一种改进的恶意PDF文档静态检测方案
2016-09-26孙本阳王轶骏
孙本阳 王轶骏 薛 质
(上海交通大学电子信息与电气工程学院 上海 200240)
一种改进的恶意PDF文档静态检测方案
孙本阳王轶骏薛质
(上海交通大学电子信息与电气工程学院上海 200240)
随着PDF文件的使用日益广泛,恶意的PDF文档不断涌现。现有的恶意PDF文档的检测方案有一定的缺陷,静态检测的准确度较低并且易混淆。提出一种基于改进的N-gram文本提取机制和增强的单一类别支持向量机的机器学习模型的静态检测方案。实验结果表明,该方案提高了静态检测方案的准确率,增加了一定的功能性和扩展性。
恶意PDF文档静态检测单一类别支持向量机
0 引 言
自2008年AdobeReader被发现出第一例关键漏洞以来,PDF已经成为了攻击者的主要目标。针对PDF的攻击方法可以分为三类。第一类是针对AdobeJavaScriptAPI的攻击,这种方法也是发现最早并使用最广的一种。第二类是利用AdobeReader的非JavaScript的漏洞,但是需要使用JavaScript来触发,例如使用堆喷射技术等。第三类是使用嵌入PDF文档中的一些TrueType的漏洞,这一类的攻击方式和JavaScript无关,也很少被使用。与其他的JavaScript的攻击方式相比,例如“由下载驱动”,SQL注入或者跨站脚本,这些JavaScript的攻击方式由于和浏览器,尤其是微软的InternetExploerer直接相关,得到了更为广泛的重视,但基于PDF的攻击在研究中并没有引起大量的关注。目前,针对PDF的攻击绝大多数是与JavaScript相关联的,其检测模式主要有三种:纯静态的检测模式;纯动态的检测模式和动静结合的模式。纯静态的检测模式,是基于PDF的某些特征,比如结构或内容,通过静态提取出文档当中的结构或字符,分析对比,确定是否为恶意。纯动态的方法则是通过构建一个JavaScript的运行环境,检测PDF中嵌入的JavaScript的运行过程,看是否有已知恶意的或敏感的调用过程,从而判断PDF是否为恶意的。动静结合的检测模式则充分利用了静态检测和动态检测的优点,对于大批量的PDF文件,先使用纯静态的检测方法,找出确定的恶意文档和非恶意文档,对于可疑部分,使用动态检测的方法来确定文档的类别。这种方法是要建立在静态检测和动态检测的基础上的,一个良好的静态检测的方法会大大提高初步筛选的效率,能够快速准确地对文档进行恶意、正常或可疑的分类,一个良好的动态检测的方法会使得对可疑文档的检测更为可靠。所以,从研究角度上讲,仍需要从静态检测和动态检测具体的方面来出发。本文主要从静态方面入手,提出一种改进的静态检测方案,提高了恶意PDF文档的检测准确率,并能提供更详尽的攻击模式信息。
1 PDF文档检测的相关知识介绍
1.1PDF文档格式的介绍
PDF即为便携式文档格式。这种文档格式是Adobe公司在1993年用于文件交换而发展出的文件格式,这种方案的优点在于跨平台,由于字体会嵌入文档,在不同的设备上,文件会得到统一的显示,因而得到广泛使用。一个典型的PDF文档通常由Header,Body,Cross-referencetable和Trailer四个部分构成。在一般情况下,PDF的文档解析过程大都首先进行的是查看Header中的版本号和Trailer中的cross-referencetable。通过查看版本号来确认用于分析文档的合适的API等信息,通过查看cross-referencetable,对文档的架构有了一个整体的了解。然后通过cross-referencetable中的文档模块和交叉引用的信息,展示整个PDF文档的内容。
