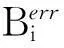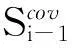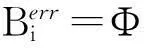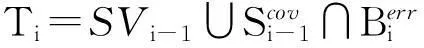一种基于KKT条件和壳向量的SVM增量学习算法
2016-02-26茅嫣蕾
茅嫣蕾,魏 赟,贾 佳
(1.上海理工大学 光电信息与计算机工程学院,上海 200093;2.上海生物信息技术研究中心,上海 201202)

一种基于KKT条件和壳向量的SVM增量学习算法
茅嫣蕾1,2,魏赟1,贾佳2
(1.上海理工大学 光电信息与计算机工程学院,上海200093;2.上海生物信息技术研究中心,上海201202)
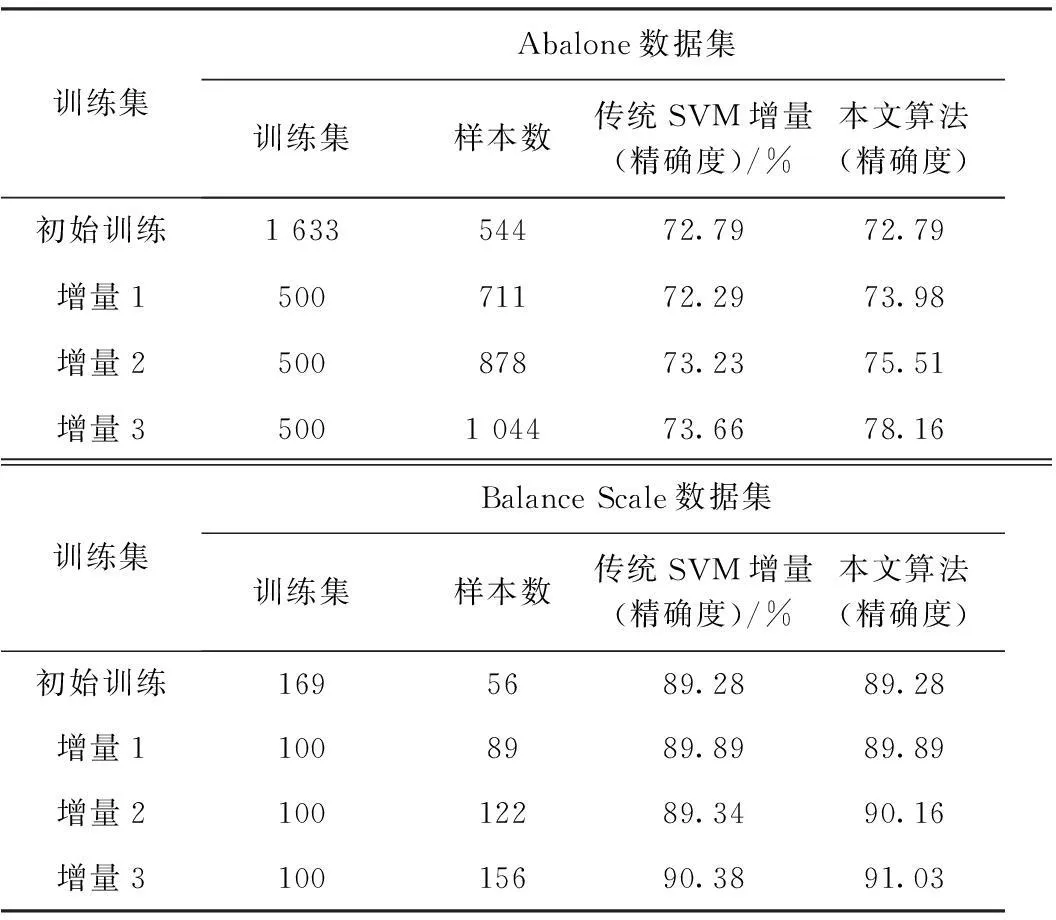
摘要针对传统支持向量机(SVM)增量算法,在学习过程中因基于局部最优解而可能舍弃含隐性信息的非支持向量样本,以及对于新增样本需全部进行训练的缺点,文中提出一种基于KKT条件和壳向量的SVM增量学习算法。该方法利用壳向量的特性保留了训练样本集中可能含隐性信息的非支持向量,并只将违反KKT条件的增量样本加入新的训练集,从而提高运算效率。通过对公共数据集Abalone和 Balance Scale的实验表明,新算法在属性列数较多的数据集上分类效果更明显。
关键词SVM;增量学习;KKT条件;壳向量
支持向量机(Support Vector Machines,SVM)是由Vapnik等人提出的一种有监督的机器学习算法。其基于结构风险最小化原则和统计学中的VC维理论,在解决非线性和高维问题时表现出良好的特性。近年来在文本分类[1]、目标识别[2]、时间序列的预测[3]等领域得到广泛应用。与传统的学习相比,增量学习在加入增量样本进行新的训练过程中充分利用历史训练结果,减少了训练时间同时又降低了存储空间[4]。
基于SVM的增量学习概念最早是由Syed提出的,在文献[5]中提出了一种分块增量学习SVM算法,该算法的基本思想是在每次增量学习后保留支持向量(Support Vector,SV),舍弃非支持向量,并将本次支持向量集与新增样本作为下一次学习的训练样本。其在算法求解上仍使用标准的SVM,并未进行改进。每次训练求得的支持向量集是局部最优解,而每次将可能包含隐性信息的非支持向量集全部舍弃,会导致分类精度的下降。针对以上问题,已有一些研究者提出了一些改进方法。文献[6~7]通过引入KKT条件,在新增样本中筛选最有可能成为支持向量的样本加入到新的训练集中。文献[8]通过两次求解壳向量来提高SVM增量学习的分类精度。文献[9]在简单SVM增量学习的基础上,提出一种基于遗忘因子T的SVM增量学习算法,对样本有选择的进行遗忘,从而提高训练速度,降低存储空间的占用。本算法利用KKT条件筛选新增样本加入新的训练集,以提高运算效率,利用壳向量的特点保留了非支持向量集中可能在下一次训练中成为支持向量的壳向量,从而提高分类精确度。
1SVM理论
SVM的基本思想是通过用内积函数定义的非线性变换将数据输入空间变换到一个高维空间,然后在这个空间中求最优线性分类面。假设存在样本(x1,y1),…,(xl,yl),xi∈Rn,yi∈{+1,-1}为类别标号,l为样本数,n为输入维数,支持向量机要寻找一个最优超平面f(x)=(w,x)+b,使得测试数据尽可能正确地分类。最优超平面即在正确分类两类样本的同时,使得分类间隔margin最大,如图1所示。
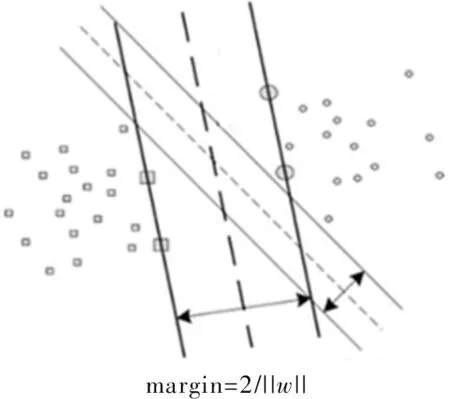
图1 最优超平面
对于线性可分的情况,可转化成如下二次优化问题,将其转化为Lagrange函数并根据Wolfe对偶定义,得到最优决策函数
(1)
对于非线性可分的情况,引入核函数K(xi,yi),将训练样本映射到一个高维线性特征空间。通过引入一个非负的松弛变量ξ,将最优问题转化为
(2)
s.t.yi((ω·xi)+b)+ξi≥1,i=1,2,…,l
ξ≥0,i=1,2,…,l
(3)
通过转化为Lagrange函数并根据Wolfe对偶定义,最终得到决策函数
(4)
其中,K(xi,yi)为核函数,通过非线性映射得到。
2改进的SVM增量学习
增量学习的过程中,其主要任务是利用历史结果避免重复训练,并得到了较高精确度的分类结果。传统的SVM在增量学习的过程中主要是寻找支持向量集SV,用于下一次训练。其在每次的增量训练中得到的支持向量集SV是基于局部最优解,从而导致可能将含有隐性信息的非支持向量全部舍弃。本文通过结合KKT条件和壳向量的特点来改进传统的SVM增量学习,从而提高分类器的准确率。
