基于层叠条件随机场的哈语树库构建技术研究
2016-09-26于智娟古丽拉阿东别克
于智娟 古丽拉·阿东别克
(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
基于层叠条件随机场的哈语树库构建技术研究
于智娟古丽拉·阿东别克
(新疆大学信息科学与工程学院新疆 乌鲁木齐 830046)
针对如何提高基于统计的哈萨克语句法分析算法的处理性能问题,提出一种通过人机交互来构建哈萨克语树库的方法。在自动句法标注阶段,采用层叠条件随机场模型实现,并在其低层与高层模型之间加入改进的基于转换的错误驱动学习算法来进行简单句的自动句法标注及自动校正。最后对特殊的整体标记错误进行人工校对,形成基于短语结构的哈萨克语树库。实验结果表明,该方法在很大程度上减少了人力及物力的投入,提高了分析精度及整体处理效率,并为后期基于哈萨克语的句法机器翻译及文本挖掘奠定了一定的基础。
哈萨克语树库人机交互层叠条件随机场错误驱动学习算法
0 引 言
哈萨克语树库为哈语自动句法分析、句法机器翻译、文本挖掘等热门研究领域提供知识源,其重要性不言而喻。特别是哈萨克语的树库构建技术相比于汉语、英语等其他语言比较滞后,仍处于初级阶段。所以说如何在节省人力及物力资源的前提下,能够更好地构建哈萨克语树库是一个急需解决的难点问题。在树库构建方面,汉语树库的构建技术已基本成熟并取得了一些成果,包括美国宾州大学的UPenn树库[1]和台湾中研院的Sinica树库[2]。英语语料库的研究也做了许多工作,其中两个比较大的项目是:英国的Lancaster-Leeds树库[3]和美国的Penn树库项目[4],树库规模已达到二百万词以上。
而哈萨克语方面,目前还没有一个相对成熟的树库,只做了一些构建树库前的铺垫工作。例如:古丽拉·阿东别克等根据哈萨克语的独特语言特点,进行了词级带标注的哈萨克语语料库构建研究[5];侯呈风等在基于词典静态标注基础上分析了隐马尔科夫模型并对哈萨克语进行了词性标注研究[6];在短语识别方面,孙瑞娜等以基本名词短语为目标,实现了哈萨克语的基本名词短语自动识别系统[7];古丽扎达·海沙根据哈萨克语基本动词短语组成结构的复杂性,提出了一种规则与最大熵相结合的方法对哈语基本动词短语进行了识别[8]。
