基于随机森林的地表下沉系数求取方法
2016-09-22赵保成谭志祥邓喀中
赵保成, 谭志祥, 邓喀中
(1.中国矿业大学 环境与测绘学院,江苏 徐州 221116; 2.中国矿业大学 江苏省资源环境信息工程重点实验室,江苏 徐州 221116)
基于随机森林的地表下沉系数求取方法
赵保成1,2,谭志祥1,2,邓喀中1,2
(1.中国矿业大学 环境与测绘学院,江苏 徐州221116; 2.中国矿业大学 江苏省资源环境信息工程重点实验室,江苏 徐州221116)
地表下沉系数是开采沉陷预计的重要参数。文章介绍了随机森林回归算法的基本原理以及基本的实现流程,讨论了影响地表下沉系数的地质采矿因素,建立了一种用于计算下沉系数的随机森林回归预测模型。对模型的测试结果表明,预测值与实际值的最大相对误差为3.52%,最小相对误差仅为1.06%。利用该预测模型求取下沉系数不仅速度快,而且具有较高的精度,可以在实际工程中推广应用,该模型为求取下沉系数提供了新的途径。
随机森林;地表下沉系数;开采沉陷;回归模型
0 引 言
地表下沉系数是开采沉陷预计中的一个关键性参数[1-2],该参数传统的求取方法是在开采工作面上方建立地表移动观测站,然后通过实测下沉、水平移动或者两者联合的数据反演求得。该方法求得的地表下沉系数较为准确可靠,但是存在耗时、耗力的缺点,并且不能满足矿山的长期发展需求[3]。目前,相关研究成果是将非线性回归模型引入地表下沉系数的求取。文献[4]将神经网络应用在下沉系数的求取,文献[5]采用了粒子群和支持向量机结合的算法,文献[6]提出了遗传算法与广义神经网络结合的方法等。多种智能优化算法的应用为地表下沉系数的求取方法提供了更多的选择。
1 随机森林理论
1.1随机森林的基础
RF的基础单位是决策树模型[11],它具有3种代表对象属性的节点,即根部节点、中间节点、叶端节点,而经由节点的路径表示对象可能的属性值。从根部节点起始,转经中间节点,最后终止于叶端节点的路径表示某种特定的规则,该规则是唯一确定的。回归决策树的基本思想是通过分析以上路径,产生一系列的回归规则,最后利用这些规则进行数据的预测。
1.2随机森林回归模型的构造
RF算法最早由LeoBreiman提出,它是由若干决策树组成的组合模型。每一棵决策树近似地表示了某些学科(某些变量)内的“小专家”,RF则是由这些专家组成的智囊团,最终模型的预测值要经过专家组织的“听证会”(取平均值)得出。这个智囊团被称为RF回归模型[12],计算公式为:
(1)
其中,H(x)为RF的输出预测值;n为决策树的数目;h(X,θi)(i=1,…,n)为单个决策树模型;θi为第i棵决策树生成的随机向量,它决定了决策树的生长方式;X为训练子集,由原始数据抽取得到。RF中的每棵决策树都必须依靠1个随机向量和1个训练子集。
1.3随机森林回归的流程
