一种基于模型的云计算容错机制开发方法
2016-04-28武义涵熊英飞
武义涵 黄 罡 张 颖 熊英飞
1(高可信软件技术教育部重点实验室(北京大学) 北京 100871)
2(北京大学信息科学技术学院 北京 100871)
3 (国家计算机网络应急技术处理协调中心 北京 100029)
(wuyihan@pku.edu.cn)
一种基于模型的云计算容错机制开发方法
武义涵1,2,3黄罡1,2张颖1,2熊英飞1,2
1(高可信软件技术教育部重点实验室(北京大学)北京100871)
2(北京大学信息科学技术学院北京100871)
3(国家计算机网络应急技术处理协调中心北京100029)
(wuyihan@pku.edu.cn)
A Model-Based Fault Tolerance Mechanism Development Approach for Cloud Computing
Wu Yihan1,2,3, Huang Gang1,2, Zhang Ying1,2, and Xiong Yingfei1,2
1(KeyLaboratoryofHighConfidenceSoftwareTechnologies(PekingUniversity),MinistryofEducation,Beijing100871)2(SchoolofElectronicsEngineering&ComputerScience,PekingUniversity,Beijing100871)3(NationalComputerNetworkEmergencyResponseTechnicalTeamCoordinationCenterofChina,Beijing100029)
AbstractThere are many different kinds of cloud computing platforms, such as CloudStack, OpenStack, Eucalyptus, and so on, which differentiate from each other in management abilities and management styles. Even in a particular cloud platform, there are also different kinds of virtualization technologies, such as Xen, KVM, VMware, etc. Recent years, with the rapid development of private cloud and hybrid cloud, the heterogeneity degree of infrastructure is aggravated. Fault tolerance (FT) mechanisms are usually supported by the management ability and management style of the infrastructure. As a result, a fault-tolerant mechanism needs to be repeatedly implemented on different platforms. Meanwhile, this directly causes the obvious growing difficulty and increasing amount of time consumption in FT mechanism. In order to reach the goal of achieving FT mechanism among different platforms, we propose a model-based, cross-platform FT mechanism development approach in this paper. To validate the effectiveness and practicability of model-based development approach, we implemente seven fault tolerance mechanisms in CloudStack and OpenStack. A series of experiments show that failover is implemented effectively by these FT mechanisms, and the reliability and availability of the FT target are improved. With high reusability (over 90%) of the code, the FT mechanisms in this thesis can function cross different platforms. Analysis of the questionnaire survey conducted among developers show that our approach can improve the development experience and development efficiency.
Key wordscloud computing; fault tolerance(FT) mechanism; runtime model; self-adaptive; dependability
摘要目前商业云平台和开源云平台种类繁多,如CloudStack,OpenStack,Eucalyptus等,这些云平台提供的管理能力和管理方式存在较大差异,即使在同一个云平台中也存在多种虚拟化方式,如Xen,KVM,VMware等.近年来,随着私有云和混合云的迅速发展,基础设施的异构程度加剧.由于容错机制往往依赖于基础设施的管理能力和管理方式,因此容错机制实例在不同的目标平台上需要分别实现,导致容错机制的开发难度和开发时间显著增加.针对这一问题,提出了一种基于模型的容错机制开发方法,实现容错机制的跨平台性.为了验证容错机制开发方法的有效性和实用性,实现了7种常见的容错机制实例,并在CloudStack和OpenStack开源云平台上进行验证.实验表明,这些容错机制能够有效地实现故障转移,提升容错对象可靠性、可用性等指标;提出的容错机制开发方法能够实现跨平台,并达到90%以上的代码复用率;对云平台管理员以及容错机制开发者的问卷调查结果表明,该方法能够较好地提升容错机制的开发体验和开发效率.
关键词云计算;容错机制;运行时模型;自适应;可信性
在云平台中,用户可以便捷地从资源池中申请和释放计算、存储、网络等形式的资源,这使资源管理和使用成本大大降低.随着云平台的普及和其规模的扩大,其可靠性所面临的挑战也越来越严峻.一方面,云平台中故障频繁发生.亚马逊AWS从2006年上线后共发生过43次故障,仅在2010年就发生过13次故障.另一方面,云平台故障的潜在影响巨大.截至2014年底,在亚马逊AWS上的活跃客户数突破百万,如果云平台发生故障,可能会影响到这些服务的正常运行,从而波及各个服务上成千上万的用户.而容错技术可保证在云平台发生故障时,使系统持续提供有效服务,提升系统的可靠性.
研究表明,容错(fault tolerance, FT)技术是防止系统失效的有效手段[1],并已在航空航天、医疗、银行等领域的系统实践中得到广泛应用.在航空领域,双引擎是最常用的容错方法.当主引擎发生故障,可以通过引擎切换达到恢复或降额发动机所需性能的要求,保证飞行安全.波音777-200是目前全球最大的双引擎客机,在1995—2014年的20年里,1 000多架飞机未发生过致命事故.在银行数据系统中,为了保证数据的可靠性,系统会将主服务器的数据实时拷贝至备份服务器,建立主服务器的副本,一旦主服务器停机,备份服务器可以继续主服务器上的业务.在这种单机或局域网环境下,上层软件独占底层基础设施,系统环境确定.因此,只需针对明确且基本不变的容错需求实现该运行环境特定的若干容错机制实例.
云环境与单机(或局域网)环境的最大区别在于云平台基础设施共享而单机环境基础设施独占.图1描述了云平台的应用层和系统层各自的特点.应用层部署的应用种类多、数量大且容错需求各异;系统层具有异构的云平台管理能力及虚拟化管理方式.
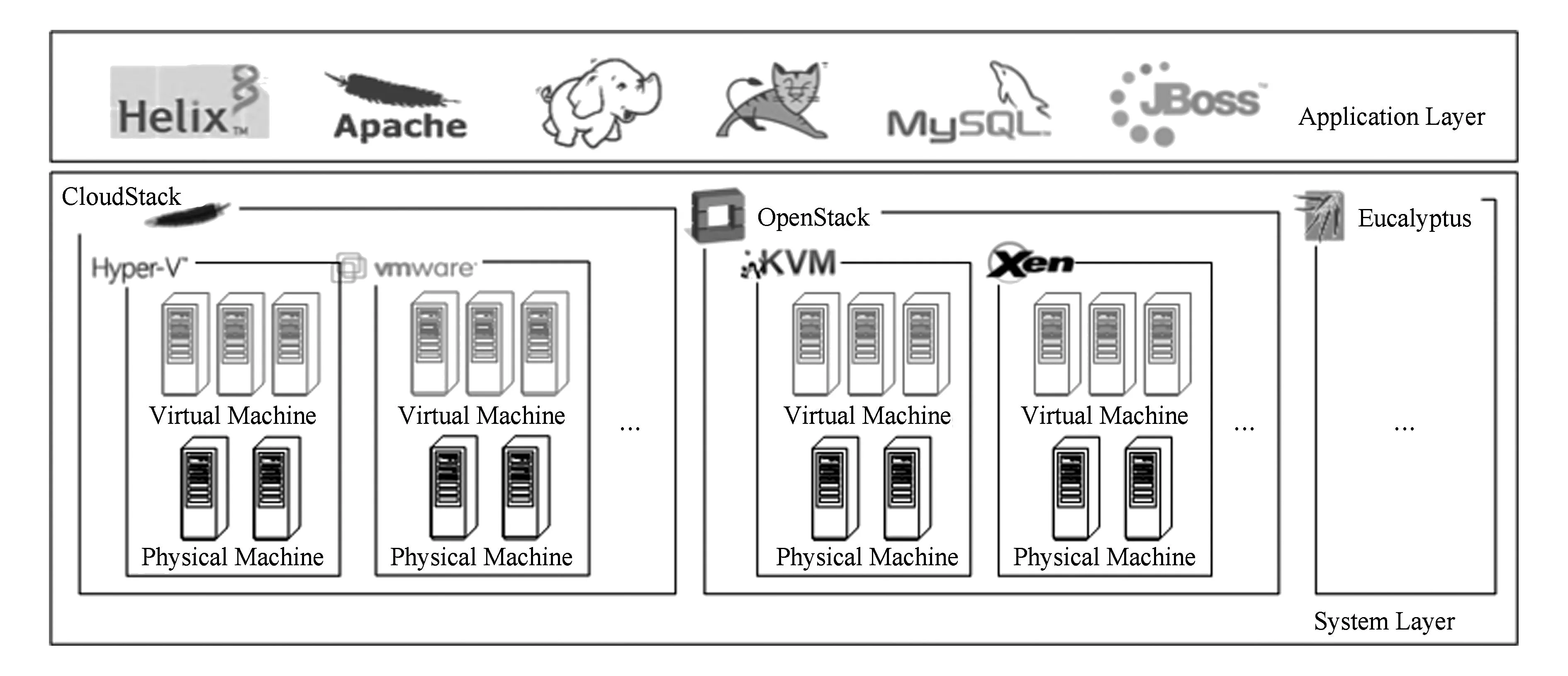
Fig. 1 Application layer and system layer in cloud platform.图1 云平台应用层与系统层
基于应用层与系统层的特点,云计算容错机制(FT mechanism)面临2方面的挑战:
1) 容错机制的容错逻辑实现难度和工作量大,而云环境下容错机制实例的大规模性加剧了容错机制开发的工作量.容错的最终目标是保证服务的可用性,所以需要结合具体的应用实现具有针对性的容错机制.而云平台中应用数量巨大,因此云容错机制实例具有大规模性.容错机制的开发往往依赖于开发者经验,开发难度高且工作量大,因此亟需一种高效的容错机制开发方法.
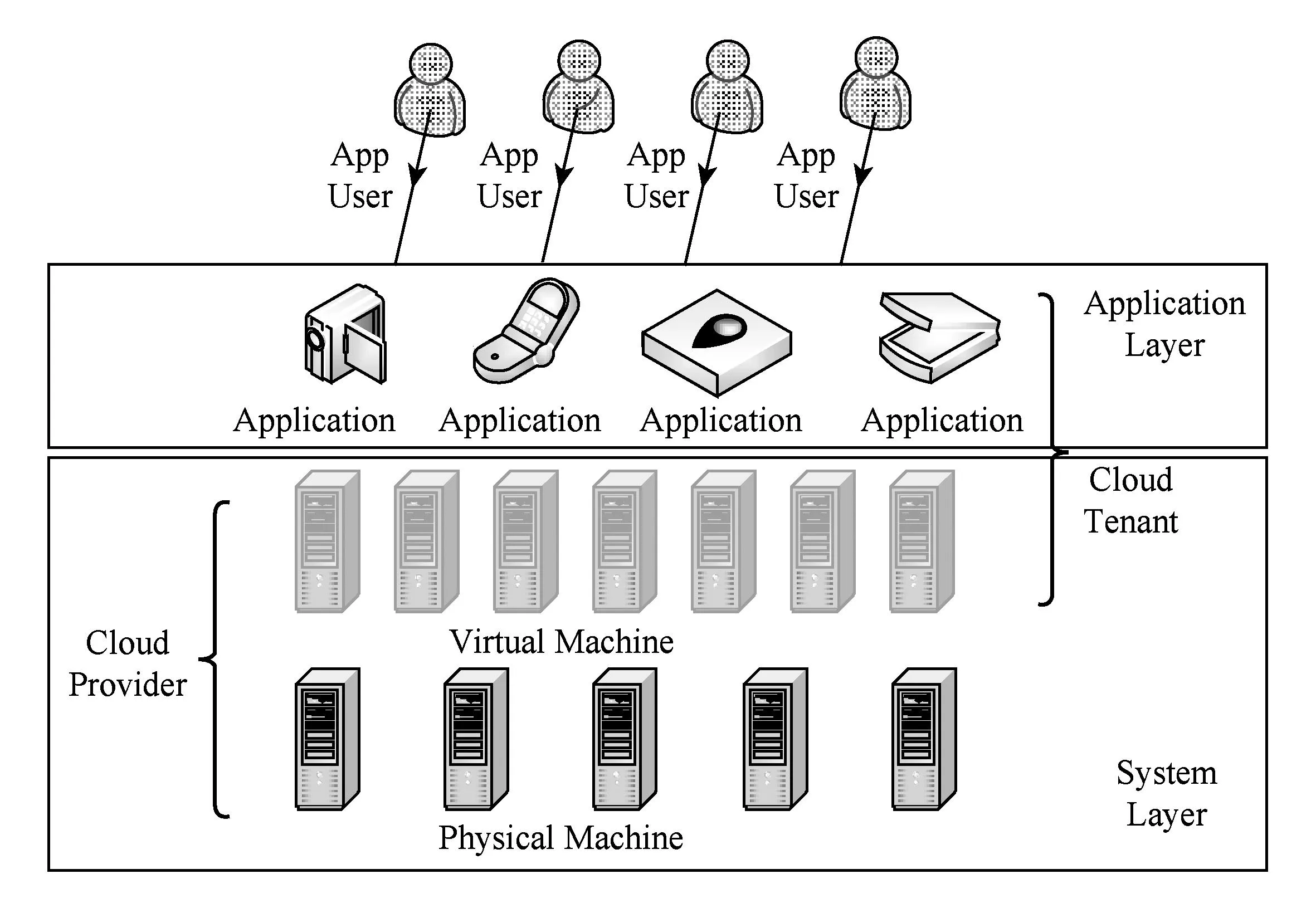
Fig. 2 Cloud platform participators.图2 云平台参与者
此外,云平台难以感知或预测上层部署的服务或应用,如图2所示,在云平台3种角色中,云平台提供者仅能管理物理机以及虚拟机所在的系统层.所以,目前的云平台更多是从资源和环境等系统层面提供少量通用的容错机制.例如,VMware提供的VMware-HA和VMware-FT两个机制仅针对物理机故障进行容错,以保证虚拟机的持续可用,缺少应用层容错支持.2) 云平台基础设施的异构性导致一个容错机制实例需要多次开发.目前云平台种类繁多,例如OpenStack[2],CloudStack[3],Eucalyptus[4]等,提供的管理能力和管理方式各异.即使在同一个云平台中也存在多种虚拟化技术,例如Xen,KVM,VMware等.容错机制的实现往往依赖于系统层提供的管理能力和管理方式,所以同一个容错机制实例需要开发不同的版本适应异构的云平台及虚拟化技术.例如虚拟机优先迁移机制,在CloudStack和OpenStack中需要调用不同的管理接口实现虚拟机迁移;而Eucalyptus未提供虚拟机迁移接口,需要分别调用虚拟化管理程序Xen和KVM提供的管理接口实现该容错机制.近年来,随着私有云及混合云的迅速发展,基础设施的异构化程度加剧,导致容错机制面临的异构性挑战更严峻.出于安全考虑,企业更愿意将数据存放在私有云中,但是同时又希望可以获得公有云的计算资源,在这种情况下混合云被越来越多地采用,它将公有云和私有云进行混合和匹配,以获得最佳的效果.由于容错机制往往依赖于基础设施的管理能力和管理方式,因此容错机制实例在不同的目标平台上需要分别实现,导致容错机制的开发难度、开发时间等成本显著增加.
