基于聚集约束的不确定性数据Top—k查询
2016-08-19占仟豪刘斌
占仟豪++刘斌

摘要:在对不确定性数据进行Top-k查询时,一般会附加一些我们已经知道的聚集约束条件,该文主要阐述了在该条件下的不确定性数据的Top-k查询问题。针对可能世界实例空间指数型增长的特点,该文借鉴了文献中对可能世界实例采样的优化思想,通过定义U-Topk和U-kRanks两种查询类型,提出了具体的查询新算法。实验结果表明,这种新的算法的查询效率很高,而且可以处理大量的具有不明确性的数据集。
关键词:不确定性数据;Top-k查询;聚集约束;数据查询
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)20-0014-03
1 引言
现阶段,随着技术的发展,在数据的采集方面和对数据的处理方面,人们的水平不断加强。但是目前在一些领域,比如经济、军事和物流等一些相关领域,会出现很多不确定性数据,这些不确定性数据对这些领域的发展有着关键性的作用[1]。近年来,针对不确定性数据Top-k查询的研究也越来越多。运用采样的近似方法,极大地减少了可能世界实例的数模,从而实现查询的优化。然而对不确定性数据的Top-k查询主要针对的都是存在级的不确定性数据,没有专门针对基于聚集约束条件的Top-k查询的研究。本文研究的是如何基于聚集约束条件更加高效的处理属性级不确定数据的Top-k查询问题。
2 对不确定性数据Top-k查询的一些基本说明
2.1 可能世界模型
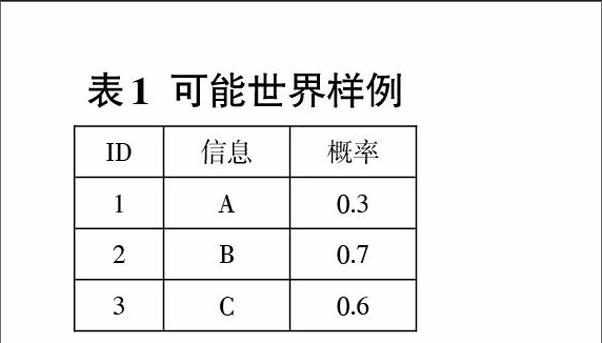
这个模型中,每个元组的组合都可以成为一个可能世界的具体例子,它的概率值可以通过该元组的概率来得出结果。在表1中,我们可以看到有3个元组,概率表示该元组的概率,但是元组之间它们的关系之间有两种,依赖或者是独立的。一我们设定元组是独立的关系的时候,可以得出23=8个可能世界实例。这些实例的概率是由实例内元组的概率相乘然后再与实例外元组的不发生的概率相乘而得到。就像,可能世界实例{1,2}的发生概率为。二当设定元组是依赖关系的时候,元组1和元组3不能同时发生,那就会有6个实例。在这种情况下,可能世界实例{1,2}的发生概率为。
但是,在很多情况下,不确定性又可以分为两种,一是存在级,二是属性级。前者主要是说明元组是否存在,而后者没有论述整个元组的不确定性,它是对某个特定对象来说明这个对象的不确定性,它主要是以概率密度函数或者是统计参数去说明的。
本文主要阐述的是对元组存在相互独立的关系时的属性级的不确定性数据方面的问题。
2.2 具体的应用实例
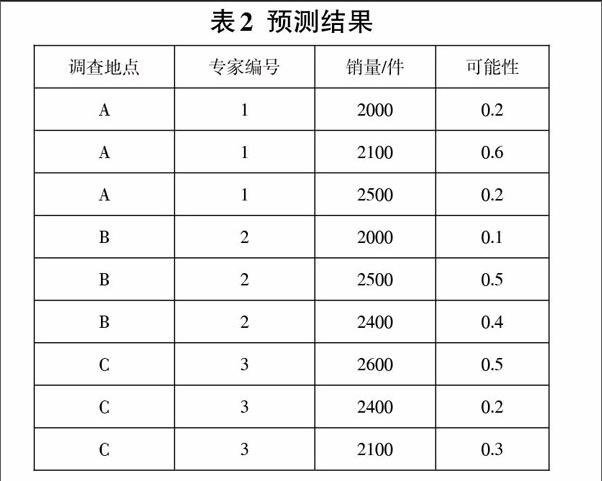
比如,一个企业计划向市场退出一个新的产品,这个企业邀请这方面的专业人士对某市的三个地区进行市场调查,A、B、C,为了是确定这个产品在三个地区的大概要推出的数量,并把结果记录下来。表2是预测的结果:
在上述表中,我们就可以用可能世界模型来进行分析。A、B、C,三个组存在着相互独立的关系,每个组都有3个可能存在的数值,然后得出总结果:可能世界实例。然后结合公司以前的销售经验,可以得出该市下个月的总的销量在[6000,6400]之间,但是在实际情况下,会考虑一些情况。第一种情况:如果我们预测范围正确的话,那A、B、C,三个地区哪个是最多的?可以达到多少?第二种情况:还是在我们对总销量预测范围正确的前提下,那这个总销量的具体数值应该是多少?第一种,第二种这两种情况的查询,都属于对不确定性数据的Top-k查询,但是它们的排序标准不同,一是按销量,二是按概率。