基于高光谱图像技术的大豆品种无损鉴别
2016-05-05柴玉华毕文佳谭克竹张春雷刘春涛东北农业大学电气与信息学院哈尔滨150030
柴玉华,毕文佳,谭克竹,张春雷,刘春涛(东北农业大学电气与信息学院,哈尔滨 150030)
基于高光谱图像技术的大豆品种无损鉴别
柴玉华,毕文佳,谭克竹,张春雷,刘春涛
(东北农业大学电气与信息学院,哈尔滨150030)
摘要:为解决传统大豆品种检测方法存在的效率低和精度差等问题,应用高光谱图像分析技术展开大豆品种甄别研究。采集10个品种(每品种100粒,共1 000粒)大豆样本400.92~999.53 nm的高光谱反射图像,分别进行中值平滑、多元散射校正和数据标准归一化预处理去噪,提取样本图像中心30×30 pixels感兴趣区域的平均光谱曲线和标准差曲线。分别以样本平均光谱值主成分得分、标准差光谱值主成分得分及两者结合作为模型输入,基于T-S模糊神经网络和随机森林思想组合分类器构建鉴别模型。经中值平滑的光谱平均值和标准差作输入,结合随机森林思想的组合分类模型鉴别效果最佳,训练集、测试集的平均鉴别率分别达99.6%和97.6%。结果表明,采用高光谱图像技术可实现大豆品种高精度无损鉴别。
关键词:大豆;高光谱图像;品种甄别;T-S模糊神经网络;随机森林思想组合分类器
柴玉华,毕文佳,谭克竹,等.基于高光谱图像技术的大豆品种无损鉴别[J].东北农业大学学报,2016,47(3):86-93.
Chai Yuhua,Bi Wenjia,Tan Kezhu,et al.Nondestructive identification of soybean seed varieties based on hyperspectral image technology[J].Journal of Northeast Agricultural University,2016,47(3):86-93.(in Chinese with English abstract)
