基于规则置信度调整的知识挖掘及在烟草科技管理中的应用
2016-09-26王乙民
王 塑 张 萍 周 新 王乙民
(陕西省烟草公司西安市公司 陕西 西安 710061)
基于规则置信度调整的知识挖掘及在烟草科技管理中的应用
王塑张萍周新王乙民
(陕西省烟草公司西安市公司陕西 西安 710061)
介绍信息管理领域中的一个热门研究主题——知识挖掘。知识挖掘旨在从结构化、半结构化的数据中挖掘信息。例如从电子文档、不完备的历史数据中搜索稳定的模式或模型,分析挖掘数据间的交互特征和规律,以辅助管理人员制定、调整规范与标准,构建专家库和知识库。提出知识挖掘的一种改进方法,通过动态规则置信度生成算法提高所获得规则的准确性与适应性,并结合烟草企业科技项目智能辅助管理中的实际应用进行了验证,取得了一定的成效。
知识挖掘规则置信度信息管理
0 引 言
根据思科公司的调查显示,全球数字化信息的年度总量从09年的0.79ZB已经上升到13年的3.3ZB。随着信息设备、互联设备、存储技术的快速发展,面向大规模数据的深度挖掘、知识挖掘、关联关系分析的智能系统被广泛部署,并逐步成为大型企业的核心价值和必须的组成部分[1]。在2013年Nazlioglu等人经过研究石油与农产品之间的微妙溢价关系而获得了巨大的市场成功后,更多的数据科学家和企业管理者将深度数据分析与知识挖掘作为其研究的重要方向[2]。
知识挖掘的核心是将数据挖掘技术应用于专业领域,从中获得可以在一定程度上和一定时间范围内实现预测和评估的技术与方法。人类在数据密集型的应用中发挥着关键作用:不仅是被动的知识消费者,同时也是活跃的数据产生者和数据的采集者,而信息技术需要协助人们解决内在的大规模数据关联分析和知识获取的难题[3]。因此,知识挖掘需要解决的问题包括:
(1)ETL(ExtractionTransformLoading):数据提取、转换和加载。现实中的数据通常由多个不同的数据源整合而来,数据冗余与数据冲突成为常态。将数据转换为信息的技术统一称之为ETL。
(2)MKS(multidimensionalknowledgestorage)高维知识的存储:知识之间的复杂关系已经难以二维化了,根据欧拉公式的推广,只有在知识之间的关联小于9条时,才可以用一张不相交的二维图形表示,复杂知识给我们带来的是牵一发而动全身的无力感。因此亟需面向高维知识的处理方法。
(3) 关联关系分析:知识本质上是不同信息之间的关联关系模型,因此只有深入分析信息之间的关系才可以获得有实用价值的预测模型。因此,关联关系分析方法可以说是知识挖掘的核心部分所在。
如图1所示。知识挖掘主要有基于概率和基于距离的两类方法。基于概率的方法以贝叶斯后验概率为理论依据,用概率分布情况描述知识模型,可以实现规则之间互相重叠的冗余知识库生成;其主要的不足是当特征空间维度增加时所生成的知识重叠率过高以致效率低下。基于距离的方法以特征向量表示基础数据,将基础数据看作向量空间中的一个点,通过计算点之间的距离实现聚类,所构建的知识可以实现特征空间的划分,不存在知识模型之间的相互重叠,其主要算法有k-means算法、瑞士卷算法等;其主要的不足是当特征空间维度较高时算法性能下降显著。

