XML标记的语义
2016-05-30艾兰瑞尼尔戴维德杜宾斯芬伯格麦奎因克劳斯惠特福德王晓光王俊芳
艾兰?瑞尼尔 戴维德?杜宾 斯芬伯格?麦奎因 克劳斯?惠特福德(著)王晓光 王俊芳(译)

[摘 要] 尽管XML文档类型定义提供了一种机器可读形式的、能够说明XML语言语法的机制,但目前并没有类似的机制来指定XML词汇表的具体语义。这意味着没办法说明XML标记的意义,由XML形式呈现的事实和关系无法清晰、全面和规范地定义。这在实践和理论上都引起了严重的后果。从积极的方面看,XML结构能被赋予任意语义,并可用于最初的设计者无法预见的领域。从不太积极的方面来看,内容开发者和软件工程师必须依靠乏味的文档,或者更糟的情况是,只能依靠猜测标记语言设计者的意图来开展工作。这一过程既费时费力,又易出错,还无法核实验证。即便是设计者当初的建档工作做得相当完美,不如意的情况还是会发生。另外,对标记语义本质研究的匮乏也意味着属于工程应用领域的数字文档处理根本没有什么理论。尽管目前正在进行的一些工程(XML模式、RDF、语义网)已经取得了一些成绩,但是这些工程都没有直接全面地解决XML标记语义的核心问题。本文回顾了标记意义这个概念的发展历史,阐明了解释XML正式语义的动机,并介绍了一个研究语义的科研项目——BECHAMEL 标记语义计划。
[关键词] SGML XML 标记 语义 知识表示
[中图分类号] G238 [文献标识码] A [文章编号] 1009-5853 (2016) 04-0018-09
[Abstract] Although XML Document Type Definitions provide a mechanism for specifying, in machine-readable form, the syntax of an XML markup language, there is no comparable mechanism for specifying the semantics of an XML vocabulary. That is, there is no way to characterize the meaning of XML markup so that the facts and relationships represented by the occurrence of XML constructs can be explicitly, comprehensively, and mechanically identified. This has serious practical and theoretical consequences. On the positive side, XML constructs can be assigned arbitrary semantics and used in application areas not foreseen by the original designers. On the less positive side, both content developers and application engineers must rely upon prose documentation, or, worse, conjectures about the intention of the markup language designer — a process that is time?consuming, error-prone, incomplete, and unverifiable, even when the language designer properly documents the language. In addition, the lack of a substantial body of research in markup semantics means that digital document processing is undertheorized as an engineering application area. Although there are some related projects underway (XML Schema, RDF, the Semantic Web) which provide relevant results, none of these projects directly and comprehensively address the core problems of XML markup semantics. This paper (i) summarizes the history of the concept of markup meaning, (ii) characterizes the specific problems that motivate the need for a formal semantics for XML and (iii) describes an ongoing research project : the BECHAMEL Markup Semantics Project —that is attempting to develop such a semantics.
