MapReduce能耗建模及优化分析
2016-10-13尹路通国冰磊
廖 彬 张 陶 于 炯 尹路通 郭 刚 国冰磊
1(新疆财经大学统计与信息学院 乌鲁木齐 830012)2(新疆大学信息科学与工程学院 乌鲁木齐 830046)3(新疆医科大学医学工程技术学院 乌鲁木齐 830011)4 (新疆大学软件学院 乌鲁木齐 830008)
MapReduce能耗建模及优化分析
廖彬1,4张陶2,3于炯2,4尹路通4郭刚4国冰磊2,4
1(新疆财经大学统计与信息学院乌鲁木齐830012)2(新疆大学信息科学与工程学院乌鲁木齐830046)3(新疆医科大学医学工程技术学院乌鲁木齐830011)4(新疆大学软件学院乌鲁木齐830008)
(liaobin665@163.com)
云计算中心规模的不断扩大以及设计时对能耗因素的忽略,使其日益暴露出高能耗低效率的问题.为提高MapReduce框架能耗利用率,首先对MapReduce任务进行了能耗建模,提出基于CPU利用率估算、主要部件能耗累加及平均功耗估算的任务能耗模型,并在此基础上建立了MapReduce作业能耗模型.其次,基于能耗模型对能耗优化进行了分析,提出从优化MapReduce作业执行能耗、减少MapReduce任务等待能耗与提高MapReduce集群能源利用效率3个方向对MapReduce进行能耗优化.再次,提出异构环境下的数据放置策略减小MapReduce任务等待能耗,提出截止时间约束下的最小资源分配方法提高MapReduce作业能耗利用效率.通过大量的实验及能耗数据分析,验证了能耗模型及能耗优化方法的有效性.
绿色计算;任务调度;能耗建模;节能分析;数据布局
数据的产生过程在经历被动和主动2种产生过程后,发展到了自动产生阶段,预示着大数据时代的来临.数据从简单的处理对象开始转变为一种基础性资源,如何更好地管理和利用大数据已经成为普遍关注的话题,大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战[1].据文献[2]统计,2007年全球数据量达到281 EB,而2007—2011年这5年时间内全球数据量增长了10倍.数据量的高速增长伴随而来的是存储与处理系统规模不断扩大,这使得运营成本不断提高,其成本不仅包括硬件、机房、冷却设备等固定成本,还包括IT设备与冷却设备的电能消耗等其他开销,并且,系统的高能耗将导致过量温室气体的排放并引发环境问题.事实上,在能源价格上涨、数据中心存储规模不断扩大的今天,高能耗已逐渐成为制约云计算与大数据快速发展的一个主要瓶颈[1].据文献[3]统计,目前IT领域的CO2排放量占人类总排放量的2%,而到2020年这一比例将翻番.2008年路由器、交换机、服务器、冷却设备、数据中心等互联网设备总共消耗8 680亿kW·h,占全球总耗电量的5.3%.纽约时报与麦肯锡经过一年的联合调查,最终在《纽约时报》上发表了“Power,pollution and the Internet”[4],调查显示Google数据中心的平均功耗为3亿W,Facebook则达到了0.6亿W,但巨大的能耗中却只有6%~12%的能耗被用于处理相应用户的请求.与此同时,Barroso等人在文献[5]中对Google内部5 000多台服务器进行长达半年的调查统计结果表明:服务器在大部分时间里利用率都在10%~50%之间,服务器在负载很低(小于10%)的情况下电能消耗也超过了峰值能耗的50%.
Hadoop[6]作为新的分布式存储与计算架构,参考Google的分布式存储系统GFS[7]实现了分布式文件存储HDFS;参考MapReduce[8]计算模型实现了自己的分布式计算框架;参考BigTable实现了分布式数据库HBase.由于能够部署在通用平台上,并且具有可扩展性(scalable)、低成本(economical)、高效性(efficient)与可靠性(reliable)等优点,使其在分布式计算领域得到了广泛运用,并且已逐渐成为工业与学术届事实上的海量数据并行处理标准[9].虽然Hadoop拥有诸多优点,但是和Google服务器一样,Hadoop集群内部服务器同样存在严重的高能耗低利用率问题[10].Hadoop主要由分布式存储系统HDFS与分布式任务执行框架MapReduce两部分组成,现有研究大多从分布式存储系统HDFS入手解决Hadoop的能耗问题,针对MapReduce框架能耗优化方面的研究则相对较少.大量研究围绕通过对存储资源的有效调度,在不影响系统性能的前提条件下将部分存储节点调整到低能耗模式,以达到节能的目的.为提高MapReduce的能耗利用效率,本文做了如下工作:
1) 对MapReduce系统模型进行了分析,提出3种任务级的能耗模型:基于CPU利用率估算的能耗模型、基于主要部件能耗累加的能耗模型及基于平均功耗估算的能耗模型,并在这3种模型基础上得到MapReduce作业能耗模型.
2) 对MapReduce作业能耗模型优化分析的基础上,对优化MapReduce作业执行能耗、减少MapReduce任务等待能耗与提高MapReduce集群能源利用效率3个方面的能耗优化方法进行了讨论.
3) 提出异构环境下的数据放置策略以减少异构环境下的MapReduce任务等待能耗;推导出截止时间约束下的最小资源槽slot分配计算公式,计算适应当前作业的最小资源数量,提高MapReduce作业能源利用效率.
4) 大量的实验及能耗数据分析表明本文所提能耗模型及能耗优化方法的有效性.
1 相关工作
传统的IT系统一方面通过超额资源供给与冗余设计以保障QoS与系统可靠性[11],另一方面负载均衡算法专注于将用户请求平均分发给集群中的所有服务器以提高系统的可用性,这些设计原则都没有考虑到系统的能耗因素,这使得IT系统的能量利用日益暴露出高能耗低效率的问题[12].学术与工业界分别从硬件[13-15]、操作系统[16-18]、虚拟机[19-26]、数据中心[27-33]4个层次去解决IT系统的能耗问题.针对分布式计算系统能耗问题的研究,通常以Hadoop作为研究对象,并且大多从分布式存储系统HDFS入手解决其存在的能耗问题,针对任务执行框架MapReduce能耗优化方面的研究则相对较少.
研究分布式存储系统HDFS节能方面,根据软硬件角度进行划分,可分为硬件节能与软件节能2个方面[34].硬件节能主要通过低能耗高效率的硬件设备或体系结构,对现有的高能耗存储设备进行替换,从而达到节能的目的.硬件节能方法效果立竿见影,且不需要复杂的能耗管理组件;但是对于已经部署的大规模应用系统,大批量的硬件替换面临成本过高的问题.软件节能通过对存储资源的有效调度,在不影响系统性能的前提条件下将部分存储节点调整到低能耗模式,以达到节能的目的.由于不需要对现有硬件体系进行改变,软件节能是目前云存储节能技术的研究热点.软件节能研究主要集中在基于节点管理与数据管理2方面.节点管理主要研究如何选择存储系统中的部分节点或磁盘为上层应用提供数据服务,并让其他节点进入低能耗模式以达到降低能耗的目的.节点管理中被关闭节点的选择与数据管理技术紧密相关,而目前已有的数据管理技术主要有基于静态数据放置、动态数据放置与缓存预取3种.其中,基于静态数据放置的数据管理[35-39]根据固定的数据放置策略将数据存储到系统中各节点上,之后将不再改变其存储结构;基于动态数据放置的数据管理[40-43]根据数据访问频度动态调整数据存放的位置,将访问频度高与频度低的数据迁移到不同磁盘上,对存储低频度数据的磁盘进行节能处理以降低系统能耗;基于缓存预取的数据管理[44]借鉴内存中的数据缓存思想,将磁盘中的数据取到内存或其他低能耗辅助存储设备并使原磁盘进入低能耗模式以此达到节能的目的.Chen等人[45]针对实际系统的研究发现数据访问具有很强的周期性,通过关闭空闲时段大量节点以达到节能的目的.文献[46]提出了covering subset的概念,将数据块与其副本中的至少一个数据块放入该子集中以保证所有数据块的可访问性的前提下,通过关闭与该数据块子集无交集的DataNode节点以达到节能的目的.文献[47-48]通过对Yahoo公司HDFS集群内部数据块访问规律的研究发现数据块的访问具有较强的规律性,根据数据块的访问规律将其放在Cold-Zone与Hot-Zone两个DataNode节点区域中,通过将Cold-Zone中DataNode节点进行节能处理从而达到整个集群节能的目的.
在分布式任务执行框架MapReduce能耗优化方面,少有的研究通过选择部分节点执行任务[46]、任务完成后关闭节点[49]、配置参数优化[45]、DVFS调度[50]、作业调度[51]、虚拟机放置策略[52]及数据压缩[53]等方法达到提高MapReduce能耗利用率的目的.与covering subset思想相反,文献[49]提出All-In Strategy(AIS)策略,即将整个MapReduce集群作为整体用于任务的执行,当任务结束后将整个集群做节能处理(关闭节点)达到节能的目的.Leverich等人[46]发现MapReduce框架的参数配置对MapReduce能耗的利用具有较大影响,通过大量的实验得到优化MapReduce能耗的配置参数,对提高MapReduce集群系统的能耗利用率具有指导意义.文献[50]中利用DVFS(dynamic voltage and frequency scaling)技术,通过动态地调整CPU频率以适应当前的MapReduce任务负载状态达到优化能耗利用的目的.文献[51]提出Hadoop节能适应性框架GreenHadoop,通过合理的作业调度,在满足作业截止时间约束的前提下通过配置与当前作业量相匹配的作业处理能力(活动节点数量),达到最小化Hadoop集群能耗的目的,实验证明GreenHadoop与Hadoop相比提高了MapReduce的能耗利用率.宋杰等人[54]对云数据管理系统(包括基于MapReduce的系统)的能耗进行了基准测试,并定义了能耗的度量模型与能耗测试方法,证明了不同系统在能耗方面存在着较大差异,需要进一步对系统进行能耗优化.
本文与已有工作的不同包括:
1) 已有工作缺少对MapReduce能耗建模的研究.本文提出3种任务级的能耗模型:基于CPU利用率估算的能耗模型、基于主要部件能耗累加的能耗模型及基于平均功耗估算的能耗模型,并在这3种模型基础上得到MapReduce作业能耗模型.能耗模型是研究MapReduce能耗优化的理论基础.
2) 已有工作往往采用单一的方法优化Map-Reduce能耗.本文在MapReduce作业能耗模型的基础上,归纳了从2种不同的层面(作业的执行能耗与集群能源效率)、3种不同的方向(优化MapReduce作业执行能耗、减少MapReduce任务等待能耗与提高MapReduce集群能源利用效率)优化MapReduce能耗.
3) 提出MapReduce任务等待能耗的概念,并提出异构环境下数据的放置策略减小MapReduce任务等待能耗.推导截止时间约束下的最小资源槽slot分配计算公式,计算适应当前作业的最小资源数量,提高MapReduce作业能源利用效率.

