基于结构特征和元模型的中文表格语义分析方法
2016-09-26张家锐
张家锐 张 涵
1(合肥学院计算机科学与技术系 安徽 合肥 230601)2(赫特福德大学生命与医药科学系 英国 赫特福德郡 AL10 9AB)
基于结构特征和元模型的中文表格语义分析方法
张家锐1张涵2
1(合肥学院计算机科学与技术系安徽 合肥 230601)2(赫特福德大学生命与医药科学系英国 赫特福德郡AL10 9AB)
针对现有技术对中文表格语义分析不够全面的现实,提出基于结构特征和元模型的语义分析方法。使用具有公知性的一阶谓词函数Value(值函数)、Num(数量函数),结合伪编码,对几类最常见的中文表格进行语义分析,获取了中文表格的表面语义、上下文语义、主-子表之间的限制语义、表附属性对表格数据的附加语义、属性值背后隐藏的关系语义。实例验证的结果表明,结构特征和元模型是中文表格语义分析的有效方法,获取的语义信息量和种类远超目前的方法。
结构特征元模型一阶谓词函数表面语义上下文语义限制语义附加语义关系语义
0 引 言
中文表格是中文书面文本中最常见的元素之一,具有比普通文字语言更高的精确性和简捷性,在很多领域相关的文本中,经常会使用表格来增强可阅读性、可理解性。因此,对中文表格进行语义分析是中文自然语言理解中不可或缺的部分。中文表格人工理解很方便,机器辨识很困难。目前,对中文表格的语义分析,多数是将研究对象限定为Web页面中基于HTML标签的电子表格,方法大致有如下几种[1]:内容树[2,3]、基于本体使用隐马尔可夫模型[4]、领域本体[5]、启发式规则[6]、正则表达式匹配[7]、基于集成的半自动化方法[8]、人工解释表格结构的半自动化方法[9],目的是通过语义抽取表格数据。在利用表格的半结构化特征来获取其语义方面,杨海涛[10]按表头的形态把表格分为:典型关系表格、可规范的关系表格、带指标森林表头的表格。赖中华[11]提出列分割、嵌套列表头跨度识别、行分段、单位识别、表格展开方式识别和表格标题识别的表格结构识别方法,把表格的物理结构规整化到逻辑结构后解读其语义。陈竞波[12]运用报表数据语义对象化处理技术,对报表数据与报表结构进行解耦,将报表数据与其语义信息封装成语义对象,并通过报表公式来描述数据对象之间的运算或约束关系。冯晓晨[13]的研究重点是表格属性之间的关系(同义/概念分类/特性关系/值的类属模式等)语义。尹文生[14]通过建立属性取值的识别规则和语义脉络树来获取表格的值语义。总之,目前的方法只对表格的表面语义(值语义)进行分析[10,11,13,14],虽然文献[12]加入了表格的运算和约束语义,但表格的上下文语义、主-子表间的限制语义、表附属性对表格的附加语义、表内属性值之间的关系语义皆未被考虑。鉴于此,针对中文书面文本中几类常见的中文表格,在以文献[10,11]方法进行表格样式解析的前提下,提出一种基于结构特征和元模型的中文表格语义分析方法,便于获得中文表格更全面的语义,希望能部分弥补目前方法的不足。
1 常见的中文表格类型
中文表格虽然不像中文文本语句那样丰富多彩、充满限制和歧义,但其类别繁多、难以穷尽,所以至今也没有一种标准的分类方法,本文仅面向应用中最典型、最常见的几类中文表格进行研究。
定义1栏目的值与且仅与某一个属性及其约束相关的表格为一维表格。如表1所示。
表1单位及信息专管员基本信息表
单位盖章:
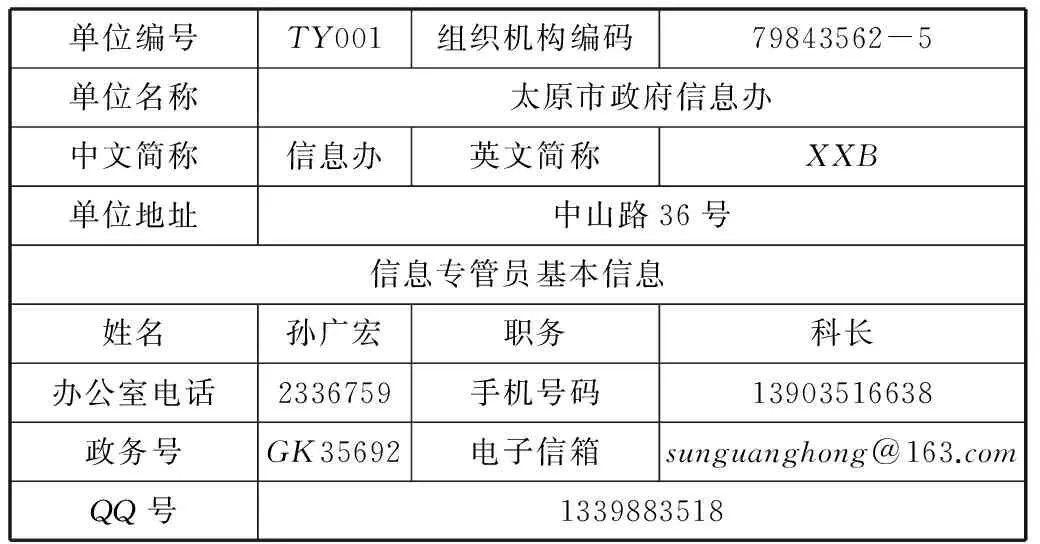
单位编号TY001组织机构编码79843562-5单位名称太原市政府信息办中文简称信息办英文简称XXB单位地址中山路36号信息专管员基本信息姓名孙广宏职务科长办公室电话2336759手机号码13903516638政务号GK35692电子信箱sunguanghong@163.comQQ号1339883518
填表人:王拥军填表日期:2014-04-08
定义2栏目的值与且仅与横、纵两个属性及其约束相关,且这两个属性之间一般有“定语+名词”或“定语+数词”或“定语+量词”构成关系的表格为二维表格。如表2所示。
表2某项目设备预算表
填表日期:2014年5月16日货币单位:元
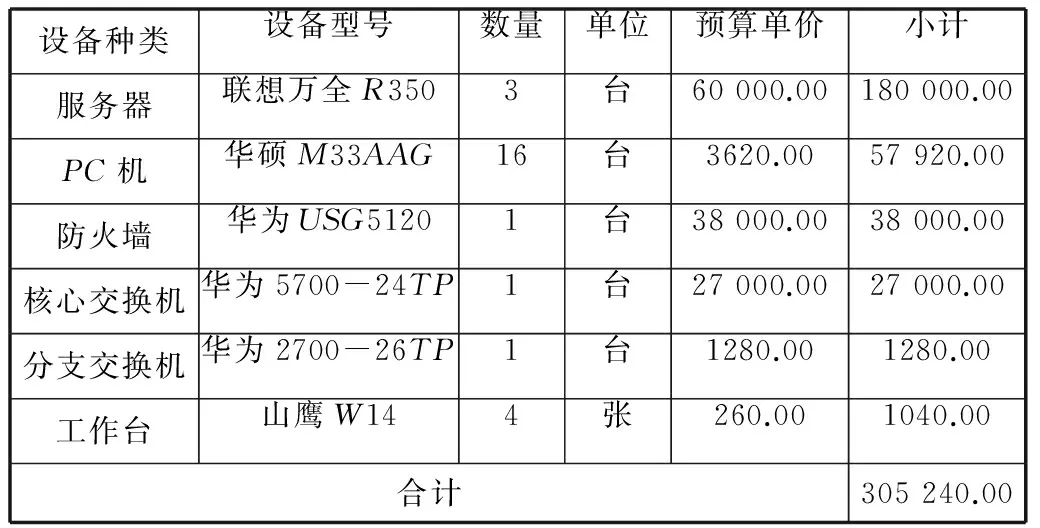
设备种类设备型号数量单位预算单价小计服务器联想万全R3503台60000.00180000.00PC机华硕M33AAG16台3620.0057920.00防火墙华为USG51201台38000.0038000.00核心交换机华为5700-24TP1台27000.0027000.00分支交换机华为2700-26TP1台1280.001280.00工作台山鹰W144张260.001040.00合计305240.00
定义3在一维表格中嵌入了另一个表格,该表格与被嵌入的表格之间构成了主-子(master-detail)关系,且一般被嵌入的表格是二维表格,此类表格称为具有主-子关系的一维表格。如表3所示。
表3某公司员工信息表
填表日期:2014-07-01
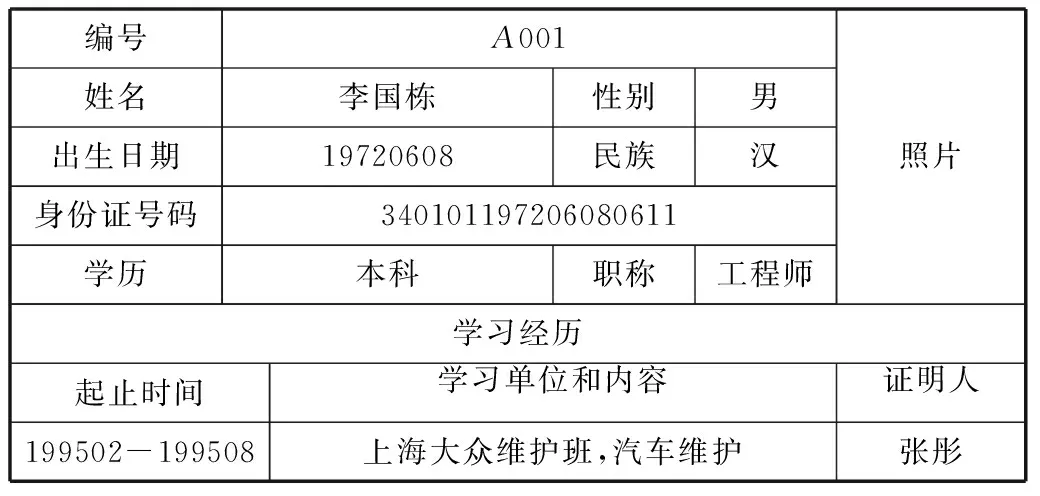
编号姓名出生日期身份证号码学历A001李国栋性别男19720608民族汉340101197206080611本科职称工程师照片学习经历起止时间学习单位和内容证明人199502-199508上海大众维护班,汽车维护张彤

续表1
定义4在二维表格中嵌入了另一个表格,该表格与被嵌入的表格之间构成了主-子关系,同样,被嵌入的表格一般也是二维表格。此类表格称为具有主-子关系的二维表格。如表4和表5所示。
表4某集团公司月度考勤统计表
统计年月:2014年5月
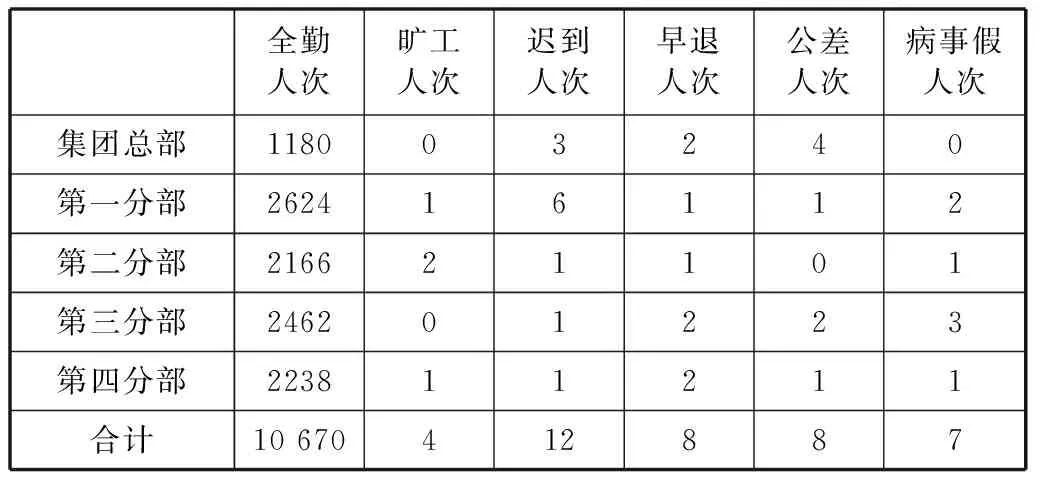
全勤人次旷工人次迟到人次早退人次公差人次病事假人次集团总部118003240第一分部262416112第二分部216621101第三分部246201223第四分部223811211合计10670412887
制表人:刘三保 制表日期:2014年6月1日
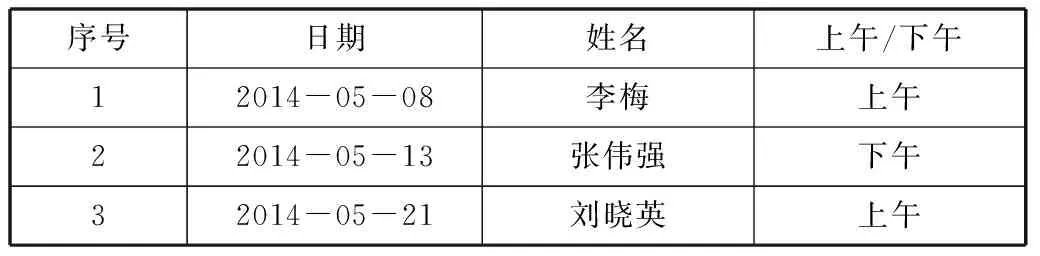
表5 集团总部2014年5月迟到人次清单
制表人:刘三保 制表日期:2014年6月1日
2 表格的结构特征
一个中文表格T可以用式(1)的六元组来表示:
T=
(1)
其中,Td为表序,即表格在文本中的序号,具有唯一性;Tn为表名,即表格的名称;Tf为表附,反映表格的外部特征,它是若干<属性,值>对所组成的集合,用FAi表示表附的第i个属性,FVi表示FAi属性的值,则:
Tf={
(2)
