基于PubMed的共词聚类分析方法
2016-02-26冒纯丽曹春萍
冒纯丽,曹春萍
(上海理工大学 光电信息与计算机工程学院,上海 200093)

基于PubMed的共词聚类分析方法
冒纯丽,曹春萍
(上海理工大学 光电信息与计算机工程学院,上海200093)
摘要针对传统共词聚类分析法中共词矩阵构建不能全面反映主题词之间的关联问题,提出了基于高频主题词共现于同一篇文献多种格式内容构建共词矩阵的方法,针对传统聚类算法对于类团非球状且类团大小相异较大导致聚类效果不理想等问题,利用改进的CRUE聚类算法对共词矩阵聚类。并对PubMed中肺癌领域相关文献进行共词聚类分析,实验论证了改进后共词聚类分析方法的可行性。
关键词共词聚类分析;共词矩阵;CRUE聚类;PubMed
PubMed是美国国立卫生研究院(NIH)下属美国国立医学图书馆(NLM)开发的因特网检索系统,建立在国家生物医学信息中心(NCBI)平台上[1]。PubMed数据库主要来源为Medline。Medline是美国国立医学图书馆生产的国际性综合生物医学信息书目数据库。Medline文献数据库作为当前全球最权威的生物医学文献检索系统,是全世界医学研究者、图书情报人员最常用的检索工具。医疗研究者通常以PubMed中相关文献为数据来源,通过共词聚类分析方法对文献处理挖掘该领域研究现状与热点。
共词聚类分析法是基于内容分析的一种方法,共词聚类分析法通过挖掘文献的主题词,选取出现频次高于一定阈值的主题词作为高频主题词,统计高频主题词对在同一篇文献(txt格式)主题词列表中共现情况来构建共词矩阵,对共词矩阵中主题词之间的共现情况进行聚类,分析聚类结果得到主题词之间相关关系,进而分析得到主题词所代表的学科和主题结构变化[2-5]。共词聚类分析方法关键点在于共词矩阵的构建以及聚类算法的选取,共词矩阵的构建过程和聚类算法的聚类过程将直接影响到最后的分析结果,目前共词分析方法在构建共词矩阵和聚类的时候都存在一些问题,具体如下:
(1)共词矩阵构建问题。共词矩阵构建依赖于高频主题词的共现分析,传统共词矩阵根据两两高频主题词在同一篇txt格式文献中的共现情况构造,如果两个高频主题词在同一篇txt格式文献的主题词中共同出现,则共现次数加一。主题词是一篇文献核心内容的浓缩和提炼,很大程度上代表了文献的研究内容和主题,通过统计高频主题词在文献主题词中的共现情况构造共词矩阵是必要的。但该方法同样存在缺陷,txt格式文献并不包含全文内容,pdf全文内容所包含的信息量远大于txt格式文献,两个高频主题词在txt文献主题词中未共同出现,并不代表这两个高频主题词之间没有联系,其有可能在全文pdf内容中共出现。因此传统共词矩阵构建只注重高频主题词在txt格式文献主题中共现情况忽略其在全文内容中的共现情况,需要改进。
(2)聚类算法问题。对共词矩阵进行聚类运算,通过计算高频主题词之间的距离分析得到高频主题词二维空间抽象分布图,图中的点代表高频主题词,两个点间的距离代表高频主题词之间的抽象距离。图1左图为主题词分布呈球状,右图为非球状。以往研究者在做共词矩阵聚类分析时习惯将共词矩阵导入SPSS[6],采用K-means[7]聚类或者系统聚类,其中系统聚类法根据合并两类类间距离的不同分为组间连接、组内连接、中位数聚类法、最近邻元素、Ward法等,此类聚类算法适用于主题词分布呈现球状的共词矩阵聚类,对于类团非球状和类团大小相异很大的聚类效果不理想。通常高频主题词分布呈现图1右图所示不规则形状,因此本文选取适合处理非球状的聚类算法进行聚类。

图1 主题词二维空间距离分布图
针对以上两个问题,本文提出了相应解决方案。
针对共词矩阵构建问题,由于本文的数据来源为PubMed,PubMed中同一篇文献格式包括txt,xml,pdf等,主题词存在于该文献xml格式中,本文在批量导出xml格式文献的同时通过技术手段批量下载对应pdf全文文献,统计高频主题词对在xml格式文献主题词中共现情况加权结合高频出题词对在pdf格式文献中共现情况构造共词矩阵,通过此类方法构造共词矩阵将解决传统共词分析方法在构建共词矩阵时,只注重主题词而忽略全文内容导致共词矩阵不能深层次反映主题词之间联系的问题。
针对聚类算法适用性不强问题,本文利用CRUE层次聚类算法对共词矩阵进行聚类挖掘研究热点,CRUE聚类算法解决了对于类团非球状和类团大小相异较大所引起的聚类效果不理想的问题。
1共词矩阵构建方法改建