本文在以上词性及基本短语标注基础上,采用基于层叠条件随机场对哈萨克语的简单句进行了句法标注,同时对部分因典型的歧义结构造成标注错误的句子进行人工校对,最终形成完整的句法结构树。同时借鉴了文献[9,10]中提出的分阶段构建汉语树库及标记集的选取相关问题的方法思路,并结合哈萨克语自身语言的粘着性特点,分阶段进行树库构建。并在基于层叠条件随机场模型的自动标注阶段,引入基于错误驱动的学习算法,进行自动校正,提高了整体句法标注的准确率,同时减少了人力及物力资源的投入。
1 树库构建的理论基础
1.1哈语句法标记集的选取
构建哈萨克语树库的一项基础工作就是要确定适合哈萨克语粘着性特点的句法标记集。在哈萨克语中,对短语进行分类一般采用两大标准:1) 内部结构;2) 外部结构。本文着重研究哈语短语的外部结构。首先参照汉语树库构建[9]和英语树库[11]的处理经验及方法。同时结合哈萨克语粘着性语言的特点,找出哈萨克语同汉语、英语、维吾尔语的异同点,其中相同的句法结构采用相同的标注集标注。不同的句法结构又可以参照与哈萨克语同属于阿尔泰语系的维吾尔语的树库标注体系[12]及现代哈萨克语实用语法[13]。根据以上方法,我们为哈萨克语设计了一套符合哈萨克语自身语言特点的句法标记集。如表1所示。

表1 哈萨克语句法标记集

1.2构建哈萨克语树库的步骤流程
大规模哈语树库的构建作为一个庞大的语言工程,在现有条件下,完全由机器自动完成是不可能的,需要找到一个很好的人工切入点,以最少的人工投入获得最佳的整体处理效果。为此,结合哈萨克语自身粘着性的语言特点,我们在已有的分词和词性标注的基础上,利用层叠条件随机场模型进行简单句的句法标注。标注出句子的短语结构层次,在加入基于错误驱动的学习算法之后,提高了标注结果的正确率,但仍然存在部分标注错误的情况,这时我们就需要人工校正来对结果进行完善。根据以上情况,本文制定出了构建半自动哈萨克语树库的思路方法,分别从词、短语层的句法分析再到最后人工的处理这三步进行。本文重点工作是在步骤一的基础上实现了步骤二、步骤三。具体步骤如下:
步骤一预处理,主要对哈语生语料做篇章级的断句、分词;并对词做统一的词性标注规范,然后进行词性标注。
步骤二机器分析,在分词和词性标注的基础上,通过层叠条件随机场模型进行短语层次结构的句法标注。从低层组块标注到高层复杂短语的标注中,引入基于错误驱动的学习算法自动进行标注结果的校正。最后形成较完善的句法分析树。
