基于RNN汉语语言模型自适应算法研究*
2016-07-12杨俊安
王 龙,杨俊安,刘 辉,陈 雷,林 伟
(1.电子工程学院,合肥 230037;2.安徽省电子制约技术重点实验室,合肥 230037;3.安徽科大讯飞公司,合肥 230037)
基于RNN汉语语言模型自适应算法研究*
王龙1,2,杨俊安1,2,刘辉1,2,陈雷1,2,林伟3
(1.电子工程学院,合肥230037;2.安徽省电子制约技术重点实验室,合肥230037;3.安徽科大讯飞公司,合肥230037)
摘要:深度学习在自然语言处理中的应用越来越广泛。相比于传统的n-gram统计语言模型,循环神经网络(Recurrent Neural Network,RNN)建模技术在语言模型建模方面表现出了极大的优越性,逐渐在语音识别、机器翻译等领域中得到应用。然而,目前RNN语言模型的训练大多是离线的,对于不同的语音识别任务,训练语料与识别任务之间存在着语言差异,使语音识别系统的识别率受到影响。在采用RNN建模技术训练汉语语言模型的同时,提出一种在线RNN模型自适应(self-adaption)算法,将语音信号初步识别结果作为语料继续训练模型,使自适应后的RNN模型与识别任务之间获得最大程度的匹配。实验结果表明:自适应模型有效地减少了语言模型与识别任务之间的语言差异,对汉语词混淆网络进行重打分后,系统识别率得到进一步提升,并在实际汉语语音识别系统中得到了验证。
关键词:语音识别,循环神经网络,语言模型,在线自适应
0 引言
语音识别(Speech Recognition)是指机器通过识别和理解把人类的语音信号转变为相应文本或命令的技术。在语音识别中,连续的语音包含了丰富的语法和句法信息,在识别器中加入语言模型的根本目的就是对这些语法和句法信息进行归类以及建模,找出最佳的词序列来减少语音特征矢量序列与词序列的匹配搜索范围。此时,语言模型以先验概率的形式发挥着重要的作用,将各种高层次的非声学知识结合到语音识别系统中。
语音识别系统的性能很大程度上依赖于语言模型与识别任务的匹配程度,对环境的依赖性强,当语言模型同识别任务主题相匹配时,常可获得好的识别结果,反之则导致识别性能恶化[1]。在实际应用中,识别任务往往混杂着多个并且是事先无法预知的主题,特别是对于电话语音识别而言,这一特点尤为明显。电话语音大都为口语,在内容上往往会涉及多个主题,不同的说话人说话风格也不相同。如果有充分的口语语料,那么训练出来的语言模型与识别任务的匹配问题就可能部分得到解决,然而大量的口语语料却不容易收集。因此,如何快速、准确地实现语言模型自适应并与识别任务主题相匹配便成为一个关键问题。
传统的语言模型自适应技术[2]是将一个通用的、训练充分的语言模型和一个特定领域的、训练不充分的模型通过某种方式组合成一个新的模型。因此,这种自适应技术通常也叫话题自适应或者领域自适应技术。组合的方法一般有两种:插值法和最大熵法。插值方法比较常用,它最大的优点是易于实现,计算效率高,其缺点是难以保证模型的完整性,并且很难达到最佳的插值效果;最大熵法的优点是能够达到更优化的插值效果,其缺点是计算量大、计算效率低。这些方法有一个共同点,即都是在该领域已知的情况下,预先搜集好该领域的适应语料,然后以离线的方式训练[3],如果领域发生了变化,则需重新进行模型训练确定自适应系数。但有时预先获得的语料非常少,只有在应用时才能确定使用领域,特别是对于电话语音识别而言,事先无法预知说话人的主题,传统的语言模型自适应技术将不再适合。
近年来,深度学习逐渐在自然语言理解中得到应用。相比于传统的n-gram统计语言模型,循环神经网络建模技术[4]在语言模型建模方面表现出了极大的优越性,逐渐在语音识别、机器翻译等领域中得到应用。本文首先将RNN建模技术应用到汉语语言模型的建模,在此基础上提出一种基于RNN汉语语言模型在线自适应算法,对语音信号初步识别结果进行模型自适应,即将语音的一遍识别结果作为训练语料经过分词等处理后在原RNN模型的基础上继续训练。通过学习更新模型的权值矩阵,使模型自适应后能够更好地反映出识别任务的语言分布情况,然后再次对识别任务重新进行解码。
1 语音识别系统框架
1.1识别系统概述
一个完整的语音识别系统基本原理框图如图1所示,语言模型是语音识别系统重要组成部分,较高层次的语言知识的利用可以在声学识别的基础上减少模式匹配的模糊性,从而提高系统识别的精确度。

