3D文本验证码的破解技术研究
2016-02-27苏智勇
陆 颖,苏智勇
(南京理工大学 自动化学院,江苏 南京 210094)
3D文本验证码的破解技术研究
陆 颖,苏智勇
(南京理工大学 自动化学院,江苏 南京 210094)
为克服传统二维文本验证码的局限性,文本验证码演变出一些新的形式,其中包括3D文本验证码。针对目前网站上使用的一种3D文本验证码,文中提出有效的破解方法。利用图片中像素密度首先从验证码图片中提取字符边界;再通过图像中背景纹理梯度方向基本不变的特征,从验证码图片中提取字符背景,从而间接得到字符表面;然后根据字符信息的表现特征,设计字符分割算法,以得到验证码图片的单个字符;最终采用OCR识别软件——ABBYY进行字符识别。实验结果表明,提出的破解算法在实验数据集上取得了较好的破解效果。充分利用了验证码系统的规律,通过提取图片背景间接得到字符前景。与基于直接提取字符表面的破解算法相比较,前者具有更好的适用性。
3D验证码;背景去除;字符提取;字符分割
1 概 述
随着互联网的发展,各种网络服务日益成为人们生活的一部分,但同时也给互联网系统带来了安全性问题。如免费服务资源遭受机器注册攻击,恶意计算机程序占用网络服务资源,产生大量网络垃圾等。因此,全自动开放式人机区分图灵测试(CAPTCHA)应运而生,即通常所说的“验证码技术”。验证码这个词最早是在2002年由卡内基梅隆大学的Von Ahn等提出[1],是一种区分用户是计算机还是人的公共全自动程序。随着验证码技术的发展,验证码的种类也有多种多样,包括基于文本字符的验证码、基于图像的验证码、基于声音的验证码和基于推理的验证码等。近年来,验证码系统被应用于各种网络服务,例如Yahoo!、Microsoft和Facebook。验证码技术已成为互联网必不可少的一部分。
2D文本验证码的应用最为广泛。这类验证码图像中包含数字、字母或其他文字。它的破解算法一般包括验证码预处理、字符分割以及字符识别这三个研究内容。其中字符分割是文本验证码破解的难点,它需要针对不同的验证码特征定制设计[2]。近年来,研究人员相继提出了许多字符分割算法,包括传统的竖直投影法、连通域分割法、基于SCP(Significant Contour Points)的分割算法[3-4]、基于背景细化的分割算法[5]、滴水算法[6]等。另一方面,由于单个字符的识别已经可以取得很高的正确率,大部分方法的识别率在90%以上[7],所以一旦通过分割得到了单个字符,验证码破解将会变得容易许多。因此,为了增加验证码的破解难度,系统一般会对图像添加各种干扰噪声,或对字符进行混杂、扭曲、粘连、变形等处理。但与此同时也给人眼识别带来了不便。
为了克服传统2D文本验证码的局限性,研究人员不断地设计安全性更高的新型验证码系统。3D验证码系统[8-10](下文简称3D CAPTCHAs)就是其中之一。3D CAPTCHAs是以人眼视觉系统能够从一幅图像中自动感知3D对象为基础而设计的,所以这类验证码潜在的安全性是:OCR软件很难直接识别出3D对象,而人眼视觉系统可以。因此对3D文本验证码系统的破解首先要从验证码图片中提取字符,这也是破解算法中最为关键的环节。
文中着重于破解一种基于文本字符的3D验证码,文献[11]将其命名3dcaptcha。利用这类验证码在像素空间呈现出的特征,如像素密度、斜线梯度方向等,先提取出验证码字符,再根据字符特征设计有效的字符分割算法,最后通过OCR识别软件进行识别。
2 研究现状
随着验证码技术的发展,研究人员在设计和开发3D CAPTCHAs的实践中进行了大量尝试。本节先介绍了3D CAPTCHAs生成技术的发展现状,之后对3D文本验证码的破解情况进行了描述。
