. 结果表明,DBMB算法能有效提升重复数据删除率,降低算法执行时间,同时减少处理小文件的内存开销,性能提升显著.
计算技术;重复数据删除;多特征匹配;布隆过滤器;EB算法;磁盘优化
重复数据删除(deduplication)是一种能有效优化存储空间、提高存储效率的技术,目前被广泛应用于数据备份和归档系统中. 在基于数据块的重复数据删除技术中,索引的内存占用量和运行效率是影响系统性能的关键. EB(extreme binning)是Bhagwat等[1]提出的一种可扩展的数据块级去重技术,能较好地缓解内存占用问题. EB算法基于数据流的相似性,通过建立和维护文件的代表块(representative chunk)指纹索引,并将文件主体在磁盘中以指纹容器(bin)保存. 由于EB算法只在内存中保存文件的代表块ID,且对于每个文件的备份至多只需访问一次磁盘,有效减小了内存占用以及磁盘的访问时间. 然而,传统的EB算法采用文件的最小块ID作为主索引,实质是牺牲部分重复删除率来获取低内存占用,其去重率相对较低. 为此,张志珂等[2]提出一种基于相似哈希的二级索引结构,以相似哈希计算文件指纹,提高了小文件的重复数据删除率. 但相似哈希只适用于处理文档数据,很难满足实际应用场景中复杂多样的文件类型. Xia等[3]提出一种重复数据删除算法SiLo,该算法通过聚合强关联文件为一个数据段,挖掘数据段间的数据相似性,同时结合数据流的局部性特征,以此提高文件重删率,然而该算法对数据段大小较敏感,选取合适的段长度较困难.
EB算法的另一个缺陷是,虽然对于每个备份的文件至多需要访问一次磁盘,但其访问磁盘时采用顺序遍历的方式,当磁盘中存储的指纹容器较大时,遍历所需时间较长. Zhang等[4]对EB算法进行拓展,提出一种wWrR策略,通过同时访问和更新多个磁盘数据块和指纹,降低总的I/O操作次数,然而该算法未能优化磁盘数据块的查找和匹配过程,导致时间开销仍较高.
针对上述EB算法的缺陷,本研究提出了基于多特征匹配和Bloom filter(布隆过滤器)的重复数据删除算法——DBMB(deduplication based on multi-feature matching and Bloom filter). 针对传统EB算法去重率较低,且小文件对内存占用影响较大的问题,通过聚合局部小文件为一个文件单元,采用多特征匹配进行重复数据删除处理;同时针对EB算法遍历磁盘中指纹容器耗时较多的缺陷,采用Bloom filter对每个存入磁盘的数据块进行记录,查询时只需通过Bloom filter再次计算即可,有效降低了磁盘查询时间. 在两个真实数据集上进行测试,结果显示相较于EB,DBMB能降低对小文件的内存开销,并有效提高重复数据删除率和算法运行效率.
1 DBMB算法
为了解决EB算法去重率较低以及磁盘访问开销较高的问题,本研究提出DBMB算法,主要改进思路如下:
1) 聚合多个小文件为局部文件单元,并对文件单元进行去重处理,提高对小文件的去重率;
2) 提出一种多特征匹配策略,选取文件的最大块、最小块以及中间块进行匹配,若均不同才认为两文件完全不同;否则表明存在相似部分,进行去重处理;
3) 采用Bloom filter,记录和维护磁盘中数据块的存储状态,使算法执行过程中无需读取磁盘数据,有效减少磁盘I/O开销.
1.1小文件聚合及多特征匹配
在典型的存储系统中,小文件(一般小于64 kbyte)所占物理空间为20%左右,其文件数目却高达总数的80%,在采用传统的EB算法去重时,内存开销大而去重效果较差. 为此,本研究提出聚合小文件为局部性文件单元,将其作为一个整体进行重复数据删除. 具体而言,对于在顺序存储的小文件(例如存储在同一个文件夹下),通过聚合成局部性文件单元,将多个小文件作为一个整体进行重复数据删除,减少小文件在主索引中的记录条数,最终使小文件的内存开销得以降低.