图1 汉语语音识别系统结构
对语音信号进行预处理及特征提取后,可以得到这个语音信号所包含的声学特征矢量,记为O。自然语言可以被看作一个随机序列,文本中的每个句子或每个词都是一个具有一定分布的随机变量。假设词(汉语中包含单字)是一个句子最小的结构单位,一个合理的有意义语句S由词序列w=w1,w2,…,wN组成。从贝叶斯(Bayes)原理出发,语音识别的过程就是根据式(1)[5],找出当前声学特征下条件概率最大的词序列作为识别结果。

其中,信号波形的先验概率p(o)与词序列w选择无关,可以不计算;p(o|w)代表在给定某个词序列的基础上,输出特征序列的可能性,在语音识别中用声学模型对其建模;而p(w)表示了词序列w出现的可能性,在语音识别中用语言模型进行建模。目前应用广泛的n-gram语言模型认为每一个预测变量出现的可能性只与长度为n-1的上下文有关,即:

通常n值取2或3,只考虑到了当前词的局部上下文的语言信息,其训练往往需要大量真实的训练语料。相比于传统的基于统计规则的n-gram语言模型,RNN语言模型在预测一个词时考虑到了较多的历史信息,因此,能够对语句中长距离的信息进行较好地描述。
1.2汉语语料的处理
在对汉语文本语料进行训练之前,必须要对语料进行一系列处理,汉语训练语料处理流程图如图2所示。在得到一份文本语料后首先要进行清洗,将粗语料中的字母、标点符号等噪声信息删除,去除冗余信息;语料中往往会存在大量的数字,正规化过程主要完成语数字正规化,将语料中的阿拉伯数字转换成相应的汉字;经过前两步后,语料中只存在着汉字信息,分词是根据分词模型将语句中词与词之间用空格分开,将句子划分成一个个词(或字)单元;词典过滤用来删除英文边界符,删除语料中的非词典词句子。对语料进行一系列处理后就可以得到能够用来训练的较为干净的语料,然后进行模型训练。

图2 汉语语料的处理流程
2 循环神经网络语言模型
一个典型的循环神经网络如图3所示,由3个网络层构成,分别是输入层、隐含层、输出层。本文中使用的是标准循环神经网络,也称为Elman网络[6],易于实现和训练。经过此RNN架构训练后,当前词wi的概率表示为:

其中hi代表语句中当前词的所有上下文信息,以向量形式保存在网络存储层,作上为下一个样本训练时网络输入的一部分。

图3 循环神经网络基本框架
假设在t时刻网络输入词样本为w(t),即当前词的词向量,维数大小为语料中词样本数决定;隐含层的状态h(t)由输入当前词向量w(t)和上一时刻隐含层的状态也即历史信息h(t-1)共同决定,通过隐含层到输入层的连接,将t-1时刻的隐含层状态作为t时刻输入的一部分;输出层y(t)表示当前历史下后接词的概率分布信息,输出层节点数与输入层节点数相同也是。各个层之间计算关系用下列式子进行表示[7]:
隐含层的输入:x(t)=w(t)+h(t-1)
其中,softmax函数保证了当前词下后接词的概率分布是合理的,即对于任意一个词m的ym(t)>0,且∑kyk(t)=1。在模型参数的初始化设置上,隐含层初始状态h(0)一般设为零,或随机初始化为很小的值。输入词向量w(t)用one-hot-vector进行表示。隐含层节点数通常取100到1 000,根据具体训练数据的大小进行调节。U、W、V为各层之间权值矩阵,随机初始化为较小的值。在模型训练的过程中,通过标准的反向传播算法(back propagation,BP)结合随机梯度下降法(stochastic gradient descend,SGD)学习更新[8]:

其中e(t)表示每处理一个样本时的输出端的误差向量,desired(t)表示特定上下文中期望输出的概率值,y(t)则是网络的实际输出。θ={u、w、v},▽SGD表示相应的梯度下降值,网络的初始学习速率α为0.1,经过不断地迭代学习直到模型收敛。
3 RNN模型自适应
语言模型对于提高语音识别系统的性能起着重要作用。语言模型自适应就是把自适应模型中蕴含的、原模型中缺少的信息,补偿到原模型中得到更为精确的模型,从而使自适应后的语言模型与应用环境获得最大程度的匹配。在少量电话标注语料的情况下,通过采用语言模型自适应技术减小模型与识别任务之间的语言差异是一种较好的选择,以适应不同应用环境各自的特征,为语音识别的解码提供更为精确的语言模型。