Tb为表体,由表格中的横、纵栏目的<属性,值>对组成的集合,设横栏有m行,纵栏有n列,m,n都是正整数,当m或n有一个为1时,表示一维表格。用x1,x2,…,xm表示横栏属性,y1,y2,…,yn表示纵栏属性,Vij表示横栏属性xi、纵栏属性yj对应的值,则:
Tb={
……
(3)
Tc是表格的上下文结构,包括状态约束、时间约束、地点约束、人物约束、事件约束。
Tc={ StatusConstraint;TimeConstraint;LocationConstraint;PersonConstraint; ThingConstraint;SequenceConstraint }
(4)
其中,StatusConstraint为状态约束,布尔型,为真(ture)表示该表格中的数据已经确认,否则未确认;TimeConstraint为时间约束,其值用SandE(starttime,endtime)来表示,描述表格数据仅在上述时间范围内有效。如果starttime为空、endtime不为空表示自endtime之前有效;如果starttime不为空、endtime不为空表示在starttime和endtime时限内有效;如果starttime不为空、endtime为空表示自starttime开始生效。若starttime=endtime则表示时间点;LocationConstraint为地点约束,描述表格数据相关的发生地点,其值为自由文本;PersonConstraint为人物约束,描述表格数据相关的人物,其值为自由文本;ThingConstraint为事件约束,描述表格数据相关的事件,其值为自由文本;SequenceConstraint为属性间的顺序约束,即所标识的列序号在解读语义时须依次进行。其值可表示为SC(y1,y2,…,yn)。
Tk是表格的链接点集合,通过链接点一个表格可以嵌入多个相关的子表格。
Tk={TL1,TL2,…,TLs}s是自然数
TLi={ EmbeddedTid;EmbeddedTname; VerifyConstraint;PrefixConstraint }
(5)
其中,EmbeddedTid为被嵌入的表格序号,实数;EmbeddedTname为被嵌入的表格名称,自由文本;VerifyConstraint为验证约束,是T对子表的整体约束,其值可以表示为Vij=RowNum(EmbeddedTid),表示序号为EmbeddedTid的子表行数必须等于T中Vij,如表1中有Vij=3=RowNum(4.2);PrefixConstraint为前缀约束,也是T对子表的整体约束,其值可以表示为Prefix(Vij,Td),表示Td子表中所有数据都需要加上前缀Vij。
3 属性的元模型
为中文表格T的所有表附属性、表体属性分别设计一个元模型,用MDFi、MDBij对应表示第i个表附属性、第i行第j列表体属性,其中h、m、n取值范围同上。
MDFi={ Type; Range; ColumnConstraint; RowConstraint }
(i=1,2,…,h)
(6)
其中,Type为该属性对应的数据类型;Range为该属性的取值范围,如按GB/T 7408-2005执行;ColumnConstraint为列约束,该属性值对表格的某一列施加约束,其值可以表示为CC(y1,y2,…,yn)+FVi,其中yj为表格的j列,j为小于等于n的正整数。(如表2中的“货币单位:元”对第5列、第6列的约束);RowConstraint为行约束,该属性值对表格的某一行施加约束,其值可以表示为RC(x1,x2,…,xm)+FVi,其中xj为表格的j行,j为小于等于m的正整数。
