基于CRP模型的聚类算法
2016-03-10白云鹏
白云鹏
【摘要】 关于聚类问题现在已经有很多方法可以实现,但大多数基于有限混合模型的聚类方法需要预先估计聚类的个数,因而聚类的准确性和泛化性会受到一定影响。本文则提出了一种基于无线混合模型——中国餐馆模型(CRP)的聚类方法,CRP模型是Dirichlet过程的一种表示方法,基于Dirichlet无线混合模型找出其后验分布,利用Gibbs采样MCMC方法估计出模型中各个参数以及潜在的聚类个数,并在MATLAB环境下进行一个小实验来验证聚类的效果。
【关键词】 聚类 CRP模型 Dirichlet过程 MCMC采样
一、引言
聚类顾名思义就是把事物按照特定的性质或者相似性进行区分和分类,在这一过程中不指导,属于无监督分类。作为一种重要的数据分析方法,聚类分析问题在很久以前就已经为人们所研究,并且已经取得了一定成果,目前的算法已经能对一般简单的聚类问题做出很好的聚类结果。但随着大数据时代的到来,实际应用中的数据越来月复杂,如基因表达数据,交通流数据,web文档等,有一些数据还存在着极大的不确定性,有的数据可以达到几百维甚至上千维,受“维度效应”的影响,很多在低维空间能得到很好结果的聚类算法在高维空间中并不是十分理想。
关于高维数据的聚类近几年一些基于有限混合模型的方法取得了很有效的成果。但是这些算法需要提前估计聚类个数的前提下,根据样本的属性进行分析分类。本文采用了一种基于Dirichlet无线混合模型的方法,利用CRP模型和Gibbs采样方法,在分析过程中找出潜在的聚类个数,实现对数据的聚类。
二、CRP模型
2.1 关于CRP
CRP模型是Dirichlet过程的一种表示方法,它是关于M个顾客到一家中国餐馆如何就坐问题的一个离散随机过程。具体描述如下:有一家中国餐馆,假设有无限个桌子,并且每张桌子上可以容纳无限个顾客,每一个顾客到来时可以随意选择一个餐桌,也可以自己新开一个餐桌。在CRP过程中,我们把每一位到来的顾客都当作最后一位来看待,有如下分配过程:第一位顾客到来,一定会开一个桌子自己坐下,第二个顾客到来时,以一定概率坐在第一个人开的桌子上,一定概率新开一张桌子,第三个顾客到来时,有一定概率坐在第一、二个人开的桌子上,也可以开第三张桌子……以此类推,具体定义的概率如下:
其中α是狄利克雷的先验参数; c 是第m 个顾客选择的餐桌上已有的顾客人数。顾客选择餐桌时不仅与顾客对餐桌的个人情感有关,还与该桌上在座的顾客关系有关,如果是朋友或是认识的人就算有更好的选择顾客也可能选择与朋友坐一桌。而在CRP模型中并未考虑到顾客的情感色彩因素。
2.2 Gibbs Samping
Gibbs Sampling是一种马尔可夫蒙特卡罗方法(MCMC),这种方法广泛应用于离散随机过程的采样处理,它的中心思想就是由一个具有2个或更多变量的联合概率分布P(x1,x2,…,xn),生成一个样本序列{y1,y2,…,ym},用于逼近这一个联合分布,或计算一个积分(例如期望)。
关于Dirichlet混合模型的Gibbs Sampling实际上就是根据先验求后验的过程,虽然中心思想一样,但具体实现方法有很多种[1],这里根据CRP的情况,选择其中一种算法,在下一节详细讲解。
2.3 参数估计
假设有一个整体的数据集D={xi}in=1,它的两个参数为z=(z1,…,zn),zn∈{1,…,K},φ=(φ1…,φK)
其中Z为隐变量,表示样本聚类的标签,Zi=k代表当前第i个类有k个成员,而φ则是该模型的每一类的成员参数,根据贝叶斯理论,可以得出p(φ,z|D)∝p0(φ)p0(z)p(D|φ,z),因此,参数φ后验分布可以通过计算其先验分布及似然函数来实现,在此基础上计算出φ的后验分布,并通过Gibbs采样的方法更新参数φ。
其中nk代表当前坐在第k个桌子上的其他人的总数。
2.4 使用Gibbs采样的算法
假设待处理的数据是高斯随机分布的,首先随机初始化参数z,φ。