为了改善EB算法去重率较低的缺陷,本研究提出一种多特征匹配的文件相似性检测策略. 对于一个新文件,计算所有数据块指纹,并选取具有最大、最小以及中间特征指纹值的数据块与主索引中已有记录进行匹配. 若存在匹配成功的指纹,则可判定新文件与已存储的文件存在相同的数据块,进行去重处理. 只有当所有特征都不匹配时,才判定该文件不存在重复数据块,在主索引中增加一条对该文件的描述记录,分别存储代表块特征指纹,并将文件的其他数据块存入磁盘. 根据Broder理论[5],两个文件的最小数据块指纹相同的概率为
(1)
其中, F1和F2是两个以数据块集合表示的文件; H(x)是哈希函数. 同理,两文件的最大块和中间块指纹相同的概率也有类似结论. 由式(1)可以看出,由于采用了最小块、最大块以及中间块指纹进行特征匹配,所以理论上本研究的多特征匹配策略相较于只采用最小块匹配的EB算法,在去重率方面具有更好的性能.
1.2基于Bloom filter的磁盘数据块去重
由于EB算法对磁盘数据块去重时,需要遍历磁盘中的指纹容器,这会造成大量的I/O开销. 为此,本研究通过建立和维护一个Bloom filter,当数据块存入磁盘时,记录相应状态位;当需要查询磁盘中是否存在相同数据块时,只需通过再次计算状态位的值即可,避免了将磁盘的指纹容器读入内存. 算法添加和查询一个元素的时间复杂度均为O(k)(k为哈希函数个数),大大提高了访问磁盘的时间效率.
在判断一个元素是否已存在时,Bloom filter会有一定的误检率(false positive rate),所以需要根据数据块集合的大小,选择合适的哈希函数个数k和位数组长度m. 误检率的计算公式为
f=(1-e-kn/m)k
(2)
令p=e-kn/m, 则有lnf=kln(1-p)=-(m/n)lnpln(1-p), 由对称性法则可知,当p=1/2即k=(m/n)ln2时,误检率f取得最小值. 同时,当给定误检率的上限φ时,位数组长度m需满足
(3)
由式(3)可见,当已知文件数据块数量n以及系统的误检率上限φ时,就能相应地计算出最佳的位数组长度m以及哈希函数个数k. φ一般根据经验来确定,本研究取0.01%.
基于前文所述,改进的算法主索引结构如图1. 其中最大、最小以及中间块ID作为文件的代表ID进行多特征匹配,位数组用于Bloom filter记录磁盘数据块的存储状态,文件指针则用于连接主索引记录与磁盘指纹容器.

图1 改进的主索引结构Fig.1 Structure of improved primary index
1.3DBMB算法流程
DBMB算法伪代码如图2,对于给定的源文件夹和目标文件夹,图2中第4~7行算法首先对小于64 kbyte的小文件进行聚合,并采用基于内容的分块算法(content-defined chunking,CDC)[6]对文件进行变长分块,随后基于MD5信息摘要算法计算数据块指纹. 第7行算法选取最大、最小以及中间块ID(MD5值)作为文件代表块ID,并进行文件的多特征匹配. 第8~16行,若在主索引中找到该代表ID,则表明已存储了相似的文件,采用Bloom filter对磁盘中的数据块进一步匹配,并存储不同的数据块;否则,直接将所有数据块存储.

