基于用户兴趣变化的数字图书馆知识推荐服务研究*
2016-04-17曾子明金鹏
曾子明,金鹏
基于用户兴趣变化的数字图书馆知识推荐服务研究*
曾子明,金鹏
针对用户的兴趣变化具有时间敏感性特点,文章提出基于用户兴趣变化的数字图书馆知识推荐模型。首先融合标签和时间等因素,通过用户使用标签的频率以及对资源的标注时间等信息构建用户-资源评分矩阵;然后结合协同过滤算法,计算目标用户最近邻从而完成知识推荐,并在此基础上设计个性化知识推荐服务模型;最后探讨系统知识推荐服务机制及其应用。
数字图书馆 知识推荐 兴趣变化 标签 协同过滤
0 引言
随着大数据时代到来,数字图书馆知识推荐服务面临新挑战。面对海量的知识资源,用户的选择更多,兴趣偏好具有时间性特点,会随着资源增加和自身需求而变化。因此,数字图书馆知识推荐服务需充分考虑用户兴趣的时间迁移特点,以解决用户兴趣的变化对推荐服务质量的影响。国内外学者利用用户对资源项目的评分时间,从而对资源项目设置一个时间衰减函数来反映用户兴趣偏好的潜在变化。邢春晓[1]通过借鉴心理学的遗忘理论,在协同过滤算法中考虑用户对资源项目的具体访问时间,以捕获用户兴趣的变化情况。Schanle M a[2]提出一个指数时间权重函数,结合基于内容的协同过滤算法来反映用户兴趣变化和解决冷启动问题。此外,用户对知识资源所使用的标签能在一定程度上体现出用户对该类知识的兴趣程度以及兴趣变化情况。因此,一些学者利用标签技术来尝试提高推荐系统的知识服务质量。比如,M ichlm ayr等[3]通过对标签进行数据挖掘来构建用户兴趣模型;Taso-Stttle等[4]提出融入用户对资源所贴的标签信息到协同过滤推荐中进行资源推荐的方法。
这些资源推荐方法在考虑用户兴趣变化时,均为单独考虑时间因素,引入时间权重函数捕捉用户兴趣变化或引入社会化标注系统利用标签构建用户兴趣模型等类似方法,而这类方法都有一定的不足。本文提出知识资源推荐模型,其推荐方法融合标签信息和标注时间等因素,能更有效地反映用户兴趣变化的时间敏感性特点,提高推荐系统的推荐质量和数字图书馆的知识服务水平。
1 数字图书馆用户兴趣变化
1.1 用户的视角
在数字图书馆领域,用户的兴趣变化是指用户对某一特定数字资源的关注度或兴趣度随着时间的推移而增加或降低的现象[5]。造成用户之间知识需求差异的原因很多,比如每个用户在性格、心理、思想、兴趣和价值观等方面的不同都会造成用户之间和需求的差异化。一方面用户的行为偏好没有明确的规律性可循,虽然在长期内具有一定的稳定性,但短期内用户的行为偏好大多会有明显变化,特别是在数字知识资源迅猛增长的大数据环境下,这是用户兴趣变化和迁移的重要原因;另一方面,用户的个性受环境影响很大,导致用户行为偏好发生变化,这是用户兴趣变化和迁移的另一个原因[6]。比如,某用户是科研工作者,长期而言,研究方向不会出现太大变化,知识偏好或需求具有一定的稳定性,长期需要获得某类数字资源,即经常下载某类电子文献或多媒体资源;但短期来说,该用户在做不同项目时,其需要的数字文献资源不同。又如,用户所处的情境不同,阅读偏好可能也不同,在咖啡馆,用户可能更偏好于获取电子小说、杂志等娱乐性信息资源;而在阅览室等学习场所更偏好于获得电子文献、期刊等信息资源。
1.2 推荐系统的视角
