基于云存储视频处理框架的研究与实现
2016-02-24谭郁松伍复慧张京京
王 法,谭郁松,伍复慧,张京京
(国防科学技术大学 计算机学院,湖南 长沙 410073)
基于云存储视频处理框架的研究与实现
王 法,谭郁松,伍复慧,张京京
(国防科学技术大学 计算机学院,湖南 长沙 410073)
随着智慧城市的快速发展,视频技术作为基础数据采集手段已经被广泛使用。这会引发一个问题:短时间内生成的海量视频数据无法快速处理,从而严重影响数据时效性价值的问题愈来愈严重。文中提出一套基于HBase的分布式处理框架。该框架首先支持多客户端同时上传的视频,然后提取其中出现的人脸,最终建立一个可以保存在内存中的索引表进行查询加速。通过处理客户端上传的含有待查人脸的图像,该框架可以快速定位人脸在上传的视频中出现的位置。针对上述需要实现的功能,文中详细描述了实现该框架各部分中最重要的表的具体设计细节与设计目的,同时简述了人脸查询的具体流程,并从整个集群的角度优化集群的具体方法。最终通过在百万人脸中查询特定的一张来揭示集群性能。实验结果显示,该框架有较好的性能并完全能满足真实需求。
HBase;Coprocessor;视频检索;云存储
0 引 言
智慧城市就是运用信息和通信技术手段感测、分析、整合城市运行核心系统的各项关键信息,借助新一代的物联网、云计算、决策分析优化等信息技术,通过感知化、物联化、智能化的方式,将城市中的物理基础设施、信息基础设施、社会基础设施和商业基础设施连接起来,成为新一代的智慧化基础设施,使城市中各领域、各子系统之间的关系显现出来,使之成为可以指挥决策、实时反应、协调运作的“系统之系统”[1]。智慧城市意味着在城市不同部门和系统之间实现信息共享和协同作业,更合理地利用资源、做出最好的城市发展和管理决策、及时预测和应对突发事件和灾害[2]。智慧城市的实现过程中,视频技术是其基本感知手段,但随着智慧城市的发展,一个严重问题会慢慢凸显出来。以天津市为例,单一个8 Mb/s的高清摄像头,每小时能产生3.6 GB的数据,“十二五”末天津市将安装60万个摄像头,即每小时天津市产生的视频数据量就达到2.05 PB。如此海量的视频数据如何在一个可以接受的时间段内进行处理并存储,是建设智慧城市过程中必须解决的问题。
1 海量视频数据的存储与处理的相关研究
海量数据存储的思路有两种:一是HDFS。由于Hadoop的广泛应用,处理海量数据很容易联想到用Hadoop,但是由于Hadoop内置的数据类型有限,视频作为典型的非结构化数据不能直接利用MapReduce框架进行处理,解决方法为扩展HDFS原生的接口、类来支持直接对视频、图像进行处理。二是通过HDFS+非结构化数据库。非结构化数据库可以直接支持视频、图像的存取,例如:HBase,MongoDB(MongoDB是介于关系型数据库和非关系型数据库之间的,最像关系型数据库,支持的查询语言多)。具体的存储方案有:邦诺公司的监控专用存储SMI-NVR系统,提供2~8 Gbps的传输带宽和单模块高达48 TB的存储空间,最大容量可以达到64 EB;天地伟业公司的最大一款网络存储产品——IPSAN网络存储系统-V2.0,最大支持96块硬盘,单块硬盘容量支持4 T;SDFS(Sky Distributed File System)通过分布式集群架构将网络中普通PC、通用服务器及各种存储设备集合起来协同工作,并通过专用数据接口,向用户提供海量数据存储、管理和访问服务。部署方式上支持全网分散部署,或在数据中心集中部署。