Mitra等[12]提出在3D环境中渲染抽象的三维模型的方法,也称之为“抽象图像(emerging images)”生成技术。它以“抽象”为基础而设计,并且利用了人类能从整幅图像中感知对象的独特能力。另外,Ross等[13]给出了对Sketcha验证码系统的可用性研究和安全性分析,该系统中用户需要将3D线模型调整到正确的位置。社交网站YUNiTi[14]采用的验证码是基于朗伯体的三维模型渲染。验证码图片中3D物体利用各种参数进行渲染,比如颜色、位置等。Imsamai和Phimoltares提出了几种3D文本验证码系统[9],验证码图片中对字符进行了旋转、倾斜处理,且字符使用了相同的阴影模型。
然而迄今为止,国内外对于3D验证码的破解研究还较少。它的破解算法一般包括:图片预处理、字符提取、字符分割和字符识别。与2D文本验证码破解算法的区别就是多了字符提取这一步。字符提取就是利用图片特征,将字符转化为可以识别的对象。由于各验证码系统之间的差异性,所以字符提取算法要根据特定的对象而设计。
文献[15]研究了Ku6网站上使用的一种新型3D文本验证码的鲁棒性,首次分析了3D空心字符验证码。文献中采用颜色填充算法(Color Filing Segmentation,CFS)先提取字符前景,再根据字符侧面与前表面的宽度差异将二者进行区分并标记,继而根据位置信息分别对各侧面和前表面碎片进行融合,最后形成字符掩膜。实验结果表明,该方法的分割成功率达到了70%。破解的难点在于对字符表面的合并,尤其当字符出现较为严重倾斜或相邻两个字符在竖直方向发生重叠时,有可能将不同字符的表面错认为来自同一个字符。文献[11]重点分析了三种基于文本的3D验证码的安全性能,这几种验证码以在有规律的图片背景上施加扰动为基础。该文献中利用像素空间线性方向的变化、像素密度、网格大小变化等特征,针对不同的验证码系统,各自设计了字符提取算法。
由于验证码都各有其特点,很难找到一种通用的算法处理不同类型的验证码,所以有必要根据特定的验证码设计相应的破解策略。
3 3dcaptcha破解技术研究
3.1 3dcaptcha特点
文中破解对象如图1所示,文献[11]将其命名为“3dcaptcha”。该类验证码从Cafe Charlotte网站上下载获得[16]。这种验证码系统利用斜线先形成有规律的图样,再对其加以扰动而形成。
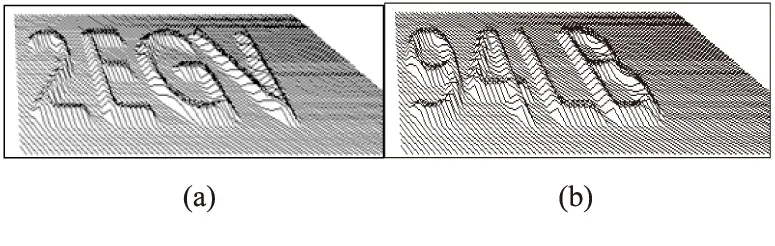
图1 实验样本示意图
经过对大量验证码样本的观察,发现该验证码有以下特点:
(1)字符前景与背景无法通过颜色信息来分离。
(2)每个验证码样本中包含4个字符,且出现在较为固定的区域。
(3)该验证码系统没有使用“0”和“O”、“1”和“I”这样结构过于类似的字符。整个验证码系统中只有32种字符。
(4)由于验证码是根据其3D模型经透视投影变换而生成,所以离视点越近的斜线之间间距越大,越远的斜线之间间距越小,并且字符发生倾斜。
(5)非字符区域(即背景区域)上,斜线斜率较为一致。
3.2 破解流程
文中验证码的破解主要包括图像预处理、背景去除、验证码字符提取、字符分割和字符识别五个部分。其中最为关键的一步是验证码字符提取。字符提取的质量会直接影响分割的正确率和识别的准确性。由于字符表面的框架由受到扰动后的斜线构成,并且扰动后的斜线没有固定的表现形式,所以很难直接获得字符表面。基于此,文中通过提取验证码图片背景来间接确定验证码字符表面。
3.3 验证码字符提取
3.3.1 提取字符边界
观察验证码样本可知,验证码字符的边界黑色像素密度较高。因此可以利用这一特征来提取属于字符边界的像素。
在对图像二值化之后,遍历图像各像素。若该点P的像素值为0(即黑色),再进一步分析P点的四邻域。若4邻域中至少有3个像素点为黑色,则将P点和它4邻域中的黑色的点都先视为文本像素。