回答上述的两个查询,方法一:先列举所有可能世界实例,然后对整个可能世界实例空间直接进行查询。方法二:如果先考虑一些制约条件的话,那就会有一个结果,针对27个可能世界实例中,只有下面3个是满足条件的例子:w1=<2000,2000,2100>,w2=<2000,2000,2400>,w3=<2100,2000,2100>,且概率P(w1)=0.006,P(w2)=0.004,P(w3)=0.018。对这三个实例进行查询,可以得出结论为:第一种情况下为C区,销量为2400,第二种情况下最有可能销量为6200件(因为P(w3)最大)。
根据上面所列举的例子,我们看到很容易得出一些结论,但是上述数据的规模是很小的,但是在一些实际情况下,数据都是很庞大的,如果存在一个不确定数据集有10000个元组,然后每个组中有3个可能的值,那么实例为。针对这种很大的数据集,第一种方法是行不通的,方法二通过简化查询的可能世界实例空间,虽然是一种非精确的方法,但是可以满足查询的要求。为了最大的提高查询效率,如何最快最准的找出满足约束条件的可能世界实例是问题的关键。
3 对问题形式的一些说明和所建立的模型
3.1 可能世界模型说明
3.2 对聚集条件的描述说明
现在是对4个SQL语言的操作:SUM,MAX,MIN和AVG。其中形式描述如下:,在这个描述中R是与该条件有关的但不确定的数据集,T是该类型,a和b各是聚集条件的上限和下限。
3.3 查询语义的定义
这两个查询U-kRank和 U-Topk,它们是大不相同的,其中U-Topk的结果是以向量k的形式所表现的,而这个k会在可能世界的最前列。在可能世界对元组的排序中,是根据分值不同的大小来排列的,这说明每个元组都是不相同的。而在U-kRank中,某一个元组可以重复出现,这是U-kRank所允许的。
4 问题解决方法
本文借鉴文献2中使用的马尔科夫链蒙特卡洛(MCMC)采样方法,先利用已知的聚集约束条件对整个可能世界实例空间进行采样,得到一个规模较小的满足条件的可能世界实例数据集,然后在对采样后的数据集进行Top-k查询。
4.1 获取满足约束的数据集
实际上,从一个已知的合格点X出发,通过改变X中某一个或几个元组的属性值,得到一个新的可能世界实例仍然极有可能满足所有约束条件。运用马尔科夫链蒙特卡洛(MCMC)方法,经过有限步的采样,就可以得到满足所有约束条件的可能世界实例数据集。
在可能世界空间中,满足约束的可能世界实例都会相邻而存在,形成一块块的合格区域。即某一个点满足约束,改变该点某几个元组的值通常也会满足约束条件。例如,可能世界实例X满足所有的约束条件,不妨称X为一个合格点,如果可能世界实例Y与X非常的相似,那么Y也极有可能是一个合格点。MCMC方法便是利用了这一特性来对可能世界空间进行采样,因此该方法可以分为两个阶段:
第一阶段:寻找一个满足约束的初始合格点
1)随机生成一个可能世界实例,逐一将各个约束条件去判断该点是否满足,如果都满足,则该点就是初始合格点;如果该点所有元组值的和小于该约束的下限,则对该点的元组需要调大投票,如果所有元组值的和大于该约束的上限,则对元组需要调小投票。
2)根据元组的得票,调整各候选值的随机选中概率。即如果某个元组的需要调大得票高,则增大该元组候选值中比初始值大的候选值的概率;需要调小的得票高,则增大比初始值小的候选值的概率。
3)对调整概率后的各个元组,重新随机选择候选值得到一个新的点,如果该点满足所有约束,则返回该点为初始合格点;如果不满足转4。