步骤三人工校对,由于第二步工作中采用的是基于规则的校正算法,而规则的获取仅依赖于语言学家的语言知识和经验,却不能完全囊括各种复杂的语言现象。所以需要人工的介入,对一些复杂的存在歧义的句法树进行人工校正,从而获得最佳的标注结果。具体处理流程如图1所示。
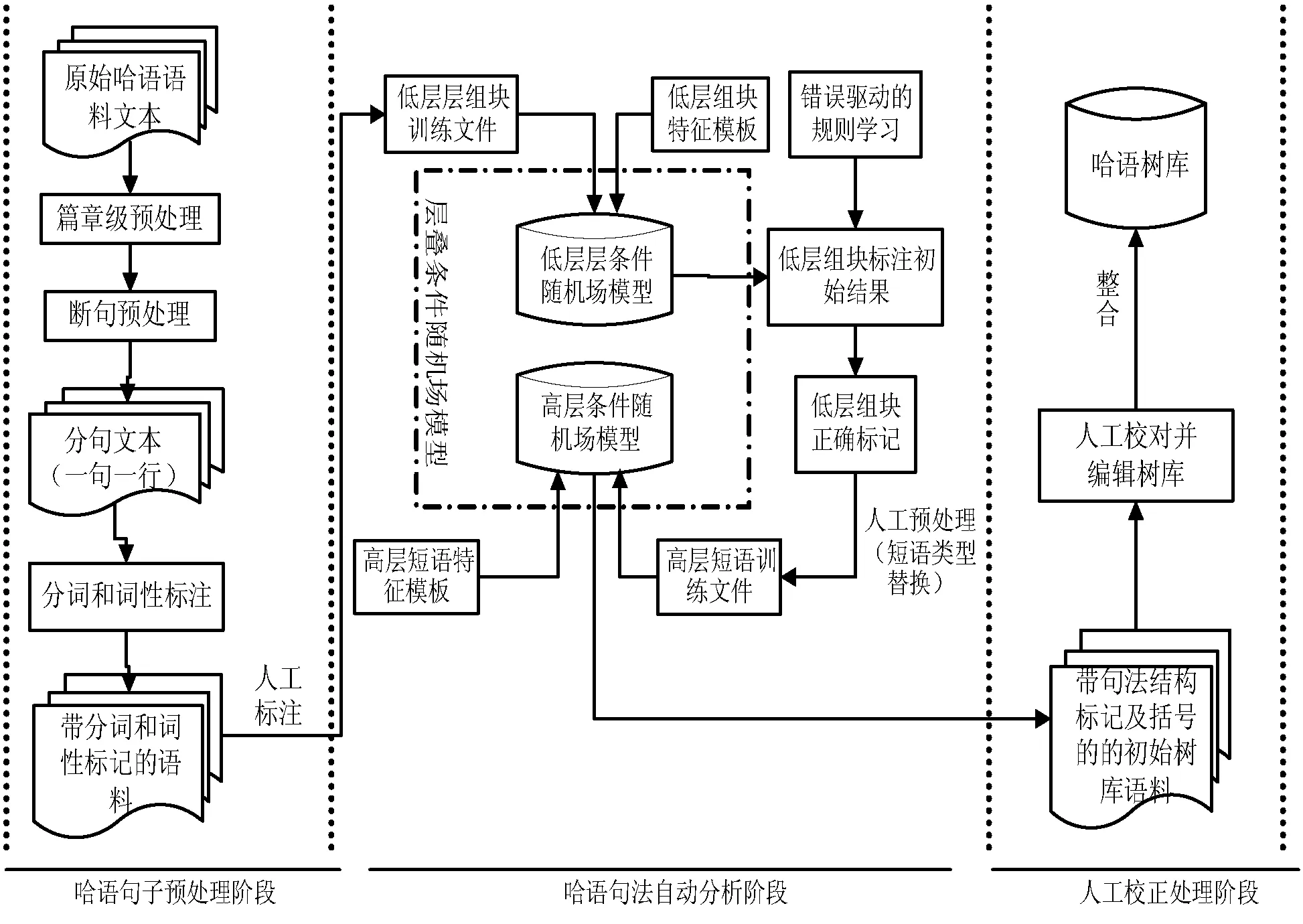
图1 半自动构建哈语树库流程图
2 哈萨克语句法标注及人工处理
由于前人在哈萨克语的分词和词性标注方面做了大量研究及实验[14,15],且在树库预处理方面已经相对比较成熟。 所以说本文重点工作在句法分析阶段。
2.1层叠条件随机场模型
由于句子中存在许多短语的嵌套及组合现象,所以在进行句法标注过程中,需要进行分层研究。层叠条件随机场(CCRFs)由一个两阶段的条件随机场模型构成,层次模型间存在松耦合关系,各模型可独立建立,且整个模型的复杂度和句子长度成线性关系。本文新加入的低层后处理模块对低层模型产生的错误可经过滤和更正后传入高层,从而避免错误传播。鉴于此,本文将句法结构任务分多个层次,每层内部用CCRFs作为层次标注的机器学习方法。在CCRFs中,低层的条件随机场仅以观察值为条件,用于基本短语即组块的识别,识别结果传递至高层条件随机场模型,作为高层模型的输入。这样高层模型的观察序列中不仅包含词和词性的信息,同时也包含了底层基本短语识别的结果,从而为高层复杂短语的识别奠定了基础。
两阶段的条件随机场模型具体算法:定义x=x1,…,xN为给定的输入观测值哈序列,即无向图模型中N个输入节点上的值,如当前输入的哈文词序列;定义y=y1,…,yN为输出的状态序列,即无向图模型中N个输出节点上的值,如输出的标记序列。CRF定义从输入x得到序列y的条件概率定义为:
(1)
其中每个fk(yi-1,yi,x)是整个观察序列和相应的标注序列中位置为i和i-1标记的特征函数,每个gk(yi,x)是在位置为i的标记和观察序列的状态特征函数,λk和uk是特征函数的权重,可从训练语料中估计得到。
层叠条件随机场的具体模型如图2所示。
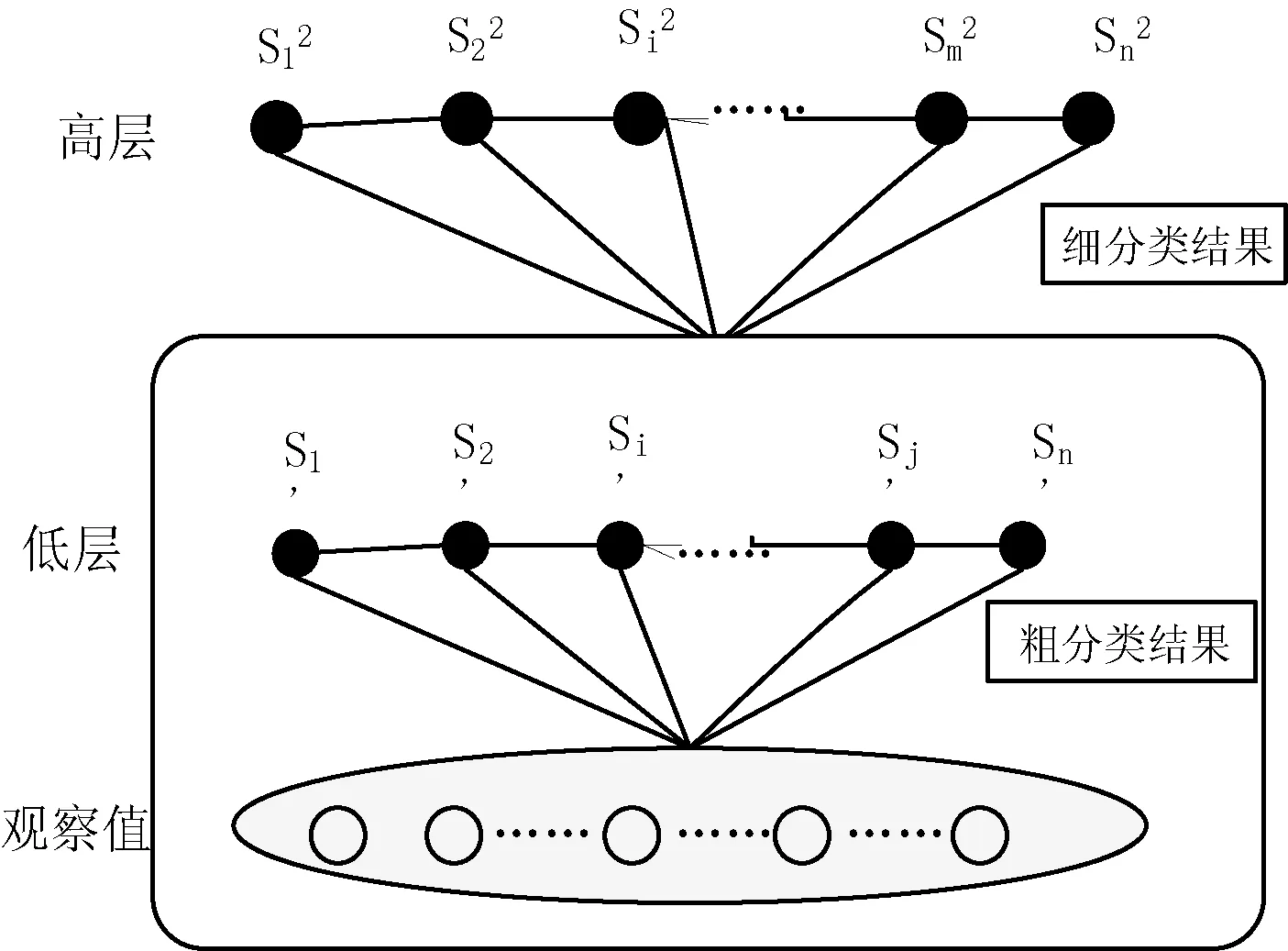
图2 层叠条件随机场模型
