一种面向专利摘要的领域术语抽取方法
2016-09-26吕学强
曾 镇 吕学强 李 卓
(北京信息科技大学网络文化与数字传播北京市重点实验室 北京 100101)
一种面向专利摘要的领域术语抽取方法
曾镇吕学强李卓
(北京信息科技大学网络文化与数字传播北京市重点实验室北京 100101)
专利领域中术语抽取结果的好坏决定了本体构建的质量。提出一种自动生成过滤词典并结合词汇密集度等影响因子的术语抽取方法。首先在分词和词性标注的基础上,对文献匹配词性规则算法生成的模板得到候选长术语和单词型短术语集合,然后利用文档一致度生成的过滤词典过滤部分候选长术语集,最后针对长术语的构成特点,将词汇密集度、文档差比、文档一致度三个术语因子加权平均作为整个长术语的术语权重值,并按值高低排序。在8000篇专利摘要文献的基准语料上进行实验,随机选取五组实验数据,平均准确率达到86%。结果表明该方法在领域术语抽取方面是行之有效的。
领域术语本体构建过滤词典词汇密集度
0 引 言
专利文献作为技术信息的有效载体,涵盖了全球90%以上的最新技术情报[1]。由于70%~80%的发明创造都只能通过专利文献的形式发表,专利文献本身蕴含了巨大的信息价值。为了增强自身竞争力,越来越多的企业也开始把目光投向了专利文献,一方面通过专利申请来保障自己的发明成果,另一方面通过专利检索了解同行的最新技术进展情况,不断学习,使自己在激烈的市场竞争中保持不败之地。因此对于专利信息部门,从专利文献中抽取有效知识,构建一个基于专利文献的本体知识库,为各企业、技术人员提供专利检索和专利预警、专利分析的支持是一个迫切而又有意义的工作。
本体构建的首要任务便是从专利文本中自动抽取出概念术语,且获得的术语准确率的高低直接影响后续的本体框架。目前很多学者都开展了这方面的研究,总的来说主要分为基于规则的方法、基于统计的方法以及两者结合的方法。从总体效果方面来看,规则与统计结合的方法更占优势。韦小丽[2]等提出采用最大熵模型的机器学习算法来提取领域概念术语。施水才[3]等运用条件随机场模型来构建合理的特征模板达到识别领域术语的效果。上述方法虽不依赖规则的制定、且可移植性较强,但需耗费一定的人力来标注训练语料,训练语料的规模也会最终影响到实验结果。文献[4-7]使用了互信息、对数似然比和C-value这类统计量在大规模语料中抽取术语。该方法很难处理单篇文档,且互信息容易错误识别经常搭配的非术语短语。刘豹[8]尝试将统计机器学习方法和规则结合起来抽取术语,虽取得了不错的效果,但缺乏对体现领域特点的长术语的识别。汤青[9]采用基于术语部件库的方法实现术语抽取,该方法对于部件库的质量有着严格的要求,不存在已知部件库的术语很难被识别。徐川[10]分析字符串之间的结合强度,提出边界结合度、串边结合度等概念抽取术语,该方法不易识别缺乏固定搭配的术语。文献[11]集成统计和规则的方法,能够挖掘大规模新词术语,但同时也引入大量如“供 选择”这类非术语固定搭配的噪音词汇。