random forest classifier
不同种类大豆品质良莠不齐,油量、蛋白含量、生长周期及抗病虫害能力不同。我国大豆种类繁杂,混种混收现象严重[1-2]。近年来,高光谱图像技术在农产品检测应用上发展迅速,主要运用在玉米、小麦、黑豆、油菜籽及西瓜籽等种类鉴别方面[3-7]。大豆种类间的活性成分含量不同能引起高光谱图像的光谱特征改变[8],谭克竹等提取高光谱特征波段,结合BP神经网络实现对大豆品种分类[9]。本文以高光谱数据作模型输入量,利用TS模糊神经网络和基于随机森林思想的组合分类模型方法无损鉴别10种大豆品种样本,研究其可行性和准确率。
1 试验概况
1.1材料
本试验选取东北农业大学选育的10个典型品种大豆进行品种甄别,分别为东农61,东农56,东农54,东农53,东农52,东农51,东农47,东农43,东农42和东农41,每品种精选100粒豆体匀称,完整无损豆粒作试验样本。试验样本由东北农业大学大豆研究所提供。
1.2仪器设备
高光谱采集系统硬件包括成像镜头CCD (1 392×1 024),成像光谱仪(HyperSpec VNIR),可调节高光谱升降台,100 mm或250 mm运动距离精准直流伺服线性控制器,照明宽度50 mm或200 mm可调节导光管作为线光源(根据试验需要运动距离选定100 mm,光源照明宽度选择200 mm),计算机,标准反射白板和暗箱。Hyperspec软件采集高光谱图像。成像光谱仪光谱范围为400.92~999.53 nm,共203个波段,光谱分辨率2~3 nm,图像分辨率为1 024×1 024。
利用ENVI5.1(ITT Visual Information Solution,USA)开展高光谱图像处理,采用Matlab2011b (The Math Works,USA)和IBM SPSS进行数据分析。
1.3高光谱图像采集
为提高试验数据的准确性,分别将每个品种的100粒大豆样本均匀平放在(20 cm×15 cm)黑色背景板上。结合以往图像采集经验以及多次反复调节高光谱系统参数,设置曝光时间为300 ms,镜头到白板距离为45 cm,步长100 mm,输送装置速度定为35 mm·s-1,确保高光谱图像清晰。

