基于可变隶属度的模糊双支持向量机研究
2016-03-17任建华刘晓帅孟祥福
任建华 刘晓帅 孟祥福 王 伟
(辽宁工程技术大学电子与信息工程学院 辽宁 葫芦岛 125105)
基于可变隶属度的模糊双支持向量机研究
任建华刘晓帅孟祥福王伟
(辽宁工程技术大学电子与信息工程学院辽宁 葫芦岛 125105)
摘要双支持向量机是一种新的非平行二分类算法。其处理速度比传统支持向量机快很多,但是双支持向量机没有考虑不同输入样本点会对最优分类超平面产生不同的贡献。在测试阶段测试点到两类超平面的距离相等时,双支持向量机也没有明确给出对这些等距点的处理方法。针对这些情况,提出一种可变隶属度的模糊双支持向量机。距离类中心较近的样本点隶属度由其到类中心的距离决定,距离类中心较远的样本点隶属度由其到类中心的距离和它的紧密度共同决定。在测试阶段出现等距点时,根据等距点与各类训练点的等价性比例进行分类。实验结果表明,与支持向量机、标准双支持向量机、双边界支持向量机、混合模糊双支持向量机相比,这种可变隶属度模糊双支持向量机分类精度最高。
关键词双支持向量机支持向量机等距点等价性比例模糊隶属度分类
RESEARCH ON OPTIONAL MEMBERSHIP-BASED FUZZY TWIN SUPPORT VECTOR MACHINE
Ren JianhuaLiu XiaoshuaiMeng XiangfuWang Wei
(School of Electronics and Information Engineering,Liaoning Technical University,Huludao 125105,Liaoning,China)
AbstractTwin support vector machine is a novel nonparallel binary classification algorithm, and its processing speed is much faster than the traditional support vector machines, but the twin support vector machine does not consider that different input sample points will have different contribution on optimal classification hyperplanes. When the distances between test points and two kinds of hyperplanes are equal in test phase, the twin support vector machine does not explicitly give the treatment approach for these equidistant points. In view of this, this paper proposes an optional membership-based fuzzy twin support vector machine. The membership of sample point closer to the class centre is determined by the distance between the point and the class centre, while the membership of sample point farther to the class centre is jointly determined by the distance of the point to class centre and the affinity of point. During the testing phase, if the equidistant points appear, they can be classified according to the equivalence ratio of equidistant points with various test points. Experimental results show that compared with the support vector machine, standard twin support vector machine, twin-bounder support vector machine and fuzzy twin support vector machine, this optional membership-based fuzzy twin support vector machine has highest classification accuracy.
KeywordsTwin support vector machineSupport vector machineEquidistant pointsEquivalence proportionFuzzy membershipClassification
0引言
支持向量机[1-3]SVM是Vapnik等人提出的一种用于解决二类问题的监督学习方法。它建立在结构风险小化原则基础之上,具有很强的学习能力和泛化能力,所以支持向量机已经被广泛地应用于现实的场景中[4,5]。SVM的核心原理是通过解一个二次规划问题来得到一对平行的最大间隔超平面,从而将两类样本尽可能地分开。近年来一些基于不平行超平面的分类算法被提出,例如,2006年Mangasarian[6]等人提出了广义特征值近似支持向量机GEPSVM(Proximal Support Vector Machine via generated Eigenvalues)和2007年Jayadeva[7]提出了双支持向量机[8,9]TWSVM(Tw -in Support Vector Machine)。
对于双支持向量机,其核心思想是寻找一对非平行的超平面,其中的一个超平面离一类尽可能的近而离另一类尽可能的远。双支持向量机与传统支持向量机根本的区别是双支持向量机解决两个规模相对更小的二次规划问题。而传统支持向量机解决一个规模较大的二次规划问题,所以双支持向量机能将训练时间约减到传统SVM的1/4[10]。后来不同的学者对双支持向量机进行了不同的改进,例如2011年Shao Y H等人提出了一种有边界的双支持向量机,即双边界支持向量机TBSVM(Twin Bounded Support Vector Machine)[11]。通过增加规则化条件,采用结构风险最小原则在一定程度上提高了模型的识别率;同年Peng X J[12]等人提出了一种双参数双支持向量机,在一定程度上解决了样本分布不平衡问题;2013年丁胜峰[13]等人提出了一种混合模糊双支持向量机HFTSVM(Hybrid Fuzzy Twin Support Vector Machine),其隶属度函数是距离与紧密度的结合,在一定程度上减少了野点和噪声的影响。以上双支持向量都没有考虑到测试点到两个分类超平面的距离相等的现象,所以会出现一些错分点,影响分类精度。为解决以上不足,进一步提高分类精度和分类效率,简化计算,本文在双边界支持向量机和模糊双支持向量机的基础上提出一种可变隶属度模糊双支持向量机OFTSVM(Optional Fuzzy Twin Support Vector Machine)。该算法根据样本点到对应类中心距离的不同确定不同类别的隶属度函数,距离类中心较近的样本点隶属度由其到类中心的距离决定,距离类中心较远的样本点隶属度由其到类中心的距离和它的紧密度共同决定。由此为不同的样本点赋予不同的隶属度,即减少了一定量的计算也减小了噪声或野点对分类结果的影响,抑制过学习现象的发生。在测试阶段出现等距测试点时,根据测试点属性与各类训练点属性相同的比例(等价性比例)对这些等距测试点分类,减少错分现象的发生,提高分类精度。实验结果表明,这种可变模糊双支持向量机在分类时间可行的情况下,分类性能最好。
1双支持向量机
对于二分类问题,双支持向量机是一种效率很高的算法。它基于GEPSVM思想,通过求解两个规模更小的二次规划问题来获得到一对非平行超平面,使得每一个超平面离一类尽可能的近而离另一类尽可能的近。其训练学习的目的就是寻找两个非平行超平面,并且规定样本点只属于两类中的一类。
双支持向量机分线性和非线性两种情况,但求解原理是一样的。线性情况比较简单,本文给出的双支持向量机都是在非线性情况下的,给定样本集{xi,yi},i=1,2,…,l,只能有yi=+1或yi=-1。假设矩阵A∈Rl1×n表示属于+1类的样本点,矩阵B∈Rl2×n表示属于-1类的样本点,l1、l2分别为样本数目,l1+l2=l,则双支持向量机的训练学习过程转化为优化问题:

(1)

(2)
其中e为全为1的列向量,b+、b-为偏移量,c1、c2为对错分样本的惩罚因子,ξ+、ξ-为惩罚因子,C=[AB],K为满足Mercer条件的核函数[14]。通过拉格朗日函数把优化问题转化为它的对偶问题:

(3)

(4)
其中S=[K(A,CT)e],R=[K(B,CT)e],所以决策函数为:
(5)

假如输入一个新的样本点,就可以根据这个样本点到两个分类超平面的垂直距离来判断其属于那一类。如果该样本点到+1类超平面的垂直距离大于它到-1类超平面的垂直距离,则该样本点被分到-1类中;如果该样本点到+1类超平面的垂直距离小于它到-1类超平面的垂直距离,则该样本点被分到+1类中。
2模糊双支持向量机
在实际分类中,由于数据本身的不确定性(主要是包括噪声和孤立点),往往分类精度不高。针对这个问题,有学者根据模糊理论提出了模糊隶属度,再将其引入到支持向量机中,进而有了模糊支持向量机。这样根据样本点对分类的影响不同而为其赋予不同的隶属度,从而抑制噪声对分类的影响。双支持向量机同样可以为每个样本点赋予不同的隶属度来提高分类精度,这就是模糊双支持向量机。
2.1可变模糊隶属度
自从模糊支持向量机提出以后,隶属度函数的设计方法层出不穷,并且没有可遵循的规律。有的学者基于距离[2],有的基于紧密度[15],但这两种隶属度设计方法都比较单一,对样本的隶属度描述不是很准确。后来又有学者又提出了基于距离和紧密度的隶属度设计方法[13]。但是在此算法中把每个样本点的紧密度都计算出来,计算量是非常大的,并且在距离类中心较近的样本点是比较紧密的,所以再计算其紧密度是没有太大意义。在此提出一种可变模糊隶属度,距离类中心较近的样本点隶属度由其到类中心的距离决定,距离类中心较远的样本点隶属度由其到类中心的距离和它的紧密度共同决定。
定义1样本点在在特征空间的中心
(6)
其中,Φ是从原始空间到高维空间的非线性映射。
定义2样本点到各自类中心的距离
di+=‖Φ(xi)-O+‖di-=‖Φ(xi)-O-‖
(7)
定义3样本到各自类中心的最远距离为类半径