在传统的自修复或容错系统中,容错机制被实现为该系统专用的容错库,系统被描述为一个自适应回路,容错机制在该回路中被调用.其中,容错机制的开发依赖于容错机制开发者的经验,开发成本高,且这种方式实现的容错机制难以实现跨平台性.针对云计算中容错机制面临的2方面挑战,本文提出了一种基于模型的容错机制开发方法,提升开发效率及开发体验,实现容错机制的异构基础设施适配能力.
为提升容错机制的开发效率及开发体验,本文提出了一种基于模型处理语言(QVT)的容错逻辑实现方式.容错机制开发的主要工作量在于如何获取被容错对象的运行时信息以及如何实现容错逻辑.本文分别通过以下方式减少这2部分的工作量及开发难度:1)本文将众多容错机制所需的运行时信息提取为一个集合,将其描述为一个运行时模型,减少实现容错机制运行时信息获取的工作量.运行时模型与运行时系统具有同步关系,能够及时获取系统运行时信息,详见1.2节.2)容错逻辑描述了对容错对象的错误检测逻辑、错误处理逻辑和故障处理逻辑,是容错机制的主要业务逻辑.本文使用QVT(QueryViewTransformation)语言实现容错逻辑.QVT是对象管理组织提出的一种标准模型处理语言,相比于Java等通用语言能够更加有效和便捷地实现对模型的分析和操作.本文将运行时模型作为容错逻辑的输入,利用QVT对模型处理的高效性,大幅度减少容错机制开发工作量.
为实现容错机制的异构基础设施适配能力,本文通过对容错机制处理逻辑的归纳总结,首次提出将容错机制描述为一个自适应回路[5],包括监测(monitor)、分析(analyze)、规划(plan)、执行(execute)四个阶段.监测阶段收集目标平台及应用的运行时信息;分析阶段通过对运行时信息的检查判断系统是否存在错误,如果存在错误则进一步分析故障源并进入规划阶段,否则返回监测阶段;规划阶段根据出现错误的类型以及故障原因制定恢复操作序列;执行阶段通过执行恢复操作序列来调整系统状态,实现容错.在上述4个阶段中,监测和执行是平台相关的,需要调用目标平台管理接口;分析和规划是平台无关的,主要实现机制自身的容错逻辑.将平台相关的监测和执行与平台无关的分析和规划分离开来以最大程度地实现容错机制跨平台性是一种自然的选择.基于模型的开发方式是实现平台相关部分和平台无关部分分离的有效手段,既能够通过隔离关注充分实现平台无关的容错逻辑,又能够通过代码生成减少容错机制开发的工作量.为了帮助开发者对容错机制进行建模,本文定义了容错机制的结构元模型,开发者通过实例化该结构元模型来实现特定容错机制的结构模型.结构模型定义了容错机制的接口、类及关联.在结构模型的指导下,通过QVT语言实现容错机制的平台无关部分,即容错分析和规划;通过Java代码调用平台管理API实现容错机制平台相关部分,即容错监测和执行.
1相关工作
1.1容错技术与容错机制
容错是指系统在出现错误的情况下继续对外提供服务的能力.错误意味着系统至少存在一个不正确的内部状态,该状态产生的原因是系统内部故障,即故障被激活时形成错误,而当错误传播至构件或系统边界时形成失效.容错就是在系统故障被激活形成错误时,使用某种策略防止错误进一步传播和失效的发生.容错包括2个步骤:错误检测和恢复[1].错误检测的目的是及时发现系统内出现的错误;恢复的目的是将系统恢复到正确状态并防止错误再次发生,包括错误恢复和故障恢复2个阶段.错误恢复是将系统中的异常状态恢复正常;故障恢复是将导致系统发生错误的根源从系统中彻底清除掉,防止故障再次被激活.
根据被激活的时机,云容错机制可分为反应式和前摄式2种类型[6-7].
1) 反应式容错机制.该机制是指当系统故障被激活形成错误时,采用某种策略防止系统失效的发生.在云平台中常用的反应式容错机制包括检查点重启(check-pointreboot)[8-9]、备份(spare)[10]、双工(duplex)[10]以及重试(retry)[11].VirtCFT[9]是一个针对虚拟化集群基于检查点重启的容错系统.该系统定期保存整个集群的状态,包括所有虚拟机的CPU、内存、硬盘以及网络交互,当故障发生后将最近的检查点恢复到整个集群中实现容错.备份和双工的区别在于前者同一时刻仅有一个实例提供服务,后者则有多个实例提供服务.根据主实例与从实例的状态一致程度,备份机制又可分为热备、温备、冷备3种.Remus[12]在Xen虚拟化技术的基础上实现了一种基于虚拟机热备的容错机制.通过增量式内存拷贝,将主虚拟机内存状态同步至从虚拟机.与Remus类似,Kemari[13]通过内存拷贝实现主从虚拟机的同步,区别在于前者通过一个固定的频率同步虚拟机,而后者仅在由外部事件(例如硬盘读写、网络发送事件等)发生时进行同步.Das在其博士论文[4]中提出一种基于双工机制的容错框架.请求转发器将请求分发给各个虚拟机,投票器从各虚拟机的反馈中选择正确的结果返回给用户,如果有虚拟机出现故障,则报告给故障处理器进行修复.对于瞬时性故障,重试机制是一种简单高效的容错策略.当返回结果超时或不正确时,该机制重新发送请求给同一个目标或其他目标.例如Apache实现了针对http请求的重试机制,以帮助开发者在对基于http请求的网络访问代码中实现容错.
2) 前摄式容错机制.该机制是指根据系统目前的状态,判断可能会发生的错误,从而采取某种容错机制优先预防失效.云平台中常用的前摄式容错机制[11]包括优先迁移和软件恢复.由于云平台中虚拟机具有热迁移能力[15-18],因此在预判物理机可能会发生错误时(例如根据物理机CPU温度、风扇转速判断该物理机可能会由于温度过高导致停机[19]),将虚拟机优先迁移到其他物理机上,以维持虚拟机的正确运行.迁移机制不仅限于虚拟机粒度,对计算任务亦可进行迁移[20-22].针对软件老化引起的故障,可以采用软件恢复机制[23]定期重启软件,使系统处于干净的状态从而避免错误.在云平台中重启单位一般是应用、虚拟机或物理机.Sousa等人提出在拜占庭容错服务器中设置定时器[24],对服务器进行重启.为了避免所有服务器同时重启而影响对外提供服务,文中设计了同步机制,由系统统一安排重启.
产业界云平台提供的容错机制主要是基于重启和冗余实现的.重启是一种简单高效的容错机制,而冗余能够对常见的fail-stop进行故障转移.基于双工的容错机制能够处理拜占庭故障,但由于其消耗过多的软硬件资源,所以更多在关键系统中使用[25].表1对VMware,XenServer,CloudStack以及Windows ServerhyperV四种云平台中的容错机制使用情况进行总结.

Table 1 Usage of FT Mechanisms in Industry Cloud Platform
1) VMware-HA.VMware-HA是基于集群实现的,让集群内的物理机之间可以彼此互相支持,一旦有物理机发生故障,其上运行的虚拟机就会在其他物理机上重新启动,VMware-HA会有短暂的停机时间.对于可靠性要求较高的虚拟机,可以使用基于热备机制的VMware-FT来完成零停机、没有数据遗失的任务.
2) XenServer HA.XenServer HA持续监视资源池中主机的运行状态.如果物理机发生故障,XenServer HA会自动将受保护的虚拟机重启至一台运行状况良好的物理机上.与VMware-HA不同的是,XenServer HA容错过程由资源池中的主服务器实现.如果主服务器发生故障,将投票产生新的主服务器,以便能够继续管理XenServer资源池.
3) CloudStack.在CloudStack中,当虚拟机所在的物理机出现故障时,HA服务能够监测该事件并且自动在同一个集群中重新启动该虚拟机.此外,CloudStack还提供了以下容错方案:
① 基于状态监测的虚拟机重启.周期性地检查虚拟机状态是否与数据库VM表中status字段所存储的内容一致,若不一致则认为虚拟机状态错误,并重启该虚拟机.
② 虚拟机优先迁移.当某台物理机负载超过阈值后(该阈值管理员可设定),虚拟机会被迁移至其他负载较低的物理机.
③ 多管理节点.CloudStack管理节点是无状态的Web应用,可将管理节点部署在多台物理机上,避免单点故障.
④ 数据库备份.CloudStack使用MySQL数据库,可以利用数据库的备份机制提供数据容错.
4) Windows Server 2008.提供了2种容错技术:故障转移集群和网络负载均衡.故障转移集群是一个提供后端应用程序故障转移的服务,用于提升应用的可用性,如SQL Server和Exchange Server.集群由一台主服务器和多个备用服务器构成,所有的服务器共享一个存储系统.若主服务器出现故障,则自动由备用服务器接管应用,实现容错.备用服务器从共享存储里面读取Session状态,继续提供服务.网络负载均衡是一个实现前端Web应用故障转移的服务,其原理与故障转移集群类似.此外,Windows Server 2012还提供了4个容错方案:
① 无共享实时迁移.在传统的热迁移技术中,需要在共享存储的条件下进行.但在Windows Server 2012中,管理员可以在无共享环境下实现虚拟机热迁移.
② 虚拟机复制.虚拟机复制是热备份容错机制的一个实例,通过立即复制或者复制计划(5 min复制一次)完成虚拟机初始复制.当主虚拟机停机后,管理员通过hyperV管理器启用计划内的故障转移,将上次复制同步后虚拟机尚未迁移的数据迁移到副本服务器中,并自动启用从虚拟机.
③ 网卡组合.网卡组合是指将2个或者多个网卡绑定,但对上层软件透明.提供故障保护、带宽聚合以及负载均衡.
④ 服务器消息块(SMB)无缝故障转移.管理员在对文件服务器集群中的节点执行硬件或软件维护任务时,不会中断在文件共享中存储数据的服务器应用程序的正常运行.如果集群内节点遇到软硬件故障,SMB 客户端可重新连接到其他群集节点,且不会造成服务中断.
故障是引起错误和失效的源头,要进行容错首先要确定故障的类型,再采用相应的策略和配置方式进行容错.故障类型是对故障源中可能出现的故障类型的一种假设,云平台中常见故障类型包含:瞬时性故障、fail-stop故障、拜占庭故障.瞬时性故障是一种具有不确定性的随机发生的故障,具有难以重现的特点,一般可采取重启等方式实现容错;fail-stop故障是云平台中常出现的故障之一,例如由于软硬件错误导致虚拟机或物理机停止运行,或由于硬件老化等因素导致磁盘坏道都属于这类故障;拜占庭故障是指在运行阶段发生的任意类型的故障,尤其是指由于受到攻击产生的故障[25].在容错过程中,容错机制的选择往往依赖于故障类型以及其他约束,如资源约束、响应时间等,可将其描述为一个约束求解问题[26].