算法:DBMB(sourceFolder,targetFolder)输入:源文件夹sourceFolder,目标文件夹targetFolder输出:主索引primaryIndex1.initializeprimaryIndex;//初始化主索引2.readfilefromsourceFolder;//读取文件3.forallfilei∈sourceFolderdo4. iffilei.size()<=64kbyte5. mergesmallfiles;//聚合小文件6. chunkFile=CDC(filei);//文件分块7. chunkID=MD5(filei);//计算数据块的MD5值8. findrepresentIDfromchunkID;9. iffindrepresentIDfromprimaryIndex//找到代表块ID10. forallchunkIDi∈chunkIDdo11. iffindchunkIDi12. bloomFilter.insert(chunkIDi);13. bin.insert(chunkIDi);14.else//未找到代表块ID15. bloomFilter.insert(chunkID);16. bin.insert(chunkID);17.writebinfiletotargetFolder;18.returnprimaryIndex
图2DBMB算法伪代码
Fig.2Pseudo code of DBMB
2 实验测试与分析
本研究通过实验评估DBMB算法的去重性能,主要从重复数据删除率(去重率)、算法执行时间以及算法的内存开销3个维度测试,其中去重率定义为原始数据量与存储数据量之比,内存开销定义为处理1 Mbyte数据所需的内存. 实验采用Linux Kernel Archives数据[7]和某公司真实的运维数据,其数据集特征如表1. 本研究在Linux系统下实现了DBMB算法,硬件环境为2.4 GHz四核处理器,4 Gbyte内存,500 Gbyte硬盘.
首先初始化Bloom filter的相关参数,由存储备份系统的统计经验,每个指纹容器的元素数目一般不超过1 000,同时Bloom filter的误检率取0.01%,则由式(3)可计算出最小的数组长度m为2 500字节,哈希函数个数k=(m/n)ln2=14.
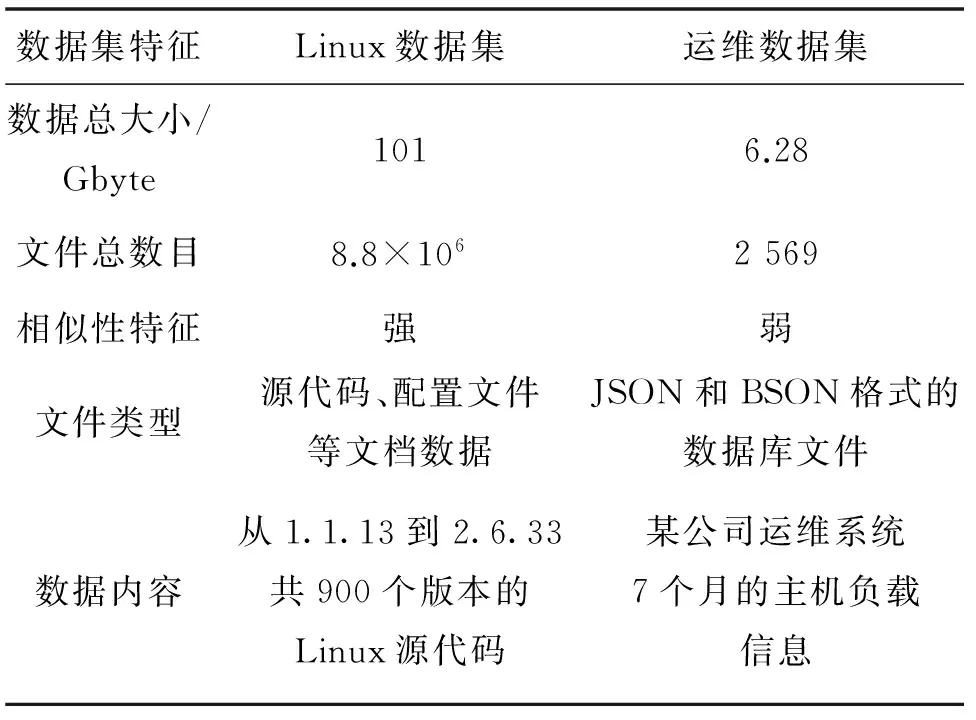
表1 测试数据集特征
2.1Linux数据集实验
对于Linux数据集,传统EB算法和DBMB算法重复数据删除后的存储空间变化如图3(a). 图3(a)中横坐标表示内核代码版本,实验中是从1.1.13到2.6.33顺序排列;纵坐标表示占用的存储空间. 由图3(a)可见,在前350个版本的去重中,DBMB算法和EB算法的去重效果相差不大,这是因为前期版本改动相对较小,文件重复率较高. 但随着数据量的进一步增大,DBMB算法展现出了多特征匹配的优势,对相似度较低的文件也能检测出重复数据块. EB算法处理的数据最终占用空间为7.69 Gbyte,去重率为13.13∶1.00;而DBMB算法占用的存储空间为5.64 GB,去重率为17.91∶1.00,相比前者提高了36.41%.
