基于MT-LDA的音乐标签主题检索
2016-02-27徐芸芝
徐芸芝,邵 曦
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
基于MT-LDA的音乐标签主题检索
徐芸芝,邵 曦
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
随着协同标注功能的普及,用户可以通过对自己感兴趣的音乐进行标注从而实现个性化的分类管理,因此音乐共享系统中的社会化标签已成为互联网的重要资源。考虑到社会化标签的特性及其对音乐信息检索系统的影响并综合考虑了用户的检索行为、歌词和音乐标签,利用MT-LDA方法对标签进行聚类以获取主题类别,从而进行分析得出检索主题,提高音乐信息检索系统的效率和性能。实验结果表明:在没有属性数据信息的检索情况下,基于标签主题的MT-LDA检索模型相比于基于标签关键词检索模型,尤其是在音乐标签稀疏和非正规的情况下,在一定程度上更能够提高音乐信息检索性能。
音乐信息检索;主题类别;关键词检索;MT-LDA模型
1 概 述
伴随着数字技术的飞速发展,人们对音乐的需求量越来越大,同时对音乐的要求也越来越高。为了满足这样的要求和现状,人们把越来越多的音乐资源上传到网上,使得这些音乐资源以海量的速度增长,因此音乐信息检索(MIR)系统得到的关注越来越多,但也给其处理音乐数据库带来了难度和挑战。即使使用多媒体引擎为音乐信息检索带来了突破性的进展,但是,目前仍然是以检索歌曲的基本属性为搜索歌曲的主要方式。当只给定一个查询,却没有精确匹配或与其近似匹配的记录来匹配时,谷歌音乐、酷狗音乐和Last.fm等众多常见的音乐检索系统很难查询到满足用户要求的歌曲[1]。或者是,当你的检索词属于多种不同的歌曲类别时,音乐检索系统会特别混乱地将所有跟关键词相关的歌曲推荐给你,这样导致你反而不能听到你想听的歌。例如,当你在百度MP3的音乐检索栏中输入“我希望找到些摇滚(rock)又古典(classic),但同时又比较动感(dance)的歌”,系统会根据你的查询,匹配数据库中存储的歌曲属性关键词,去除掉输入的一些不要的词汇,提取出“摇滚、古典、舞曲”,从而把和这些词相关的歌曲推荐给你。在这一过程中,音乐标签在一定程度上起到了至关重要的作用。其实还可以根据这些词提取出用户的主要需求。
对音乐歌曲进行轻量级的文字描述的过程就是所谓的标注行为,这些描述的文字就是标签[2]。标签不仅表达和标注出了用户对资源的喜好和看法,还可以看作是用户协作参与交互的一种途径。虽然没有一个通用的词典或公共标准来约束用户的标注行为,但是标签里面暗含的信息也是不能忽视的,有时候为用户获取和分享信息提供相当大的便利。因此,如果能从标签中挖掘出用户能理解的语义信息,并且结合音乐本身具有的属性数据来完成音乐的检索和推荐,这将为MIR(Music Information Retrieval)领域研究者检索音乐带来巨大的突破。
文中主要使用MT-LDA(Music Tag Latent Dirichlet Allocation,音乐标签潜在狄利克雷分配模型)提取出用户需要检索的主题,从而改善音乐搜索引擎的数据处理过程。MT-LDA模型是一种来源于LDA模型的产生式概率模型,它适用于很多离散数据集(例如:音乐歌曲的标签集合)。该方法先将用户的查询映射到更广阔的空间,通过泛化概念来更好地了解和理解用户的检索意图和目的。
2 相关工作
文中的研究重点在两个方面:一方面是如何从网站上得到你想要的歌曲标签及挖掘出这些标签潜在的语义信息;另一方面根据你挖掘的信息进行主题提取并进行建模,得出相应的主题并完成检索。通过以上两方面的研究,探索主题提取模型在MIR系统中的应用。