用户的兴趣偏好是推荐系统进行资源推荐的主要依据,兴趣偏好的变化直接影响数字图书馆知识推荐服务的质量。如果用户兴趣偏好的变化没有被推荐系统及时发现并捕捉到,那么系统无法调整有效的推荐策略来适应用户的兴趣变化,进而影响推荐系统动态地适应用户的变化。这样就不能为用户提供实时且准确有效的个性化知识推荐服务,知识推荐系统的推荐效果会下降。这就是用户兴趣变化或兴趣迁移问题[7]。图1显示了推荐系统角度的用户兴趣变化,目标用户对A类数字资源兴趣度较高,之前一段时间对其评分也较高,而现在更偏好B类数字资源并给出较高评分。因此,推荐系统在进行知识推荐时应区分用户对A类和B类数字资源的评分差别及兴趣迁移问题的重要性,在推荐策略中充分感知用户的兴趣变化。

图1 推荐系统角度的用户兴趣变化
2 基于用户兴趣变化——综合标签时间因素的推荐策略
在数字图书馆海量数字资源的背景下,读者的知识需求不断提高,同时信息服务形态正在从传统的被动型知识搜索向主动型知识分析预测转变。个性化是保障读者知识服务水平的重要条件,用户可根据个性化信息推荐技术提供的一系列策略来构建自己的数字资源馆藏,获取需要的知识资源,以满足个性化的信息需求。根据数字图书馆用户不同的知识服务需求,推荐系统的推荐策略也有所不同。例如,为改善数字图书馆OPAC系统功能,在推荐系统中融入分众分类思想[8];将用户情境和地理位置等因素考虑到移动图书馆的知识推荐系统中,为读者提供个性化和实时性的信息服务,可提高数字图书馆服务效率[9]。本文推荐算法策略主要是将读者给资源所标注的标签的频率和时间信息融入协同过滤推荐算法,改进推荐系统推荐效率的策略,进而提高用户知识服务体验。
2.1 构建“用户-资源”评分矩阵
协同过滤是当前推荐系统中最主流、应用最广且效果最好的方法,其算法基础是用户对推荐对象(数字图书馆知识资源项目)的评分。因此,收集用户对知识资源的评分,继而构建“用户-资源”评分矩阵是首要的步骤。用户对资源的评分一般有显性评分和隐性评分两种,在数字图书馆海量数字资源中,很多知识资源并没有得到用户的显性评分(比如很少有人会下载一篇电子文献用完后对它评分),这就是用户评分稀缺性问题,通常会通过隐性评分的方法来解决。传统的用户对资源评分是用m×n阶矩阵来表示m个用户对n个资源项目的评分,其中m为用户的个数,n为资源项目的个数,矩阵中的Rij即为用户i对资源项目j的评分。
本文提出综合标签时间因素的推荐方法,如何利用标签和时间信息产生用户对知识资源的评分值是构建“用户-资源”评分矩阵的关键。“用户-资源”评分矩阵,主要通过三步策略:①标签评分权值策略:依据用户给知识资源贴的标签和使用标签的频率来构建;②时间评分权值策略:采用自适应性指数衰减函数的办法来自动地估量和追踪每个读者的兴趣漂移情况,并构建时间评分权值,发现用户最近兴趣;③融合标签时间因素评分策略:通过结合标签时间信息即结合标签和时间评分权值构建“用户-资源”评分矩阵。
2.1.1 标签评分权值
一般来说,用户对某一知识资源使用的标签次数越多,表明对该资源的兴趣程度越大,即用户可能更偏好于经常使用标签标注的知识资源。此外,用户也会倾向于使用相同的标签描绘同种知识资源来表达兴趣偏好。标签评分权值也就是基于这样的假设条件下提出来的,可以定义为:

其中,tag(u,r)为用户u给知识资源r标记的所有标签的集合;Wu,ta为标签集tag(u,r)中的每一个标签ta对知识资源的评分值;Wtag(u,r)为标签评分权值,用来衡量读者u对已标注知识r的兴趣偏好程度。
用户对知识资源使用每个标签的评分值通过用户使用标签的频率来反映,采用下面的方式计算出来:

其中,freq(u,ta)代表着用户u使用标签ta标注知识资源的次数;k为用户用于标注知识资源的标签的总数量,Wtag(u,r)∈[0,1],用户的兴趣程度可以通过计算标签评分的权值大小来掌握,标签评分权值越高,用户对此知识资源越感兴趣。