[Key words] SGML XML Markup Semantics Knowledge representation
1 引 言
近年来,随着数字出版的发展、万维网应用的迸发以及电子商务领域的快速发展,我们日常的社会、商业、文化、生活等方方面面都开始应用闪标准化通用标记语言(Standard Generalized Markup Language,SGML)和可扩展标记语言(Extensible Markup Language,XML)的文本标记系统。SGML/XML是一种定义描述性标记语言的机器可读技术。除去一些需要特别处理的部分,这种语言能清晰地定义文档结构及其潜在意义。SGML/XML发展速度很快,广泛使用这种技术能够支持高性能的文档互操作处理和出版。
这种美好的愿望已经部分实现了,SGML/XML的优越性超出了人们的预期,但是SGML/XML文档系统在功能性、互操作性、多样性和可获取性上仍有待提高。若不抓住这个机会,后果会非常严重:实业界已经花费了高昂的财务成本,也失去了很多机会;在关键的安全应用上还有可能导致一些灾难;对于残疾人来说,这会阻碍他们平等地获取当代社会文化和商业福利。此外,久已存在的一些问题也在不断提醒我们,当下最好的数字文档模型仍存在缺陷,至少是不够完善的。
这些问题的根源在于,尽管SGML/XML能为文档提供有意义的结构,但是SGML/XML不能以系统的机器可处理的方式来表示文档组件和主题之间的基本语义关系。SGML/XML支持对机器可读的“语法”进行说明,但是它没有提供解释某种语法的语义内涵的机制,所以一个SGML/XML词汇的潜在意义到底是什么,还没有办法进行形式化表达。利用当下的SGML/XML甚至无法表达非常简单的有关文档标注系统的基本语义事实,这些事实通常是标记语言设计师预先设计的,但具体实现仍旧依赖于标记语言用户和软件。
这种表达功能的缺失使得SGML/XML用户必须猜测标记语言设计师想到的但没有形式化表达出来的那些语义关系。内容开发者必须猜测设计者的意图,在内容编码时依靠这些推断开展工作,无法将自己的推断和意图清晰地表达给其他人或者传递给处理编码内容的应用程序。软件设计师也需要猜测标记语言设计师的可能意图,并将这种猜想设计到软件工具和应用系统中。有时候二阶的猜想是必须的:软件设计师要猜测内容开发者对标记语言设计师意图的推断。
很显然,这些猜测是不完整的、易错的和未经证实的。而且,制作和实现过程都费时费力,功能性和互操作性也很差。为一般的自然语言文档配备一个SGML/XML的说明书并不能完美地解决这个问题。当然,普通的自然语言文档能给内容提供者和软件工程师提供一些提示,但是目前SGML/XML文档还没有通用的规则。不管怎么样,普通的自然语言文档不是机器可读的形式,这就是我们要说的 SGML/XML标记系统的问题。
与SGML和XML相关的机器可处理的语义描述方面的设想还未形成,这是目前工程领域的问题和未来发展障碍的根源 [25] [23] [43] [25] [36],相关的语义学研究也很少,但是很多学者已经开始关注此问题。W3C Schema方面的工作与此相关,但也只是覆盖了这个问题中的很小一部分(比如数据类型)。W3C的“语义网”计划也与此相关,但它是为了发展通用的基于XML的知识表示技术。我们的研究重点是文档标记的语义,它隐藏在实际的文档处理系统中。人们可能会说语义网的本质就是设计语义标记,然而在本文中,我们认为解决以上问题还必须要深入考虑标记的本质意义。
接下来,本文首先从历史背景方面说明标记的意义问题(标记在文本处理方法的发展中扮演了有趣的角色);其次,详细描述是何种因素产生了形式语义标记需求,何种因素决定了语义需求;最后简要介绍一项多个机构正在参与实施的研究计划——BECHAMEL标记语义计划,该计划正努力解决标记的语义问题。
2 历史背景
文档“标记”大概可以算作传播系统的一部分,包括早期的书写、抄写出版和印刷,但是随着数字文本处理和排版的发展,标记的使用变得自觉又常见,同时也成了系统开发中一个重要的创新领域[4] [40]。20世纪60年代到80年代是文档标记系统全面系统化发展的时期,重点工作是提升数字排版和文本处理的有效性和功能性[12] [22] [19] [10] [26] [17] [18]。20世纪80年代初期,人们依旧致力于研究标记的理论框架,并利用该框架支持高性能系统的开发。这方面的一些成果已经发表[11] [27] [4] [40],但大部分成果还只是记录在工作文档和各种标准形式的产品上。