目前,包括社会化标签的音乐分类检索[3-4]应用系统已经广泛地使用了社会化标签来满足用户多层次多角度的要求。利用已有的标签信息并将用户标注的标签聚类来完成相应音乐的检索,这种改进检索效果的方法是由Begelman和Karydis提出的[5-6]。
从以上研究成果可以看出,如果在一个应用系统中将用户标注的标签进行整合和应用,这将大大提升MIR系统的检索性能。词以及低级特征(属性数据)已经通过信息检索模型被广泛地应用到含有标注的图像检索系统等多媒体检索系统中来进行索引,但还没有被用到音乐检索系统里。实验结果表明,如果利用音乐对应标签的潜在的语义信息再结合音乐的音频特征和组成各个类别的同义词典的方法,能在很大程度上提高MIR的性能。
很多人都在进行音乐信息检索的相关研究,但他们主要研究的是音频的处理和音乐分类,对用户检索意图和音乐数据库进行理解和分析的研究相对较少。LDA模型是一种挖掘潜在语义和理解属性数据语义信息的模型,它主要是将相关属性聚合成人们看不到的簇团,但这些簇团内部又包含着相关的属性联系。LDA模型是由Blei等提出的,后来又被广泛用到自然语言处理的各个相关领域,例如垃圾网页的分类、检测、去除以及主题识别等[7]。传统的音乐检索,都只是用关键词匹配来得到歌曲推荐列表。Krestel等已经将LDA模型应用到标签推荐系统中[7-8],与传统的音乐检索方法——关键字匹配检索相比,该方法能扩展资源,在新资源中能够较好地改进搜索效果,从而极大地提高检索性能。
3 音乐检索相关介绍
3.1 音乐向量空间模型
通过对用户的查询进行分析发现:在大部分情况下,用户只是输入歌曲名、歌手信息或与歌曲相关的其他属性数据而不会输入其他数据;这样就有必要统计用户的查询来调整属性数据特征的权重,从而修改传统的属性数据的向量空间模型[9]。结合用户查询,对本地组件包特征再赋权值,以这种方式重新组合集中的数据向量,式(1)是对音乐向量进行的描述:
Vsong=(a1w1,a2w2,a3w3,a4w4)
(1)
其中,w1表示歌曲名;w2表示作者名字的维度;w3表示专辑;w4表示包括歌词等其他维度的音乐信息;a1,a2,a3和a4分别表示修正参数,考虑到四者在用户查询统计中的比重和查询的意义,将四者初步设定为0.4,0.2,0.2,0.1。
对音乐的描述定义完后,用式(2)来计算歌曲查询相似度。
3.2 关键词音乐信息检索
关键词音乐信息检索,是一种基于标签的检索模式。该模式改变了传统的检索模式,允许用户在不知道音乐的名称、歌词或歌手名等特定信息的情况下,输入一些与想查询的歌曲相关的标签信息来辅助查询扩展和结果的排序。用户也可以在搜索引擎输入框中输入自己当时的心情、自己当时的情感以及当时的环境,系统会根据用户输入的信息对检索出来的结果进行过滤、筛选和排序,最后实现音乐的检索和自动推荐[10]。为了提高音乐信息的检索效果,要考虑到如下几个因素:
(1)歌曲除了歌手、歌名等标注,还有关于其他信息的标签。
(2)该歌曲被听过的用户数目,及标签是否大众化而不是个别用户标注的。
(3)该歌曲的标签数目及标签的形式,标签是否有多余、重复和不相关的词。
为此,文中从Last.fm网站上爬取了很多已经进行过分类的歌曲并进行标签整理,去除多余、没用和无关的标签,并且对标签数目进行统计。用式(3)计算每首歌每个标签的概率:
(3)
其中,TFij是词频(TermFrequency),即某标签ti在该歌曲标签中出现的频率;IDF是逆向文件频率(InverseDocumentFrequency),可以由总歌曲数目除以包含该标签的歌曲的数目,再将得到的商取对数得到。