1.2PDF中的JavaScript
PDF文档除了可以展示文字和图片信息之外,还提供了较为复杂的动态表格等功能。这些较为复杂的功能需要使用JavaScript代码来实现,例如有些PDF表格,能够自动检查填写的内容是否符合数据要求,是否为正确合理的日期等数值范围,或是自动在表格填写完成后发送给服务器等。PDF文档标准为实现这些功能提供了丰富的基于JavaScript的API接口。
在PDF文档中,主要用来标明是JavaScript的代码的数据类型是通过/JS关键字,还有一种方式是利用引用的方式,通过/JS关键字指明另一模块是JavaScript代码,这两种方案的对比如表1所示。

表1 两种PDF嵌入JavaScript的方式
表1中的左边的部分定义了一个OpenAction的JavaScript代码,在文档打开时,会输出“HellofromJavaScriptinPDF!”,右边的部分定义了一个OpenAction的JavaScript代码,但执行的内容是在Obj16中,并没有直接显示JavaScript代码的内容,这种方式可以将JavaScript封装在其他的文档模块中,并可能通过加密等手段,隐藏需要执行的内容。除此之外,PDF中的JavaScript还可以用于动态代码的执行,例如eval()函数,也可以重定向至其他页面,例如使用/URL或/GoTo关键字,这些也可以作为一些文档中嵌入的恶意代码执行的入口。
2 相关工作
在现有的研究中,针对恶意PDF文档的检测方法可以分为三种,纯静态检测、纯动态检测以及动态检测和静态检测结合的模式。
2.1纯静态检测模式
这种检测模式是通过提取PDF文档中的JavaScript代码,分析这些JavaScript代码的特征,依据这些特征来判断是否为恶意的,由于这种检测模式不涉及PDF中JavaScript代码的执行,仅仅从代码本身做判断,不需要构建JavaScript解析引擎,检测所需要的时间也是比较短的。例如PJScan[14],这种方法直接提取PDF文档中的JavaScript代码,在语意分析过程中,设置了一些TOKEN,例如,TOK_STR_10,TOK_STR_100,TOK_STR_1000指代码中出现了长度小于10,100,1000的string类型的数据,TOK_LP指代码中出现了左括号。用这些TOKEN建立数学模型,从而判断文档是否为恶意文档。这种方法的缺点是,并没有对JavaScript中的代码做具体的分析,准确度比较低。例如,对于两份完全不同的JavaScript代码,一份代码中有一个String变量的名称有8字节,但存储的数据仅仅是一个“0”,另一份代码中的String变量名称为a,但存储的内容有8字节,在这种检测模式下,两份代码提取出的和该String相关的TOKEN是一样的,均为TOK_STR_10,从而导致这种纯文本的分析易混淆,差错率相对较高。在2013年SrndicN.等提出了一种利用PDF文档结构来判断恶意文档的方法[16],这种方案对PDF的各个模块结构进行分析,将恶意PDF文档结构上的特征作为分析的依据,从而对未知文档进行判断。这种思路较为新颖,但对于攻击者来说,可通过改变结构但不用改变攻击模式即可躲避检测,绕过难度较低。
2.2纯动态检测模式
