基于改进谱哈希的大规模图像检索
2016-09-22夏立超蒋建国齐美彬
夏立超, 蒋建国, 齐美彬
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
基于改进谱哈希的大规模图像检索
夏立超,蒋建国,齐美彬
(合肥工业大学 计算机与信息学院,安徽 合肥230009)
为了提高图像检索精度,文章在谱哈希的基础上引入最小量化误差的思想,提出了一种基于改进谱哈希的大规模图像检索算法,该算法避免了谱哈希中要求的数据服从均匀分布的假设,并且能够保持数据在原始空间的相似性;引入Boosting算法来确定阈值,使得该算法具有更强的适应性和更广泛的应用;在公开的图像数据集上做了实验,实验结果表明该方法优于谱哈希、局部敏感哈希和迭代量化等哈希算法。
哈希;经验误差;拉普拉斯矩阵;Boosting算法
在大规模图像数据检索领域,近似最近邻(approximate nearest neighbor,ANN)检索是计算机视觉中最基本的问题[1-2]。对于近似最近邻(ANN)检索,有很多基于建立索引结构的方法,例如KD树(k-dimensional tree)和R树等,但是当维度很高时,就会产生维数灾难,使其检索效率低于线性检索[3]。为了解决这一问题,基于哈希的图像检索算法[4]成为近年来研究的热点。哈希方法的准则是在原始空间中相似的图像有相似的哈希码,其原理是将高维数据映射至汉明空间,直接用汉明距离进行快速准确的检索。为了进一步提高基于哈希的图像检索效率,近年来有研究者提出建立基于汉明空间索引结构[5]的方法以提高检索效率。
现有的哈希方法大致可以分为数据相关和数据无关2种方法。在数据相互独立前提下的哈希方法中,哈希函数可通过输入数据直接训练而得到,局部敏感哈希(locality-sensitive hashing,LSH)[6]是其中经典的方法,其改进方法有核化局部敏感哈希(kernelized locality-sensitive hashing,KLSH)[7]和拓扑局部敏感哈希[8]等,但这类方法都是基于随机映射,有较大的随机性,因此检索准确率较低。近年来有许多基于数据分布特性的自学习的哈希方法被提出。谱哈希(spectral hashing,SH)的方法[9]创新性地利用谱图分割最优化问题,最终转换为对应的图的拉普拉斯矩阵[10-11]的特征向量求解问题,取得了较好的检索效果。其改进算法有语义一致图谱哈希[12],它是一类有监督算法,利用图像的标签(先验知识)构建最优的拉普拉斯矩阵,提高了检索的精度。谱哈希前提是假设数据服从均匀分布,但实际中很难满足,导致检索准确率低下。迭代量化(Iterative Quantization,ITQ)的方法[13]和K均值笛卡尔哈希[14]均通过旋转数据中心使得映射的量化误差最小。球哈希(spherical hashing,SPH)[15]使用超球面分割原始数据,从而得到相应的球哈希函数,其优势在于哈希函数学习过程的算法复杂度较低,且提高了检索准确率。还有许多基于监督学习的哈希方法,例如监督哈希[12,16]和半监督哈希(semi-supervised hashing,SSH)[17]。
谱哈希算法为了得到数据集的哈希码,需要用流形学习[18]的方法计算拉普拉斯矩阵的特征向量。本文引入迭代量化的经验误差最小化得到哈希码,但不是通过迭代取得最优解,而是通过谱哈希的模型直接求解哈希函数,训练过程中不需要用到流形学习方法,从而摆脱谱哈希要求的数据服从均匀分布的假设,又能保持数据在原始空间的相似性。谱哈希算法假设原始数据在高维空间中服从均匀分布,以理论最优值0为阈值,但是每个图像数据集的数据分布都不尽相同,图像本身的结构化信息丰富,因此以0为阈值并不能适用于所有的哈希方法。本文引入机器学习中的Boosting算法[19],根据不同数据集本身的性质,计算出合适的阈值,使得本文算法对于不同的数据集都具有良好的适应性。
1 算法原理
1.1相关定义与假设
训练集{(xi∈R1×d),i=1,2,…,n}由n幅图像组成,其中xi为第i幅图像对应的d维特征向量;X∈Rn×d为n幅图像组成的训练全集矩阵。{(yi∈{-1,1}1×k),i=1,2,…,n}为n幅图像经过哈希函数转换到汉明空间后对应的哈希编码,其中yi为第i幅图像对应的k维编码向量,Y∈{-1,1}n×k为n幅图像对应的哈希编码矩阵。本文的目标就是要学习得到一系列哈希函数如下:
(1)
第i个哈希函数定义为:
(2)
其中,ωi∈Rd×1为哈希函数的变换矩阵,bi∈R为哈希函数的偏移量。定义W∈Rd×k和B∈R1×k分别为:
(3)
相似图像间的平均汉明距离为:
(4)
其中,D∈Rn×n为训练集的相似度矩阵,本文用高斯核函数计算训练集的相似度矩阵为:
(5)
其中,ε=1。
根据谱哈希的思想,为了保持欧式空间的相似性,需最小化(4)式,即
其中,L为拉普拉斯矩阵,且有:
(7)
