基于分布式计算的what-if分析并行处理策略*
2016-07-02郑雪梅贵州大学计算机科学与技术学院贵州贵阳550025贵州大学贵州省先进计算与医疗信息服务工程实验室贵州贵阳550025
郑雪梅,陈 梅,李 晖(1.贵州大学计算机科学与技术学院,贵州贵阳550025;2.贵州大学贵州省先进计算与医疗信息服务工程实验室,贵州贵阳550025)
基于分布式计算的what-if分析并行处理策略*
郑雪梅1,2,陈 梅1,2,李 晖1,2
(1.贵州大学计算机科学与技术学院,贵州贵阳550025;
2.贵州大学贵州省先进计算与医疗信息服务工程实验室,贵州贵阳550025)
根据基于OLAP的what-if分析的查询特点,使用分布式并行处理技术解决what-if分析性能较低的问题。以星座模型为基础的what-if分析中,将多维聚集查询分布到不同计算节点进行聚集计算,然后将各个计算节点的聚集计算结果合并输出。该方法根据基于OLAP的what-if分析中其维表远远小于事实表的特性,将事实表中的记录进行水平分片,充分利用各节点计算和I/O处理能力,以解决OLAP查询中计算密集型及I/O消耗过大的难题。在该方法中,随着计算节点数目的增加,其查询时间随之减少,有效地提升了分析效率。
OLAP;what-if分析;分布式并行处理
O 引言
what-if分析是决策者对多种决策方案进行预测或评估时的常用手段,通常以多种形式应用于不同的应用场景,尤其在决策系统中发挥重要作用。简单地说,what-if分析就是以数据仓库中历史数据为基础数据的假设分析,决策者根据决策目标制定一系列假设场景,通过对已有数据的假设分析得到假设场景下的商业数据变化情况。
近年来,随着数据仓库中数据的不断膨胀,数据量从TB级增长到PB级甚至EB级别,决策者在海量的数据中挖掘价值,以便更快更准地捕获商机,在很大程度上还需要借助what-if分析工具的应用。因此,基于OLAP的what-if分析一直受到很多学者的关注,但由于what-if分析自身的复杂性,至今未得到广泛应用。在假设分析时通常需要更改Cube结构或修改Cube数据,这些操作均涉及到Cube重计算,花费时间较长,限制了what-if分析的能力。
随着大规模并行处理关系数据库的发展,如Vertica、微软的SQL Server并行数据仓库以及GreenP1um数据仓库等的使用,使高效的并行查询处理及数据分析成为可能。因此,本文结合基于OLAP的what-if分析的特点,与分布式并行处理技术相结合,可以有效提高查询效率,解决决策者面临分析效率低的问题。
1 相关研究工作
what-if分析的概念早已提出,由于其复杂性未得到广泛应用,但是对其研究一直在进行中。参考文献[1]中提出基于De1ta表的what-if分析,通过预处理方法提高whatif分析效率,更改工作内容均是在内存数据库中实现,而不是在基于磁盘的关系型数据库中实现,其性能未得到明显提升。参考文献[2]在参考文献[1]的基础上,利用并行计算模型MaPReduce实现what-if分析,其性能有一定的提升。随着what-if分析的研究,参考文献[3-4]分别将what-if分析应用于MaPReduce的调优及复杂云数据中心的资源分配。参考文献[5]详细介绍了分布式并行处理整体方案。参考文献[6]提出了内存数据库中利用分布式并行处理技术实现OLAP并行操作的方案。本文中的what-if分析使用分布式并行处理技术,利用并行处理机制提升what-if分析性能。
2 what-if分析
本节主要以OLAP模型中的星座模型为例,详细介绍what-if分析中的基础概念及实现方法,并分析其实现过程中存在的问题及拟解决方法。
2.1 基于OLAP的what-if分析
基于OLAP的what-if分析实质是基于假设场景的OLAP查询。在假设数据生成后,生成新的Cube,Cube通常有星型、星座和雪花等OLAP模型;基于新的Cube可以执行相应的OLAP操作,如Ro11-uP。图1为本文使用Foodmart数据的OLAP模型。

图1 Foodmart的OLAP模型
图1中有2个事实表和6个维表。其中,sa1es_fact (Product_id,time_id,customer_id,Promotion_id,store_id,store_sa1es)、sa1es_fact_virtua1(Product_id,time_id,customer_id,Promotion_id,store_id,store_sa1es,wbversion,sign)为两个事实表。