上述研究中所抽取出来的术语从严格意义上来讲只能称为短语,几乎未能体现术语的领域特性。针对上述方法所存在的不足,该文提出一种首先利用词性规则模板得到候选的单词型短术语和多词长术语集合,然后计算词汇密集度权重参数来抽取单词型术语,最后结合平衡语料自动生成一部过滤词典,通过过滤词典和组成该长术语的每个词的术语因子筛选出最终的长术语的方法。过滤词典由于利用领域一致度动态生成,且较好的筛选掉部分非术语常用搭配噪音信息,能很好地跨领域移植。对构成长术语的原子词语赋予其术语权重,加权平均其术语权重值,作为整个长术语的术语度,最后按术语度对术语进行排序。排名越靠前其成为术语的可能性越大, 剩下的非术语常用搭配由于其组成词语术语权重值均偏低,其排名偏靠后,这种随可信度分布的术语词表可以提供用户更灵活的选择。
1 词性规则模板
1.1语料预处理
专利摘要作为对整个专利的介绍说明,是整篇专利文档核心内容,蕴含丰富的价值信息。其内容一般涵盖以下几部分:对专利的用途介绍、专利的工作原理阐述、专利的创新改进之处,专利的功效矩阵、以及专利的应用领域。
对8 000篇新能源电动汽车领域的专利摘要进行分词和词性标注的文档预处理。分词工具选用中科院自主开发的ICTCLAS,ICTCLAS运用隐马尔科夫模型进行分词,融合了实体识别、未登录词识别和词性标注等功能模块,是市面上十分成熟的一个分词软件。
1.2词性规则生成算法
术语按其组成长度可划分为单词短术语和多词长术语[12],单词短术语由单个词汇构成,下文简称短术语,多词长术语一般由2到6个词组成。作为某个领域反复使用、形势较为固定又表达某特定概念的词语,术语的组成结构一般具有词性特点。单词短术语一般为名词n或动名词vn。多词型长术语的词性规则比较复杂,常见的搭配有n+n、vn+n、b+v+n等。Sui在文献[11]总结了2词-6词的术语构词规则。该规则比较宽松,对特定的领域语料并不十分实用。在大量研究专利文献的基础上,发现标题多为体现该专利创新的领域特色的长术语,且其嵌套词组也多为术语。基于这个现象,设计一个针对实验文献自动生成词性规则的算法。算法流程如下所示:
输入:标题字符串集合T={T1,T2,…T8000},TI=W1,W2,…,Wn(i=1,…,8000)