MDBij={Type; Range; RowColumnConstraint }
(i=1,2,…,m;j=1,2,…,n)
(7)
其中,Type为该属性对应的数据类型;Range为值域,该属性的取值范围,如按GB/T7408-2005执行;RowColumnConstraint为属性间的行列约束,其值可表示为RCC(Vab运算符Vuv运算符…Vdw关系符 Vij)。其中,a、b、u、v、d、w皆为正整数。
4 语义分析
本文将中文表格的语义扩展为:表面语义(包括“非值”部分和“值”部分)、上下文语义、主-子表间的限制语义、表附属性对表格的附加语义、表内属性值之间的关系语义。
对于给定的表格T,按照式(1)-式(7)构建表格的结构特征和属性的元模型,利用一阶谓词演算中的函数和伪码来进行中文表格的语义分析。
4.1表面语义
根据所构建的式(1)-式(3)的值,则有:
∀T,∃Td,Tn,Tf,Tb,Tk,h,m,n,s
Value(T,Td)∩Value(T,Tn)∩Num(T,Tf,h)∩
Num(T,R,m)∩Num(T,C,n)∩Num(T,Tk,s)
(8)
其中,Value(T,X)表示“表T的X属性的值”,Num(T,R,Q)表示“表T的行数量是Q”,Num(T,C,Q)表示“表T的列数量是Q”。则上述谓词公式表达了表面语义的“非值”部分:给定的中文表格T,其序号为Td,名称为Tn,有h个附加属性,有m行,有n列,有s个被嵌入的子表。
为了机器处理的效率,表面语义的“值”部分融合到以下语义中。
4.2上下文语义
ifTc.StatusConstraint=truethen"T的数据已经被确认"else"T的数据未被确认";
ifTc.TimeConstraint <>nullthen{
if(starttime <>nullandendtime =null)then"T的数据从starttime开始生效";
if(starttime =nullandendtime <>null)then"T的数据在endtime之前有效";
if(starttime <>nullandendtime <>null)then"T的数据在starttime和endtime之间有效";
}
ifTc.LocationConstraint <>nullthen"T的数据与地点Tc.LocationConstraint 相关";
ifTc.PersonConstraint <>nullthen"T的数据与人物Tc.PersonConstraint 相关";
ifTc.ThingConstraint <>nullthen"T的数据与事件Tc.ThingConstraint相关";
ifTc.SequenceConstraint <>nullthen"T的数据具有SC(y1,y2,…,yn)顺序要求";
4.3主-子表间的限制语义
ifs<>0then
for(i=1tos) {
被嵌入的表格序号为TLi.EmbeddedTid;
被嵌入的表格名称为TLi.EmbeddedTname;
表格T对TLi.EmbeddedTid子表的验证约束为TLi.VerifyConstraint;