(8)
定义4样本点之间的距离
dij=‖Φ(xi)-Φ(xj)‖
(9)
则基于距离的隶属度为:
(10)
δ>0且足够小,取离xi最近的k个样本点:
(11)
M=max(m1,m2,…,ml)
(12)
则基于紧密度的隶属度为:
(13)
则可变隶属度为:
其中0<θ<1。
2.2可变隶属度模糊双支持向量机
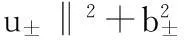
给定样本集{xi,yi},为每个样本点计算其隶属度si,把si作为权值加入到样本集中,这时样本集就变为{xi,si,yi},则优化问题:
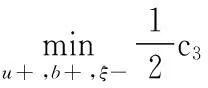
(14)

(15)
其中c1、c2、c3、c4都为惩罚因子,SA、SB表示正负样本的隶属度组成的向量,采用拉格朗日乘子法求解优化问题,则其对偶问题为:

(16)
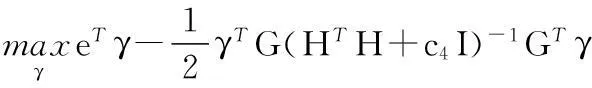
(17)
其中,H=[K(B,CT)e],G=[K(A,CT)e]。
[u+,b+]T=-(GTG+c3I)-1HTα
(18)
[u-,b-]T= (HTH + c4I)-1GTγ
(19)
从对偶问题中可以看出,变量α、γ不同于标准双支持向量机的变量。此处的α、γ的上界是随隶属度变化的,相当于不同的样本点使用不同的惩罚因子,这样使得分类面对重要数据的分类精度明显提高。
只要解出式(18)、式(19)就能可以求出决策函数:
(20)
此决策函数与式(5)看起来是一样的,但实际上[u±,b±]T的值是不一样的,只是形式一样。假如输入一个新的样本点,就可以根据这个样本点到两个分类超平面的垂直距离来判断其属于那一类了。但是如果当样本点到两个分类超平面距离相等时,标准双支持向量机没有给出明确的分类方法,在此称这样的点为等距点。
2.3等距点的处理
由于数据的不确定性,在分类过程中会出现等距点。双支持向量机又规定样本点只能属于两类中的其中一类,对于这些等距点,双支持向量机进入一个盲区,影响分类精度。如果是随机分类,有可能属于+1类的点被随机分到了+1类。但是也有可能属于+1类的点被分到-1类,属于-1类的点被分到+1类,这样就会出现错分现象。针对这种现象,为进一步提高分类精度,本文根据等距点与各类训练点的属性等价性比例[16]对这些等距点进行再分类。
定义5属性等价性比例是描述样本点之间有效联系的参数:
(21)
其中,a表示样本点属性集合,Ci(a)表示样本点与其他样本点属性相等的个数,Ni(a)该样本点总的属性个数。
当分类中出现等距点时,分别计算该等距样本点与各类所有训练样本点的属性等价性比例,记为qi+,qi-。等价性比例越高说明该等距点与该类的训练样本点联系性越高,越有可能属于该类。即如果qi+>qi-,则该等距点就会被分到+1类,如果qi+ 3实验与分析 3.1实验数据与实验环境 为了验证本文算法的性能,在此选用两种数据集进行实验,即人工数据集和标准数据集。人工数据集是由计算机随机长生的500个二维空间样本点,记为D;标准数据集是在UCI[17]数据库中选择的几组数据,如表1所示,记为U。 表1 标准数据集 实验环境是在Intel(R) Core(TM) i5-3230M CPU @2.6 GHz, 4 GB内存, 500 GB硬盘和Microsoft Windows7操作系统,使用Matlab V7R14工具实现算法。 3.2含噪声的人工数据实验 表2 人工数据集分类结果 从实验结果可以看出,本文算法的分类精度最高,分类精度比标准双支持向量机(TWSVM)高5个百分点,比双边界支持向量机(TBSVM)高3个百分点,也比混合模糊双支持向量机(HFTSVM)高一个百分点。这是由于本算法为每个样本点赋予不同的隶属度。同时对等距点进行再分类,这样提高了分类精度。分类时间与TWSVM几乎相同,远少于SVM,比混合双支持向量机(HFTSVM)有所减小。这是由于本文算法采用可变隶属度,比HFTSVM节省了一定的计算量,即为核参数和惩罚参数的确定节省一定的计算开销,本算法对等距点的处理也增加了少量的计算量,但本文算法的总体分类性能是最好的。 3.3标准数据集实验 与人工数据集的实验一样,本算法与其他四种分类算法进行比较。在标准数据集中取前10%的数据集作为训练样本,其余的作为测试样本,依然采用高斯核函数作为本实验的核函数,最终确定最佳参数σ=5,c1=50,c2=80,c3=40,c4=75,θ=41%,分类精度如表3所示,分类时间如表4所示。从表3可以看出,在Sonar数据集上,本文算法与HFTSVM算法的分类精度几乎相等,但比TWSVM高3个百分点;在Pima-Indian数据集上,本文算法分类精度最高,比HFTSVM算法高3个百分点,比TWSVM高5个百分点。从表4可以看出,在Sonar数据集上,本文算法分类时间与HFTSVM的分类时间几乎相等,但比TWSVM多4.2 s;在Pima-Indian数据集上的,本文算法分类时间比HFTSVM少2.6 s,比TWSVM多1.4 s,可以看出本文算法在分类时间可行的情况下,分类精度有一定的提高,所以本文算法是有效的。 表3 所选数据集的分类精度结果(%) 表4 所选数据集的分类时间结果(s) 3.4扩展分析 从表3中可以看出,随着数据集的增大分类精度越来越高,但是随着数据集的增大,本文算法分类精度增长率最大。