2.1KKT条件
对于上述对偶问题中的最优解α=[α1,α2,…,αl],使得每个样本x满足优化问题的KKT条件为
K1+160—K1+310边坡总长150 m,由于是开挖阶段故以施工便道通行的工程车辆为主,平均车速约为Vv=20 km/h,日通过车次约Nv=360辆/日。计算得到人员时空概率PS∶T=0.1125。
(5)
定理1SVM中,α=0的样本分布于分类间隔之外;0<α 由此可将上述KKT条件转化为 (6) 定理2若新增样本中存在某些违反KKT条件的样本,则这些违反KKT条件的样本中肯定存在新的支持向量;若新增样本中不存在违背KKT条件的样本,则新增样本中肯定不存在新的支持向量。 定理3若新增样本中存在违反KKT条件的样本,则上次训练结果中的非支持向量有可能转化为支持向量。 由上述定理知,可根据KKT条件对新增样本集进行筛选。对于新增样本中违反KKT条件的样本,说明原支持向量中不包含这部分信息,需将其与原非支持向量一同加入进行训练。而对于新增样本集中没有违反原支持向量的KKT条件,说明已包含这部分信息,即为对分类无用的样本,可进行舍弃。通过该种方式大幅减少了对新增样本的学习,同时又不影响原支持向量所含的信息。 2.2壳向量 由前文对SVM机理的介绍可知,SVM在训练的过程中寻找的是对分类起决定作用的支持向量的样本。在对样本训练的过程中只有类边界附近样本有可能成为支持向量[10]。定义壳向量为所有位于训练集中类边界的样本,即壳向量是样本集凸顶点。求壳向量集合S的方法:首先求出给定样本集中各类的最小超球体,然后以超球面上的点作为初始的壳向量,通过迭代方法求出其极点集合S0,最后从S0中逐步舍弃一些多余的内点从而求出凸壳的壳向量集合[11]。 3算法设计与实验分析 由于传统的SVM增量学习每次通过训练求得的支持向量集是局部最优解,故每次舍弃的非支持向量中可能包含隐性信息,从而导致分类精度下降。本文针对这一问题本文在改进传统SVM增量学习时利用KKT条件筛选新增样本加入新的训练集,利用壳向量可能成为支持向量的特性,保留了非支持向量中的壳向量部分,即可能含隐性信息的非支持向量,将其加入下一次训练。 3.1算法的设计 设T0为初始样本集,B为新增样本集B={B1,B2,…,Bn},且T0∩B1∩B2∩…∩Bn=Φ。算法: (1)使用标准的SVM对初始样本集T0进行训练,得到初始向量集SV0和决策函数f0; (2)加入新增样本集Bi,若i>n,算法终止,否则转(3); 3.2实验分析 为验证本文算法的有效性,采用本文提出的基于KKT条件和壳向量的增量学习算法与传统的SVM增量学习进行比较。实验数据使用UCI数据库中的Abalone数据集和BalanceScale数据集。实验过程中核函数均选用径向基函数(RadialBasisFunction,RBF)。训练样本数与测试样本数比为3:1,如表1所示。在数据集Abalone上的每次增量学习样本数为500,在数据集BalanceScale上每次增量学习样本数为100,实验结果如表2所示。 表1 实验数据集 表2 实验结果 由上述实验可知,本文算法与传统SVM增量学习算法相比,在数据集的属性列数较少的Balance Scale数据集上都显示出良好的分类特性。在数据集的属性列数较多的Abalone数据集上,本文算法的分类精确度要高于传统SVM增量学习算法,以上结果验证了本文算法的有效性。 4结束语 本文分析了SVM的特性,探讨了传统SVM增量学习的不足之处。在此基础上利用KKT条件以及壳向量的特性提出一种新的SVM增量学习算法。并在UCI数据库中的Abalone数据集和Balance Scale数据集上验证了本文算法的有效性。 参考文献 [1]崔建明,刘建明,廖周宇.基于SVM算法的文本分类技术研究[J].计算机仿真,2013,30(2):299-302. [2]David A,Lerner B.Support vector machine-based image classification for genetic syndrome diagnosis[J].Pattern Recognition Letters,2005,26(8):1029-1038. [3]尹华,吴虹.最小二乘支持向量机在混沌时间序列中的应用[J].