1.1传统共词矩阵构建方法
传统共词分析方法中给定txt文献集T={t1,t2,…,tm},高频主题词集K={k1,k2,…,kn},主题词ki和kj共现频率为f(ki:kj)。
定义1共词矩阵是对称矩阵,且行、列均为代表了重要知识点的高频主题词,矩阵中的元素为两两高频主题词在txt文献集中出现次数之和。共词矩阵C如式(1)所示。
(1)
其中
传统的共词分析法算法流程如下:
(1)提取高频主题词。提取txt文献集T的主题词,选取出现频次高于一定阈值的主题词作为高频主题词,得到高频主题词集K;
(2)构造共词矩阵。统计高频主题词集K中两两主题词共出现次数,构造共词矩阵C,由于共词矩阵中主题词的频次悬殊可能对后续的分析结果造成不必要的影响,研究者通常借用Ochiia系数[8]对共词矩阵进行处理,使其转化为相关矩阵R。
(2)
1.2改进后的共词矩阵构建方法
本文从PubMed检索系统上获取肺癌相关的文献进行分析研究,该系统数据库中同一篇文章的格式有xml,pdf等,xml格式的文献包含了文章的主题词且主题词与主题词之间用标识,pdf格式的文献包含了该文章的实体研究内容。本文通过技术手段挖掘出xml格式中的高频主题词,统计高频主题词在xml中的共现情况加权结合高频主题词在pdf中的共现情况构造共词矩阵。给定xml文献集X={x1,x2,…,xm},给定pdf文献集P={p1,p2,…,pm},对每个关键词ki(1≤i≤n)设置一个权值v(0≤v≤1),具体设定值根据实际分析确定。步骤如下:
(1)批量获取pdf文献。
1)使用Jsoup挖取全文pdf下载地址。本文使用Jsoup[9]来解析xml文献,Jsoup是Java的xml解析器,Jsoup可直接解析xml、html文本内容,它提供了一套省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。使用Jsoup挖掘出xml标记集中
2)使用HttpClient实现全文pdf下载。HttpClient是Apache Jakarta Common 下的子项目,用来提供高效的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。通过HttpClient中的Get(url)方法获取链接并下载。此处url为:http://www.ncbi.nlm.nih.gov/pmc/articles/PMC号/pdf。本文只需在程序中循环m(m篇文献)次执行此url将得到的字符流保存到本地即可下载m篇pdf文献。
(2)提取高频主题词。
通过Jsoup挖掘出文章
(3)构造共词矩阵。
1)主题词ki(1≤i≤n)和kj(1≤j≤n)根据在同一篇文献两种格式xd和pd中共现情况赋予不同共现频率,若词对在文献xd的主题词中共出现,则共现频率加1,若词对在文献pd中共出现,则共现频率加0.5。词对共现频率计算公式为
(3)
2)主题词ki在同一篇文献两种格式xd和pd中出现频率计算公式为
(4)
3)相关矩阵R中的元素rij计算公式为
(5)
2共词矩阵聚类算法改进
本文利用基于层次聚类[10]的CRUE聚类算法[11]对共词矩阵进行聚类。CRUE聚类算法运用基于对象质心和对象中心点之间的策略来计算聚类对象之间的距离,CRUE聚类算法区别于其他适合处理球状类团的聚类算法,其不是选取对象数据集中某个对象代表一个类而是选取最具代表性对象乘以一个合适的收缩因子α使该对象更加靠近类的中心。多个代表点的选择使该算法适合处理类团非球状的几何形状。
CRUE聚类算法对相关矩阵聚类的步骤如下:
(1)对任意主题词ki(1≤i≤n),其n维坐标表现形式为ki=(ri1,ri2,…,rin),(ri1,ri2,…,rin)为矩阵R中第i行元素,将主题词初始Ki化为第i类。对于类i(1≤i≤n),其中心点为i.mean,代表点为i.rep。中心点初始化为i.mean=(ri1,ri2,…,rin),代表点初始化为i.rep=(ri1,ri2,…,rin),合并距离最近的两个类。对于类i和j,距离计算公式为
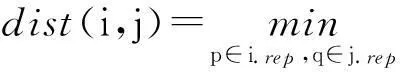
(6)
dist(p,q)为代表点p和q之间的欧式距离。
(2)计算新类的中心点和代表点。新类的中心点计算公式为
(7)
新类的代表点计算公式如下
wrep=p+α×(wmean-p)