在视频的处理领域,传统的海量视频处理方案有:
(1)视频浓缩摘要。它将生成一个简短的视频,其中包含了原视频中所有重要的目标活动和快照。这一技术主要通过对目标前景与背景的分割、视频目标活动重排序来摘要和检索。即截取视频中有目标运动的部分进行分析,可使数据量缩小一半左右,但是对于海量视频没有本质的改变[3]。
(2)基于智能分析算法进行检索。目前,业界推出的智能产品已经有周界防范、车牌识别、人脸识别等较成熟的产品。在这些产品中,触发周界防范规则的物体,被识别的车牌和人脸,都可作为视频检索的输入检索条件[4]。一帧图像算法执行时间在10 ms左右,监控视频的帧率为24~25 帧/s,每帧的播放时间为40 ms左右,即检索速度提升了4倍,一个24小时的视频经过浓缩,智能分析算法之后可缩短为3个小时左右。
(3)基于视频数据的元数据的检索。对经过智能算法分析生成的元数据进行检索,24小时的视频检索时间可以控制在10秒量级,但对于60万个摄像头1个小时生成的视频来说,查询其中特定的信息就需要接近70个小时,还不计算海量数据传输对性能的影响。
所以传统的视频处理手段已经不能满足日益增长的性能需求。针对此问题,文中提出一种基于云存储的视频处理框架。该框架所有的部件都是开源软件,实现了从视频中抽取人脸,快速查询某一图片中人脸在视频中出现位置的功能。
2 基于云存储视频处理框架
HBase是基于Bigtable:A Distributed Storage System for Structured Data[5]的开源实现,建立在HDFS上,具有高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统[6]。HBase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力[7]。HBase中表的逻辑结构如图1所示。

图1 HBase表的逻辑结构
图中:Key1,Key2表示行健(Rowkey);T1,T2,T3表示时间戳(TimeStamp);Column1,Column2,Column3表示列(Column);ColumnFamily1,ColumnFamily2表示列簇(ColumnFamily)。
其中,行健、列簇都是不可重复的,而不同的列簇可以有相同的列,如图中ColumnFamily1:Column1,ColumnFamily2:Column1。而要确定一个单元格的位置,就要通过