纯动态方法往往采用多种多样的技术来检测PDF文档打开后的运行情况,通过使用第三方的JavaScript解析引擎,多为浏览器中的JavaScript解析引擎,例如MoziliaFirefox的Spidermokey,Rhino,TraceMonkey和JaegerMonkey,或GoogleChrome中的V8等,并加入堆的监视器,设置合适的监控范围,能够探测到绝大多数的恶意JavaScript代码,具有很高的准确度。但是,这样的检测方法需要较多的时间和空间资源,检测速度比较慢。并且,纯动态检测的基础是嵌入PDF文档的JavaScript代码得到执行,对于一些恶意代码来说,如果设置了版本或其他对应的环境检测,或是因为其他原因,在不符合条件的情况下,并不触发执行恶意代码,从而逃避检测,也不能实现百分之百的检测率。所以,对于纯动态的检测而言,需要尽可能的模拟环境,让每一步跳转指令都尽可能的执行,这样的话需要模拟仿真的参数就非常多,而且同一份文件要在多个环境下检测,所带来的时间上消耗也是非常大的。CWSandbox[15]是纯动态检测中较为典型的例子。CWSandbox使用的是基于行为检测的恶意代码分析模式,对于PDF文档,CWSandbox中加载了一个AdobeReader,在沙箱模式中加载该文件,通过监测系统调用和文档打开的过程来判断文档是否嵌入恶意代码。这种模式的优点是,对于符合环境条件的检测是非常准确的,对于一般的正常的文档来说,不会产生对应的可疑的调用,所以不会被标记为恶意文档。缺点也十分明显,在批量监测中,所花费的时间等成本是比较显著的。
2.3动静结合的检测模式
这种方案结合了动态检测和静态检测的优点,充分利用静态检测的高效和动态检测的高准确度,制定合适的检测方案。由于这种方案是建立在动态检测过程和静态检测过程两个部分的基础上的,所以这种方案的瓶颈仍然存在于寻找一种更为高效的动态检测方案和更准确的静态检测方案。目前最新的MPScan[6]的方案中,采用了对AdobeReader自身的JavaScript引擎直接挂钩,得到代码在执行过程中的op-code,进行对比和分析,和其他方案相比,这种方案由于使用了AdobeReader的JavaScript引擎,而非其他第三方的JavaScript引擎,不需要仿真模拟许多API,减少了搭建JavaScript引擎的复杂度,并且提供了真实完整的PDF格式中的JavaScriptAPI,在获得了op-code以后,对op-code进行静态和动态两方面的检测。这种方案由于利用了某些漏洞,挂钩非开源软件AdobeReader的技术,检测效果是非常出色的,但一旦Adobe公司修补了该漏洞,那么这种挂钩技术就无法实现,后续的操作就无法开展,可持续使用性较低。
3 改进的恶意PDF文档检测方案
PDF文档检测的主要影响因素有:PDF文档中JavaScript的代码提取是否完整;对提取出的JavaScript代码的特征分析是否准确;检测模型是否能够将恶意PDF文档和正常PDF文档区别开来。本节主要阐述了改进的恶意PDF文档的检测方案,基于已有的PDF文档检测方案的缺陷,提出了基于静态检测的改进思路,并建立了更为完善的机器学习模型,从而能够更准确地检测恶意文档。
整个模型建立和检测的思路如图1所示。系统可以分为三个大的模块,为JavaScript代码的提取,JavaScript特征分析和模型建立。通过分析一定量的样本,建立模型之后,将这个模型用于对未知文档的分析中,通过设定一定的权值,来比较未知文档和建立的模型的相似程度,从而判断文档是否为恶意的。
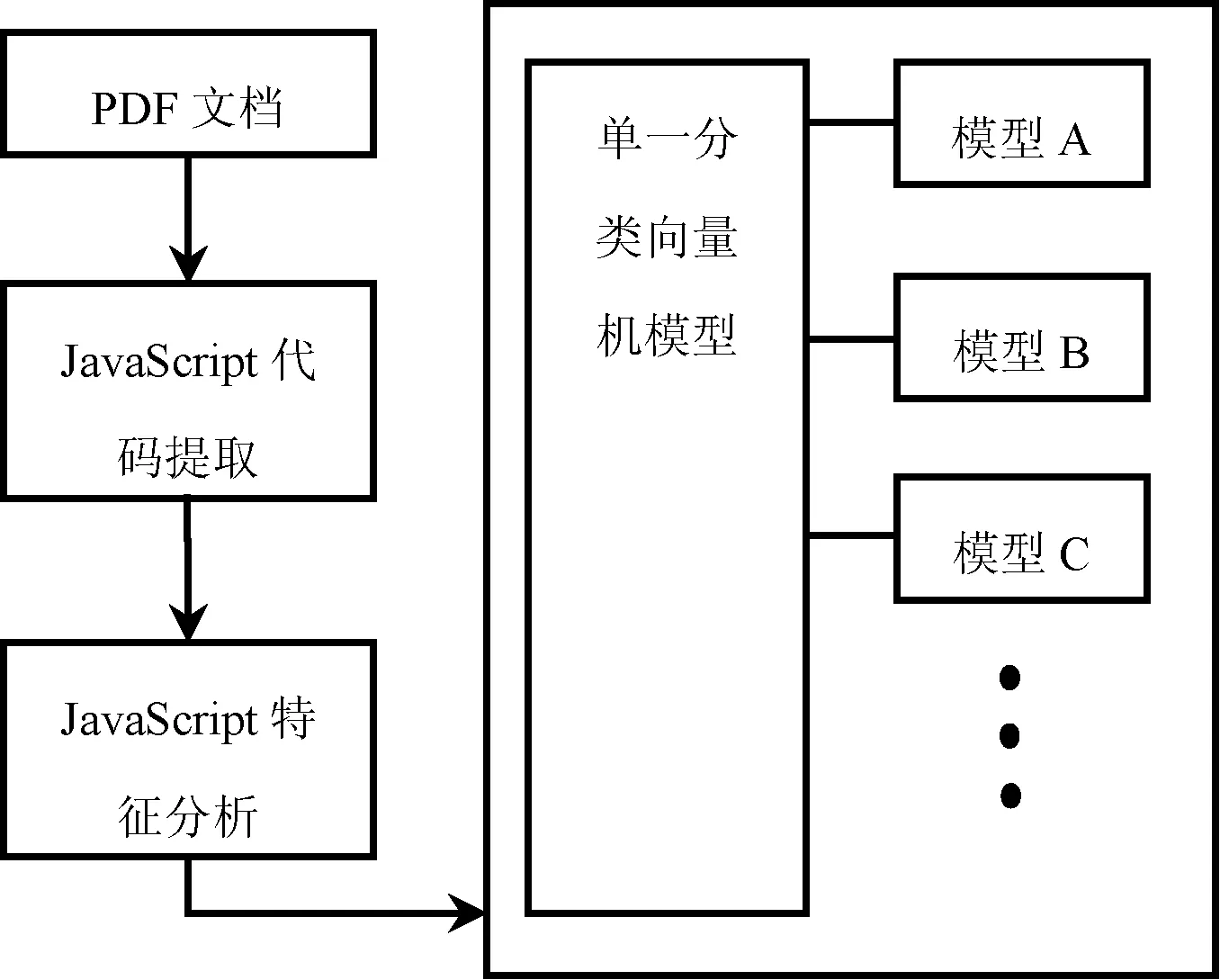
图1 改进的PDF文档检测方案模型
3.1PDF文档中JavaScript代码的提取
由于JavaScript的代码在PDF中的存在模式有两种方式,直接显式的嵌入在/JS模块中和在/JS模块中使用引用的方式,标明另一模块是JavaScript的代码。
