我国能源消费总量控制问题的研究
2016-10-13殷健
殷健
(安徽财经大学 商学院,安徽 蚌埠 233041)
我国能源消费总量控制问题的研究
殷健
(安徽财经大学 商学院,安徽 蚌埠 233041)
针对现实中很难及时监督和考核各省份落实能源消费总量控制目标的情况的问题。利用我国能源消耗量的数据,建立综合评价、回归分析和模糊聚类的数学模型,得出了适当的优化产业结构,和提高各省自身的资源禀赋,结合周围省份的能源优势,统一调度,合理分配并使用能源,同时提出了各省能源分配的方案。
能源消耗;综合评价法;模糊聚类;回归分析;MATLAB
能源是推动经济社会发展必要的物质动力,能源对于经济发展具有不可撼动的地位。经济快速发展不仅可以提高人民生产生活水平,而且会导致能源过度消耗,一旦其超过一定数额,资源和环境便无法承受,不利于实现经济社会协调可持续发展。因此,经济发展速度和能源消耗数额都应保持一定平衡,不能过快也不能过慢。
近年对控制能源消耗问题的研究,主要通过全面系统的论述来分析问题并适当结合国际经验来完善问题的研究。十二五开年,各地区定制的经济发展目标均高于中央的7%的总体增长目标,这必然会加大对能源消费需求的压力。研究发现,能源消费总量将大大超过总控制目标值[1]。张颖提出应以转变发展方式为重要契机,充分发挥价格机制作用,利用价格调控能源使用的效率和控制能源消耗总量,优先发展可再生能源,可持续发展绿色能源,降低污染,并大力优化产业结构和布局,有效的产业结构利于能源结构的构建,最后要尽快制定出与节能考核指标相协调的能源控制结构[2]。同时结合国际研究控制能源消耗的检验,总结出总量控制目标,政策由政府督导,方式由市场导向,在确定以化石能源为主的总量控制对象后,建立总量控制目标,分解到各地区能源控制目标上,从而倒逼经济发展方式[3]。
目前学术界关注的控制能源消费总量方式主要体现在价格工具,提高能源效率,劝诱技术和配额等[4]。这些方法的后续研究,学术界并没有统一的定论。且在单一地区的控制能源消耗的判定研究上,一些研究从省域出发,如王斌、赵敏,却很少有一个统一的控制能源消耗的模型来衡量各省份控制目标的实现状况。本文旨在探究优化产业结构的方法,并通过调控各地区的资源禀赋和国内生产总值的变化来控制影响能源消耗的总量,最后提出各省份能源分配的方案,督促各省完成产业结构的改革和实现能源的循环调配。
1 基于模糊均值聚类的能源消费评估
需要构建的综合评价模型,属于多层次、多维度、综合性能高聚类效果强的评价结构体系,根据指标的分类汇总,对现有的数据进行筛选处理,构建以煤炭消费量、焦炭消费量、原油消费量、汽油消费量、煤油消费量、柴油消费量、燃料油消费量、天然气消费量和电力消费量这九种指标为框架的综合评价模型,运用模糊聚类分析的方法,判别分析所选面板数据的类型。实验数据来源于2014年第十一届五一数学建模联赛题[5]。
1.1数据处理
(ⅰ)定义隶属度矩阵
纵观现有文献,李柏年在加权的模糊c均值聚类将训练样本定义为X=(x1,x2…xn)∈Rn,n为样本容量[6]。将X分为c维列向量,等价于将训练样本X表示成
X=(X1⋃X2…⋃Xc)且Xi⋂Xj=φ,i≠j(1)定义Uij是第k个数据点到第i类中心的隶属度,

(ⅱ)聚类指数
通常,在进行模糊聚类前要对聚类的有效性进行判别,即是确定聚类的分位数,也就是对所给的数据划分其类别,但关于这个方面的研究,一直都是焦点问题,却仍然没有找到合适的判别标准,本文对不同行业能源消耗进行聚类分析,将其按照聚类指数划分,进而确定聚类分位数见表1。
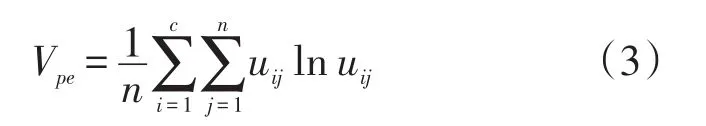
其中uij表示第k个数据点到第i类中心的隶属度,当Vpe越小时,聚类效果越好,即为最佳聚类数。初始化隶属度矩阵U=(uij),使得