谱哈希算法还需要保证映射的扩展性,即当有新的数据时,不需要重新训练,而直接进行编码。谱哈希通过假设数据服从多维均匀分布,用流形学习方法求拉普拉斯矩阵L的特征向量,再阈值化得到哈希码。谱哈希引入拉普拉斯矩阵L并且放松Y(i,j)∈{-1,1}的编码条件,于是(6)式的求解就转换为拉普拉斯特征图的降维。为了解决训练集外图像索引编码问题,将特征向量转换为特征方程,通过有权重的拉普拉斯-贝特拉米算子的特征方程来解决。
本文引入量化误差最小化,避免模型求解过拟合问题,同时可直接求解哈希函数,即W和B。最小化式变换如下:

(8)
其中,Ω(hl)为哈希函数hl的归一化函数;α为原始空间相似度和经验误差间的权重;β为哈希函数归一化权重。根据谱哈希算法原理,(8)式在约束条件下是一个NP-hard解问题,需放宽约束条件才能求解,故将(8)式变换为:
(9)
其中,I1∈Rn×1为一个元素全为1的列向量。
1.2模型求解
分别对(9)式中的W和B求偏导,令偏导数为0,求得W和B分别为:
W=(XTLcX+βId)-1XTLcY,
(10)
其中,Id∈Rd×d为一个单位阵;Lc=In-I1I1T/n,In∈Rn×n为一个单位阵。把(10)式带入 (9)式中,化简目标函数可得:
min tr(YTLY)+tr(YTMY),
(11)
其中
M=Lc-LcX(XTLcX+βId)-1XTLc
(12)
(11)式形如谱哈希(9)式,L*=L+M相当于谱哈希中的拉普拉斯矩阵,通过对矩阵L*求特征值和特征向量,即可求出W和B。
1.3Boosting算法确定阈值
谱哈希算法以理论最优值0为阈值,将特征映射矩阵二值化为二元汉明编码矩阵。本文在谱哈希的基础上引入量化误差最小化,再采用Boosting算法,通过训练获得相应的阈值,使得本文算法具有更好的适应性。
Boosting算法是一种有监督的分类算法,其核心思想是通过学习训练得到一组弱分类器,由弱分类器组合获得需要的强分类器。本文在改进谱哈希算法基础上引入相似度敏感编码Boosting(Boosting similarity sensitive coding)算法[20],对每个数据集分别计算得到相应的阈值。
假设有k个哈希函数,图像训练集矩阵经过哈希函数计算获得阈值的编码矩阵每列需要确定1个阈值,且可作为1个弱分类器,则共有k个弱分类器。通过训练获得最优的k个弱分类器,即k个阈值。引入Boosting算法是为了计算每个哈希函数的阈值,因此不需要将弱分类器组合成强分类器。
为了得到错误率最低的弱分类器,本文将哈希映射的结果进行适当的预处理。假设有n个图像数据,2个为1组,则总共有n2种组合。以图像间近邻与否对每个组合添加标签f,如果图像间相似则为正例且f记为1,否则为反例且f记为0。f计算式为:
(13)
考虑由哈希函数得到的编码矩阵的第j列,即第j个弱分类器,其编码表达式为:
(14)
其中,z(i,j)为编码矩阵第i行第j列的值,即第i个图像的第j个哈希值;Tj为阈值。那么根据以上编码过程,可能产生以下2种不正确的分类。
(1) xa和xb相似,但是通过编码计算后,在第j列上相应的z(a,j)和z(b,j)被二值化成不同的值,例如z(a,j)=1和z(b,j)=0。
(2) xa和xb不相似,但是通过编码计算后,在第j列上相应的z(a,j)和z(b,j)被二值化成相同的值,例如z(a,j)=z(b,j)=0。
本文的目标是利用Boosting算法,训练获得合适的阈值Tj,使得不正确的分类数尽量小。
1.4Boosting确定阈值基本流程
Boosting算法实际将每列的所有值作为可能的阈值,并计算错误率,最终选择错误率最低的数作为阈值。并且在哈希编码矩阵的每列上重复该操作,以获得编码矩阵所有列的阈值。确定阈值步骤如下,其中eps为可定义的最小正数。
(1) 根据哈希函数H(x)得到编码矩阵,即所有图像的哈希值z(a,j)、z(b,j),还有近邻数据f(xa,xb)。
(2) 初始化集合A=∅,错误分类的数目Tn=0。
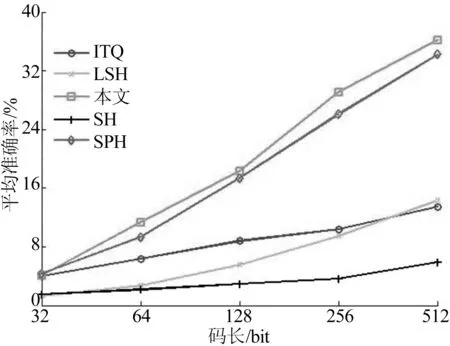
(3) 对于每个三元组z(a,j)、z(b,j)、f(xa,xb),若z(a,j)>z(b,j),则lab=1;如果z(a,j) (4) 根据集合A中的元素的第1项z(:,j)值,升序排列A的2N2个元素。 (5)Sp为相似图像的所有l值之和,Sn为非相似图像的所有l值之和,cb为动态变化的阈值。令Sp=Sn=0,cb=Tn,Tj=min(z(:,j))-eps。 (6) 对于k=1∶2N2,(z,l,f)=A[k],若f=1,则Sp=Sp-1;若f=-1,则Sn=Sn-1;令c=Tn-Sn+Sp,若c 利用上述算法计算哈希编码矩阵每列对应的阈值,对图像的哈希码进行二值化,得到最终的哈希码Y。 1.5编码过程 对于包含n幅图像的训练集矩阵X∈Rn×d,训练集包含数据较多,若全部参与编码,数据量太大,计算机无法实现,故一般随机采样一些数据,组成X*∈Rm×d,利用求出的哈希函数再对X所有数据进行编码。