计算机仿真,2011,28(2):225-227. [4]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138. [5]Ruping S.Incremental learning with support vector machines[C].DA USA:Proceedings IEEE International Conference on Data Mining,2001. [6]Wu C,Wang X,Bai D,et al.Fast incremental learning algorithm of SVM on KKT conditions[C].SA USA:Proceedings of the 6th International Conference on Fuzzy Systems and Knowledge Discovery,IEEE Press,2009. [7]吴崇明,王晓丹,白冬婴,等.利用KKT条件与类边界包向量的SVM增量学习算法[J].计算机工程与设计,2010,31(8):1792-1794. [8]王一,杨俊安,刘辉,等.一种基于内壳向量的SVM增量式学习算法[J].电路与系统学报,2011,16(6):109-113. [9]萧嵘,王继成,孙正兴.一种SVM增量学习算法α-SVM[J].软件学报,2001,12(12):1818-1824. [10]周伟达,张莉,焦李成.支撑矢量机推广能力分析[J].电子学报,2001,29(5):590-594. [11]薛贞霞.支持向量机及半监督学习中若干问题的研究[D].西安:西安电子科技大学,2009. A New Incremental SVM Learning Algorithm Based on KKT Conditions and Hull Vectors MAO Yanlei1,2,WEI Yun1,JIA Jia2 (1.School of Optical-electrical and Computer Engineering,University of Shanghai for Science and Technology, Shanghai 200093,China;2.Shanghai Center for Bioinformation Technology,Shanghai 201202,China) AbstractThe traditional support vector machine (SVM) incremental algorithm in the learning process may give up the non-support vectors with implicit information,and requires the training of all the incremental samples.This paper presents a new incremental SVM learning algorithm based on KKT conditions and hull vectors.The algorithm makes use of the characteristics of hull vectors to retrain non-support vectors with implicit information,and it only add the samples violating the KKT conditions to the new training set.The experimental results from Abalone dataset and Balance Scale dataset show this algorithm has better classification effect in the datasets with more columns of properties. KeywordsSVM;incremental learning;KKT conditions;hull vectors 中图分类号SVM 文献标识码A 文章编号1007-7820(2016)02-038-04 doi:10.16180/j.cnki.issn1007-7820.2016.02.010 作者简介:茅嫣蕾(1991—),女,硕士研究生。研究方向:机器学习等。 基金项目:国家自然科学基金资助项目(61170277);上海市教委科研创新基金资助项目(12YZ094) 收稿日期:2015- 06- 09