4)按1中的规则进行投票,对得票最高的元组进行候选值调整,得到新的点。判断该点是否满足所有约束条件,满足即返回该点为初始合格点。如果不满足转5。
5)重复步骤4一定次数,如果仍得不到合格点,则返回错误信息。
第二阶段:从初始合格点出发进行采样
1)从初始点出发,随机选取s(称为步长)个元组,改变选中的元组的值,随机选择与原来值大小相邻的值中的一个,得到一个新的状态点。
2)判断新的点是否满足所有约束条件,满足则采集该点为马尔科夫链的下一个状态点;不满足则依据Metropolis-Hastings采样规则以一定的概率接受该点为下一个状态点。
3)重复步骤1和2,直到采集到足够的合格样本点。
4.2 查询一些采集的数据集
这些采集的数据集都要进行两种查询,分别是U-Topk和U-kRanks,从下面可以看出各自的算法,
U-Topk算法
5 它的实验应用
MATLAB的运用可以对上面提到的算法进行去实现,Windows XP系统是它的运行系统,Intel Core 2 CPU(6400 2.13GHz),它的内存是1GB.
5.1 它的实验中的数据
它的实验中的数据集采用的是一种模拟数据,这种模拟数据是由计算机生成的,这些数据集中的每个元组都包括4个在[0,100]之间生成的一些候选值,而这些值具有随机性。假设元组的个数为N,这个N可以设为1K、10K、20K,组成三个大小不一样的数据集。然后还有4个聚集约束条件,可以写成一种矩阵的形式来表示:。这4个条件约束的元组都是不同的,第一个是第0到0.4N个元组,第二个是第0.2N到0.6N个元组,第三个是第0.4N到0.8N元组,第四个是第0.6N到第N个。
5.2它的实验结果
在实验进行的过程中,先针对不同大小的三个数据集,分别进行U-Topk和U-kRanks查询,实验中参数k=3,采样链mclength=1000,得到实验结果如下表所示:
从表3和表4我们可以发现,两种查询消耗的时间都在几秒到几十秒之间,相对于直接对整个可能世界空间查询效率有很大的提高。况且当N=10K时,可能世界实例总数将达到个,利用穷举的方法根本不可能得到查询结果。
6 结论
综上所述,本文主要是讨论了对在聚集约束条件下对一些不确定性的数据Top-k的查询方面的问题,然后分析了一些目前的查询方法,借鉴文献2中的采样思想,提出了针对不确定性数据的U-Topk和U-kRanks查询的新的计算方法。而且通过实验可以看出,这两个新的算法可以对一些大规模的不确定的数据进行处理,并且查询效率相对于传统方法有很大的提高。
参考文献:
[1] 周傲英,金澈清,王国仁,李建中. 不确定性数据管理技术研究综述[J]. 计算机学报,2009,31(1) .
[2] Mohan Yang, Haixun Wang, Haiquan Chen, Jeff Ku. Querying Uncertain Data with Aggregate Constraints [C]. SIGMOD. Athens,Greece: 2011.
[3] Todd J.Green, Val Tannen. Models for incomplete and probabilistic information [C]. IEEE Date Engineering Bulletin. 2006.
[4] Nilesh Dalvi, Dan Sucin. Efficient Query Evaluation on Probabilistic Databases[J]. VLDBJ,2007,16(4) .