Fig. 1 MapReduce job decomposed into tasks.图1 MapReduce作业的任务分解
2 相关模型与定义
2.1MapReduce系统模型
MapReduce运行环境通常由多个机架RACK组成,而一个RACK内部又由多个节点服务器组成.通常情况下,MapReduce集群由2个NameNode管理节点(主管理节点与从管理节点)与多个DataNode节点构成.实际应用环境中,考虑到DataNode节点数量远远大于NameNode节点,DataNode节点能耗之和占系统总能耗的95%以上,并且NameNode负责整个系统的管理与调度工作,对NameNode进行节能处理将对系统的稳定性造成影响.所以本文的能耗模型主要针对DataNode节点、不对NameNode节点进行能耗建模.
定义1. MapReduce集群DataNode节点模型.将MapReduce集群中n个DataNode节点用集合DN表示:
(1)
其中,dni∈DN(0≤i≤n-1)表示MapReduce集群中的DataNode节点.
定义2. 作业的任务分解模型.如图1所示,MapReduce框架将作业job分解为多个Map与Reduce任务并行地在集群中执行,可将这个过程定义为f(job)|→M∪R,其中f为映射函数,集合M与R分别表示job分解后的Map与Reduce任务,其映射模型可由式(2)表示:
(2)
式(2)表示作业job被分解为m个Map任务与r个Reduce任务.其中,mti∈M(0≤i≤m-1)表示任意Map任务,rti∈R(0≤i≤r-1)表示任意Reduce任务.
定义3. 任务资源映射模型.作业job被分解为Map与Reduce任务后,将由作业调度系统将任务映射到具有空闲资源槽的DataNode节点dni上执行.任务与资源映射过程可定义为映射f(M∪R)|→DN,其中f为映射函数,M与R分别表示Map与Reduce任务的集合,DN表示MapReduce集群中DataNode节点的集合.具体而言,映射模型可由式(3)具体描述:
(3)
2.2MapReduce任务能耗模型
设某个任务task∈M∪R被映射到具有空闲资源槽的DataNode节点dni上执行.任务task从时间点ts开始,运行到时间点te结束,即作业运行时间区间为[ts,te].那么,运行任务task所需要的能耗Etask可由式(4)得到:
(4)其中,ui(t)表示在时刻t∈[ts,te]节点dni的系统利用率(也可分别表示CPU、内存、磁盘、网卡等部件的利用率),并且存在ui(t)∈[0,1];Pdni(ui(t))则表示在时刻t系统利用率为ui(t)条件下dni节点的功耗.
节点dni的电能消耗是由CPU、内存、磁盘、网卡等设备的电能消耗共同组成的[55].节点瞬时功率值为这些硬件部件的瞬时功率之和.由于CPU、内存、磁盘、网卡等部件的电器特性之间存在着很大的差异,导致不同部件能耗计算方法不同.使用累加所有部件能耗(或瞬时功耗)来计算节点的能耗值的方法较为复杂.所以,考虑到能耗模型的简便性与完备性,本文提出3种能耗模型:第1种能耗模型考虑到系统整体能耗通常与CPU利用率成正比的特性,提出基于CPU利用率估算的能耗模型;第2种对系统主要的部件能耗模型进行分别建模,从而累加得到系统的整体能耗,该模型是一种完备的能耗模型,但具有较高的复杂度;第3种基于平均功耗估算的能耗模型是基于历史数据分析的能耗估算模型,主要用于作业运行前的执行能耗预测.
2.2.1基于CPU利用率估算的能耗模型
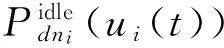
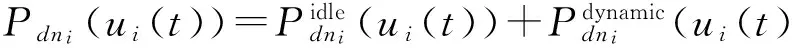
(5)
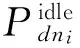
(6)

由式(4)~(6)可以得到:

(7)
定理1. 据微积分的思想,将时间区间[ts,te]等分为k份时(k→+∞),即将[ts,te]等分为[t0,t1,…,tk-1],且∀[tj,tj+1],j∈[0,1,…,k-2],满足ui(t∈[tj,tj+1])≡ui j,其中ui j为在时间区间[tj,tj+1]内不随时间变化的常量,并且同样存在ui j∈[0,1].那么可将在节点dni运行任务taskj所需要的能耗进一步表达为式(8):
(8)
证明. 由于运行任务task所需要的能耗Etask可由式(7)进行计算,即:
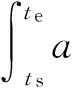
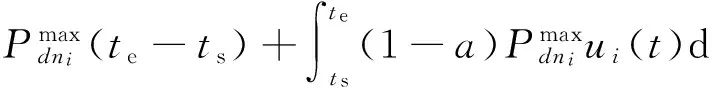
当将时间区间[ts,te]等分为k(k→+∞)份时,即将[ts,te]等分为[t0,t1,…,tk-1],且∀[tj,tj+1],j∈[0,1,…,k-2],满足ui(t∈[tj,tj+1])≡ui j,其中ui j为在时间区间[tj,tj+1]内不随时间变化的常量,且存在ui j∈[0,1],那么:

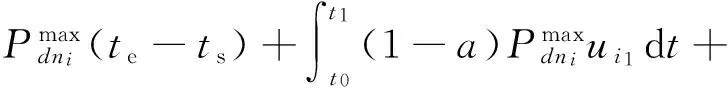
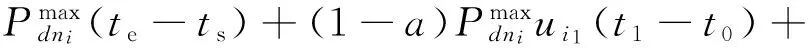

又因为将时间区间等分为了k份,可以得到等分区间的大小tj+1-tj为
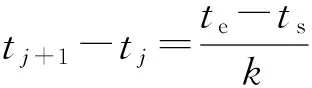
并且存在j∈[0,1,…,k-2]且k→+∞.
证毕.
利用基于CPU利用率估算能耗模型对Map-Reduce作业进行能耗计算的唯一前提条件是取得所有任务运行过程中的CPU利用率变化序列.CPU利用率变化序列可通过资源利用监控软件取得,或对现有的MapReduce框架进行扩展,在作业运行报告中添加任务执行节点的CPU负载信息.基于CPU利用率估算的能耗模型意义在于作业运行完毕后对作业能耗的计算,是将来开发Hadoop能耗监控及优化软件的理论基础.
2.2.2基于主要部件能耗累加的能耗模型
由于节点的电能消耗是由CPU、内存、磁盘、主板、风扇、网卡等设备的电能消耗共同组成的,本节首先建立各计算机主要部件的能耗模型,继而推导出基于主要部件能耗累加的能耗模型(本节主要考虑CPU、内存、磁盘、网卡的能耗模型,其他部件如主板、风扇等可根据其能耗模型进行扩展).
CPU的能耗模型受到处理器的活动状态、指令执行情况、高速cache使用情况、当前执行频率及制造工艺等因素的影响.设PCPU表示CPU利用率为uCPU时的功率,根据Kansal等人在文献[58]中提出的能耗模型,PCPU与uCPU的关系可表示如下:
(9)其中,aCPU与λCPU为CPU能耗模型的常数,不同的CPU之间存在着差异,其值可通过大量的训练获得.
已有大量工作针对内存的能耗模型进行了研究,发现影响内存能耗的主要因素是内存读写数据的吞吐量[59].记录内存最后一层Cache(last level cache, LLA)的缺失次数,是一种轻量级的内存吞吐量评估方法.根据吞吐量指标,设Emem(T)表示内存在时间区间T内的能耗,N表示最后一层Cache的缺失次数,内存模型表达如下[58]:
(10)
其中,amem与λmem为内存能耗模型的常数.
磁盘能耗与读写数据量密切相关,设Edisk(T)表示磁盘在时间区间T内的能耗,r与w分别表示在时间区间T内磁盘的读写数据量,磁盘能耗模型可表达如下[60]:
(11)
其中,aread与awrite分别表示磁盘读写参数,λdisk表示磁盘的静态能耗,3个参数的值可通过大量的能耗数据分析与训练获得.
与磁盘能耗模型类似,网卡的能耗与发送、接收到的数据量成正比.设Enet(T)表示网卡在时间区间T内的能耗,s与v分别表示在T时间区间内网卡发送与接收到的数据量,网卡能耗模型可表达如下:
(12)
其中,asend与areceive分别表示网卡在发送、接收数据时的能耗参数,λnet为网卡的静态能耗参数.
节点的电能消耗是由CPU、内存、磁盘、网卡等设备的电能消耗的总和.当任务task∈M∪R在节点dni上执行,运行时间区间为T=[ts,te]时运行任务task所需要的能耗Etask可表示如下:
Etask=ECPU+Emem+Edisk+Enet=

(13)
基于主要部件能耗累加的能耗模型相比基于CPU利用率估算能耗模型不仅考虑了CPU能耗,还考虑了内存、磁盘及网络等部件的能耗使用,准确地表达了任务在执行过程各部件的能耗,理论上比基于CPU利用率估算的能耗模型更为完毕、精确.由于MapReduce任务主要分为CPU密集型、网络 IO 密集型、磁盘IO密集型、Map阶段CPU与Reduce阶段IO密集型5类,基于主要部件能耗累加的能耗模型更能够清晰地对不同MapReduce任务类型的能耗行为进行描述.但是,由于参数偏多且参数值的取得较为困难,加之资源在任务执行过程中的动态性使得基于主要部件能耗累加的能耗模型计算更为复杂.所以,本文的研究重点是基于CPU利用率估算的能耗模型与基于平均功耗估算的能耗模型.但是,由于具有更为精确的特点,基于主要部件能耗累加的能耗模型将是将来研究工作的重点.
2.2.3基于平均功耗估算的能耗模型

(14)
利用基于平均功耗估算的能耗模型对Map-Reduce作业进行能耗计算的唯一前提条件是取得作业的分解与调度结果.作业的分解与调度结果由MapReduce的作业调度系统确定,现有的调度系统在考虑集群CPU、内存、磁盘及网络等资源状态的基础上,基于作业优先级、截止时间、作业量、作业类型等因素对作业进行调度.现有调度系统并没有将能耗作为一种资源进行考虑,而基于平均功耗估算的能耗模型主要功能是在作业运行前对作业的执行能耗进行预测,所以基于平均功耗估算的能耗模型是将来研究节能的MapReduce作业调度系统的基础.
2.3MapReduce作业能耗模型
当MapReduce接收到一个作业job后,MapReduce框架首先将按照定义2(作业的任务分解模型)将job分解为多个Map与Reduce任务;当job进入运行状态后,MapReduce框架按照定义3中的资源映射模型将所有的任务绑定到一个空闲资源槽执行.
设[ms0,me0]与[rs0,re0]分别表示Map任务mt0与Reduce任务rt0执行的起始时间,那么可将任务集合M与R中所有任务起始时间用式(15)表示:
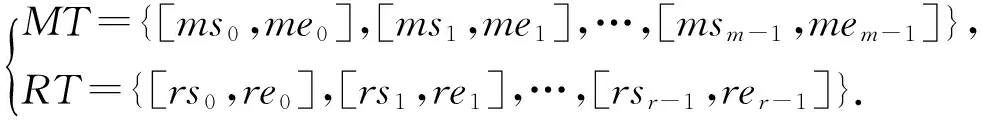
(15)
MapReduce作业的执行能耗为所有子任务(Map任务与Reduce任务)能耗的总和,设Ejobexe表示某作业的执行能耗,基于CPU利用率估算的能耗模型Ejobexe计算公式推导如式(16)所示:
Ejobexe=(Emt0+Emt1+…+Emtm)+



(16)
基于主要部件能耗累加的能耗模型Ejobexe计算公式推导如式(17)所示:
Ejobexe=(Emt0+Emt1+…+Emtm)+
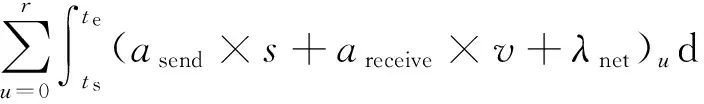
(17)
基于平均功耗估算的能耗模型Ejobexe计算公式推导如式(18)所示:
Ejobexe=(Emt0+Emt1+…+Emtm)+
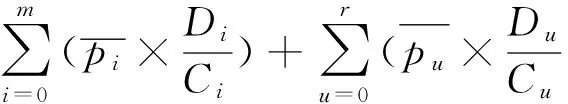
(18)
3 能耗优化分析
3.1能耗优化方法讨论
基于MapReduce作业能耗模型与MapReduce调度模型,本节对MapReduce作业的节能优化问题进行讨论.下面分别从优化单个MapReduce作业的执行能耗与提高MapReduce集群能源效率(MPUE),即从作业级与系级2方面出发,提出以下3个方面对MapReduce作业能耗进行优化:
1) 优化MapReduce作业执行能耗
基于2.3节提出的3种作业能耗模型,优化单个MapReduce作业执行能耗即是在相同作业条件下求解式(16)~(18)的极小值,具体可分为以下2种方法:

事实上,方法①的节能实质是采用低能耗高效率的硬件设备或体系结构(a与λ参数值较小),对现有的高能耗设备进行替换,从而达到节能的目的.已有大量工作[59,61-62]采用此方法,并取得了不错的节能效果.基于方法①,节能效果立竿见影,且不需要复杂的软件节能方法相匹配;但是对于已经部署的大规模MapReduce应用系统,大批量的硬件替换面临成本过高的问题.
② 寻找任务数量与任务执行时间总和之间的平衡点.根据式(16)与式(17)可知,当a与λ参数值固定时,可通过求解式(19)得到式(16)与式(17)的极小值:

(19)
式(19)中Map任务的数m主要由逻辑单元Split决定,多数情况下Split与Block呈一一对应关系,数据块Block与Split对应关系如图2所示;Reduce任务数r可由任务调度算法进行指定.理想情况下,相同作业被分解后的Map任务数目与Reduce任务数目越大,任务完成时间越短;但是,实际情况则不是这样,如图3所示为TeraSort任务在不同任务(Map任务数量固定,Reduce数量增多)数条件下的完成时间比较.图3表明任务数目与任务完成时间之间并不呈线性关系,当任务数量增加到某临界点时,任务完成时间并不会因为任务数量的增加而减小.一方面由于MapReduce集群资源状态具有动态性;另一方面当作业类型不同时,其任务数目与任务完成时间之间关系也存在着较大差异.以上2点原因造成试图通过求解式(19)来优化MapReduce作业能耗面临诸多挑战.但是,一种可行的方案是针对单一的作业类型,可通过大量的实验取得基础数据,对基础数据进行分析得到式(19)的近似解.