DBMB算法和EB算法在Linux数据集上的执行时间如图3(b). 从图3(b)可以看出,当数据量较小时,两个算法的执行时间增长较慢. 而随着数据量的增大,指纹容器中的元素个数也相应增多,对磁盘中数据的匹配成为EB算法的瓶颈,其算法执行时间陡增. 对于DBMB算法,由于其采用了Bloom filter优化磁盘去重过程,添加和查询操作的时间复杂度均为O(k),其算法执行时间不受数据规模的影响,故保持缓慢增长. EB算法最终执行时间为125.47 s,而DBMB算法为76.54 s,相较于前者性能提升了38.99%.
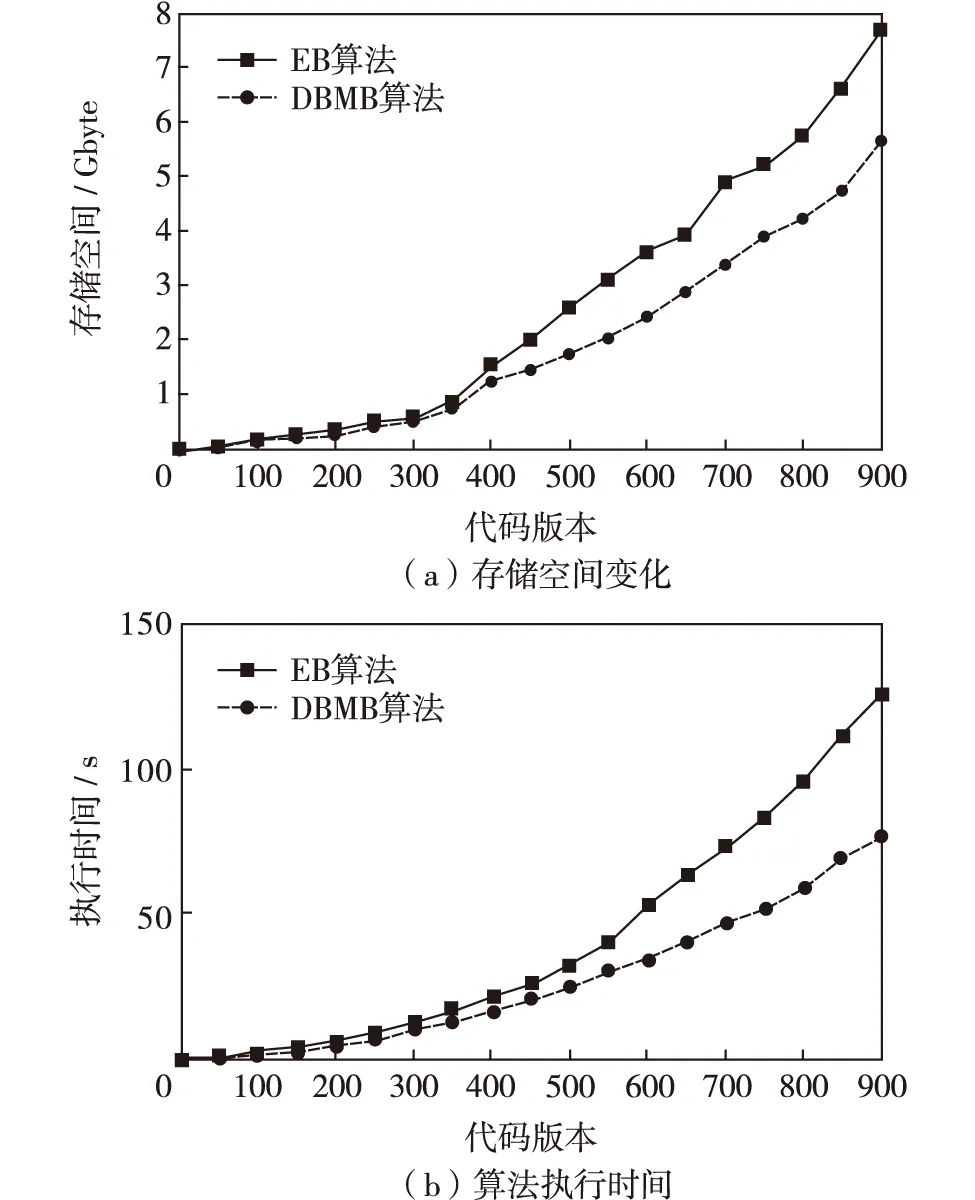
图3 Linux数据集实验结果Fig.3 Results of Linux data set
2.2运维数据集实验
分别采用EB算法和DBMB算法对运维数据集进行重复数据删除,实验结果与Linux数据集相似,最终实验结果如图4. 其中EB算法去重后的数据为761.38 Mbyte,去重率为8.44∶1.00,算法执行时间为16.84 s;而DBMB算法处理后的数据为537.78 Mbyte,去重率为11.95∶1.00,算法执行时间为12.05 s. DBMB算法的去重率和运行效率比EB算法分别提升了41.59%和28.44%.