把搜索输入框输入的关键词与音乐歌曲库的标签进行匹配,按照式(4)计算并推荐概率相对较大的歌曲:
(4)
从表1可以发现,某歌曲属于某一个主题类别时,它的标签描述会大多数偏向于这种主题类别,说明用户标注不是盲目的。每首歌会有不同的标签,而且有的标签会被用户重复标注,这将直接影响到计算该标签的概率,从而会改变检索歌曲的概率值,使该歌曲更容易被检索到。

表1 随机抽取的5首歌类别及标签
3.3 基于音乐标签理解的MT-LDA检索
MT-LDA(Music Tags-Latent Dirichlet Allocation)是一种提取音乐标签主题的LDA模型。该模型(见图1)不仅为音乐标签设置了潜在语义模型,还使每首歌对应的标签内容是一个随机变量,用来显示所归属的潜在主题(潜在类别)的概率值。在模型中,潜在话题定义为一个在有限词典上的单词(标签,这里主要考虑与流派相关的标签)的离散分布。MT-LDA假设每个歌曲标签是由一个带有随机选择参数分布的随机主题从可见以及非可见的歌曲标签群中产生的,主题单一平滑分布会将歌曲标签满足的参数实例化一次[11]。
该方法中的随机变量有:变量θ~p(θ);多项式变量c来表示主题类别;多项式变量t表示歌曲标签词汇。

图1 基于音乐标签的MT-LDA方法
其中,M是整个音乐标签数据集;α是Dirichlet先验参数,在模型中用于生成一个主题θ向量;β是表示各个主题对应的标签概率分布矩阵[12]。它证明了基于MT-LDA的音乐标签主题检索方法在注重简单词语扩展的相关规则下,可以从用户协作标注的标签中挖掘出一个共享的主题结构。
在这个简化基本模型中有一些假设。首先,假设维度为K的狄利克雷分布(即主题类别的维度变量c)是已知和固定的。其次,就是词汇的概率参数β是一个K×V的矩阵,将其看成是固定的且可以估计出来的[13]。最后,泊松估计不是很重要,它可以根据歌曲的标签多少来调节使用。此外,发现N独立于其他所有生成数据变量(θ和t),它是一个辅助变量,所以通常会忽略其随机性对数据变量的影响。

(5)
式中,α为K维变量;Γ(x)是伽马函数。
鉴于给定了参数α和β,混合主题θ、N个主题类别c、N个标签词组的联合概率如式(6):
(6)
该方法中歌曲的标签组t被当成观察变量,θ和c被当成隐藏变量,于是就可以通过EM算法[14]学习训练出α和β。在这个学习训练求解过程中,若遇到后验概率p(θ,c|t)无法直接求解的情况,需要找到一个似然函数下界来辅助近似求解。文中使用基于分解假设的变分法进行计算,用到了EM算法,每次E-step输入α和β,计算得到所需的似然函数,再用M-step最大化这个似然函数,算出α和β,不断循环迭代直到收敛[14]。
从以上的讨论中可以看出,MT-LDA模型有三个重要的部分:
(1)α和β都是用来表示语料级别的参数,也就是每首歌的标签组都被当作是一样的,因此生成过程只采样一次;
(2)θ是歌曲标签组级别的变量,方法中每个歌曲标签组产生各个主题类别c的概率是不同的,因此每个歌曲标签组对应一个不同的θ,也就是说,所有生成的每个歌曲标签组采样一次θ;
(3)c和t都是标签词汇级别变量,c由θ生成,t由c和β共同生成,一个标签词汇t对应一个主题类别c[15]。
至此,MT-LDA模型主要通过GibbsSampling学习求解出音乐标签集中标签在主题类别上的概率分布α,以及主题类别在标签词汇上的概率分布β。根据α和β,就能求解出每次输入的检索词汇向量组关于各个主题类别的概率分布以及主题类别关于各个标签词汇的概率分布[16]。通过概率计算,就能分析出每次检索最可能想要检索到的歌曲主题类别,及各个主题类别最具代表性的标签词汇,从而完成歌曲的检索和推荐。