文本字符串集合D={D1,D2,…,DM},Di=W1,W2,…,Wn(i=1,…,m)
文本字符串以标点符号为分隔符,WI为词性标记
输出:HashMap,其key为词性规则WI,value为规则频次
流程:for T1to T800
Begin
IF D包含TI|| D包含Ti的字串Sub(Ti)
IF Ti||Sub(Ti)不存在HashMap中
HashMap.add(Ti||Sub(Ti),1)
Else
从HashMap取得其对应的value
HashMap.put(Ti||Sub(Ti),value++)
Repeat;
长术语由于其词汇繁多,结构复杂成为术语抽取的一个难点。该算法从文献的实际特点出发,其生成的长术语的构词规则更符合其在整个文献的实际频次分布。在HashMap结果集中取出长度为2到6且频次为前三名的词性规则,如表1所示。

表1 部分术语词性构词规则
表1中,n表示名词,vn表示动名词,v表示动词,m表示数词,b表示区分词,u表示助词。将上述词性规则作为模板在文献里匹配得到候选多词长术语集。筛选出所有词性标注为名词或动名词的词语作为候选短术语集。本文的规则自动生成算法解决了通用规则准确性差和领域适应性低的问题。
2 过滤词典
术语作为在专有学科领域内具有高流通量的词汇,其本身含有极强的专业性,且与日常生活领域交集甚少。某些明显不含领域专业信息,却在日常生活常见的词汇,如“我们”、“简单”、等,可以通过判断候选术语是否包含它们筛选出非术语,从而实现最终的术语抽取。这里将其定义为过滤词,好的过滤词典能保证抽取术语质量的好坏。现有专利领域内往往不存在专业的过滤词典,一方面是词典的构建需要耗费大量人力,另一方面词典限制了其他领域的适应性,不易移植,对外部资源依赖性大。本文借鉴领域一致度[13]用在平衡语料上,实现过滤词典的自动生成。
定义1领域文档一致度是指某术语在不同领域类别的文档分布一致情况。设有k个不同领域D={D1,D2,…,Dk},每个领域的文档数为{T1,T2,…,TK}。则候选术语t的领域文档一致度定义为:
(1)
其中概率P(t,Dj)可用频率估计:
(2)
其中,f(t,Dj)表示候选术语在领域Dj内出现的文档数。当候选术语t在平衡语料各个领域内出现的文档分布越均匀时,其文档一致度H(t)也就越大,说明其很大可能上是过滤词。专业的术语在其他领域内并不流通、很少甚至不出现,其分布极不平衡,故其领域文档一致度偏小。依据式(1)和平衡语料能自动生成一部过滤词典,借助过滤词典能从候选术语集筛选出大部分明显不是术语的词组。部分过滤词如表2所示。

表2 部分过滤词
3 词汇密集度和文档差比