Fig. 2 The relationship between data Block and Split.图2 数据块Block与Split之间的对应关系
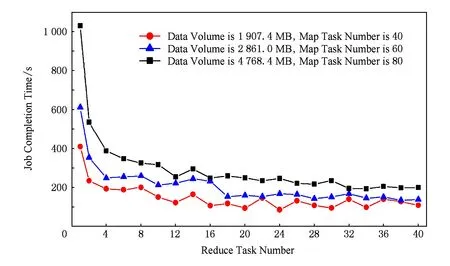
Fig. 3 The relationship between task number and job completion time (with 10 datanodes cluster).图3 任务数与作业完成时间之间的关系(10节点集群环境下)
2) 减少MapReduce任务等待能耗
当前Hadoop中采用机架感知的数据存放策略,将数据文件切分为相同大小的数据块(block)随机存储到集群DataNode节点中.在同构环境中,这种数据的切分与存储方法能够满足系统可用性与负载分流的要求.但是,在异构环境中,由于集群中各节点的计算能力存在着差异,异构节点处理相同任务(任务数据集大小相同)的完成时间不同.由于只有当一个作业的Map任务成功完成的数量超过一定的阈值时,才能开始分配该作业的Reduce任务给某TaskTracker节点执行,所以对于计算机能力强的节点,机架感知的数据存放策略会造成大量的等待时延.MapReduce任务执行过程中任务之间并不是按照完全并行的方式进行的,Map与Reduce任务之间存在不同程度的执行顺序与数据调用的制约关系.当某任务处于等待其他任务的执行结果(或等待其他任务的执行完毕)才能继续往下执行而处于“被动空闲”状态时,“任务等待能耗”便产生了,下面对MapReduce任务等待能耗进行定义.
定义4. MapReduce任务等待能耗.在Map-Reduce任务执行过程中,某些Map任务或Reduce任务由于等待其他任务的完结或执行结果,或者等待额外资源的分配才能继续往下执行,将这些任务所处的“被动空闲”状态所产生的能耗定义为MapReduce任务等待能耗.
同构环境中,由于各节点计算能力相同,各并行任务产生MapReduce任务等待能耗的概率较小.本文在3.2节提出异构环境下数据的放置策略,有效地缩短等待时延的同时达到减小“MapReduce任务等待能耗”的目的.
3) 提高MapReduce集群能源利用效率
如图4所示为WordCount与TeraSort两种作业在10个节点的MapReduce集群环境中同时执行时的资源利用图.其中WordCount作业Map任务数为10,Reduce任务数为2;TeraSort作业Map任务数为8,Reduce任务数为5.从图4可以看出,即使在MapReduce集群并行处理多个作业的情况下,Map资源槽与Reduce资源槽出现空闲的现象(特别是Reduce资源槽).特别当MapReduce集群资源数目较多且作业较少的情况下,资源空闲的现象将更为严重.
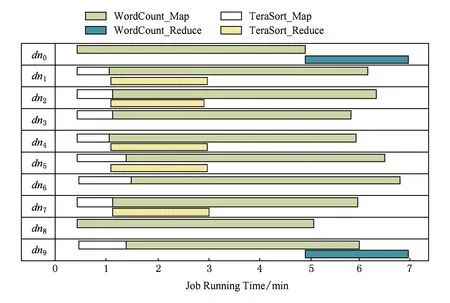
Fig. 4 The usage of slot by WordCount and TeraSort job.图4 WordCount与TeraSort两种作业slot占用图示
为了提高集群能耗利用率,传统的方法是减小“空闲能耗”,此方法在MapReduce集群系统中同样适用.在解决数据块可用性的前提下(即关闭空闲节点不会影响MapReduce任务的执行),可通过减小“空闲能耗”达到优化MapReduce的能耗利用率.在我们的前期工作中,已经通过构造数据块可用性度量矩阵[63-65],从数据的存储层解决了数据可用性完全覆盖问题.所以,在解决数据可用性问题且满足作业的截止时间约束的前提条件下,将作业队列中的作业压缩(调度)到合适的资源集上执行,并关闭“空闲资源”以达到提高MapReduce集群能源利用率是一种切实可行的办法.本文3.3节提出截止时间约束下的最小资源槽slot分配方法,在满足作业任务截止时间约束的前提下,计算完成该任务所需最少资源;通过任务调度方法将作业调度到部分资源集上,由此可产生大量的“空闲资源”.为了统一MapReduce集群能源利用效率的度量标准,需要对MapReduce任务执行系统的能源使用效率的度量标准——MapReduce集群能源效率(MapReduce power usage effectiveness,MPUE)进行定义.
定义5. MapReduce集群能源效率(MPUE).设在时间段T内,某MapReduce集群总共完成n(n≥0)个作业,这些作业的执行能耗分别为Ei(0≤i≤n-1),并设时间段T内集群总能耗为Ecluster.特定义在时间段T内,MapReduce能源效率(MPUE)来衡量该MapReduce集群的能源利用效率.MPUE可由如式(20)进行计算.
(20)
其中,MPUE∈[0,1].MPUE值越大,表明该集群MapReduce作业能源利用效率越高.当MPUE=0,说明在时间段T内没有MapReduce作业执行;MPUE=1为理想情况,表明集群所有能耗都花费在了执行作业操作上.MPUE表达的是集群层面的能源利用效率,也是衡量集群效能与slot资源利用率的重要标准.
3.2异构环境下数据的放置策略
异构环境中的数据放置策略应当适应不同节点的计算能力,数据块的大小应与存储该数据块节点的数据处理能力成正比.这样的数据块切分原则可以有效地屏蔽异构集群中各个节点处理能力的差异性,保证多个并行数据处理任务尽量在相同的时间内完成,在有效地缩短等待时延的同时减小“MapReduce任务等待能耗”.
设Ci j表示节点dni处理任务taskj时的计算能力,那么Ci j可表示为:
(21)
其中,Ti j表示节点dni完成任务taskj所花的时间,Di j表示任务所处理数据量的大小.Hadoop集群中每个节点对于不同任务的计算能力可通过大量的训练与测试得到,本文中设Ci j值为已知.可将训练后不同节点处理不同任务时的计算能力用表1进行记录.

Table 1 Computing Capability of DataNodes for Each Task
设某MapReduce作业J∈job被分解为n个Map任务,每个Map任务映射到具有不同计算能力的节点资源slot上.为使这n个Map任务完成时间均衡并缩短等待时延,数据的切分规则应满足式(22):
(22)
其中,C1,C2,…,Cn与D1,D2,…,Dn分别表示对应节点的计算能力与被分配到的数据量;D表示作业J需要处理的总数据量.
3.3截止时间约束下的最小资源分配
在数据放置策略确定并且节点的计算能力已知的情况下,能够对任务的完成时间进行有效的预测.本节提出截止时间约束下的最小资源分配计算方法,在满足作业完成时间deadline约束前提下,计算完成该任务所需最少资源;通过任务调度方法将作业集中地调度到部分资源集上.一方面,该调度方法可产生大量的“空闲资源”,通过将空闲资源进行休眠处理以达到节能的目的;另一方面,该调度策略也能提高单作业的能耗效率.
设某MapReduce作业J被初始化为NM个Map任务与NR个Reduce任务,并且这些任务在拥有RM个Map任务执行资源(Map slot)与RR个Reduce任务执行资源(Reduce slot)的集群中运行.在数据量大小与节点计算能力确定的情况下,能够通过式(21)对Map任务完成时间进行预测,但由于MapReduce任务由Map阶段、shuffle&sort阶段与Reduce阶段组成,shuffle&sort阶段与Reduce阶段的任务完成时间无法进行直接计算.所以,下面通过任务采样的方法来预测作业J的完成时间,其主要步骤如下:
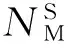
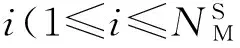

(23)
(24)
4) 记录每个采样Reduce任务j的完成时间TR(j)与处理数据量大小DR(j).利用得到的采样数据建立Reduce任务输入数据量与完成时间的函数关系:
(25)
其中,式(22)~(24)中的C表示任意节点dnij处理作业J时的计算能力.
5) 计算Map阶段的采样任务平均完成时间为
(26)
6) 计算shuffle&sort阶段的采样任务平均完成时间为
(27)
7) 计算Reduce阶段的采样任务平均完成时间为
(28)
基于采样任务的运行结果,可预测作业J在Map阶段的平均完成时间为
(29)
同样的方法,可预测Reduce阶段(包含shuffle &sort阶段)任务的平均完成时间为
(30)
值得注意的是,由于作业J在集群中运行shuffle&sort的第1次操作与Map阶段有重叠部分,所以式(29)中减去了重叠部分的时间.
设Tavg表示作业J的总完成时间,在式(29)与式(30)的基础上,总完成时间为
(31)
对式(31)进行变换,可得到式(32):
(32)
(33)
本文提出截止时间约束下的最小资源分配的计算方法,即是RM与RR值最小,通过最优化的办法建立最优化目标函数为

(34)
利用拉格朗日乘数法求函数f(RM,RR)最小值为
(35)
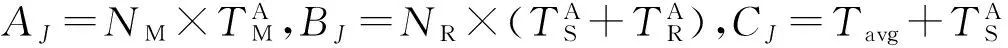
(36)
由于MapReduce作业的类型是有限的,相同类型的作业Map,shuffle&sort,Reduce的数据量与完成时间的函数(式(26)~(28))相同.所以对于相同类型的MapReduce作业,函数式(26)~(28)具有可重用性.即通过大量的训练与测试,可确定不同类型作业的处理数据量与完成时间之间的函数关系.再则,通过3.2节的方法可确定任意节点dni处理作业J时的计算能力,所以,式(36)可解.同样,当参数RM与RR值已知时,可利用式(36)确定参数NM与NR的值,即当可用Map资源slot及Reduce资源slot已知的情况下,可对满足作业完成时间deadline约束条件下的最小Map及Reduce任务数进行计算.
从图3可知,MapReduce任务数目与任务完成时间之间并不呈线性关系,当任务数量增加到某临界点时,任务完成时间并不会因为任务数量的增加而减小.通过式(36)可计算出任意作业在满足截止时间约束前提下的最小资源分配RM与RR.根据MapReduce作业执行原理,RM值可指导数据的分块策略(或Split切分原则);RR值确定了Reduce任务的数量.由于截止时间约束下的最小资源分配策略减少了执行相同作业所需的资源,从而减小了完成单个MapReduce作业所需能耗,优化了单个MapReduce作业对能耗的利用效率.
从整个集群的角度看,如图5所示为MapReduce作业的节能调度模型,当所有的MapReduce作业切分任务数量减少时,完成相同作业所需的资源数量将减少,即截止时间约束下的最小资源分配策略将更容易产生空闲节点.特别当系统空闲时段,截止时间约束下的最小资源分配策略可将任务集中分配在少量的节点上,从而产生大量的空闲节点.将空闲节点进行休眠处理,将大大提高MPUE值.特别地,利用休眠空闲节点方法进行节能时需要考虑数据的可用性需求,该问题属于数据存储层的问题,可参考文献[46,63].由于提高MapReduce集群的能源利用效率(MPUE)主要涉及MapReduce作业及任务的调度问题,涉及的研究内容较多,不作为本文的研究重点,是下一步研究的主要内容.