为了能够更好地将句法标注问题转化为序列标注问题,在使用层叠条件随机场模型前,需要在分词和词性标注的基础上,对句子进行预处理。处理成符合此模型接口模式,并在标注过程中采用RamShow等人在1995年最早提出的Inside/Outside标记法,即BIO标记法[16]。具体标记集为T={B,I,O},其中B表示短语的开始词,I是短语中的第二个以上(包括第二个)的词,O是短语外部的词。例如表2所示的名词短语块(NP)的标记方法。
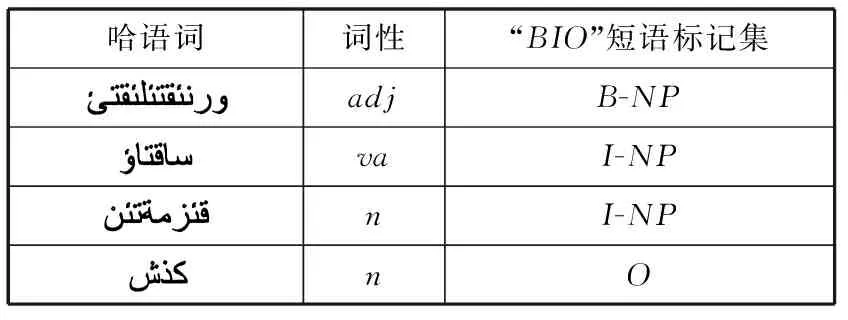
表2 “BIO”标记法的短语标记集实例
2.2特征及特征模板选择
在基于CCRFs的分层标注问题中,特征函数的选择往往是至关重要前提准备工作。特征选取的好坏决定着CCRFs标注结果的优劣,所以本文结合哈萨克语的语法习惯,采用基于贪心策略的增益式特征模板自动选择算法[17]。尽量少地自动选取合适的特征,以此来降低选取过程中的空间及时间复杂度。
算法思想是将已经选择的特征模板集设为空,然后在每次迭代的过程中将备选特征模板集中的各个模板项依次加入到已选特征模板集中。并用条件随机场模型依次训练测试,根据测试结果给出其评分Scores,从备选特征集中选取评分最高的模板项加入已选特征模板中。然后进行下一次迭代,至多重复m次,最终选择出一个特征模板子集,时间复杂度从原先的O(2m)数量级降低到了O(m2)数量级。选取结果如表3所示。
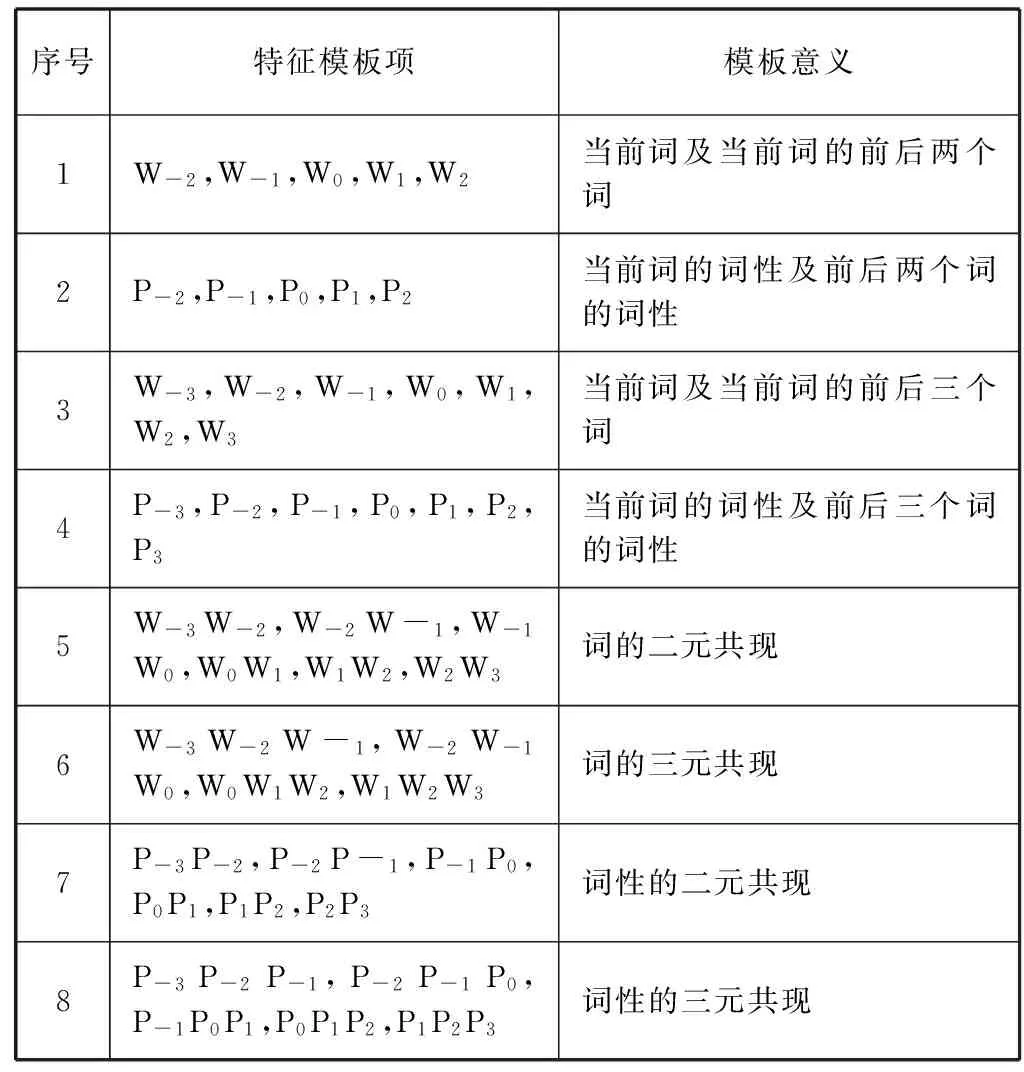
表3 哈萨克语层叠条件随机场的最优特征模板
2.3训练及标注
在训练阶段:基于层叠条件随机场模型中,低层条件随机场的训练语料包括词、词性标注和人工基本短语的类型标记。而高层的训练语料是在低层组块标注结果的基础上经短语类型替换后作为高层的训练语料。也就是说,高层训练语料的观察值序列中不仅包括词及词性标注信息,同时涵盖了来自低层的组块标注结果。如表4、表5所示。
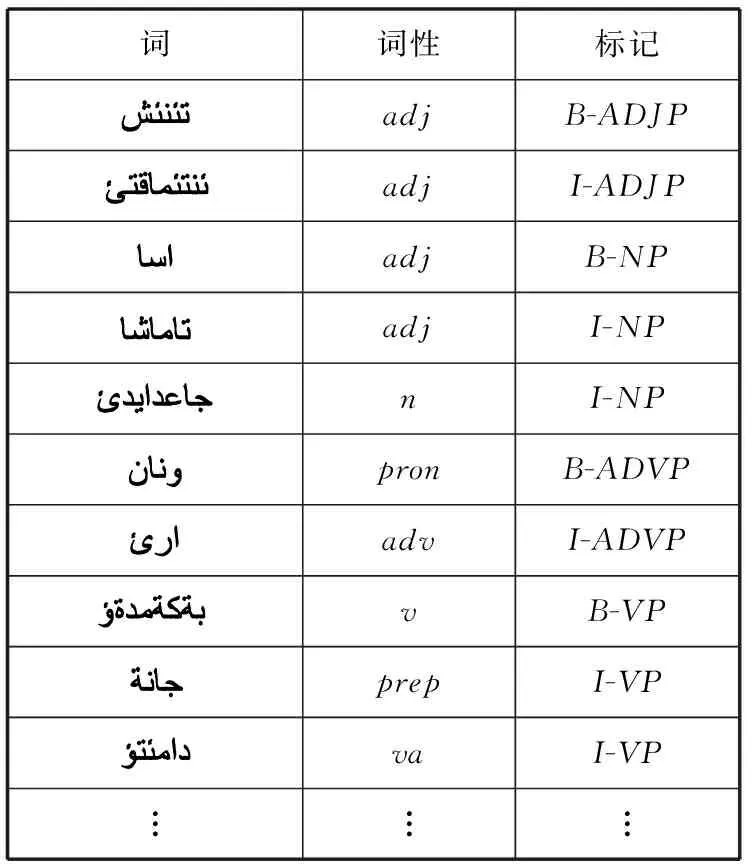
表4 CCRFS低层组块训练语料标注格式
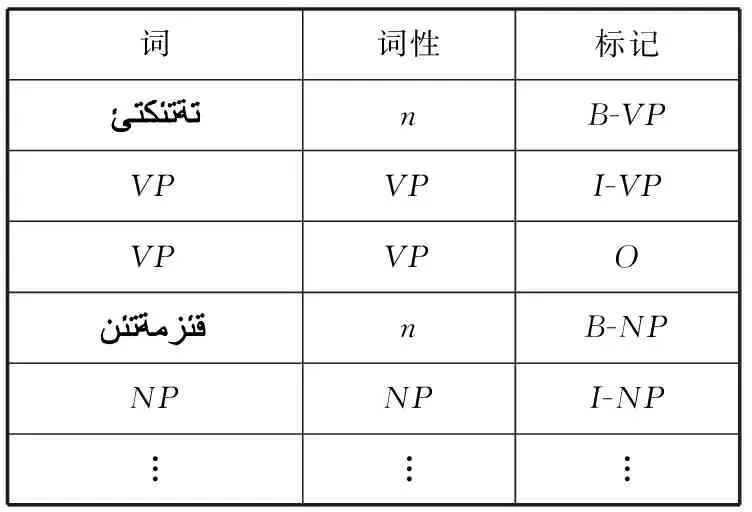
表5 CCRFS高层短语训练语料标注格式