图1 采集系统实物Fig.1 Picture of acquisition system
在不同波段下,光谱图像中包含大量由于系统光源强度分布不均匀造成的噪音及摄像头中暗电流噪音。先对高光谱图像黑白标定[10],采集标定白板反射光谱及暗电流反射光谱,代入标定方程中:R=Ri-Rd/Rw-Rd
式中,R-标定后图像,Ri-样本图像,Rd-全黑标定图像,Rw-全白标定图像。大豆样本(东农41)原始图像见图2。高光谱波长495.749 nm下大豆样本(东农41)相对图像见图3。

图2 东农41原始图像Fig.2 Original image of Dongnong 41
2 结果与分析
2.1光谱数据预处理
为提高光谱信噪比,分别对10种大豆标定后高光谱图像进行5×5中值滤波平滑、多元散射校正(MSC)和标准归一化(SNV)处理。在每粒大豆样本中心部位选取30 pixel×30 pixel区域,以其所有像素的光谱平均值作为该样本平均光谱,以其光谱标准差值作为该样本标准差光谱。东农42大豆100粒样本反射平均值光谱和反射标准差光谱如图4、5所示。
5×5中值滤波平滑是通过用某点的前后5点值拟合出该点值,使数据平滑,减弱试验过程中叠加在原始光谱数据上的众多随机误差,如基线漂移等[11]。多元散射校正可较好削弱样品大小及水分等造成的散射影响;因该算法假设光谱波长变化不影响散射,对样品间性质差别较小的区分处理作用明显[12]。数据标准归一化使样本数据向量方差为单位1,可减少冗余信息,化繁为简,使样本间不同突显化[13]。

图3 东农41在高光谱495.749 nm波长下相对图像Fig.3 Corrected image of Dongnong41 for 495.749 nm wavelength

图4 东农42反射光谱均值图像Fig.4 Average reflectance spectra of Dongnong42
