基于Landsat5 TM遥感影像估算江山市公益林生物量*
2016-02-26张伟陈蜀蓉侯平
张伟,陈蜀蓉,侯平
(浙江农林大学林业与生物技术学院,浙江 临安311300)
基于Landsat5 TM遥感影像估算江山市公益林生物量*
张伟,陈蜀蓉,侯平
(浙江农林大学林业与生物技术学院,浙江临安311300)
摘要:本研究基于Landsat5 TM遥感影像数据和样地调查数据,利用多元逐步回归、偏最小二乘回归和随机森林回归3种方法,建立江山市公益林生物量估算模型,分析和比较3种模型的精度结果,探究随机森林回归模型在估算生物量方面的应用,为提高估算森林生物量的精度提供参考。结果表明,多元逐步回归模型的预测精度为58.31 %、均方根误差为31.02 t/hm2,偏最小二乘回归模型分别为60.84 %、30.72 t/hm2,随机森林回归模型为70.02 %, 22.18 t/hm2。由此可得,随机森林回归模型的预测精度优于其他2种模型,随机森林算法能提高估算森林生物量的精度。
关键词:生物量估算;随机森林回归;多元逐步回归;偏最小二乘回归
全球气候不断变暖,森林碳储量的研究成为社会关注的一个热点,而森林生物量的估算是森林碳储量和碳循环研究的基础。随着遥感技术的发展,学者们逐渐改变了传统估算森林生物量的方法,转而利用遥感影像信息和典型样地调查的数据建立某种关系的模型对森林生物量进行估算,这种方法不但减少了对生态系统的破坏,而且还减少了大量的人力和物力,使大尺度的森林生物量的估算成为可能[1~3]。
21世纪初,Leo Breiman 和Cutler Adele开发完成随机森林(Random Forests)算法[4]。随机森林是基于分类树的一种算法,在分类和回归中都有广泛的应用[5~6],并取得较好的效果。它运算速度快,能高效的处理大数据,不需要考虑一般回归模型存在的自变量间的多重共线性的问题,能有效的提高模型的预测精度[7]。在国外,随机森林算法最近10多年来得到迅速发展,已经广泛应用在医学、管理学、经济学等众多领域[8~10]。但在国内,对于随机森林方面研究较少,而应用在森林生物量估算方面寥寥无几[11]。
本项研究基于遥感信息和样地调查数据,利用随机森林算法、多元逐步回归及偏最小二乘回归等3种方法建立江山市的森林生物量估算模型,研究和分析随机森林回归模型在估算森林生物量的精度,并择优对江山市的公益林生物量进行反演。本项研究方法将为随机森林算法估算森林生物量提供参考依据,为江山市的公益林生物量估算提供可行性方法。
1研究区域概况
江山市(北纬28°15′~28°53′,东经118°22′~118°48′48″)位于浙江省西南部,以山地丘陵为主,属于中亚热带北部湿润季风气候区,冬夏季风交替明显,四季冷暖干湿分明,光照充足,降雨充沛,雨热同期。平均气温为17.0℃。全市土地总面积20.13×104hm2,其中林业用地面积14.69×104hm2,占土地总面积的73 %,有林地面积12.75×104hm2,森林蓄积量673.3×104m3,森林覆盖率68.4 %。公益林面积为5.26×104hm2,占全市土地面积的26.13 %。根据森林类型大致可分为6类,即松〔包括马尾松(Pinusmassoniana)、湿地松(Pinuselliottii)〕林、毛竹(Phyllostachysheterocycla)林、杉木(Cunninghamialanceolata)林、灌木林、针阔混交林、常绿阔叶林。
2研究方法
2.1 样地数据来源与处理
采用2阶抽样法,在对固定监测小班全面普查的基础上,选取典型地段以设置面积为20 m×20 m的固定样地,详细记录样地基本信息,包括经纬度、海拔、坡度、坡向等环境因子[12~13];样地内乔木层(胸径大于5 cm)采用每木调查(包括测定树高、胸径、冠幅和枝下高等),同时在每块样地对角线上均匀设置3个2 m×2 m的灌草固定小样方,详细记录灌木种类、株数、盖度、高度以及草本种类、株数、盖度等指标[14~15]。根据固定小班监测数据和浙江省重点公益林生物量模型[16],推算各样方森林生物量(包括乔木层、灌木层以及草本层)。由于固定样地与遥感图像的分辨率大小不一致,本项研究将各研究区域的样地生物量按比例换算成与遥感图像分辨率大小一致的样地生物量。乔木生物量的单位为kg/400m2,灌木生物量和草本的单位为kg/4m2,为与遥感图像分辨率大小一致,将乔木生物量、灌木生物量和草本生物量的单位换算成30 m×30 m范围的面积内的生物量,得到单位为t/900m2的生物量值,最后转化成单位为t/hm2的生物量值。此次调查共抽取江山市监测样地80个。