Fig. 5 Energy-Effcient scheduling model for MapReduce jobs.图5 MapReduce作业的节能调度模型

Fig. 6 Topology diagram of experimental environment.图6 实验环境拓扑结构图
4 能耗模型实验与结果分析
本节对3种能耗模型及作业运行时的资源行为进行了实验分析,讨论了3种模型的不同特点及适用的场景;对基于CPU利用率估算与基于平均功耗估算的能耗模型进行了运用及误差分析;对3.1节中讨论的能耗优化方法进行了实验.
4.1实验环境及参数配置
为了对MapReduce能耗模型进行实验分析,项目组搭建了拥有52个节点的Hadoop集群;其中NameNode与SecondNameNode分别独立为1个节点,其余50个节点为DataNode(5Rack×10DataNode).实验拓扑结构如图6所示.
为了控制实验过程中的Map任务数量,达到控制实验数据的统计与计算量的目的,特将数据块分块大小配置为512 MB,即dfs.block.size=512MB.单个DataNode节点上Map与Reduce任务slot资源槽数设置为1,即配置项mapred.tasktracker.map.tasks.maximum=1与mapred.tasktracker.reduce.tasks.maximum=1.能耗数据测量方面,实验采用北电电力监测仪(USB智能版),数据采样频率设置为每次1 s,各节点能耗数据(包括瞬时功率、电流值、电压值、能耗累加值等)可通过USB接口实时地传输到能耗数据监测机上,实现能耗数据的收集.实验总体环境描述如表2所示:

Table 2 Description of Experimental Environment
4.2能耗模型与作业资源行为分析
本节选用不同种类的作业进行实验,通过数据分析总结MapReduce作业能耗与不同资源(主要包括CPU、磁盘、内存及网络)利用行为之间的关系.
本节选取WordCount,TeraSort,NutchIndex,K-means,Bayes,PageRank六种作业进行实验,作业参数设置如表3所示:

Table 3 Description of MapReduce Jobs
本实验中将DataNode节点规模配置为10,通过设置作业的Map与Reduce任务数(如表3所示)为DataNode节点的整数倍,使得Map与Reduce任务均分到每个DataNode节点.通过10台能耗监测仪对作业运行中的所有DataNode节点功耗进行采样,利用时间戳关联实时功耗数据与节点CPU利用率.6种作业运行时节点功耗与CPU负载之间的关系比如图7所示:
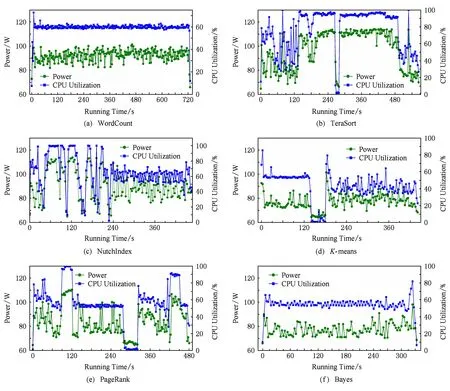
Fig. 7 Comparison between real-time power consumption and CPU utilization.图7 作业实时功耗与CPU利用率之间的比较
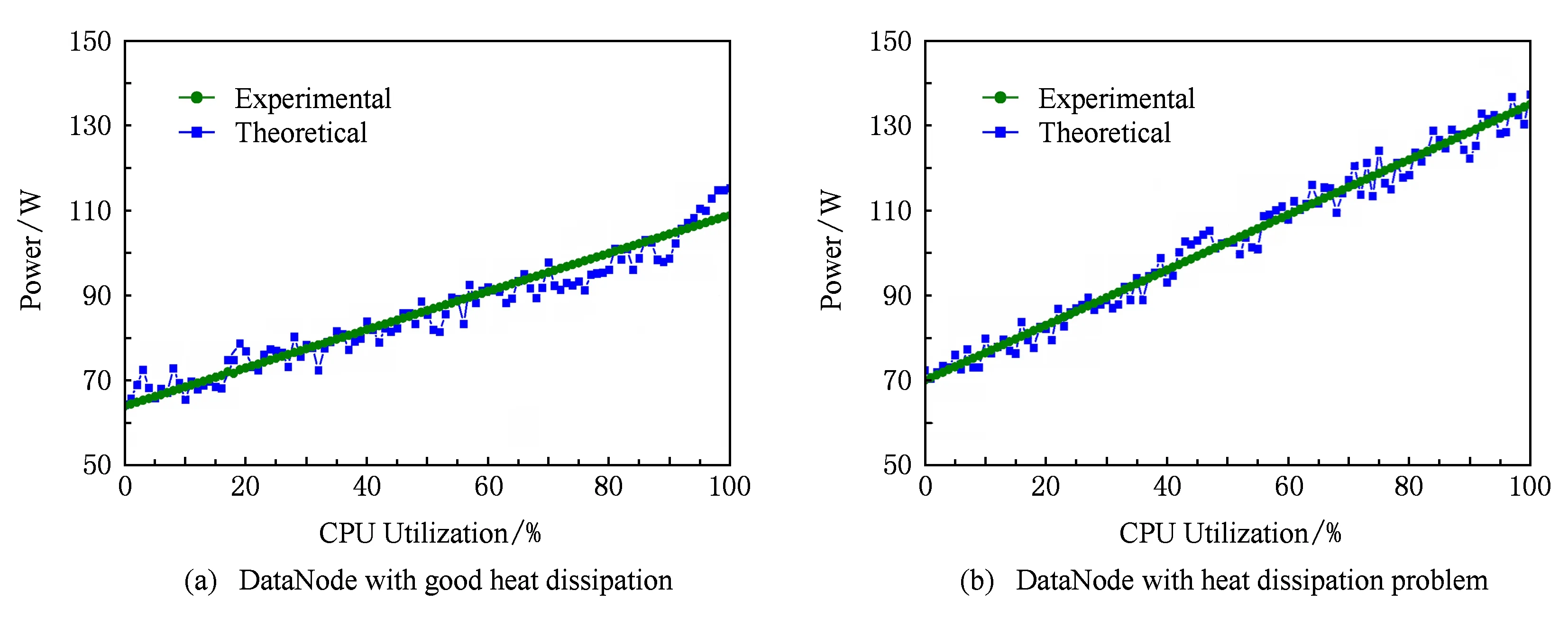
Fig. 8 The relationship between CPU utilization and power consumption .图8 DataNode节点CPU利用率与功耗之间的关系
通过图7可以看出6种作业实时功耗与CPU利用率之间联系紧密;当CPU利用率上升时能耗上升;当CPU利用率下降时能耗下降;CPU变化趋势与能耗变化趋势基本一致.事实上,通过图7表明了本文2.2.1节中提出的基于CPU利用率估算的能耗模型的可行性.通过大量的能耗数据分析得出节点功耗与CPU利用率之间的关系如图8(a)所示.
如图8所示分别为散热良好(图8(a))与散热故障(图8(b))的DataNode节点CPU利用率与功耗之间的关系.实验值取大量测试数据的平均值,如CPU利用率在50%时功耗测试数据为{83.1,85.7,88.4,87.5,89.2,84.7,90.3,83.5,82.4,87.2,82.6,85.8,86.9,85.1,84.3,88.2,86.1,83.2,88.8,86.8},取其平均值85.99为实验值.实验中我们发现散热良好的与出现散热故障的节点功耗存在较大的差异,散热良好的节点静态功耗为[64,65]W,运行时CPU温度稳定在50~65℃;而出现散热故障的节点静态功耗为[70,72]W,运行时CPU在70~88℃.基于CPU利用率估算的能耗模型的计算方法(式(5)与式(6)),可得出散热良好DataNode节点CPU利用率与功耗之间的理论函数如式(37):

(37)
其中,u表示CPU利用率,P(u)表示CPU利用率为u时节点的功耗.节点静态功耗为64 W,峰值功耗为110 W,由式(6)得出参数a≈0.5.同样方法可得到出现散热故障的DataNode节点CPU利用率与功耗之间的理论函数:
P(u)=70+0.65u.
(38)
当节点出现散热故障时,节点静态功耗为70 W,峰值功耗为135 W,参数a≈0.65.值得一提的是,式(37)(38)及图8中所示的CPU与功耗关系曲线与文献[57]中的结论一致,表明基于CPU利用率估算能耗模型的可行性.
利用基于CPU利用率估算能耗模型对Map-Reduce作业进行能耗计算的唯一前提条件是取得所有任务运行过程中的CPU利用率变化序列.基于CPU利用率估算的能耗模型是将来开发Hadoop能耗优化及监控软件的理论基础.
由于基于主要部件能耗累加的能耗模型不仅考虑了CPU能耗,还考虑了内存、磁盘及网络等部件的能耗使用.所以除了关注作业执行过程中能耗与CPU之间的关系,本实验还对作业执行过程中DataNode节点主要资源(内存、磁盘与网络)进行了监测,WordCount,TeraSort,NutchIndex,K-means,PageRank,Bayes六种作业的内存、磁盘与网络资源运行时状态变化如图9所示:

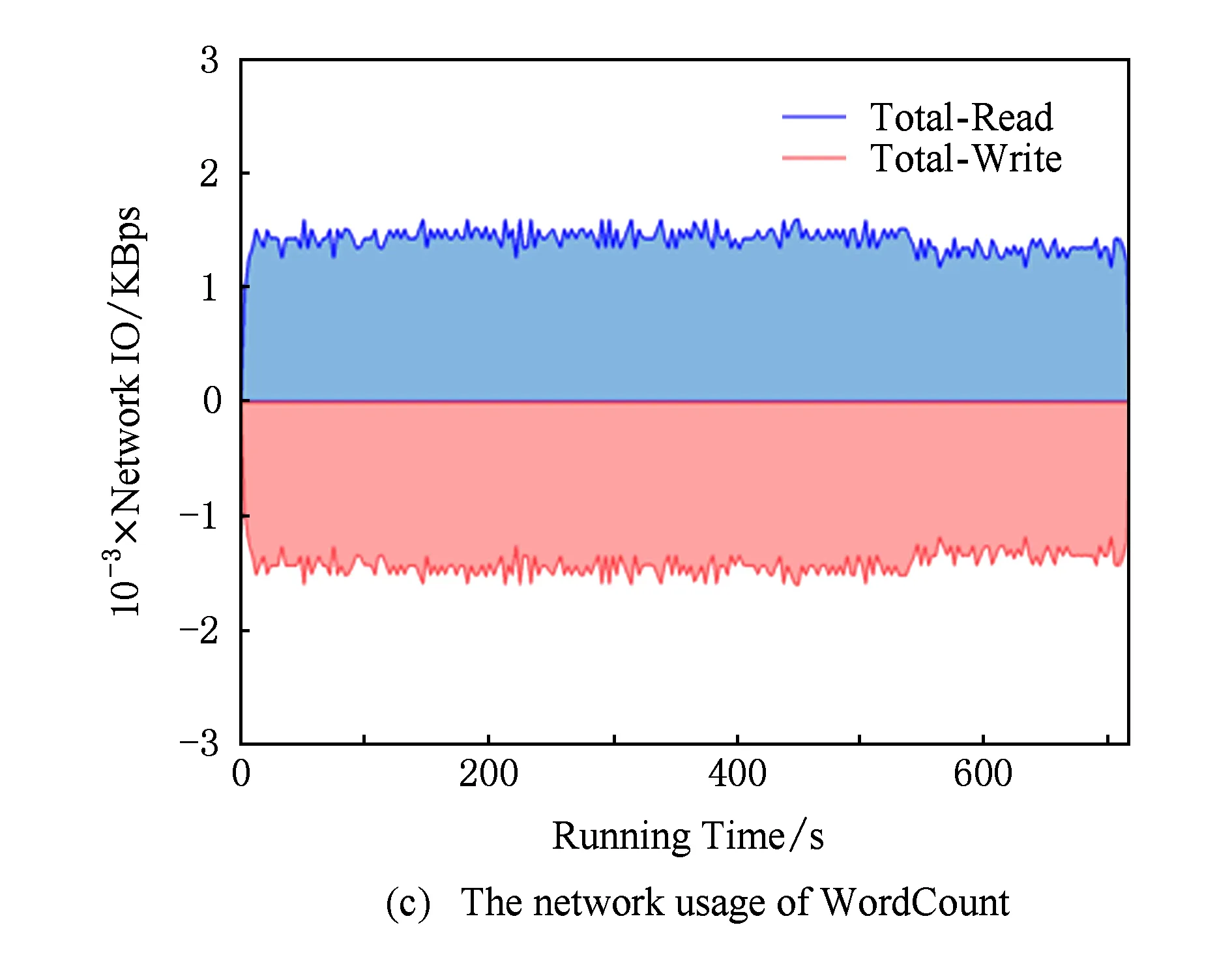
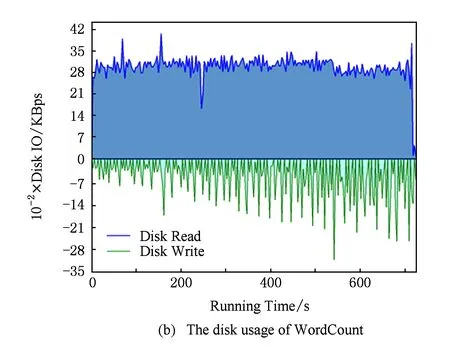
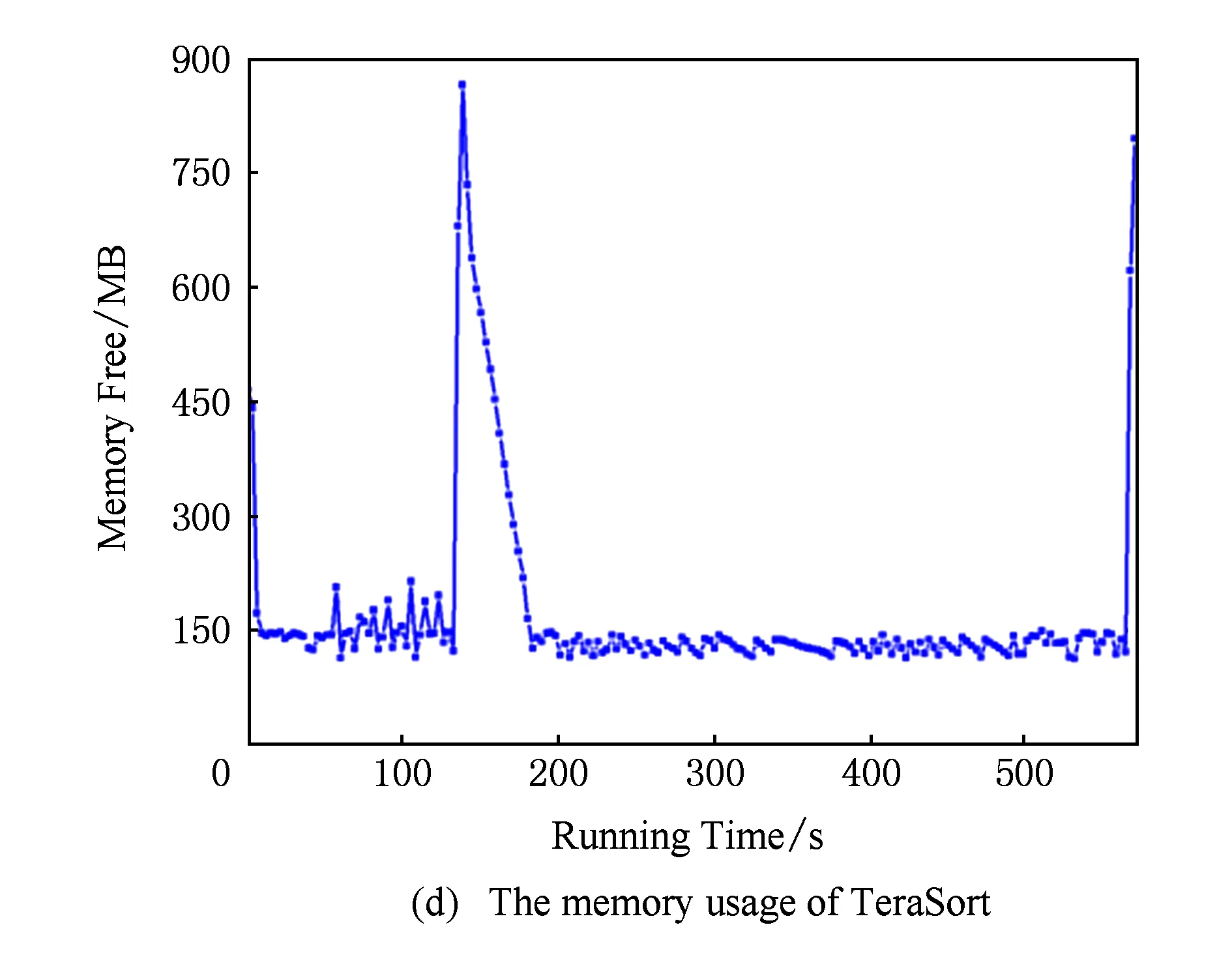


