Wikipedia跨语言链接发现中的锚文本译项选择
2016-05-04郑剑夕张桂平
郑剑夕,白 宇,郭 程,张桂平
(沈阳航空航天大学 知识工程研究中心,辽宁,沈阳 110136)
Wikipedia跨语言链接发现中的锚文本译项选择
郑剑夕,白 宇,郭 程,张桂平
(沈阳航空航天大学 知识工程研究中心,辽宁,沈阳 110136)
Wikipedia跨语言链接发现主要研究从源语言Wikipedia文章中自动识别与主题相关的锚文本,并为锚文本推荐一组相关的目标语言链接。该研究涉及三个关键问题: 锚文本识别、锚文本翻译和目标链接发现。在锚文本翻译中,一个锚文本可能存在多个目标译项,如果其译项选择有误,将会直接影响目标链接发现中的链接推荐的准确性。为此,该文提出了一种基于上下文的锚文本译项选择方法,使用基于逐点互信息投票的方式确定锚文本的译项。 对中英文Wikipedia中的人名、术语以及缩略语的译项选择进行测试,实验表明该方法取得了较好的效果。
Wikipedia;跨语言链接发现;锚文本;译项选择;逐点互信息
1 引言
Wikipedia作为一个以开放和用户协作编辑为特点的Web 2.0知识库系统[1],具有丰富的语义信息,特别是锚文本及其链接关系对,使得用户可以通过链接进一步获取知识。事实上,不同语言描述的wiki词条之间存在着互补的关系,为了全面了解词条内容,用户往往需要通过跨语言的方式获取知识。然而目前这种关系对一般只存在于单语言的Wikipedia文章中,同时,跨语言链接也仅存在于为数不多的文章标题之间。因此,一种面向Wikipedia跨语言链接需求的跨语言链接发现技术(Cross-Lingual Link Discovery, CLLD)被提出[2],它旨在从源语言Wikipedia文章中识别与主题相关的锚文本(anchor text),并为锚文本推荐一组相关的目标语言链接。图1与图2分别展示了Wikipedia中的单语言链接和跨语言链接。
跨语言链接发现技术涉及三个关键问题: 锚文本识别、锚文本翻译和目标链接发现。其基本流程如图3所示。
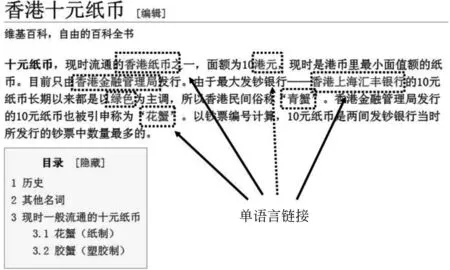
图1 Wikipedia中的单语言链接

图2 Wikipedia跨语言链接发现[3]

图3 Wikipedia跨语言链接发现基本流程
在锚文本翻译过程中, 一个锚文本可能存在多个目标译项,如果其译项选择有误,将会直接影响目标链接发现中的链接推荐的准确性,进而影响跨语言链接发现系统的整体性能。以“自然语言处理”的缩写形式“NLP”为例,其可能的候选译项有 “Natural Language Processing”“Neuro-linguistic Programming”“Non-linear Programming”等,并且它们在Wikipedia中都有对应的链接,此时,跨语言链接发现就存在着锚文本译项的选择问题。此类问题在缩略语、人名和专业术语中较为普遍。
在现有锚文本翻译的相关研究[3-8]中,普遍采用的方法是先通过利用翻译资源(如Wikipedia已有的跨语言链接,双语词典以及在线翻译引擎等)来构建一部面向锚文本翻译的双语词典,然后通过查找双语词典的方法获取锚文本的翻译。该方法是为锚文本找到最频繁使用的译项,但是它忽视了锚文本的上下文信息。