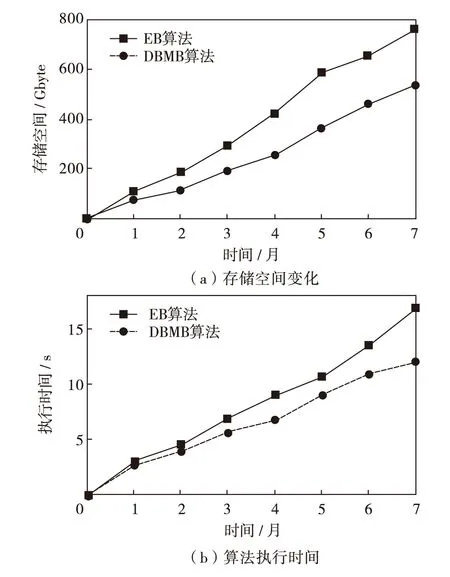
图4 运维数据集实验结果Fig.4 Results of operational data set
图5展示了EB算法和DBMB算法在对两个数据集去重的内存开销. 由于Linux数据集小文件较多,所以DBMB算法聚合小文件的策略在一定程度上减小内存占用量. 而对于运维数据集,由于其主要是大文件,故DBMB算法的内存开销与EB算法基本持平.
由上述两个数据集的测试结果可知,本研究提出的基于多特征匹配和Bloom filter改进的EB算法比传统EB算法具有更高的去重性能和更快的时间效率,且对于小文件占主导的存储系统能有效减小内存开销.
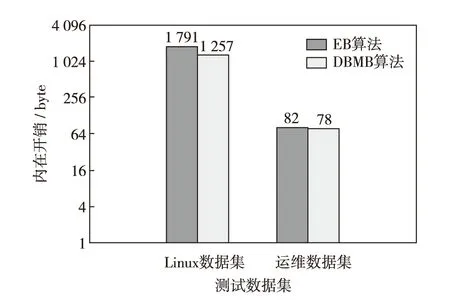
图5 EB和DBMB的内存开销Fig.5 Memory overhead of EB and DBMB
结 语
针对传统EB算法去重率较低以及磁盘数据匹配吞吐率较低的缺陷,提出聚合小文件为局部性单元,并基于最大块、最小块以及中间块的多特征匹配策略,提高重复数据删除率;同时采用Bloom filter记录和维护指纹容器中的数据,有效提高了磁盘数据匹配的时间效率. 实验结果表明,本研究提出的DBMB算法的去重率和执行时间均优于传统EB算法,且对小文件去重时具有较低的内存开销.