图4 基于RNN语言模型在线自适应语音识别系统结构
基于RNN语言模型在线自适应语音识别系统结构如图4所示,在原有系统的末端增加了语言模型自适应处理模块。将RNN模型用于识别系统中时,通过RNN语言模型对每一条语音解码后的词混淆网络即n-best列表进行重新打分能够得到RNN模型下系统的一遍识别结果(one-best)。尽管系统一遍识别结果不一定是完全正确的,但却在一定程度上能够反映出识别任务的主题以及语言分布情况。因此,可以将一遍识别结果作为模型自适应语料,经过分词等一系列处理后,在原RNN语言模型的基础上继续训练,进一步更新RNN模型参数。此时,模型就能够学习到与识别任务相关的新的知识,不断调整语言模型中各种语言现象出现的概率,更好地预测识别任务的语言真实分布情况,实现模型自适应。将自适应后的RNN模型再次对语音n-best列表重打分,得到每一个列表新的语言模型得分。然后根据式(7)再结合声学模型得分、惩罚分等信息计算出每一个列表总的得分情况。

其中,n是句子中词的个数,wp是词的惩罚分,asci为词wi声学模型得分,lms为模型规模,prnn(wi|hi)代表每个词的RNN语言模型得分。计算出每一列表的得分结果后,从中选出得分最高的一个作n-best列表的最优解。将新得到的one-best列表与识别任务标注数据进行比对计算出系统识别率。
4 实验与分析
4.1数据集及实验设置
在实验中选用词错误率(Word Error Rate,WER)作为评测标准,系统词错误率越低,则认为语言模型性能越好。训练数据来源于科大讯飞语音公司提供的实际汉语电话信道语音标注数据,共16.5 M,包含550 k个句子文本,包含4 342 k个词,验证集为282 kb,测试集为对电话语音解码结果343 300句(100-best)列表,大小为87 k。
采用RNN训练模型时,隐含层节点数(Hidden)和语料分类数(Class)分别设为100H-500C、200H-100C、500H-400C、500H-500C、600H-500C并完成各个模型的训练。然后用训练出的RNN模型对343 300句列表的语言模型得分进行重打分,从中选出3 433句得分最高的作为一遍识别结果,利用上述的RNN自适应方法对各个RNN模型进行再训练。并测试模型自适应后的系统识别率。本试验中n-gram语言模型训练采用3-gram (Tri-gram)模型结合性能较好的Kneser-Ney back-off平滑算法进行训练,由SRILM工具箱构建。
4.2实验结果与分析
表1中以3-gram模型为基线模型,分别给出了RNN语言模型以及RNN自适应后的实验结果,同时给出了RNN自适应后与3-gram模型插值融合后的实验结果。
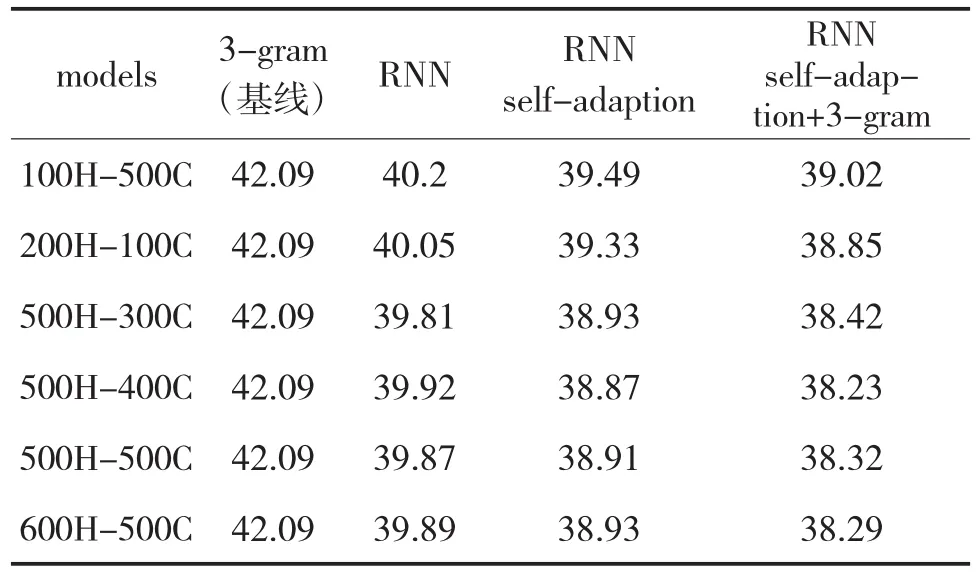
表1 RNN模型自适应后系统词错误率(WER)比较
实验结果如表1中所示,相比于n-gram语言模型而言,采用RNN建模技术训练汉语语言模型,系统WER得到了有效地降低,说明了RNN建模技术的优越性,并适用于汉语语言模型训练。当对RNN模型自适应训练后系统WER相比于RNN模型系统的WER绝对下降达到1个百分点,而将自适应后的RNN模型与3-gram进行线性插值以后系统的WER绝对下降达到1.5个百分点,说明了文中所提出的自适应算法的有效性。对RNN模型再训练后确实学习到了与识别任务相关的新的知识,使模型与识别任务之间获得了一定程度的匹配。然而,也可以看出由于语料有限,原RNN模型的系统识别率并不高,所以系统的一遍识别结果中存在着一些识别错误,进行RNN自适应后模型也会学习到一些错误的知识,影响系统识别率。尽管如此,由于自适应算法时间开销上并不大,并且在一定程度上能够提高模型的性能,因此,自适应算法在实际应用中仍然不失为一种有效的算法。
5 结论
本文针对RNN生成模型与识别任务存在着差异问题,提出了一种RNN模型自适应算法,该算法不是传统的针对领域训练语言模型再与通用模型进行插值等融合,而是将语音的初步识别结果作为训练语料,进行重新处理后继续训练RNN模型。由于初步识别结果文本不大,因此,能够较快地更新模型权值参数,不断调整语言模型中各种语言现象出现的概率,使自适应后的RNN模型与识别任务之间能够获得最大程度的匹配。实验表明,本文提出的RNN语言模型在线自适应算法能够有效地降低系统识别错误率。另外从实验结果中可以看出,系统的一遍识别结果对自适应模型的性能有较大影响,因此,如何调整RNN训练算法提高系统的一遍识别率是下一步的研究重点。需要说明的是,试验中采用了若干经验参数,如果模型的训练条件变化了,则要对要对这些参数进行相应调整。
参考文献:
[1]纪生,王作英.一种新的基于主题的语言模型自适应方法
[J].中文信息学报,2006,20(4):82-87.
[2]梁奇,郑方,徐明星.基于trigram语体特征分类的语言模型自适应方法[J].中文信息学报,2006,20(4),68-74.
[3]吴根清,郑方,金陵.一种在线递增式语言模型自适应方法[J].中文信息学报,2002,16(1):60-65.
[4]MIKOLOV T,KARAFI'AT M,BURGET L,et al. Recurrent neural network based language model[C]// Proceedings of Interspeech,2010:1045-1048.