通过使用开源的PDF解析引擎和编写的Python脚本,对于直接显示的嵌入在/JS模块中的JavaScript代码,采用直接提取的方式,将模块中的JavaScript代码导出。对于采用引用模式嵌入了JavaScript代码,则查找到/JS关键字后,将引用的模块中的内容导出,作为从文档中提取出的JavaScript代码。
3.2PDF文档提取的JavaScript代码的特征分析
从PDF文档中提取出对应的JavaScript代码后,对于这些代码的分析采用的是改进的N-gram的方法。N-gram是一种基于马尔科夫链的一种常用的文本或语言分析算法,在恶意文档的检测中,提取出连续的长度为N的JavaScript代码,分析这些代码中是否具有某些特征,作为多维向量的数据,用于模型建立。为了防止混淆,提高特征提取的准确度,采用以下改进的措施:
(1) 对JavaScript中的代码进行合理的处理
在原有的静态检测的方法中,大量使用了简单的N-gram方法,从代码中直接提取连续的长度为N的数据进行分析,这些在恶意文档中查找到JavaScript代码中,已经采用了一些混淆的措施,如原有的检测方案是查看代码中是否有String.fromCharCode()关键字,许多比较新的恶意PDF文档中提取的代码中采用的方案是:”Str”+”in”+”g.”+…,类似的混淆方法有很多,大都是采用JavaScript中的加法操作,在原有的分析方法中就难以找到匹配的字符串。对此,改进的方法是利用类似于程序设计语言中编译器检测括号的匹配的算法,用栈来实现,遇到str,就压入栈中,接下来查找到加号,跳过,继续查找到in,压入栈中,重复该过程。使用这种简单的操作,将拆分的关键字合并,从而准确地提取出特征。
类似的混淆的变量还有被大量采用的分段赋值给变量的的shellcode,分多次赋值的用于溢出的var变量,这些大都通过加法操作合并数据的,通过采用合适的入栈出栈操作,将这些代码进行处理,以实现反混淆。
(2) 跳过无关变量名和函数名
在恶意PDF文档提取的JavaScript代码中,还有些常见的混淆代码,给静态检测增加难度的方法是使用较长的随机的字符串作为变量名和函数名,例如functionasdbdafregaeeateageg(),varqewrfabaoijaoijteijngiaodsjfo,如果对这些名称进行匹配和分析,是得不到任何有效的数据,会大大增加文本分析的所消耗的时间,降低模型建立的准确度。所以在实际分析中,直接跳过这些命名,给定一些简单的名称代替进行分析,例如对于var变量,直接跳到等号以后的赋值部分,对于函数,直接跳到括号和函数体,从而提高代码静态分析的有效性。
(3) 加入重复字符串的检测
在分析样本中,有一类比较常见的特征是使用大量重复的字符作为溢出操作的切入点,如申请长变量a=129999999 99999999888888888888887777777777777…等,在shellcode中,也会大量的填充u9090,对于这些特征,可以加入重复字符串的检测,将重复的字符串合并,例如将变量a=129999999999 8888888887777777777…标记为12987…,作为重点的比对特征加以使用。
(4) 针对使用replace()的方法的检测