表格T对TLi.EmbeddedTid子表的前缀约束为TLi.PrefixConstraint;
}
4.4表附属性对表格的附加语义
ifh<>0then
fori=1toh {
表附属性FAi的值是FVi;
表附属性FAi的数据类型为MDFi.Type;
表附属性FAi的值域为MDFi.Range;
表附属性FAi对T的列约束为MDFi.ColumnConstraint;
表附属性FAi对T的行约束为MDFi.RowConstraint;
}
4.5表内属性值之间的关系语义
fori=1tom {
forj=1ton {
表体横栏属性为xi、纵栏属性为yj对应的值是Vij;
该表体属性值的数据类型为MDBij.Type;
该表体属性值的值域为MDBij.Range;
if(MDBij.RowColumnConstraint<>null)then
"值Vij隐含了RCC(Vab运算符Vuv运算符…Vdw关系符 Vij)关系";
if(MDFj.ColumnConstraint<>null)thenVij=Vij+MDFj.Co-lumnConstraint;
if(MDFi.RowConstraint<>null)thenVij=Vij+MDFi.RowConstraint);
}
}
5 实例应用
利用上述的语义分析方法,针对本文给定的四类典型的中文表格进行验证。
表1的语义分析:
构建该表的结构特征和元模型:
Td=1;Tn=单位及信息专管员基本信息表;h=3;m=1;n=13; s=0;
Tf= {<单位盖章,null>,<填表人,王拥军>,<填表日期,2014-04-08>};
Tb= {<单位编号,TY001>,<组织机构编码,79843562-5>,<单位名称,太原市政府信息办>,<中文简称,信息办>,<英文简称,XXB>,<单位地址,中山路36号>,<信息专管员姓名,孙广宏>,<信息专管员职务,科长>,<信息专管员办公室电话,2336759>,<信息专管员手机号码,13903516638>,<信息专管员政务号,GK35692>,<信息专管员电子信箱,sunguanghong@ 163.com>,<信息专管员QQ号,1339883518>};
Tc={
StatusConstraint=false;
TimeConstraint=null;
LocationConstraint=null;
PersonConstraint=null;
ThingConstraint=为配合全市信息化统一规划,对各委办局和信息专管员的基本信息进行采集;
SequenceConstraint=null}
s=0,故无须构建Tk。
属性的元模型为:
MDF1={
Type=字符串;
Range=自由文本;
ColumnConstraint=null;
RowConstraint=null;}
MDF2={
Type=字符串;
Range=长度不超过五个汉字;
ColumnConstraint=null;
RowConstraint=null;}
MDF3={
Type=日期型;
Range=符合YYYY-MM-DD日期规范;
ColumnConstraint=null;
RowConstraint=null;}
MB11={
Type=字符串;
Range=TY+3位数字;
