一种CPU和FPGA的快速交换数据方法
2016-09-15陈庆旭朱明浩余华武
陈庆旭,朱明浩,余华武
(1.南京国电南自自动化有限公司,南京 211153;2.南京依维柯汽车有限公司)
一种CPU和FPGA的快速交换数据方法
陈庆旭1,朱明浩2,余华武1
(1.南京国电南自自动化有限公司,南京 211153;2.南京依维柯汽车有限公司)
为了提高CPU读写FPGA的速度,提出了一种基于Burst方式的CPU和FPGA快速交换数据的方法。CPU在完成第一次读写之后,FPGA会记录该地址,并使双口RAM的地址自动递增,不需要CPU再给出地址,这样CPU可以操作多个连续地址中双口RAM的数据。经过测试,该方法可以大大提高CPU和FPGA进行数据交换的速度。
CPU;FPGA;Burst;快速数据交换
引 言
随着可编程逻辑控制器(Field Programmable Gate Array,FPGA)的应用日渐广泛,很多系统采用了中央处理器(Central Processing Unit,CPU)+FPGA的架构方式。由于FPGA可以并行运算,所以大量的运算工作可由FPGA完成,CPU从FPGA中直接读取计算结果,这种方式可以减少CPU的运算时间,降低了对CPU的要求。
目前,FPGA一般通过双口RAM和CPU进行交互,通过双口随机存取存储器(Random Access Memory,RAM)的缓冲解决FPGA和CPU的速度和并行性等问题。在CPU和FPGA之间有大量的数据需要进行交互的场合,这种方式CPU读写数据过程需要占用大量的时间,如何提高CPU读写FPGA的效率已经成为很多应用中的一个瓶颈问题。在数据量较大的电力系统滤波、图像处理等应用场合,CPU读取数据的时间是无法忽略的,甚至会造成系统的响应时间无法满足要求。
尽管目前可以采用PCI-E、SRIO等方式实现CPU和FPGA之间的快速数据交换,但是这些方式对CPU和FPGA具有较高的要求,在某些成本比较敏感的场合是无法使用的。
本文提出了一种不需要增加额外成本,采用Burst方式对FPGA进行读写的方法。在CPU和FPGA有大量数据进行交互的场合,采用这种方式大大降低了CPU读写FPGA所需要的时间,提高了CPU读写FPGA的效率。
1 Burst模式的基本原理
目前很多CPU都支持Burst读写模式,通过该模式可以快速连续地完成多次读写。目前该模式一般仅用在了DRAM的读写操作中。图1是DRAM芯片的读时序。

图1 DRAM的Burst时序
当DRAM芯片收到读命令后,需要等待一段时间后才可以输出数据,该值称为CAS Latency。CPU给出读命令后,等待CAS Latency时间后,DRAM就可以连续输出后续地址的数据传送给CPU,数据的数量可以由Burst Length进行设置。
在DRAM内部维护了一个地址寄存器,每当输出一个数据后,内部地址寄存器自动加1,读取下一个地址中的数据,由于每次读取数据都经过了CAS Latency的延时,在第一个输出后,在下一个周期的时候,下一个地址的数据进行输出,这样在外部CPU看来,等待CAS Latency时间后,每个时钟周期都可以读到DRAM的数据。采用这种方式后,可以大大提高CPU和DRAM交换数据的效率。
2 Burst模式CPU和FPGA交换数据方法
参考DRAM的读写过程,把Burst模式应用到CPU和FPGA之间进行数据交换。FPGA内部的双口RAM地址不再由CPU给出的地址直接控制,而是使用FPGA内部维护的地址寄存器进行设置。

图2 CPU和FPGA的连接
另外,为了实现以上工作方式,还需要CPU和FPGA的工作时钟是同步的,只有这样,CPU和FPGA才可以按照同样的步调进行工作,为了实现这种功能,需要CPU和FPGA使用同一个外部时钟。CPU和FPGA的连接如图2所示。
另外,CPU需要能够支持Burst功能,在Freescale的MPC82XX系列CPU中,每个片选输出都可以灵活地配置Burst的长度、等待周期等,其他的CPU、DSP也有类似的功能。
当CPU开始对FPGA进行读写操作的时候,FPGA会把CPU给出的地址存储到内部地址寄存器,同时双口RAM开始输出该地址的数据。在下一个时钟周期到来时,FPGA会把内部地址寄存器的值加1,内部双口RAM开始输出下一个地址中的数据,依此类推,CPU便可以连续地从FPGA内部读取到双口RAM中的数据。图3给出Burst长度等于8时,CPU读取FPGA内部双口RAM的时序图。