将上述转换好格式的训练语料分别进行特征提取,将提取结果加入到相应特征模板集。然后分别对特征模板集进行有限内存拟牛顿法(L-BFGS)参数估计。根据层叠条件随机场模型使得每个特征对应一个参数,从而使模型得到充分训练并达到自学习的目的,训练结束后建立起相应的低层及高层条件随机场模型。
在测试阶段:首先将测试语料预处理成符合模型识别接口的格式,对每层的待标注的词根据特征模板选取出合适的特征,并获取出每个词的特征对应参数。通过Viterbi算法对每个词进行解码标注,输出标注结果。在这个过程中,为了避免由低层标注错误传递到高层模型而引起的错误蔓延,我们在层叠条件随机场模型中引入了基于转换的错误驱动学习算法[17]。该算法是EricBrill提出的。本文在此基础上改进了转换算法,在原有的评价函数方法式(2)的基础上改进得到方法式(3)。通过人工给出的参数分别与F1(r)、F2(r)进行比较选出最佳规则。此改进的算法在符合哈萨克语句法特点的及相同语料环境下,不需要遍历所有规则,同时加入评分准则,根据其得分和失分情况来判断其是否满足条件。若满足则加入规则集,若不满足则舍弃,最终遍历完所有转换规则。
F(r)=g(r)-f(r)
(2)
(3)
注:g(r)为转换正确次数,f(r)为转换错误次数。
系统中获取并筛选出的错误标记规则集如图3所示。
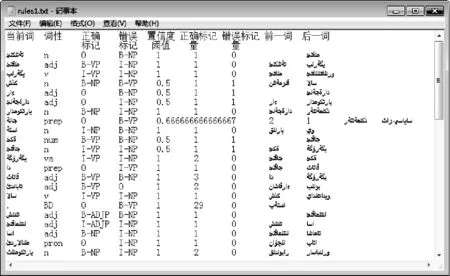
图3 筛选出的错误标记规则集
经过自动校正的低层标注结果部分自动替换成高层模型的训练语料格式,剩余部分作为高层模型的输入进行高层短语的标注,最终提高了整体标注准确率,同时节省了时间开销。
2.4人工校正
对于基于规则的错误驱动学习算法来说,规则集的庞大与否是一项至关重要的工作。由于哈萨克语树库构建仍处于初步阶段,所以要从大规模的语言现象中总结囊括所有规则情况,是一件困难的事。而人工的后期校正工作尤为重要,人工校对主要工作包括:标记错误、结构组合错误等。例如:
标记错误:

上述句子将n+n+n+v组合的动词短语(VP)错误标记成了名词短语(NP)。
标注不全:
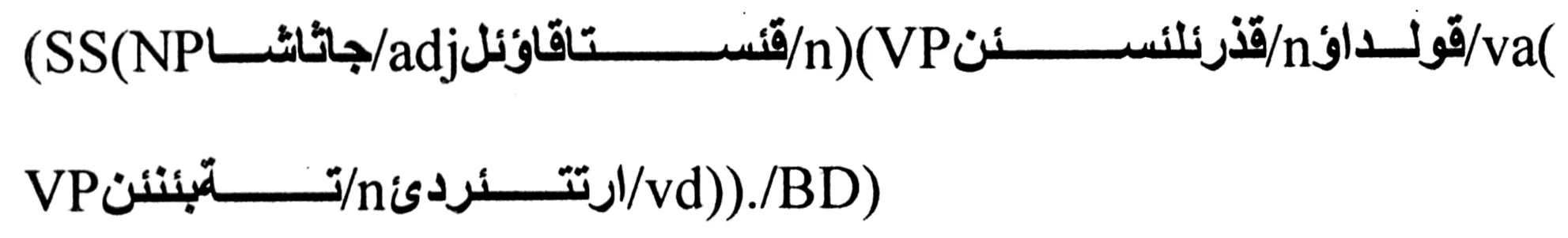
上述句子中未将n+va的动词短语(VP)组合识别出来,从而造成低层组块识别不全的情况。
3 实验结果及分析
3.1语料准备及评价指标