(1) 采用有放回的重采样的技术从训练数据集中随机抽取k个自主样本集,以此来构建具备k棵决策树的RF回归预测模型。采样过程中没有被抽到的样本组成k个袋外数据(out-of-bag,OOB),作为RF的测试样本。
在此次停工吹扫期间,严格把关。在流程较长和换热器较多的管线吹扫过程中,先从后端换热器给汽贯通赶油,可确保快速贯通和赶油,再依次从后往前赶油贯通,直至整个流程贯通,在吹扫过程中快速贯通是关键,一方面可有效保证管线大量油赶至塔内,主路畅通,另一方面可确保蒸汽和主线温度,防止产生大量冷凝水。贯通赶油完毕后,关死或关小后端给汽点蒸汽,再从前往后给汽憋压吹扫。在憋压吹扫期间,逐台换热器进行憋压吹扫。每台换热器憋压至少三次,直至出口放空蒸汽无油渍,换热器吹扫干净后,出口重污油过汽,换热器跨线过汽5 min,吹扫线路上每个放空均要确保畅通和见汽。
(2) 在决策树模型中间节点处,在所有变量中随机抽取n个变量作为备选分枝变量,个数要远小于原始训练集的变量个数,最后根据分枝优度准则选择最佳分枝。
(3) 每棵决策树从根部节点起始,到叶端节点终止,逐渐递归分枝,RF预测模型中可以调节叶端节点的最小尺寸参数,实现对决策树生长以及RF生成的控制。
(4) 由以上步骤产生的k棵决策树组成RF回归预测模型,该模型的回归预测效果采用OOB预测的误差率评价。
2 RF回归应用于求取地表下沉系数
2.1影响地表下沉系数的地质采矿因素分析
影响地表下沉系数的地质采矿因素众多,自20世纪50年代起,我国在一些主要矿区积累了上千条观测线的实测资料,为我国“三下”采煤研究建立了巨大的知识库。经过几十年的开采沉陷规律研究,我国科技工作者总结出了诸多求取沉陷预计参数的经验公式[13]。常见的求取地表下沉系数的经验公式有:
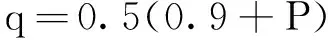
(2)
(3)
(4)
其中,P为上覆岩层的综合评价性系数;E为岩体的综合变形模量;Em为中等硬岩石的变形模量,一般认为Em=3 600MPa;ρ为上覆岩石的平均密度;qf为在重复采动情况下的下沉系数;α为岩层的活化系数;qc为初次采动情况下的下沉系数;H为开采深度;M为开采厚度。从以上的经验公式可以看出,地表下沉系数主要与上覆岩层的性质、开采深度、开采厚度、坚硬岩层所占比例、重复采动等地质采矿因素有关。此外,有关研究还表明,地表下沉系数还与松散层厚度δ以及顶板管理方法有较大的关系[14]。
2.2训练与测试样本的选择
与经典的线性回归分析一样,RF回归模型通过一组自变量对某一因变量作解释,即用地质采矿因素反映地表下沉系数。由于是否重复采动属于定性因素,与采厚和松散层厚度等定量因素很难一起做回归分析,因此选择数值0代表初次采动,1代表重复采动。