4 实 验
4.1 实验过程
音乐社会化标签可以从不同角度和方面反映人们对音乐的感受和想法,具有许多社会属性的同时,也包含了歌曲自身的许多客观属性。为了保证实验数据的客观性及可再现,文中使用了著名音乐社交网站Last.fm的数据语料。该数据集是从Last.fm上爬取了2014年下半年至2015年3月份全球各个地区的热门音乐榜单,其中包括歌曲名、歌手名及其标签信息。
数据集本身包含的是原始的歌曲信息,其中有的歌曲标签只有一个,选择标签数为三个以上的歌曲。还有的标签是句子或词组,要对其进行处理和整理。对于一些无明确含义及对检索没有帮助的垃圾标签,如“first listen”,将垃圾标签从语料中去除。最终得到了500首歌曲和38个标签词汇,而且大多数标签是有关音乐流派风格。
使用MT-LDA模型对数据库进行主题类别挖掘,训练得出α和β,根据α和β,再结合检索框输入的检索词汇挖掘出用户最想听到什么样的歌,把这些相关的歌推荐给用户。
4.2 实验结果及分析
文中实验过程中一共进行了9次检索操作,每次检索输入多个检索词汇来查找自己想听到的歌曲。分别用传统的关键词检索和MT-LDA模型提取主题检索两个方法进行检索,检索到的推荐歌曲数选择最靠前的20首。抽出其中的一次检索,可得到关键词检索歌曲推荐表,如表2所示。表3显示的是用MT-LDA主题提取方法检索得到的歌曲表。歌曲推荐表中不仅显示了歌曲名,还包括检索的相关歌曲类别。
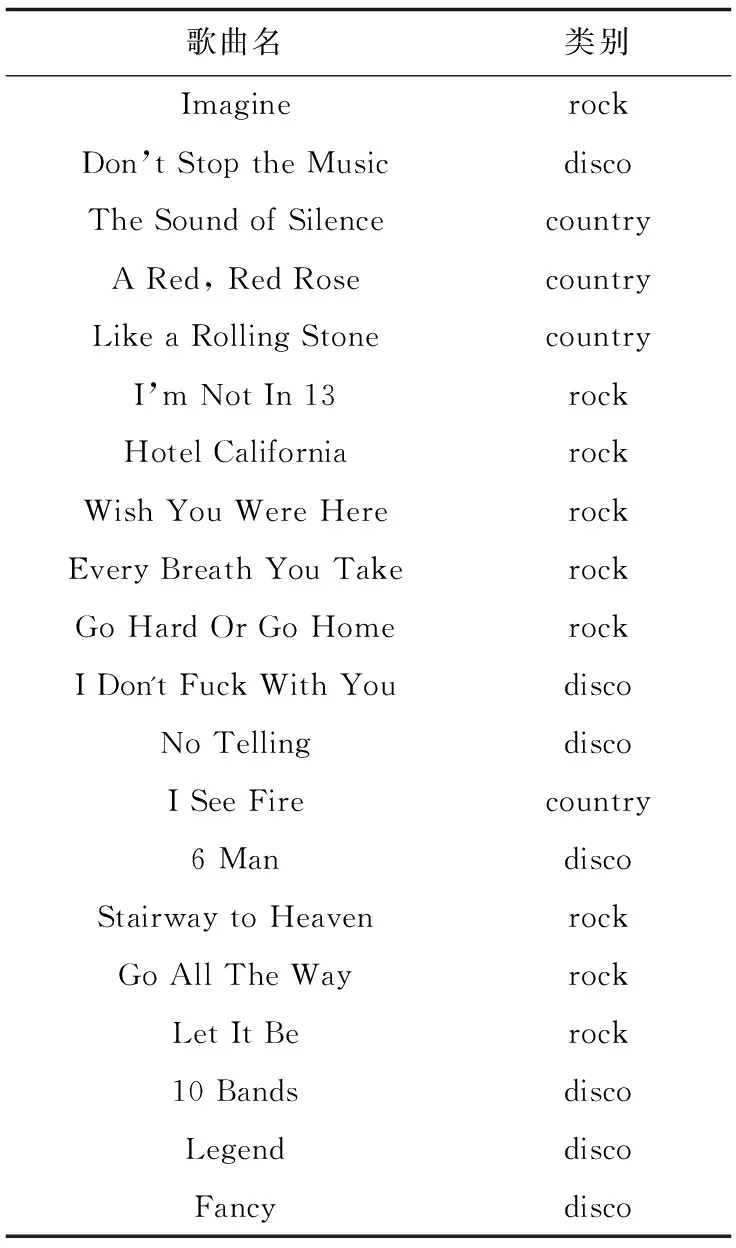
表2 关键词检索歌曲推荐表

表3 MT-LDA主题检索歌曲推荐表
文中采用MAP(Mean Average Precision),每个主题类别的平均准确率的平均值指标,对实验结果进行度量。MAP是度量检索系统性能的常用指标,也是主题建模界常用的衡量方法。系统检索出来的相关歌曲越靠前,MAP值越高,表示检索性能越好,模型的推广性越好。
图2显示了两种检索方式9次检索的MAP值的比较。

图2 两种检索方法的MAP值比较
把表2和表3进行比较可以得出,虽然输入的检索词汇都是“rap rock folk electronic”,但是,关键词检索方法只会匹配跟这四个检索词相关的歌曲,把概率值大的歌曲推荐给你。而MT-LDA检索方法会结合训练出的参数得出你最想检索的歌曲的主题类别,从而把这个主题类别相关的歌曲推荐给你。所以会发现,表2中的歌曲的类别特别混乱,反而不知道你想听什么歌;而表3主要给你推荐了“disco”和“electronic”的歌曲。
由图2可以看出,MT-LDA主题检索方法的MAP值比关键词检索方法的高出许多,证明MT-LDA主题检索方法的检索性能要高于关键词检索方法。
综上所述,MT-LDA主题检索方法在设计中不仅考虑了歌曲集的标签信息,还能从不知道歌曲歌名及歌手信息的用户检索信息中挖掘出用户最想听的歌曲的主题类别,从而把相关歌曲推荐给用户,大大提高了检索性能。
5 结束语
MT-LDA模型通过对已有的数据集进行数据处理及分析,得出标签检索主题,极大地提高了检索的准确性和性能。未来将侧重于结合歌曲的音频特性和MT-LDA模型给用户标注过的新歌曲进行分类,使得歌曲数据集更具有准确性,从而提高主题提取精度,进一步增强检索性能。
[1] Levy M,Sandler M.Music information retrieval using social tags and audio[J].IEEE Transactions on Multimedia,2009,11(3):383-395.