/
[1] Bhagwat D, Eshghi K, Long D D E, et al. Extreme binning: scalable, parallel deduplication for chunk-based file backup[C]// IEEE International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems.Dresden, Germany: IEEE, 2009: 1-9.
[2] 张志珂, 蒋泽军, 蔡小斌,等. 相似索引:适用于重复数据删除的二级索引[J]. 计算机应用研究, 2013, 30(12):3614-3617.
Zhang Zhike, Jiang Zejun, Cai Xiaobin, et al. Similar index: two-level index used for deduplication[J]. Application Research of Computers, 2013, 30(12):3614-3617.(in Chinese)
[3] Xia Wen,Jiang Hong,Feng Dan,et al.SiLo:a similarity-locality based near-exact deduplication scheme with low RAM overhead and high throughput[C]// USENIX Annual Technical Conference. Compton, USA: USENIX Association, 2011:26-28.
[4] Zhang Zhike, Bhagwat D, Litwin W, et al. Improved deduplication through parallel binning [C]// IEEE the 31st International Performance Computing and Communications Conference. Ottawa, Canada: IEEE, 2012: 130-141.
[5] Broder A Z. On the resemblance and containment of documents[C]// Compression and Complexity of Sequences. Atlanta, USA: IEEE, 1997: 21-29.
[6] 付印金, 肖侬, 刘芳. 重复数据删除关键技术研究进展[J]. 计算机研究与发展, 2012, 49(1):12-20.
Fu Yinjin, Xiao Nong, Liu Fang. Research and development on key techniques of data deduplication[J]. Journal of Computer Research and Development, 2012, 49(1):12-20.(in Chinese)
[7] Linux Kernel Organization. The Linux Kernel[DB/OL]. Compton, USA: Linux Kernal Organization[2016-05-12].https://www.kernel.org/.
【中文责编:坪梓;英文责编:子兰】
2016-08-12;Accepted:2016-09-05
Deduplication based on multi-feature matching and Bloom filter
Zhang Zonghua1, Qu Ying2, Ye Zhijia2, and Niu Xinzheng2†
1)Ministry of Information and Communication, Beijing Electric Power Hospital, State Grid Corporation of China, Beijing 100073, P.R.China 2)School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu 611731, Sichuan Province, P.R.China
Aiming at low deduplication rate and high disk I/O overhead of EB (extreme binning), we propose a deduplication algorithm based on multi-feature matching and Bloom filter (DBMB). Firstly, we group small files as a local file unit in order to process them as a whole. Then we take the maximum, minimum and middle ID of data chunk for similarity matching. Finally, we optimize the process of searching and matching disk data blocks based on Bloom filter. The experiment results show that DBMB algorithm can effectively increase the deduplication rate and reduce the execution time. In the meantime, DBMB reduces the memory overhead of small files deduplication, the comprehensive performance is improved significantly.
computing technology; deduplication; multi-feature matching; Bloom filter; extreme binning; disk optimization
Zhang Zonghua,Qu Ying,Ye Zhijia,et al.Deduplication based on multi-feature matching and Bloom filter[J]. Journal of Shenzhen University Science and Engineering, 2016, 33(5): 531-535.(in Chinese)
TP 301.6
Adoi:10.3724/SP.J.1249.2016.05531
国家自然科学基金资助项目(61300192);中央高校基本科研业务费资助项目(ZYGX2014J052);北京电力医院一体化运维监控与管理资助项目
张宗华(1977—),男,国家电网公司北京电力医院工程师. 研究方向:电力信息化.E-mail:zhang.zonghua@nc.sgcc.com.cn
Foundation:National Natural Science Foundation of China (61300192); Fundamental Research Funds for the Central Universities (ZYGX2014J052); Integration of Operational Monitoring and Management Project of Beijing Electric Power Hospital
† Corresponding author:Associate professor Niu Xinzheng.E-mail: xinzhengniu@uestc.edu.cn
引文:张宗华,屈英,叶志佳,等.基于多特征匹配和Bloom filter的重复数据删除算法[J]. 深圳大学学报理工版,2016,33(5):531-535.