(8)
研究证明当α收缩因子取值在0.2~0.7之间聚类效果较好,本文α取0.5。
(3)重复步骤2,直到得到预期的聚类数。
3实验数据和分析
3.1数据来源及实验环境
本研究以PubMed数据库中2012/01/01~2014/11/06发表的以Lung Cancer为Mesh(Medical Subject Headings)主题词的文献作为研究对象。过滤掉没有免费全文pdf的文献,最终对4 251篇文献进行分析,挖取高频主题词72个,对72个高频主题词进行聚类分析。如表1所示。
本实验在PC端进行,操作系统是Windows 7,算法编写工具是Eclipse,用Java语言编程实现。

表1 高频主题词表
3.2改进之前的共词分析方法结果
将共词矩阵导入IBMSPSSStatistics,选择系统聚类,通过组间连接方法使合成的新类各个变量之间的平均距离最短,通过平方欧式距离来计算类与类之间的距离,绘制出的树状图,如图2所示。

图2 传统共词分析方法聚类结果
主题词被分为9类:第1类由主题词2,3构成;第2类由主题词14,23,24构成;第3类由主题词45,57,26,25,28,41,55构成;第4类由主题词40,66,5,36,22,50构成;第5类由主题词21,65,53构成;第6类由主题词7,42,15,4,19,17,18,46,6,35,44,1,51,62,39,54,9,32,38,13,27,10,58,68,60,67,33,61构成;第7类由主题词37,59,71构成;第8类由主题词47,69,43,31构成;第9类由主题词8,29,11,52,72,30,48,12,20,16,56构成。
3.3改进之后的共词分析方法结果
在Java平台编写CRUE算法代码对改进后的共词矩阵进行聚类,聚类结果被分成了5类:第1类由主题词24,26,14,8,16,43,59,12,20,72,6,48,56,49,30,71,23构成;第2类由主题词2,3,11,29,5,28,40,66,70,19,51,7,63构成;第3类由主题词4,13,61,28,54,58,27,32,39,21,9,62,69,31,35,42,1,10,17,68,53,60,33构成;第4类由主题词47,64,18,34,37,52,67,44,46构成;第5类由主题词22,65,41,36,55,45,57,15,50,25构成。
3.4聚类效果对比分析
由聚类结果可知改进后的共词分析方法效果更加理想,如主题词22,65,41,55分别对应为RetrospectiveStudies,ProspectiveStudies,Case-ControlStudies,CohortStudies,这4个主题词在改进后的共词分析法中被聚为一类,在传统共词分析法中被分在3个类别中。主题词2,3对应为Female,Male,在改进后的共词分析法中和主题词Smoking,Adult,SurvivalRate等主题词聚在一个类中,在传统共词分析法中两个主题词聚成一类。
改进后的共词分析法将聚类结果分为5类:(1)肺癌单核苷酸多态性、肺癌遗传易感性研究以及DNA结合蛋白质类研究;(2)肺癌多发人群、年龄段、存活率以及吸烟与肺癌之间的关系等因素统计研究;(3)肺癌患者化疗疗效的研究,尤其是喹唑啉类对肺癌的化疗作用以及肺癌中的酶学研究和应用;(4)肺癌相关基因,细胞组织的研究;(5)肺切除术在肺癌中的治疗效果,术后生存率,以及发展现状的研究。
4结束语
本文使用共词聚类分析方法来挖掘PubMed中肺癌领域的研究热点。本文根据PubMed中数据库文献的特点,提出一种新的方法统计高频主题词在xml文献中的共现情况加权结合高频主题词在pdf文献中的共现情况构造共词矩阵。并利用CRUE聚类算法对共词矩阵进行聚类,实验验证其效果颇为理想。
本文构造共词矩阵的加权系数有待进一步优化。文中提取xml文献中的高频主题词为基础构造共词矩阵,忽略副主题与主题词之间的联系,随着聚类算法针对性越来越强,每种聚类算法聚类效果各不相同,如何选取最合适的聚类算法对共词矩阵进行聚类分析同样值得深入研究。
参考文献
[1]U.S.NationalLibraryofMadicine.NCBIdata[EB/OL].(2014-12-18)[2015-06-12]http://www.ncbi.nlm.nih.gov/pubmed.