HBase主体包括两部分:一是HMaster,主要负责一系列的系统级的操作。例如,管理用户对表的增删改查,管理HRegionServer的负载均衡,调整Region分布;RegionSplit后,负责新Region的分布;在HRegionServer停机后,负责失效HRegionServer上Region的迁移。二是HRegionServer,负责响应用户的I/O请求,即数据的入库,查询都是通过RegionServer来处理的[8]。
目前随着云计算的快速发展,海量数据的处理都可以通过云计算来完成,而HBase自身支持的Coprocessor[9]分布式计算框架,可以和HBase共享缓存,不需要单独的内存数据库,同时可以加载到HBase的任意位置,即可以对HBase中所有操作执行前后加载自定义功能。对文中框架来说,即可以在入库的同时分布式地完成数据的处理[10]。
对于视频的处理,采用OpenCV(OpensourceComputerVisionlibrary)开源计算机视觉库来进行。OpenCV对于商业应用和非商业应用都是免费的,有C++,C,Python,Java版本的接口同时支持Windows,Linux,IOS,Android等平台[11]。
综上所述,文中框架所用的软件有HBase+HDFS+Zookeeper(HBase集群需要),分布式计算使用Coprocessor计算框架,视频处理采用OpenCV库。
系统框架图如图2所示。
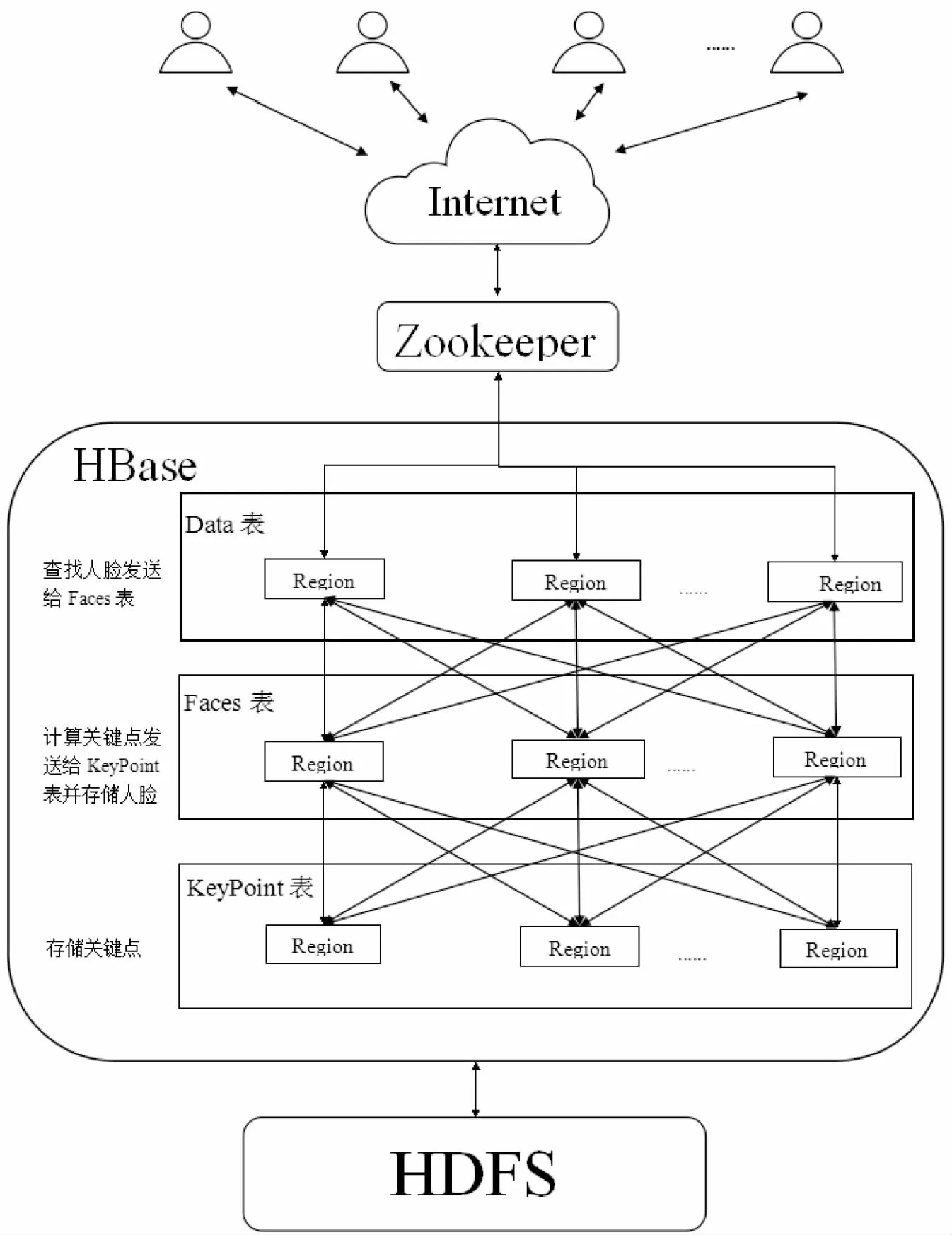
图2 系统框架图
图2中,客户端通过网络访问Zookeeper集群,获取HBase中各个节点的位置[12]。面临海量数据时一个重要的问题就是,怎么能尽可能均匀地把数据分发到集群中的各个节点。若都集中在一个或几个节点,容易引起系统性能降低,甚至宕机等问题[13]。同时若所有数据都存储在磁盘中查询的时候会影响性能,传统解决思路就是把表放到内存中,但是海量数据即使经过提取也不可能放到内存中。下面的实现中会解决这些问题。
3 基于云存储视频处理框架的实现
3.1 表的设计
文中框架的分布式计算是部分通过挂载在各个表上的Coprocessor实现的,用到的表有3个,分别为:Data,Faces,KeyPoint。其具体设计如下:
1)Data、Faces表中行健和列簇设计是相同的。不同的是,Data表并不存储任何数据,而是作为原始数据接收节点进行第一次分布式计算,即检测从客户端上传的每一帧图像中的人脸,而Faces表在保存所有检测到的人脸的同时进行关键点检测,并且两个表支持的数据版本数不一致。所有表的设计都遵循一个原则:尽量保持行健、列簇最小化[14]。两个表的结构为:
(1)行健(Rowkey):形式表示为A+B。其中,A表示一个7位16进制数,B表示文件名,例如:ef00201+file1.avi。其中七位数为这一帧图片在视频中的位置,表示成16进制逆序形式。取七位数是由于目前的视频大都是每秒24~25帧,即使是7*24小时不停地录制成一个文件,最后一帧转换成16进制,也可以表示为8000019。所以为了保持行健尽可能短,只取7位数。