观察专利文档发现,术语对领域依赖性较强,作为领域核心知识的载体,同一术语往往会在单篇文档内被反复提到。基于以上规律,提出词汇密集度的概念。
定义2候选术语t在单篇文档的平均词频表示t在领域文档内的密集程度。术语t的密集程度可以用公式表示为:
(3)
其中,tf(t)表示术语t在整个领域内的出现频次,df(t)表示术语t在领域内出现的文档数。术语的密集度并不能有效区分一些不属于本领域的基础术语和常用词汇。如“化合物”、“微生物”等词已延伸到各个学术、生活领域中。通过候选术语的在领域文档和平衡文档的文档差比来加权平均,定义一个综合指标来筛选单词集中的单词短术语。
(4)
其中,DF、PF分别表示领域文档总数和平衡文档总数,权重α和β表示词汇密集度和文档差比各自的贡献度。df(t)和pf(t)指示候选术语t在领域文档的文档频次和平衡文档的文档频次。当候选术语t的词汇密集度较大时,t可能为领域术语,但也将日常用语如“感觉”、“意识”、“结果”等错选为领域术语。但该类词语在其他领域也应用广泛,即其领域文档差比值教小,真正的领域术语存在在本领域密集分布,平衡领域鲜有出现的现象,最终使得其综合指标D(t)值偏大,而达到过滤单词术语的效果。
一般而言,人们所掌握的词汇是有限的,如果在构建专业术语时大量引入新的词汇,会阻碍技术之间的交流和知识的普及。这就出现了频繁使用已有单词来构成新的术语的现象,正是这种背景下,随着学科领域的发展,出现了大批的词组型长术语,并且词组型长术语在整个术语系统中也远远超过了单词型术语的规模。
词组型长术语一般含有核心词语来表示其概念内容,围绕在核心词周围往往还有很多修饰词。所以仅凭长术语中单个词或一两个词很难判定其是否是术语。本文充分考虑组成长术语中的每个词对整体的影响,利用上述提到的式(1)和式(2),设计一个表示单个词对术语贡献度大小的术语权重因子,最后将每个词的术语权重因子加和求均值来表示该长术语成为术语的可能性大小。术语权重因子公式如下:
(5)
其中,H(t)越小,表示该候选术语t在平衡语料中分布越不均匀,其越有可能是领域术语,对H(t)做了取倒操作来与D(t)的变化保持一致。
4 实验和结果分析
本文的实验语料为专利总局提供的8000篇关于新能源电动汽车领域的专利摘要文献。专利摘要一般包含专利标题、专利分类号和申请专利说明。平衡语料选用了搜狗实验室开放的2012年分类语料[14],选取军事、娱乐、女人、旅游、经济、房地产等六大类领域语料各1300篇。
4.1实验步骤