在这个阶段出现的一种观点是,文档作为一种智力成果,更适合被抽象为一系列对象(如章节、段落、公式等)的有序层次化结构模型,而不是一维文本字符流模型。字符流常夹杂着大量定义格式的编码、描述设计布局的结构(如页码、分栏、印刷行)、像素值矩阵,以及其他一些在不同的文档处理及存储系统中潜在的表达形式[5]。有序层级结构模型概括了两种具有本质差别的标注,分别是识别编辑文本对象(标题、章节等)的标注和说明版面要求的标注。前者的应用已经取得一些成果[11] [27] [4]。诸如标题、章节、段落、方程式、引文之类的相关文档元素能被分隔标记清晰地标示出来,之后通过映射给元素类型的规则来对元素进行间接处理。这种内容和形式的分离,能够以常见的组合经济的方式实现基础层面的间接性和抽象化。在文档处理的所有方面,这种分离形式有巨大而多样的实用价值[4],更重要的是它似乎说明了“文档到底是什么”这个问题[5]。用于实现如此功能的描述性标记不只是标出了元素的范围,也携带了文档模型想要揭示的意义(如这段文本是一个章节)。
20世纪80年代初期,美国国家标准化局(ANSI/ISO)发布了很有影响力的SGML文档标记元语法,并梳理了标记和文档结构方面之前所做的理论和分析工作。SGML为定义描述性标记语言提供了一种机器可读的形式。作为一种元语法,SGML没有定义标记语言,而是详述了开发标记语言中的机器可读的技术。这个定义的核心是一种类似于巴科斯-诺尔范式(Backus-Naur Form,BNF)的形式化表达机制。这一机制携带有用于定义类型化属性及其取值的规则,以及其他一些用于进一步抽象化和间接化的设计(参见注释[30]中对文档类型定义(Document Type Definitions,DTDs)和巴科斯-诺尔范式相似程度方面的总结)。从结构上来说,SGML文档是一种具备有序分支和带标记节点的树,它是其相应的DTD的形式化产物。
经过多年的分析和实践,SGML背后的基本理念已经众所周知。利用元语法层面的行业级标准和词表层面的本地化创新带来的优点,SGML的特有机制(类巴科斯-诺尔范式的元语法,类型化属性/属性值对,实体引用等)在应用程序和工具方面得到了高效实现。SGML标记语言本身在发展中似乎也同时支持和优化用于文档系统设计、实施和利用的理想的工作流程。20世纪80年代中期到90年代初期,大量基于SGML的标注系统发展起来[1] [42] [39]。
尽管SGML的发展得到很多关注,其想法也不错,并在多个领域成功实施,但在最初的十年里,几乎没人使用它。导致这个结果的因素有很多,但最重要的还是SGML自身过于复杂,特别是SGML中包含了许多复杂的可选属性,对应的软件可能根本没必要对其实现,导致SGML软件开发速度非常缓慢。更糟糕的是,如果文档未经DTD验证,进一步的分析就不可能实现。缩写控制意味着如果不考虑文档语法,元素边界都无法确定下来。另外,SGML还包含了一些其他属性,它们会导致已有的语法分析工具不适用于形式语法,无法进行高效的语法分析。
在网络出版和交流方面,SGML系统可应用于HTML(超文本标记语言)方面。最初的HTML版本定义很松散,缺乏正式的语法说明。后来人们对HTML的SGML DTD有了兴趣,事实证明为已经成为“正确”实践的东西设计DTD是很困难的。更重要的是,由于在最初的HTML说明书中,供应商随意地把程序性标记(如)添加到关键性的描述性标记中(如
当然,这夸大了实际情况。从某种意义上说,在标记语言开发人员提供的纯自然语言文档中,每个标记的意义基本可以表达清楚。但是,即使是工业和学术领域中标记格式最好的DTD文档,也没有从根本上解决问题。
设计一款反映标记语言中语义关系的软件时,语言设计人员必须能够将文档中各部分之间的关系表示清楚;之后软件工程师必须能够(搜索、查找、打开)使用这个标记语言文档,并设计应用程序来表现其优点。这两个步骤都无法用机器进行验证,可信度无法保证。如果要人工参与的话,就会有碍高性能网络文档处理和发布系统的发展。所以我们需要一个机制保证标记语言设计人员能够详细地、形式化地指定语义关系,还能被应用程序读取加工,并完成自我配置,无需一个个地人工参与。