逆序是为预防HBase中的HotSpotting问题(即当大量的客户端访问流量集中在集群中的一个或几个节点时,这个流量可能是由大量的读、写或者其他操作造成的,这样超过单一节点反应能力的流量会导致性能下降甚至RegionServer宕机)。而在HBase的设计中,每一个要存入HBase的数据,都是通过Rowkey来定位Region,而HBase中Rowkey是严格按字典序排列的。例如01,02,03,3个Rowkey都是以0开头的,所以它们都会定位到同一个或几个Region中。所以若不做预防,大量具有相同行健首字节的写入请求会导致RegionServer宕机,而把帧数变成16进制逆序就可以把写入请求平均分配到以0-f开头的16个或者16的倍数个Region中,而帧位置+文件名,就可以唯一定位一帧图像了。这样保持了行健的唯一性,生产环境中可以再加入客户端ip,端口,来防止Rowkey重名。
(2)列簇(ColumnFamily):列簇名定为T(Time的首字母),表示的是这一帧图像在视频中的时间,单位为ms,列名以字节形式保存。此设计有2个优点:一是人性化。这样查找到的结果显示的格式就是类似:file:file1.avi,time:01h:01m:30.23s,而不会是file:file1.avi,locate:5600帧;二是在保持需求的情况下,列尽可能得小。
(3)版本数:Data表本身不会存储数据,所以版本数设置为1。而Faces表中存储的数据是一帧图像中提取出来的人脸,由于在一帧图像中可能找到多于一张人脸,所以Faces表中的版本数设定为256个,即文中框架假设一帧图片中定位出的人脸最多有256个,这是2位16进制数可以表示的最大数量。而在实际测试中,一帧图像中所能提取的人脸数量一般只有个位数个。
2)KeyPoint表中存储的是每一张提取出来的人脸的关键点序列,其设计为:
(1)行健(Rowkey):形式表示为A+B。其中,A表示一个2位16进制随机数(与Faces表的版本数对应),B表示本张人脸所对应的图片在视频中的位置,即存储在Faces表中对应数据的行健。例如:ef+ef00201+file1.avi,A对应ef,B对应ef00201+file1.avi。由于每行数据的入库操作都是在不同的RegionServer上提交的,所以很难构造一个可以全局比对的唯一行健,而且进行比对还要花费额外的网络开销。针对此问题,行健的设计:B为Faces表中的行健,所以单就B来说是唯一的,不唯一的情况是一帧图片中提取的人脸不唯一,所以只要在B之前加一个2位16进制随机数,且保证同一帧图片中提取出来的多个人脸所取得的随机数不重复,就可以保证行健的唯一性。取随机数同样是为了预防HotSpotting问题,如果都是从1开始增加,则所有的写入数据还是会定位到一个或几个Region上。
(2)列簇(ColumnFamily):列簇名为F(From的首字母),存储的是本行数据来自视频中的哪一帧图像的行健。这样只要查询到本条记录之后,就可以直接以行健来查询Faces表。
(3)版本数:由于KeyPoint表中的每一行数据表示的是每一张人脸提取出来的关键点序列,所以版本数设置为1即可。