实验语料为新疆日报(哈语版)2008年20天的已被准确分词和词性标注的数据,由于目前哈萨克语树库构建处于初级阶段,所以重点研究简单句的句法标记。题材包括政治、经济、文化、体育、娱乐、军事等,共5469条语句,并将语料分成两部分进行哈萨克语树库构建的分析实验。5天的语料做封闭测试,15天的语料做开放测试。本文在实验结果的评测中,采用了标准的评测方式,分为准确率P(Precision)、召回率R(Recall)和F值F(F-score)。
准确率:P=N3/N2×100%
(4)
召回率:R=N3/N1×100%
(5)
以及综合反映二者的指标:
F=(β2+1)×P×R/(R+β2×P),β=1
(6)
其中N1:测试语料中实际的短语或括号对数量
N2:系统自动识别出的短语或括号对数量
N3:系统正确识别出的短语或括号对数量
系统中语料的输入输出模式主要如图4、图5所示。
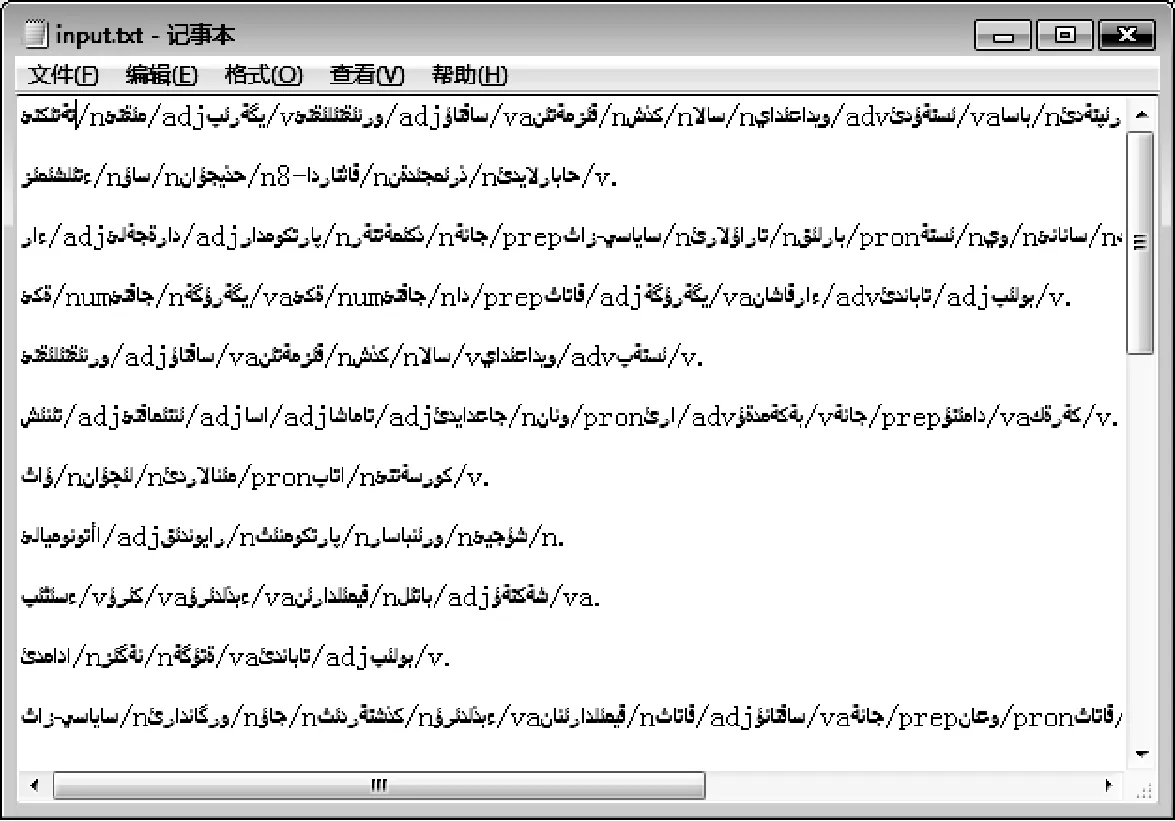
图4 输入文件(带有分词和词性标记的句子)
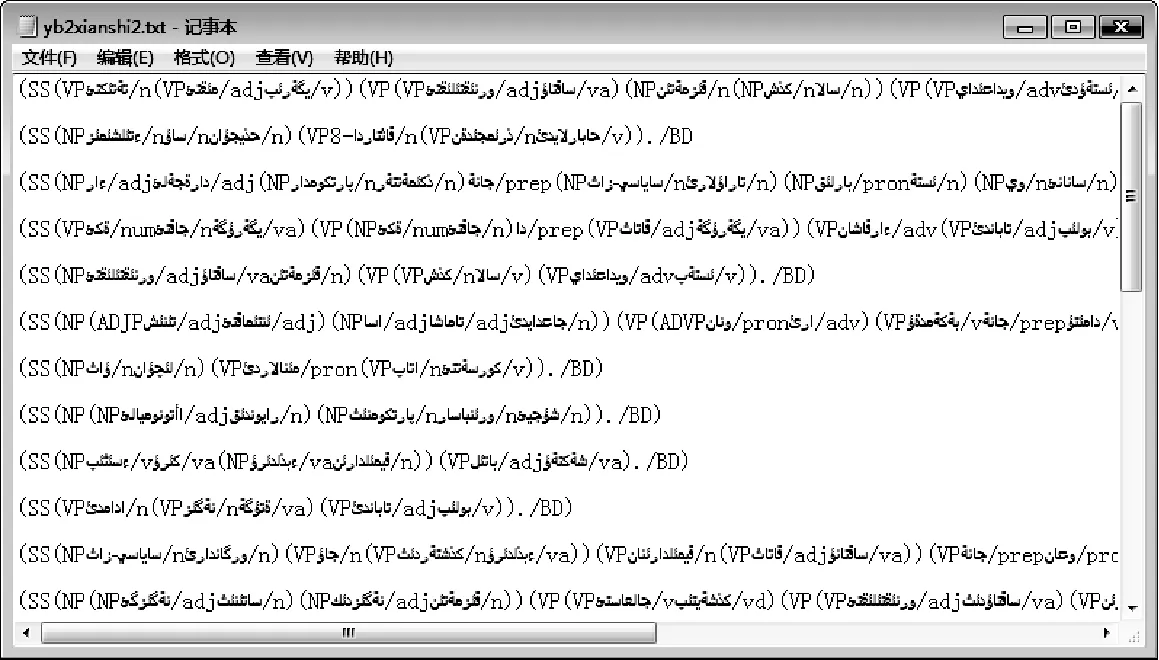
图5 输出文件(带有基于短语结构的句法标记句子)
3.2实验结果对比及分析
在自动句法标记中,我们通过开放测试和封闭测试两个评测方向进行了对比试验。对CCRFs+人工模板选择、CCRFs+增益式模板自动选择和CCRFs+增益式模板自动选择+基于转换的错误驱动学习的后处理模块进行了对比试验,如表6所示。
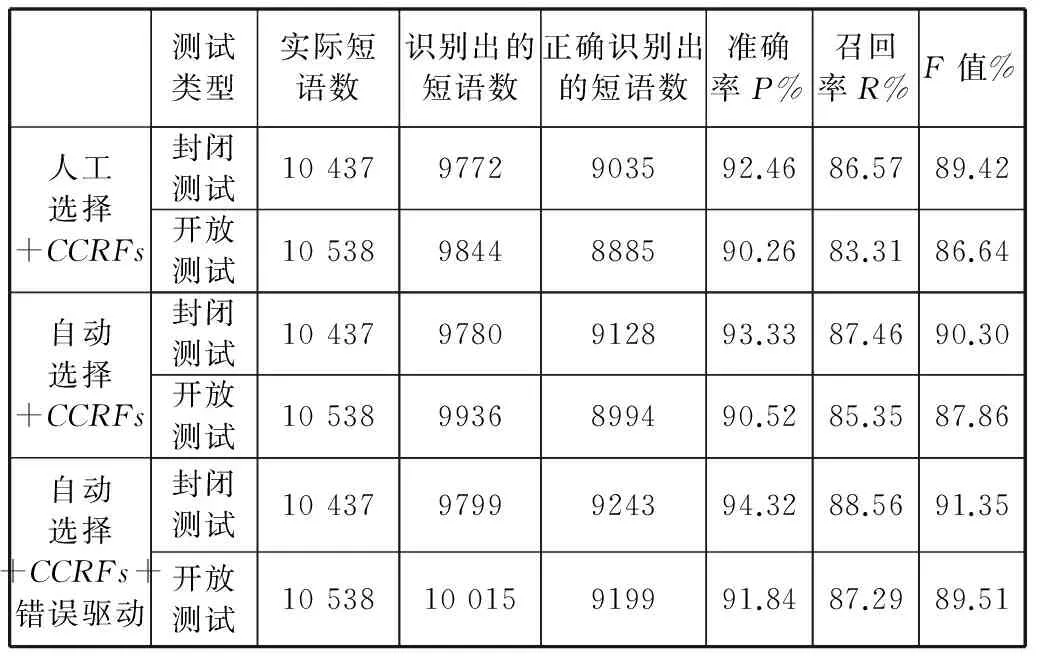
表6 采用不同方法的CCRFs实验结果比较
从实验结果可以看出,基于层叠的条件随机场模型+增益式选择模板及引入基于转换的错误驱动学习算法的识别效果,相对于基于层叠的条件随机场模型外加人工选择模板有了较大的改进。提高了整体自动句法标记的准确率,同时降低了低层模型对高层模型造成错误蔓延的发生率。
在自动句法标注结果的基础上我们加入了人工校对的处理环节,同时对人工校对前后的树库构建的整体准确率进行了对比试验,如图6所示。
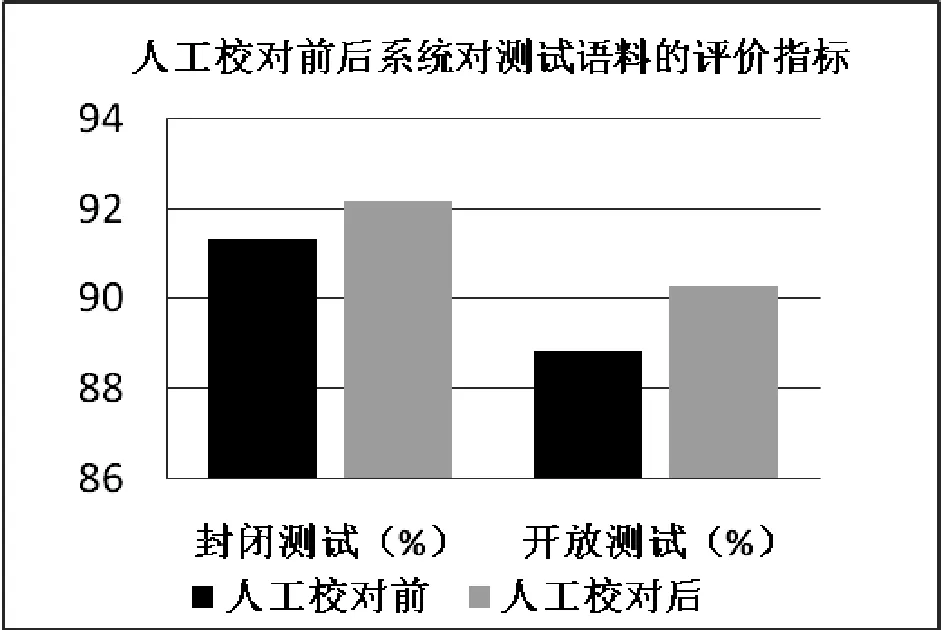
图6 人工校对前后系统对测试语料的评价指标
由图6可知:人工校对的介入对于哈萨克语树库构建的影响之大,且开放测试语料的人工处理效果明显优于封闭测试语料的人工处理效果。