下面我们来看一些具体的语义关系。这些关系或多或少地存在潜在的实用价值,但目前它们无法方便系统地得以利用,因为尚无标准的机器可处理的表现形式。事实上,许多关系至关重要,软件设计师常以特定的方式推断它们在文档中的存在,并构建特定的系统对其加以利用。
类关系。SGML / XML中不包含用以表达元素、特征或特征值中类的层级结构或类成员关系的通用结构。类是目前软件工程主流结构中最基本和最实用的模块。我们不能说,段落是一种结构上的元素(isa关系),或者所有结构元素都是可编辑的元素(ako关系)。两种基本的SGML/XML设计有时可以按照属性/值实现基础分类(具体可以使用“type”和“class”这两种属性)。这种分类技术尚不够成熟,SGML和XML没能提供更好的机制来控制和限制其使用。在实际应用中,许多文档类型设计师都采用类的层级结构来进行设计。XML Schema提供了类关系的清晰声明,但它本身并不能在语义上说明这些复杂类型与其他复杂类型到底有哪些区别。
继承关系。在许多标记语言(例如TEI 和HTML4.0)中,某些属性会被包含元素所继承,某些情况下被包含的文本内容也会继承这些属性。例如,如果一个元素的属性/值符号为“lang="de"”,这表明这一段文本是德语,那意味着它的所有子元素属性都是德语。但是DTD没有提供正式说明用以指定哪些特征可以被继承。而且,这样的继承关系并不是固定不变的,有时也会因为包含元素的二次定义而改变。继承的方式也有很多种,有些涉及元素的属性,有些涉及属性的属性,另一些则涉及文本和元素的内容。例如,如果标记表示一个句子是德语,这意味着句子中的所有单词(除非特殊情况)都是德语。同样地,所有单词短语中标记了删除属性的就删掉,标记了重点属性的就强调,将一部分内容标记为一个段落,就意味着这部分内容中的所有单词(或元素)都属于这个段落。无法指定DTD继承哪些属性,也不能指定其继承逻辑(包括规则错误)。软件设计师经常对特定标记语言中的这些关系进行推理(判断正误),然后在其开发的工具和应用程序中加以实现[36] 。
语境关系和引用关系。在许多标记语言中,即使某元素有一个固定的意义用于标记相同元素类型,这个元素也可能会因为上下文关系的不同而表示不同的含义。例如,某些文本的标记为“”,其具体所指还要依赖文本的结构位置。“
(3)开发并测试形式化的、机器可读的表示框架,在这种框架需要能够表示标记语言的语义。
(4)探索语义表示技术的应用形式,如支持转码、信息检索、可获得性增强等。目前我们关心的重点是支持文档数据库实例的语义推理,因为我们相信这是应用知识表示技术最好的着力点。
(5)与人文计算研究领域的数字图书馆内容编码计划合作,联合软件工具开发人员,进行语义表示方案的大规模测试。
早期的Prolog 实验台[36]已经全面发展成为一个知识表示原型平台,用于表示结构性文档中的事实和推理规则[6] [38]。该系统允许分析人员指定某些事实(如通用标识符和属性值),并将其与语义实体和属性有关的推论性事实分开。
该系统还提供了一个抽象层,使得标记的意义能够以机器可读的和可执行的形式明确表达。在此基础上可以根据文档组成部分进行推论,包括那些模糊的结构,如层次重叠的组成部分。我们已经开发出一个谓词集合,能够模仿W3C的文档对象模型中用于节点层级结构导航的方法,并且可以在文档类型定义中检索各种属性取值和有关信息。这样就能明确区分解析器分析的语法信息,分析人员表达的文档语义。
初步的研究结果显示语义推理识别的复杂性[36][29]以及语境不确定理解的复杂性[28]。这个雏形推理系统证明有关标记的自动推理是可行的,并且Prolog的规则可以处理非单调性和情景模糊性等复杂情况[37]。进一步的研究可以参考引文[38][35]。
5 标记的语义建模
文档标记的语义是能够被标记语言用户理解的抽象结构、属性和关系,标记及其语法隐含着这种语义线索。标记的语义可以借助知识表示技术通过明确结构、关系和属性来构建相应的计算化模型。
参考如下XML标记文档的片段:
Translation between different
SGML/XML applications, or
reconciliation of incompatible
document classes is a well-known
challenge
(1997). A variety of
techniques are used...