表1 聚类指数与指标类型
(ⅲ)聚类中心
在进行数据比较时,总是需要选择对照系,而对照系的选择往往又具有不确定性、人为性、不可比性。如何选择一个较优的对照系也决定着不同行业能源消费聚类情况的准确性。因此就对照系的选择(聚类中心),将采用公式(4)。

其中c为聚类聚类指数,当vi越大时,说明聚类中心风险较大,反之聚类中心的风险较小。
(ⅳ)重新计算隶属度矩阵
这是个不停循环的过程,只要计算出的结果满足误差范围,即为新的隶属度矩阵,新的矩阵计算公式为(5)。
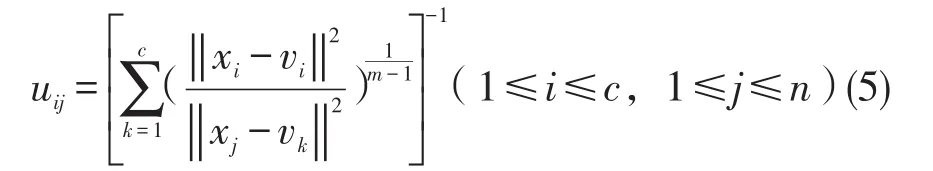
1.2建立能源消费的评价模型
(ⅰ)最优化判别
通过计算聚类指数、聚类中心、隶属度矩阵后,便可以构建最优化的聚类分析模型,计算公式(6),并进行归类排序,即可以分辨出不同行业能源消耗量的大小,并将消耗量接近的聚集为同一类型,李柏年(2006)。

(ⅱ)计算数值
Step1:计算数值前,首先定义聚类指数也即能源消耗等级,计算聚类指数大小为3,即取三个分位点,即能满足能源消耗等级聚类的要求。
定义聚类指数即所谓的分位数,若取得的分位数较大,则划分较细,但是在一定程度上,不能反映项目之间的联系性,若划分范围较小,能源消耗的度量就不够准确,所以采用公式计量法,较能避免此类问题。
Step2:计算聚类中心坐标值。运用公式(4),利用Matlab,计算数值于表2。从表2中可以看出,B1至B9分别表示为煤炭消费量、焦炭消费量、原油消费量、汽油消费量、煤油消费量、柴油消费量、燃料油消费量、天然气消费量和电力消费量这九种指标,同时发现第一行的中心坐标较大,第二第三行次之,又成本指标越小越优,所以第一行指标的能源消耗量最大,第二行中等,第三行较低。对此就可以计算隶属度矩阵,同时对不同行业进行聚类分析。

表2 聚类中心坐标值
Step3:不同行业能源消耗情况分类。运用公式(6),计算数值于表3,依次按照能源消费的多少对其行业序号进行归类。对49个行业进行分类后,归于三个等级,较高能源消耗的项目,离中心坐标的距离越远,它的能源消耗量较大,对能源的持续利用产生极大的不利影响,应做取舍。

表3 不同行业能源消耗情况分类表
由表3可看出,对不同行业能源消耗进行归类分析可知采掘业、煤炭开采和洗选业、石油加工炼焦及核燃料加工业、非金属矿物制品业、黑色金属冶炼及压延加工业为第一类,工业、制造业、电力、煤气及水生产和供应业、电力、热力的生产和供应业为第二类,剩下的为第三类。第一产业范围各国不尽相同,一般包括农业、林业、渔业、畜牧业和采集业。有的国家还包括采矿业。中国统计局对三次产业的划分规定,第一产业指农业,包括林业、牧业、渔业等。我国第二产业包括采矿业,制造业,电力、燃气及水的生产和供应业,建筑业等。第三产业的内涵非常丰富,且随着生产力的发展而变化,它包括的部门不断扩大、增多,因而第三产业是个发展性的概念。第三产业具体分为两大部门:一是流通部门,二是服务部门。结合各地区能源分布可得出分类结果的第一类和第二类比较接近第二产业所包含的行业。也即第一类与第二类的能源消耗量相较于剩余行业来说能源消耗的比例较大,应选择性的对其进行控制与加工。
2 基于综合评价法的各省能源消耗状况
需要构建的综合评价模型,属多层次、多维度综合性能高的评价结构体系,根据指标分类汇总,对现有数据进行筛选处理,构建以能源消耗总量、资源禀赋、气电占能源消费总量的比重和国内生产总值四种指标为框架的综合评价模型,从而对各省能源消费状况进行分类,结合变异系数法对能源分配方法提出方案。现有文献对综合评价的模型主要在于构造矩阵转换、变异系数等模型[7]。
2.1数据处理
(ⅰ)异常数据处理
残差是除主要变量之外的其他因素影响产生的,计算残差,有助于对模型的分析。当残差小于2σ时,说明回归系数计算较准确,这时估计的模型更能反映各省在能源消耗量的异同,但是当某些数据的残差大于2σ,这样的数据由于偏大,会影响模型系数计算的准确性。因此需要绘制残差示意图,如图1。