对于每一个zi才用如下采样方法:
选择已有桌子(第K个)的概率: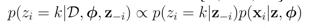

新开一个桌子(第K+1)的概率:
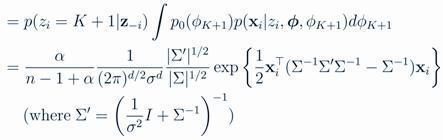
而对于参数φ,采用如下方式(每当第k个桌子上加了人,这个类的参数φk就要更新):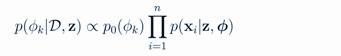
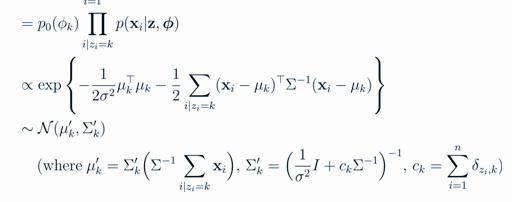
三、实验与结果
本文以matlab为平台,对二维空间上一些随机分布的点进行模拟聚类测试。正如上一节所说,这里对测试数据采用高斯随机来生成,为了简化处理,生成了300个各项同向高斯分布的点,具体代码如下:


这样就默认把这300个点分成了潜在的3个类,我们最后要求出的结果应该就是K=3。实验结果发现,真正的结果与Dirichlet过程CRP模型的集中度参数α有很大关系。α很大的时候会不准确,我在这里让α随机选取,并重复了100次,最后一次的结果是k=4:
而根据α的不同取值,100次的聚类结果在3-6之间,其中还是以3居多:
由此可知,对于Dirichlet先验参数α的选择会直接影响到最终的聚类效果。而Dirichlet过程作为一个无线混合模型,随着数据的增多,模型的个数是呈现log 增加的,即模型的个数的增长是比数据的增长要缓慢得多的。同时也可以说明Dirichlet过程是有一个马太效应在里面的,即“越富裕的人越来越富裕”,每个桌子已有的人越多,那么下一次被选中的概率越大,因为与在桌子上的个数成正比的,因而这种无线混合模型对于发现潜在的聚类个数会有很好的效果。
四、总结
基于CRP模型的聚类方法不同于先前的有限混合模型,无需预先估计聚类的个数,而是在分析过程中自动确定。聚类的结果与α有关,所以选取合适的集中度参数很重要。关于CRP模型现在的研究还不是很广泛,也有一些在主题模型中的应用,比如基于CRP模型的词汇分类,实现主题模型等。相信在不远的将来,这种利用无线混合模型的聚类方法会有更多的开拓空间。
参 考 文 献
[1] 张林,刘辉. Dirichlet过程混合模型的聚类算法[J]. 中国矿业大学学报. 2012(01)
[2] 张小平,周雪忠,黄厚宽,冯奇,陈世波. 基于词相似性与CRP的主题模型[J]. 模式识别与人工智能. 2010(01)[3] 罗辉停. 基于CRP模型的评论热点挖掘研究修正版[J]. 技术与创新管理. 2012(02)
[4] 易莹莹. 基于Dirichlet过程的非参数贝叶斯方法研究综述[J]. 统计与决策. 2012(04)
[5] Pruteanu-Malinici I,Ren L,Paisley J,Wang E,Carin L.Hierarchical Bayesian modeling of topics in time-stamped documents. IEEE Transactions on Pattern Analysis and Ma-chine Intelligence . 2010
[6] H. Ishwaran,M. Zarepour.Markov Chain Monte Carlo in approximate Dirichlet and beta two-parameter process hierarchical models. Biometrika . 2000
[7] R Thibaux,M I Jordan.Hierarchical beta processes and the indian buffet process. Proceedings of International Conference on Artificial Intelligence and Statistics . 2007