先对所有文档进行分词和词性标注。在此基础上,将规则自动生成算法所生成的候选规则集,保留其前40条最为最终的术语筛选构词规则。采用前向最大匹配算法对专利文档处理,得到候选的词组型长术语22 935个,并按词频从大到小排序。候选单词型短术语集则按名词或动名词属性过滤获取,也按词频排序,数量为13 943。
结合平衡语料,对候选单词型短术语集进行式(1)运算,自动生成一部过滤词典,词汇量大小为1217个。候选单词型短术语集在去除了过滤词典后,继续按式(3)筛选出最终的单词型短术语4216个,其中参数α和β分别设为0.4和0.6。过滤词典则用来去除部分候选词组型长术语。在术语权重排名阶段,式(5)中λ值为max(H(t))。术语可能性越大的排名越靠前,阈值的选定可以按准确率和召回率的要求适当调整。
4.2评价指标
实验结果用准确率、召回率、F值进行评价。由于语料规模较大,加上专家知识有限、很难标注出所有术语,难以计算实际的召回率。为此随机选取五组语料,每组由5篇专利文献组成。对每组文献单独计算其准确率和召回率。
定义3单组正确率,即单组文献中,正确识别的术语数Nt与该组文献中提取到的术语数Tt之比:
(6)
定义4单组召回率,即单组文献中,正确识别术语数Nt与该组文献中所有术语数At之比:
(7)
4.3结果分析
本文利用领域文档一致度公式自动生成了过滤词典。1217个过滤词在候选词组型长术语筛选出8215个非术语。部分结果如表3所示。

表3 部分过滤词筛选出的长术语结果
从表3可以看出,过滤词确实很大程度上解决了规则宽泛所带来的大量错误候选长术语问题,大大提升了候选长术语的质量。过滤词典借助平衡语料自动生成,具有跨领域的优势。但“微生物燃料电池”、“电子散热元件”等术语也被错误地筛选了,这是因为“微生物”、“电子”等基础学术性词汇早已突破了单个学科的限制,融入了人们的日常生活。提高过滤词的筛选阈值可以部分避免这一现象。
对剩余候选长术语利用词汇密集度、文档差比、文档一致度三个加权因素计算其最终的术语权重并对其排序。排序结果如表4所示。
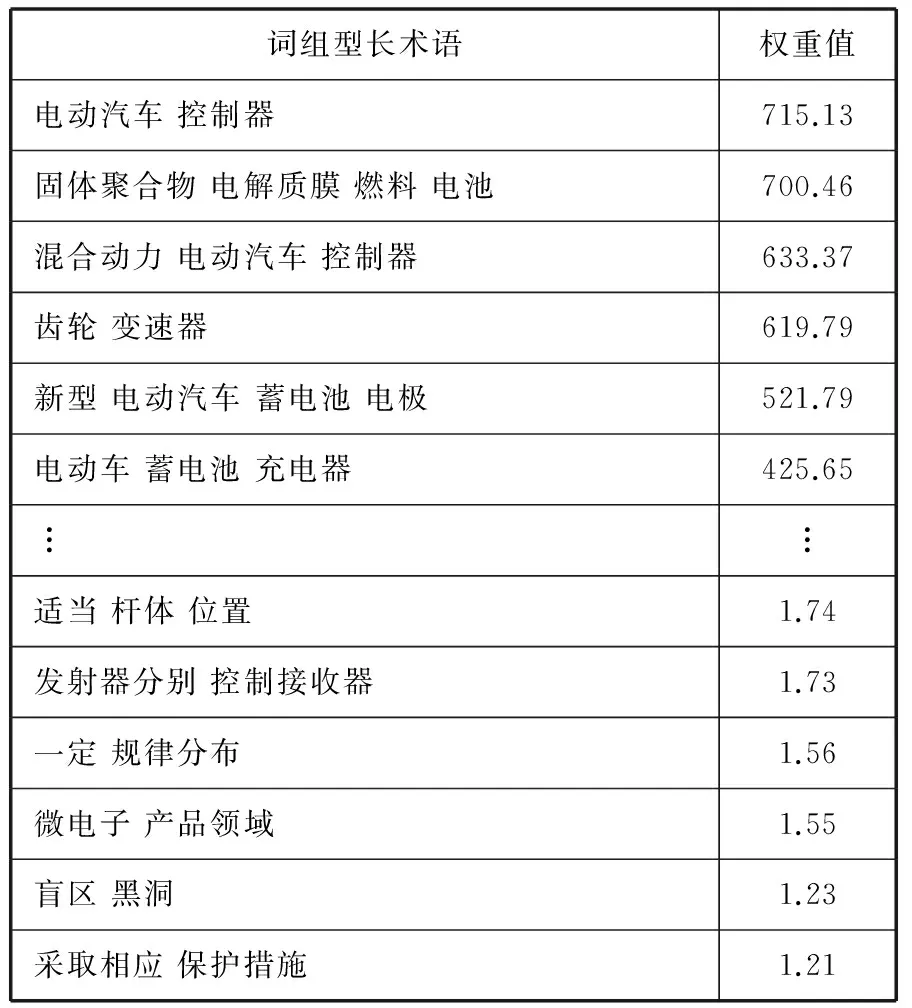
表4 候选长术语排序结果
表4中结果表明该术语权重排名方法较为真实地反映了每个候选词组型长术语代表领域术语的真实程度。排名靠前的长术语均是对新能源电动汽车专利领域内的核心知识表述,具有很强的专业性,集中概括了能源汽车这个领域知识体系的重要知识点。排名靠后的可以明显判断出其不属于术语范畴,大都是分词不规范而满足一定词性规则所遗留下来的短语结构。此外排名靠前的结果集中如“固体聚合物电解质膜燃料电池”这类四词以上的长术语也占了不小的比例,长术语的正确识别,保障了整个术语库的质量,体现出领域知识特点。