本文使用基于模型的容错机制开发方法实现了云平台中7种容错机制的实例,它们针对的故障类型以及适用的故障源如表2所示:
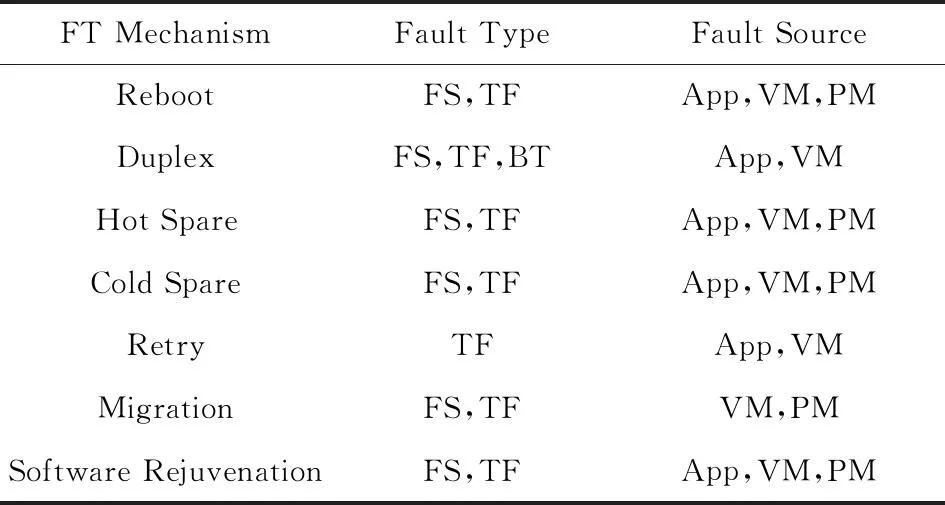
Table 2The Fault Type and Fault Source of Each FT Mechanism
FS:Fail-Stop; TF:Transient Fault; BT:Byzantine Fault;
App:Application; VM:Virtual Machine; PM:Physical Machine.
1.2基于运行时模型的自适应回路
自修复是IBM在2001年提出的自治计算[27]中一个重要组成部分(其他3个部分是自配置、自修复、自保护),其目的是实现系统容错.此后,在学术界从自修复的角度实现容错已达成共识.自治系统通过MAPEK(monitor-analysis-plan-executorknowledge)控制回路实现自适应.在上述自适应回路中,知识处于核心地位.如何获取与管理目标相符的知识成为自治计算研究的热点之一.北京大学开发的运行时模型支撑工具SM@RT(supporting model at runtime)实现了一种通用的运行时模型构造方法[28],利用目标平台的管理能力实现模型与系统的因果关联,即系统的状态变化同步至模型,反之模型的变化也会同步至系统.图3展示了SM@RT工具的输入输出以及元模型和访问模型的概念.元模型描述了被管理的元素及元素间的组织结构,访问模型描述了获取这些元素运行时信息的方法.
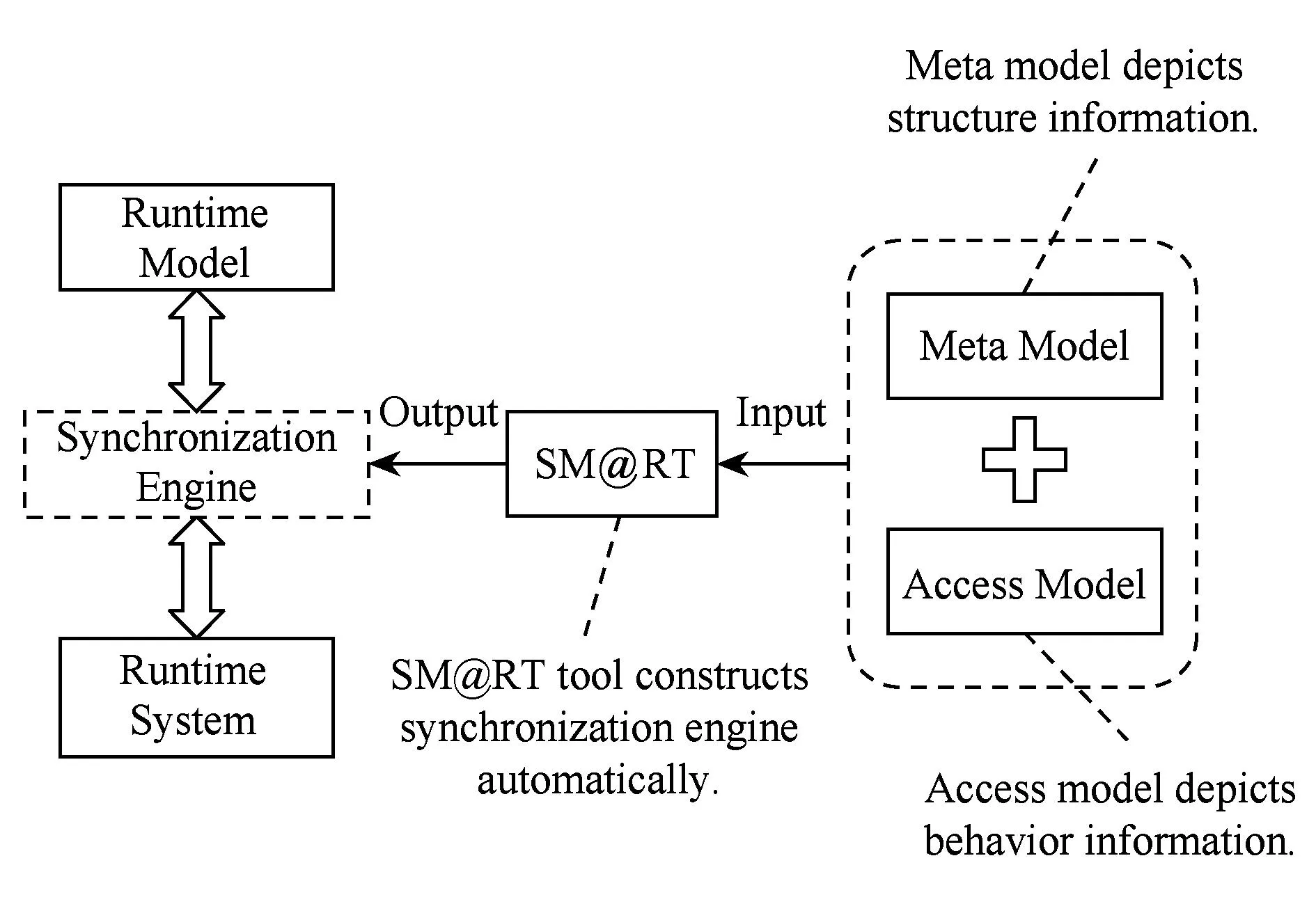
Fig. 3 Input and output of SM@RT.图3 SM@RT工具输入输出
借助运行时模型的同步能力,可以构造基于运行时模型的自适应回路,如图4所示.宋晖等人[28]对Android,Eclipse以及物联网等系统或应用构造了运行时模型,并利用运行时模型与系统具有的同步关联这一特点,使用基于模型的语言或管理工具对运行时系统在模型层面进行管理,以避免对系统进行直接管理的复杂性.
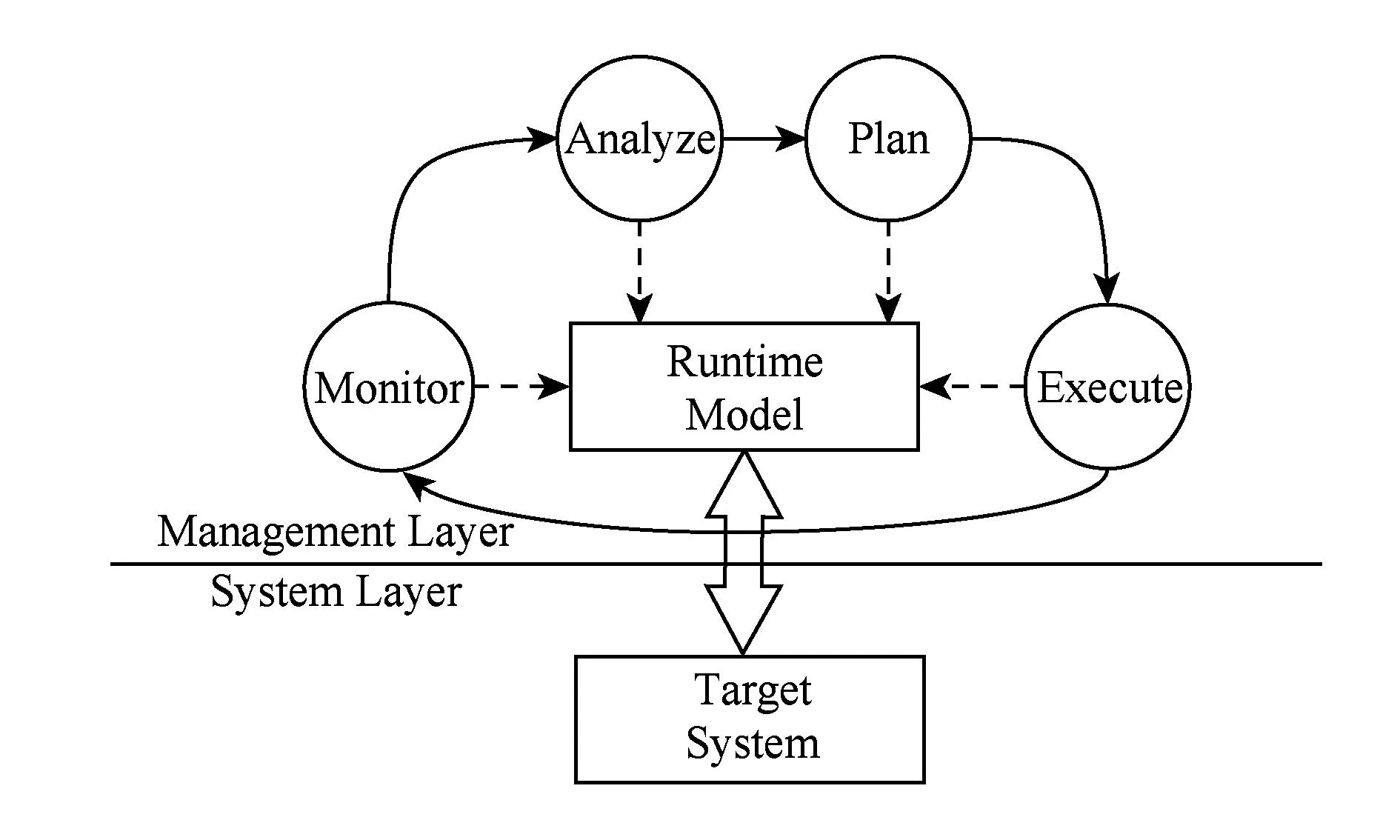
Fig. 4 Runtime model-based self-adaptive loop.图4 基于运行时模型的自适应回路
本文在自适应回路和SM@RT的基础上提出了一种基于模型的容错机制开发方法.在容错机制开发阶段,将容错机制开发过程描述为自适应回路,通过容错机制平台相关部分和平台无关部分的分离,实现容错机制的跨平台性.在容错机制执行阶段:①使用SM@RT将系统信息抽象为运行时模型,并实现运行时系统与运行时模型的同步;②通过容错机制对运行时模型的监测和调整,实现对目标系统的容错.
2基于模型的容错机制开发方法
本文提出将容错机制描述为一个自适应回路.一个自适应回路包含4个步骤[5]:监测、分析、规划、执行.在监测阶段,收集被管理系统的运行时信息,一般通过调用目标系统管理API或查看日志等方式收集,例如Aparna根据CloudStack架构提出了被监测对象的相关属性[29].本文假设容错机制的监测能力一定程度上依赖于目标系统提供的管理接口且该管理接口持续可用,若目标系统不具备该管理功能,需要容错机制开发者实现该信息的获取能力.在分析阶段,通过预先定义的方式处理监测信息,得出系统运行状态的相关结论.在规划阶段,按照分析阶段得出的结论制定相应的策略,以便将系统调整到一个更加合适的目标状态.在执行阶段,按照规划结果对系统进行调整.由此可以看出,在一个自适应过程中只有监测和执行阶段需要与目标系统交互,是平台相关的,而分析和规划阶段仅包含该自适应过程自身的业务逻辑,是平台无关的;与此相对应,在一个容错机制中,监测和执行阶段是平台相关的,分析和规划阶段是平台无关的.因此,本文通过将平台相关部分(监测、执行)和平台无关部分(分析、规划)进行分离,最大程度地实现容错机制的跨平台性.如图5所示,在容错机制实例的跨平台实现过程中,分析模块和规划模块可实现一次性开发,为适应异构的基础设施,开发者只需开发其相应的监测模块和执行模块即可.