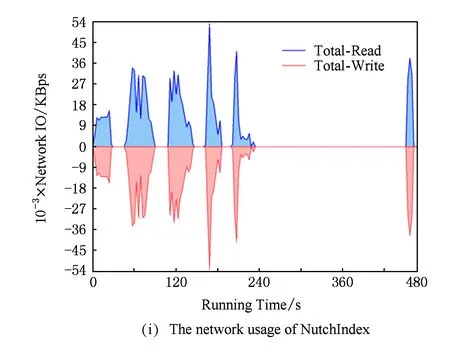




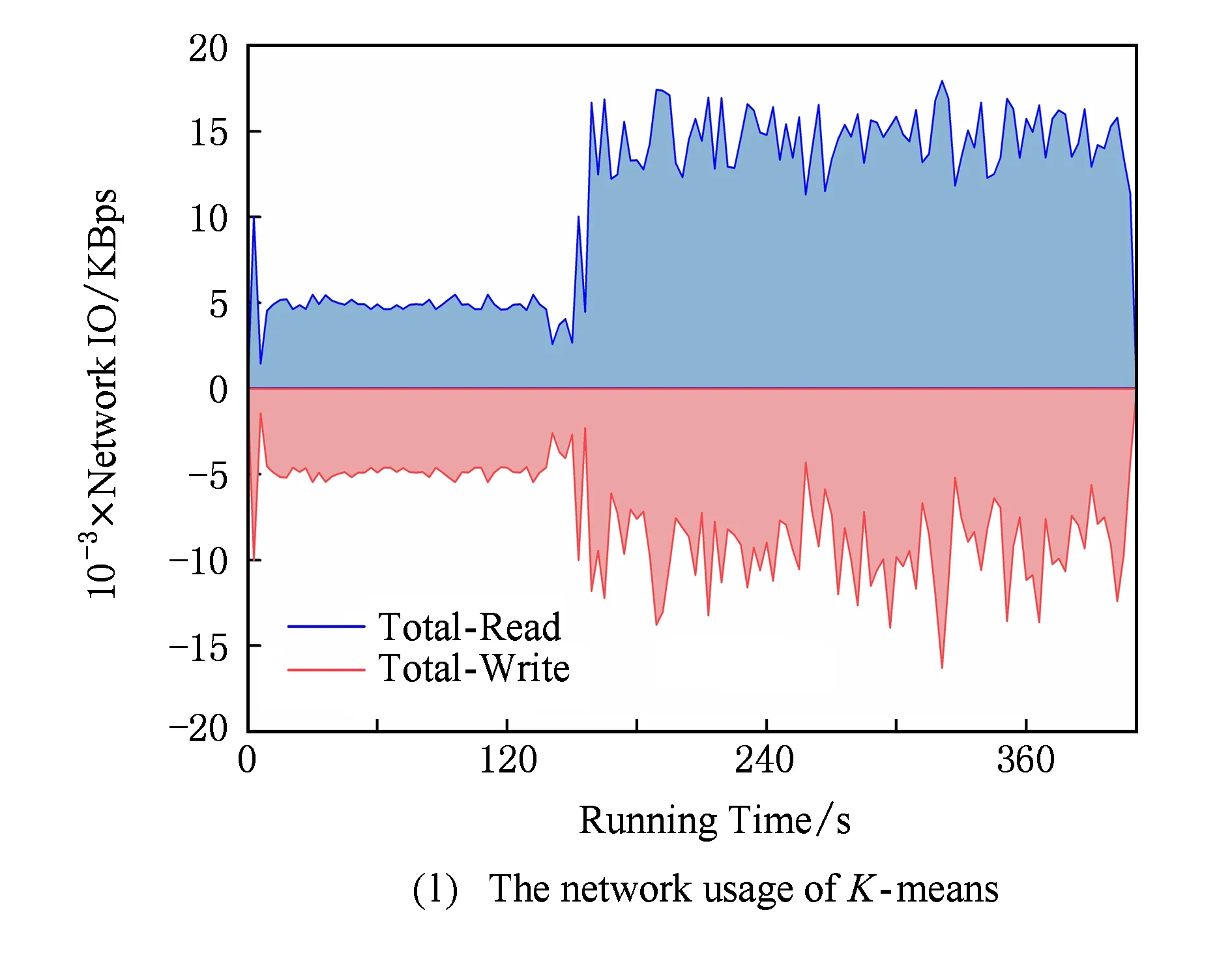







Fig. 9The comparison of memery,disk and network usage while job running.
图9不同作业运行时内存、磁盘及网络资源使用情况对比
通过图9可以看出不同作业在运行过程中的内存、磁盘与网络资源的利用存在较大的差异,并且相同作业在不同时间点资源利用率变化也很大.这使得利用本文2.2.2节中提出的基于主要部件能耗累加的能耗模型进行能耗计算时需要进行大量的计算.确定CPU利用率与能耗之间具有规律性,但归纳内存、磁盘与网络资源利用率与能耗之间的关系则具有较大的难度.虽然基于主要部件能耗累加的能耗模型能够准确地表达任务在执行过程中CPU、内存、磁盘、网卡等各设备的能耗,但由于模型的参数偏多且参数值的取得较为困难,加之资源利用率的动态性,使得基于主要部件能耗累加的能耗模型实践难度较大.
将WordCount,TeraSort,NutchIndex,K-means,PageRank,Bayes六种作业分别执行10次(减小实验误差),详细的记录各作业Map与Reduce任务的开始与结束时间,通过能耗监测仪的采样数据得到每个任务的执行能耗.任务的平均功耗由任务的执行能耗除以任务的执行时间得到,节点对任务的计算能力通过式(21)计算获得.6种作业Map与Reduce任务的平均功耗及计算能力情况如表4所示.其中,WordCount单任务处理数据量为975.88 MB,TeraSort单任务处理数据量为953.67 MB,PageRank单任务处理300 000个页面,K-means单任务处理4 000 000个SAMPLE,Bayes单任务处理30 000个页面.
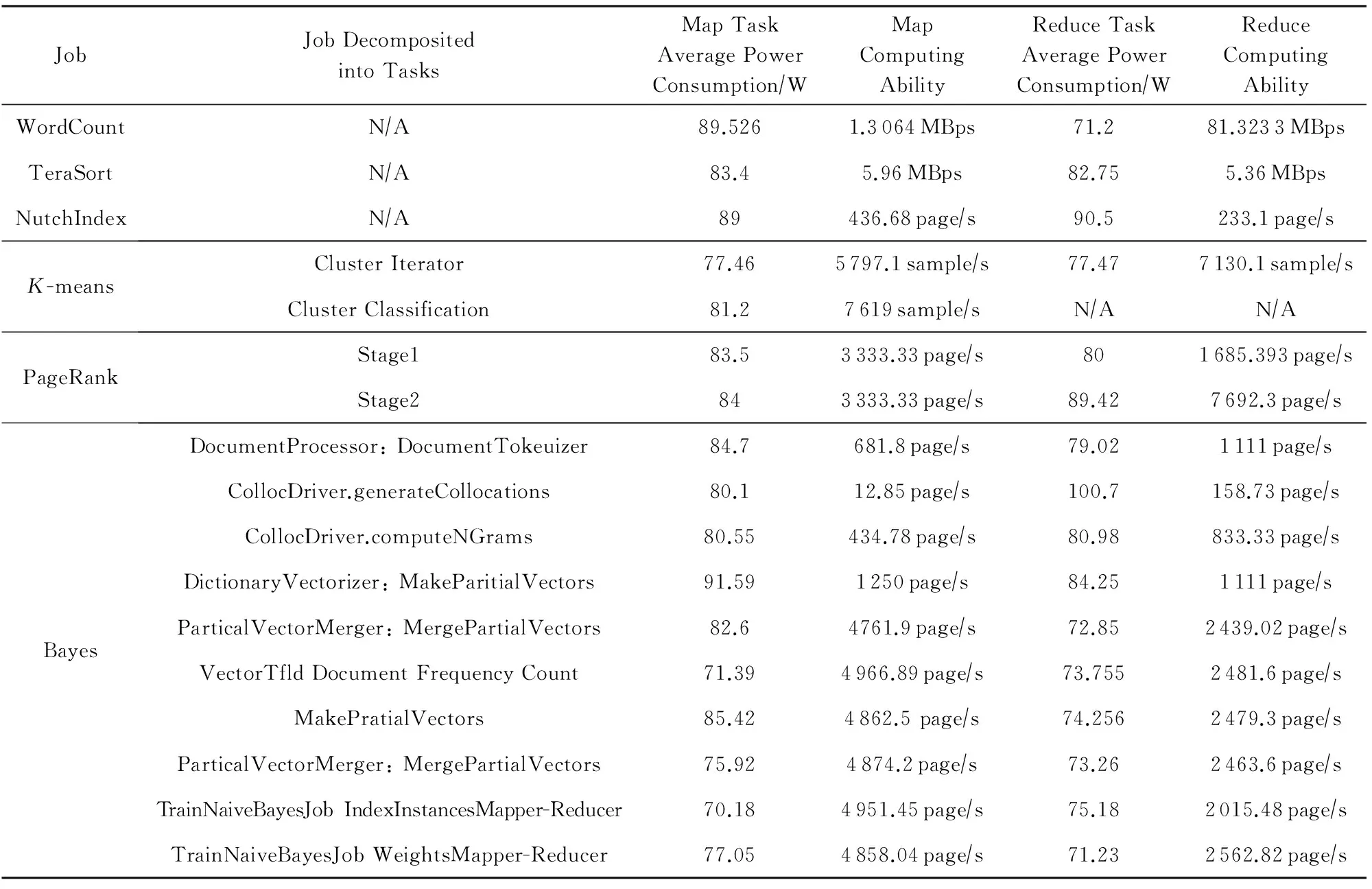
Table 4 Average Power Consumption and Computing Capability of Map and Reduce Task
当作业的任务分解及调度结果确定后,结合表4中的数据,可通过基于平均功耗估算的能耗模型(式(18))对作业的能耗进行预测.对于WordCount,TeraSort,NutchIndex,K-means,PageRank这5种作业,由于作业阶段性任务较少,利用基于平均功耗估算的能耗模型进行能耗预测相比Bayes作业容易.因为Bayes作业多达10个阶段性任务,使得任务的分解及调度复杂度较高,即增加了利用平均功耗估算的能耗模型对Bayes作业进行能耗预测的难度;同时,较多的阶段性任务增大了预测的计算量.值得注意的是,表4表示的是同构集群环境(节点配置如表2所示)中的数据,在异构环境中,由于节点计算能力及能耗属性的不同,大大增加了构造表4数据的难度与工作量.即基于平均功耗估算的能耗模型适合对同构环境中阶段性任务较少(或任务分解与调度较简单)的作业进行能耗预测.由于基于平均功耗估算的能耗模型主要用于作业能耗的预测,并且依赖于作业的分解与调度结果,所以是将来研究节能的MapReduce作业调度系统的基础.
4.3能耗模型运用及误差分析
本节对基于CPU利用率估算的能耗模型与基于平均功耗估算的能耗模型进行运用,选取了Word-Count,TeraSort,Sort,NutchIndex,K-means,PageRank,Bayes七种作业作为研究对象,作业的配置如表3所示.在作业运行前根据作业的任务分解及调度结果,运用基于平均功耗估算的能耗模型对7种作业的能耗进行估算,各任务不同阶段的计算能力及平均功耗如表4所示.作业运行过程中利用能耗监测仪对各任务执行能耗(任务开始到任务结束时间段内节点能耗)进行监测,累加得到作业能耗实际值,并将此能耗值作为基准值.作业执行过程中还需对各任务的CPU利用率进行监测,作业执行完毕后运用基于CPU利用率估算的能耗模型对各作业能耗进行计算(CPU利用率与节点能耗值的对应关系如图8所示).
此外,由于2种能耗模型都是估算模型,难免存在一定程度的误差,表5对2种能耗模型的估算值、能耗测量值及估算误差进行了记录.
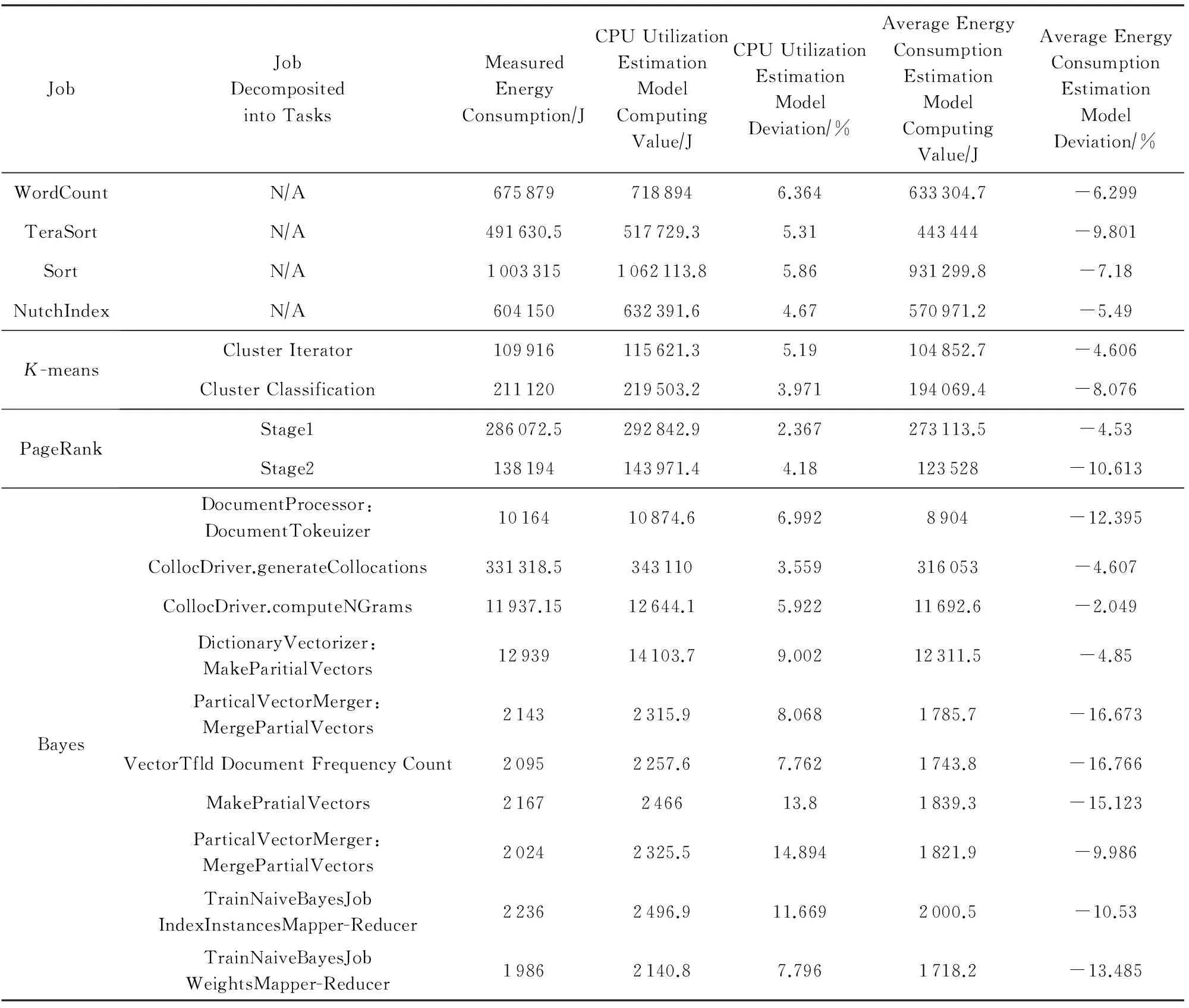
Table 5 The Usage Demonstration and Error Analysis for Energy Model
总结表5中对2种能耗模型的估算值、能耗测量值及估算误差数据可以得到以下4个结论:
1) 基于CPU利用率估算能耗模型的估算值总是比实际测量值大.如图8(a)DataNode节点CPU利用率与功耗之间的关系所示,大多数实验测量值都小于理论值,由于使用式(37)所确定的理论能耗值进行计算,所以造成估算值大于实际测量值.
2) 基于平均功耗估算能耗模型的估算值总是比实际测量值小.基于平均功耗估算的能耗模型在任务分解及调度结果确定后,进行能耗估算时没有考虑到任务的执行失败问题.而在任务的实际运行过程中存在不少任务的失败现象,在对失败任务重调度及重新执行过程中,消耗了额外的能耗,使得估算值小于实际测量值.
3) 基于CPU利用率估算的能耗模型估算值总体上较基于平均功耗估算的能耗模型估算值误差小.这是由于前者是作业完成后的估算,计算过程只依赖于CPU利用率与能耗之间的对应关系,CPU利用率与能耗估算值与实际值之间的误差决定了能耗模型的误差;而后者则是作业运行前的估算,首先需要对每个任务的完成时间进行估算,然后再基于估算的任务完成时间对能耗进行计算,2次估算过程增大了误差.
4) 任务执行时间越短,任务数量越多,估算误差越大.较短的任务执行时间使得能耗采样数据较小,导致能耗测量值本身的误差.
4.4能耗优化方法实验
根据3.1节对能耗优化方法讨论的结果,本节分别对优化MapReduce作业执行能耗及减少MapReduce任务等待能耗2种能耗优化方法进行实验.由于提高MapReduce集群的能源利用效率主要涉及MapReduce作业及任务的调度问题,虽然不作为本文的研究重点,但却是将来的重要研究内容.
4.4.1优化MapReduce作业执行能耗
采用低能耗高效率的硬件设备或体系结构,对MapReduce集群中的高能耗设备进行替换,该方法能够大幅度降低MapReduce作业的执行能耗.但是硬件的更换面临过高的成本问题,该方法已经在文献[59,61-62]中进行了大量的讨论,本文则不对此方法进行重复的实验.本实验将DataNode节点数设置为50,即设置Map与Reduce任务资源槽数各为50,将表3中配置的6种作业随机提交到集群时,可利用式(36)计算满足截止时间要求的Map与Reduce任务数.虽然式(36)中的不同作业不同阶段的完成时间可通过表4已知实验值确定,但多个作业同时提交到系统时,涉及到复杂的MapReduce作业及任务的调度问题,故本文首先考虑解决优化MapReduce单个作业执行能耗问题.对于节能的作业及任务调度研究,是下一步研究的主要内容.以TeraSort作业为例,将任务运行10次取平均数,其任务数与作业完成时间及能耗之间的关系如表6所示:

Table 6 The Relationship between Job Completion Time and Energy Consumption with Different Task Numbers
如图10所示为作业任务数对完成时间及能耗的影响.一方面,理论上任务数越大作业完成时间越小,但实际上任务数目与任务完成时间之间并不呈线性关系,当任务数量增加到某临界点时,作业完成时间并不会因为任务数量的增加而减小(或减小效果不明显);另一方面,随着任务数量的不断增大,作业能耗不断地增加,即完成相同作业,任务数越大,完成该任务能耗越大.这是因为当任务数较多时,任务之间的数据传输增加,任务之间的关联变得复杂,任务协调成本增加,任务启动操作及任务完成后的清理动作增加,以上4方面都导致了能耗的增加.理论上,作业被分解的任务数越少,作业能耗利用率越高;但是作业具有截止时间QoS约束时,需满足作业完成时间deadline约束需求.
利用3.3节提出的截止时间约束下的最小资源槽slot分配方法计算出的作业分解方案,能够在满足作业完成时间deadline约束前提条件下最小化作业执行能耗.所以,截止时间约束下的最小资源槽slot分配方法是一种适应节能的作业的任务分解模型.