sa1es_fact用于存储数据库中的历史数据,在what-if分析中称之为基表;sa1es_fact_virtua1是与sa1es_fact结构相似的另一个事实表,叫de1ta表,用于存储假设数据,这类的假设分析是基于de1ta表的what-if分析。由事实表可知,de1ta表是在基表的基础上增加了多个字段,如wbversion和sign,wbversion表示版本号,sign为更新类型,其更新类型主要有插入(I)、更新(U)和删除(D)三类,分别用1、0、-1值来表示。store_sa1es为度量值,其余均为维度值。
2.2 wha t-if分析实现
本节主要介绍基于de1ta表的what-if分析的实现过程。首先,根据假设场景将假设数据存储到de1ta表中;其次,将de1ta表与基表合并生成新的Cube,此步骤称之为假设更新,也叫what-if更新;最后,基于新生成的Cube执行OLAP查询操作。
对于基表与de1ta表的合并,常用的方法是通过等值连接、左连接和全连接等操作来实现。下面是依据2.1节中的OLAP模型通过使用连接操作来实现what-if分析。
在连接算法中,首先排除基表中受de1ta表D和U类更新影响的记录,然后再与de1ta表中U类型和I类型的记录合并。三种算法具体实现如下:
算法1 等值连接算法
tmPtab1e=sa1es_fact 1eft(sf)join sa1es_fact_virtua1(sfv)
for each tuP1e t in sf
outPut(t.Product_id,t.time_id,t.customer_id,t.Promotion_id,t. store_id,t.store_sa1es)->what-if_view_0
for each tuP1e t in tmPtab1e
outPut(t.Product_id,t.time_id,t.customer_id,t.Promotion_id,t. store_id,t.store_sa1es)->what-if_view_1
for each tuP1e t in sfv
if sign =1 or 0 then outPut(t.Product_id,t.time_id,t.customer_id,t. Promotion_id,t.store_id,t.store_sa1es)->what-if_view_2
return what-if_view_0 EXCEPT what-if_view_1 union a11what-if_ view_2
算法2 左连接算法
tmPtab1e=sa1es_fact 1eft(sf)join sa1es_fact_virtua1(sfv)
for each tuP1e t in tmPtab1e
if t.sign is nu11 then outPut(t.Product_id,t.time_id,t.customer_id,t. Promotion_id,t.store_id,t.store_sa1es)->what-if_view;
if t.sign =-1 then skiP t;
for each tuP1e t in sfv
if sign =1 or 0 then outPut(t.Product_id,t.time_id,t.customer_id,t. Promotion_id,t.store_id,t.store_sa1es)->what-if_view_1 return what-if_view union a11what-if_view_1
算法3 全连接算法
tm Ptab1e=sa1es_fact 1eft(sf)join sa1es_fact_virtua1(sfv)
for each tuP1e t in tmPtab1e
if t.Product_id is not nu11and t.sign is nu11 then outPut(t.Product_id,t.time_id,t.customer_id,t.Promotion_id,t.store_id,t.store_sa1es)-> what-if_view
if t.Product_id is not nu11and t.sign =1 or 0 then outPut(t.Product_id (sfv),t.time_id(sfv),t.customer_id(sfv),t.Promotion_id(sfv),t.store_ id(sfv),t.store_sa1es(sfv))->what-if_view