另外,还有一种恶意代码使用的替换的方法来混淆代码,在申请变量时,使用的是无意义的字符串来代表,在程序运行时,使用replace()函数,将这些无意义的字符串替换为有特殊用意的恶意代码。例如,在申请变量时,给变量赋值为TYCAE,TYCBE等,在代码执行中,使用replace函数,把T替换为%u,这样的方法在动态检测中是可以检测出的,但对于传统的静态检测的方法,是难以分析的。在改进的方案中,检测这种方法,可以和上文中的(3)结合起来,因为这种方法通常是shellcode堆喷射中使用的,如果要实现堆喷射,就需要大量的填充无意义的NOP语句,使得在申请变量时,会出现大量的重复字符串,最后再使用replace函数将这些字符串进行替换。在实际检测中,首先标记出大量重复的字符串,如果后文中有replace关键字,则直接替换掉重复字符串的内容,从而准确地提取出特征。
一些特征关键字如表2所示,将这些特征用多维向量标识出,对每一份PDF文档可以提取出一个特征向量,利用这些向量进行数学运算和分析。
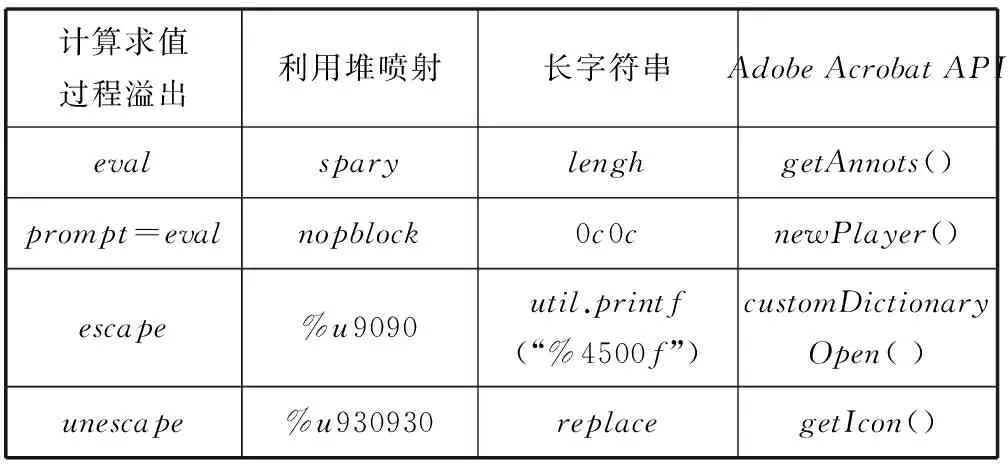
表2 一些恶意PDF静态分析特征
3.3检测模型的建立
本方案使用的恶意PDF文档模型是改进的单一类别支持向量机,其优点在于只需要单一类别的数据来建立一个模型,这种方案在恶意PDF文档检测的模型建立过程中是非常适用的,因为绝大多数使用JavaScript代码的PDF文档都是恶意的。正常使用了JavaScript代码的PDF文档的数目与恶意文档相比是微乎其微的,不足以产生足够的数据用于建立模型,所以利用恶意文档中收集到的特征,建立模型,进行检测。
这种单一类别支持向量机模型对数据的分类方法过程为:通过学习一定量的样本,建立模型O,对于未知样本,计算未知样本提取出的向量和模型O中原点两者之间的欧式距离,设置一定的权值R,当距离在R之内时,认为属于类别O中的,归类为恶意文档,否则为不属于,认为文档是非恶意的。数学描述为:对于样本{xi|xi∈Rm,i=1,2,…,n},选用高斯核函数映射到高维空间,求解最优化问题:
s.t.‖φ(xi)-Oc‖2≤R2+ξi
v∈(0,1)ξi≥0i=1,2,…,n
即将数据点映射到高维空间上,求解出能够包含数据样本的最小超球体的球心Oc和半径R,ξi为松弛因子,v为控制参数,φ(x)为映射函数,又称核函数(对于此类非线性问题,选用高斯函数),m为用于训练的样本数。将恶意PDF文档对应的数据点映射并求解出球心和半径后,未知文档的判别公式为:
f(x)=‖φ(xi)-Oc‖2-R2
当f(x)≤0时,文档被归类为恶意,当f(x)>0时,文档被分类为非恶意。
在实际的分析恶意文档的样本的过程中,发现有些恶意文档的攻击模式具有很大的相似性,类似于病毒的变种。但不同类型的攻击模式之间差异较大,在归一化建立模型的过程中,会损失一部分数据,从而降低检测的准确度。
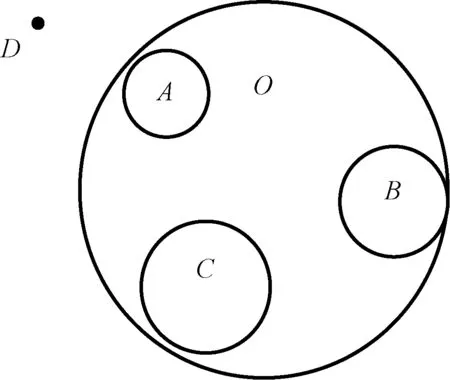
图2 单一类别支持向量机衍生模型
如图2所示,传统的分析模式下,在建立模型的过程中,将A,B,C归一化为O,检测过程中,通过计算未知文档D和O的距离来判定是否为恶意文档。如果采用这种模式,结合恶意文档特有的情况,在设置了某个合适的阈值后,D和O的距离很远,被分类为非恶意的文档,但如果具体分析D和A的距离,那么就会被归类为恶意文档。所以,改进的方案应该是不仅仅建立一个统一的模型O,而且针对可归类的数据建立模型A,B,C。这样,在分析对比时,加入了ABC的模型,准确度会相应的提高,同时可以看出D最有可能是哪一类的攻击模式。在简单情况下,认为只要有一个子模型将样本文档归类为恶意即认为该文档为恶意文档,此时可选择判别函数为:
g(x)=min{fO(x),fA(x),fB(x),…}
则当g(x)≤0时,文档被归类为恶意,当g(x)>0时,文档被分类为非恶意。对于复杂情况,可选择判别函数为:
g(x)=kOfO(x)+kAfA(x)+kOfB(x)+…