以权重值5为阈值,将大于阈值的长术语作为最后的术语识别结果。总共含领域术语10 843个。为了验证该方法在局部专利文献内的识别效果,选定了5组测试文档,每组由5篇专利文献组成,平均每篇文献术语量达到12个。人工标注出领域术语,对照最后的领域长术语集和单词型短术语,计算出单组准确率、单组召回率评价指标。考虑到文献[10]的研究方向也是专利文献的术语抽取,故选取其最终的实验结果作为BaseLine,结果如图1所示。
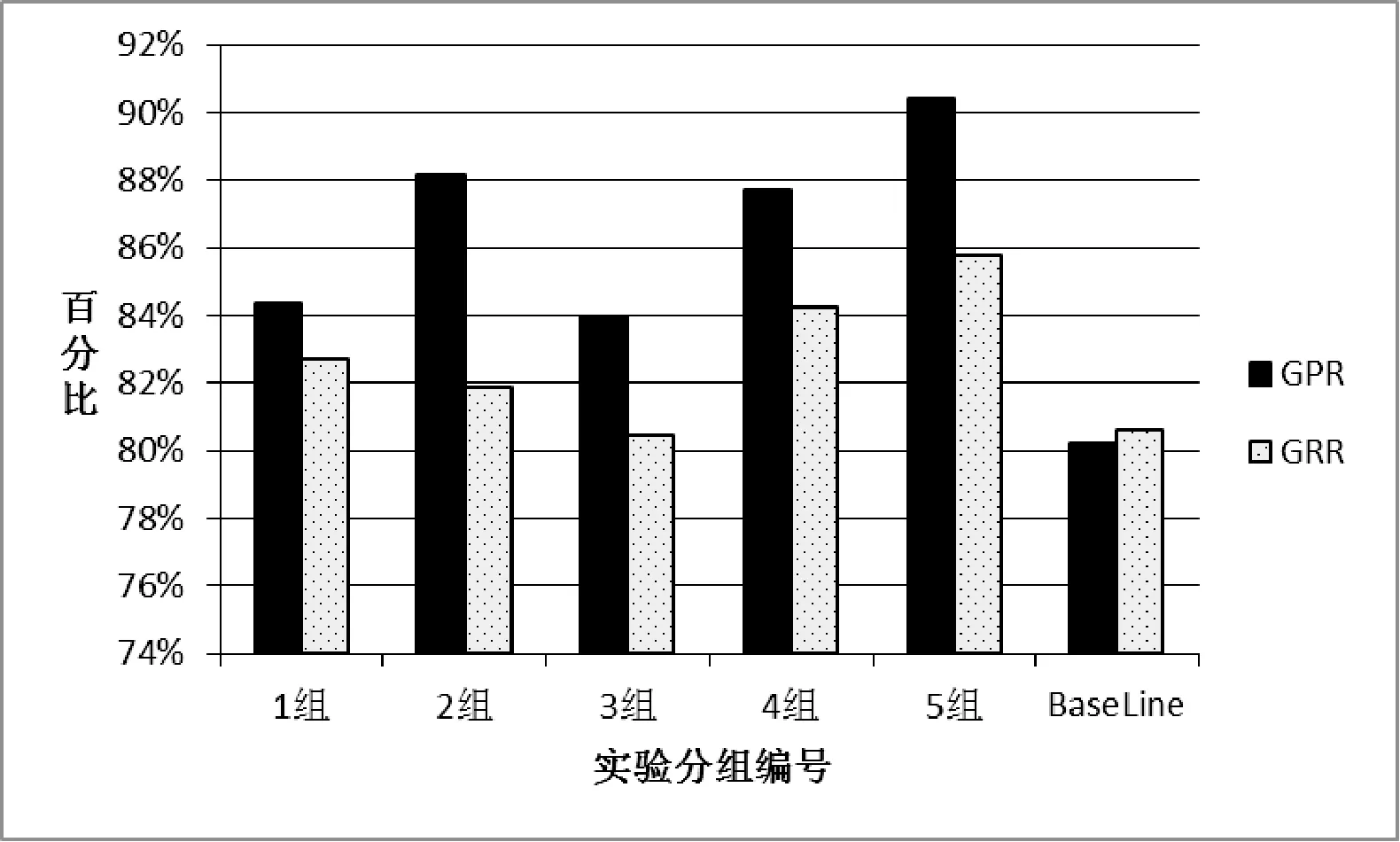
图1 术语抽取实验结果
从图中的统计结果看出,本文提出的方法取得了不错的实验效果,五组专利文档平均准确率达到了86%,召回率达到了82%,相对于BaseLine80.24%的准确率和80.61%的召回率,结果有不小的提高。实验过程中发现,对BaseLine中易识别错误的动宾结构短语,如“发出 信号”等词组,本文生成的过滤词典往往能涵盖到那些常用动词,从而有效地避免了这一现象。BaseLine中存在的常用非术语搭配词组在本方法中一部分被过滤词典成功过滤,一部分自动排序到术语词表末尾处。只剩下分词粒度过大的非术语搭配存在误识别,如“电动汽车 结构简单”、“蓄电池 充电状态”,这类词语因符合词性规则且反复出现,但由于分词软件将“结构简单”、“充电状态”分为单个词,使其在平衡语料中也甚少出现,从而出现了误识别。如将“结构简单”拆分为“结构”、“简单”,“充电状态”拆分为“充电”、“状态”,则能被成功过滤。少量在专利文档内很少出现,没形成统计规律的低频术语,如“电磁波 衰减 材料”等词组,其术语权重排名靠后,在召回它们的同时会带入大量非术语。
5 结 语
专利摘要中领域术语的识别,对后期专利知识库的构建和用户对专利信息的语义检索等方面都有着极为重要的意义。本文从专利文献独有的数据特点出发,设计了易移植的术语词性规则生成算法,根据过滤词在平衡语料内分布比较均匀的特点,利用文档一致度熵公式自动构造过滤词典,达到过滤掉一部分候选长术语的目的,对剩下的数据集结合词汇密集度、文档差比、文档一致度三个针对领域术语的分布规律公式来计算每个候选长术语的术语权重参数,并按值排序,实现术语的自动抽取。在实际应用阶段,如何最大限度准确抽取无明显统计规律的低频候选长术语,提高它们的术语权重排名,是需要进一步改进的地方。
[1] 专利分析系统:专利生命周期评价模型[EB/OL].(2011-08-02).[2014-07-02].http://www.iprtop.com/pages/view/fn/fxxt_7/.