编码过程如下: (1) 固定α、β,根据(11)式求出L*=L+M。 (2) 求L*的特征值和特征向量,取k个最小的特征值对应的特征向量。将k个特征向量按列组成W。 (3) 通过(10)式求出B。 (4) 用W和B对训练集矩阵X和测试集矩阵T进行哈希编码,并根据测试集矩阵T的欧氏距离k近邻数据求出平均准确率,即均值平均精度(mean average precision,MAP)。 (5) 重复步骤(2)~步骤(4),取MAP最高的一组确定α、β。 2.1实验数据及特征表达 本文实验在2个数据集上完成,查询集包含1 000个图像,数据集其他参数见表1所列。 表1 实验数据集 注:括号中数字为维度大小。 GIST-1M数据集[21]已包含图像的GIST特征[22],对CIFAR-10数据集[23]每幅图像计算8个方向和4个尺度的灰度GIST特征,生成320维特征的数据集。 2.2评价指标 对图像的编码过程是线下进行的,即先对图像特征数据进行编码,将图像数据的哈希码保存入库。当有查询图像时,直接对查询图像进行编码,并与图像库中的哈希码进行码间异或运算。通常所说的哈希算法提高效率是指提高查找效率,而图像哈希是通过训练获得更好的哈希函数,其训练过程也是线下操作,不影响图像的检索效率,所以哈希算法的算法复杂度并不作为算法评价的重要指标,而且相关研究[6-7,9,13-15]也未对算法复杂度进行比较分析,因此本文不对哈希算法的算法复杂度进行分析和比较,只将MAP作为评价指标。MAP是信息检索中常用性能指标,现已被广泛应用于各种图像检索算法[6-7,9,13-15]的性能评价。 假设对于每幅图像xi,在图像库中有mi个相似图像。对于n幅图像的MAP计算公式为: 其中,R为第j个相似图像在返回结果中的Rank,Rank为排序后的序号。 采用LSH、ITQ、SH、SPH 4种方法作为对比,这4种方法在GIST-1M和CIFAR-10数据集上计算3次MAP取平均,本文算法由于较复杂且计算量较大,所以只做1次运算。 2.3实验结果及分析 在GIST-1M和CIFAR-10数据集中随机选取1 000个数据作为测试集,余下的数据作为训练集。用欧氏距离计算出测试集每个数据的k近邻(KNN)作为基准,计算检索MAP。其中GIST-1M数据集上k取1 000(1 000-NN),CIFAR-10数据集上k取100(100-NN)。每种方法在GIST-1M数据集上都取码长32~512 bit,在CIFAR-10数据集上取码长16~256 bit,并计算MAP。 实验结果如图1、图2所示,本文方法在2个数据集上的准确率见表2所列。 从图1和图2可以看出,本文算法略优于球哈希(SPH)算法。其中迭代量化(ITQ)算法的检索平均精度随着码长的增加大致呈线性增长,本文算法、球哈希(SPH)和迭代量化(ITQ)在码长较低时检索平均精度相近,而位置敏感哈希(LSH)和谱哈希(SH)效果明显差于其他算法。本文算法效果最好,谱哈希(SH)最差。 图1 GIST-1M数据集的实验结果 图2 CIFAR-10数据集的实验结果 表2 本文方法在2个数据集上的准确率 % 2.4图像检索结果示例 查询图像实例1、实例2如图3所示,对应检索实例如图4、图5所示。检索实例均为在CIFAR数据集上以128 bit检索的结果,每幅图上合成了用相应算法检索出的前100幅相似图像。 图3 查询图例 图4 检索实例1 图5 检索实例2 图4a、图5a为欧式空间用特征间的欧式距离查询的结果;图4b、图5b为本文算法的检索结果;括号内为对应的查准率。可以看出本文算法优于其他算法。 本文引入量化误差最小化的思想改进谱哈希,摆脱了谱哈希对训练数据的限制,并引入Boosting算法确定阈值,提高了图像检索的精度。实验结果表明本文方法优于其他哈希算法。下一步将研究图像哈希算法,进一步提高检索的准确率。 [1]KULIS B,JAIN P,GRAUMAN K.Fast similarity search for learned metrics[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(12):2143-2157. [2]XU H,WANG J,LI Z,et al.Complementary hashing for approximate nearest neighbor search[C]//2011 IEEE International Conference on Computer Vision (ICCV).[S.l.]:IEEE,2011:1631-1638. [3]BEYER K,GOLDSTEIN J,RAMAKRISHNAN R,et al.When is “nearest neighbor” meaningful?