2.2样本的主成分定性分析
对于待测10种大豆品种样本各100粒,根据Kennard-Stone算法按3ϑ1比例分成训练集和测试集[14]。在光谱图像中,没有明显的噪声波段,训练集样本在400.918~999.530 nm全光谱波长范围内进行主成分分析,10类大豆样本的反射光谱平均值降维得到前3个主成分的累计方差贡献率均达到98%以上;反射光谱标准差值降维得到前3个主成分的累计方差贡献率均达99%。反射光谱平均值结合反射光谱标准差值降维,得到前4个主成分累计方差贡献率均达99%[15-16]。反射光谱平均值的前3个主成分PC1、PC2和PC3得分分布情况如图6、7所示。反射光谱标准差的前三个主成分PC1、PC2和PC3得分分布情况如图8、9所示。网络模型输入量维数过少,造成模型输出结果准确率较低。因此,分别在平均光谱和标准差光谱第一主成分系数中,选择5个最大数值对应的波段作为特征波段。试验以3组8维数据作为模型输入信息,一组为大豆样本平均光谱的3个主成分得分和5个特征波段上的光谱数据,一组为大豆样本标准差光谱的3个主成分得分和5个特征波段上的光谱数据,另一组是大豆样本平均光谱3个主成分得分、标准差光谱3个主成分以及各自1个特征波段光谱数据。
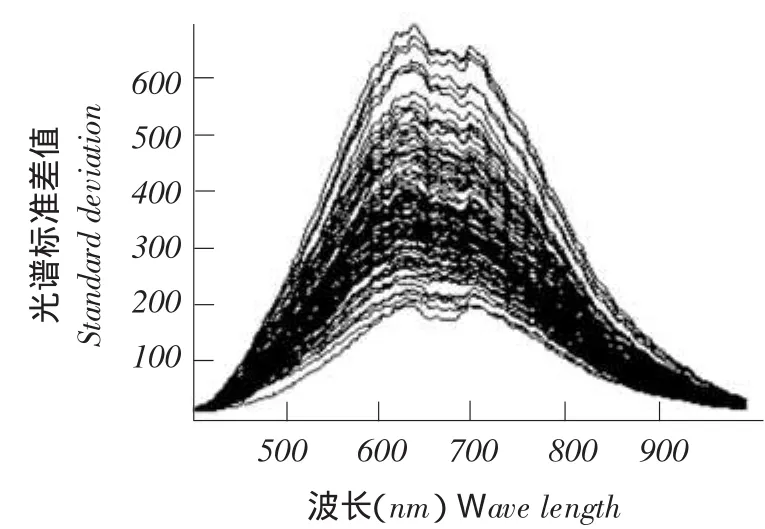
图5 东农42反射光谱标准差值图像Fig.5 Standard deviation reflectance spectra of Dongnong42
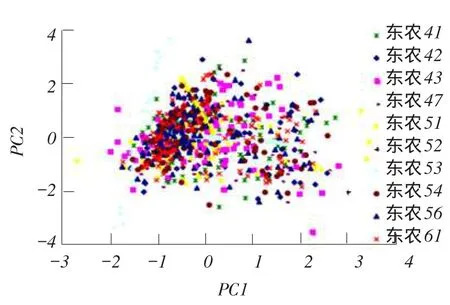
图6 反射光谱均值主成分PC1和PC2得分分布Fig.6 Scores scatter plot of PC1 and PC2
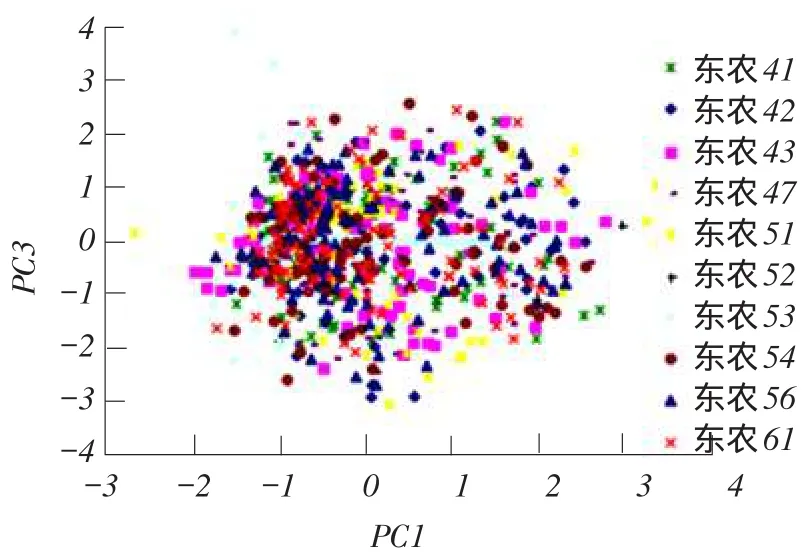
图7 反射光谱均值主成分PC1和PC3得分分布Fig.7 Scores scatter plot of PC1 and PC3