图3 FPGA的Burst时序
CPU给出/CS和/RD信号的同时,也给出了双口RAM读地址,在FPGA内部锁存该地址并把其送到双口RAM的地址端,在之后的每个时钟周期内,FPGA会自动把双口RAM的输入地址加1,输出下一个地址双口RAM中的数据。在图3中,假定FPGA双口RAM的输出延时是2个时钟周期,那么CPU将会在/RD信号2个周期后读到地址Addr0中的数据Dout0,第3个周期读到地址Addr0+1中的数据Dout1,依此类推,在此之后的每个时钟周期,CPU都可以读到FPGA中的一个数据。
采用Burst模式要求数据线的各位输出延时必须基本一致,只有这样才可以保证各位数据同时到达CPU。表1是FPGA编译报告中所给出的数据输出延时的报告。
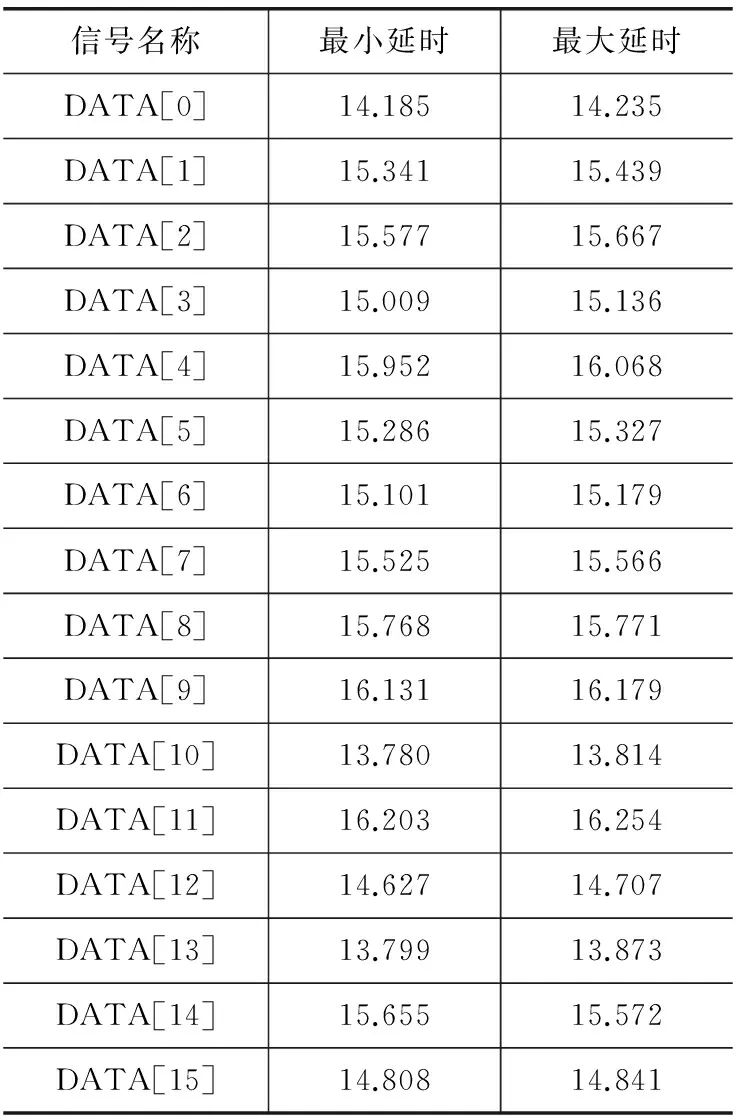
表1 FPGA的数据输出延时(单位:ns)
可以看到,16位数据线的输出延时均为10~20 ns。以100 MHz外频的MPC8247为例,由于CPU的每个时钟周期是10 ns,所以数据输出延时取为2个时钟周期,此时建立时间最短的是DATA[11]信号,等于3.746 ns;保持时间最短的是DATA[13]信号,等于3.799 ns。查阅MPC8247的手册,CPU要求的建立时间不小于3.5 ns,保持时间不小于0.5 ns,时序上是可以满足要求的。当不同数据线之间的延时差异比较大时,可以通过时序约束来保证不同数据线之间延时的一致性。
结 语
对于外频是100 MHz的CPU,每读一次至少需要4个时钟周期,那么读8次共需要32个时钟周期,而采用上面的方式后,在10个时钟周期内就可以读到8个数据,读写速度至少提高了3.2倍。表2是MPC8247在关闭中断的情况下,实际测试得到的1 s内CPU读写FPGA的次数和吞吐率(数据位宽按照16位计算)。

表2 是否采用Burst方式的性能对比
可以看到,采用Burst方式后,CPU读数据的速度大约提高了3.7倍左右,与理论上基本相符。该方案在产品中经过长期应用,可靠性良好。
[1] 夏宇闻.Verilog数字系统设计教程[M].北京:北京航空航天大学出版社,2009.
[2] 阎石.数字电子技术基础[M].4版.北京:高等教育出版社,2004.
[3] 罗苑棠.CPLD/FPGA常用模块与综合系统设计实例精讲[M].北京:电子工业出版社,2007.
[4] Micron Inc.MT48LC4M32 User’s guide,2001.
[5] Freescale Inc.MPC8272 PowerQUICC II Family Reference Manual,2005.
陈庆旭(工程师)、余华武(高级工程师),主要研究方向为继电保护平台;朱明浩(助理工程师),主要研究方向为自动化控制。
Method of Exchange Data Quickly Between CPU and FPGA
Chen Qingxu1,Zhu Minghao2,Yu Huawu1
(1.Nanjing SAC Automation Co.,Ltd.,Nanjing 211153,China;2.Nanjing IVECO Co.,Ltd.)
To improve the reading and writing speed of the CPU for FPGA,a method of exchange data quickly between CPU and FPGA based on the Burst mode is proposed.There is a base address register in FPGA.After the CPU finished the first reading command,FPGA can record the address and increase the dual-port RAM address automatically without the address provided by CPU.So the CPU can operate multiple data of the consecutive address.The test results show that the method can improve the data exchanging speed between CPU and FPGA.
CPU;FPGA;Burst;exchange data quickly
TP368.1
A
(责任编辑:薛士然2016-02-29)