本文提出了一种面向Wikipedia跨语言链接发现的锚文本译项选择方法,与以往方法不同,该方法考虑了上下文信息,并使用逐点互信息对锚文本的候选译项进行投票,然后按照票数的大小确定锚文本的译项。本文组织结构如下: 第二节回顾了现有的研究工作;第三节详细描述了本文方法;在第四节给出了实验的结果和分析;最后在第五节对本文工作进行总结。
2 相关工作
在Wikipedia跨语言链接发现研究中,已有的锚文本翻译方法按照译项消歧的资源不同分为基于词典的方法[4-8]和基于Web统计的方法[9-11]。
Kang[4]在英韩跨语言链接发现研究中提出了使用英韩双语词典对锚文本进行翻译的方法,该方法的缺点在于构建双语词典的过程费时费力,且词典覆盖度较低。Tang[5]和Liu[6]分别利用Wikipedia中已有的跨语言链接关系与Wikipedia的正文内容中抽取已有的翻译对,对锚文本进行翻译。该方法能够自动获取Wikipedia的双语等价网页的标题,其优点在于翻译准确率较高,但是由于其规模十分有限,不足以满足跨语言链接发现过程中对锚文本翻译的需求。Gao[7]等人利用在线翻译引擎对锚文本进行翻译,然而,其翻译结果的优劣依赖于在线翻译引擎的性能。此外,Kim[8]对上述方法进行组合,提出了一种层级翻译方法。赵军[9]总结了利用Web对命名实体进行翻译的方法。郭稷[10]等人首先使用统计判别模型并融合多种识别特征从Web中获取了命名实体、新词以及术语等双语翻译对,然后使用搜索引擎对翻译对进行了验证。Tang[11]提出了一种命名实体的翻译方法,其基本思想是根据Web中的统计信息来确定锚文本的译项。该方法从基于多种翻译资源获得的全部翻译结果中选择出现频率最高的翻译结果作为最终的译项。
3 方法描述
3.1 系统框架
本文的系统框架主要包括五个模块: 上下文抽取模块、翻译获取模块、信息统计模块,关联度计算模块以及决策消歧模块。给定一个测试集,首先,在上下文抽取模块中获取锚文本的上下文词集合;同时,在翻译获取模块中利用在线翻译引擎获得锚文本的全部候选译项;然后,在信息统计模块中,统计Wikipedia中的共现信息。在关联度计算模块中,使用PMI方法衡量锚文本的上下文词通过该锚文本与其所有的候选译项的关联度;最后在决策消歧模块中使用VOTE算法确定锚文本的最终译项。该系统框架如图4所示。
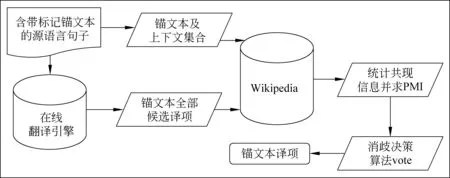
图4 系统框架
3.2 基于上下文的译项选择
本文采用了一种基于上下文的译项选择方法,该方法的基本思想是使用基于逐点互信息投票的方式确定锚文本的译项。PMI是指已知两个离散变量的分布,求这两个变量联合分布的方法[12]。因为对一个在特定上下文环境下的锚文本而言,它只有一个正确的译项,所以锚文本的译项选择依赖于其上下文环境。这种依赖程度可以利用上下文词与该译项的相关度进行投票的方式来度量,但是由于上下文词与锚文本译项组成的双语词对存在的语言空间问题,故本文选择在含锚文本的Wikipedia混合语言文档中计算该双语词对的相关度。锚文本的上下文与译项共现的Wikipedia文档数越多,意味着上下文词与译项之间存在较强的关联关系的概率就越大,则该译项作为锚文本的翻译的可能性也越大。本文采用PMI公式度量上下文与译项的关联程度,它由式(1)表示。