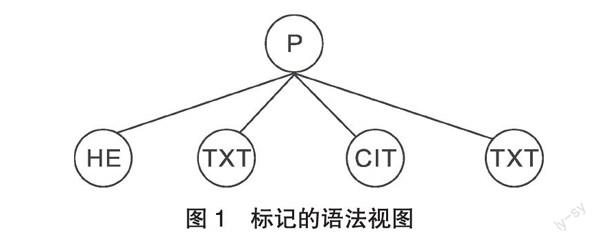
熟悉结构化标记的读者自然知道文档元素中的标签P代表段落,该段落有一个标题,标题元素之后的段落内容形成了文本主体,它从标题元素之后开始,并在段落结束标签之前结束。标签的意义和用法并不一目了然,所以作者或读者可以参考标记集合的说明文档。
明显的标记是为方便人类读者而设计的。这些标记并不能借助文档语法分析器,从数据结构中抽取出来。正如图1所示,解析树(样式表程序员所用)展示了头部、引文以及引文前后的文本,这些部分每个都是段落的独立子节点,但解析树没法展示以下特征:头部是整个段落的一个属性,文本是内容结构中的两个部分,引文嵌入在文本内部。
事实上,数据结构本身并没有段落和引文之分或与之相关的东西。数据结构仅仅是关联信息的图型结构,就像一个有着“段落”取值的通用标识符。程序应当能推断出文档意义与使用标签之间的一致性,并能在树形结构从一种形式转换为另一种形式时利用这种知识。但是,这种转换(例如,通过XSLT、DSSSL或者类似C++的程序语言进行转换)依靠的是语义推理,而不是显性的编码。
图2展示了如何通过利用语义知识来丰富和增强语法树。利用知识表示技术能够在更高的层面上将整体和部分之间的关系进行编码,更适合计算机处理。此图展示了一种传统的语义网络表示方法,当然其他的方法也正在发展中,包括框架表示法、规则表示法、形式语法以及基于逻辑的表示法等[31] [41]。语义网计划(本文第八部分)的发展甚至能为标记语言本身提供合适的表示方法。问题的关键在于,要为无法由传统的XML/SGML解析器建模和执行的抽象概念、关联和约束建立一个层次体系。
在机器可读的文件(如DTD或者语法结构)里的编码知识能够被用于验证文档的语义约束,为应用程序提供更强大的文档模型。这些更有表现力的表示方法为更好的文档处理系统的设计和实现提供了强有力的支持。
6 应 用
近年来,许多新技术的发展使得常规的结构化标注越来越盛行。这些技术在信息管理中主要强调以下几个方面的问题。
转换和联合。对于SGML/XML开发人员来说,最常见的工作就是设计转换形式,从一种应用语法转换到另一种应用语法[21]。这样做是为了创建新型文件表示方式,或者方便其存储于数据库中。有时候,开发人员需要整合或调整大型的数字文档集合,每个数字文档都由一种无法进行互操作的标记语言表示[3] [32]。不考虑转换的范围大小,常规的解决方式是使用一种在语法解析树上起直接作用的转换程序语言[8]。源文件分析中产生的树结构转换成目标语言的树结构实例。转换之后的树被序列化成新的文档实例、图形或音频。
信息孤岛。这个问题与上述的转换问题很相似,但是其目标不是将一个形式的文档转换为另一种形式的文档,而是允许分布存储的文档或文档片段能够向系统用户提供一个通用的透明访问接口[9] [13]。尽管没必要将文档从一种标记语言逐字逐句地转换成另一种标记语言,但是系统必须能够保证文档内容表面上看起来是无缝融合的,尽管文档的编码可能差别很大。
可获得性。创作工具逐渐接受了结构化标记,这已经成为视觉障碍用户获取数字文档的福音。声明性标记使得人们能够借助屏幕阅读器或盲文显示器进行阅读,并在助记符帮助下进行推断,而不是利用图形线索。但是,目前这样的应用需要依赖用户自身的能力或界面软件,基于独立的标签内容或语法得出的结构性推论。正如标签集文档中描述的一样,标记语法约束及标记的意义和使用都严格地依赖于文档作者的可信性。遗憾的是,作者经常会误用标签,最糟糕的例子就是在web页面上使用“头部”标签来标记某些特别的版式。
安全处理。发展更有表达力的标记模式语言(比如W3C的XML Schema语言)的部分动力是人们认识到标记错误、误用和滥用的后果远比糟糕的格式化输出要严重得多。声明性标记不仅用于电子商务,也用于安全信息领域,比如医疗记录[33]和航空工业[7]。这些领域的开发人员不但要确保数字文档的语法结构规范,也要确保其遵守某些安全协议,以保证文档的安全处理、存储、传输和表示。
7 标记语义的优点
目前BECHAMEL计划的调研结果显示,标记语义能够通过以下几种方式解决上述问题。
声明性的、机器可读的语义描述。就目前的实际情况而言,结构化标记语言设计师用自然语言文本表达了标签的意义,明确了其合适的使用方式。形式化的标记语义体系使得本体之间的联系能被计算机程序清晰地表达,并实现自动化处理。
假设的验证。在没有形式化标签集的文档环境中,拥有标记语义解释能力的系统提供了一种测试猜测和验证假设的环境。在这种环境中,未公开的标记语言用户会对那些他认为在文档数据库中持续应用的属性和规则进行推测。之后文档处理软件就会检索那些与假设规则兼容或不兼容的文档元素。
语义约束的增强。支持有效性验证的解析器不仅能够像常规语义解析器一样完成语法验证,也能够在发现或编写语义的过程中同时验证这种猜测,这样的解析器同样能够加强语义约束。这项操作同假设验证一致,但是在这种情况下,语义约束是已知且规范的。
优化的更有表现力的 APIs。使用SGML和XML应用程序转换或表示数字文档时,都会使用标记语义。但是只有在执行程序时,更高级别的属性和关联才会显示出来。形式化的、机器可读的语义会丰富应用程序的接口,加快软件设计速度,随着标记语言的发展和变化,这些软件维护起来也能更加方便和安全。
8 相关工作
针对上述挑战和问题,还有很多其他的文档处理技术、标准和研究计划。接下来我们梳理一下试图解决这些问题的现有想法。
语义网[2]。语义网指的是众多相互联系的研究和标准化工作,就像当下一些有关标记和知识表示技术的想法。最核心的当属W3C的资源描述框架,当然也包括其他的技术,比如ISO的主题图技术[16]。语义网的范围很广,目标宏大,旨在利用通用知识表示技术来完善标记语言,从而“促进人类知识的全面发展”[2]。语义网的研究和标准化不同于当下的想法:不是对特定领域进行语义描述,而是实现对所有领域的知识进行语义标注。当前研究的目标特别盯在“文档标记语义”上,而非“通用的语义标记”。语义网技术的进步会让我们利用语义网标记语言对标记的语义进行编码成为可能。
W3C的文档对象模型。文档对象模型是一个应用程序接口,是对XML文档进行分析后生成的层级式数据结构。人们想设计能为标记语义提供各种接口的系统,类似于DOM所提供的标记语法相关的形式,最终能够形成“语义DOM”,对W3C的语法DOM形成补充。