图1 江山市海拔分布图
2.2 遥感数据处理
本项研究以2009年12月6日的Landsat5 TM 影像为数据源,从1︰10000地形图上采集地面控制点,使用ENVI 4.8遥感图像处理软件对遥感影像进行几何精校正和地形校正[17](改进的C校正法)[18],误差控制在1个像元内,重采样后像元大小为30 m×30 m。为减少实测样地与影像的配准误差,选取样点坐标附近的9个像元的平均值作为该样点的变量值。
本项研究选取66个自变量作为建模的初始自变量,分别是6种原始波段、4种波段组合信息、8种植被指数信息、48种纹理信息及5种地学信息(包括经纬度信息、海拔、坡度和坡向),初始自变量与江山市森林生物量的相关系数详见表1。

表1 自变量因子与样地生物量相关系数
注:(1)TM3123457=TM3/(TM1+TM2+TM3+TM4+TM5+TM7);DVI=TM4-TM3;IIVI=(TM4-TM5)/(TM4+TM5);TM437=TM4×TM3/TM7;TM73=TM7/TM3;SR=TM4/TM3;EVI=5×(TM4-TM3)/(TM4+6×TM3-7.5×TM1+1);TVI=(NDVI+0.5)^0.5;TM452=(TM4+TM5-TM2)/(TM4+TM5+TM2);PVI=0.939×TM4-0.344×TM3+0.09;SAVI=1.5×(TM4-TM3)/(TM4+TM3+0.5)。(2)**在P为0.01水平上极显著相关;*在P为0.05水平上显著相关。
2.3 模型评价指标

3模型的建立
3.1 多元逐步回归模型
使用SPSS19.0软件进行多元逐步回归分析,将超出2倍标准化残差阈值的数据作为异常点剔除后重新建模,重复上述步骤直到没有异常值剔除[21],经过剔除后余下53个样地数据作为拟合样本,18个样地数据作为预测样本。利用拟合样本建立多元逐步回归模型,经过筛选后最终有4个变量通过检验,分别是B5、TM73、CONB2和ENTB5,模型的拟合相关系数为0.645 4,RMSE是26.46 t/hm2,预测精度为68.12 %。
多元逐步回归模型表达式为,BIOMASS=41.050-7.998×CONB2+49.247×ENTB5-877.193×B5+85.516×TM73,式中:B5是第5波段数值;TM73是第7波段与第3波段的比值;CONB2是第2波段的对比度;ENTB5是第5波段的熵。
江山市多元逐步回归模型描述及显著性检验分别如表2~3。