(1)

然后,本文利用锚文本的每一个上下文词与译项之间的关联程度对译项的选择进行投票,每次投票的权重为1,投票算法vote由公式(2)表示。

(2)
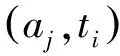
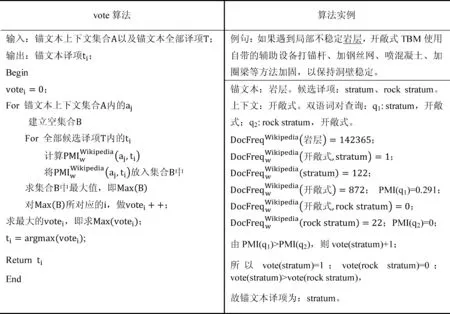
图5 vote算法及其实例
4 实验及结果分析
4.1 实验语料及评价指标
本文在统计Wikipedia中的共现信息时,使用了NTCIR-10提供的中英文Wikipedia文档集[13],该文档集的详细信息如表1所示。实验的测试集包含人名、术语和缩略语三类锚文本(如表2所示)以及含该锚文本的例句。
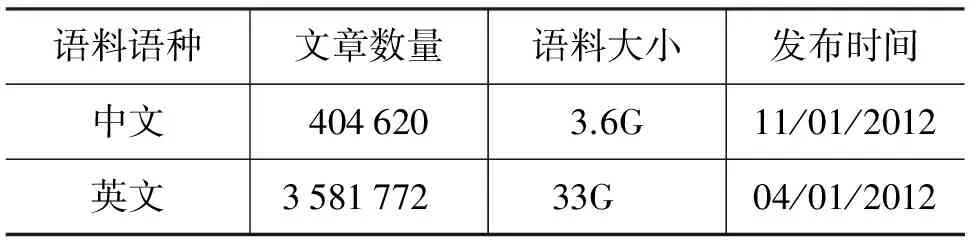
表1 NTCIR-10中英文Wikipedia文档集
本文使用SemEval 2007中的Multilingual Chinese-English Lexical Sample Task评测任务提供的标准评测工具进行评测。该评测工具包含两种评价指标Pmir和Pmar(MicroAverageAccuracy和MacroAverageAccuracy)[14],如式(3)~(4)所示。
(3)
(4)
其中N为所有的目标词数,mi是对每一个特定的词所标注正确的例句数,ni是对该特定词的所有测试例句数。上述两者指标的不同之处在于:Pmir是每一个测试例句的性能指标的算数平均值,Pmar是每一个类别的性能指标的算数平均值。

表2 中英文Wikipedia锚文本

表3 中文Wikipedia实验结果对比
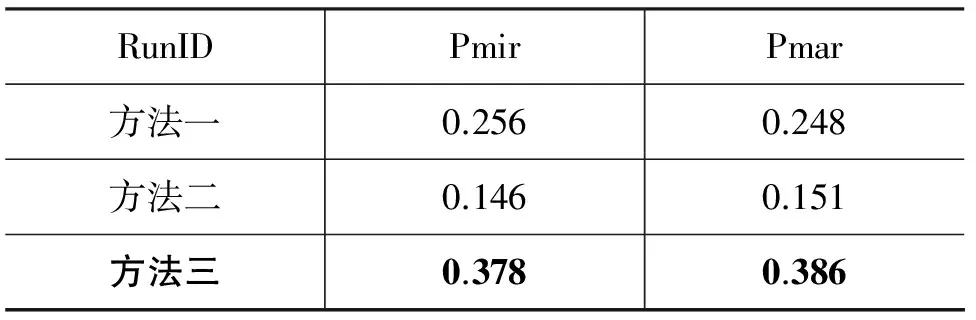
表4 英文Wikipedia实验结果对比
4.2 实验结果及分析
实验分别采用了三种方法在中英文Wikipedia测试集上进行对比分析。本文采用文献[15]提出的基于双语词汇Web间接关联度的最优方法做为对比方法一。方法一将搜索引擎返回的页面总数(Page Counts)作为间接共现信息,但该信息通常为估计值,不够精确。因此,本文利用搜索引擎返回的首页摘要片段总数(Snippet Counts)替代页面总数的改进方法作为对比方法二。另外,为避免数据稀疏问题,该方法采用了加1平滑。方法三采用第三节提出的方法。表3和表4分别展示了中文和英文Wikipedia对比实验结果。
由表3~4中可见,方法三的效果高于方法一和方法二。这表明与其他两种方法相比,本文提出的方法在锚文本译项选择问题上更加有效。进一步分析得出,方法一和方法二使用搜索引擎作为统计共现信息的资源,由于搜索引擎是一个通用领域的Web知识检索系统,在对Wikipedia的三类锚文本(人名、术语及缩略语)上下文与其目标译项的共现信息的覆盖度较低,所以导致两者的效果不如方法三。此外,在中文测试集上方法二的效果高于方法一,然而在英文测试集上结果却相反,原因可能在于中文搜索引擎中的英文摘要片段的质量不佳,导致共现信息的价值不高。