为了减小其他可变因素的影响,增强模型的科学性和稳健性,此次试验数据均选择相同的开采方法和顶板管理方法(长壁全垮落法),从文献[14]中挑选34组数据,1~31组数据作为训练样本,32~34组作为测试样本。训练与测试样本见表1所列。

表1 训练与测试样本
2.3回归模型参数设置和泛化性能评价
根据RF回归的原理及实现流程,采用Matlab软件进行编程实现。选择将覆岩的平均坚固性系数f、开采深度H、开采厚度M、松散层厚度δ、坚硬岩层所占比例以及是否重复采动作为输入自变量X,相应的地表下沉系数作为输出因变量Y。
通过简单设置RF回归模型参数,如决策树数目设定为500棵、终止条件即叶端节点尺寸(nodesize)设为5、中间节点处的备选分枝变量的个数设为2,然后对模型进行训练。
泛化性能是评价所建立回归模型预测能力的重要指标,泛化误差越小,回归模型学习训练的效果越好,预测能力越强。在RF回归模型中,存在一种相对优秀的估计泛化误差的方式,即OOB袋外误差估计,其计算公式为:
(5)
该回归模型500棵决策树的OOB误差率如图1所示。
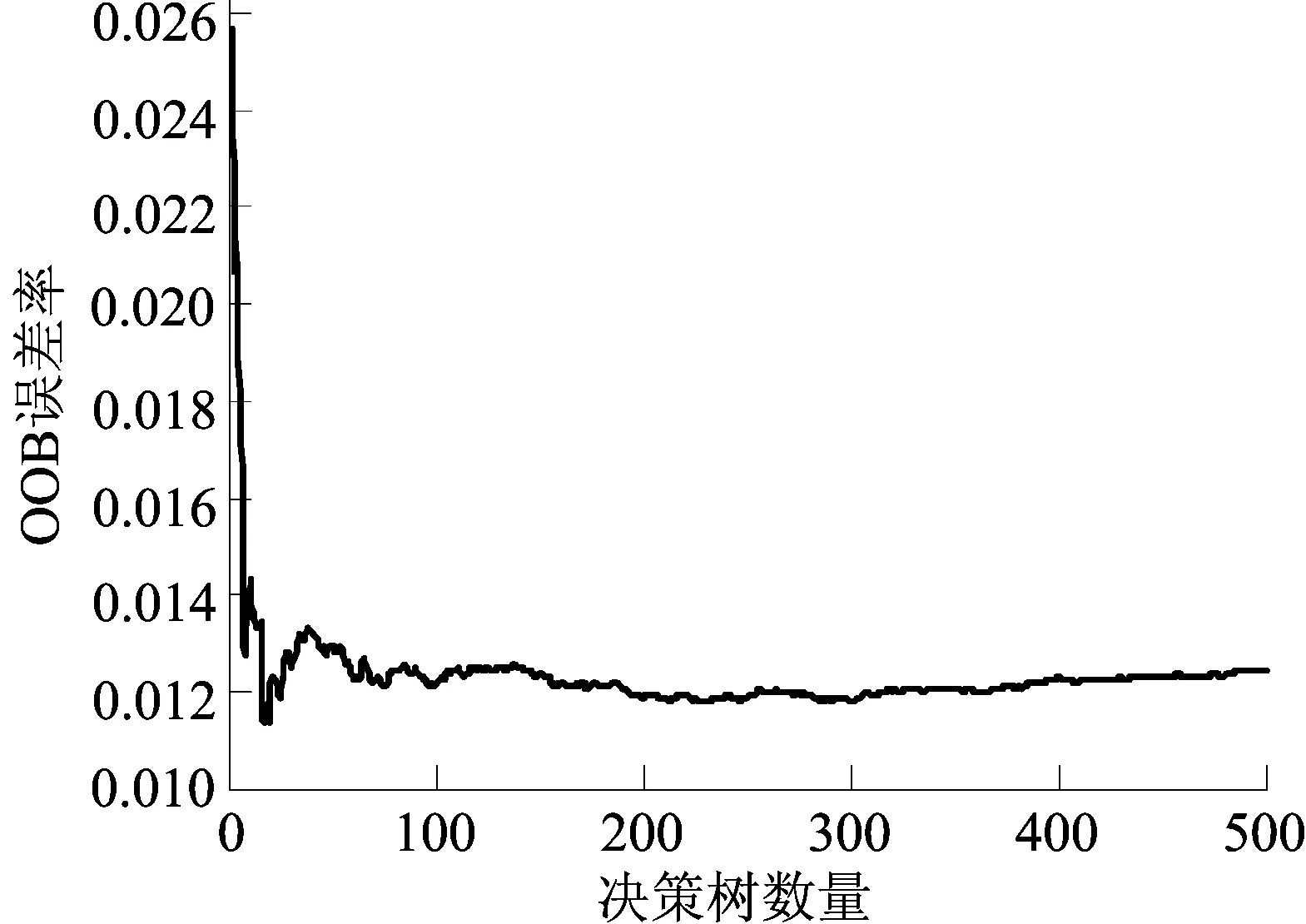
图1 OOB误差率
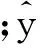
以单棵决策树为基本单位,利用未被RF选中的训练样本点的集合,统计该决策树的OOB误差率,将森林中所有树的误差率取平均值即可得到RF的OOB误差率,OOB估计是泛化误差的无偏估计,该值越小,则说明模型的泛化能力越强。从图1可以看出,该模型稳定后的平均OOB误差率基本控制在0.012。由此可见,该回归模型预测误差较小,学习训练效果很好,预测精度高,具有较强的泛化能力。
2.4测试结果
随机森林回归模型的预测结果与实测结果的对比见表2所列。
由表2可以看出,下沉系数预测值与实测值的最大绝对误差仅为0.029 2,最大相对误差为3.52%,利用该模型预测的结果与实际值误差小,精度高,完全能够满足矿山工程的实际需要,从而证明了利用随机森林回归模型求取地表下沉系数这一方法的可行性与有效性。

表2 下沉系数预测结果与实测结果的比较
3 结 论
(1) 建立了求取地表下沉系数的随机森林回归预测模型,利用大量的地表移动观测站实测数据对回归模型进行学习训练,并且进行了性能测试,试验证明了随机森林回归应用于求取地表下沉系数的可行性、准确性和科学性。
(2) 利用随机森林回归模型求取地表下沉系数,模型简单,方便计算机编程实现,并且参数少,有利于模型的进一步推广和应用。
(3) 同其他非线性预测模型不同,该模型所考虑的因素比较全面,输出结果相对可靠,与传统地表下沉系数求取方法相比,在不失精度的同时节省了财力、物力和时间,为求取地表下沉系数提供了新的途径。
[1]邹友峰.地表下沉系数计算方法研究[J].岩土工程学报,1997,199(3):109-112.