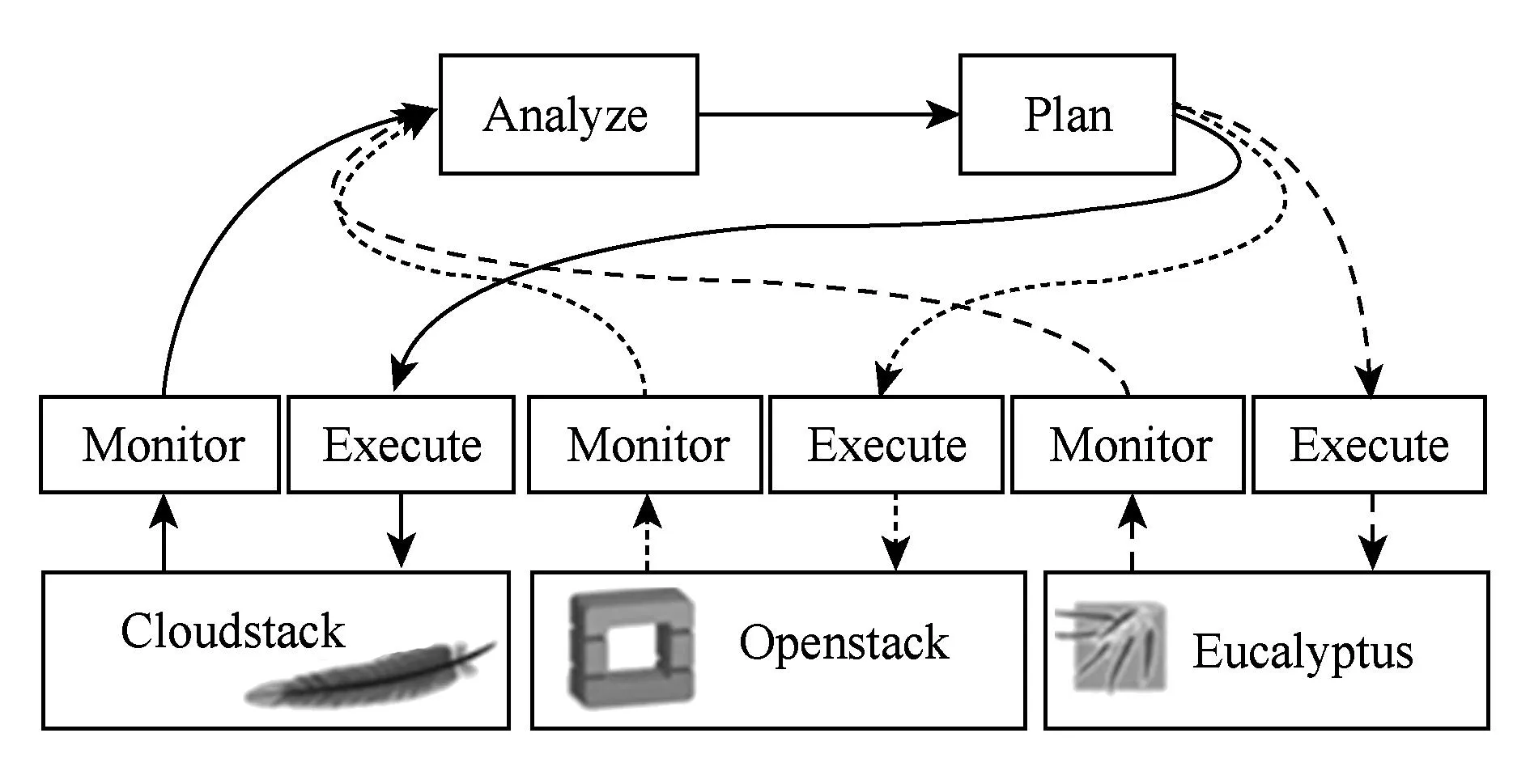
Fig. 5 A fault tolerance mechanism enables cross-platform.图5 一个容错机制的跨平台实现
2.1容错机制实例研究
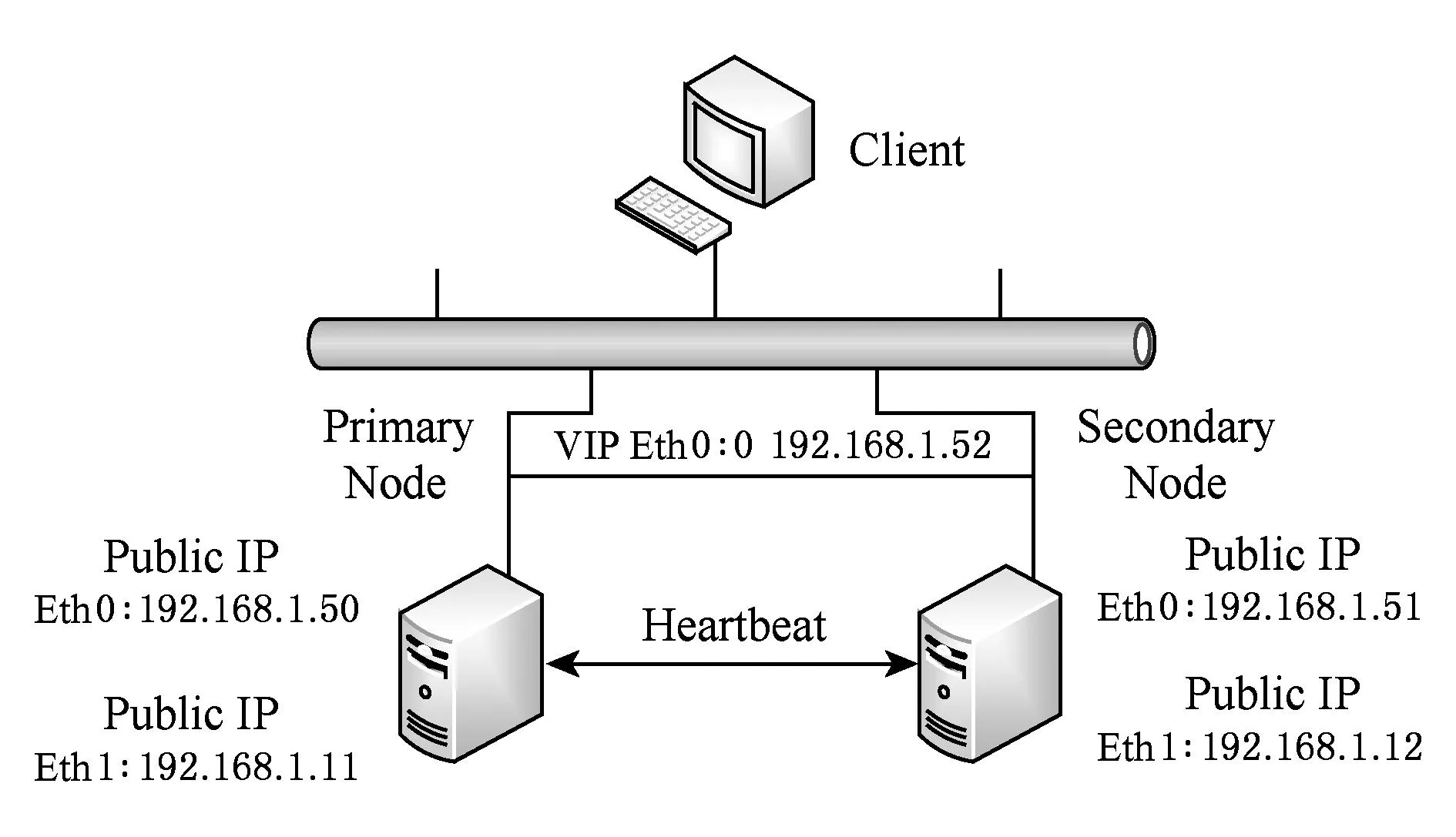
Fig. 6 Deployment of hot spare mechanism.图6 热备容错机制的部署
本节以热备容错机制为例,展示容错机制描述为自适应回路的过程.热备是一种基于资源冗余的容错机制.主节点和备用节点中部署着相同的服务,其中主节点处于活动状态,备用节点处于待命状态.当主节点出现故障时,备用节点将被激活至活动状态.热备机制的部署方式如图6所示.主节点的外部IP地址为192.168.1.50(IP1),备用节点的外部IP地址为192.168.1.51(IP2).当主节点失效,IP1不可访问时,用户可通过访问IP2继续获得服务,但会影响用户体验.为使容错过程对用户透明,通常采用虚拟IP(VIP)技术实现故障转移.当主节点有效时,VIP绑定于主节点.当主节点失效且备用节点被激活时,VIP漂移到备用节点,此时客户端通过访问VIP依然可以获取正确的服务.这一过程中,为使备用节点感知主节点的失效,热备机制使用心跳(heartbeat[30])的方式进行监测.容错机制配置过程中需要为2个节点配置内部IP以便于传输和监测心跳.
热备机制容错逻辑对应的自适应环路过程如图7所示.首先,在监测阶段获取主节点的运行时信息,包括该节点的运行状态、被监测服务的运行状态等;其次,在分析阶段判断目标服务是否正常运行,如果任务非正常则进入规划阶段;再次,在规划阶段制定相应的故障转移实施步骤;最后,在执行阶段按照规划方案对系统进行调整.
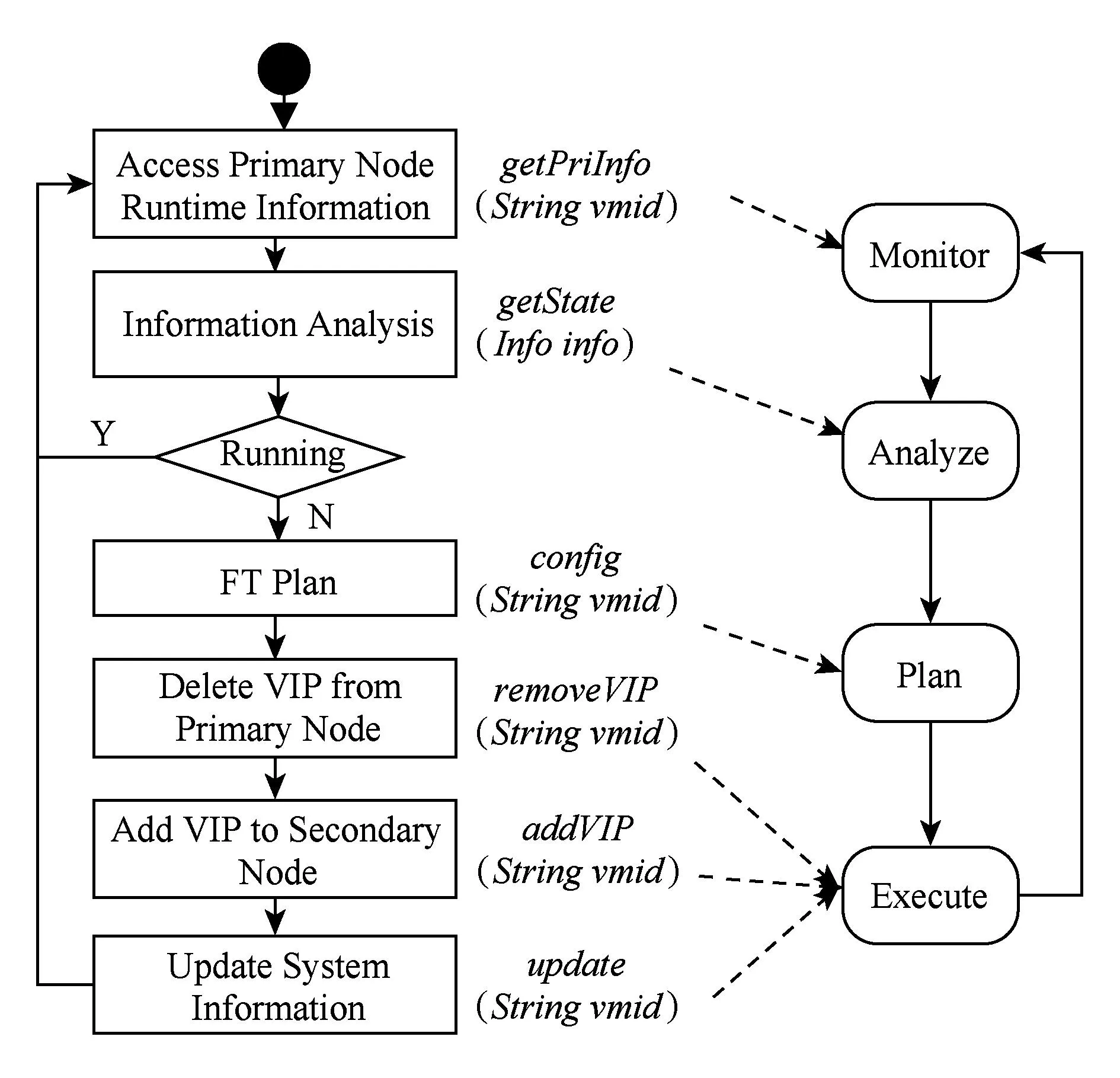
Fig. 7 Relationship between hot spare and adaptive loop.图7 热备机制与自适应回路对应关系
检查点重启机制容错逻辑对应自适应环路的过程如图8所示.1)在监测阶段获取容错对象的运行时信息;2)在分析阶段判断容错对象是否正常运行,若非正常则进入规划阶段;3)在规划阶段制定相应的故障转移实施步骤,例如选择最近可用的检查点;4)在执行阶段将容错对象进行重启并恢复至检查点.