3.2 数据的查询
数据一遍查询的过程如图3所示。

图3 查询的过程
查询的过程如下:
(1)输入要检测的图片。直接把图片放到程序中设置的文件夹中即可。
(2)判断给定的图片中是否有人脸,若有则跳转到第3步,若没有则跳转到第6步。执行和加载在Data表上的Coprocessor同样的功能,直接把检测结果放到一个List中。若List为空,则表示图片中没有检测到人脸,执行第6步;若List不为空,则对提取出来的结果进行第3步。
(3)计算每张提取出的人脸的关键点序列。为List中每一张提取出来的人脸计算关键点,经过与加载在Faces表中的Coprocessor同样过程的关键点序列提取转化,生成用于查询的字节数组。进行第4步。
(4)构造ValueFilter过滤器,在KeyPoint表中查询,若有则跳转到第5步,若没有则跳转到第6步。构造用于KeyPoint表中查询的ValueFilter中比较运算符设置为EQUAL,比较器使用原生的BinaryPrefixComparator,此比较器从左向右比较当前值与阈值,这样在匹配过程中只要有一位不匹配就放弃,提高了查询速度。若匹配结果为空,执行第6步;若匹配结果不为空,则执行第5步。
(5)提取匹配结果中的列名,直接通过行健构造Get在Faces表中查找。因为KeyPoint表的匹配结果中提取出来的列名即为Faces表中的行键,通过行健检索表直接构造Get即可,执行第6步。
(6)输出结果。若执行顺序为2-6,则表示图片中没有检测到人脸,输出“图片中未检测到人脸”。若执行顺序为4-6,则表示数据库中没有匹配项,则输出“数据库中没有匹配”。若执行顺序为5-6,提取查询结果中的各个数据输出结果:列值,转换为图片即为匹配到的人脸;列名,即为查询到的人脸在视频中出现的时间;行健,跳过7位数就可以得到文件名。
4 性能优化与测评
4.1 处理性能优化
要保证计算的速度,就要尽量使得协处理器(Coprocessor)的计算时间最少。文中框架加载了两个协处理器:
(1)加载于Data表中,与CheckAndPut操作挂钩用于人脸检测的协处理器。即在写入Data表之前判断这一帧图片中有没有人脸,如果有则将提取出来的人脸存入Face表中,如果没有,则抛弃。而OpenCV视觉库中,用于人正脸检测的分类器(CascadeClassifier)有3种,分别是frontface_alt,frontface_alt2,frontface_default。三种检测的硬件环境完全相同,所处理的10帧图片完全相同,三种分类器检测用时如图4所示。
如图4所示,文中框架选择了frontface_default分类器。

图4 三种分类器检测10帧图片用时累积
(2)加载于Faces表中,同样与挂钩CheckAndPut操作用于计算关键点序列的协处理器。即所有检测到的人脸图片在写入Faces表之前都计算关键点,计算结果存入KeyPoint表。OpenCV视觉库中关键点提取算法有很多种,经过实验,在已提取出的人脸图片中始终可以检测到关键点的算法有3种:DYNAMIC_FAST、PYNAMIC_FAST、FAST。只使用单一个频率为2.0 GHz的CPU,分别用3种算法计算3 000帧图片中关键点所用的时间,每次计算都是独立运行,三种算法计算用时如表1所示。