RowColumnConstraint=null;}
MB12={
Type=9位数字字符串;
Range=符合国家组织机构编码及校验规则;
RowColumnConstraint=null}
以下MB13至MB112类似,省略。
MB113={
Type=数字串;
Range=四至十位的数字;
RowColumnConstraint=null;}
可获得如下语义:
(1) 表面语义
根据式(8)可以得到表面语义的“非值”部分:表的序号为“1”,表名为“单位及信息专管员基本信息表”,有3个附加属性,有1行13列,没有嵌入子表。
(2) 上下文语义
该表是“为配合全市信息化统一规划,对各委办局和信息专管员的基本信息进行采集”,但本表填报的信息尚未得到单位“确认”。
(3) 主-子表间的限制语义
无。
(4) 表附属性对表格的附加语义
表附属性值为:
单位盖章=null,字符串,自由文本;
填表人=王拥军,字符串,不超过五个汉字;
填表日期=2014-04-08,日期型,格式为YYYY-MM-DD;
附加语义:无。
(5) 表内属性值之间的关系语义
表体属性值为:
单位编号=TY001,字符串,格式为TY+3位数字;
组织机构编码=79843562-5,9位数字字符串,符合国家组织机构编码及校验规则;
单位名称=太原市政府信息办,字符串,自由文本;
中文简称=信息办,字符串,自由文本;
英文简称=XXB,字符串,自由文本;
单位地址=中山路36号,字符串,自由文本;
信息专管员姓名=孙广宏,字符串,长度不超过五个汉字;
信息专管员职务=科长,字符串,符合国家职务编码规范;
信息专管员办公室电话=2336759,数字串,七位数字;
信息专管员手机号码=13903516638,数字串,十位数字;
信息专管员政务号=GK35692,字符串,GK+5位数字,具有唯一性;
信息专管员电子信箱=sunguanghong@163.com,字符数字串,符合电子邮件地址规范;
信息专管员QQ号=1339883518,数字串,四至十位数字;
属性值之间关系语义:无。
表2的语义分析:
限于篇幅,省略结构特征和元模型的构建过程,对于表格的表面语义的“值”部分也予以省略。
(1) 表面语义
表的序号为“2”,表名为“某项目设备预算表”,有2个附加属性,有7行6列,没有嵌入子表。
(2) 上下文语义
该表是“针对某项目设备预算制作的清单”,解读该表时针对每一行按第1、2、3、4、5、6列顺序进行,本表填报的信息已经“确认”。
(3) 主-子表间的限制语义
无。
(4) 表附属性对表格的附加语义
表附属性值:省略。
附加语义:表的第6、7列的限制量词为“元”。
(5) 表内属性值之间的关系语义
表体属性值:省略。
属性值之间关系语义:满足V13×V15=V16;V23×V25=V26;V33×V35=V36;V43×V45=V46;V53×V55=V56;V63×V65=V66;V16+V26+V36+V46+V56+V66=V76。
表3的语义分析:
(1) 表面语义
表的序号为“3”,表名为“某公司员工信息表”,有1个附加属性,有1行9列,有2个嵌入子表,表序分别为3.1和3.2。
(2) 上下文语义
该表“对公司所有员工的基本信息进行采集”,本表填报的信息已经“确认”,信息在2014年7月1日前有效。
(3) 主-子表间的限制语义