表2 江山市多元逐步回归模型描述及参数表

表3 江山市多元逐步回归模型系数与显著性
3.2 偏最小二乘回归模型
偏最小二乘回归(PLS)[22]主要是运用主成分的思想,并结合典型相关分析的多元统计分析方法,它克服了传统回归模型中自变量之间多重共逐步的问题,它是由伍德和阿巴诺于1983年首先提出的回归方法[21,23]。其基本思路:设已知单因变量Y和自变量[x1,x2,…,xn],样本个数为n,在X与Y相关矩阵中提取第一主成分t1,Y与X对t1进行回归,采用交叉有效性原则,确定提取的主成分个数,将这些主成分作为自变量表达为Y对原始变量X的回归方程[24]。将初始自变量和拟合样本建立模型,在相关性大小和自变量间多重相关性的基础上,根据构建模型的R2不断选取和调整自变量,最终选取的自变量分别是SECB1、CONB2、CONB3、CORB4和ENTB5,确定的最佳成分个数为2。将18个检验样本代入模型中进行检验。模型的拟合相关系数为0.691 6,RMSE为27.41 t/hm2,预测精度为69.16 %。
偏最小二乘回归的模型表达式为,BIOMASS=12.487+82.923×SECB1-17.653×CONB2+9.066×CONB3+0.234×CORB4+45.586×ENTB5(3-5),式中,SECB1是第1波段的角二阶矩;CONB2是第2波段的对比度;CONB3是第3波段的对比度;CORB4是第4波段的相关性;ENTB5是第5波段的熵。
3.3 随机森林回归模型
随机森林算法是一种基于分类树的统计学习方法,它通过汇总大量的分类树来提高模型预测精度,不用对自变量进行筛选,能较好的容忍噪声和异常值,在许多领域得到广泛的应用[8]。其基本思想是通过Bootstrap重抽样方法从原始样本中抽取多个样本,并且对每个Bootstrap样本都进行决策树建模,然后组合多棵决策树的预测,从而形成随机森林[4]。其算法过程参见李欣海[7]。
本项研究使用所有自变量及经剔除后的53个样地数据进行随机森林回归模型的建立,并预测18个检验样本的森林生物量。利用R软件的randomForest函数包来建立随机森林回归模型,在建立随机森林回归模型中,ntree和mtry是重要的参数,因此要择优选择。ntree是使用bootstrap重抽样的次数,根据图2可知,模型的回归误差在回归树数量达到500后趋于稳定;mtry是使用到的输入变量的个数,其大小在回归分析中通常为输入变量数的1/3,当变量数<3时取1。为确保模型精度,选择ntree为500,mtry为22。经过多次的测试和检验,最终选取的自变量分别是1/B3、ASPECT、SR、VARB1、CORB1、VARB4、CORB4、CORB5和CONB7(图3)。
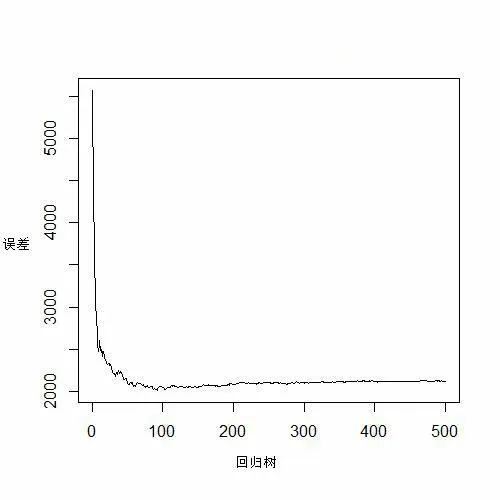
图2 回归误差随回归树数量变化趋势

图3 变量相对重要性
4结果与分析
根据3种模型建立的估算江山市公益林生物量的模型结果如表4。

表4 江山市各模型结果的比较
对于决定系数、精度,随机森林回归模型的效果最好,分别是0.609 1、70.02 %,偏最小二乘回归模型次之,分别为0.441 0、60.84 %,最差为多元逐步回归模型(分别为0.342 6、58.31 %);对于均方根误差,最高的是多元逐步回归模型(34.13 t/hm2),最小为随机森林回归模型(22.18 t/hm2)。对于方差比(VR),随机森林回归模型、偏最小二乘回归模型和多元逐步回归模型分别是0.73、0.54、0.47,随机森林回归模型的预测结果偏离程度较小,而多元逐步回归模型的偏离程度大;对于偏差(BIAS)而言,随机森林回归模型偏差最小为-2.91 t/hm2,多元逐步回归模型和偏最小二乘回归模型的偏差最大,分别是-13.35 t/hm2和-13.37 t/hm2,由图4~5可知,3种模型预测的结果与实测值相比偏低,特别是多元逐步回归和偏最小二乘回归2种模型与实测值相比相差较大。