图1 知识挖掘的三个主要环节
本文的应用背景是尝试解决烟草企业科技项目管理平台中的自动化辅助管理问题。在项目类型多样化、数量巨大化的情况下,如何通过知识挖掘技术实现文档的关键词提取与自动主题分类将直接影响科技项目的申报周期。在科研管理申报过程中有两个重要的概念:主题、关键词。其中主题是在项目申请指南中由科研管理人员根据年度科研规划会议确定的,那么各个单位根据自己的情况提交申请,申请书常常跨越不同的专业领域,在以往的工作中只能由科研管理人员主观判断,对于交叉学科常常造成专家选择不准确的情况,影响了申请书评审的及时性和准确性。而由申请书作者填写的关键词也不能完全保证其选取的有效性与作者个人的主观判断,采用自动方式从申请书中提取关键词与作者设定的关键词综合考虑,依据主题进行分类,将大大降低科研管理人员的工作量,同时提高交叉领域申请书申报的准确性和有效性。本文研究的重点是从结构化和半结构化的电子文档中提取核心知识,分析主题与文档之间的关联度,以便对文档进行有效分析与分类推荐,实现烟草企业科技项目管理平台实际效率的提升。
1 基于文档主题关联度的知识挖掘
1.1电子文档的结构化、半结构化表示
电子文档是一种结构化、半结构化数据,电子文档中的每一项内容均可以与数据库中的特定字段相对应。内容明确的字段被认为是结构化数据,例如日期、姓名、编号等;内容宽泛的字段被认为是半结构化数据,例如标题、摘要、关键词、文档正文等。结构化数据的意义明确,分类、聚类过程相对简单;而半结构化电子文档的特征分类是本文研究的重点内容。
1.2关键词与主题特征向量
针对结构化文档数据,可以采用向量空间模型表示每一个主题,并根据主题特征向量和结构化文档数据内容生成主题向量,在计算特定文档不同主题向量之间的关联度比较,创建结构化文档数据与主题之间的关联矩阵,再通过归一化和标准化实现关联矩阵的可比性[4]。其主题特征向量的形式化表述如下:
Topici=[(keyi,1,weighti,1),(keyi,2,weighti,2),…,
(keyi,j,weighti,j),…,(keyi,n,weighti,n)]
(1)

根据上述特征向量的定义可知,由于结构化文档数据其搜索过程可以通过SQL查询语句获得,只需要生成其不同关键词(在数据库中各个意义明确的字段)的权重即可完成基本知识挖掘建模过程。
1.3文档与主题的关联度评估
文档与主题的关联度表示结构化或半结构化电子文档数据与特定主题之间的关联程度[5]。因此,文档Dock与主题Topici之间的关联度与关键词所占比重与出现次数有关。即使在结构化文档中,除关键字段外,其他数据也有缺少的可能,在半结构化文档数据中,关键词的出现次数需要对文档进行扫描统计得出。因此可以构建文档Dock与主题Topici之间的关联矩阵如下:
(2)
其中,n表示主题数,m表示文档数,ηik表示Dock与主题Topici的关联度。ηik的计算过程如下:
(3)
其中,i表示主题Topici中的关键词个数,而‖Dock‖×weighti,j表示文档Dock中关键词keyi,j的加权出现率。
通过计算文档与主题之间的关联度,构建了文档与主题之间的关联矩阵,下一节中将在结构化文档与主题的关联度生成算法的基础上构建基于规则置信度的关联度生成算法。
2 基于规则置信度调整的知识挖掘算法
上一节中说明了关键词、主题、文档之间关联度的基本计算方法,而从一篇文档中获取关键词主流的方式是使用最大熵模型以Chi-square统计量的方法进行判定,已经形成了完整的算法库,在此不再赘述。本节主要介绍的内容是在获取文档关键词后,如何对科技项目申请指南中的不同主题进行对应与分类。
提取关键词完成后,需要将关键词与不同的主题相对应,而关键词又需要与文档相对应,其关系如图2所示。从申请书中可以获得多个关键词,这些关键词一部分来自作者的设定,另一部分来自从电子文档中的自动提取,每一份申请书所包含的关键词组成关键词向量,所有的申请书所对应的关键词向量组成关键词矩阵。关键词矩阵与申请指南中的主题形成的主题向量一起,通过标准化和归一化过程,可以计算得出关键词矩阵与主题向量之间的特征向量ηik,ηik表示了每个关键词与各个主题之间的相对抽象距离,那么我们可以通过ηik计算申请书与每项主题直接的抽象距离,结合关键词加权出现率‖Dock‖×weighti,j可以得出申请书与主题之间的相对距离,从而完成应该归于哪一类或者哪几类中的问题,进而指导科研管理人员对申请书进行快速分类与评审专家组选择。
在获得相对距离后,分类算法方面目前绝大多数系统采用的是k-means算法,k-means算法以二维空间距离表征相对距离,算法简洁,但不适合交叉领域情况,也就是说k-means算法只能将一份申请书分配到一个主题下,而目前的科研项目交叉领域的申请成为多数情况,因此k-means算法所带来的问题在其他的科研管理平台中已经日益凸显[6-8]。为了解决交叉领域匹配问题,本文提出了基于规则置信度调整的知识挖掘算法CKMA(basedofconfidenceknowledgeminingalgorithm)。如图2所示。
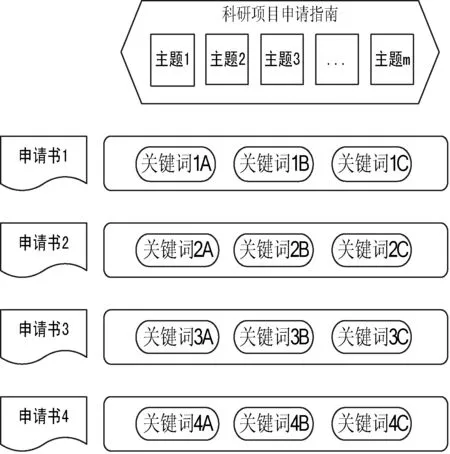
图2 申请书关键词提取与主题间的关系
CKMA算法的核心思想是关键词被越多的申请书所采用意味着该关键词的熵越小,其对分类的指导度也越低;同时根据关键词与主题的关联度进行综合计算,得出申请书的主题序列,即交叉领域的申请书也需要确定所涉及的多个主题之间的主次顺序。
(1) 针对关键词keyi,j在所有申请书中出现的频次,对比在特定申请书Dock中出现的频次确定keyi,j对申请书Dock的辨识贡献度,计算其熵值;
(2) 根据第一步计算所得熵值,所得申请书Dock对关键词keyi,j的置信度,在获得申请书Dock所有的关键词置信度后进行置信度层次化排列;