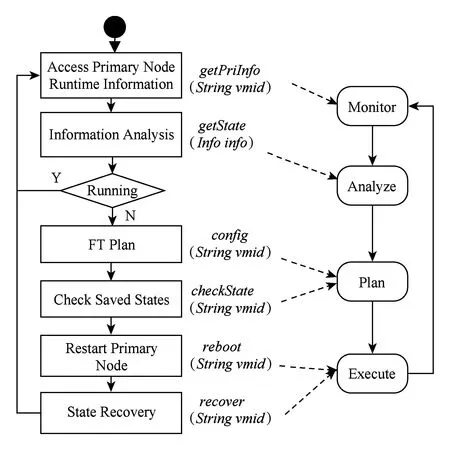
Fig. 8 Relationship between check-point restart and adaptive loop.图8 检查点重启机制与自适应回路对应关系
在传统的自修复系统中,开发者通常将目标系统描述为一个自适应环路,容错机制作为规划阶段的一部分实现于该系统特定的容错库中[31-33].这种方式并未考虑容错机制的跨平台性,导致其难以复用;此外,传统的容错机制开发方法要求开发者对目标系统管理能力和管理方式具有比较深入的了解,且实现难度大.
为实现容错机制中平台相关部分和平台无关部分的分离,需要对容错机制过程进行抽象,并定义这2部分之间的接口.由于模型具有良好的抽象能力,模型驱动软件开发能够有效地控制开发成本、提升开发效率,因此,使用基于模型的方法开发容错机制,通过隔离关注,不仅可以有效地实现平台无关部分的容错逻辑,还可以提升平台相关部分的开发效率,降低容错机制跨平台所需的工作量.
2.2容错机制开发

Fig. 9 Development procedure of a FT mechanism.图9 容错机制开发过程
基于模型的容错机制开发过程包括3个阶段:定义结构模型、构造行为模型、实现适配代码.其中结构模型通过UML类图描述容错机制的静态特征;行为模型通过QVT语言描述容错机制的动态行为,实现容错机制的平台无关部分;适配代码通过Java,C等程序语言调用目标云平台的管理API,实现容错机制的平台相关部分.基于模型的容错机制开发过程如图9所示,首先将结构元模型实例化为结构模型,然后在结构模型的指导下分别实现行为模型和适配代码.
2.2.1结构模型
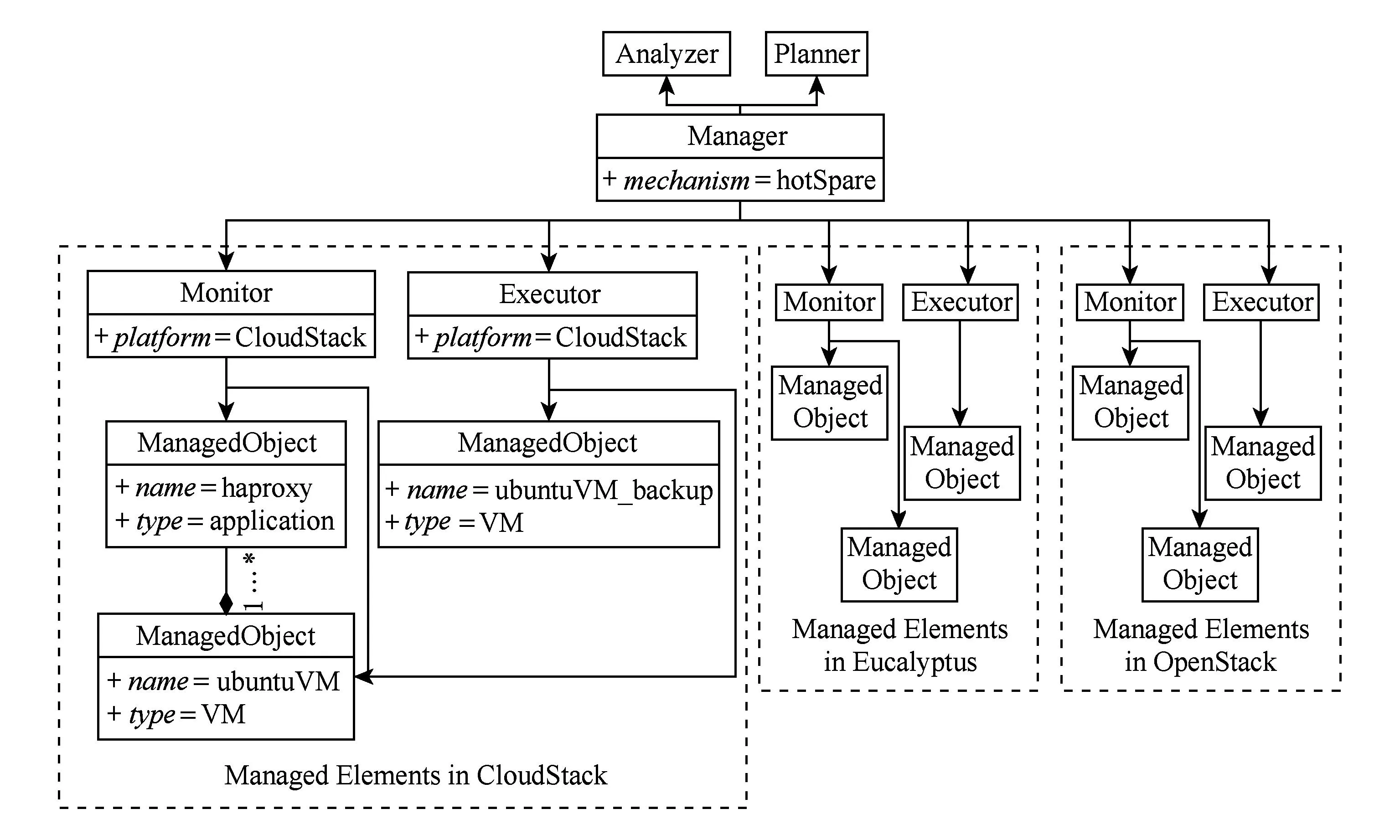
Fig. 11 Structure model of hot spare.图11 热备机制结构模型
在基于模型的容错机制开发过程中,结构模型描述了容错机制的静态特征.为了便于开发者定义结构模型,本文根据容错机制自适应环路的4个阶段定义了结构模型的元模型.当开发者实现特定的容错机制时,只需按照该元模型的约束定义结构模型即可,元模型如图10所示.Manager类定义了容错机制的主逻辑,包括对监测、分析、规划、执行4个阶段的调用,并定义了该容错机制的非功能属性,例如该容错机制对容错对象提供的可用性、故障转移时间、资源消耗等.其中,可用性属性描述了使用该容错机制后容错对象可用性的提升程度.如双机热备可将故障时间减少一倍,从而提升可用性的百分比.ManagedObject类描述了云平台中被监测和调整的对象,其用于描述物理机、虚拟机、应用、网络、存储等软硬件设备.Monitor类描述了容错机制中监测模块,其中,platform属性描述被监测的平台,getObject方法获取到被监测的对象,例如虚拟机对象;Analyzer类描述了运行时信息分析过程,并最终判定被监测的对象是否出现状态错误,根据其分析结果来判定Planner类是否被调用;Planner类描述了针对该错误状态构造的恢复逻辑,例如将出现错误的虚拟机关闭、启动备份虚拟机等;Executor类描述了通过对目标云平台管理API的调用,执行规划模块制定的恢复逻辑.
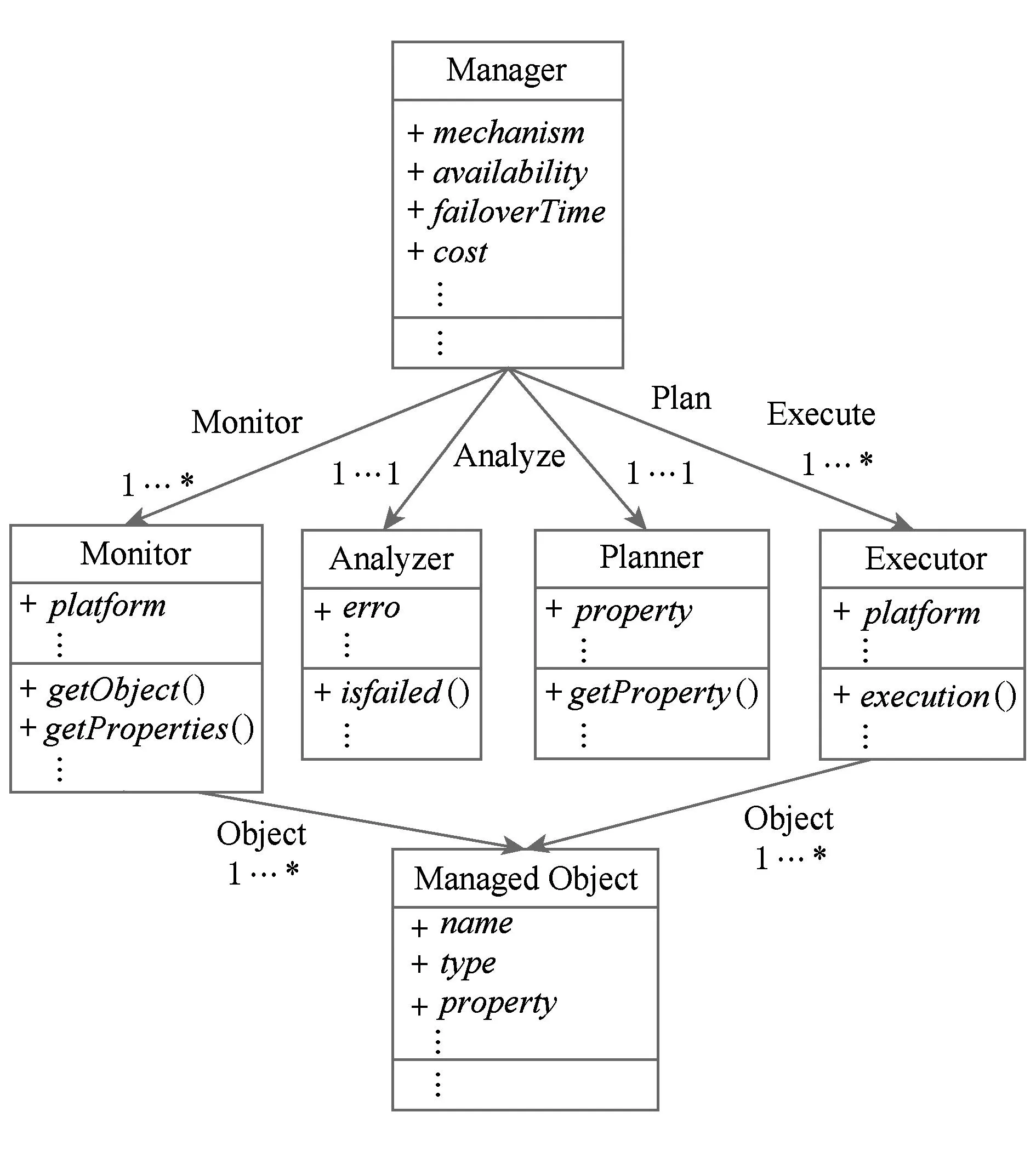
Fig. 10 The meta-model of structure model.图10 结构模型的元模型
本文对上述元模型进行实例化,定义出热备机制的结构模型,如图11所示.该结构模型定义了在3种云平台中热备机制的实现方式,由于分析、规划模块是可复用的平台无关部分,因此在结构模型中只需出现一次;而监测、执行模块是平台相关部分,因此需要针对3种云平台分别定义.图11中仅展示了CloudStack被管理元素的部分细节.其中被监测的元素分别是haproxy应用(name属性值为haproxy,type属性值为application)和ubuntuVM虚拟机(name属性值为ubuntuVM,type属性值为VM),并且该应用运行于该虚拟机之上.Monitor类通过监测被管理元素的运行时信息,将其反馈给Analyzer类,当Analyzer类分析结果表明被监测对象出现错误时,Manager主函数则调用Planner类制定恢复计划,并最终通过Executor类实施该计划.被实施操作的对象是2台名为ubuntuVM和ubuntuVM_backup的虚拟机.操作过程则是将虚拟IP从主虚拟机迁移到备份虚拟机,实现故障转移.该热备机制在Eucalyptus和OpenStack中的处理逻辑与CloudStack中的处理逻辑类似,此处不再赘述.
2.2.2行为模型
行为模型负责实现结构模型中定义的Analyzer类和Planner类,其功能是分析系统运行状态、检测系统中发生的错误、查找故障源并制定恢复计划.本文通过运行时模型获取系统状态,并将其作为行为模型的输入.为了便于实现对运行时模型的分析和操作,本文采用QVT[34]语言实现行为模型.图12描述了行为模型对系统调整的条件和过程.当在虚拟机v1上运行的应用hp1出现故障且虚拟机v2上运行的应用hp2状态正常时,则将虚拟机v1上的VIP迁移至虚拟机v2.我们采用XML格式描述分析和规划的结果,并在代码中使用QVT的log()函数将结果保存至中间数据.