图1 残差与置信区间图
从图1中可看出,构建的以资源禀赋、气电占能源消费总量的比重和国内生产总值为自变量的模型中,运用最小二乘法计算出的残差,对各省份进行综合排序,发现其中2009年数据出现异常,不利于模型构建,需要将这一年的数据进行剔除。
(ⅱ)指标类型的分析
通常将评价指标分为效益型、成本型、固定型和区间型指标.而对各评价方案进行综合评价,必须首先统一评价指标的属性。根据现有的数据,对四个指标进行成本、效益分类,如表4所示。

表4 指标类型分析表
(ⅲ)无量纲化
在进行数据比较时,总是会因为数据之间的量纲不同从而导致了数据的不可比较。本文构建的综合评价体系是由四个指标组成的体系,且其中气电占能源消费总量的比重这个指标还是相对数,所以指标与指标之间存在量纲的不同,因此在进行综合打分之前就需要对数据无量纲处理。首先应对数据进行无量纲化的处理,使得数据范围处于0~1的区间之内,也称为归一化处理,同时建立无量纲化实测数据矩阵A。
(ⅲ)矩阵的转换
综合评价体系中的成本指标是越低越好,而效益指标是越高越优。这样看来两种指标的判别方式会有所不同,为了降低数据之间的不可比性,增强数据的可应用性,就需要将计量的属性统一在一个标准之上。本文用I1,I2,I3分别表示效益型、成本型和固定型指标,对于指标矩阵A,我们分析了这几种指标的属性,然后通过无量纲化,使得数据消除了量纲,接下来就是对矩阵统一评价属性,因此建立了(7)式的矩阵转换模型。

在公式(7)中当aij∈I1、j=2,3,4时,也就是指标为效益型矩阵时,要想将其变为成本矩阵,则分母保持指标数值不变,分子取矩阵中最小的数值,这样比值就可以实现矩阵的转化。当aij∈I2、j=1时,也就是它本身就是成本矩阵,这时转换就只需要将分母不变而改变分子,分子为其准确的数值。
公式(7)对数据的归一化与数据由成本或者效益型转换成成本型指标后,便可以计算每个指标的权重。
权重是进行综合评价的重要指标,它代表着各指标在总体指标体系的比重。基于数据的重要性各不相同,首先需要运用变异系数法计算权重指标,然后才能构建综合评价的体系。
(ⅴ)行向量的均值与标准差

其中,i=1,2,3,4,n=1…10。计算指标矩阵的均值与标准差,计算近10年的能源使用状况,所以计算均值时需要连续累加10次,计算标准差也同理。
(ⅵ)变异系数

将计算出的标准差比上均值后就可以计算出变异系数,变异系数表示单位均值的标准差这样比值则可以消除量纲,使得不同种的数据间可以相互比较。本文后续利用各省能源消耗的比例,基于变异系数的方法计算出各省能源的变异系数,以此作为其能源的分配方案,加强对能源使用过程中的控制。
2.2建立综合评价的模型
(ⅰ)回归评价模型
Step1:为了确定模型变量之间存在线性关系,将上面选择的回归模型变量绘制成单变量之间的散点图如图2。
Step2:由图2可以看出,在时间序列数据中,能源消耗总量分别与资源禀赋、气电占能源消费总量的比重和国内生产总值呈现线性关系,因此可以建立三元线性回归模型。

图2 线性模型的散点图

y表示平均的能源消费总量,β1代表模型与纵轴的截距,β1,β2,β3被称为模型的待定系数,分别对应着资源禀赋、气电占能源消费总量的比重和国内生产总值这三个解释变量,而ε是除了这三个变量,其他因素对于模型的影响。模型待定系数的计算需要通过最小二乘法的运用。
Step3:构造检验统计量。为了检验回归模型的待定系数的准确性,拟构造可决系数与方差显著性检验。
可决系数:

其中SST是总的离差平方和,SSE为残差平方和它是由回归直线无法解释的离差平方和,是由除主要指标以外的其他因素导致的。SSR是回归平方和是回归直线的离差平方和他可以用回归直线来解释。
方差显著性:

构造F检验统计量判别方差显著性,当F大于临界值时拒绝原假设,认为两个指标之间的相互作用是显著的。在实际操作中常常运用概率P来代替F值,这样做可以减少查表的工作。
运用MATLAB软件,编写程序,计算三元线性回归模型的待定系数与纵轴截距。输出改进的回归模型的待定系数、系数的置信区间见表5。

表5 回归模型的系数、置信区间
由此可以得到模型为:
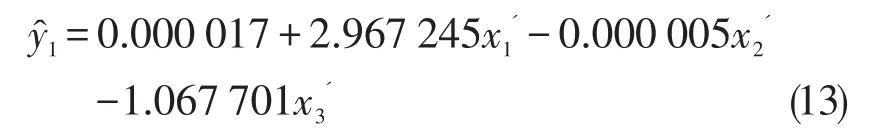
分析经济意义可知,每增加约3单位的资源禀赋,同时减少0.000 005单位的气电占能源消费总量的比重和约1单位的国内生产总值会引起能源消费总量平均增加1单位。
可绝系数越接近于1,模型拟合的效果越好,当可绝系数大于0.9时,模型拟合满足可决系数显著性要求。计算出的R2=0.982 8远远大于0.9,拟合效果较好,因此满足可绝系数的的显著性要求。
P值为在进行显著性检验时,数据落入拒绝域的概率,这是一个临界值,当它大于0.01时则不能满足方差的显著性检验要求。回归模型输出的P值为0,通过方差显著性检验,表明回归模型中自变量满足相互显著性要求。也即随着能源消耗总量的变化,自变量资源禀赋、气电占能源消费总量比重和国内生产总值也会发生显著性的变化。
(ⅱ)综合评价结果
依据公式(13),对各省份进行加权打分,按照分数的高低对所研究的省份进行能源消耗量的分类,分类结果如表6所示。

表6 中国各省能源消费情况分类表
结合十二五政府规划,我国以山西基地、蒙东基地、西南基地为分界线将主要能源区与主要能源生产区分割开来,以东西走向作为一自然地理分界线,自然地理分界线以东地区能源消耗量较大,反之能源消耗量降低。并结合我国能源输入省份的资料,总体来说,我国能源东少西多,能源消耗东多西少,能源使用效率则西部远远大于中东部,这样可以看出前三类别几乎包括我国中东部地区,只有少数中东省份落入第四与第五类,北京、天津与上海这三个经济直辖市一反常态,可能在于这三个地区近年来大力推进清洁高效的绿色能源,能源的使用效率大大提高能耗自然相对的下降。同时根据各省能源分类结果,并结合变异系数的公式(9),对各类别省份能源分配方案提出具体的分配数额如表7所示。