为了观察三种方法对不同类别的锚文本的译项选择效果,本文还计算了每个类别锚文本的Pmar值(Pmir的表现与Pmar类似,故本文只考虑了Pmar的情况),实验结果分别如图6和图7所示。
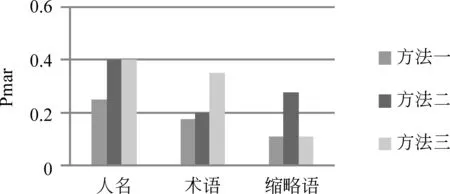
图6 中文Wikipedia中不同类型锚文本的实验结果

图7 英文Wikipedia中不同类型锚文本的实验结果
由图6可见,在中文Wikipedia中,方法三和方法二在人名方面的测试效果均达到了40%,两者均比方法一提高了15%,说明方法三和方法二在人名的译项选择上有效;在术语方面的测试结果中,方法三达到了35%,分别比方法二和方法一提高了15%和17.5%,这说明了Wikipedia对术语信息的覆盖度较高;在缩略语方面的测试结果中,方法二的效果为27.8%,明显高于方法一和方法三的11.1%,说明Wikipedia文档集对中文缩略语信息的覆盖度较低,导致效果有限。实验表明,在中文Wikipedia中,方法三适合人名和术语的译项选择任务,方法二适合人名和缩略语的译项选择任务。
由图7可见,在英文Wikipedia中,方法三在人名的测试效果达到了27.3%,它比方法二下降了4.5%,与方法一相比提高了4.6%,主要原因在于该Wikipedia文档集对英文人名信息的覆盖度有限;在术语方面的测试结果中,方法三的效果达到了47.5%,分别比方法一和方法二提高了12.5%和40%,说明术语在Wikipedia中的共现信息价值大,方法三充分利用了该信息,从而效果明显提升;在缩略语方面的实验结果中,方法三为31%,分别比方法一和方法二提高了3.6%和20.3%,说明方法三在缩略语的译项选择方面更有效,而方法二效果不理想。实验表明,在英文Wikipedia中,方法三适合术语和缩略语的译项选择任务,方法二适合人名的译项选择任务。
5 结论
本文提出了一种面向Wikipedia跨语言链接发现的锚文本译项选择方法。该方法考虑了上下文信息,并使用逐点互信息对锚文本的候选译项进行投票,然后按照票数的大小确定锚文本的译项。实验结果表明: 该方法在整体性能上与方法一、二相比有明显的提升。其中,该方法在术语方面效果最佳;在人名方面,中文效果较好,英文效果还需提升;在缩略语方面,英文效果较好,中文效果有限。由于该方法依赖于Wikipedia文档集的规模、质量和类别,因此存在一定的局限性。另外,从中文Wikipedia中缩略语类型锚文本的实验结果和英文Wikipedia中人名类型锚文本的实验结果可以看出,方法二和方法三在锚文本的译项选择上各有优势。因此,下一步工作将考虑对现有方法进行融合。
[1] 涂新辉,张红春,周琨峰,等. 中文维基百科的结构化信息抽取及词语相关度计算方法[J].中文信息学报,2012,26(3): 109-115.
[2]HuangWC,TrotmanA,GevaS.AVirtualEvaluationTrackforCrossLanguageLinkDiscovery[A].InSIGIR’09.Boston,USA, 2009: 1-7.