3.3.2 背景去除
3dcaptcha的字符由一组经过扰动的斜线构成,没有受到扰动的斜线构成验证码图像的背景框架。由于字符表面的框架并没有固定的表现形式,很难直接得到字符表面。因此文中将通过提取验证码字符背景来间接获得字符前景。
经过对大量样本的观察发现,每条背景线延伸方向相对一致,因此可以通过方向信息先提取到背景线(下文将它称为基准线),再利用基准线之间的间距信息得到验证码图片的背景区域。
文中将借助图2来说明提取基准线的方法,具体步骤如下:
(1)遍历整幅验证码图中的黑色像素,若该点不属于在3.3.1节中所提取的字符边界,将它设为点P,见图2。
(2)经观察发现,在以图像左上角为原点,水平向右为X轴正方向,竖直向下为Y轴正方向的坐标系下,基准线可以近似看作斜率约等于1的斜线。结合图2,可以认为点P2、P3、P6、P7均不可能是基准线上的点。在本步骤中,查看点P邻域上的点P2、P3、P6和P7,如果这四个位置都是白色,则继续执行步骤(3),否则执行步骤(4)。
(3)若P4和P5位置只有一个方向有黑色像素,P1和P8位置也只有一个方向有黑色像素,则将点P视为基准线上的像素。
(4)由于视点远处的基准线出现了重叠现象,所以若P3、P5同时为黑色,或P1、P7同时为黑色,则也认为点P为基准线上的像素。
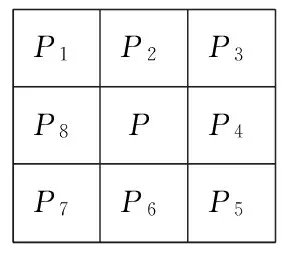
P1P2P3P8PP4P7P6P5
图2 当前像素P及其8邻域编号
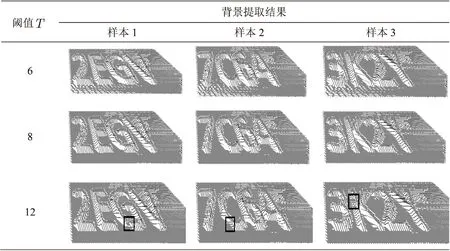
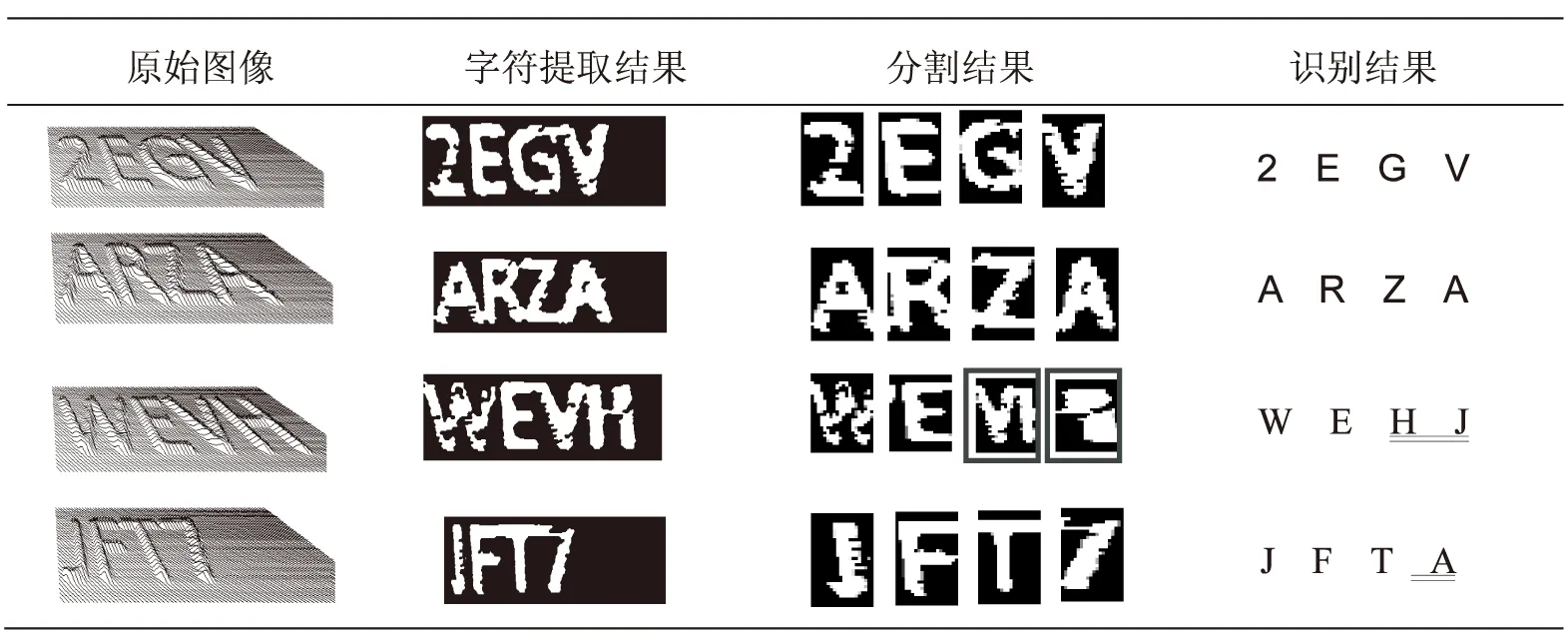
提取到基准线后,下一步就是对背景区域进行填充。如果同一行中两个基准线上的点之间的距离D 3.3.3 提取字符 验证码字符提取分为二次确定字符边界和提取字符表面两个部分。由于透视投影的原因,导致验证码图像出现近大远小的特征;另一方面图像本身的精确度较低,图像右上角为黑色像素密度最高的区域。因此3.3.1节中提取字符边界的方法会将验证码图片中的右上角区域错认为字符边界。所以,要准确提取验证码字符首先要对3.3.1节中提取出的字符边界进行二次提取。 (1)文中利用漫水填充算法,将图像四周的空白区都填充为背景。因为验证码字符出现在较为固定的区域,所以可对图像进行裁剪。这可能会减少字符周围的噪声,从而提高最终识别的正确率;另一方面也提高了运算速度。 (2)初步提取字符表面,作为去除字符边界噪声的依据。为方便处理,在初步提取字符表面区域之前,需要对图像进行阈值处理,即将字符表面上的框架置为白色。然后按水平方向遍历图像,若同一行中连续为白色像素的区域宽度D1>T1,则先将该区域视为字符表面。 (3)遍历属于字符边界上的点,设该点为A,若点A附近存在字符表面像素,则确认点A属于字符边界,否则属于图像背景。 经过图像形态学去噪后,最终可以得到较为清晰的验证码字符。 3.3.4 后期处理 后期处理包括透视校正和孔洞填充两部分。 (1)由于成像系统与目标的距离以及它们之间的位置原因,导致形成的图像发生了倾斜而不再是正视图,这不利于对字符进行分割。为了提高字符分割的成功率,考虑对图像进行透视变换校正。 透视变换(PerspectiveTransformation)是将图片投影到一个新的视平面,也称为投影映射。已知变换对应的四组点就可以求取变换矩阵,从而得到变换后的像素坐标,即得到校正后的图像。 (2)因为提取出的字符表面还存在小孔洞,为了使字符信息更加完整,文中对孔洞进行了填充。方法如下: 计算每个孔洞的面积,若孔洞面积小于T2,则认为它需要被填充。其中孔洞面积是指该孔洞所包含的像素点个数。