根据1.3节的说明,在分析文档与主题的关联度时将‖Dock‖×weighti,j(文档Dock中关键词keyi,j的加权出现率)作为关键词与主题之间关联度评估的重要参数。根据CKMA算法中再次以‖Dock‖×weighti,j为基础,综合评估获得申请书Dock对主题Topici的基于置信度的关联度时,整个计算过程将申请书与研究主题之间完整连接,从而实现申请书的有效分类。
3 实验分析
实验部分采用的样本数据包括两个集合:其中一个是拥有2584份文档的两主题数据集;另一个是拥有45 781份文档、31个主题的数据集。显然,4万余条数据31个主题的数据集是科研管理平台所需要承担的任务。我们将CKMA算法与基于相对距离的k-means算法进行比对。
3.1实验步骤
根据第2节的说明,实验中采用的测试文档经过三个步骤的计算:
(1) 计算关键字熵值:两个数据集分别包括2584份文档和45 781文档,每份文档有3至5个关键词,根据每个关键词在所属文档中的出现频率和文档总词数计算其熵值。在该步骤中,CKMA算法与传统的k-means算法没有差别。
(2) 根据文档Dock与主题Topici之间的关联矩阵,每个关键词与所属文档的熵值将根据重复关键词和重复主题之间进行交叉计算,每个关键词的熵值将不仅与所属文档相关,与同主题的所有文档均呈现相关性,这是CKMA算法与k-means算法的主要差别,该步骤在文档数较少的测试集合由于同主题的关键词较少,因此计算结果变化不明显;而文档数据增加后关键词的熵值代表意义明显增强,对第三步骤的分类提供了强有力的支持。
对第二步骤的关键词熵值,分析文档与主题的关联度,由于已经CKMA算法的关键词熵值在全局具有代表性,因此作为稳定分类依据所产生的提升效果明显。
3.2实验结果对比