表3.1和3.2所有数据值都应冠以前缀“李国栋”。
(4) 表附属性对表格的附加语义
表附属性值:省略。
附加语义:无。
(5) 表内属性值之间的关系语义
表体属性值为:略
关系语义:无。
子表3.1和3.2的语义分析:省略。
表4和表5的语义分析:
(1) 表面语义
表的序号为“4”,表名为“某集团公司月度考勤统计表”,有3个附加属性,有6行6列,有1个嵌入子表,表序为“5”。
(2) 上下文语义
该表“对集团所有员工按所在分部进行考勤汇总”,本表填报的信息已经“确认”,信息的有效性范围为2014年5月1日至2014年5月31日。
(3) 主-子表间的限制语义
被嵌入的子表5的行数必须为3。
(4) 表附属性对表格的附加语义
表附属性值:省略。
附加语义:无。
(5) 表内属性值之间的关系语义
表体属性值为:略。
关系语义:
V11+V21+V31+V41+V51=V61;V12+V22+V32+V42+V52=V62;
V13+V23+V33+V43+V53=V63;V14+V24+V34+V44+V54=V64;
V15+V25+V35+V45+V55=V65;V16+V26+V36+V46+V56=V66。
对子表5的语义分析:省略。
6 语义质量评价
邓敏等[15]基于CHENG[16]提出了准确性、一致性、完整性语义质量评价方法,孙翀等[17]提出了语义损失率的评价方法,还有基于语义扩散距离的评价方法。这些方法都是在假定研究对象的语义已经存在的前提下,进行某种运算(文献[15]为综合,文献[16]为汇总)时,对运算前后语义的变化进行质量评价,而针对中文表格到底应该包含哪些语义尚未得到统一认知的情况下(这正是本文的研究目标之一),上述方法皆不可行。以下用本文中的四个实例来对比目前方法与本文方法所获得的语义信息量,见表6所示。
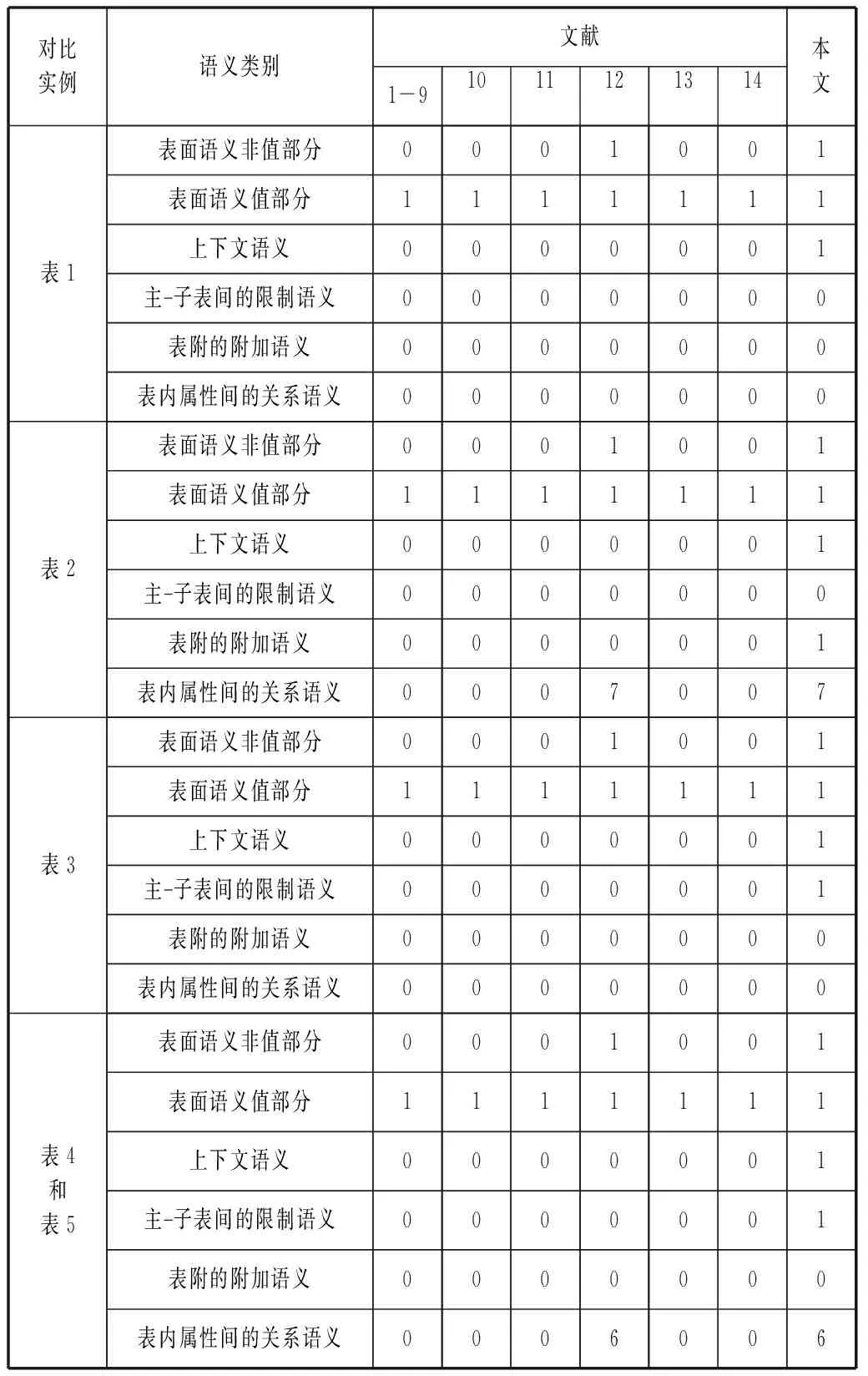
表6 各种方法所获得的语义信息量比较
7 结 语
在实际情况中,中文表格的分类标准、语义范畴、是否领域相关等问题的认识并未得到统一,因此,面向常见的几种表格类型,基于结构特征和元模型对中文表格进行了语义分析,思路清晰,算法简单。较已有的方法,获取了中文表格的表面语义(“值”和“非值”语义)、上下文语义、表附属性的附加语义、主-子表之间的限制语义、表内属性值间的关系语义,扩展了中文表格语义分析的范围,丰富了语义信息量。
从本质上说,构建中文表格的结构特征和元模型的过程就是表格概化的过程,可看成槽填充表示法[18]的扩展,且具备对多层嵌套子表的递归分析能力。显然,从结构特征和元模型中获取中文表格语义的过程对语义是无损的,结果是无歧义的。不难看出,该方法也可用于中文表格的信息抽取。
[1] 范莉娅,肖田元.自动获取HTML表格语义层次结构方法[J].清华大学学报(自然科学版),2007,47(10):1586-1590.
[2]LimSeungjin,NgYiukai.AnautomatedapproachforretrievinghierarchicaldatafromHTMLtables[C]//ProceedingsoftheEighthInternationalConferenceonInformationandKnowledgeManagement.KansasCity:ACM,1999: 466-474.