2.1.2 时间评分权值
考虑用户对知识的兴趣具有随时间变化的特点,本文借鉴Cheng等[10]提出的自适应指数衰减函数来处理知识推荐系统中标签的时间信息,其定义为:
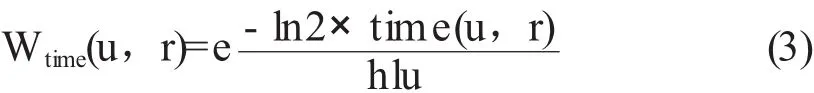
其中,Wtime(u,r)为时间评分权值,表示用户对知识的兴趣衰减程度;tim e(u,r)≥0,且∈N。当tim e(u,r)=0时,表示用户u对知识资源r最后的标注时间;tim e(u,r)=1时,表示该用户对知识资源倒数第二次的标注时间,以此类推。hlu是用户u的半衰期,其值随着用户的知识获取行为周期而有所不同。用户的行为周期较短,其对某类知识资源的兴趣度会下降得比较快,而对于那些行为周期更长的用户,他们对知识资源的兴趣变化就比较慢。Wtime(u,r)是对tim e(u,r)的单调递减函数,所以用户最近打标签的知识资源能够被赋予更大的权重,而早期的给知识资源标注的标签则评分权值较小,用户最近的兴趣通过这种方法就能很好地被发掘出来。
2.1.3 综合标签时间权值用户评分策略
本文利用用户对数字图书馆知识资源的标签和时间信息构建知识资源推荐模型,提出整合标签和时间评分权值的用户评分为:

其中,参数λ为调和因子,用于调整Wtag(u,r)和Wtime(u,r)两者的权重。这样考虑使用的标签信息可以得到用户对知识的偏好程度,而把知识资源的标注时间信息融合到资源评分中,能反映用户的兴趣漂移,不仅能更加准确地表示用户的知识偏好信息,也能很好地反映用户目前的主要兴趣偏好。与传统用户-资源评分矩阵的构建不同,本文提出的知识推荐综合利用标签和时间信息构建的评分矩阵能够在一定程度上解决评分稀缺性问题,也能在大数据环境下海量数字资源中反映用户的兴趣变化。
2.2 用户相似度计算
计算用户的相似性是协同过滤算法的核心,也是最关键的一步。通过用户对知识资源的评分可以找到与当前用户兴趣相似的邻居用户,生成目标用户的最近邻居集,然后根据邻居用户的偏好进行知识推荐。用户相似度计算常用的相似性度量标准有皮尔逊相关系数[11],余弦相似度[12]等。本文采用余弦相似度作为相似度度量标准计算用户相似度:

2.3 预测评分,生产Top-N推荐
根据相似度计算结果,对相似度降序排列,取前K个为当前用户的最近邻U,根据最近邻集可以预测用户a对项i的评分。根据当前读者的K个最近邻对目标知识项目的评分信息来预测当前读者的评分,并选择预测评分最高的前n个知识项目推荐给该读者,即产生Top-N推荐[13]。

3 基于用户兴趣变化的知识推荐服务模型
3.1 知识推荐模型构建
根据数字图书馆用户的知识个性化需求,并充分感知用户兴趣变化,融合用户标注资源的标签以及标注的时间,本文设计基于用户兴趣变化的知识推荐模型,采取融合标签和时间因素的协同过滤推荐方法。该推荐模型旨在为用户在浩如烟海的数字图书馆知识资源中,获取符合即时兴趣偏好的个性化知识资源,如图2所示。
3.2 知识推荐服务
基于用户兴趣变化的知识推荐流程是:(1)数字图书馆的用户在检索资源或浏览图书馆推送的资源时,根据自身偏好给资源打标签,利用用户标注行为提供的标签信息和时间信息构建“用户-资源”评分矩阵,作为协同信息推荐的基本组成部分。用户的个人信息、借阅信息以及数字图书馆资源信息全部存储在数字图书馆的大数据资源库中。(2)对大数据资源库的数据资源进行数据分析、数据挖掘,形成对用户有价值的知识资源,存储在知识库中。(3)用户通过图书馆知识检索界面或其他知识界面获取知识时对知识打的标签反馈到用户-知识-标签系统中,为系统进行知识推荐做准备。