由以上两个实验的对比,我们通过自动模板选择进行基于层叠条件随机场模型的自动句法标注,并加入基于错误驱动的学习算法后做一个整体的树库构建性能对比。其中缺失括号对指在句子中缺失半个括号或者未标记出的括号对,既每个句子的平均括号缺失对的数目。括号正确率及召回率分别为式(4)和式(5)所示,具体的实验性能对比如表7所示。
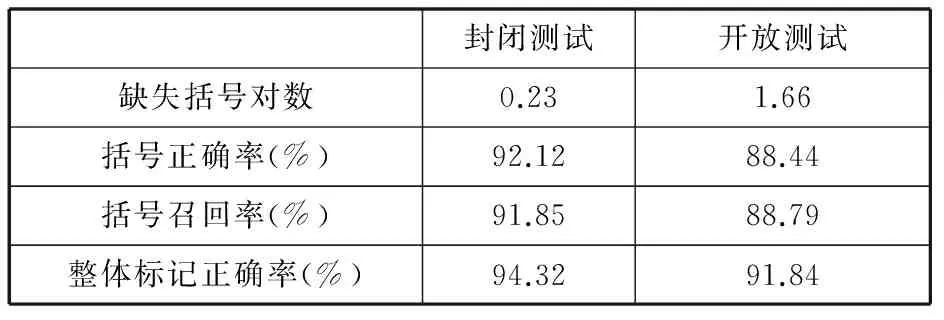
表7 哈语语料整体句法标注性能对比
从上表可以看出,平均每个句子的括号缺失对数相对比较少,原因是采用层叠条件随机场模型进行分层句法标记时。对待标记的序列采用的“BIO”标记法,它的优点在于至少是两个词、两个短语、一个短语和一个词组成的嵌套短语或者复杂短语,所以在标记的时,如果是短语,必定存在短语开头“B-”+“短语类型”及短语结尾“I-”+“短语类型”。括号对不全的情况较低,只存在未标注出的短语情况,既缺失一对的括号。
4 结 语
本文介绍了构建哈萨克语树库流程及方法,首先选取了哈语句法标记集,同时提出了采用基于层叠条件随机场进行哈萨克语自动句法标注。在层叠条件随机场模型中,文中在低层模型与高层模型之间加入了基于转换的错误驱动学习算法,减少其造成的错误蔓延同时提高标注准确率。最后对整体标注结果进行人工校对从而完善树库。从目前的实验结果来看,我们证明了该方法在特殊的哈语自动句法标注层面的有效性,也为我们在自动句法标注和人工校正方面积累了一定的经验。但目前哈语树库构建处于初级阶段,实验语料规模较小,因此需要后期在以下几个方面做进一步提升:1) 增加哈萨克语语料规模并分析处理,发现新的语言现象;2) 补充及完善树库句法标记规范,确保机器自动标注与人工标注的一致性;3) 提出新的技术,能够更好地分析复杂句子,加强句子的排歧能力,从而降低人工校对的工作量。
[1]NianwenXue,FuDongChiou,MarthaPalmer.BuildingaLarge-ScaleAnnotatedChineseCorpus[C]//Proc.of19thInternationalConferenceonComputationalLinguistics(COLING-02),Taiwan,2002:1-7.