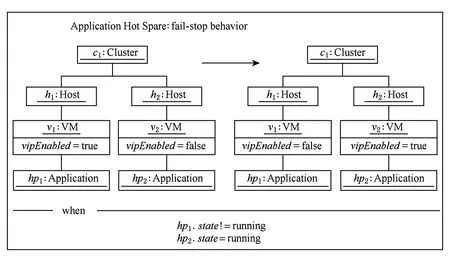
Fig. 12 Behavior model of hot spare mechanism.图12 热备机制行为模型.
上述行为模型的执行结果如图13所示,其含义是将VIP从webloadbalancer3虚拟机删除,并且绑定至webloadbalancer3Backup虚拟机.
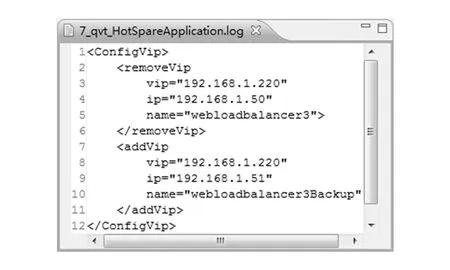
Fig. 13 Output of behavior model.图13 行为模型执行结果
2.2.3适配代码
适配代码实现结构模型中Executor类,即按照分析规划的结果调用目标平台的管理能力,对云平台实现状态调整.由于在热备机制的结构模型中定义了3个异构的云平台:CloudStack,OpenStack,Eucalyptus,因此适配代码需要分别加以实现.如图14所示,热备机制通过调用CloudStack提供的RESTFUL API、OpenStack提供的CLI以及Eucalyptus提供的RESTFUL API实现对VIP的绑定.对VIP的删除操作与之类似,此处不赘述.

Fig. 14 Adapter code of hot spare in three cloud platforms.图14 热备机制在3种云平台的部分适配代码实现
3基于运行时模型的容错执行框架
为支持容错机制的运行,本文实现了一个基于运行时模型的容错机制执行框架.如图15所示,包括云容错运行时模型的构造以及容错测试.
运行时模型的构造分为2个步骤:构造元模型以及构造访问模型.1)构造面向容错的云平台元模型.该元模型包括2个方面的属性,即云平台属性以及容错机制相关属性,本文对CloudStack,OpenStack以及Eucalyptus三大开源云平台的管理能力进行统计,取其并集构造出通用云平台管理模型,此外将容错机制相关属性进行整合,得到面向容错的云平台容错元模型.2)构造平台相关的访问模型,实现对元模型的实例化.元模型是平台无关模型,定义了云平台管理能力以及运行时信息的结构,而运行时模型是平台相关模型,通过对各个平台管理能力的绑定实现对元模型的实例化.SM@RT将元模型和访问模型作为输入,通过代码生成工具构造维护运行时模型的引擎.
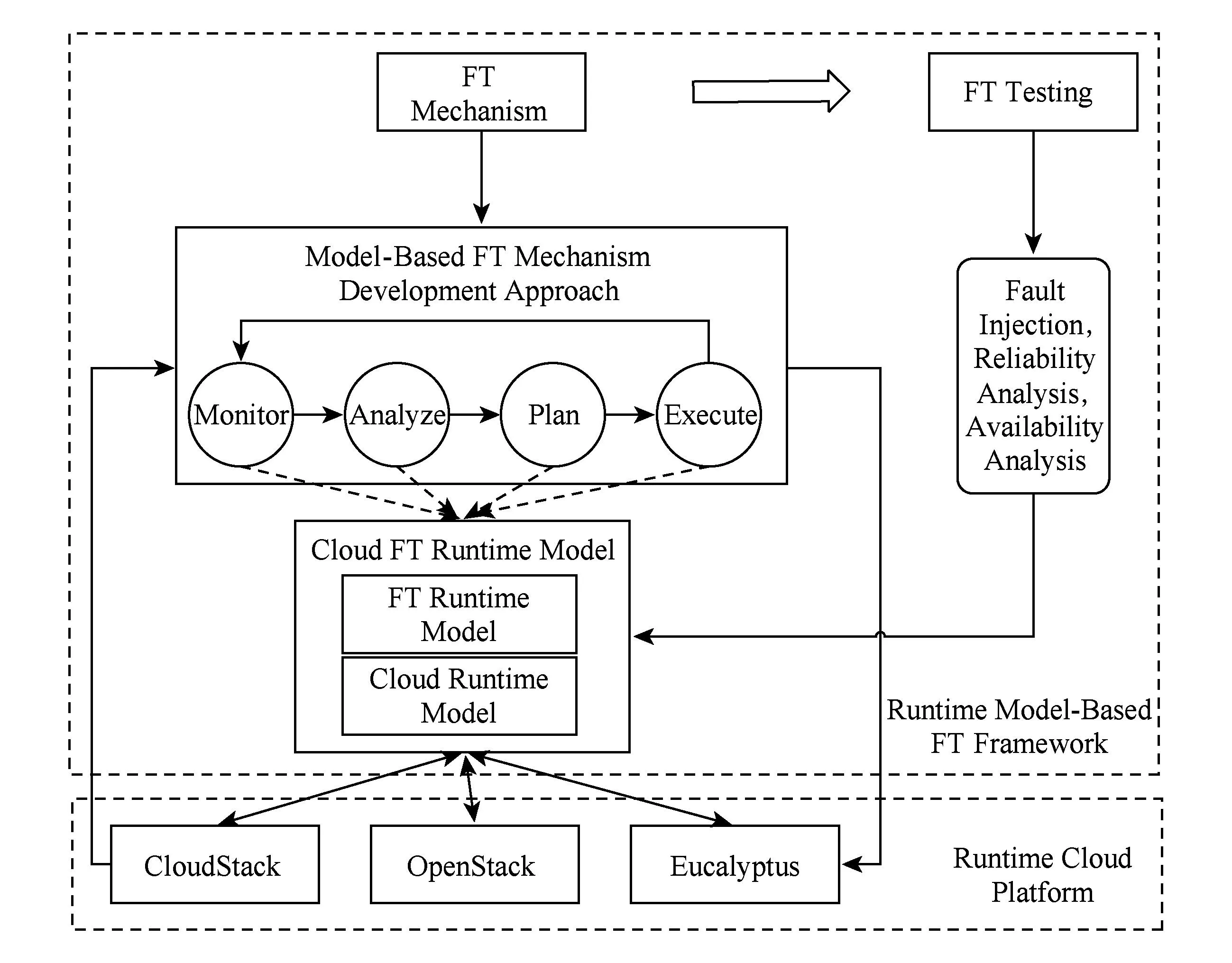
Fig. 15 Runtime model-based FT framework.图15 基于运行时模型的容错框架
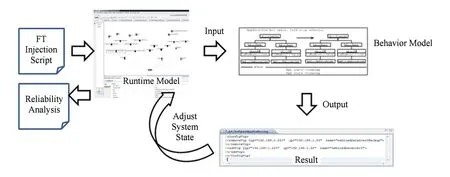
Fig. 16 FT testing.图16 容错测试
为验证容错机制和容错配置效果,本文提出一种基于运行时模型的容错测试方法.在运行阶段对云平台中的故障源进行故障注入,并对运行时模型以及容错机制的运行状态进行分析,计算可靠性指标.如图16所示,本文通过QVT脚本对运行时模型进行故障注入,模拟系统故障.例如,通过QVT对运行时模型进行操作,将指定的应用状态从running设置为error,此时容错机制的监测模块观察到该错误,并由执行模块实现故障转移.在状态调整后,利用QVT实现SBRA(scenario-based reliability analysis approach)[35]等可靠性分析算法在模型层面对系统进行可靠性评估.
4实验与分析
在本文的实验中采用基于模型的容错机制开发方法,实现了7个容错机制实例:重试、重启、热备、冷备、双工、优先迁移、软件恢复,并将这些容错机制分别在CloudStack和OpenStack环境下进行测试.1)分析容错效果,验证容错机制跨平台能力,统计代码复用率及开发成本;2)分析对云平台管理员以及容错机制开发者的问卷调查结果,验证基于模型的容错机制开发方法能够提升开发体验和开发效率.
为了对实现的容错机制进行效果评估,本文在CloudStack和OpenStack中进行了一系列实验,验证容错机制的有效性、跨平台性以及基于模型开发方法对容错机制开发效率的提升.本文将相同的JOnAS应用服务器部署于多个虚拟机中,并部署基准测试程序PetStore,使用LoadRunner作为测试工具.
实验配置如下:应用:PetStore 1.3.1_02及JOnAS_4_9_2;虚拟机:操作系统Centos6.4,VCPU 2×2 GHz,内存1 GB;云平台:CloudStack4.2.1,OpenStack Essex;测试工具:HP LoadRunner 11.00.
4.1容错机制有效性及跨平台性
原生CloudStack系统中有3个容错机制实例,分别是虚拟机重启、虚拟机迁移以及应用双工.基于容错机制开发方法,本文实现了其他4种容错机制相应的实例,即热备、冷备、重启、恢复.OpenStack中仅提供了针对基础设施的容错机制实例,而不对客户虚拟机提供容错支持,因此本文在OpenStack中为客户虚拟机或应用实现了7种容错机制相应的实例.

Fig. 17 Success rate of transactions.图17 事务成功率曲线
在容错对象运行过程中,通过预先定义的脚本随机触发一类故障,并选取故障前后20 min内的数据进行分析.实验中测量的是故障注入前后的一段时间内事务成功率,监测无故障运行的时间过长并无太大意义.此外,针对JOnAS服务器以及实验环境中虚拟机的资源配置,100个用户的使用量能够较好地将服务质量维持在较为稳定的水平,排除由于用户量过大导致的JOnAS请求丢失.在表2描述的3类故障中,fail-stop故障是云平台中常出现的故障之一[36].例如由于软硬件错误导致虚拟机或物理机停止运行,或由于硬件老化等因素导致磁盘坏道都属于这类故障,对该故障的模拟能够覆盖最多的故障数量,因此本文实验中选择注入fail-stop类型故障.在JOnAS服务器运行过程中,故障注入脚本在某时刻被激活,导致JOnAS强行关闭(模拟fail-stop故障),并分别验证7个容错机制实例的容错效果.本文对容错机制的评价指标主要体现在可靠性和可用性2个方面,其中可靠性描述事务的成功率,可用性描述系统的可用时间占总时间的比例,性能方面的评价暂未考虑在容错机制的评价范围内.图17展示了7种容错机制的容错效果.纵坐标表示每秒事务成功数量,横坐标表示访问时间.其中,双工机制能够提供最优的容错效果,较快实现故障转移,而由于重试机制仅能支持瞬时性故障,因此在第10分钟之后无法针对fail-stop错误提供有效的容错支持. 图18展示了7种容错机制分别部署在CloudStack和OpenStack中的可靠性.可靠性是指在规定的条件下和规定的时间内软件不引起系统失效的概率.据此概念,本文通过对事务成功率进行计算描述在各种容错机制保障下的软件可靠性,即,可靠性=成功事务数总事务数.其中,双工机制均能提供100%的可靠性,这是因为双工机制无故障转移时间,能够最有效地防止单点故障引起的系统失效;重试机制无法针对fail-stop错误提供有效的容错支持,因此其理论可靠性为50%(20 min内仅有前10 min工作,且用户以相同的频率访问).实验测试可靠性(分别是49.9%和49.7%)与理论值较接近,说明本实验将误差控制在较小范围内.其他各种容错机制在2种云平台中的可靠性有较小区别,是由于在容错机制中调用云平台管理API实现效率的差别,导致错误恢复和故障转移时间不同.

