一种无候选项的闭合序列模式挖掘算法
2016-09-26张万桢陆垂伟
杨 斐 张万桢 陆垂伟
1(湖北理工学院计算机学院 湖北 黄石 435003)2(桂林电子科技大学 广西 桂林 541004)
一种无候选项的闭合序列模式挖掘算法
杨斐1张万桢2陆垂伟1
1(湖北理工学院计算机学院湖北 黄石 435003)2(桂林电子科技大学广西 桂林 541004)
算法CloSpan在挖掘闭合序列模式时分两阶段进行,首先产生候选的闭合序列模式,然后在此基础上挖掘闭合序列模式。针对CloSpan算法中大量候选模式影响挖掘效率的问题,提出改进的算法ssCloSpan。该算法在序列模式增长时,利用支持度和末节点哈希表剪枝非闭合模式,同时利用频繁项头表进行闭合性检测。实验结果表明,对于不含项集项的序列,当存在较长频繁序列时,挖掘效率得到了有效的提高。
闭合序列模式支持数剪枝末节点哈希表频繁项头表
0 引 言
传统序列模式挖掘算法主要是从序列数据库中挖掘出所有满足支持度阈值的频繁序列。从AprioriAll算法到PrefixSpan算法,虽然算法性能总体上得到了提高,但当支持度阈值较低时,都会产生大量符合条件的序列模式。一方面不能高效地从挖掘结果中提取有用的信息;另一方面也使得挖掘效率大大降低,当挖掘时面临的是长序列模式数据库,类似的情况更容易出现[1]。分析得知挖掘得到的序列模式存在大量冗余信息,因此挖掘最大序列模式和挖掘闭合序列模式的问题被提出。
闭合序列模式挖掘的CloSpan算法分两个阶段进行,第一阶段是产生候选集阶段,同时生成前缀序列搜索树;第二阶段是剪枝掉非闭合序列阶段,从而得到全部的闭合序列。在第一阶段中,该算法采用公共前缀及子模式回溯、超模式回溯等策略剪枝生成的前缀序列搜索树,使得PrefixSpan算法结构框架下不断生成投影序列数据库的过程可以提早结束。分析发现,CloSpan算法存在保留候选闭合序列从而影响效率的问题,因此本文提出改进后的ssCloSpan算法,考虑在第一阶段生成前缀搜索树的同时消除所有的非闭合序列,直接得到所有闭合序列模式。
1 相关概念
前缀搜索树中的层: 给定一棵空树,则其层数为0。从根节点开始深度优先遍历其节点时,必定由底层向高层遍历。具体如图1所示。

图1 前缀搜素树层次图
前缀搜索树节点:前缀搜索树节点由六部分组成,分别是项名、支持数、层数、闭合性标记、父节点指针域、下一闭合节点指针域[2]。其中项名即该节点的名称,由于节点亦代表从根节点到当前节点的序列,所以支持数即为该序列的支持数,父节点指针域指向父节点,即序列中的上一个节点,下一闭合节点指针域指向一个闭合序列,该序列的结束项与本节点项相同。
末节点哈希表:该哈希表中的哈希值即为频繁项,指针域指向一系列的以该频繁项为结束项的闭合序列。
频繁项头表:该头表中的内容为频繁项,每个频繁项指向各闭合序列中对应的项节点。
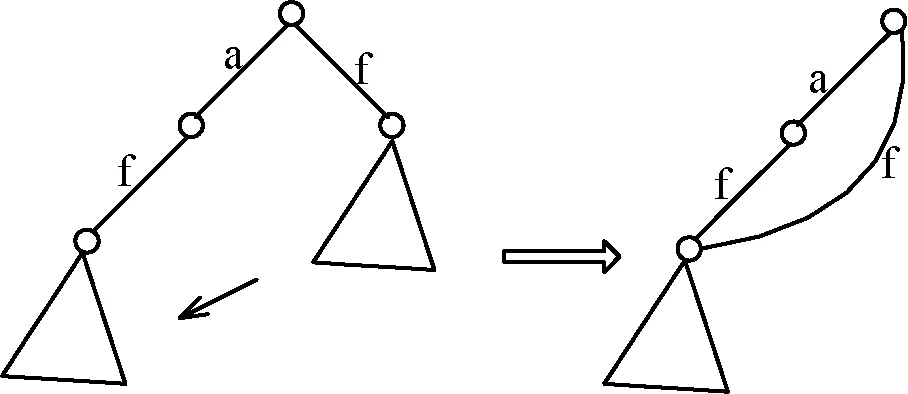
图2 子模式回溯
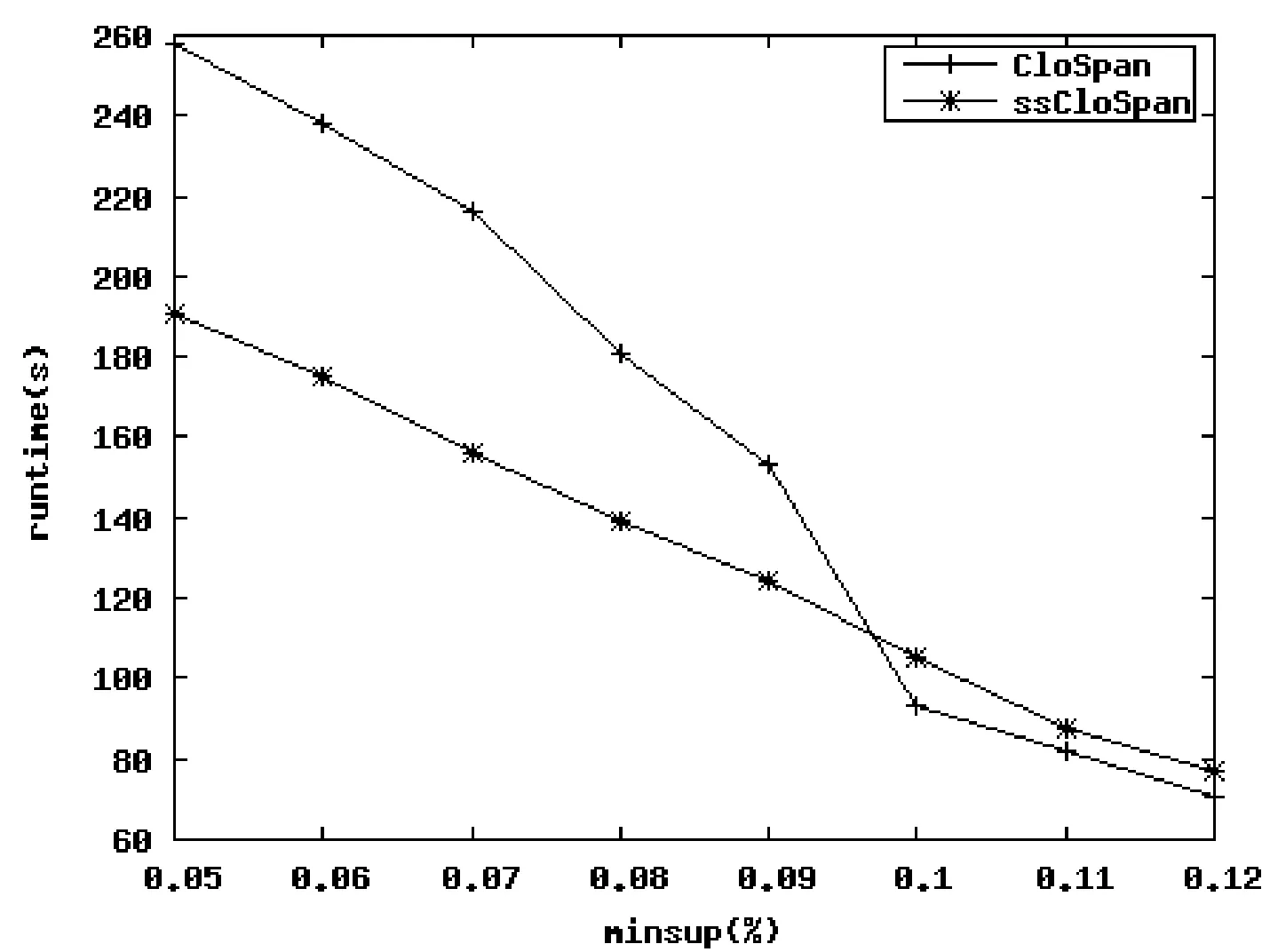