图4 多元逐步回归结果
图6随机森林回归结果
Fig.6The results of Random Forest model
综合上述5个指标,不管是在拟合样本和预测样本中,随机森林回归模型的预测效果都优于其他2种模型,其次为偏最小二乘回归模型,最差是多元逐步回归模型。因此,选取精度高的随机森林回归模型进行江山市森林生物量的反演。
5模型的应用
根据3种模型的结果分析择优选取随机森林回归模型对江山市公益林生物量进行反演,得到整个研究区公益林生物量(图7)。统计结果表明,2009年底的江山市公益林总生物量约为556.61×104t,生物量密度为105.82 t/hm2,较多处于60~120 t/hm2之间。根据图7可知,江山市生物量的分布为南部高于北部,东部高于西部,主要可能是与江山市的地形及植被分布情况有关(图中白色为零,因为没有数据无法计算)。

图7 江山市公益林生物量反演图
6结论与讨论
从模型的结果分析来看,随机森林回归模型的预测精度为70.02 %,R2为0.609 1,均方根误差为22.18 t/hm2,方差比为0.73,偏差为-2.91 t/hm2。以上5个指标的结果都优于偏最小二乘回归和多元逐步回归模型。而多元逐步回归模型和偏最小二乘回归模型都出现了较大的偏差。
择优选取随机森林回归模型对江山市公益林生物量进行反演,获得公益林总生物量约为556.61×104t,生物量密度为105.82 t/hm2。随机森林回归模型学习过程快,处理了大量的自变量数据,解决了一般回归模型中出现的自变量间多重共线性,还能评估所有变量的重要性[7]。由于随机森林算法本身就具有交叉验证的作用,提高了估算森林生物量的预测精度。因此随机森林算法能较好的应用于森林生物量的估算。
根据模型的预测结果分析,多元逐步回归和偏最小二乘回归2种模型估算江山市公益林生物量都出现较明显的偏差,估算森林生物量的精度较低,这可能与多元逐步回归和偏最小二乘回归模型自身的特点有关。而随机森林算法则利用其自身选择样本和自变量的随机性,注意不同样本和自变量的关系与因变量与自变量之间的关系,不会过度拟合,使预测值更加接近真实值。随机森林算法在江山市的公益林生物量估算中取得较好的预测效果,但是利用随机森林算法估算森林生物量的研究还不够多,不能确定它在其它地区能否取得较好的效果。因此,未来可以进一步加强随机森林算法在不同区域估算森林生物量方面的验证研究。
模型的精度不仅仅是受到模型自身的因素影响,还受到其他多种因素的影响[25]。首先,样地数据并不是实际测量得出的,而是根据生物量模型计算得出。第二,遥感影像信息在校正过程中产生的误差和样地坐标与遥感影像的匹配不准确等因素也会导致的森林生物量的估算精度的降低。在今后的研究中,对于样地的设置和数据的测量中要规范操作减少误差;对于遥感影像的处理过程中,要选取高精度的校正方法,并结合高分辨率的影像或雷达影像,提高遥感影像的精度;在模型建立方面,应该更倾向于结合遥感信息进行遥感数据结合生物过程的生物量遥感机理或半机理模型。
参考文献:
[1]Main-Knorn M,Sean G G M.Evaluating the Remote Sensing and Inventory-Based Estimation of Biomass in the Western Carpathians [J].Remote Sensing,2011,3(7):1427-1446.
[2]Hall R J,Skakun R S,Arsenault E J,etal.Modeling forest stand structure attributes using Landsat ETM+ data:Application to mapping of aboveground biomass and stand volume[J].Forest Ecology and Management,2006,225(1):378-390.
[3]余朝林,杜华强,周国模,等.毛竹林地上部分生物量遥感估算模型的可移植性[J].应用生态学报,2012,23(9):2422-2428.
[4]L B.Random Forests[J].Machine Learning,2001,45(1):5-32.
[5]Peters J,Baets B D,Verhoest N E C,etal.Random forests as a tool for ecohydrological distribution modelling[J].Ecological Modelling,2007,207(2):304-318.
[6]Pall Oskar Gislason,Jon Atli Benediktsson,Johannes R.Sveinsson.Random Forests for Land Cover Classification[J].Pattern Recognition Letters,2006,27(4):294-300.
[7]李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.
[8]方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[9]Andrew Mellor,Andrew Haywood,Christine Stone,etal.The performance of random forests in an operational setting for large area sclerophyll forest classification[J].Remote Sensing,2013,5(6):2838-2856.
[10]Powell S L,Cohen W B,Healey S P,etal.Quantification of live aboveground forest biomass dynamics with Landsat time-series and field inventory data:A comparison of empirical modeling approaches[J].Remote Sensing of Environment,2010,114(5):1053-1068.