Fig. 18 Reliability of FT mechanisms.图18 容错机制可靠性
本文分别统计了7个容错机制实例的故障转移时间,具体如图19所示:
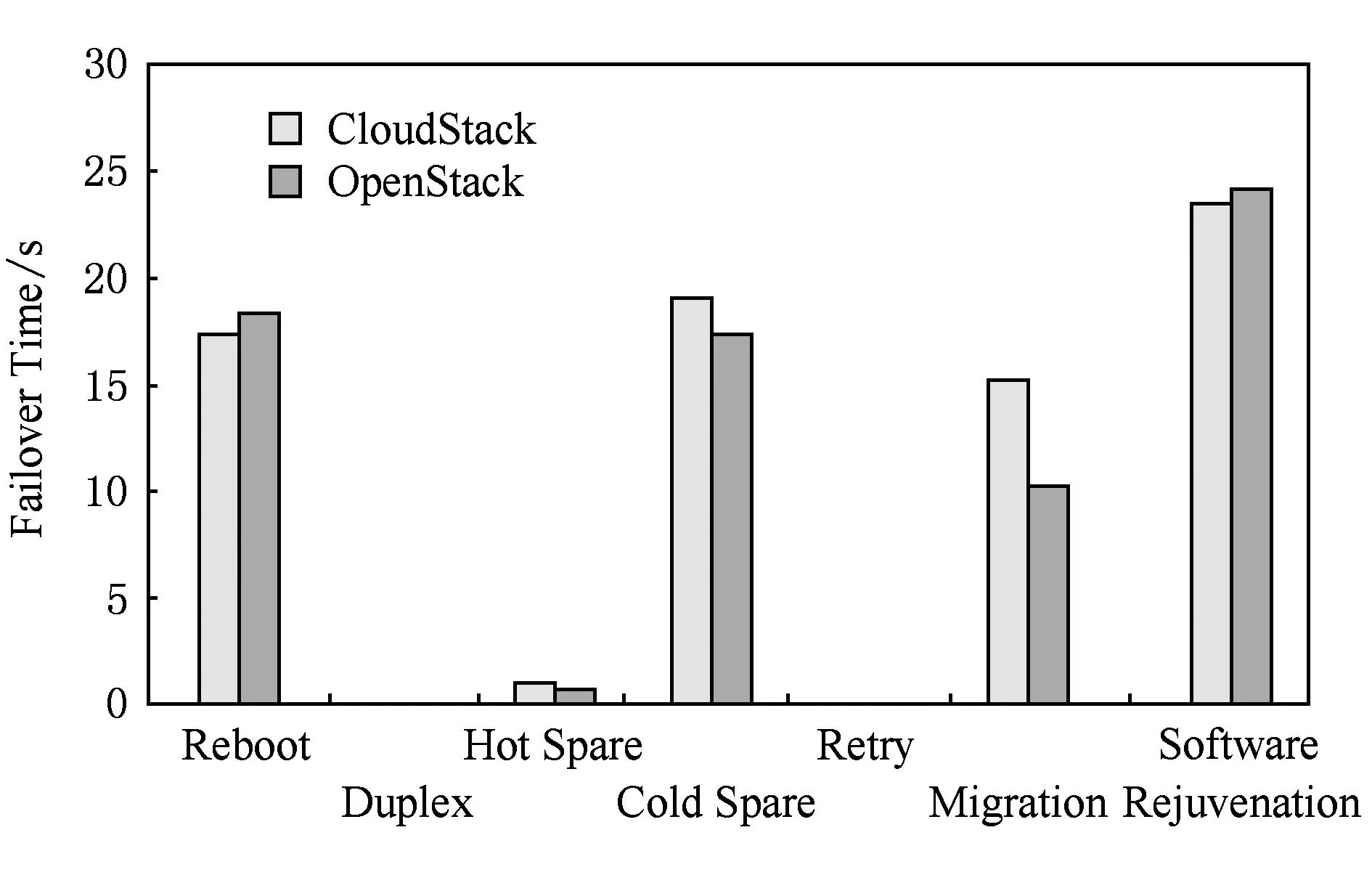
Fig. 19 Failover time of FT mechanisms.图19 容错机制故障转移时间
为更进一步描述容错机制在可信性方面的支持能力,本文从可用性(Availability)角度进行分析.Availability=MTTF(MTTF+MTTR).其中,MTTF为评价无故障运行时间;MTTR为平均故障修复时间,即本文中的故障转移时间.可用性直接从故障转移时间的角度评估系统可信性,因此7种容错机制的实例对可用性的提升能力不同于可靠性.图20展示了各种容错机制的可用性.

Fig. 20 Availability of FT mechanisms.图20 容错机制可用性
此外,基于模型的容错机制具有较小的性能损失.相关文献[19]展示了基于虚拟机迁移的容错方法会带来1%~4%的性能损耗,而本文实现的虚拟机热迁移容错机制产生3.4%的性能损失(本文部署的CloudStack环境中虚拟机迁移基准时间为14.7 s,基于优先迁移的容错机制时间为15.2 s),处在性能损失范围内,因此基于模型的容错机制带来的性能损失是可接受的.
4.2容错机制资源消耗
容错机制会产生额外的资源消耗,包括计算资源、存储资源以及网络资源.表3展示了各种容错机制消耗的资源在EC2(类型为t2.small)和EBS(存储介质为磁盘类型)中的成本.其中,相对于不使用容错机制时应用本身所消耗的资源,双工机制使用了2倍的计算资源、1倍的存储资源以及2倍的网络资源.重启、重试以及优先迁移不消耗计算资源和存储资源,这是由于这3种机制是基于时间冗余的容错机制.
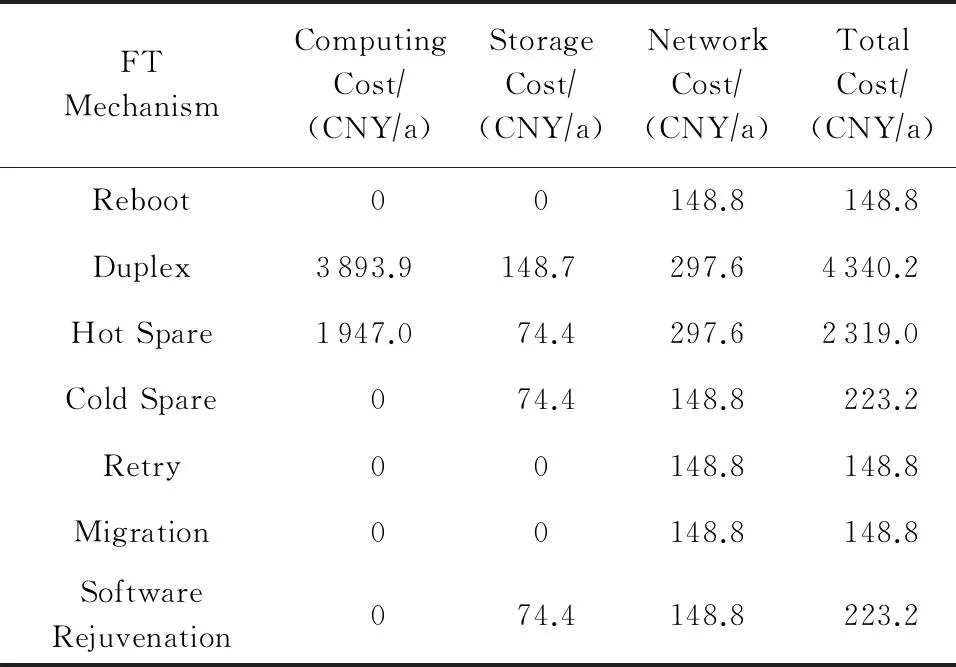
Table 3 FT Costs
4.3容错机制开发工作量及代码复用率
基于模型的容错机制开发方法能够在较大程度上降低容错机制的开发量.本文统计了7种容错机制实例开发过程中的工作量,如表4所示.在结构模型中,本文统计了所有模型元素的总数,包括类、属性、方法和关联;在行为模型中,本文统计了QVT代码行数(line of code, LOC).在适配代码中,分别统计了在CloudStack和OpenStack中的Java代码行数.
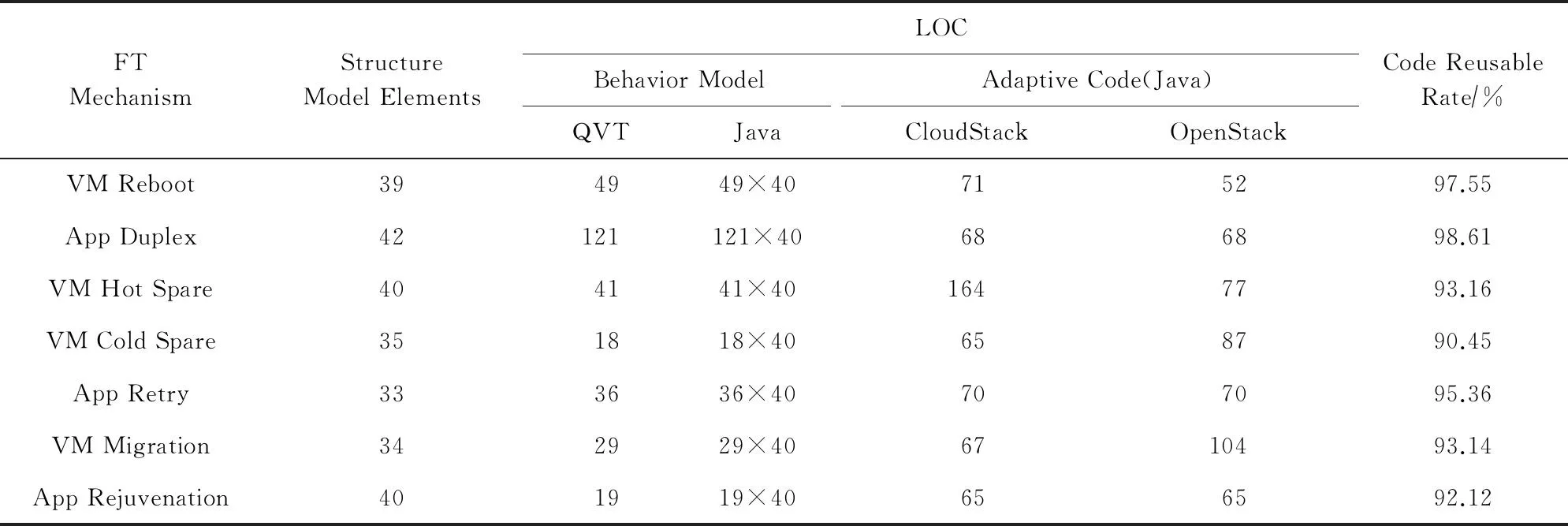
Table 4 Development Efforts of FT Mechanisms
行为模型是容错机制开发过程中的平台无关部分,适配代码是平台相关部分.根据各自实现的代码行数,本文计算出7个容错机制实例的代码复用率.参照实验及相关论文[28]中的统计数据,实现相同功能所需的QVT代码与Java代码的行数比为1∶40.按照该比例将行为模型的QVT代码转化为Java代码,容错机制的代码复用率在90%以上,如表4所示.因此,本文提出的基于模型的容错机制开发方法能够较好地解决平台异构性问题.
与相关工作相比,本文提出的容错机制开发方法有效地减少了容错机制开发过程中的工作量.原生CloudStack实现了一个基于虚拟机重启的容错机制.被标记为HA-Enable的虚拟机将会被High-AvailabilityManager监控,如果该虚拟机的状态与数据库中保存的状态不一致或其所在的物理机失效,则对该虚拟机在集群内其他物理机上进行重启.该容错机制实现需1 597行Java代码,而在本文的开发方法中仅使用了49行QVT以及71行Java代码.
4.4容错机制开发效率及开发体验
基于模型的容错机制开发方法将平台无关模块与平台相关模块分离,由容错机制开发者和云管理员2类开发者共同参与.其中,容错机制开发者擅长容错逻辑,实现平台无关部分(即容错机制的分析和规划逻辑);云管理员擅长云平台管理能力的使用,实现平台相关部分(即容错机制的执行逻辑).2类开发者只需预先定义之间的接口即可.
本文通过对容错机制开发者和云管理员的问卷调查,分析虚拟机重启、应用热备和优先迁移3种机制分别在平台相关部分和无关部分的开发难度,探索基于模型的容错机制开发方法是否能够在整体上降低开发难度、提升开发效率.
本研究邀请7名云管理员对容错机制开发过程进行评估,评估内容包括在容错机制开发过程中的平台相关和无关部分的开发难度、开发时间、代码行数,评估结果统计如表5所示.本文的调查对象均来自北京大学软件所的硕士研究生和博士研究生,分别开发和维护不同的云平台Openstack 和CloudStack.其中,部分调查对象的OpenStack开发和管理经验达1年,CloudStack的开发和管理经验达2年,且曾基于OpenStack和CloudStack参与开发青云[37]和燕云[38]2个云平台系统.目前燕云已经部署于北京大学软件所供上百名师生使用,且该云平台的日常维护和管理均由他们完成.因此,调查对象对云平台具有丰富的管理经验,能够代表一般的云管理员.在问卷中首先描述了基于模型容错机制的原理及开发过程,然后由云调查对象对平台无关部分和相关部分的实现难度(1~10)进行评估,并预测平台相关部分的代码行数以及开发时间.其中,开发时间包括对云平台API的学习时间.调查结果表明,平台无关部分的开发难度相对较大.例如,调查对象在实现虚拟机优先迁移平台无关部分的反馈中提到“难以找出物理机故障的判定条件,诸如资源实时利用率过高、最近出现过故障、距上一次出现故障时间、磁盘寿命等.如果只是简单地考虑几个属性会比较容易,但要作出正确率较高的决策比较困难”.这反映了容错机制开发过程中的一般问题,即难以准确判断错误的出现以及故障源,而这一过程对于容错机制开发者相对简单.