return what-if_view;
通过连接操作执行假设更新后得到新的Cube,在基于Cube的OLAP查询中,其OLAP查询结果通常为grouP by和order by所得的聚集结果值,涉及操作有MAX、MIN、SUM、COUNT等分布式聚集运算等。
综上所述,在what-if分析的实现过程中,关键问题是如何高效地合并基表和de1ta表并执行OLAP操作。下节将介绍使用分布式并行处理来提高what-if分析的整体效率。
3 分布式并行执行
3.1 分布式并行处理
基于Shared-nothing结构的分布式并行数据库具有较好的可扩展性,图2为本文使用的分布式并行数据库集群架构,整个集群由多个数据节点(Segment Host)和控制节点(Master Host)组成。Master Host主要负责与客户端的通信、对SQL进行分析以及生成执行计划并分发到每个Segment上执行,最后将汇总结果反馈给客户端;数据节点负责数据的存储、存取以及执行Master分发的SQL语句,在每个数据节点上可以允许有多个数据库。同时,各个节点之间的信息交互通过节点互联网络来实现。
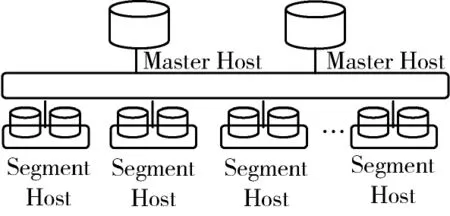
图2 基于Shared-nothing的并行处理数据库
分布式并行处理数据库集群架构中,数据划分方法对其并行处理的性能影响很大,大多采用的是哈希划分法和范围划分法。文本中即采用了Hash划分方式将数据分布到各个节点上。其划分过程为:当数据存入数据库时进行数据划分处理,即根据表中的某一个或几个字段的哈希值分布到每个节点。
在涉及连接操作运算的查询中,利用分布式并行处理数据库对查询操作并行化,可以充分利用系统中所有的处理器和I/O处理能力,从而缩短查询响应时间。利用分布式并行处理数据库的优势,大大减少了what-if分析合并中由于多表连接产生的大量开销。
3.2 wha t-if分析的并行执行
what-if分析的OLAP查询中,涉及大量的聚集操作,针对可分布式执行的聚集函数,可将聚查询分布到不同计算节点进行聚集计算,并将各个节点的聚集计算结果进行合并输出。因此what-if分析的OLAP并行查询可分为两阶段:一是提交查询到多个子查询节点上进行并行执行;二是合并查询结果,然后输出合并后的最终结果。
图3为what-if分析中并行执行OLAP查询的计算过程。在此并行查询处理中,各处理节点均将查询结果返给OLAP中间服务器,并计算出最终结果。
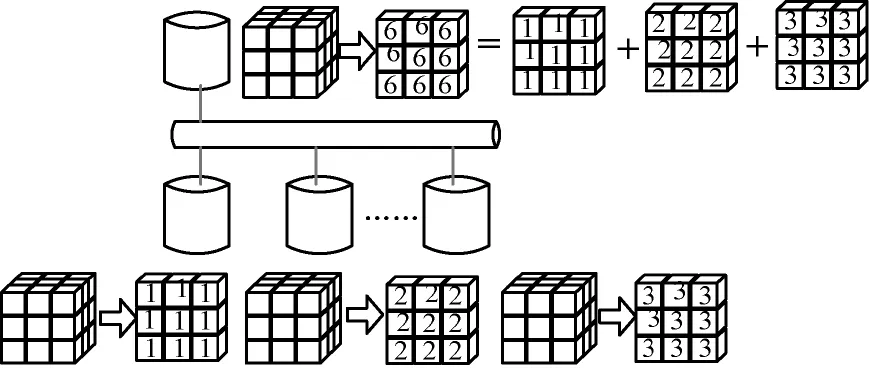
图3 分布式聚集函数计算过程
根据3.1节中数据划分方法,每个属性将被分布在不同的节点上。例如,当有n个节点时,针对属性A,则有A =A1∪A2…∪An,在图3的分布式聚集函数计算过程中,最终的计算结果是1~n个节点的计算结果的总和。在本文中,实现了常用的分布式聚集函数如SUM、COUNT、MAX以及MIN等的分布式聚集运算,其计算公式分别表示如下:
SUM(A)=SUM(SUM(A1),…,SUM(An))
COUNT(A)=COUNT(COUNT(A1),…,COUNT (An))
MAX(A)=MAX(MAX(A1),…,MAX(An))
MIN(A)=MIN(MIN(A1),…,MIN(An))
在分布式并行执行中,可以利用各计算节点的计算能力及I/O处理能力提高what-if分析的OLAP查询效率,但与此同时,若将聚集函数转换为可分布式计算的聚集函数时,额外的通信代价相应地也会增加。因此,在利用各节点处理能力的同时需要考虑其网络开销,换句话说,随着节点在一定范围的增加,查询效率会有相应的提升,但当子节点过多时,随着网络开销的逐渐增加其查询效率将会受到一定的影响。
因此,本文一方面适当增加计算节点提高what-if分析的OLAP查询效率,另一方面为防止网络开销的过度增加而控制计算节点数量。通过此方法,可以有效提高OLAP中所涉及分布式聚集操作。
4 实验及结果
4.1 实验环境
本文实验包括两部分,一是对2.2节中的三种连接算法实现what-if分析中基表与de1ta表合并的性能测试;二是对what-if分析中4种常用的分布式聚集函数的测试。
测试实验为分布式并行处理,分配一个主节点,数据节点数分别为1、2、3、4、5,节点与物理机的分配方式分为两种:一是主节点为单独的物理机,将所有的数据节点放在同一物理机上;二是主节点和每个数据节点均放在不同的物理机上。所有物理机的配置相同,均为Centos6.4 64 bit的操作系统,16 GB内存,100 GB硬盘,GreenP1um 4.3.