图8 反射光谱标准差值主成分PC1和PC2得分分布Fig.8 Scores scatter plot of PC1 and PC2
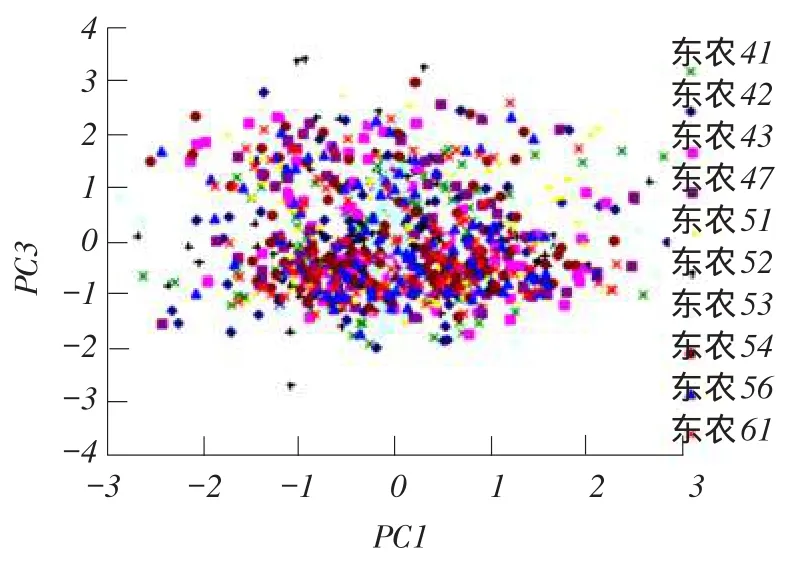
图9 反射光谱标准差值主成分PC1和PC3得分分布Fig.9 Scores scatter plot of PC1 and PC3
2.3判别模型的建立和结果讨论
2.3.1基于T-S模糊神经网络判别模型的建立
T-S模糊系统[17-18]自适应能力强,能自动更新,自行修正隶属函数。遵从“if-then”规则如式(1)所示。
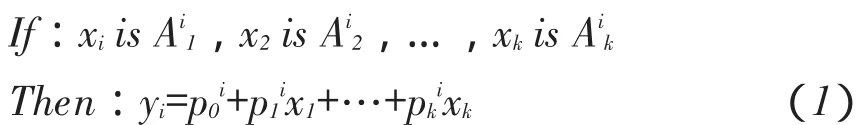
Aji是模糊集;yi是模糊系统输出的模糊值;pji(j=1,2,…,k)是模糊系统参数。模糊系统是根据已知输出,通过不断更新改动隶属函数,调整隶属度,获得与之呈线性关系模糊输入。当给定输入变量X=[x1,x2,…,xk],运用式(2)求取xj变量的隶属度:

μ是指模糊隶属度值;bji是指隶属度函数宽度;cji是指隶属度函数中心;其中模糊子集有n个,输入参数有k个。运用连乘模糊算子如式(3)所示对隶属度计算:
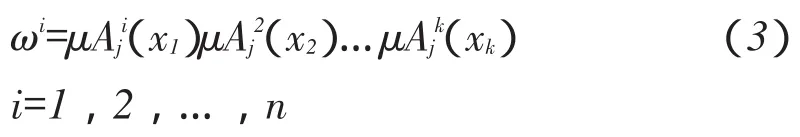
最后算得模糊输出如式(4)所示的yi:
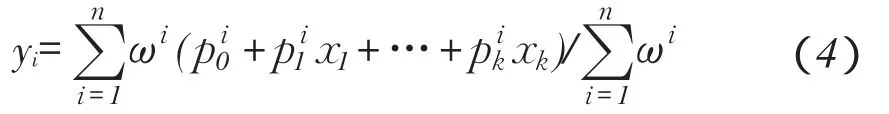
T-S模糊神经网络模型输入数据维数都为8,输出维数均为1,设定隶属度函数都为16个,网络训练重复200次,网络结构均为8-16-1。经过三种不同预处理为输入量在该模型下的判别情况(见表1~3)。
2.3.2基于随机森林思想组合分类判别模型建立
对于大豆样本集,随机森林思想[19-20]是基于Bootstrap法重复随机抽取样本,构成多个训练集S1,S2,...,Sk,再对应生成决策树C1,C2,...Ck。通过随机选取部分分裂属性集,再选取出其中最好的分裂方式分裂。最后,通过投票方式从这k个决策树选出分类最多的(见表4~6)。