[M]//Database Theory: ICDT’99.Berlin:Springer,1999:217-235. [4]TORRALBA A,FERGUS R,WEISS Y.Small codes and large image databases for recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2008:1-8. [5]NOROUZI M,PUNJANI A,FLEET D J.Fast exact search in hamming space with multi-index hashing[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(6):1107-1119. [6]ANDONI A,INDYK P.Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions[C]//47th Annual IEEE Symposium on Foundations of Computer Science.[S.l.]:IEEE,2006:459-468. [7]KULIS B,GRAUMAN K.Kernelized locality-sensitive hashing[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(6):1092-1104. [8]PANIGRAHY R.Entropy based nearest neighbor search in high dimensions[C]//Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm.[S.l.]:Society for Industrial and Applied Mathematics,2006:1186-1195. [9]WEISS Y,TORRALBA A,FERGUS R.Spectral hashing[M]//Advances in Neural Information Processing Systems.[S.l.:s.n.],2009:1753-1760. [10]XIE B,WANG M,TAO D.Toward the optimization of normalized graph Laplacian[J].IEEE Transactions on Neural Networks,2011,22(4):660-666. [11]蒋云志,王年,汪斌,等.基于图的Laplace矩阵和非负矩阵的图像分类[J].合肥工业大学学报(自然科学版),2011,34(9):1330-1334. [12]LI P,WANG M,CHENG J,et al.Spectral hashing with semantically consistent graph for image indexing[J].IEEE Transactions on Multimedia,2013,15(1):141-152. [13]GONG Y,LAZEBNIK S.Iterative quantization: a procrustean approach to learning binary codes[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2011:817-824. [14]NOROUZI M,FLEET D J.Cartesian k-means[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2013:3017-3024. [15]HEO J P,LEE Y,HE J,et al.Spherical hashing[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2012:2957-2964. [16]LIU W,WANG J,JI R,et al.Supervised hashing with kernels[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2012:2074-2081. [17]WANG J,KUMAR S,CHANG S F.Semi-supervised hashing for large-scale search[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(12):2393-2406. [18]CHENG J,LENG C,LI P,et al.Semi-supervised multi-graph hashing for scalable similarity search[J].Computer Vision & Image Understanding,2014,124:12-21. [19]NADLER B,LAFON S,COIFMAN R R,et al.Diffusion maps,spectral clustering and reaction coordinates of dynamical systems[J].Applied and Computational Harmonic Analysis,2006,21(1):113-127. [20]SHAKHNAROVICH G,VIOLA P,DARRELL T.Fast pose estimation with parameter-sensitive hashing[C]//Proceedings of the Ninth IEEE International Conference on Computer Vision (ICCV),Vol 2.Washington D C,USA:IEEE Computer Society,2003:750-757. [21]JEGOU H,DOUZE M,SCHMID C.Product quantization for nearest neighbor search[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(1):117-128. [22]OLIVA A,TORRALBA A.Modeling the shape of the scene: a holistic representation of the spatial envelope[J].International Journal of Computer Vision,2001,42(3):145-175. [23]KRIZHEVSKY A.Learning multiple layers of features from tiny images[R].Toronto:University of Toronto,2009. (责任编辑张淑艳) A large-scale image retrieval method based on improved spectral hashing XIA Lichao,JIANG Jianguo,QI Meibin (School of Computer and Information, Hefei University of Technology, Hefei 230009, China) In this paper, a large-scale image retrieval method based on improved spectral hashing is proposed by introducing the quantization error minimization to improve the image retrieval accuracy. The algorithm gets rid of the assumption that data is uniformly distributed required by the spectral hashing,and can keep the data similarity in the original space.Boosting algorithm is used to determine the threshold so that the algorithm can be more adaptive and more widely used. The algorithm is evaluated on the public datasets, and the experimental results show that the proposed method is better than spectral hashing(SH), locality-sensitive hashing(LSH) and iterative quantization hashing algorithm. hashing; empirical error; Laplacian matrix; Boosting algorithm 2015-04-21; 2015-05-05 国家自然科学基金资助项目(61371155;61174170) 夏立超(1990-),男,安徽庐江人,合肥工业大学硕士生; 蒋建国(1955-),男,安徽宁国人,合肥工业大学教授,博士生导师; 10.3969/j.issn.1003-5060.2016.08.009 TN919.81 A 1003-5060(2016)08-1049-06 齐美彬(1969-),男,安徽东至人,博士,合肥工业大学教授,硕士生导师.2 实验结果及分析







3 结 论