[11]王云飞,庞勇,舒清态.基于随机森林算法的橡胶林地上生物量遥感反演研究——以景洪市为例[J].西南林业大学学报,2013,33(6):38-45.
[12]张华柳,伊力塔,余树全,等.嵊州市公益林生物量及生态效益价值评价[J].林业资源管理,2011(1):78-85.
[13]钱逸凡,伊力塔,钭培民,等.浙江缙云公益林生物量及固碳释氧效益[J].浙江农林大学学报,2012,29(2):257-264.
[14]伊力塔,严晓素,余树全,等.浙江省不同森林类型林分健康指标体系[J].南京林业大学学报(自然科学版),2012,36(1):145-148.
[15]钱逸凡,伊力塔,张超,等.浙江省中部地区公益林生物量与碳储量[J].林业科学,2013,49(5):17-23.
[16]袁位高,江波,葛永金,等.浙江省重点公益林生物量模型研究[J].浙江林业科技,2009,29(2):1-5.
[17]鲍晨光,范文义,李明泽,等.地形校正对森林生物量遥感估测的影响[J].应用生态学报,2009,20(11):2750-2756.
[18]黄微,张良培,李平湘.一种改进的卫星影像地形校正算法[J].中国图象图形学报,2005,10(9):1124-1128.
[19]范文义,张海玉,于颖,等.三种森林生物量估测模型的比较分析[J].植物生态学报,2011,35(4):402-410.
[20]Foody G M,Cutler M E,Mcmorrow J,etal.Mapping the biomass of Bornean tropical rain forest from remotely sensed data[J].Global Ecology and Biogeography,2001,10:379-387.
[21]徐小军,周国模,杜华强,等.基于Landsat TM数据估算雷竹林地上生物量[J].林业科学,2011,47(9):1-6.
[22]Nguyen Hung T L B.Assessment of rice leaf growth and nitrogen status by hyperspectral canopy reflectance and partial least square regression[J].European Journal of Agronomy,2006,24(4):349-356.
[23]王慧文,吴栽彬,孟洁.偏最小二乘回归的线性与非线性方法[M].北京:国防工业出版社,2006:152-153.
[24]刘琼阁,彭道黎,涂云燕,等.基于偏最小二乘的森林生物量遥感估测[J].东北林业大学学报,2014,42(7):44-47.
[25]Lu D, Chen Q, Wang G,etal.Aboveground forest biomass estimation with landsat and LiDAR Data and uncertainty analysis of the estimates[J].International Journal of Forestry Research,2012(2):1-16.
Landsat5 TM-based Biomass Estimation of
Public-welfare Forest of Jiangshan City
ZHANG Wei,CHEN Shu-rong,HOU Ping
(School of Forestry and Biotechnology,Zhejiang A & F University,Lin’an Zhejiang 311300,P.R.China)
Abstract:By using Landsat5 TM data and forest inventory data,multi-stepwise regression model,partial least square regression model and random forest regression model were built to estimate forest biomass in Jiangshan City,and the accuracy of these three models were analyzed and compared to study the application of regression models in forest biomass estimation.The results showed that the precisions and root mean square errors of multi-stepwise,partial least square regression and random forest were 58.31%,and 31.02 t/hm2,60.84 % and 30.72 t/hm2, 70.02 % and 22.18 t/hm2respectively.Therefore random forest regression model is better than the other two models,and it could improve the accuracy of forest biomass estimation.
Key words:biomass estimation;random forest regression;multi-stepwise regression;partial least square regression
通讯作者简介:侯平(1961-),男,教授,博士,博士生导师,主要从事生态恢复研究。E-mail:houpingg@263.net
作者简介:第一张伟(1988-),男,硕士生,主要从事生态环境监测与区域碳收支评估研究。E-mail:zjzhangwei321@163.com
*收稿日期:2015-06-04
中图分类号:S 718.55+6
文献标识码:A
文章编号:1672-8246(2016)01-0105-07