推论1(子模式回溯)如果一个序列s 推论2(超模式回溯)如果一个序列s 图3 超模式回溯 以图3为例,序列 2.1前缀搜索树和超序 通过不断深度优先增长序列实现前缀搜索树的构建,即在某一序列的基础上增长其后续节点,因此,在同一分支上可能有明显的超序产生,形如序列 同一分支上,超序在子序后产生;不同分支上,子序与超序产生的先后关系不确定[3]。因此在不同分支上确定超序的难度较大。然而基于前缀搜索树中各节点有对应的层信息,由超序的基本定义,至少满足超序的长度比子序长,在不同分支上进行超序判断时可借鉴层信息[4],提高闭合性检测的效率。 2.2深度优先策略与支持数剪枝 在序列模式挖掘中,基于序列模式的时间顺序性和连续性,通常采用深度优先的方式挖掘序列[5,6]。在PrefixSpan算法被提出后,几乎所有的算法都是基于此框架结构,闭合序列模式挖掘也不例外。 根据闭合序列的概念,假定在深度优先挖掘过程中会产生闭合序列,那么序列的支持数和序列分支的组合情况如图4所示。 (a) (b) (c) (d)图4 前缀搜索树中支持数大小分布情况 图4中显示了树结构中所有的可能情况,前两个图中深度扩展时仅有一个分支,后两个图代表深度扩展时有多个分支。(a)中节点a的支持数为3,节点b的支持数为2,很显然序列<…a>:3和序列<…b>:2都是闭合序列,由两者不同的支持数值便可推断。而(b)中两节点的支持数都是3,序列<…a>是序列<…b>的子序,闭合序列是<…b>:3。(c)中节点a和节点b的支持数是3,节点c的支持数是2,闭合序列是<…ab>:3和<…ac>:2。(d)中节点a的支持数是3,节点b和节点c的支持数是2,闭合序列是<…ab>:2和<…ac>:2。 由此得出,当某节点的支持数等于其下一级节点的最大支持数时,该节点所代表的序列一定不是闭合序列。当某节点的支持数大于其下一级每个节点的支持数时,该节点所代表的序列一定是闭合序列。而对于序列数较长的序列,该方法能有效提高对非闭合序列的判断效率。 2.3基于末节点哈希表的闭合性检测 序列模式增长的同时,对当前存在的闭合性序列集进行检测。若当前节点为a,此检测以末节点为基础,仅检测以末节点哈希表中哈希值为a的所指链表中的序列。若其中有以a为末节点的子序列,则将该序列从闭合序列中删除。以此对非永久性的闭合序列进行剪枝。 对于给定的字典序a≤b≤c≤d≤e,若有序列 在基于末节点哈希表的闭合性检测中,通过支持数和层数的信息加速检测效率。当末节点哈希表中的节点支持数与当前序列的支持数相同,且层数不大于当前序列的层数时,则进行比较判断子序列的过程,否则直接提前终止。 2.4基于频繁项头表的闭合性检测 受Pei等在文献[7]中提出的H-struct的启发,构建基于频繁项的头表。H-struct中是将首项相同的各交易链成不同的queues,将各queue的对应项保存在一个占用极少空间的头表中。本文将所有闭合序列中相同的项链接成链表,由频繁项头表中相对应的项作为头节点指向该链表。 频繁项头表主要用于对超序的检测,由于子序出现在超序中的位置的不确定性,判断当前序列S是否为子序,可以通过S序列的末节点开始,在头表中找到该项,然后进入链表入口,逐一判断已产生的闭合序列集中是否有自身的超序出现[8]。如果检测到超序,则表明序列S是非闭合序列,可能存在其他非闭合序列,利用末节点哈希表可将其修剪掉。反之,若未检测到超序,则序列S则为闭合序列,加入到闭合序列集中。 在检测时通过支持数和层数以提高检测的效率。当频繁项头表中序列节点的支持数与当前序列的支持数相同,且层数不小于当前序列的层数,则进行比较判断,否则直接提前终止。序列数据库如表1所示。 表1 序列数据库 对于表1所示的数据库,以频繁项a为例,对于第一层: ① 计算I(Ds);默认字序为深度优先挖掘的顺序即:a≤b≤c≤d≤e≤f。首先计算I(D)=21。同时得到频繁项:4, ② 根据情况判断是否将该点加入数据库大小哈希表IH中对应的指针链表,并更新前缀搜索树L;将a加入到前缀搜索树L;IH中无哈希值21,故将21加入到IH中,同时将a链入到相应的指针域。 ③ 根据支持数情况判断是否需要更新末节点哈希表LH以及频繁项头表FH;由于support()=support( 图5 前缀搜索树中加入节点a后的图示 第二层:根据深度优先挖掘的原则,且a存在下一层节点:4, 第三层:采用与第二层同样的步骤考虑节点 图6 前缀搜索树中加入多个节点后的图示 根据递归算法,返回第二层继续对 图7 a分支深度优先挖掘结束后的前缀搜索树 2.5ssCloSpan算法的主要步骤 ssCloSpan算法的主要步骤如下: (1) 扫描数据库一遍,得到满足支持度阈值min_sup的所有频繁项,即频繁1-序列。根据频繁项划分搜索空间。 (2) 在各搜索空间上,分别递归执行以下操作步骤: ① 对于当前的节点a,扫描其投影数据库,得到投影数据库中的频繁项及各频繁项的支持数,同时得到当前节点的I(Ds)值。 ② 从数据库大小哈希表IH中查找是否存在与I(Ds)值相同的子序或超序,以此进行子模式回溯或超模式回溯,达到提前终止扫描投影数据库的目的,以提高算法效率[9]。 ③ 若当前节点a未被②剪枝掉,则加入构建的前缀搜索树中,否则结束。 ④ 若a节点的支持数等于后续频繁项的最大支持数,则可确定该序列为非闭合序列,同时利用基于末节点的闭合性检测方法,检测已有闭合序列在各分支上的闭合性,之后进行深度优先模式增长。若a节点的支持数大于其后续各频繁项的最大支持数,则该序列是当前分支的闭合序列,利用基于频繁项头表的闭合性检测方法检测其在不同分支上的闭合性。如果检测后发现该序列为不同分支上的闭合序列,则反向以该序列为基础,通过基于末节点的闭合性检测,反测已发现序列的闭合性。如果该序列不是闭合序列,则进行深度优先模式增长。 反复执行以上各步骤,最后形成的末节点哈希表就是所有闭合序列模式的链表。 2.6ssCloSpan算法的伪代码 为了更清晰地描述ssCloSpan算法的基本思想及主要步骤,特给出如下的形式化伪代码加以说明。 算法ssCloSpan(S◇α,DS◇α,min_sup,L,LH,FH) 输入:序列S◇α及其投影数据库DS◇α和最小支持度阈值min_sup 输出:前缀搜索树L 方法: 1:调用子程序flag1=CheckProjection(S◇α,k,IH,L) 2:ifflag1=0then 3:return; 4:endif 5:ifflag1=1then 6:令flag2=1; 7:扫描DS◇α一遍,找出每个频繁项β及其支持数 8:if∃support(α)=support(β) 或FH为空then 9:return; 10:elseif∀support(α)>support(β) 或 不存在频繁项βthen 11:调用flag2=SupS(S◇α,LH,FH); 12:ifflag2=0then 13:for当前分支上闭合性标记为0的节点 14: 调用SubS(S◇α,LH,FH); 15:endfor 16:endif 17:endif 18:endif 19:for每一个βdo 20:调用ssCloSpan(S◇α◇β,DS◇α◇β,min_sup,L,LH,FH) 21:endfor 22:return; 其中代码第1行是用来提前终止模式增长的判断,在此过程中已实现超模式回溯和子模式回溯的剪枝;第8行和第9行根据支持度的值进行当前分支非闭合序列的判断,并提前结束;第10行和第11行根据已有闭合序列集中是否存在当前分支闭合序列的超序来确定当前序列是否为最终闭合性序列。第14行是对子程序SubS的调用,由支持度值和flag2的值共同决定,其中flag2的值为0,表示在频繁项头表中不存在当前序列的超序。 