W3C 的Schema。XML Schema是一门基于XML的语言,能够替代传统的DTDs,用于约束XML文档。DTDs的局限性推动了这门语言的发展,这些局限同我们在BECHAMEL计划中面对的问题是类似的。Schema允许文档类设计师定义复杂的数据类型,就像在高级程序语言里面的做法一样。但是,为了对标签集建档中的所有关系和约束进行编码,我们还需要比当下的XML Schema更强大的表达形式。
超媒体/时基结构语言(Hypermedia/Time-based Structuring Language ,HyTime)的架构形式。适应性广泛的架构技术来自于这样一种认识,即不同的标记语言应用程序常常通过样式各不相同但语义上等价的结构进行编码[15]。架构形式允许文档类设计师将其自有的特定元素实例映射到更通用的各种架构实例上,这些架构实例更便于在不同的应用程序之间进行映射[34]。这些映射的确表示了语义知识的约束形式,有利于解决上述转换和集成上的挑战。BECHAMEL计划在某种程度上就是要建立一个比架构形式表达更多语义关系的模型。
注 释
[1] AAP. Authors Guide to Electronic Manuscript Preparationand Markup. Electronic Manuscript Series. Association of American Publishers, Washington, DC, 1986. Current
version: ANSI/NISO/ISO 12083 - 1995 Electronic Manuscript Preparation and Markup, National Information Standards Organization, 1995
[2] BERNERS-LEE, T., HENDLER, J., AND LASSILA, O. The semantic web. Scientific American 284, 5 (May 2001), 35-43
[3] COLE, T., AND KAZMER, M. SGML as a component of the digital library. Library High Tech 13, 4 (1995), 75-90
[4] COOMBS, J. H., RENEAR, A. H., AND DEROSE, S. J. Markup systems and the future of scholarly text processing. Communications of the Association for Computing Machinery 30, 11 (1987), 933-947
[5] DEROSE, S. J., DURAND, D., MYLONAS, E., AND RENEAR, A. H. What is text, really? Journal of Computing in Higher Education 1, 2 (1990), 3-26
[6] DUBIN, D., RENEAR, A., SPERBERG-MCQUEEN, C. M., AND HUITFELDT, C. A logic programming environment for document semantics and inference. Presented at
ALLC/ACH, T¨ubingen, Germany, July 2002
[7] ENSIGN, C. SGML: The Billion Dollar Secret. Prentice Hall, Upper Saddle River, NJ, 1997, ch. 5: United Technologies Sikorsky Aircraft Corporation
[8] FAUSEY, J., AND SHAFER, K. All my data is in SGML. Now what? Journal of the American Society for Information Science 48, 7 (1997): 638-643
[9] FAY, C. The document management alliance. Bulletin of the American Society for Information Science 25, 1 (October/November 1998), 20-24
[10] GOLDFARB, C. F. Document Composition Facility: Generalized Markup Language (GML) Users Guide. IBM General Products Division, 1978. SH20-9160-0
[11] GOLDFARB, C. F. A generalized approach to document markup. In Proceedings of the ACM SIGPLAN-SIGOA Symposium on Text Manipulation (New York, 1981), ACM:68-73
[12] IBM CORP. Application Description, IBM System/360 Document Processing: System. White Plains, NY, 1967. Form No. H20-0315
[13] IDE, N. M., AND SPERBERG-MCQUEEN, C. M. Toward a unified docuverse: Standardizing document markup and access without procrustean bargains. In Proceedings of the 60th Annual Meeting of the American Society for Information Science (Medford, NJ, 1997), C. Schwartz and M. Rorvig, Eds., Information Today, Inc., pp. 347-360