由于本试验是品种鉴别,类别数固定,所以建模过程中不断调试随机森林中决策树个数,针对三种试验数据,本试验最终设定为100个、150个和100个,保证鉴别精度。试验共1 000组数据,训练集随机选750组,其余为测试集。三种不同预处理的三种输入量判别情况(见表4~6)。
2.3.3结果与讨论
分别分析比较表1~3或表4~6,无论是以光谱平均值、光谱标准差值还是两者结合,代入T-S模糊神经网络模型或是基于随机森林思想的组合分类模型中均取得较为理想识别效果,训练集识别率94%,测试集识别率最低达84%。
同模型同输入变量情况下,数据预处理方式不同对鉴别结果存在一定影响。三种预处理方式中,中值滤波平滑效果最适于本试验选定的模型输入和构建的模型种类,多元散射校正次之,鉴别效果可接受,基本强于数据标准归一处理。但以光谱标准差作输入随机森林思想组合分类模型时,多元散射校正处理和归一化处理对于鉴别效果影响不显著,只是前者比后者在测试集鉴别效果上略高且表现稳定。综合比较,5×5中值滤波平滑效果最优。
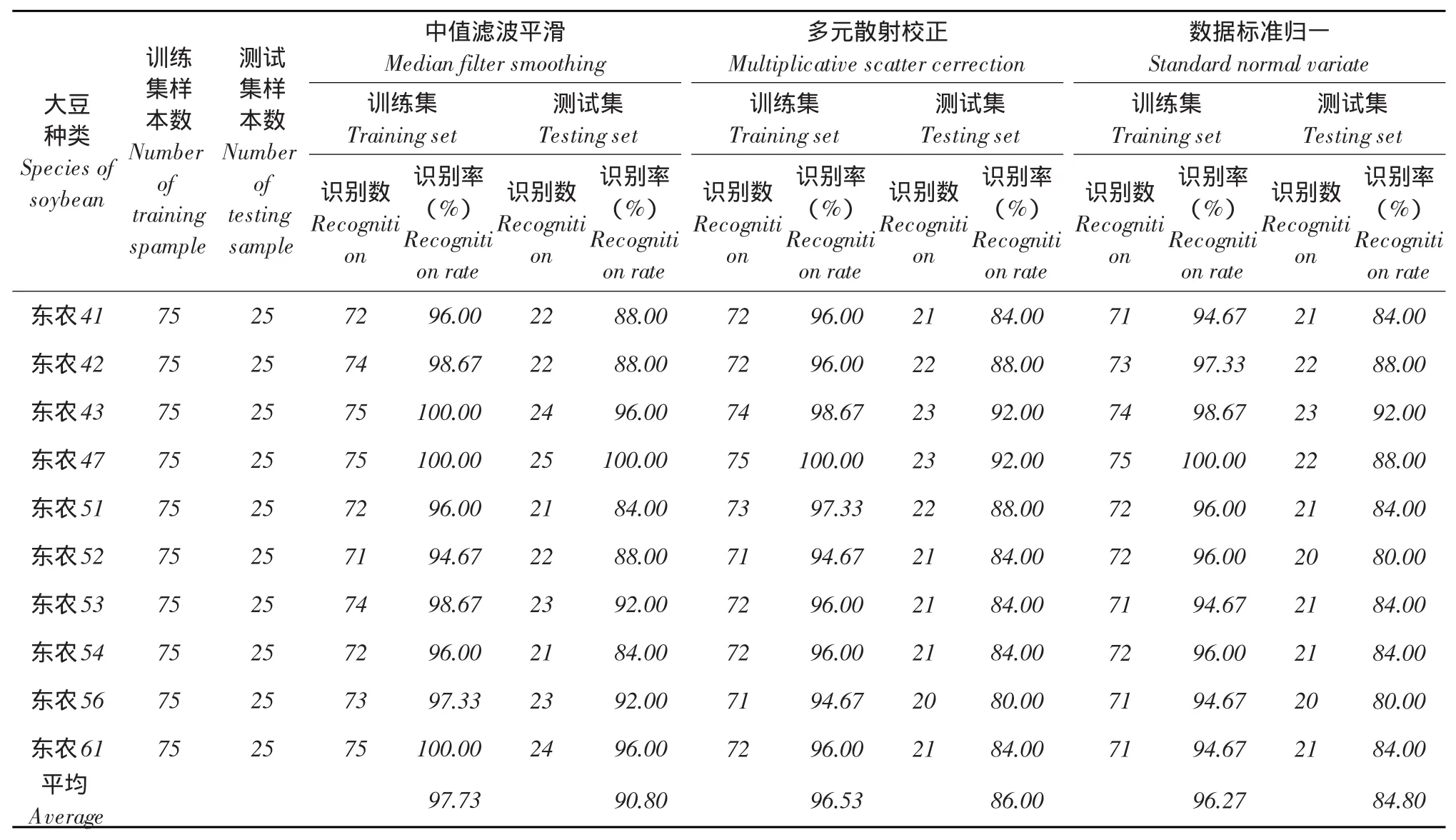
表1 反射光谱均值作模型输入时判别结果Table 1 Discriminant results of average spectral as inputs
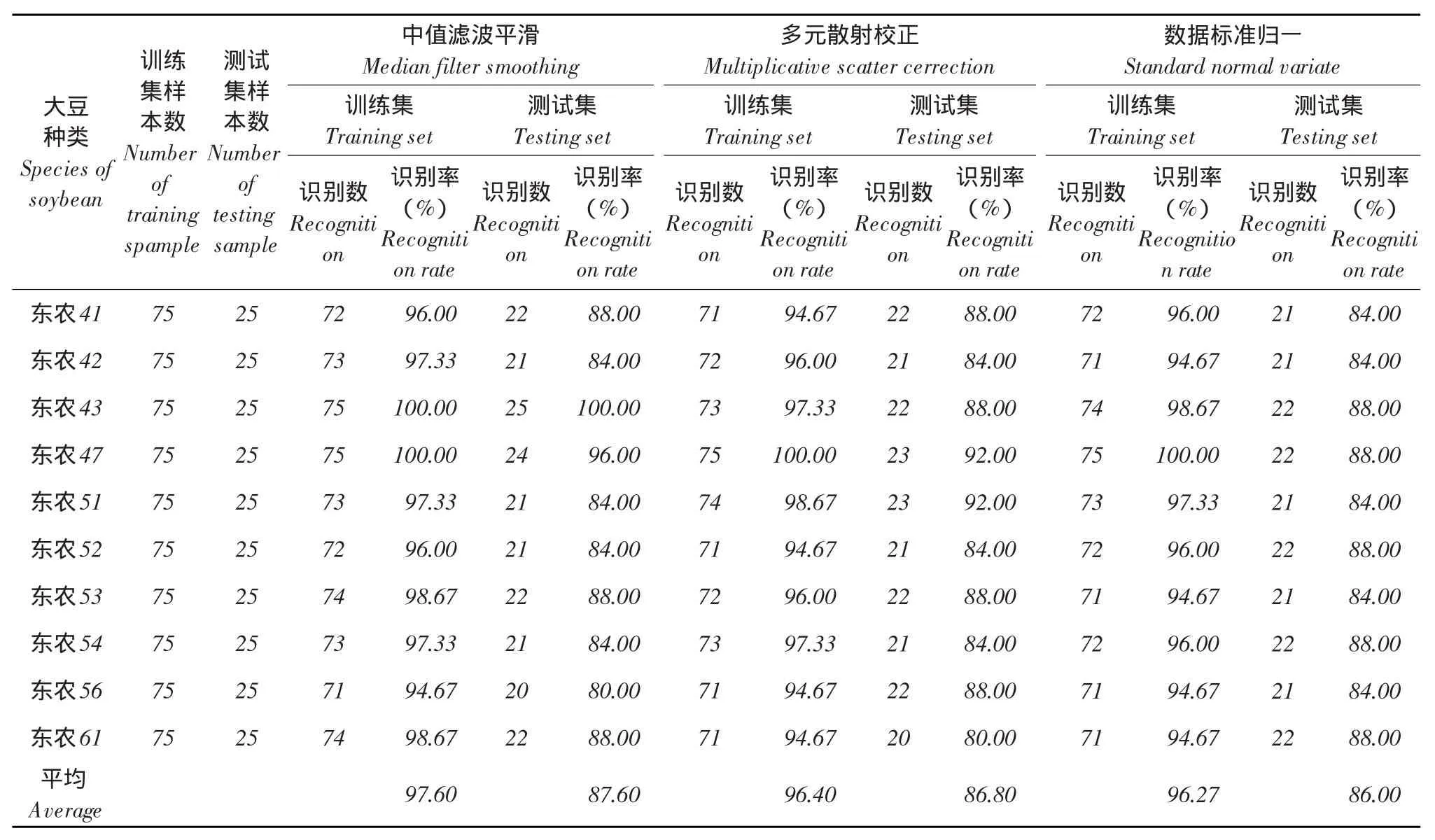
表2 反射光谱标准差值作模型输入时判别结果Table 2 Discriminant results of standard deviation spectral as inputs
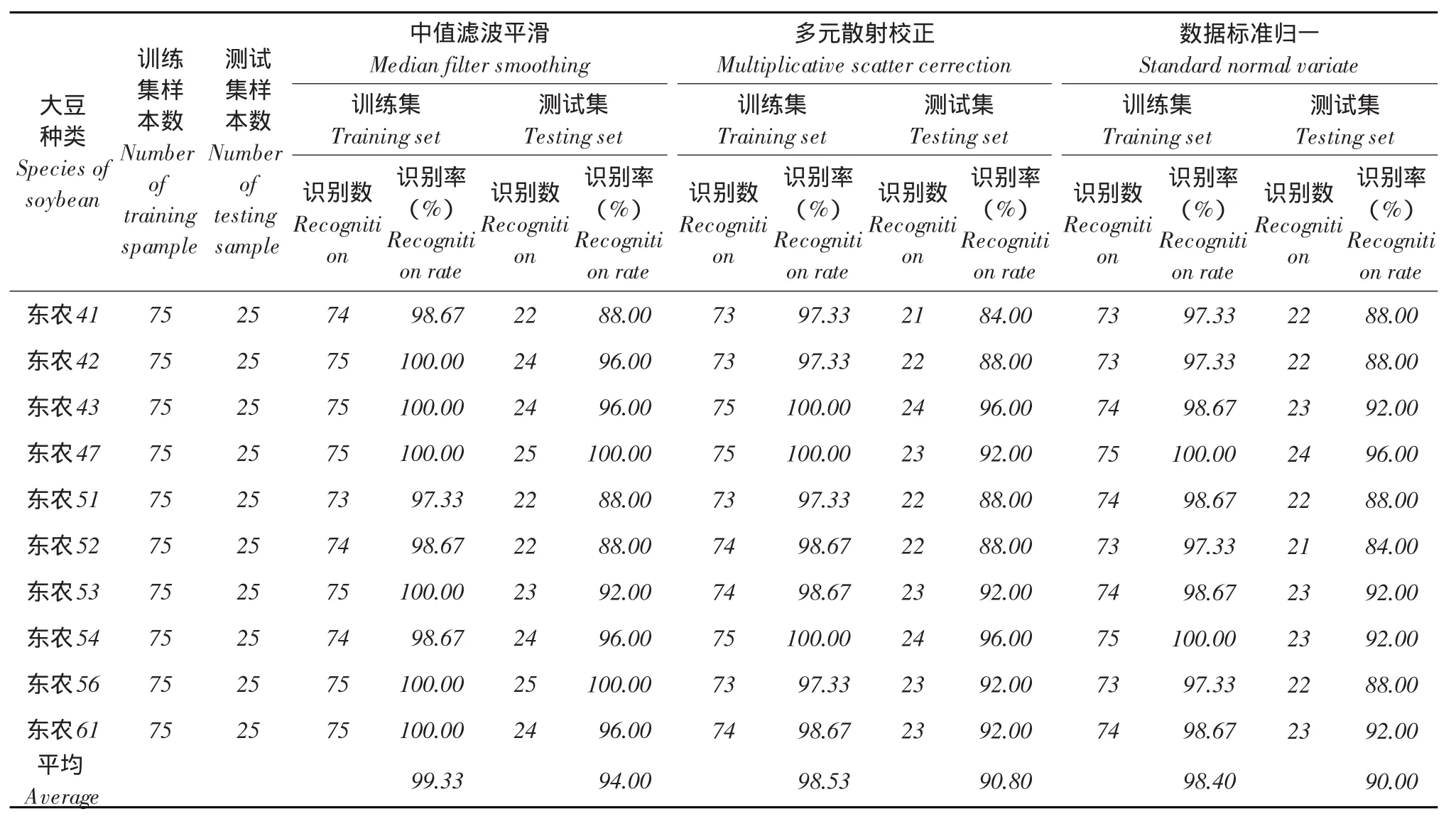
表3 反射光谱均值结合标准差值作模型输入时判别结果Table 3 Discriminant results of average spectral and standard deviation spectral as inputs