此时kO,kA,…为针对子模型设置的权值,当g(x)≤0时,文档被归类为恶意,当g(x)>0时,文档被分类为非恶意。对不同类型不同年份的PDF文档,合理设置权值可以调整子模型的判别函数值对整体的判别函数的影响,从而使检测结果更准确。
在添加样本分类的过程中,可以根据不同的类别,设置不同的距离计算方法,提高某些显著符合该类别的特征在计算距离时的影响因子,充分利用不同类别的攻击方法的特殊性,提高检测的正确率。例如,对于堆喷射攻击模型,将有spray,%u9090,%930930等关键字在计算距离时所占有的权重提高,从而更精确地表达出堆喷射的攻击模型,如果含有这些关键字,那么在分析过程中,极易被分入堆喷射的攻击模型中,从而提高了整体的分析正确率。同时,添加新的样本分类也可以保证较为良好的可扩展性,当新的攻击模式出现时,分析合适的样本,在已有的模型中添加新的分类,静态检测的过程会更加准确。
4 检测结果与分析
本小结所使用的数据是从网络中收集的在2010年至2013年的时间段内的294个恶意文档的样本建立模型。分析测试的样本是网络中收集的从2008年至2013年的4966个恶意的PDF文档和从网络中随机下载的4800个正常的PDF文档进行试验得到的结果。具体结果如表3和表4所示。
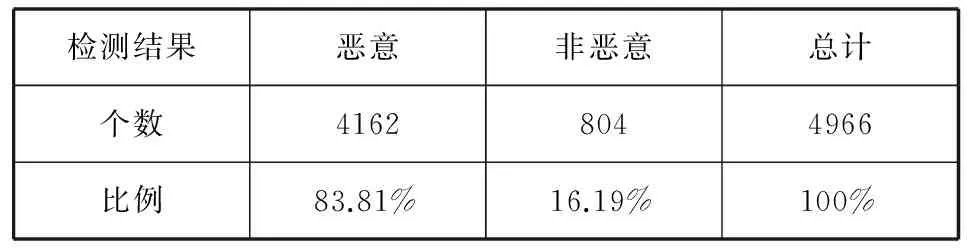
表3 对4 966个恶意文档的检测结果
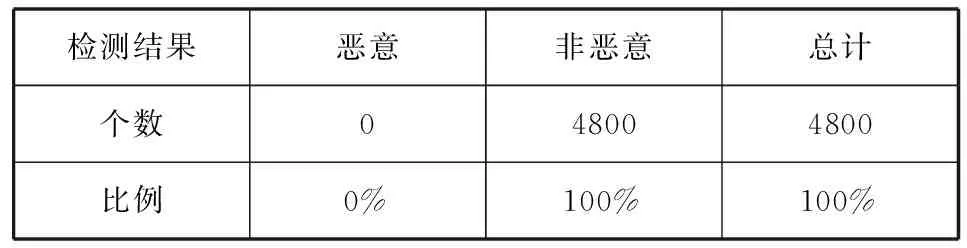
表4 对4 800个正常文档的检测结果
从表3可以看出,对于样本恶意文档的检测正确率为83.81%。从表4可以看出对于正常文档,由于收集到的文档中绝大多数都不含有JavaScript代码,含有JavaScript代码的正常PDF样本也多为表格,使用的是判断表格中填写的是否为日期是否为合适的数字等简单的JavaScript代码,所以被误报的可能性非常小。
如果采用传统的单一模型,检测结果见表5所示。从表3和表5的对比可以看出,如果使用了单一的模型进行检测,恶意文档的检出率是78.39%,比改进模型的检出率83.81%低,这说明在使用了分类的模型后,能够较好地提高检出率。与传统的病毒分析模式不同,恶意PDF的攻击模式相对较为单一,研究人员通过一定时间的分析,通过手动设置更为精确的特征,不断地添加和修改分类,能够使静态分析更为准确,检出率还可以进一步提高。
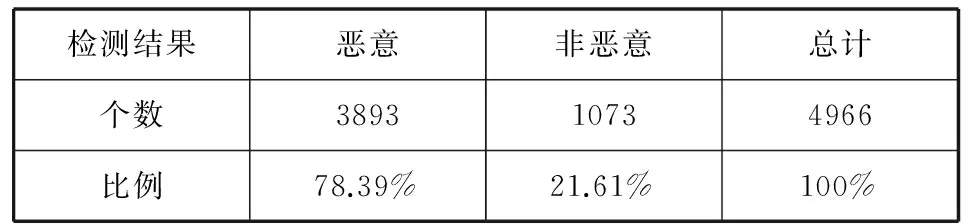
表5 单一模型检测结果
由于其他大多数PDF静态检测方案适用的模型多为2009年之前的方案,对近年来恶意PDF文档的检出率很低,不具有对比意义。其中PJScan是较为典型的使用的是纯静态的检测方案,因此,对同样的样本数据,与PJScan进行对比,对检测率和时间进行分析。结果如表6所示。从表6中可以看出,由于对JavaScript的特征提取更为准确并且加入了子模型的检测,检出率要高于PJScan。但同时由于增加了多模型的检测过程,检测时间多了约5%,但检出率提升了9.77%,对于纯静态的检测方案,检出率的提升是较为明显的。增加了子模型需要更多的模型建立时间,但对检测过程的影响是较少的。

表6 和近年静态方案检测效果对比