表1 k-means算法在2584数据集中的处理结果

表2 CKMA算法在2584数据集中的处理结果

表3 k-means算法在45781数据集中的处理结果

表4 CKMA算法在45781数据集中的处理结果
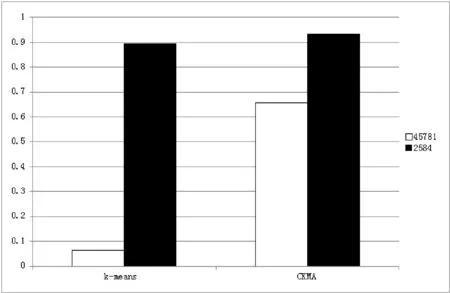
图3 两种算法在两个数据集中的准确性比较
3.3实验结果分析
当文档主题限制为两类时,新的CKMA算法较传统的
k-means算法提高了约4个百分点,在实际应用中效果不明显,分析时间均在1秒钟以内;而当主题多达31项,且一个文档可能与多个主题相关时,CKMA算法仍保持了60%以上的准确性,而k-means算法下降到仅为6%,完全失去了指导科研人员进行分类的可能性。
4 结 语
本文通过全面分析主题、文档与关键词之间的基于置信分析的关联度评估,实现CKMA算法,针对多主题文档分类问题进行了尝试,并在烟草企业科技项目申报管理平台中进行了试用,解决了传统方法无法实现的多主题分类指导。但目前,针对复杂文档的多目标分类仍是研究的难点,其准确性有待提高,而主要的技术难点在于大量文档的存储与并行算法框架两方面,这将是我们下一步研究工作的重点内容。
[1]ChenH,ChiangRHL,StoreyVC.BusinessIntelligenceandAnalytics:FromBigDatatoBigImpact[J].MISQuarterly,2012,36(4):1165-1188.
[2]ChauM,XuJ.Businessintelligenceinblogs:UnderstandingConsumerInteractionsandCommunities[J].MISQuarterly,2012,36(4):1189-1216.
[3]DuanL,DaXuL.BusinessIntelligenceforEnterpriseSystems:ASurvey[J].IndustrialInformatics,IEEETransactionson,2012,8(3):679-687.
[4]MoraesR,ValiatiJF,GaviãONetoWP.Document-levelSentimentClassification:AnEmpiricalComparisonBetweenSVMandANN[J].ExpertSystemswithApplications,2013,40(2):621-633.
[5]GordoA,PerronninF,ValvenyE.Large-scaleDocumentImageRetrievalandClassificationwithRunlengthHistogramsandBinaryEmbeddings[J].PatternRecognition,2013,46(7):1898-1905.
[6]SahuN,ThakurRS,ThakurGS.Hesitantk-NearestNeighbor(HK-nn)ClassifierforDocumentClassificationandNumericalResultAnalysis[C]//ProceedingsoftheSecondInternationalConferenceonSoftComputingforProblemSolving(SocProS2012),December28-30,2012.SpringerIndia,2014:631-638.
[7]DattolaRT.AFastAlgorithmforAutomaticClassification[J].InformationTechnologyandLibraries,2013,2(1):31-48.
[8]CulottaAron.LightweightMethodstoEstimateInfluenzaRatesandAlcoholSalesVolumefromTwitterMessages[J].Languageresourcesandevaluation,2013,47(1):217-238.
KNOWLEDGEMININGBASEDONRULESCONFIDENCEADJUSTMENTANDITSAPPLICATIONINTOBACCOS&TMANAGEMENT
WangSuZhangPingZhouXinWangYimin
(Xi’an Company of Shaanxi Provincial Tobacco Company,Xi’an 710061,Shaanxi,China)
Thispaperintroducesapopularresearchtopicinthefieldofinformationmanagement,knowledgemining.Itaimsatminingtheinformationfromstructuredandsemi-structureddata,forexample,searchingthestablepatternormodelfromelectronicdocumentsandtheincompletehistoricaldata,analysingandminingtheinteractivefeaturesandrulesbetweendata,soastoassistthemanagerstoformulateandadjustthenormsandstandards,constructtheexpertdatabaseandknowledgebase.Inthispaper,wediscussanimprovedmethodforknowledgemining,throughdynamicruleconfidencegenerationalgorithmitimprovestheaccuracyandadaptabilityoftheobtainedrules.Wealsoverifiedthemethodcombiningtheactualapplicationinintelligentauxiliarymanagementoftobaccoindustryproject,andachievedsomeeffect.
KnowledgeminingRulesofconfidenceInformationmanagement
2014-06-05。国家自然科学基金项目(61373120);陕西省市科技项目(KJ-2013-06)。王塑,高级经济师,主研领域:经济管理,科技管理。张萍,高级经济师。周新,硕士。王乙民,学士。
TP311.13
ADOI:10.3969/j.issn.1000-386x.2016.03.019