[2]吕伟才,高井祥,蒋法文,等.煤矿开采沉陷自动化监测系统及其精度分析[J].合肥工业大学学报(自然科学版),2015,38(6):846-850.
[3]张敬霞,刘超,龙仁波,等.矿区高精度GPS地表变形监测体系[J].合肥工业大学学报(自然科学版),2013,36(7):855-860.
[4]郭文兵,邓喀中,邹友峰.地表下沉系数计算的人工神经网络方法研究[J].岩土工程学报,2003,25(2):212-215.
[5]于宁锋,杨化超,邓喀中,等.基于PSO和SVM的矿区地表下沉系数预测[J].辽宁工程技术大学学报(自然科学版),2008,27(3):365-367.
[6]王拂晓,谭志祥,邓喀中.基于GA-GRNN的地表下沉系数预测方法研究[J].煤炭工程,2014,46(7):94-96.
[7]李贞子,张涛,武晓岩,等.随机森林回归分析及在代谢调控关系研究中的应用[J].中国卫生统计,2012,29(2):158-160,163.
[8]崔东文.随机森林回归模型及其在污水排放量预测中的应用[J].供水技术,2014,8(1):31-36.
[9]王丽爱,马昌,周旭东,等.基于随机森林回归算法的小麦叶片SPAD值遥感估算[J].农业机械学报,2015,46(1):259-265.
[10]孙雪莲,舒清态,欧光龙,等.基于随机森林回归模型的思茅松人工林生物量遥感估测[J].林业资源管理,2015(1):71-76.
[11]崔东文,金波.基于随机森林回归算法的水生态文明的综合评价[J].水利水电科技进展,2014,34(5):56-60,79.
[12]候艳,杨凯,李康.基于随机森林回归的网络构建方法及应用[J].中国卫生统计,2015,32(4):558-561.
[13]何国清,杨伦,凌赓娣,等.矿山开采沉陷学[M].徐州:中国矿业大学出版社,1991:270.
[14]国家煤炭工业局.建筑物、水体、铁路及主要井巷煤柱留设与压煤开采规程[S].北京:煤炭工业出版社,2000:5.
(责任编辑张淑艳)
Calculationofsurfacesubsidencefactorbasedonrandomforest
ZHAOBaocheng1,2,TANZhixiang1,2,DENGKazhong1,2
(1.SchoolofEnvironmentScienceandSpatialInformatics,ChinaUniversityofMiningandTechnology,Xuzhou221116,China; 2.JiangsuKeyLaboratoryofResourcesandEnvironmentalInformationEngineering,ChinaUniversityofMiningandTechnology,Xuzhou221116,China)
Thesurfacesubsidencefactorisanimportantparameterofminingsubsidenceprediction.Firstly,thebasicprinciplesandtheprocessofrandomforestregressionalgorithmareintroduced.Secondly,thegeologicalandminingfactorsinfluencingthesurfacesubsidencefactorarediscussed.Finally,arandomforestregressionpredictionmodelforcalculatingthevalueofthesubsidencefactorisestablished.Thetestresultsshowthattheminimumrelativeerrorbetweenthepredictivevaluesandtheactualvaluesisonly1.06%,andthemaximumrelativeerroris3.52%.Thesubsidencefactorcanbecalculatedbythepredictionmodelquicklyandaccurately.Thismethodcanbeappliedinpracticalengineering,anditprovidesanewwaytocalculatethesubsidencefactor.
randomforest;surfacesubsidencefactor;miningsubsidence;regressionmodel
2016-03-14;
2016-04-08
国家自然科学基金资助项目(41272389);江苏高校优势学科建设工程资助项目(SZBF2011-6-B35)
赵保成(1990-),男,河南焦作人,中国矿业大学硕士生;
谭志祥(1969-),男,江苏扬州人, 博士,中国矿业大学教授,博士生导师;
10.3969/j.issn.1003-5060.2016.08.023
TD325.2
A
1003-5060(2016)08-1123-04
邓喀中(1957-),男,四川资中人, 博士,中国矿业大学教授,博士生导师.