[5]张强.大词汇量连续语音识别系统的统计语言模型应用研究[D].成都:西南交通大学,2009.
[6]KOMBRINK S,MIKOLOV T,ARAFI'AT M,et al. Recurrent Neural Network based Language Modeling in Meeting Recognition[C]// Proceedings of Interspeech,2011:2877-2880.
[7]MIKOLOV T,KOMBRINK S,BURGET L,et al .Extensions of recurrent neural network language model[C]// Proceedings of ICASSP,2011:5528-5531.
[8]MIKOLOV T,ARAFI'AT M,BURGET L,et al. Recurrent neural network based language model[C]// Proceedings of Interspeech,2010:1045-1048.
Research on a Self- Adaption Algorithm of Recurrent Neural Network Based Chinese Language Model
WANG Long1,2,YANG Jun-an1,2,LIU Hui1,2,CHEN Lei1,2,LIN Wei3
(1.Electronic Engineering Institute,Hefei 230037,China;2.Key Laboratory of Electronic Restriction,Anhui Province,Hefei 230037,China;3.Anhui USTC IFlytek Corporation,Hefei 230037,China)
Abstract:Deep learning is used more and more widely in natural language processing. Compared with the conventional n -gram statistical language model,recurrent neural network(RNN)modeling technology shows great superiority in the aspect of language model modeling,which is gradually applied in speech recognition,machine translation and other fields. However,most RNN language models are trained off-line at present,for different speech recognition tasks,there exist many language differences between training corpus and recognition tasks that affects the recognition rate of speech recognition system deeply. The authors adopt RNN model technical in training the Chinese language model and put forward a online self-adaption model training algorithm at the same time,with this algorithm,we treat the voice signal preliminary recognition results as the additional training corpus to retrain the model to ensure that the adaptive RNN model can match with different tasks mostly. The experiment results show that the self-adaption model can reduce the differences against recognition tasks effectively and further improve the system recognition rate after rescoring the lattice,it is proved in the actual Chinese speech recognition system at the same time.
Key words:speech recognition,recurrent neural network,language model,online adaptation
中图分类号:TP391
文献标识码:A
文章编号:1002-0640(2016)05-0031-04
收稿日期:2015-03-05修回日期:2015-05-18
*基金项目:国家自然科学基金(60872113);安徽省自然科学基金资助项目(1208085MF94)
作者简介:王龙(1989-),男,安徽阜阳人,硕士研究生。研究方向:声信号分析与识别技术等。