[2] 韦小丽,孙涌,张书奎,等.基于最大熵模型的本体概念获取方法[J].计算机工程,2009,35(24):114-116.
[3] 施水才,王锴,韩艳铧,等.基于条件随机场的领域术语识别研究[J].计算机工程与应用,2013,49(10):147-149.
[4] 胡阿沛,张静,刘俊丽.基于改进C-value方法的中文术语抽取[J].现代图书情报技术,2013,29(2):24-29.
[5] 陈士超,郁滨.面向术语抽取的双阈值互信息过滤方法[J].计算机应用,2011,31(4):1070-1073.
[6] 屈鹏,王惠临.面向信息分析的专利术语抽取研究[J].图书情报工作,2013,57(1):130-135.
[7] 林磊,孙承杰,张二艳,等.一种基于改进似然比的术语自动抽取方法[J].广西师范大学学报:自然科学版,2010(1):153-156.
[8] 刘豹,张桂平,蔡东风.基于统计和规则相结合的科技术语自动抽取研究[J].计算机工程与应用,2008,44(23):147-150.
[9] 汤青,吕学强,李卓,等.领域本体术语抽取研究[J].现代图书情报技术,2014(1):43-50.
[10] 徐川,施水才,房祥,等.中文专利文献术语抽取[J].计算机工程与设计,2013,34(6):2175-2179.
[11] Sui Zhifang,Chen Yirong.The Research on the Automatic Term Extraction in the Domain of Information Science and Technology[C]//Proceedings of the 5th East Asia Forum of the Terminology,2007.
[12] 周浪.中文术语抽取若干问题研究[D].南京:南京理工大学计算机学院,2009.
[13] 傅丽鸟,黄利强,付春雷.一种改进的面向文本的领域概念筛选算法[J].计算机科学,2012,39(Z6):253-256.
[14] 搜狗官方实验室文本分类语料库.[EB/OL].(2008-06-30).[2014-07-02].http://www.sogou.com/labs/dl/c.html.
A FIELD TERMINOLOGY EXTRACTION METHOD FOR PATENT ABSTRACTS
Zeng ZhenLü XueqiangLi Zhuo
(BeijingKeyLaboratoryofInternetCultureandDigitalDisseminationResearch,BeijingInformationScienceandTechnologyUniversity,Beijing100101,China)
The quality of ontology is determined by the result of terminology extraction in patent field. In this paper we propose a method of terminology extraction, which automatically generates the filtering dictionary and combines the effect of factors such as the intensity of vocabulary terms. First, on the basis of word segmentation and parts of speech tagging, it matches the template generated by the parts of speech rule algorithm on the literatures and gets the candidate long terms set and word-type short terms set. Then it uses the filtering dictionaries generated with documentation coincidence to filter part of the candidate long term set. Finally, in light of the characteristic of long terms constitution, it uses the weighted average of three term factors of word intensity, document discrepancy ratio and document consistency as the term weight of whole long terms, and sorts them from high to low. Experiments were conducted on the benchmark corpus of 8000 patent summary literatures, and we randomly selected five sets of experimental data, the average accuracy rate achieved 86%. Results showed that the method was effective in the aspect of field terminology extraction.
Field terminologyOntology creationFiltering dictionaryWords intensity
2014-07-20。国家自然科学基金项目(61271304);北京市教委科技发展计划重点项目暨北京市自然科学基金B类重点项目(KZ201311232037);北京市属高等学校创新团队建设与教师职业发展计划项目(IDHT20130519)。曾镇,硕士,主研领域:中文信息处理。吕学强,博士。李卓,研究员。
TP3
A
10.3969/j.issn.1000-386x.2016.03.010