[2]ChuRenHuang,FengYiChen,ZhaomingGao,etal.SinicaTreebank:designcriteria,annotationguidelines,andon-lineinterface[C]//ProceedingsoftheSecondWorkshopChineseLanguageProcessing,HongKong,2000:29-37.
[3]WojciechSkut,ThorstenBrants,BrigitteKrenn,etal.AlinguisticallyinterpretedcorpusofGermanNewspapertext[C]//ProceedingsoftheConferenceonLanguageResourcesandEvaluationLREC-98.Granade,Spain,1998:705-711.
[4]SabineBrants,SilviaHansen.DevelopmentsintheTIGERannotationschemeandtheirrealizationinthecorpus[C]//ProceedingsoftheThirdConferenceonLanguageResourcesandEvaluation(LREC-02).LasPalmasdeGranCanaria,Spain,2002:1643-1649.
[5] 古丽拉·阿东别克,达吾勒·阿布都哈依尔,木合亚提·尼亚孜别克,等.现代哈萨克语词级标注语料库的构建研究(特邀文章)[J].新疆大学学报:自然科学版,2009,26(4):394-401.
[6] 侯呈风,古丽拉·阿东别克,陈景超.基于HMM的哈萨克语词性标注研究 [J].计算机应用与软件,2012,29(2):31-33.
[7] 孙瑞娜,古丽拉·阿东别克.哈萨克语基本名词短语自动识别研究与实现[J].中文信息学报, 2010,24(6):114-119.
[8] 古丽扎达·海沙.哈萨克语基本动词短语自动识别研究[D].新疆:新疆大学信息科学与工程学院, 2013.
[9] 周强,张伟,俞士汶.汉语树库的构建[J].中文信息学报,1997,11(4):42-51.
[10] 周强,任海波,孙茂松.分阶段构建汉语树库[C]//第二届中日自然语言处理专家研讨会,2006,5:189-197.
[11] 周强, 俞士汶.汉语短语标注标记集的确定[J].中文信息学报,1996,10(4):1-11.
[12]MarcusMP,MarcinkiewiczMA,SantoriniB.BuildingaLargeAnnotatedCorpusofEnglish:ThePennTreeband[J].ComputationalLinguistics,1993,19(2):313-330.
[13] 张定京.现代哈萨克语使用语法(语法形式篇)[M].北京:中央民族大学出版社,2004.
[14] 桑海岩,古丽拉·阿东别克,牛宁宁.基于最大熵的哈萨克语词性标注模型[J].计算机工程与应用,2013,49(11):126-129.
[15] 侯呈风,古丽拉·阿东别克.改进的HMM应用于哈萨克语词性标注[J].计算机工程与应用,2010,46(36):147-149.
[16]RamshowLA,MarcusMP.Textchunkingusingtransformation-basedlearning[C]//ProceedingsoftheThirdACLWorkshoponVeryLargeCorpora,1995:82-94.
[17]EricBrill.Transformation-basederror-drivelearningandnaturallanguageprocessing:acasestudyinpartofspeechtagging[J].ComputationalLinguistics,1995,21(4):543-565.
RESEARCH ON THE TECHNOLOGY OF BUILDING KAZAKH TREEBANK BASED ON CASCADED CONDITIONAL RANDOM FIELD
Yu ZhijuanGulia·Altenbek
(SchoolofInformationScienceandEngineering,XinjiangUniversity,Urumqi830046,Xinjiang,China)
On the issue of how to improve the processing performance of statistical analysis-based Kazakh syntax parsing algorithm, this paper proposes a method of constructing the Kazakh treebank by human-computer interaction. In automatic syntax annotation stage, it achieves by using the cascade conditional random field model. And between its low-level and high-level models it adds the improved and transformation-based error-driven learning algorithm to carry out automatic syntax annotation and automatic correction of the simple sentences. Finally for special entire marking errors the artificial proofreading will be conducted, thus the method forms the phrase structure-based Kazakh treebank. Experimental results show that this method reduces to a large extent the investment on human power and material resources, improves the parsing accuracy and overall processing efficiency. Moreover, it lays the certain foundation for the Kazakh-based syntactic machine translation and text mining afterwards.
Kazakh treebankHuman-machine interactionCascade conditional random fieldsError-driven learning algorithm
2014-09-12。国家自然科学基金项目(61063025,61363062)。于智娟,硕士,主研领域:自然语言信息处理。古丽拉·阿东别克,教授。
TP391.1
A
10.3969/j.issn.1000-386x.2016.03.015