(4)知识推荐系统部分,根据用户的知识需求及其知识行为对用户进行聚类,然后用知识评分矩阵计算用户之间的相似度,找出每一个用户的最近邻居,即计算目标用户的邻居(即具有相似偏好的用户),从而获得目标用户及其相邻用户的信息需求。(5)根据用户-资源评分数据集中相邻用户的资源使用历史数据,并结合目标用户的信息需求,将排名前Top-N的资源推荐给目标用户。(6)推荐系统把推荐资源主动推送给目标用户,在这一过程中,目标用户如果对这些资源标注新的标签,可以反馈到知识-标签系统,作为对其以后进行知识推荐的基础数据。(7)系统动态、重复执行以上4个步骤,从而实现数字图书馆对各用户的个性化知识推荐及其推送服务。
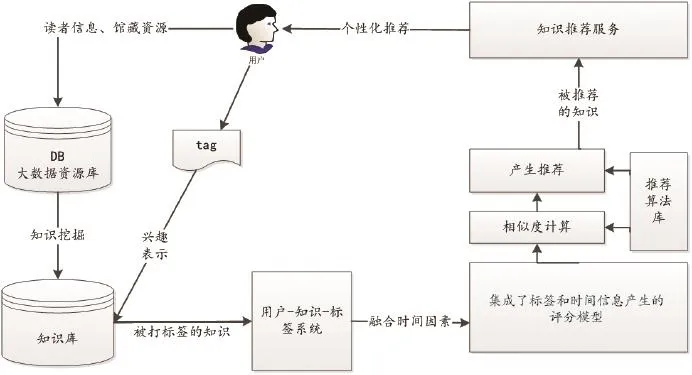
图2 基于用户兴趣变化的知识推荐模型
3.3 数字图书馆个性化知识推荐服务的应用
大数据时代到来,数字图书馆信息资源膨胀,图书馆知识服务面临信息过载、知识迷航等困境。同时读者的知识需求不断提高,需要在任何时间和地点便捷、高效获取数字资源。大数据环境下数字图书馆知识推荐应能捕捉到用户兴趣偏好的变化,根据时间标签的推荐机制提高数字图书馆推荐系统服务质量。因此,本文提出的知识推荐融合了标签和时间信息,能较好地感知用户的偏好情境,实时地获取用户的偏好数据。
随着物联网、云计算等技术的发展,本文提出的推荐服务能为用户提供更高层次的个性化知识服务。具体来说,可以在两方面进行服务模式的应用和拓展:(1)目前图书馆普遍采用物联网和RFID等技术。知识推荐系统能够利用这些技术,根据采集和扫描的数据结果获取用户的身份、用户知识检索、知识标注频率和时间等一系列信息,在此基础上将这些数据信息在经过后台数据分析后判断读者的文献或者借阅兴趣偏好,从而将读者感兴趣的知识资源通过移动设备等个性化地推送给读者。(2)用户利用移动设备连接无线网络,图书馆突破时空限制,可随时随地访问图书馆资源。因此知识推荐服务也可应用于移动阅读领域,实时适应用户兴趣、情境、地理位置等变化,并将用户给数字资源打的标签信息反馈到用户-知识-标签系统中,由推荐系统实时个性化地将数字资源推送到移动设备上。泛在知识推荐加强了读者与图书馆的交互。
4 结语
在大数据时代,数字图书馆对用户的阅读兴趣、阅读行为方式、阅读需求以及阅读满意度等有更精准的预判和更周到的服务。图书馆需深入挖掘各类知识资源特别是数字信息资源所隐含的数据价值,树立以人为本的服务理念,并以读者个性需求和大数据科学分析结果为依据,为读者提供安全、高效、满意、低碳的个性化大数据阅读服务。传统推荐模型忽略了用户兴趣随着时间变化而变化,针对用户兴趣的偏好习惯具有一定的时间转移的特性,本文结合用户标注行为,重点考虑反映用户行为的几个特征,如标签频率、标签时间。用户使用的标签频率与用户偏好的项目之间有着极大的联系,用户的兴趣会随着时间而有所改变,研究用户对使用标签项目的标注时间,构建了基于标签和时间权值的资源评分矩阵,然后构建了基于用户兴趣变化的知识推荐模型,并阐述系统知识推荐服务机制及其应用。
[1]邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[2]MaS,LiX,Ding Y,etal.A recommendersystem w ith interest-drifting[M].W eb Information Systems Engineering W ISE 2007.Springer Berlin Heidelberg,2007:633-642.