除了能够提高准确率外,这种检测方式也能够提供更多的有效信息。例如可以将样本文档按照年份进行分类,利用子模型的检测模式来研究PDF文档的攻击趋势信息,使用其他检测方案不具有该功能。对于样本恶意文档,各个子模型后的检测结果在所有恶意文档中的比例如表7所示。该部分选择19个相对比较显著的子模型,并将不显著的和未能归类的文档标记为其他。从表7可以看出,对于不同的分类,有些分类的在检测时所占的比例比较高,有些类别的检测结果所占比例非常小,这和建立子模型时选择的模型特征和参数有很大的关系,同时也反映了不同类型的恶意代码在样本中所占的比例,如果在某一时期某种特定的攻击方式特别流行,那么该时期的文档检测结果会集中于该子模型。表7中类型A是利用变量溢出的攻击模式,类型B是利用堆喷射的攻击模式,这两种方式在收集的恶意PDF文档的样本中较为显著。
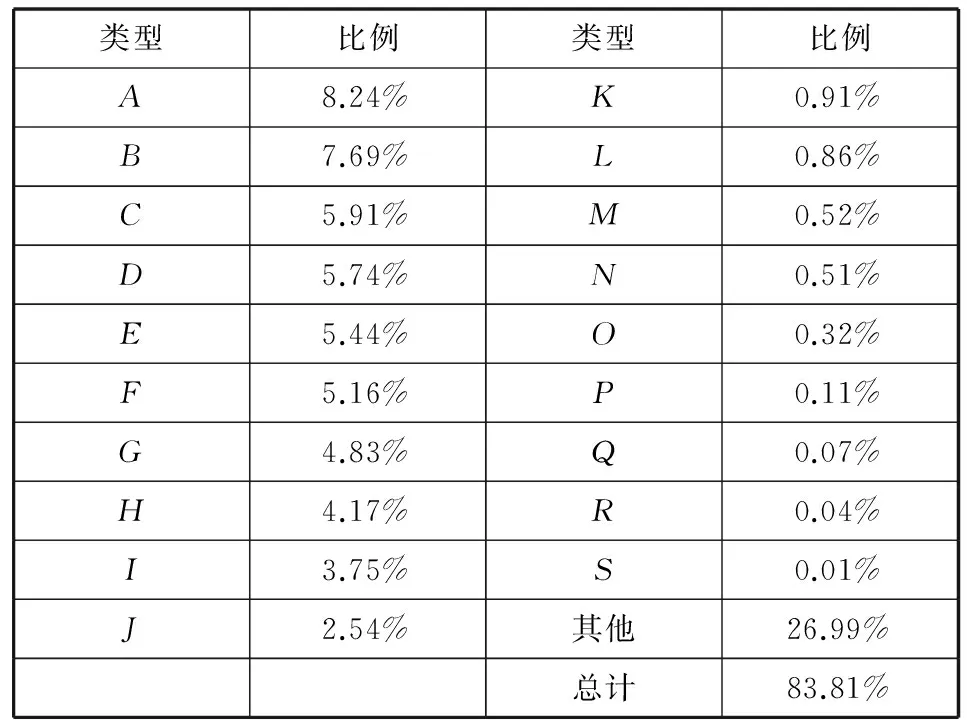
表7 子模型检测结果
实验中分析的样本PDF文档收集的时间是在2013年,选择其中能够确定年份时间的有3511份。这其中,属于类型A的有328份,占9.34%。将这些可以确定样本时间的和CVE漏洞信息库[6]中的和PDF有关的漏洞数目进行对比,A类型的对比结果如图3和图4所示。
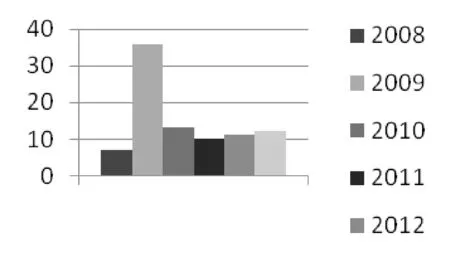
图3 近五年CVE网站统计的A类型值溢出漏洞数目(单位:个)
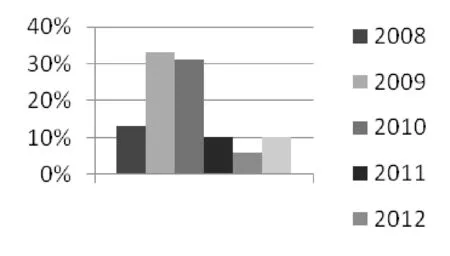
图4 近五年A类型值溢出恶意文档在样本中所占比例
在图3中,A类型值溢出CVE漏洞数目在2009年时最多,有CVE-2009-0193、CVE-2009-1861等31个和值溢出相关的漏洞,从图4可以看出,该类型漏洞的涌现在收集到的恶意文档样本中也得到了很好的体现,在2009年和2010年的恶意文档样本中,利用值溢出漏洞的恶意PDF文档数目最多。随着时间的推进,Adobe公司发布了一系列修补漏洞的补丁,在2011年之后,利用值溢出的攻击方式的恶意文档显著减少。
这种添加了子模型的检测模式也增加了可扩展性。针对新出现的样本,可以在收集到一定的信息之后在检测模型中加入新的模型信息。例如,在2009-2010年间,利用堆喷射技术和shellcode攻击相关的恶意PDF文档大量出现,从收集到的样本来看,2008年堆喷射相关的恶意文档占该年份所有样本的6%,2009年增至27%,2010年达32%。对2010年的样本PDF文档,增加了2009年堆喷射相关的模型信息和未增加2009年堆喷射相关的模型信息检测结果对比见表8所示。从表中可以看出,对2010年样本PDF文档的检测,在增加了2009年堆喷射模型的信息之后,检测率有了较为显著的提高。在实际应用中,一段时期内大量涌现了一种新的基于恶意PDF文档的攻击模式,可以针对这种模式建立新的子模型数据,从而提高静态检测的准确率。

表8 针对2010年样本文档检测结果
从上述实验结果对比可以看出,如果在网络上搭建爬虫系统,采用这种改进的模型,在一定的时间段内对网络中传播的PDF文档进行收集、统计和分析,不仅有较高的准确率,而且能够对于掌握恶意文档代码攻击方式的流行趋势以及针对特定的攻击模式制定相应的检测及防护手段提供很大的帮助。
5 结 语
本文简要介绍了PDF和PDF中的JavaScript的基本理论知识,并提出了一种改进的基于机器学习的模型静态检测方案。通过改进PDF中嵌入的JavaScript代码的分析过程,引入反混淆和简单的处理机制,使特征分析更为精确,并建立更为完善的机器学习模型。通过设置子模型,能够对恶意PDF的攻击模式进行分类,提高了静态检测的准确度,并能提供更多的有效信息。在接下来的研究中,可以加入合适的动态检测的方案,提出一种更为完善的、检测准确率和检测效率都较为满意的动态检测和静态检测相结合的检测系统。
[1] 王清.0day安全:软件漏洞分析技术[M].2版.北京:电子工业出版社,2011.