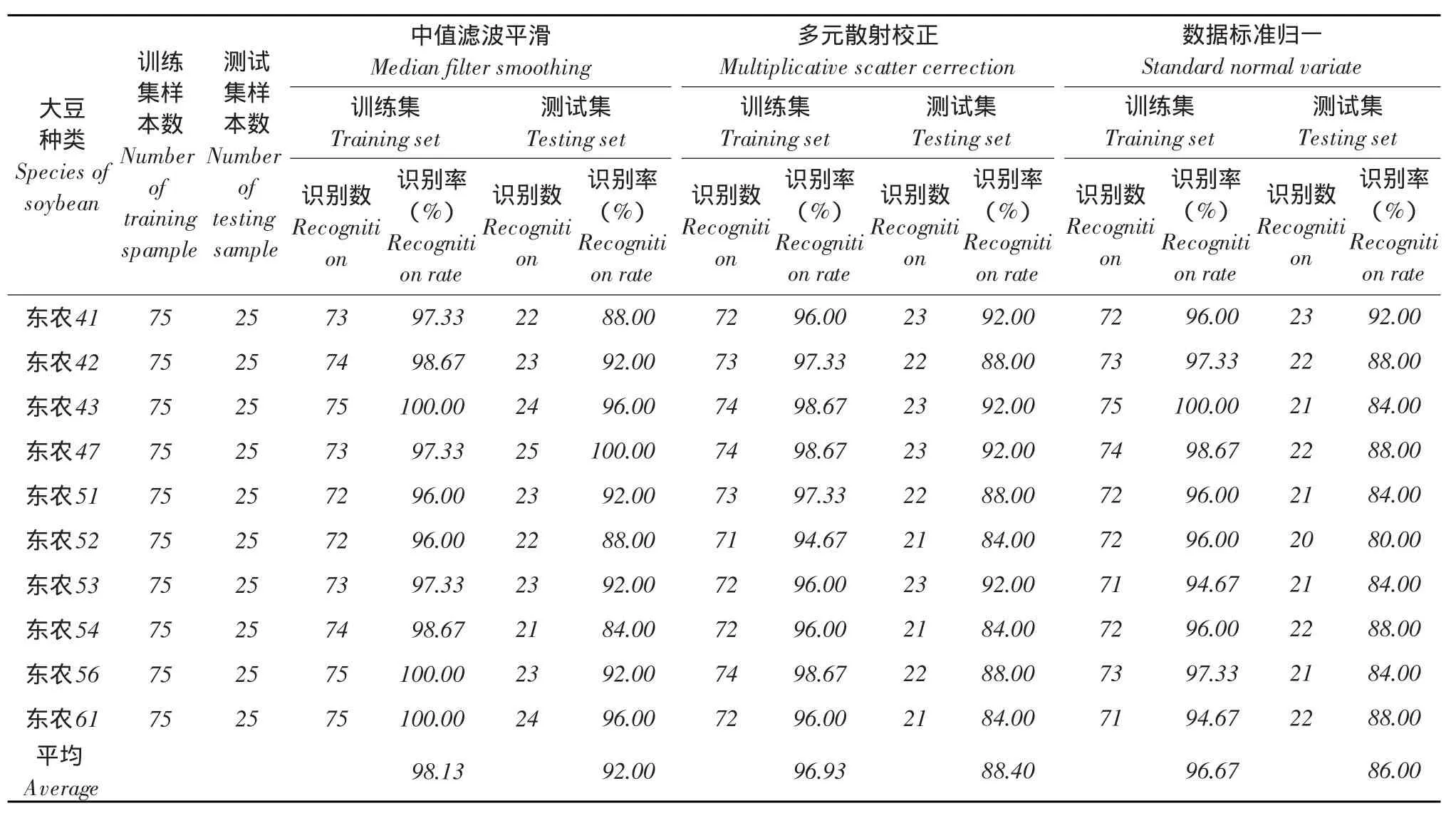
表4 反射光谱均值作模型输入时判别结果Table 4 Discriminant results of average spectral as inputs
同种模型同种数据预处理方法情况下,以光谱平均值作为输入变量要微高于以光谱标准差为输入变量的识别率,两者识别效果较稳定,光谱平均值和标准差输入结合后比单独一方作为输入变量时训练集和测试集识别率均高出2%,达到最高水平,模型鉴别结果最佳。当相同预处理方法获得的同种光谱反射数据作模型输入时,两种模型鉴别效果存在差异,表1、4,表2、5,表3、6相对对比,随机森林组合分类模型的鉴别结果不低于基于T-S模糊神经网络模型,前者鉴别能力高于后者。两种模型对试验样本鉴别能力均较好,性能稳健,操作简易快捷。

表5 反射光谱准差值作模型输入时判别结果Table 5 Discriminant results of standard deviation spectral as inputs

表6 反射光谱均值结合标准差值作模型输入时判别结果Table 6 Discriminant results of average spectral standard deviation spectral as inputs
3 结 论
本试验以高光谱平均值数据和高光谱标准差数据作为模型输入,对比选用三种数据预处理方法,构建两种鉴别模型实现10种大豆种类鉴别,获得良好结果。表明本试验提出预处理方法及鉴别模型适用于大豆品种甄别,较传统鉴别方法更快速、准确。分析对比鉴别结果发现,以经过5×5中值滤波平滑处理后光谱平均值和标准差作为输入变量,结合随机森林思想的组合分类鉴别模型使大豆种类鉴别效果达到最佳,鉴别性能稳定,操作简易快捷。
[参考文献]
[1]程浩,金杭霞,盖钧镒,等.转基因技术与大豆品质改良[J].遗传,2011(5):431-437.