[2] Beckett D. Semantics through the tag[C]//Proceeding of XTech 2006:building web 2.0.[s.l.]:[s.n.],2006.
[3] Kim H,Breslin J G,Yang S,et al.Social semantic cloud of tag:semantic model for social tagging[C]//Proceedings of the 2nd KES international conference on agent and multi-agent systems:technologies and applications.[s.l.]:ACM,2008:83-92.
[4] Wang F,Wang X,Shao B,et al.Tag integrated multi-label music style classification with hypergraph[C]//Proc of 10th international society for music information retrieval conference.Kode,Japan:[s.n.],2009:363-368.
[5] Begelman G,Keller P,Smadja F.Automated tag clustering,improving search and exploration in the tag space[C]//Proc of the 15th international world wide web conference.Edinburgh,UK:[s.n.],2006.
[6] Karydis I,Nanopoulos A,Gabriel H,et al.Tag-aware spectral clustering of music items[C]//Proc of 10th international society for music information retrieval conference.Kode,Japan:[s.n.],2009:159-164.
[7] Krestel R,Fankhouser P,Nejdl W.Latent Dirichlet allocation for tag recommendation[C]//Proceedings of ACM conference on recommender systems.New York,USA:ACM,2009:61-68.
[8] Feng Y,Zhang Y,Pan Y.Popular music retrieval by detecting music[C]//Proc of ACM SIGIR’03.Toronto,Canada:ACM,2003.
[9] Baeza-Yates R,Ribeiro-Neto B.Modern information retrieval[M].New York:ACM Press,1999.
[10] Meila M,Heckerman D.An experimental comparison of several clustering and initialization methods[J].Machine Learning,2001,42:9-29.
[11] 周利娟,林鸿飞,闫 俊.基于TLDA和SVSM的音乐信息检索模型[J].计算机科学,2014,41(2):174-178.
[12] Stigler S M.Parametric empirical Bayes inference:theory and applications[J].Journal of the American Statistical Association,1983,78(381):47-65.
[13] Nigam A,McCallum A K,Thrun S.Text classification from labeled and unlabeled documents using EM[J].Machine Learning,2000,39:103-134.
[14] Popescul A,Ungar L H,Pennock D,et al.Probabilistic models for unified collaborative and content-based recommendation in sparse-data environments[C]//Proceedings of the seventeenth conference on uncertainty in artificial intelligence.San Francisco:Morgan Kaufmann,2001.
[15] Rennie J.Improving multi-class text classification with Naive Bayes[R].[s.l.]:MIT,2001.
[16] Ronning G.Maximum likelihood estimation of Dirichlet distributions[J].Journal of Statistical Computation and Simulation,1989,34(4):215-221.
Music Tags Topic Retrieval Based on MT-LDA
XU Yun-zhi,SHAO Xi
(College of Communication & Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Music sharing systems with collaboratively tagging function have been important parts on the Internet.They make the system users annotate and categorize their own interests and thoughts about the resources possible.Considering the characteristics of social tagging and its influence on Music Information Retrieval (MIR) system,MT-LDA method by jointly considering lyrics,tags and searching behavior can be used to analyze collaboratively generated tags and the topic category of tags to catch the retrieval topic,so as to improve the efficiency and performance of MIR system.The experiment shows that MT-LDA retrieval model based on tags topic performs better than keywords retrieval model based on tags into improving the MIR system performance especially tags for tracks are extremely sparse and informal,when retrieval information have no attribute data.
music information retrieval;topic category;keywords retrieval;MT-LDA model
2015-09-28
2015-12-30
时间:2016-05-25
国家自然科学基金青年基金(60902065)
徐芸芝(1989-),女,硕士研究生,研究方向为多媒体音乐信息处理和检索;邵 曦,博士,副教授,研究生导师,研究方向为多媒体信息处理系统、基于内容的音乐信息检索等。
http://www.cnki.net/kcms/detail/61.1450.TP.20160525.1711.068.html
TP31
A
1673-629X(2016)07-0200-05
10.3969/j.issn.1673-629X.2016.07.043