这里T2不能太大,否则会把“4”、“P”等字符结构中的闭合区域也填充掉。文中选取T2=40。 3.4 字符分割 字符分割的目的是在验证码图像中划分各字符所处的区域,把各字符所处的区域的子图像分割出来。基于文本字符之间既有粘连又有断裂的特点,文中采用垂直投影分割、轮廓差投影分割和均分法相结合的分割方法。 因为文中研究的验证码固定只包含4个字符,所以要将字符正确分割需要五条分割线,记为分割序列seg_Line,seg_Line={S0,S1,S2,S3,S4}。其中,Si表示第i条分割线在验证码图片中所在位置的列值。S0为第一个出现字符像素的列值,S4为出现字符像素最后一列列值。因此,四个字符的有效宽度L=S4-S0。另外,由于单个字符的宽度并不是严格相同,经过对大量样本的研究,发现S1、S2和S3满足下式: (1) 3.4.1 垂直投影分割 垂直投影分割是利用字符之间的列空白来分割字符。字符图像经过二值化和去噪后,将白色像素设为前景点。以像素点为单位逐列扫描图像,累加该列中前景点的个数,累积的结果即为该列的垂直投影。 以图3(h)样本为例,投影值较大的地方表明此列字符像素多,而投影值为0的地方认为是两个字符之间的分割位置。文中先把投影值为0的列作为候选分割线的所在位置,再根据式(1)判断该分割线是第几条。若不满足式(1),则说明该点不是合适的分割位置。 3.4.2 轮廓差投影分割 若垂直投影分割不能得到所有的分割线,则说明上一步的分割结果中还存在相互粘连的字符块。针对这一情况,文中利用轮廓差投影分割法对粘连部分进行二次分割,以解决字符间轻微粘连的问题。 该方法对前景字符竖直方向上的上边界和下边界进行投影,投影到X轴上的是每一列的最上和最下白色像素点之间的距离。文中先根据上节的结果得到字符块中粘连字符的个数和粘连字符的具体位置,再在该字符块进行轮廓差投影。得到投影值序列后,寻找投影值最小的列c。若该列投影值m小于字符笔画宽度line_w,且列c满足式(2),则列c所在位置为候选分割点。同样,根据式(1)判断该点在分割序列seg_Line中的位置。若不满足式(1),则认为列c所在位置不是合适的分割点。 (2) 其中,Si∈seg_Line;width为单个字符的平均宽度。 3.4.3 均 分 在字符粘连较为严重时,垂直投影和轮廓差投影方法将会不适用。因此文中选择了均分的方法。 均分就是先通过分割序列seg_Line,判断粘连字符块的位置及宽度,再根据该粘连块包含的粘连字符个数,对粘连块进行平均分割处理。 为了验证文中算法的有效性,从网站上收集了500个实验样本,样本分辨率为400×120。本节对破解结果进行了分析,并进一步讨论破解失败的原因。 4.1 字符提取 文中算法利用验证码图片中基准线方向基本一致的特征,先根据像素密度特征得到字符边界,再通过提取图片背景来间接得到字符表面,最终提取出比较完整的字符信息。以图1(a)中的样本为例,图3给出了字符提取的结果。下文给出了算法中用到的阈值T、T1的选取标准。 图3 字符提取结果 (1)在背景去除算法中,阈值T选取不同的值对背景提取结果的影响见表1。当T=6时,由于背景填充不够充分,字符下方出现大量噪声;当T=10时,因为阈值过大,而将字符表面错认为背景被填充为黑色,导致字符信息不完整(图中方框区域)。经比较发现,当T=8时,背景填充效果较好。因此,文中选取阈值T=8。 (2)在字符边界噪声去除中,先利用阈值T1提取出字符表面的大致区域,再根据字符表面区域二次确定字符边界。经实验验证,由于去噪结果对阈值T1不敏感,T1的取值范围为5~12,文中选取T1=6。若T1过小,会将字符周围的噪声误认为字符,导致去噪不完全;若T1太大,提取出字符表面信息会很少,使得去噪过度。阈值T1对字符提取的影响如表2所示。 