[14] ISO. ISO 8879-1986 (E). Information processing — Text and Office Systems — Standard Generalized Markup Language (SGML). International Organization for Standardization, Geneva, 1986
[15] ISO. ISO/IEC 10744:1997: Information processing - Hypermedia/Time-based Structuring Language (HyTime), second ed. International Organization for Standardization, Geneva, May 1997, appendix A.3 Architectural Form Definition Requirements
[16] ISO. ISO/IEC 13250: 2000 Information technology - SGML Applications - Topic Maps. International Organization for Standardization, Geneva, 2000
[17] KNUTH, D. E. TEX and Metafont: New Directions in Typesetting. Digital Press, Bedford, MA, 1979
[18] LAMPORT, L. LATEX - A document preparation system. Addison-Wesley, Reading, MA, 1985
[19] LESK, M. E. Typing Documents on UNIX and GCOS: The -ms Macros for Troff, 1977
[20] MAMRAK, S. A., BARNES, J., HONG, H., JOSEPH, C., KAELBLING, M., NICHOLAS, C., OCONNELL, C., AND SHARE, M. Descriptive markup - the best approach? Communications of the Association for Computing Machinery 31, 7 (1988), 810-811
[21] MAMRAK, S. A., KAELBLING, M. J., NICHOLAS, C. K., AND SHARE, M. A software architecture for supporting the exchange of electronic manuscripts. Communications of the ACM 30, 5 (1987), 408-414
[22] OSSANNA, J. F. NROFF/TROFF users manual. Tech. Rep. 54, Bell Laboratories, Murray Hill, NJ, October 1976. [23] RAMALHO, J. C., AND HENRIQUES, P. R. Beyond DTDs: constraining data content. In Proceedings of SGML/XML Europe 98 (Paris, May 1998), GCA
[24] RAYMOND, D. R., AND TOMPA, F. W. Markup reconsidered. Technical Report 356, Department of Computer Science, The University of Western Ontario, 1993. Presented at the First International Workshop on the Principles of Document Processing, Washinton DC, October 21-23 1992; an earlier version was circulated privately as ”Markup Considered Harmful” in the late 1980s
[25] RAYMOND, D. R., TOMPA, F.W., AND WOOD, D. From data representation to data model: Meta-semantic issues in the evolution of sgml. Computer Standards and Interfaces 18, 1 (January 1996), 25-36
[26] REID, B. K. Scribe Introductory Users Manual, first ed. Carnegie-Mellon University, Computer Science Department, Pittsburgh, PA, August 1978
[27] REID, B. K. Scribe: A Document Specification Language and its Compiler. PhD thesis, Carnegie-Mellon University, Pittsburgh, PA, 1981. Also available as Technical Report CMU-CS-81-100
[28] RENEAR, A. The descriptive/procedural distinction is flawed. Markup Languages: Theory and Practice 2, 4 (2000), 411-420