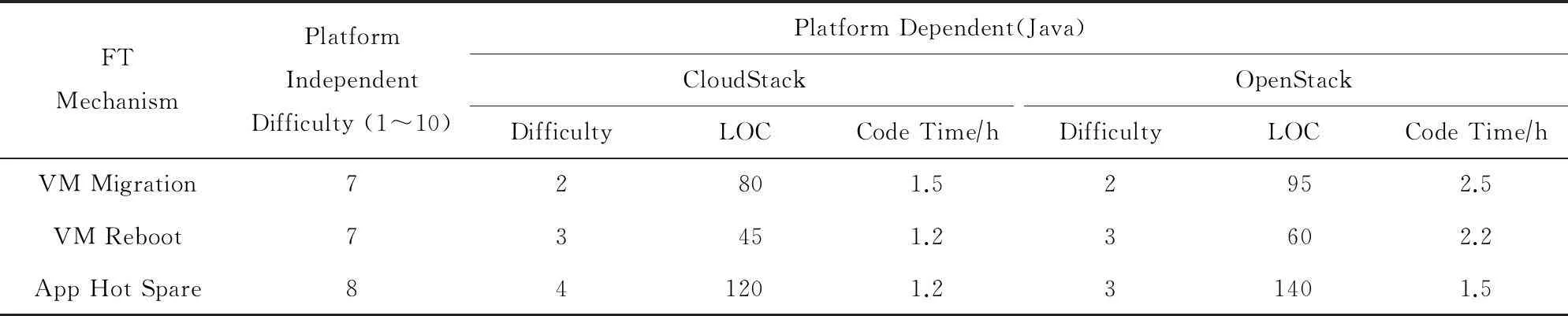
Table 5 Development Efforts on Cloud Administrators of FT Mechanisms
The following numbers stand for difficulty. 1: Very Easy; 3: Easy; 5: Hard; 7: Very Hard; 10: Impossible.
此外,本文对4名具有容错经验的开发者进行问卷调查,结果如表6所示.这4名开发者均为对QVT语言具有一年以上编程经验的研究生.为了模拟容错机制开发者,我们在问卷中预先描述了每个容错机制实例的分析、规划逻辑.在该问卷中,首先,描述了基于模型容错机制的原理及开发过程;然后,描述这3种容错机制的分析、规划逻辑,例如如何判断物理机故障、如何实现故障转移(模拟容错机制开发者);最后,由开发者评估平台无关部分和相关部分的实现难度(1~10分),并预测平台无关部分的代码行数以及开发时间.调查表明对容错机制开发者而言,平台相关的容错逻辑的实现难度更低.

Table 6 Development Efforts on FT Experts
综上所示,平台相关部分的开发对于管理员难度较低,而平台无关部分的开发对于容错机制开发者难度较低.因此,通过容错机制平台相关部分与平台无关部分的分离,由云管理员实现平台相关部分、容错机制开发者实现平台无关部分,能够有效地降低容错机制开发难度、提升开发效率及开发体验.
5结束语
在传统的自修复或容错系统中,容错机制被实现在该系统专用的容错库中,系统被描述为一个自适应回路,容错机制在该回路中被调用.这种方式实现的容错机制难以实现跨平台性和复用性.不同于传统方法,本文首次提出将容错机制描述为一个自适应回路(监测-分析-规划-执行),并采用基于模型的开发方式实现容错机制的跨平台性,同时降低开发成本、提升开发体验.通过本文方法实现的容错机制可形成一个跨平台的容错机制库,供异构云平台调用.为了帮助容错机制开发者实现容错机制,本文提出一个容错机制开发方法,包括3个步骤:定义机构模型、定义行为模型、实现适配代码.1)本文定义了容错机制结构模型的元模型,该元模型的实例化开发者可以构造出特定容错机制的结构模型,以进一步指导该容错机制的实现;2)本文提出通过模型描述语言QVT实现平台无关的行为模型,实现容错分析和规划;3)适配代码可由目标系统提供管理接口的语言类型实现(例如Java,C++等通用语言),即开发容错机制平台相关部分,将行为模型的分析和规划结果通过平台管理API实现到系统中.
在未来工作中,可进一步提高容错机制开发过程的自动化程度.在基于模型的容错机制开发方法中,行为模型描述了容错逻辑是通过QVT语言实现的,该过程需要手动实现.虽然工作量已大幅度减少,但考虑到该语言的专业性,会增加学习成本.针对这一问题,可以采用领域建模语言半自动代码生成的方式帮助管理员生成容错逻辑代码.
参考文献
[1]Avizienis A, Laprie J C, Randell B, et al. Basic concepts and taxonomy of dependable and secure computing[J]. IEEE Trans Dependable and Secure Computing, 2004, 1(1): 11-33
[2]OpenStack Foundation. OpenStack API complete reference[ROL]. 2015 [2015-06-15]. http:www.openstack.org
[3]Apache CloudStack. Apache CloudStack API documentation(V4.5.0)[ROL]. 2015 [2015-06-15]. http:cloudstack.apache.orgapiapidocs-4.5TOC_Root_Admin.html
[4]Hewlett Packard Enterprise Development LP. General purpose reference architecture: Detailed solution example for Eucalyptus private clouds[ROL]. 2015 [2015-06-15]. http:docs.hpcloud.comeucalyptus4.2.0
[5]Kephart J O, Chess D M. The vision of autonomic computing[J]. Computer, 2003, 36(1): 41-50
[6]Mahalkari A, Tondon R. A replica distribution based fault tolerance management for cloud computing[J]. International Journal of Computer Science & Information Technologies, 2014, 5(5): 6880-6887
[7]Ganesh A, Sandhya M, Shankar S. A study on fault tolerance methods in cloud computing[C]Proc of Int Advance Computing Conf (IACC2014). Piscataway, NJ: IEEE, 2014: 844-849
[8]Joshi S C, Sivalingam K M. Fault tolerance mechanisms for virtual data center architectures[J]. Photonic Network Communications, 2014, 28(2): 154-164
[9]Zhang Minjia, Jin Hai, Shi Xuanhua, et al. VirtCFT: A transparent VM-level fault-tolerant system for virtual clusters[C]Proc of the 16th Int Conf on Parallel and Distributed Systems (ICPADS). Piscataway, NJ: IEEE, 2010: 147-154
[10]Haas F. Openstack High Availability Guide[MOL]. 2014 [2015-06-15]. http:docs.openstack.orgha-guide
[11]Ganga K, Karthik S. A fault tolerent approach in scientific workflow systems based on cloud computing[C]Proc of Int Conf on Pattern Recognition, Informatics and Mobile Engineering (PRIME). Piscataway, NJ: IEEE, 2013: 387-390
[12]Cully B, Lefebvre G, Meyer D, et al. Remus: High availability via asynchronous virtual machine replication[C]Proc of the 5th USENIX Symp on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2008: 161-174
[13]Tamura Y, Sato K, Kihara S, et al. Kemari: Virtual machine synchronization for fault tolerance[C]Proc of USENIX Annual Technology Conf. Berkeley, CA: USENIX Association, 2008: 1-3
[14]Das P. Virtualization and fault tolerance in cloud computing[D]. Rourkela, India: National Institute of Technology Rourkela, 2013
[15]Clark C, Fraser K, Hand S, et al. Live migration of virtual machines[C]Proc of the 2nd USENIX Symp on Networked Systems Design & Implementation. Berkeley, CA: USENIX Association, 2005: 273-286
[16]Pradip D, Miren K, Bhavsar M, et al. Live virtual machine migration techniques in cloud computing: A survey[J]. International Journal of Computer Applications, 2014, 86(16): 18-21
[17]Ahmad R W, Gani A, Hamid S H A, et al. A survey on virtual machine migration and server consolidation frameworks for cloud data centers[J]. Journal of Network and Computer Applications, 2015, 52(1): 11-25
[18]Ahmad R W, Gani A, Hamid S H A, et al. Virtual machine migration in cloud data centers: A review, taxonomy, and open research issues[J]. The Journal of Supercomputing, 2015, 71(7): 1-43
[19]Nagarajan A B, Mueller F, Engelmann C, et al. Proactive fault tolerance for HPC with Xen virtualization[C]Proc of the 21st Annual Int Conf on Supercomputing. New York: ACM, 2007: 23-32
[20]Bala A, Chana I. Fault tolerance-challenges, techniques and implementation in cloud computing[J]. International Journal of Computer Science Issues, 2012, 9(1): 37-41
[21]Choudhary S, Vits M. Task migration based fault tolerant scheme for cloud computing[J]. International Journal of Scientific Progress and Research, 2014, 2(1): 55-61
[22]Shyamsunder S, Varkhede K, Bhuruk S, et al. Efficient fault tolerant strategies in cloud computing systems[J]. Resource, 2015, 2(2): 32-34
[23]Sudhakar C, Shah I, Ramesh T. Software rejuvenation in cloud systems using neural networks[C]Proc of Int Conf on Parallel, Distributed and Grid Computing (PDGC2014). Piscataway, NJ: IEEE, 2014: 230-233
[24]Sousa P, Bessani A N, Correia M, et al. Highly available intrusion-tolerant services with proactive-reactive recovery[J]. IEEE Trans on Parallel and Distributed Systems, 2010, 21(4): 452-465
[25]Fan Jie, Yi Letian, Shu Jiwu. Research on the technologies of Byzantine system[J]. Journal of Software, 2013, 24(6): 1346-1360 (in Chinese)(范捷, 易乐天, 舒继武. 拜占庭系统技术研究综述[J]. 软件学报, 2013, 24(6): 1346-1360)
[26]Zheng Zibin, Zhou T C, Lyu M R, et al. Component ranking for fault-tolerant cloud applications[J]. IEEE Trans on Services Computing, 2012, 5(4): 540-550
[27]Kephart J O, Chess D M. The vision of autonomic computing[J]. Computer, 2003, 36(1): 41-50
[28]Song Hui, Huang Gang, Wu Yihan, et al. Modeling and maintaining runtime software architectures[J]. Journal of Software, 2013, 24(8): 1731-1745 (in Chinese)(宋晖, 黄罡, 武义涵, 等. 运行时软件体系结构的建模与维护[J]. 软件学报, 2013, 24(8): 1731-1745)
[29]Datt A, Goel A, Gupta S C. Comparing infrastructure monitoring with CloudStack compute services for cloud computing systems[G]Databases in Networked Information Systems. Berlin: Springer, 2015: 195-212
[30]Haas F. The Linux-HA User’s Guide[MOL]. 2010 [2015-06-15]. http:www.linux-ha.orgdocusers-guideusers-guide.html
[31]Garlan D, Schmerl B. Model-based adaptation for self-healing systems[C]Proc of the 1st Workshop on Self-Healing Systems. New York: ACM, 2002: 27-32
[32]Cheng S W, Garlan D, Schmerl B, et al. Using architectural style as a basis for system self-repair[G]Software Architecture. Berlin: Springer, 2002: 45-59
[33]Garlan D, Cheng S W, Huang A C, et al. Rainbow: Architecture-based self-adaptation with reusable infrastructure[J]. Computer, 2004, 37(10): 46-54
[34]Object Management Group, Inc. OMG Formal Version of QVT. Version 1.1: Meta Object Facility (MOF) 2.0 QueryViewTransformation Specification[R]. 2015 [2015-06-15]. http:www.omg.orgspecQVT1.2
[35]Sherif Y, Bojan C, Hany A. A scenario-based reliability analysis approach for component-based software[J]. IEEE Trans on Reliability 2004, 53(4): 465-480
[36]Vishwanath K V, Nagappan N. Characterizing cloud computing hardware reliability[C]Proc of the 1st ACM Symp on Cloud Computing. New York: ACM, 2010: 193-204
[37]Wu Yihan, Huang Gang. Model-based high availability configuration framework for cloud[C]Proc of the Middleware Doctoral Symp. New York: ACM, 2013: 6-11
[38]Wu Yihan. Research on runtime model-based approach to cloud fault tolerance[D]. Beijing: Peking University, 2015 (in Chinese)(武义涵. 基于运行时模型的云计算容错技术研究[D]. 北京: 北京大学, 2015)

Wu Yihan, born in 1988. PhD from Peking University. His research interests include software reliability, runtime software architecture, cloud availability and fault tolerance.

Huang Gang, born in 1975. Professor and PhD supervisor. His research interests include middleware, software architecture, and Internetware which is a new paradigm for software of Internet as a computer.

Zhang Ying, born in 1982. Research assistant. His research interests include distributed computing with a focus on middleware, the construction and management of middleware, software engineering with a focus on component based development, and mobile computing.

Xiong Yingfei, born in 1982. Received his BS degree from University of Electronic Science and Technology of China in 2004, and his PhD degree from the Department of Information Engineering of University of Tokyo in 2009. He worked as a post-doctoral in University of Waterloo from 2009 to 2011. Assistant professor (Young Talents Plan) at Peking University. His research interests include consistency management.
中图法分类号TP311.5
基金项目:国家“八六三”高技术研究发展计划基金项目(2015AA01A202);国家自然科学基金项目(61222203,61300002)
收稿日期:2015-06-29;修回日期:2015-11-16
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2015AA01A202), and the National Natural Science Foundation of China (61222203, 61300002).