表1 阈值T对背景提取结果的影响 表2 阈值T1对字符边界提取结果的影响 4.2 字符分割 由于透射投影导致样本中斜线间隔呈现远大近小的特点,在验证码图像的右上方甚至出现斜线之间相互簇拥的现象,使得最终提取到的文本字符可能出现断裂或字符间严重粘连等情况。因此,文中采用垂直投影分割、轮廓差投影分割和均分法相结合的分割方法。 经过对大量样本的研究,字符笔画宽度line_w=20,样本字符的平均宽度width=75。表3给出了部分验证码的分割结果。其中被方框标记的为分割失败的字符。 表3 部分样本的实验结果 实验结果表明,文中的分割方法有较高的可行性,但是若字符本身信息不完整或与相邻字符大面积粘连,则可能导致分割失败。 4.3 字符识别 字符分割完成后将得到2 000个单个字符,文中将其中的1 280个作为训练集,剩余的作为测试集,利用OCR识别软件—ABBYY进行识别。分割结果和识别结果见表3。表中识别错误的字符已用下划线标出。经过对大量实验样本识别结果的分析,总结出识别失败的原因有两个: (1)字符分割失败。 (2)字符结构的相似性。比如字符“7”和“T”、字符“2”与“Z”,因为它们的结构类似,导致分类器识别失败。 针对文中采集的验证码数据集,在提出的破解算法下,单个字符的识别率达到95.4%,整个验证码完全识别的正确率为76.3%。 4.4 与其他破解方法进行比较 文中方法主要由字符提取、字符分割和字符识别三个部分组成。在从验证码图片中提取到字符前景的基础上,针对这类验证码设计了字符分割算法,最后利用OCR识别软件进行识别。 文献[11]同样对文中的实验样本进行了破解。文献中字符提取算法分为按行列扫描提取字符表面、按像素密度提取字符边界和按网格面积提取字符表面三个部分,最后同样用开源OCR软件进行识别,识别率为58%。针对文中破解的验证码系统,在采用同一识别方法的前提下,文中的字符提取算法具有明显的优越性,识别率比文献[11]高出18.3%。由此可见,该算法具有更高的有效性。 文中3dcaptcha的成功破解源于这类验证码是基于有规律的扰动而设计的,以便于人类能够感知3D字符。然而实验证明,虽然它可以防止OCR程序的直接破解,但是验证码系统的扰动规律可以成为破解验证码的有利信息,如像素密度、斜线斜率等特征。 实验结果证明了文中提出的3dcaptcha系统破解算法的可行性和有效性。但是在字符提取方面还存在一些不足,导致离视点越远的字符提取效果不理想,比如会出现字符信息严重丢失或字符间严重粘连的现象,从而影响了最终的识别结果。在以后的工作中将进一步解决这些问题。 [1] Ahn L V,Blum M,Langford J.Telling humans and computer apart automatically[J].Communications of the ACM,2004,47(2):56-60. [2] 李秋洁,茅耀斌,王执铨.CAPTCHA技术研究综述[J].计算机研究与发展,2012,49(3):469-480. [3] Strathy N W,Suen C Y,Krzyzak A.Segmentation of handwritten digits using contour features[C]//Proceedings of the second international conference on document analysis and recognition.[s.l.]:IEEE,1993:577-580. [4] Shi Z,Shrihari S N,Shin Y C,et al.A system for segmentation and recognition of totally unconstrained handwritten numeral strings[C]//Proc of international conference on document analysis and recognition.