[3]M ICHLMAYR E,GAYZER S.Learning user profiles from tagging data and leveraging them for personal(ized)information access[C]//Proc of the6th InternationalW orld W ideW eb Conference.New York:ACM Press,2007.
[4]TSO-SUTTER K H L,MSR INHO L B,SCHM IDT-THIEME L S.Tag aware recommender systems by fusion of collaborative filtering rithms[C] //Pros of ACM Symposium on Applied Computing. New York:ACM Press,2008:95-99.
[5]于洪,转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报(自然科学版),2010,46(5):520.
[6]Liu Q,Chen E,Xiong H,etal.Enhancing collaborative filtering by user interestexpansion viapersonalized ranking[J].Systems,Man,and Cybernetics,Part B:Cybernetics,IEEE Transactionson,2012,42(1):218-233.
[7]郑运刚,马建国.基于分类的用户兴趣漂移模型[J].情报杂志,2008(1):37-39.
[8]蒋若珊.基于SOM聚类的个性化图书推荐研究[J].现代情报,2011,31(5):146-148.
[9]张兴旺,李晨晖,麦范金.变革中的大数据知识服务:面向大数据的信息移动推荐服务新模式[J].图书与情报,2013(4):74-78.
[10]CHENG Yuan,QIU Guang,BU Jia-jun,et al. Model bloggers'interestsbased on forgettingmechanism [C]//Prosofthe17th lnternationalConferenceonW orld W ide W eb.New York:ACM Press,2008:1129-1130.
[11]Shardanand U,Maes P.Social Information Filtering:Algorithmsfor Automating’wordofmouth’[C].In Proc. of the Conf.on Human Factorsin Computing Systems,2009.
[12]Sarwar B,Karypis G,KonstanJ,et al.Item-based Collaborative Filtering Recommendation Algorithms[C]. In Proc.of the 10 the InternationalWWWConference,2013.
[13]Breese JS,Heckerman D,KadieC.EmpiricalAnalysis of Predictive Algorithm for Collaborative Filtering[C] //Proceedingsof the 14th Conference on Uncertainty in Artificial Intelligence(UAI'98).San Francisco:Morgan Kaufmann Publisher,2009:43-52.
Research on Know ledge Recommendation Service of Digital Library Based on Users’Interest Drift
ZENG Zi-ming,JIN Peng
In view of the time sensitivity ofusers’interestdrift,this paper presentsa knowledge recommendation model for digital library based on users’interest drift.Firstly,it colligates tags and time factors,through the usage frequency and marking time of tags to construct a user resource evaluation matrix,then combines with collaborative filtering algorithm,and calculates the target user’s nearest neighbor set and conducts knowledge recommendation.On the basisof the above considerations,itdesigns the personalized knowledge recommendation servicemodel.Finally,knowledge recommendationmechanism and application ofsystem are discussed.
digital library;knowledge recommendation;interestdrift;tag;collaborative filtering
格式曾子明,金鹏.基于用户兴趣变化的数字图书馆知识推荐服务研究[J].图书馆论坛,2016(1):94-99.
曾子明,男,博士后,武汉大学信息管理学院教授;金鹏,男,武汉大学信息管理学院硕士研究生。
2015-05-26
*本文系教育部人文社科重点研究基地重大项目“商品评论源信息获取方法与技术研究”(项目编号:14JJD870002)和国家自然科学基金项目“泛在环境下基于情境感知的信息多维推荐服务模型与实现研究”(项目编号:71103136)研究成果之一