实验结果表明,DYNAMIC_FAST是最快的关键点提取算法。
4.2 查询性能优化
KeyPoint表中存储的是每一张提取出来的人脸的关键点,相当于人脸检索的索引表。为保证查询速度,就要保持KeyPoint表一直在内存中,即要保证KeyPoint表中每条数据尽可能小。而OpenCV中每个关键点的坐标由2个double,3个float,2个int组成。若不做变化直接存储,那么每个关键点需要36 B空间,而经过筛选简化之后,每个关键点只需要16 B,这样就减少了55%的空间。3 000张人脸中的关键点数与平均关键点数如图5所示。

表1 三种检测算法用时
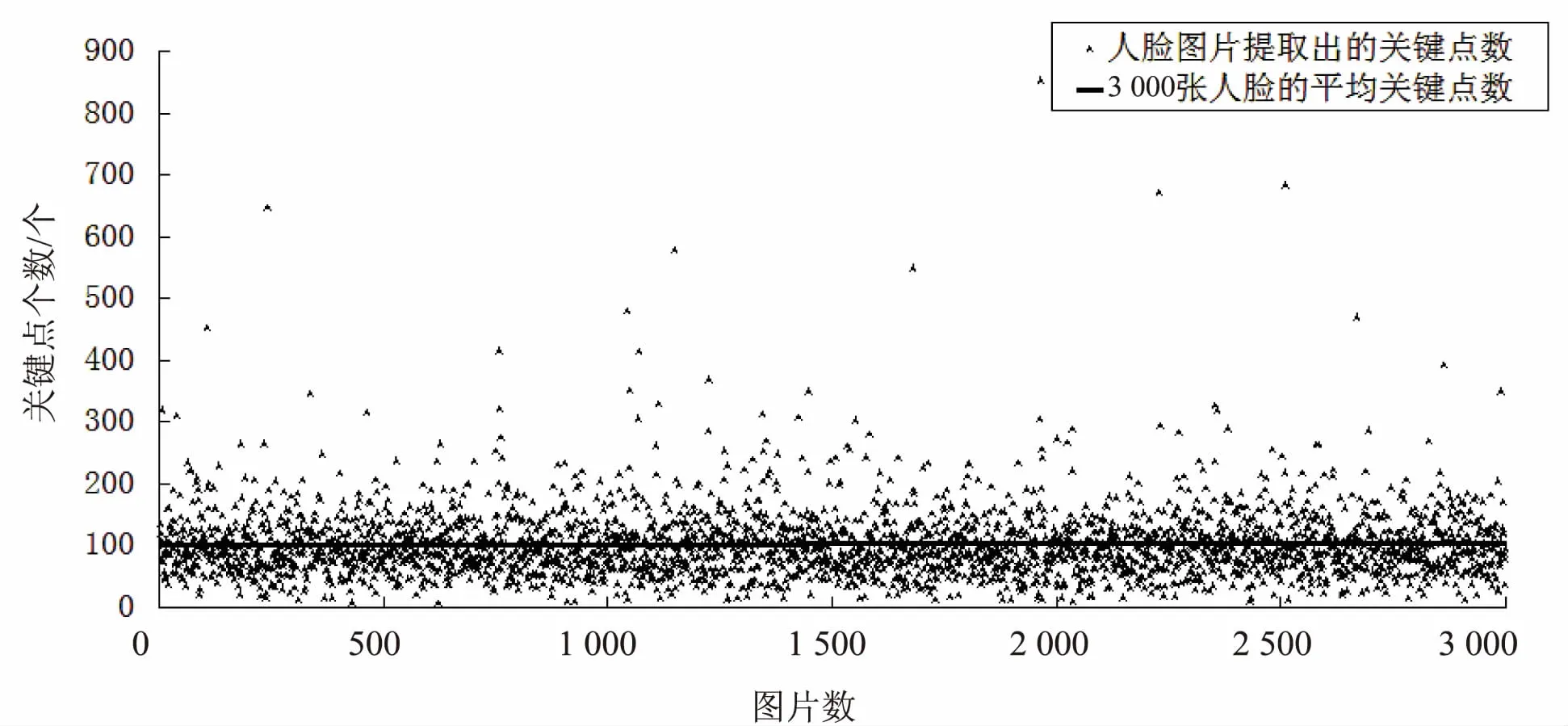
图5 3 000张人脸中的关键点数与平均关键点数
实验结果显示,每张提取出的人脸中其关键点数平均为102个,即每张人脸的关键点需要1 632 B,加上入库时的行健、列簇名、列名、时间戳,即KeyPoint表中每行数据大约为2 000 B,则一千万张人脸的关键点表所占的空间约为18.63 GB。这样的内存占用对于一个集群来说没有压力。
4.3 查询性能测评
测试环境:集群为8个HRegionServer+1个HMaster,所有的节点都部署在广州天河2号云平台上。其中,HRegionServer配置:4核CPU,内存8 G,系统为Ubuntu 14.04;HMaster配置:8核CPU,内存16 G,系统为Ubuntu 14.04。HMaster配置提高是为了通过多线程模拟多个客户端并发提交入库任务。待匹配的表中有人脸1 558 093张,实验所测得的时间包括两次查表时间及结果返回时间,不包括与集群建立链接的时间。200帧图片独立查询时间及平均查询时间如图6所示。

图6 200帧图片独立查询时间及平均查询时间
实验结果显示,在155万帧图片中进行查询,文中框架有较好的性能,查询一张图片中人脸的平均查询时间在1.5 s左右。而其中个别图片的查询时间接近3 s,可能是由于进行近似全表扫描造成的。
5 结束语
文中基于HBase的非结构化存储特性和本身支持的Coprocessor计算框架,设计并实现了一个视频处理框架,在86万图片中平均查询时间为1 s左右。文中对视频处理框架进行了介绍,视频的处理时间的影响因素主要是OpenCV视觉库中的处理算法用时,所以提高视频处理速度的主要途径是优化OpenCV视觉库中的视频处理算法,而查询时间则可以体现该框架的性能。实验结果表明,该框架运用云资源或者PC集群来处理视频是可行的,并有较好的效率。下一步即通过优化OpenCV端的处理算法,来对该框架的整体性能进行优化。
[1] 戈悦迎,寇有观,金江军,等.大数据时代下城市应急管理发展之路[J].中国信息界,2014(1):56-65.