同时从表4可以看出随着数据集的增大分类时间也相应的增加,但随着数据集的增大,本文算法分类时间增长的相对较小,这说明本文算法在数据集较大时有很大的优势。 4结语 本文在引进可变隶属度的同时也对等距点进行再分类,简化了少量计算,为不同的样本点赋予不同的隶属度,提高了抗噪性能,减少错分现象的发生,提高了分类精度。实验结果表明,在分类时间可行的同时,分类精度值也比标准双支持向量机也有了提高,因此本算法优于标准双支持向量机。由于在本文算法中涉及了多个参数,参数之间的联系是以后需要研究的问题。 参考文献 [1] Vladimir N Vapnik.统计学习理论的本质[M].张学工,译.北京:清华大学出版社,2000. [2] 李凯,李娜,卢霄霞.一种模糊加权的孪生支持向量机算法[J].计算机工程与应用,2013,49(4):162-165. [3] 王晓丹,王积勤.支持向量机训练和实现算法综述[J].计算机工程与应用,2004,40(13):75-78. [4] 余辉,赵晖.支持向量机多类分类算法新研究[J].计算机工程与应用,2008,44(7):185-189. [5] 靳玉萍,张兵,高凯.球形支持向量机在煤自燃预测中的应用[J].计算机应用与软件,2013,30(9):57-60. [6] Mangasarian O L,Wild E W.Multisurface proximal support vector machine classification via generalized eigenvalues[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(1):69-74. [7] Khemchandni R,Suresh C.Twin support vector machine for pattern classification[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2007,29(5):905-910. [8] Tian Y J,Shi Y,Liu X H.Recent advances on support vector machines research[J].Tech Econ Develop Econ,2012,18(3):5-33. [9] Qi Z Q,Tian Y J,Shi Y.Robust twin support vector machine for pattern classification[J].Pattern Recognition,2013,46(1):305-316. [10] Ye Qiaolin,Zhao Chunxia,Ye Ning.Least squares twin support vector machine classification via maximum one-class within class variance[J].Optimization Methods & Software,2012,27(1):53-69. [11] Shao Y H.Improvements on twin support vector machines[J].IEEE Transactions on Neural Networks,2011,22(6):962-968. [12] Peng X J.A novel twin parametric-margin support vector machine for pattern recognition[J].Pattern Recognition,2011,44(10):2678-2692. [13] 丁胜峰,孙劲光.基于混合模糊隶属度的模糊双支持向量机研究[J].计算机应用研究,2013,30(2):432-435. [14] 刘华富.支持向量机Mercer核的若干性质[J].北京联合大学学报,2005,19(1):40-42. [15] 张翔,肖小玲,徐光祐.基于样本之间紧密度的模糊支持向量机方法[J].软件学报,2006,17(5):951-958. [16] 梁宏霞,闫得勤.粗糙支持向量机[J].计算机科学,2009,36(4):208-210. [17] Blake C L,Merz C J.UCI Repository for machine learning databases[EB/OL].(1998-01-12).IrvineCA: University of California,Department of Information and Computer Sciences.http://www.ics.uci.edu /mlearn /MLRepository.html. [18] Han Jiawei,Micheline Kamber,Jian Pei.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2012. 中图分类号TP3 文献标识码A DOI:10.3969/j.issn.1000-386x.2016.02.033 收稿日期:2014-08-07。国家自然科学基金青年科学基金项目(61003162);辽宁省教育厅项目(L2013131)。任建华,副教授,主研领域:数据库系统,数据挖掘等。刘晓帅,硕士生。孟祥福,副教授。王伟,讲师。