子程序CheckProjection(S◇α,k,IH,L) 输入:序列S◇α及其关键码k(即为I(DS◇α))和数据库大小哈希表IH,前缀搜索树L 输出:更新的哈希表IH 方法: 1:根据关键码k索引数据库大小哈希表IH 2:ifIH中不存在哈希值kthen 3:flag1=1; 4:将k值加入到IH中 5:将α插入到L中 6:else 7:if检测到k值对应的序列链中有(S◇α)⊆S′或者S′⊆(S◇α)then 8:flag1=0; 9:修改前缀搜索树L中的指针链接 10:endif 11:returnflag1; 该子程序用来提前结束序列模式的增长,以flag1为结束的标志。对于数据库大小哈希表IH中哈希值与I(DS◇α)相等的序列链,若发现有S◇α的超序或者子序,则可以提前终止。 子程序SubS(S◇α,LH,FH) 输入:序列S◇α,末节点哈希表LH和频繁项头表FH 输出:更新的末节点哈希表LH和更新的频繁项头表FH 方法: 1:对于当前节点α及其顺序递增的闭合性标记为0的父节点 2:记当前的末节点为t,根据关键码t,索引末节点哈希表LH 3:if在LH中找到值tthen 4:fort指向的链表中的每一个序列Tdo 5:if该序列T是当前序列的子序列then 6:删掉LH中的序列T 7:删掉FH中的序列T 8:endif 9:endfor; 10:endif; 11:将α加入到索引末节点哈希表LH中 12:return; 该子程序用来检测闭合序列集中是否存在S◇α的子序列,以修剪掉临时性的闭合序列。第1行中,当某父节点的闭合性标记为1,则停止向上一级父节点检测。第4行至第9行是发现子序列的处理,可以利用层数和支持数信息加速对比查找。 子程序SupS(S◇α,LH,FH) 输入:序列S◇α,末节点哈希表LH和频繁项头表FH 输出:更新的末节点哈希表LH和更新的频繁项头表FH 方法: 1:根据关键码α,索引频繁项头表FH 2:flag2=0; 3:ifFH中关键码αthen 4:forFH中α指向的链表中的每一个序列Tdo 5:ifT⊃(S◇α)then 6:flag2=1;break; 7:returnflag2; 8:endif 9:endfor; 10:endif; 11:将S◇α序列中以α为开始,直到某个父节点闭合性标记为1之间的所有节点加入到频繁项头表FH中 12:returnflag2; 该子程序用来检测闭合序列集中是否存在S◇α的超序列,并以flag2的值作为判断的标志。其中第5行判断超序列时,利用支持数和层数的信息加速比较判断。第7行中的break语句表示只要找到一个超序则停止继续查找,因为此时足以确定序列S◇α不可能为闭合序列。第11行中实现了对加入频繁项头表FH中的节点的剪枝,以减少后续的比较次数。 算法CloSpan在挖掘闭合序列模式的第一阶段采用子模式回溯和超模式回溯,提前结束在某些分支上的挖掘,减少不必要的投影,获得全部频繁模式。第二阶段在此基础上逐一排除非闭合模式,由于基数较大,在一定程度上影响了算法的效率[10]。而算法ssCloSpan在第一阶段就直接获得闭合模式,考虑在同一分支上,闭合序列与非闭合序列的支持数特征,直接删除同一分支上的非闭合序列,同时采用子模式回溯、超模式回溯、频繁项头表剪枝、末节点哈希表剪枝的综合策略,删除不同分支的非闭合序列,特别在处理长序列模式时,同一分支上的优势更为突出,算法性能的优化也更明显。 本文实验环境为CPUIntelCore2.00GHz,2GB内存,Windows7操作系统,算法代码采用C++编写,在VisualC++ 6.0环境下进行编译。