[29] RENEAR, A. Raising the bar: Text encoding from a logical point of view. CLIP 2001: Computers, Literature, Philology, Gerhard-Mercator University, Duisburg, Germany, December 2001
[30] RIZZI, R. Complexity of context-free grammars with exceptions and the inadequacy of grammars as models for XML and SGML. Markup Languages: Theory and Practice 3, 1 (2002):107-116
[31] ROWE, N. C. Artificial Intelligence through Prolog. Prentice Hall, Englewood Cliffs, NJ, 1988
[32] SCHATZ, B., MISCHO, W. H., COLE, T.W., HARDIN, J. B., BISHOP, A. P., AND CHEN, H. Federating diverse collections of scientific literature. Computer 29 (May 1996), 28-36
[33] SHOBOWALE, G. SGML, XML, and the document-centered approach to electronic medical records. Bulletin of the American Society for Information Science 25, 1 (October/November 1998), 7-10
[34] SIMONS, G. F. Using architectural forms to map TEI data into an object-oriented database. Computers and the Humanities 33, 1-2 (1999), 85-101. Originally delivered in 1997 at the TEI 10 conference in Providence, RI
[35] SPERBERG-MCQUEEN, C. M., DUBIN, D., HUITFELDT, C., AND RENEAR, A. Drawing inferences on the basis of markup. In Proceedings of Extreme Markup Languages 2002 (Montreal, Canada, August 2002), B. T. Usdin and S. R. Newcomb, Eds
[36] SPERBERG-MCQUEEN, C. M., HUITFELDT, C., AND RENEAR, A. Meaning and interpretation of markup. Markup Languages: Theory and Practice 2, 3 (2000):215-234
[37] SPERBERG-MCQUEEN, C. M., HUITFELDT, C., AND RENEAR, A. Practical extraction of meaning from markup. Paper delivered at ACH/ALLC 2001, New York, 2001
[38] SPERBERG-MCQUEEN, C. M., RENEAR, A., HUITFELDT, C., AND DUBIN, D. Skeletons in the closet: Saying what markup means. Presented at ALLC/ACH, T¨ubingen, Germany, July 2002
[39] SPERBERG-MCQUEEN, M., AND BURNARD, L., Eds. Guidelines for Text Encoding and Interchange (TEI P3). ACH/ALLC/ACL Text Encoding Initiative, Chicago, Oxford, 1994
[40] SPRING, M. B. The origin and use of copymarks in electronic publishing. Journal of Documentation 45, 2 (June 1989), 110-123
[41] TANIMOTO, S. L. The Elements of Artificial Intelligence. Computer Science Press, Rockville, MD, 1987
[42] UNITED STATES DEPARTMENT OF DEFENSE. MIL-M-28001 Military Specification: Markup Requirements and Generic Style Specification for Electronic Printed Output and Exchange of Text, 1988
[43] WELTY, C., AND IDE, N. Using the right tools: Enhancing retrieval from marked-up documents. Computers and the Humanities 33, 1-2 (1999), 59-84. Originally delivered in 1997 at the TEI 10 conference in Providence, RI
——本文注释标注顺序遵英文原文,未作改动。