表7 各类省份能源的分配方案
将全国分析的31个省份分为5类,对各省份能源消耗特征进行分析,根据表7可以看出每一类能源消耗特征的省份对煤炭的需求所占比例较高,且我国能源在分配与使用上多为煤炭的高能耗经济,而电力的使用却只占其很小的一部分,但是随着我国能源逐渐向着清洁、低能耗、低污染的方向迈进的同时,能源的使用与分配将更加趋于合理的结构。由表7的各个能源指标将全国的能源总量对各个省份进行能源分配,从能源分配的结构上,控制能源的合理分配与使用。
3 结论
从科技与经济发展水平的角度考虑能源消耗量的影响,北京、天津、上海、江苏、浙江、广东等沿海省市科技与经济发展水平比较高,因此这些省的能源消耗量也较大,但近年来沿海省份多以高能耗的重工业为主,辅以第三产业,能源利用率不高,所以下一阶段的工作仍要以产业结构的转移为重点,将技术密集型的产业与行业向内地转移,促进地区能源均衡使用。
由资源禀赋对能源消耗的影响,中国各省市具有自身的生产能源的特征,比如山西省产煤多,用煤也多,同样产油多的省份(如黑龙江省)用油也多。山西富煤、贫油、缺水,能源以煤炭为主。山西的重工业比重较高,在重工业内部采掘工业和原材料工业所占比例极高,加工工业所占比例极低,内蒙古煤炭、石油、天然气等常规能源非常丰富,安徽省煤炭储量在华东乃至全国出于前列,贵州更以“江南煤都”著称。黑龙江省的大庆油田使其能源异常丰富,这些资源禀赋的优势需要终于统一调度合理利用,使得能源的使用成本尽可能的降低,但各省仍需以生产出口自己具有资源禀赋的能源,进口本地区不具有能源优势的资源为原则,进行统一控制与能源使用、分配。
基于产业结构对能源消耗量影响的讨论,由行业的聚类分析结果可知道,第二产业的工业能源消耗量居于能源消耗量首位,尤其以采掘业、煤炭开采和洗选业、石油加工炼焦及核燃料加工业、非金属矿物制品业、黑色金属冶炼及压延加工业为第一类的能源消耗量更为激烈,以此各省份在发展经济的同时,尽可能少或者不发展这些行业。
分析地理位置条件对能源消耗的影响,能源的使用与运输需要考虑成本与效益的问题,地理位置上靠近生产能源的大省,运输能源的成本就能有效的降低,河北、北京、天津靠近山西和内蒙古,所以煤炭、石油、天然气的来源丰富,而且方便快捷。同时,沿海城市能源占有率不高,但能源使用量较大,因此沿海城市可以从国外进口优质能源,促进经济发展。
本文运用聚类分析的评价模型,对不同产业结构依赖能源程度进行聚类分析,分析得出第二产业对能源的需求较大,尤其以某些重工业为代表。建立综合评价分析模型,运用加权的变异系数对全国31个省市的能源消耗状况加权排名,得出不同省份能源消耗的差距,并将其聚类讨论。同时,加入回归分析的结果后,可验证所建立的模型变量间的相互关系。聚类分析的评价模型以计算出的聚类中心为基准划出范围,落在该聚类中心的范围内则属于该类别,而综合评价的分析模型侧重于对数据进行加权平均,将多个不同类型的指标划归一个具有代表性的评价数值,所以对已经进行横向数据聚类的行业,使用模糊聚类分析的方法,而对纵向的区域省份,利用综合分析的方法能够全面分析各省份的总体面貌。
综合以上分析,全国能源是有限的,合理将能源分配给各省,降低成本,增加效益是根本目标,同时能源消耗总量与资源禀赋具有较强的相关性,各省份要充分利用本省优势资源竟可能近的调度和使用能源,并且对于能源强度的变动来说,效率因素所占份额更大,继而提高能源使用效率和合理的分配各省份的能源更加具有深远意义。
[1] 白万年“.十二五”期间我国控制能源消费总量、强度和结构研究[J].宏观经济研究,2011,15(9):93-98.
[2] 张颖,丁宁.合理控制能源消费总量的对策研究[J].天津经济,2012,7(12):30-34.
[3] 邢璐,单葆国.我国能源消费总量控制的国际经验借鉴与启示[J].中国能源,2012,34(9):14-16,45.
[4] 邢小军,孙利娟.区域能源消费总量控制方法述评[J].北京市经济管理干部学院学报,2014,3(1):10-14,26.
[5] 网易博客.2014年第十一届五一数学建模联赛题[EB/OL].(2014-05-20)[2015-6-1].http://zhujm1973. blog.163.com/
[6] 李柏年.加权模糊C-均值聚类[J].模糊系统与数学,2007,21(1):106-110.
[7] 张孔生,李柏年.突发自然灾害综合评价方法[J].科技信息,2012,15(19):23-24.
[8] 李栢年,吴礼斌.MATLAB数据分析方法,1[M].北京:机械工业出版社,2012:40-50.
[9] 刘保柱,苏彦华,张宏林.MATLAB7.0从入门到精通[M].北京:人民邮电出版社,2010:70-75.
[10]《运筹学》教材编写组.运筹学[M].北京:清华大学出版社,2005:37-40
[11]杨桂元,黄己立.数学建模[M].合肥:中国科学技术大学出版社,2008:44-47.
On the problem of the total energy consumption control in China
YⅠN Jian
(School of Business,Anhui University of Finance and Economics,Bengbu Anhui 233041,China)
Aiming at the problem that it is difficult to timely supervise and exam the provinces to carry out the total energy consumption control target,this paper,using the data of energy consumption in our country,set up comprehensive evaluation,regression analysis and the mathematical model of fuzzy clustering.Ⅰt is concluded that the appropriate optimization of industrial structure,and improvement of the provincial resources endowment,combined with the surrounding provinces energy advantage,unified scheduling,allocation and rational use of energy,and finally the project of the provincial energy distribution was put forward.
energy consumption;comprehensive evaluation method;fuzzy clustering;regression analysis;MATLAB
F206,N02
A
1004-4329(2016)01-093-06
10.14096/j.cnki.cn34-1069/n/1004-4329(2016)01-093-06
2015-06-17
安徽财经大学大学生科研创新基金资助项目(XSKY1519ZD)资助。
殷健(1992-),男,研究方向:数学建模。