实验测试数据采用IBMQuestSyntheticDataGenerator生成,对数据集D10C10N10S6和数据集D5C20N10S10进行测试。测试数据集生成过程中相关的参数为:D表示顾客数,默认值为1000;C表示每个顾客的平均事务数,默认值为10;T表示每个事务的平均项数,默认值为2.5;N表示总项数,设为1000;I表示最长频繁序列的平均长度,设为1.25。实验结果如图8和图9所示。 图8 D10C10N10S6数据集 图9 D5C20N10S10数据集 图8以数据集D10C10N10S6为测试数据,图中可以看出在支持度较高时,两算法的执行时间比较接近,随着支持度的减小,挖掘出来的序列模式越来越多,相应的闭合序列模式也会越来越多,此时算法ssCloSpan的优势得以体现。图9以数据集D5C20N10S10为测试数据的实验结果图,由于在生成数据集时,该数据集的序列长度参数要比D10C10N10S6数据集的序列长度参数设置得更大,因此支持度的设置也相应提高。在挖掘较长的序列模式时,采用不同支持度的情况下ssCloSpan算法性能均优于CloSpan算法。与理论上采用支持数剪枝,快速确定闭合性序列的策略相吻合。 实验结果证明,ssCloSpan算法在挖掘闭合序列模式方面优于CloSpan算法,尤其是在处理含较长序列的数据集时,优势更为突出,实验结果符合理论分析。 本文在分析当前主要闭合序列模式挖掘算法的基础上,根据算法CloSpan中存在候选闭合序列模式的问题,提出了无候选闭合序列的序列模式挖掘算法ssCloSpan。该算法利用子模式回溯和超模式回溯加速深度优先挖掘的前提下,对每次产生的频繁序列进行非闭合性剪枝。剪枝的策略一方面有赖于支持度的数值,另一方面由末节点哈希表快速剪枝掉闭合序列的子序列。同时根据频繁项头表迅速判断当前序列的闭合性。实验结果表明,在处理含较长序列的数据集时该算法在执行效率上优于CloSpan算法。 [1]YanX,HanJ,AfsharR.CloSpan:MiningClosedSequentialPatternsinLargeDatasets[C]//Proc.ofthe3rdSLAMInt.Conf.onDataMining.SanFrancisco,USA:2003:166-177. [2]HanJW,KamberM.数据挖掘:概念与技术[M].北京:机械工业出版社,2007. [3]HalawaniSM,ZubairKhanM.AStudyofCustomerBehaviorandSalesPromotionUsingGeneralizedSequentialPatternMining[J].InternationalJournalofEngineeringandTechnology,2010,2(2):149-154. [4] 王丹丹,蒋文娟.一种新的工作流频繁闭合模式挖掘算法研究[J].计算机科学,2012,39(11):153-156. [5] 公伟,刘培玉,贾娴. 基于改进PrefixSpan的序列模式挖掘算法[J].计算机应用,2011,31(9):2405-2407. [6]PeiJ,HanJ,LuH,etal.H-Mine:Hyper-StructureMiningofFrequentPatternsinLargeDatabases[C]//Proc.ofthe2001IEEEInt.Conf.onDataMining.SanJose,USA:2009:441-448. [7] 王翠青,陈未如.序列模式挖掘支持度阈值的确定方法[J].