Fig. 10 The comparison of job completion time and energy consumption with different task numbers.图10 作业任务数对完成时间及能耗的影响
此外,实验过程中我们还发现,当DataNode节点CPU温度较高时,完成相同的任务,需要消耗更多的能耗.图8(b)所示当CPU温度较高时(70~88℃之间)DataNode节点CPU利用率与功耗之间的关系.即在进行任务与资源之间的绑定过程中,需要考虑CPU的温度.
4.4.2减少MapReduce任务等待能耗
为了构造异构集群实验环境,我们向同构集群中添加了1台性能较差的DataNode节点.实验中异构集群由9台同构DataNode节点(配置如表2)及1台配置为单核Intel Pentium 4 1.5 GHz、512 MB内存及40 GB硬盘的低配节点组成.实验准备阶段,首先对新加入的异构节点计算能力进行测试.测试的方法是在异构节点上运行作业,记录作业完成时间与已有节点进行对比,最后得到异构节点是原节点性能的0.228倍.数据布局阶段,首先按照机架感知的数据块布局策略将7种不同的作业数据进行分布存储,数据块大小相同;再次,按照3.2节中异构环境下数据的放置策略和节点的计算能力进行数据布局,异构节点数据量是原节点的0.228倍.2种布局策略下6种作业(作业配置参数如表3所示)的能耗及完成时间(实验10次平均值)对比如表7所示:
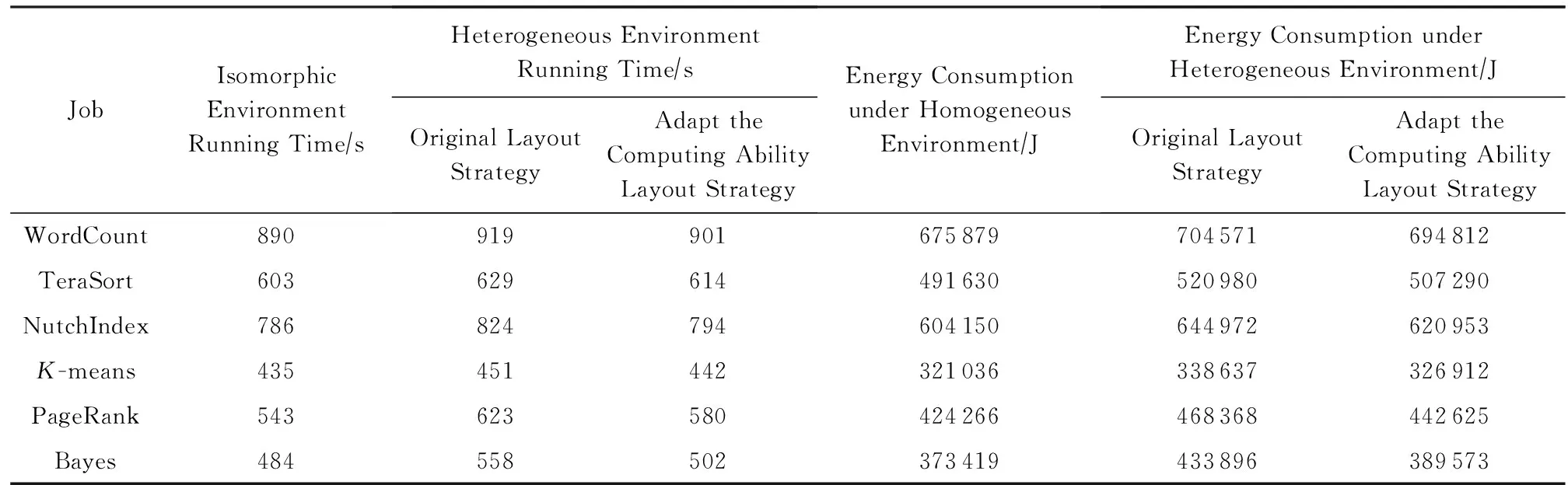
Table 7 Comparison of Job Completion Time and Energy Consumption with Different Data Layout Strategies