[2]MaiorcaD,GiacintoG,CoronaI.ApatternrecognitionsystemformaliciousPDFfilesdetection[C]//MachineLearningandDataMininginPatternRecognition.Proceedings8thInternationalConference,2012:510-524.
[3]RobledoHG.AnalyzingCharacteristicsofMaliciousPDFs[J].IEEELatinAmericaTransactions,2012,10(3SI):1767-1773.
[4]ShawR.AnalyzingMaliciousPDFs-InfoSecInstitute[EB/OL].2013.http://resources.infosecinstitute.com/analyzing-malicious-pdf/.
[5]TzermiasZ,SykiotakisG,PolychronakisM,etal.Combiningstaticanddynamicanalysisforthedetectionofmaliciousdocuments[C]//ACM,2011.
[6]CVE-CommonVulnerabilitiesandExposures(CVE)[EB/OL].http://cve.mitre.org/.
[7]LuX,ZhugeJ,WangR,etal.De-obfuscationandDetectionofMaliciousPDFFileswithHighAccuracy[C]//SystemSciences(HICSS),2013 46thHawaiiInternationalConferenceon.2013.
[8]CovaM,KruegelC,VignaG.Detectionandanalysisofdrive-by-downloadattacksandmaliciousJavaScriptcode[C]//ACM,2010.
[9]MitchellTM.Machinelearning[M].McGrawHill,1997.
[10]StevensD.MaliciousPDFDocumentsExplained[J].IEEESecurity&Privacy,2011,9(1):80-82.
[11]Adobe.PDFReferenceandAdobeExtensionstothePDFSpecification[EB/OL].2014.http://www.adobe.com/devnet/pdf/pdf_reference.html.
[12]SchmittF,GassenJ,Gerhards-PadillaE.PDFscrutinizer:detectingJavaScript-basedattacksinPDFdocuments[C]//2012TenthAnnualInternationalConferenceonPrivacy,SecurityandTrust(PST).2012:104-111.
[13]PortableDocumentFormat-Wikipedia,thefreeencyclopedia[EB/OL].2014.http://en.wikipedia.org/wiki/Portable_Document_Format.
[14]LaskovP,šrndicN.StaticdetectionofmaliciousJavaScript-bearingPDFdocuments[C]//ACM,2011.
[15]WillemsC,HolzT,FreilingF.Towardautomateddynamicmalwareanalysisusingcwsandbox[J].IEEESecurityandPrivacy,2007,5(2):32-39.
[16]SrndicN,LaskovP.DetectionofMaliciousPDFFilesBasedonHierarchicalDocumentStructure[C]//Proceedingsofthe20thAnnualNetwork&DistributedSystemSecuritySymposium,2013.
ANIMPROVEDSTATICDETECTIONSCHEMEFORMALICIOUSPDFDOCUMENTS
SunBenyangWangYijunXueZhi
(School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University,Shanghai 200240,China)
WiththeincreasinglywidespreaduseofPDF,maliciousPDFdocumentsareconstantlyemerging.ExistingdetectingschemesofmaliciousPDFdocumentsallhavecertaindefects.Thestaticdetectionisinlowaccuracyandiseasilygarbledaswell.Thispaperpresentsastaticdetectionscheme,itisbasedonimprovedN-gramtextextractionmechanismandenhancedOCSVM(one-classsupportvectormachine)machinelearningmodels.Experimentalresultsshowthattheschemeimprovestheaccuracyofstaticdetectionscheme,andaddssomefunctionalityandscalability.
MaliciousPDFdocumentsStaticdetectionOCSVM
2014-05-19。中国信息安全测评中心科研项目(CNITSEC-KY-2013-009/2)。孙本阳,硕士生,主研领域:信息安全。王轶骏,讲师。薛质,教授。
TP393
ADOI:10.3969/j.issn.1000-386x.2016.03.073