[2] 张永民,杜忠潮.我国智慧城市建设的现状及思考[J].中国信息界,2011(2):28-32.
[3] 郭 斌,蔡巍伟,王 鹏.海量视频数据快速检索[J].中国公共安全,2013(6):109-111.
[4] Garcia A,Kalva H,Furht B.A study of transcoding on cloud environments for video content delivery[C]//Proceedings of the 2010 ACM multimedia workshop on mobile cloud media computing.[s.l.]:ACM,2010:13-18.
[5] Chang F,Dean J,Ghemawat S,et al.Bigtable:a distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):4-4.
[6] 刘炳均,戴云松.基于超算平台和Hadoop的并行转码方案设计[J].电视技术,2014,38(7):123-126.
[7] Dutta H,Kamil A,Pooleery M,et al.Distributed storage of large-scale multidimensional electroencephalogram data using Hadoop and HBase[M]//Grid and cloud database management.Berlin:Springer,2011:331-347.
[8] George L.HBase:the definitive guide[M].[s.l.]:O'Reilly Media,Inc,2011.
[9] Han D,Stroulia E.A three-dimensional data model in HBase for large time-series dataset analysis[C]//Proc of IEEE 6th international workshop on the maintenance and evolution of service-oriented and cloud-based systems.[s.l.]:IEEE,2012:47-56.
[10] Vora M N.Hadoop-HBase for large-scale data[C]//Proc of international conference on computer science and network technology.[s.l.]:IEEE,2011:601-605.
[11] Bradski G,Kaehler A.Learning OpenCV:computer vision with the OpenCV library[M].[s.l.]:O'Reilly Media,Inc,2008.
[12] Hunt P,Konar M,Junqueira F P,et al.ZooKeeper:wait-free coordination for internet-scale systems[C]//Proc of USENIX annual technical conference.[s.l.]:USENIX,2010.
[13] Bertini M,del Bimbo A,Nunziati W.Video clip matching using MPEG-7 descriptors and edit distance[M]//Image and video retrieval.Berlin:Springer,2006:133-142.
[14] Nishimura S,Das S,Agrawal D,et al.MD-HBase:design and implementation of an elastic data infrastructure for cloud-scale location services[J].Distributed and Parallel Databases,2013,31(2):289-319.
Research and Implementation of Video Processing Framework Based on Cloud Storage
WANG Fa,TAN Yu-song,WU Fu-hui,ZHANG Jing-jing
(School of Computer,National University of Defense Technology,Changsha 410073,China)
With the rapid development of smart city,video technology has been widely used as a basic data collection method which has caused a problem that the massive video data generated in a short time wouldn’t process promptly,seriously affecting the timeliness of data value,becomes more and more serious.In this paper,a distributed processing framework based on HBase is proposed.It supports multi-client updated videos simultaneously,then extracts faces appeared in those videos and builds an index table stored in memory to increase query speed.Through processing a frame image which uploaded from client with special faces,the framework could locate those faces in those videos.In response to those functions which needs to be implemented,the details and design purpose of most important table in various parts of framework are described in this paper,meanwhile it outlines the specific processes of the face query,optimizing it from the perspective of entire cluster.Finally,an experiment that retrieves one special face in millions of magnitude of image data is used to reflect the effect of this framework.According to the experiment,this framework has good performance,and actual demand is satisfied completely.
HBase;Coprocessor;video retrieval;cloud storage
2015-08-14
2015-11-18
时间:2016-05-05
国家“863”高技术发展计划项目(2013AA01A212);国家自然科学基金资助项目(61202121);广州市科技计划(2013Y2-00043)
王 法(1990-),男,硕士研究生,研究方向为云计算、云存储;谭郁松,博士,硕导,研究员,研究方向为操作系统、云计算。
http://www.cnki.net/kcms/detail/61.1450.TP.20160505.0829.090.html
TP39
A
1673-629X(2016)05-0001-06
10.3969/j.issn.1673-629X.2016.05.001