[s.l.]:[s.n.],1997:455-458. [5] Lu Z,Chi Z,Siu W C,et al.A background-thinning-based approach for separating and recognizing connected handwritten digit strings[J].Pattern Recognition,1999,32(6):921-933. [6] Congedo G,Dimauro G,Impedovo S,et al.Segmentation of numeric strings[C]//Proc of third international conference on document analysis and recognition.Montreal,Que:IEEE,1995:1038-1041. [7] 曲金山.基于形状上下文的验证码识别研究[D].哈尔滨:哈尔滨工程大学,2013. [8] Chaudhari S K,Deshpande A R,Bendale S B,et al.3D drag-n-drop CAPTCHA enhanced security through CAPTCHA[C]//Proceedings of the international conference & workshop on emerging trends in technology.[s.l.]:ACM,2011:598-601. [9] Imsamai M,Phimoltares S.3D CAPTCHA:a next generation of the CAPTCHA[C]//Proc of international conference on information science and applications.[s.l.]:IEEE,2010:1-8. [10] Macias C R,Izquierdo E.Visual word-based CAPTCHA using 3D characters[C]//Proc of 3rd international conference on crime detection and prevention.[s.l.]:[s.n.],2009:1-5. [11] Nguyen V D,Chow Y W,Susilo W.On the security of text-based 3D CAPTCHAs[J].Computers & Security,2014,45:84-99. [12] Mitra N J,Chu H K,Lee T Y,et al.Emerging images[J].ACM Transactions on Graphics,2009,28(5):1-8. [13] Ross S A,Halderman J A,Finkelstein A.Sketcha:a captcha based on line drawings of 3D models[C]//Proceedings of international conference on world wide web.