[2]王恩慧.中国大豆消费现状与展望[J].农业展望,2010,6(5):33-36.
[3]冯朝丽,朱启兵,朱晓,等.基于光谱特征的玉米品种高光谱图像识别[J].江南大学学报:自科学版,2012,11(2):149-153.
[4]吴静珠,吴胜男,刘翠玲,等.近红外和高光谱技术用于小麦籽粒蛋白含量预测探索[J].传感器与微系统,2013,32(2):60-62.
[5]张初,刘飞,张海亮,等.近地高光谱成像技术对黑豆产品无损鉴别[J].光谱学与光谱分析,2014,34(3):746-750.
[6]邹伟,方慧,刘飞,等.基于高光谱图像技术的油菜籽品种鉴别方法研究[J].东北农业大学学报,2011,37(2):175-180.
[7]张初,刘飞,孔汶汶,等.利用近红外高光谱图像技术快速鉴别西瓜种子品种[J].农业工程学报,2013,29(20):270-277.
[8]谭克竹,柴玉华,宋伟先,等.基于高光谱图像处理的大豆品种识别[J].农业工程学报,2014,30(5):235-242.
[9]贾仕强,刘哲,李绍明.基于高光谱图像技术的玉米杂交种纯度鉴定方法探究[J].光谱学与光谱分析,2013,33(10):2847-2852.
[10]Tan K Z,Chai Y H,Song W X,et al.Identification of diseases for soybean seeds by computure vision applying Bpneural network[J].IJABE,2014,7(3):43-50.
[11]Barbin D F,ElMasry G,Sun D W,et al.Predicting quality and sensory attributes of pork using near- infrared hyperspectral imaging[J].Anal Chim Acta,2012,719:30-42.
[12]Bauriegel E,Giebel A,Geyer M,et al.Early detection of fusarium infection in wheat using hyper- spectral imaging[J].Computers and Electronics in Agriculture,2011,75(2):304-312.
[13]高海龙,李小昱,徐森淼,等.透射和反射高光谱成像的马铃薯损伤检测比较研究[J].光谱学与光谱分析,2013,12(12):3366-3372.
[14]侯升飞,柴玉华,彭长禄.基于高光谱图像技术的大豆分级识别方法的研究[J].东北农业大学学报,2014,45(4):1-6.
[15]赫敏,麻硕士,郝小冬.基于Zernike矩的马铃薯薯形检测[J].农业工程学报,2010,26(2):347-350.
[16]金苹,朱粉霞,谭晓斌.基于主成分分析的茶叶预防肺癌药效物质研究[J].中药材,2013,36(6):948-952.
[17]张宇,卢文喜,陈杜明,等.基于T-S模糊神经网络的地下水水质评价[J].节水灌溉,2012(7):35-39.
[18]柯喻寅,谢镔,吴卿.基于T-S模糊神经网络的汽车故障诊断的研究[J].杭州电子科技大学学报,2012,4(2):41-45.
[19]过东峰,胡海洲,汪季涛,等.基于随机森林的烤烟香型分类研究[J].中国农学通报,2015,6(6):241-247.
[20]鄢仁武,叶轻舟,周理.基于随机森林的电力电子电路故障诊断技术[J].武汉大学学报,2013,12(6):742-747.
Nondestructive identification of soybean seed varieties based on hyperspectral image technology
CHAI Yuhua,BI Wenjia,TAN Kezhu,ZHANG Chun lei,LIU Chuntao(School of Electrical and Information,Northeast Agricultural University,Northeast Agricultural University,Harbin 150030,China)
Abstract:In order to improve the efficiency and accuracy of identification,hyperspectral image technology was employed to determine the varieties of soybean seed.In this study,10 soybean seed varieties with 1 000 grains were selected as inspection samples.Hyperspectral reflectance data of soybean samples were collected in spectral region of wave length of 400.92-999.53 nm,followed by the image denoised by median smoothing,correction of multiplicative scatter and normalization to extract the regions of interesting average spectral curves and standard deviation curves.Scores of average spectral data from PCs,scores of standard deviation spectral data from PCs and both of them together were used as inputs respectively.The combined classification model was developed based on T-S fuzzy neural network or random forest classifier.Taken the combination of median smoothed average and standard deviation as inputs,the random forest model presented the highest identification with 99.6% in training and 97.6% in testing.Hyperspectral image technology is feasible for nondestructive identification of soybean seed varieties.
Key words:soybean seed; hyperspectral image; variety identification; T-S fuzzy neural network;
作者简介:柴玉华(1965-2015),女,教授,博士生导师,研究方向为模式识别与智能控制。E-mail:yhchai@163.com
基金项目:国家自然科学基金(31271911);黑龙江省自然科学基金(ZD201303)
收稿日期:2015-08-04
中图分类号:TP391.4
文献标志码:A
文章编号:1005-9369(2016)03-0086-08