[3]LIUJiexue,AOZhuoyun,ParkHH,etal.AnXMLapproachtosemanticallyextractdatafromHTMLtables[C]//DatabaseandExpertSystemsApplications,DEXA2005,LectureNotesinComputerScience3588.Heidelberg:SpringerBerlin,2005:696-705.
[4]YoshidaM,TorisawaK,TsujiiJ.Extractingattributesandtheirvaluesfromwebpages[C]//AntonacopoulosA,HuJianying.WebDocumentAnalysis:ChallengesandOpportunities.Singapore:WorldScientificPublishing,2003: 179-200.
[5]HsiaoShuling,ChouShihchun,ChangLuping.InformationextractionfromHTMLtablesbaseondomainontology[C]//InternationalConferenceonInformationandKnowledgeEngineering-IKE’03.LasVegas:CSREAPress,2003: 70-78.
[6]KimYeonseok,LeeKyongho.ExtractingtableinformationfromtheWeb[C]//DocumentAnalysisSystemsVI. 6thInternationalWorkshop,DAS2004,LectureNotesinComputerScience3163,2004:438-441.
[7] 张凯.基于本体的web信息集成若干关键技术研究[D].上海:复旦大学,2004.
[8]LiShijun,PENGZhiyong,LIUMengchi.ExtractionandintegrationinformationinHTMLtables[C]//FourthInternationalConferenceonComputerandInformationTechnology.Nanjing,China,2004:315-320.
[9]TanakaM,IshidaT.Ontologyextractionfromtablesontheweb[C]//ProceedingsoftheInternationalSymposiumonApplicationsonInternetinSAINT-06.Washington:IEEEComputerSociety,2006:284-290.
[10] 杨海涛.复杂表头表格的关系模式表示[J].计算机工程,2011,37(2):49-54.
[11] 赖中华. 基于本体的金融年报语义网自动构建方法[D].哈尔滨工业大学,2008.
[12] 陈竞波.基于语义的报表系统模型的应用研究[D].辽宁:辽宁工程技术大学,2010.
[13] 冯晓晨,张晓辉,邸瑞华.基于本体的电子表格数据到语义数据的转换[J].计算机科学,2011,38(10):145-148.
[14] 尹文生.HTML表格语义脉络分析方法:中国,200910272408[P]. 2011-05-04.
[15] 邓敏,刘扬,程涛,等.地图综合中语义质量的度量方法研究[J].地理与地理信息科学,2008,24(5):11-15.
[16]ChengT,LIZL.Quantitativemeasuresforsemanticqualityofpolygongeneralization[J].Cartographica,2006,41(2):135-148.
[17] 孙翀,卢炎生.基于层次空间聚类的表语义汇总算法[J].计算机科学,2012,39(3):163-169.
[18] 冯志伟.自然语言处理简明教程[M].上海:上海外语教育出版社,2012:516-517.
SEMANTICANALYSISMETHODFORTABLESINCHINESEBASEDONSTRUCTURALFEATURESANDMETA-MODEL
ZhangJiarui1ZhangHan2
1(Department of Computer Science and Technology,Hefei University,Hefei 230601,Anhui, China)2(Department of Life and Medical Science, University of Hertfordshire,Hatfield,AL10 9AB,UK)
InlightoftheactualityoflesscomprehensiveanalysisonsemanticsoftablesinChinesethecurrenttechniqueis,inthispaperwepresentthestructuralfeaturesandmeta-modelbasedsemanticsanalysismethod.Byusingthewell-knownfirst-orderpredicatecalculusfunctionsincludingValue(valuefunction)andNum(numberfunction),aswellascombiningpseudocode,weanalysethesemanticsofseveralkindsofthemostcommontablesinChineseandobtaintheirsurfacesemantics,contextsemantics,restrictsemanticsbetweenmastertableandsub-tables,additionalsemanticsofsubsidiarynatureoftableontabledata,andrelationshipsemanticsbehindtheattributevalue.Resultsofexampleverificationindicatethatthestructuralfeatureandmeta-modelaretheeffectivewayforanalysingthesemanticsoftablesinChinese,theacquiredinformationamountandcategoriesofsemanticsexceedfarthantheexistingmethods.
StructuralfeaturesMeta-modelFirstorderpredicatecalculusfunctionSurfacesemanticsContextsemanticsRestrictionsemanticsAdditionalsemanticsRelationshipsemantics
2014-10-08。科技部中小企业创新基金项目(11C26 213401181);校人才科研基金项目(14RC08)。张家锐,高工,主研领域:软件建模,信息集成,数据挖掘。张涵,本科生。
TP311
ADOI:10.3969/j.issn.1000-386x.2016.03.020