Fig. 11 The comparison of job completion time and energy consumption.图11 作业运行时间及能耗对比
如表7数据及图11所示,与异构环境下原数据布局策略(机架感知的数据布局策略)相比较,适应异构集群的数据布局策略(按计算力布局策略)分别提高WordCount,TeraSort,NutchIndex,K-means,PageRank,Bayes作业完成时间18 s,15 s,30 s,9 s,43 s,56 s,提升作业完成时间1.959%,2.385%,3.64%,1.99%,6.902%,10.036%; 分别节能9 759 J,13 690 J,24 019 J,11 725 J,25 743 J,44 323 J,节能率为1.385%,2.628%,3.724%,3.462%,5.496%,10.215%.可以发现适应异构集群的数据布局策略对于WordCount,TeraSort,NutchIndex,K-means四种作业完成时间及节能效率提升并不明显,而PageRank及Bayes有较为明显的提升,这是因为PageRank与Bayes作业Reduce任务需要等待所有Map任务完成才能开始,造成等待时延较长;而其他作业完成部分Map任务Reduce任务就能开始,等待时延较短.所以,利用3.2节中提出的数据布局策略,能够达到减小作业运行时间并提高MapReduce作业能耗利用率的目的.
5 结 论
首先,本文对MapReduce系统模型进行了分析,提出3种任务级的能耗模型:基于CPU利用率估算的能耗模型、基于主要部件能耗累加的能耗模型及基于平均功耗估算的能耗模型,并在这3种模型基础上得到了MapReduce作业能耗模型.其中,基于CPU利用率估算的能耗模型用于作业完成后的能耗的估算,是将来开发Hadoop作业能耗监控及优化软件的理论基础;基于平均功耗估算的能耗模型用于作业运行前的能耗预测,是将来研究节能的MapReduce作业调度系统的基础;基于主要部件能耗累加的能耗模型参数较多,能够清晰地表达作业执行过程中各部件的能耗行为.其次,对MapReduce作业能耗优化进行了分析,提出从单个MapReduce作业的执行能耗与提高MapReduce集群能源效率2个层面,以及优化MapReduce作业执行能耗、减少MapReduce任务等待能耗与提高MapReduce集群能源利用效率3个方向对MapReduce进行能耗优化,并提出异构环境下数据的放置策略及截止时间约束下的最小资源槽slot分配方法分别从减少MapReduce任务等待能耗及MapReduce作业执行能耗2种方法提高能耗利用率.最后,通过大量的实验及能耗数据分析,证明本文所提能耗模型及能耗优化方法的正确性.下一步工作主要集中在以下4个方面:
1) 对基于主要部件能耗累加的能耗模型进行研究,对各部件的能耗参数进行确定,实现对作业执行过程中各部件能耗的精细化监控,并在本文的基础上研究MapReduce执行过程中网络传输的能耗行为及优化方法.
2) 在基于CPU利用率估算的能耗模型基础上,研究并开发Hadoop作业能耗监控及优化软件,实现对MapReduce作业能耗的自动化计算.
3) 基于本文提出的截止时间约束下的最小资源槽slot分配方法及基于平均功耗估算的能耗模型,研究节能的作业及任务调度算法,从提高Map-Reduce集群能源效率角度对能耗进行优化.
4) 设计温度感知的任务资源映射算法,将节点CPU温度状态加入到任务到资源的映射模型中,实现节能的任务资源映射模型.
[1]Meng Xiaofeng, Ci Xiang. Big data management: Concepts, techniques and challenges[J]. Journal of Computer Research and Development, 2013, 50(1): 146-149 (in Chinese)(孟小峰, 慈祥. 大数据管理: 概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-149)[2]Gantz J, Chute C, Manfrediz A, et al. The diverse and exploding digital universe: An updated forecast of worldwide information growth through 2011[EBOL]. 2012[2015-05-25]. http:wwww.ifap.rulibrarybook268.pdf[3]Global Action Plan International. Global action plan, an inefficient truth[EBOL]. 2007[2011-02-12]. http:globalactionplan.org.uk[4]Times N Y. Power, pollution and the Internet[EBOL]. 2012 [2015-05-20]. http:www.nytimes.com20120923technologydata-ceneters-waste-vast-amounts-of-energy-belying-industry-image.html[5]Barroso L A, Hlzle U. The datacenter as a computer: An introduction to the design of warehouse-scale machines[R]. San Francisco, CA: Morgan & Claypool Publishers, 2009[6]Borthaku D. The Hadoop distributed file system: Architecture and design[EBOL]. (2007-07-01) [2015-02-12]. http:hadoop.apache.orgdocsr1.2.1hdfs_design.html[7]Ghemawat S, Gobioff H, Leung S T. The Google file system[C]Proc of the 19th ACM Symp on Operating System Principles. New York: ACM, 2003: 29-43[8]Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[C]Proc of the Conf on Operating System Design and Implementation (OSDI). New York: ACM, 2004: 137-150[9]Wang Peng, Meng Dan, Zhan Jianfeng, et al. Review of programming models for data-intensive computing[J]. Journal of Computer Research and Development, 2010, 47(11): 1993-2002 (in Chinese)(王鹏, 孟丹, 詹剑锋, 等. 数据密集型计算编程模型研究进展[J]. 计算机研究与发展, 2010, 47(11): 1993-2002)[10]Li D, Wang J E. Energy efficient redundant and inexpensive disk array[C]Proc of the ACM SIGOPS European Workshop. New York: ACM, 2004: 29-35[11]Liao X, Jin H, Liu H. Towards a green cluster through dynamic remapping of virtual machines[J]. Future Generation Computer Systems, 2012, 28(2): 469-477[12]Liao Bin, Yu Jiong, Zhang Tao, et al. Energy-efficient algorithms for distributed file system HDFS[J]. Chinese Journal of Computers, 2013, 36(5): 1047-1064 (in Chinese)(廖彬, 于炯, 张陶, 等. 基于分布式文件系统HDFS的节能算法[J]. 计算机学报, 2013, 36(5): 1047-1064)[13]Albers S. Energy-efficient algorithms[J]. Communications of the ACM, 2010, 53(5): 86-96[14]Wierman A, Andrew L L, Tang A. Power-aware speed scaling in processor sharing systems[C]Proc of the 28th IEEE Int Conf on Computer Communications (INFOCOM 2009). Piscataway, NJ: IEEE, 2009: 2007-2015[15]Andrew L L, Lin M, Wierman A. Optimality, fairness, and robustness in speed scaling designs[C]Proc of ACM Int Conf on Measurement and Modeling of Int Computer Systems (SIGMETRICS 2010). New York: ACM, 2010: 37-48[16]Neugebauer R, McAuley D. Energy is just another resource: Energy accounting and energy pricing in the nemesis OS[C]Proc of the 8th IEEE Workshop on Hot Topics in Operating Systems. Piscataway, NJ: IEEE, 2001: 59-64[17]Flinn J, Satyanarayanan M. Managing battery lifetime with energy-aware adaptation[J]. ACM Trans on Computer Systems, 2004, 22(2): 179-182[18]Meisner D, Gold B T, Wenisch T F. PowerNap: Eliminating server idle power[J]. ACM SIGPLAN Notices, 2009, 44(3): 205-216[19]Ye K, Jiang X, Ye D, et al. Two optimization mechanisms to improve the isolation property of server consolidation in virtualized multi-core server[C]Proc of the 12th IEEE Int Conf on High Performance Computing and Communications. Piscataway, NJ: IEEE, 2010: 281-288[20]Choi J, Govindan S, Jeong J, et al. Power consumption prediction and power-aware packing in consolidated environments[J]. IEEE Trans on Computers, 2010, 59(12): 1640-1654[21]Ye K, Jiang X, Huang D, et al. Live migration of multiple virtual machines with resource reservation in cloud computing environments[C]Proc of the 4th IEEE Int Conf on Cloud Computing. Piscataway, NJ: IEEE, 2011: 267-274[22]Liao X, Jin H, Liu H. Towards a green cluster through dynamic remapping of virtual machines[J]. Future Generation Computer Systems, 2012, 28(2): 469-477[23]Jang J W, Jeon M, Kim H S, et al. Energy reduction in consolidated servers through memory-aware virtual machine scheduling[J]. IEEE Trans on Computers, 2011, 99(1): 552-564[24]Wang X, Wang Y. Coordinating power control and performance management for virtualized server cluster[J]. IEEE Trans on Parallel and Distributed Systems, 2011, 22(2): 245-259[25]Wang Y, Wang X, Chen M, et al. Partic: Power-aware response time control for virtualized Web servers[J]. IEEE Trans on Parallel and Distributed Systems, 2011, 22(2): 323-336[26]Dasgupta G, Sharma A, Verma A, et al. Workload management for power efficiency in virtualized data-centers[J]. Communications of the ACM, 2011, 54(7): 131-141[27]Srikantaiah S, Kansal A, Zhao F. Energy aware consolidation for cloud computing[J]. Cluster Computing, 2009, 12(1): 1-15[28]Garg S K, Yeo C S, Anandasivam A, et al. Environment-conscious scheduling of HPC applications on distributed cloud-oriented data centers[J]. Journal of Parallel and Distributed Computing, 2010, 71(6): 732-749[29]Kusic D, Kephart J O, Hanson J E, et al. Power and performance management of virtualized computing environments via lookahead control[J]. Cluster Computing, 2009, 12(1): 1-15[30]Song Y, Wang H, Li Y, et al. Multi-tiered on-demand resource scheduling for VM-based data center[C]Proc of the 9th IEEEACM Int Symp on Cluster Computing and the Grid (CCGrid 2009). Piscataway, NJ: IEEE, 2009: 148-155[31]Gmach D, Rolia J, Cherkasova L, et al. Resource pool management: Reactive versus proactive or let’s be friends[J]. Computer Networks, 2009, 53(17): 2905-2922[32]Buyya R, Beloglazov A, Abawajy J. Energy-Efficient management of data center resources for cloud computing: A vision, architectural elements, and open challenges[C]Proc of the 2010 Int Conf on Parallel and Distributed Processing Techniques and Applications (PDPTA 2010). New York: ACM, 2010[33]Kim K H, Beloglazov A, Buyya R. Power-aware provisioning of cloud resources for real-time services[C]Proc of the 7th Int Workshop on Middleware for Grids. New York: ACM, 2009: 1-6[34]Wang Yijie, Sun Weidong, Zhou Song, et al. Key technologies of distributed storage for cloud computing[J]. Journal of Software, 2012, 23(4): 962-986 (in Chinese)(王意洁, 孙伟东, 周松, 等. 云计算环境下分布存储关键技术[J]. 软件学报, 2012, 23(4): 962-986)[35]Greenan K M, Long D D E, Miller E L, et al. A spin-up saved is energy earned: Achieving power-efficient, erasure-coded storage[C]Proc of the HotDep 2008. Berkeley, CA: USENIX Association, 2008[36]Weddle C, Oldham M, Qian J, et al. A gear-shifting power-aware raid[J]. ACM Trans on Storage, 2007, 3(3): 1553-1569[37]Li D, Wang J. Conserving energy in conventional disk based RAID systems[C]Proc of the 3rd Int Workshop on Storage Network Architecture and Parallel IOs (SNAPI 2005). Piscataway, NJ: IEEE, 2005: 65-72[38]Yao X, Wang J. Rimac: A novel redundancy-based hierarchical cache architecture for energy efficient, high performance storage systems[C]Proc of the EuroSys. New York: ACM, 2006: 249-262[39]Pinheiro E, Bianchini R, Dubnicki C. Exploiting redundancy to conserve energy in storage systems[C]Proc of the SIGMetrics Performance 2006. New York: ACM, 2006: 15-26[40]Narayanan D, Donnelly A, Rowstron A. Write off-loading: Practical power management for enterprise storage[J]. ACM Trans on Storage, 2008, 4(3): 253-267[41]Storer M, Greenan K, Miller E, et al. Pergamum: Replacing tape with energy efficient, reliable, disk-based archival storage[C]Proc of the FAST 2008. New York: ACM, 2008: 1-16[42]Zhu Q, Chen Z, Tan L, et al. Hibernator: Helping disk arrays sleep through the winter[C]Proc of the 20th ACM Symp on Operating Systems Principles (SOSP). New York: ACM, 2005: 177-190[43]Vasic N, Barisits M, Salzgeber V. Making cluster applications energy-aware[C]Proc of the ACDC 2009. New York: ACM, 2009: 37-42[44]Zhu Q, David F M, Devaraj C F, et al. Reducing energy consumption of disk storage using power-aware cache management[C]Proc of the HPCA 2004. Piscataway, NJ: IEEE, 2004: 118-129[45]Chen Y, Keys L, Katz R H. Towards energy efficient MapReduce[R]. Berkeley, CA: EECS Department, University of California, 2009[46]Leverich J, Kozyrakis C. On the energy (in)efficiency of Hadoop clusters[J]. ACM SIGOPS Operating Systems Review, 2010, 44 (1): 61-65[47]Kaushik R T, Bhandarkar M. GreenHDFS: Towards an energy-conserving, storage-efficient, hybrid Hadoop compute cluster[C]Proc of the 2010 Int Conf on Power Aware Computing and Systems. Piscataway, NJ: IEEE, 2010: 1-9[48]Kaushik R T, Bhandarkar M, Nahrstedt K. Evaluation and analysis of GreenHDFS: A self-adaptive, energy conserving variant of the Hadoop distributed file system[C]Proc of the 2nd IEEE Int Conf on Cloud Computing Technology and Science. Piscataway, NJ: IEEE, 2010: 274-287[49]Lang W, Patel J M. Energy management for MapReduce clusters[J]. Proceedings of the VLDB Endowment, 2010, 3(12): 129-139[50]Wirtz T, Ge R. Improving MapReduce energy efficiency for computation intensive workloads[C]Proc of Int Green Computing Conf and Workshops (IGCC). Piscataway, NJ: IEEE, 2011: 1-8[51]Goiri í, Le K, Nguyen T D, et al. GreenHadoop: Leveraging green energy in data-processing frameworks[C]Proc of the 7th ACM European Conf on Computer Systems. New York: ACM, 2012: 57-70[52]Cardosa M, Singh A, Pucha H, et al. Exploiting spatio-temporal tradeoffs for energy efficient MapReduce in the cloud[R]. Minneapolis, Minnesota:Department of Computer Science and Engineering, University of Minnesota, 2010[53]Chen Y, Ganapathi A, Katz R H. To compress or not to compress-compute vs IO tradeoffs for MapReduce energy efficiency[C]Proc of the 1st ACM SIGCOMM Workshop on Green Networking. New York: ACM, 2010: 23-28[54]Song Jie, Li Tiantian, Zhu Zhiliang, et al. Benchmarking and analyzing the energy consumption of cloud data management system[J]. Chinese Journal of Computers, 2013, 36(7): 1485-1499 (in Chinese)(宋杰, 李甜甜, 朱志良, 等. 云数据管理系统能耗基准测试与分析[J]. 计算机学报, 2013, 36(7): 1485-1499)[55]Lin Chuang, Tian Yuan, Yao Min. Green network and green evaluation: Mechanism, modeling and evaluation[J]. Chinese Journal of Computers, 2011, 34(4): 593-612 (in Chinese)(林闯, 田源, 姚敏. 绿色网络和绿色评价: 节能机制、模型和评价[J]. 计算机学报, 2011, 34(4): 593-612)[56]Andrews M, Anta A F, Zhang L, et al. Routing for energy minimization in the speed scaling model[C]Proc of the 29th IEEE Int Conf on Computer Communications (INFOCOM 2010). Piscataway, NJ: IEEE, 2010: 1-9[57]Barroso L A, Holzle U. The case for energy-proportional computing[J]. Computer, 2007, 40(12): 33-37[58]Kansal A, Zhao F, Liu J, et al. Vitrual machine power metering and provisioning[C]Proc of the 1st ACM Symp on Cloud Computing. New York: ACM, 2010: 39-50[59]Harnik D, Naor D, Segall I. Low power mode in cloud storage systems[C]Proc of the IPDPS 2009. Piscataway, NJ: IEEE, 2009: 1-8[60]Bao Y, Chen M, Ruan Y, et al. HMTT: A platform independent full-system memory trace monitoring system[J]. ACM SIGMETRICS Performance Evaluation Review, 2008, 36(1): 229-240[61]Vasudevan V, Franklin J, Andersen D. FAWN damentally power-efficient clusters[C]Proc of the HotOS XII. Berkeley, CA: USENIX Association, 2009[62]Kim H S, Shin D I, Yu Y J, et al. Towards energy proportional cloud for data processing frameworks[C]Proc of the 1st USENIX Conf on Sustainable Information Technology. Berkeley, CA: USENIX Association, 2010: 1-8[63]Liao Bin, Yu Jiong, Sun Hua, et al. Energy-efficient algorithms for distributed storage system based on data storage structure reconfiguration[J]. Journal of Computer Research and Development, 2013: 50(1): 3-18 (in Chinese)(廖彬, 于炯, 孙华, 等. 基于存储结构重配置的分布式存储系统节能算法[J]. 计算机研究与发展, 2013, 50(1): 3-18)[64]Liao B, Yu J, Sun H, et al. A QoS-aware dynamic data replica deletion strategy for distributed storage systems under cloud computing environments[C]Proc of the Cloud and Green Computing. Piscataway, NJ: IEEE, 2012: 219-225
[65]Liao Bin, Yu Jiong, Qian Yurong, et al. The node failure recovery algorithm for distributed file system based on measurement of data availability[J]. Computer Sicence, 2013, 40(1): 144-149 (in Chinese)(廖彬, 于炯, 钱育蓉, 等. 基于可用性度量的分布式文件系统节点失效恢复算法[J]. 计算机科学, 2013, 40(1): 144-149)

Liao Bin, born in 1986. PhD and associate professor in the School of Statistics and Information, Xinjiang University of Finance and Economics. His main research interests include database theory and technology, big data and green computing, etc.

Zhang Tao, born in 1988. PhD candidate in the School of Information Science and Engineering, Xinjiang University. Her main research interests include big data and cloud computing, etc.

Yu Jiong, born in 1964. Professor and PhD supervisor in computer science at the School of Software, Xinjiang University. His main research interests include on grid computing, parallel computing, etc.

Yin Lutong, born in 1992. MSc candidate in the School of Software, Xinjiang University. His main research interests include cloud and green computing, etc.

Guo Gang, born in 1990. MSc candidate in the School of Software, Xinjiang University. His main research interests include data mining and green computing, etc.

Guo Binglei, born in 1991. PhD candidate in the School of Information Science and Engineering, Xinjiang University. Her main research interests include cloud and green computing, etc.

2014年《计算机研究与发展》高被引论文TOP10
数据来源:中国知网, CSCD;统计日期:2016-02-16
Energy Consumption Modeling and Optimization Analysis for MapReduce
Liao Bin1,4, Zhang Tao2,3, Yu Jiong2,4, Yin Lutong4, Guo Gang4, and Guo Binglei2,4
1(SchoolofStatisticsandInformation,XinjiangUniversityofFinanceandEconomics,Urumqi830012)2(SchoolofInformationScienceandEngineering,XinjiangUniversity,Urumqi830046)3(CollegeofMedicalEngineeringandTechnology,XinjiangMedicalUniversity,Urumqi830011)4(SchoolofSoftware,XinjiangUniversity,Urumqi830008)
The continuous expansion of the cloud computing centers scale and neglect of energy consumption factors exposed the problem of high energy consumption and low efficiency. To improve the MapReduce framework utilization of energy consumption, we build an energy consumption model for MapReduce framework. First, we propose a task energy consumption model which is based on CPU utilization estimation, energy consumption accumulation of main components and the average energy consumption estimation as well as the job energy consumption model of MapReduce. Specifically, after analyzing the energy optimization under energy consumption model, we come up with three directions to optimize energy consumption of MapReduce: optimize MapReduce energy consumption of job execution, reduce MapReduce energy consumption of task waiting and improve the energy utilization rate of MapReduce cluster. We further propose the data placement policy to decrease energy consumption of task waiting under heterogeneous environment and the minimum resource allocation algorithms to improve energy utilization rate of MapReduce jobs by the deadline constraints. A large number of experiments and data analysis of energy consumption demonstrate the effectiveness of energy consumption model and optimum policy of energy consumption.
green computing; task scheduling; energy consumption modeling; energy analysis; data layout
2014-12-30;
2016-02-16
国家自然科学基金项目(61562078,61262088,71261025);新疆财经大学博士科研启动基金项目(2015BS007)
TP393.09
This work was supported by the National Natural Science Foundation of China (61562078, 61262088, 71261025) and the PhD Research Startup Foundation of Xinjiang University of Finance and Economics (2015BS007).