[3]TangLX,TrotmanA,GevaS,etal.Cross-LingualKnowledgeDiscovery:Chinese-to-EnglishArticleLinkinginWikipedia[J].InformationRetrievalTechnology.SpringerBerlinHeidelberg, 2012: 286-295.
[4]KangIS,MarigomenR.English-to-KoreanCross-linkingofWikipediaArticlesatKSLP[C]//ProceedingsofNTCIR-9,Tokyo,Japan, 2011: 481-483.
[5]TangLX,CavanaghD,TrotmanA.AutomatedCross-lingualLinkDiscoveryinWikipedia[C]//ProceedingsofNTCIR-9,Tokyo,Japan, 2011: 512-529.
[6]LiuMF,KangL,YangS,etal.WUSTEN-CSCrosslinkSystematNTCIR-9CLLDTask[C]//ProceedingsofNTCIR-9,Tokyo,Japan, 2011: 508-511.
[7]GaoYF,XuHJ,ZhangJS,etal.Multi-filteringMethodBasedCross-lingualLinkDiscovery[C]//ProceedingsofNTCIR-9,Tokyo,Japan, 2011: 520-523.
[8]KimJ,GurevychI.UKPatCrossLink:AnchorTextTranslationforCross-lingualLinkDiscovery[C]//ProceedingsofNTCIR-9,Tokyo,Japan, 2011: 487-494.
[9] 赵军. 命名实体识别、排歧和跨语言关联[J]. 中文信息学报,2009,23(2): 3-17.
[10] 郭稷,吕雅娟,刘群. 一种有效的基于Web的双语翻译对获取方法[J]. 中文信息学报,2008,22(6): 103-109.
[11]TangLX.LinkDiscoveryforChinese/EnglishCross-LanguageWebInformationRetrieval[D].QueenslandUniversityofTechnology, 2012.
[12] 朱亚东,张成,俞晓明,等. 基于逐点互信息的查询结构分析[J]. 中文信息学报,2012,26 (5): 33-39.
[13]TangLX,KangIS,KimuraF,etal.OverviewoftheNTCIR-10Cross-LingualLinkDiscoveryTask[C]//ProceedingsofNTCIR-10,Tokyo,Japan, 2013: 1-36.
[14]JinP,WuYF,YuS.SemEval-2007Task5:MultilingualChinese-EnglishLexicalSample[C]//ProceedingsofSemEval-2007Prague, 2007: 19-23.
[15] 刘鹏远,赵铁军. 基于双语词汇Web间接关联的无指导译文消歧[J]. 软件学报, 2010, 21 (4): 575-585.
The Translation Selection of Anchor Text in Wikipedia Cross-Lingual Link Discovery
ZHENG Jianxi, BAI Yu, GUO Cheng, ZHANG Guiping
(Research Center for Knowledge Engineering, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
The research on Wikipedia Cross-Lingual Link Discovery (CLLD) is to automatically identify an anchor text related to topic from source language Wikipedia articles, and recommend a set of relevant target language links to the anchor text. It involves three key problems: anchor text identification, anchor text translation, and target link discovery. To deal with the multiple target translations of an anchor text, we propose a context-based translation selection method, which uses a vote method based on pointwise mutual information (PMI). Experiments on the translation selection of person names, terminology and abbreviation in Chinese and English Wikipedia articles, the results show that the method achieves good performances.
Wikipedia; CLLD; anchor text; translation selection; PMI

郑剑夕(1988—),博士研究生,主要研究领域为自然语言处理,信息检索。E⁃mail:zhengjxkercir@163.com白宇(1982—),通信作者,博士研究生,讲师,主要研究领域为信息检索。E⁃mail:baiyu@sau.edu.cn郭程(1987—),硕士研究生,主要研究领域为信息检索。E⁃mail:guocheng1987@163.com
1003-0077(2016)02-0196-06
2013-09-20 定稿日期: 2014-04-15
国家科技支撑计划资助项目(2012BAH14F00);国家973计划资助项目(2010CB530401)
TP391
A