计算机工程,2010,36(8):93-95. [8]LinJR,HsiehCY,YangDL,etal.AFlexibleandEfficientSequentialPatternMiningAlgorithm[J].InternationalJournalofIntelligentInformationandDatabaseSystems,2009(3):291-310. [9] 张巍,刘峰,滕少华.改进的PrefixSpan算法及其在序列模式挖掘中的应用[J].广东工业大学学报,2013,30(4):49-54. [10] 付宇,于艳华,宋美娜,等.时序关系下的闭合序列模式挖掘算法[J].北京邮电大学学报,2013,36(4):19-22. ACLOSEDSEQUENTIALPATTERNMININGALGORITHMWITHOUTCANDIDATETERMS YangFei1ZhangWanzhen2LuChuiwei1 1(School of Computer Science, Hubei Polytechnic University, Huangshi 435003,Hubei,China)2(School of Computer Science and Engineering, Guilin University of Electronic Technology, Guilin 541004,Guangxi,China) Whenminingtheclosedsequentialpatterns,thealgorithmCloSpandoesitintwophases.First,itwillgeneratethecandidateclosedsequentialpatterns,andthenbasedonthisitminestheclosedsequentialpatterns.AimingattheproblemofnumerouscandidatepatternsimpactingtheminingefficiencyinCloSpanalgorithm,weproposedanimprovedalgorithmcalledssCloSpan.Thisalgorithmprunesthenon-closedpatternsusingsupportdegreeandlastnodehashtableinthecourseofsequentialpatterngrowth,meanwhileitusesfrequentitemheadertableforclosurechecking.Experimentalresultsshowedthatforthesequenceswithoutitemsetsandwithlongerfrequentsequence,theminingefficiencywaswellimproved. ClosedsequentialpatternSupportnumberpruningLastnodehashtableFrequentitemheadertable 2014-08-30。湖北省自然科学基金项目(2013CFB039);湖北省教育厅重点科学研究项目(D20144403);湖北省教育厅科学研究项目(B2013064);湖北理工学院优秀青年科技创新团队项目(13xtz10)。杨斐,讲师,主研领域:可重构技术、嵌入式系统可信计算。张万桢,讲师。陆垂伟,副教授。 TP311.13 ADOI:10.3969/j.issn.1000-386x.2016.03.066
2 ssCloSpan算法





3 实验及分析

4 结 语