[2]马费成,望俊成,陈金霞,等.我国数字信息资源研究的热点领域:共词分析透视[J].情报理论与实践,2007,30(4):438-443.
[3]MahmoudRokaya,ElsayedAtlam,MasaoFuketa,etal.Rankingoffieldassociationtermsusingco-wordanalysis[J].InformationProcessingandManagement,2008,44(2):738-755.
[4]杨彦荣,张阳.加权共词分析法研究[J].情报理论与实践,2011,34(4):61-63.
[5]皇甫青红,华薇娜,刘艳华,等.国际数字图书馆领域研究热点及作者团体分析——基于共词分析和社会网络分析[J].情报杂志,2013,32(1):118-123.
[6]薛薇.统计分析与SPSS的应用[M].北京:中国人民大学出版社,2011.
[7]吴夙慧,成颖,郑彦宁,等.K-means算法研究综述[J].现代情报图书技术,2011(5):28-35.
[8]Callon.Co-wordanalysisforbasicandtechn-ologicalreseach[J].Scientmetrics,1991,22(2):155-2.
[9]JonathanHedley.Jsoup:javahtmlparser[EB/OL].(2009-11-29)[2015-06-12]http://jsoup.org.
[10]KarypisG,HanEH,KumarV.Chameleon:Ahierarc-hicalclusteringalgorithmusingdynamicmodeling[J].Computer,1999(32):68-75.
[11]魏桂英,郑玄轩.层次聚类方法的CRUE算法研究[J].科技与产业,2005,5(11):22-24.

欢 迎 刊 登 广 告
请访问:www.dianzikeji.orgE-mail:dzkj@mail.xidian.edu.cn
联系电话:029-88202440传真:029-88202440
Co-word Clustering Analysis Based on PubMed
MAO Chunli,CAO Chunping
(School of Optical-Electrical and Computer Engineering,University of Shanghai for
Science and Technology,Shanghai 200093,China)
AbstractThe co-word matrix in the current co-word clustering analysis can not fully reflect the connection between the keywords.This paper proposes a new method to build co-word matrix based on the high frequency keywords co-occurrence in the same paper with variety of formats.The shortcomings of traditional clustering algorithms,such as poor performance in non-spherical cases and difference in size clusters,are pointed out.The paper proposes an improved CRUE algorithm to cluster the Co-word matrix.The new co-word clustering analysis has been made of lung cancer in PubMed,which proves its feasibility.
Keywordsco-word clustering analysis;co-word matrix;CRUE clustering algorithm;PubMed
中图分类号G354
文献标识码A
文章编号1007-7820(2016)02-053-05
doi:10.16180/j.cnki.issn1007-7820.2016.02.014
作者简介:冒纯丽(1991—),女,硕士研究生。研究方向:数据挖掘。曹春萍(1968—),女,副教授。研究方向:智能决策知识系统,个性化服务。
基金项目:国家高科技研究发展计划(863)基金资助项目(2014AA021502)
收稿日期:2015- 07- 03