[s.l.]:ACM,2010:821-830. [14] YUNiTi.YUNiTi-do something good[EB/OL].2013-06-29.http://www.yuniti.com/register.php. [15] Ye Q,Chen Y,Zhu B.The robustness of a new 3D CAPTCHA[C]//Proc of 11th IAPR international workshop on document analysis systems.[s.l.]:IEEE,2014:319-323. [16] Charlotte C.Cafe charlotte[EB/OL].2013-06-29.http://www.cafe-charlotte.cz/en/fanclub. Research on Breaking of Text-based 3D CAPTCHAs LU Ying,SU Zhi-yong (College of Automation,Nanjing University of Science and Technology,Nanjing 210094,China) In order to overcome the traditional limitations of two-dimensional text CAPTCHAs,there comes many new forms,including 3D text CAPTCHAs.Aiming at authentication code of 3D text using on site currently,an effective crack method is put forward.Using features in pixel space,such as pixel density and gradient direction of diagonal lines,the character boundaries and surface from image is extracted.Secondly,character segmentation algorithm is designed to get single character according to the information of text.Finally,using OCR for identification.The experiment shows that the breaking algorithm proposed achieves a good result on experimental data set.Making full use of the rule of CAPTCHA scheme,characters from images are obtained indirectly.Compared with the algorithm which extracts characters directly,it has a better applicability. 3D CAPTCHA;background removal;character extraction;character segmentation 2015-10-22 2016-01-27 时间:2016-06-22 国家自然科学基金资助项目(61300160) 陆 颖(1990-),女,硕士研究生,研究方向为视频图像处理;苏智勇,副教授,研究方向为计算机视觉、计算机图形学。 http://www.cnki.net/kcms/detail/61.1450.TP.20160622.0842.020.html TP31 A 1673-629X(2016)07-0070-05 10.3969/j.issn.1673-629X.2016.07.0154 实验结果与分析


5 结束语