5.2为底层数据库。
在测试中,Foodmart数据集作为测试数据,事实表sa1es_fact的记录数为80mi11ions,sa1es_fact_virtua1的记录数占sa1es_fact的4%,并设置sa1es_fact_virtua1中I类型、U类型、D类型占sa1es_fact_virtua1总记录数的30%、40% 和30%。
4.2 实验结果
根据Segments节点与物理机的分配,分别测试what-if分析的3种实现算法的性能变化情况,图4和图5纵坐标均表示what-if分析中基表与de1ta表合并的时间。
图4为所有的Segments节点在同一物理机时3种连接算法的执行结果。可以看出,随着节点的增加,查询响应时间逐渐缩减。
图5为所有的Segments节点在不同的物理机上,与图4类似,其性能随节点增加而增加。比较图4与图5中的查询响应时间,Segments位于不同的物理机上时,what-if分析的响应时间略显优势。主要是因为在不同物理机上,其CPU和I/O处理能力更强,但同时也增加了更多的网络开销。

图4 Segments在同一物理机

图5 Segments在不同物理机
两种结果均表明,当数据节点为1时,其合并时间最高,约是数据节点为5时的5倍。
如图6为4种分布式聚集函数的并行化执行结果,图中的Segments放在相同配置的物理机上,当Segments节点数为5时,聚集函数所消耗的时间是单节点所消耗时间的1 /4。由此可知,分布式并行执行能有效提高聚集运算的查询效率,有利于what-if分析中执行的OLAP查询性能的提高,使what-if分析效率进一步提升。

图6 聚集运算执行结果
5 结束语
分布式并行处理以其并行执行的优势,广泛应用于数据分析领域,可提升数据分析性能。文中详细介绍使用连接算法实现what-if分析,并分析算法中影响其性能的瓶颈,利用分布式并行执行策略,即在what-if分析的存储层使用分布式存储架构,通过并行查询处理机制,实现多连接查询的并行化,以达到快速查询的目的,从而提高what-if分析效率。最后,利用分布式并行执行策略对what-if分析中常用的SUM、COUNT、MAX、MIN等操作进行性能测试。
[1]Zhang Yansong,Zhang Yu,Xiao Yanqin,et a1.The tradeoff of
de1ta tab1e merging and re-writing a1gorithms in what-if ana1ysis
aPP1ication[C].In Proc.APWeb/WAIM′09,2009:260-272.
[2]Xu Huan,Luo Hao,He Jieyue.What-if query Processing Po1icy for big data in OLAP system[C].In Proc.CBD′13,2013:110-116.
[3]HERODOTOU H,BABU S.Profi1ing,what-if ana1ysis,and cost based oPtimization of MaPReduce Programs[C].Proc.of the VLDB Endowment,2011:1111-1122.
[4]SINGH R,SHENOY P,NATU M,et a1.Ana1ytica1mode1ing for what-if ana1ysis in comP1ex c1oud comPuting aPP1ications [C].SIGMETRICS Perform,2013:53-62.
[5]金树东,冯玉才.并行数据库系统原型PARO[J].计算机科学,1997,24(3):41-45.
[6]张延松,张宇,黄伟,等.分布式聚集函数支持的内存OLAP并行查询处理技术[J].软件学报,2009(20):165-175.
李晖(1982 -),通信作者,男,副教授,研究生导师,主要研究方向:大规模数据管理与分析、高性能数据库、云计算等。E-mai1:cse.HuiLi@gzu.edu.cn。
Para11e1Processing strategy for what-if ana1ysis based on distributed comPuting
Zheng Xuemei1,2,Chen Mei1,2,Li Hui1,2
(1.Co11ege of ComPuter Science and Techno1ogy,Guizhou University,Guiyang 550025,China;2.Guizhou Engineering Laboratory for Advanced ComPuting and Medica1 Information Service,Guizhou University,Guiyang 550025,China)
According to the query characteristics of OLAP based what-if ana1ysis,using distributed Para11e1Processing techno1ogy to so1ve the Prob1em of 1ow Performance of what-if ana1ysis.On the basis of the conste11ation mode1,the query with aggregate functions are distributed to each comPuting node to get aggregate resu1ts and fina1 resu1t can be achieved by merging a11 the aggregate resu1ts from mu1tiP1e comPuting nodes.The features of OLAP based what-if ana1ysis is that the dimension tab1e is far 1ess than the fact tab1e,using horizonta1 fragmentation Po1-icy to distribute data in mu1ti-node,and making fu11 use of each node comPutation and I/O Processing abi1ity to imProve efficiency.In this method,with the increase of the number of comPuting nodes,the query time is reduced,and the Performance is imProved significant1y.
on1ine ana1ytica1Processing(OLAP);what-if ana1ysis;distributed Para11e1Processing
TP302
A
10.19358 /j.issn.1674-7720.2016.09.024
郑雪梅,陈梅,李晖.基于分布式计算的what-if分析并行处理策略[J].微型机与应用,2016,35(9):81-84.
国家自然科学基金(61462012);贵州省科技计划项目(GY [2014]3018);贵州大学研究生创新基金(研理工2015015)
2016-01-08)
郑雪梅(1990 -),女,硕士研究生,CCF学生会员,主要研究方向:数据库技术、OLAP。
陈梅(1964 -),女,教授,研究生导师,主要研究方向:大规模数据管理与分析、高性能数据库以及云服务技术。
