大数据环境下数据挖掘平台的设计研究
2016-02-20孙马莉
孙马莉
(安徽新华学院 财会与金融学院,安徽 合肥 230088)
大数据环境下数据挖掘平台的设计研究
孙马莉
(安徽新华学院 财会与金融学院,安徽 合肥 230088)
大数据时代的到来给人们带来丰富信息量的同时,也给人们获取有效数据带来了不便。怎样从海量的数据里迅速、准确的获取所需信息是目前亟待解决的难题。为了解决这一问题,本文设计了大数据环境下数据挖掘平台;并对平台中应该的数据挖掘技术和算法做了进一步研究分析。
大数据环境;数据挖掘;平台设计
互联网的用户伴随互联网和信息技术的飞速发展也在快速增加,目前每天使用人数达到数十亿,用户的互联网操作行为会导致大量信息数据的产生。有统计数据显示,全球数据总量每年在以ZB(1ZB=10^21KB)为单位增长,其中有接近9成以上的数据产生于近几年[1]。全球的数据总量预计在2020年能达到40ZB。飞速增长的数据量带领人们直接迈入了“信息过载”的时代环境中[2]。人们希望通过这些数据的保存和分析,对其背后隐含的价值和模式进行深入的研究和提取。新的问题和需求必将带来新的挑战,具体体现为大数据的处理、存储以及具体的数据挖掘方法。
本文基于上述研究背景,在大数据环境下构建设计了数据挖掘平台。其目的和意义是在数据量激增的时代,通过平台的海量数据存储和挖掘能力,方便用户的使用,用户只需对平台接口进行访问即可获取具体的服务,也即是说用户在应用过程中只需重点关注本身的业务逻辑即可,有效的节约了数据挖掘方面的成本。
1 大数据环境下数据挖掘平台的设计
1.1 平台整体架构设计
在设计的数据挖掘平台中,大数据的存储和挖掘能力是主要核心功能所在。本文在设计系统架构时通过分层思想的应用,根据系统模块的功能作用,把整个系统划分为服务中间层、基础能力支持层以及业务应用层三个层次,图1给出了具体的系统架构示意图。

图1 大数据环境下数据挖掘平台系统框架
首先是业务应用层,在基于云计算的数据挖掘平台中,该层是作为使用者存在的,只要有数据挖掘能力需求即可应用,值得注意的是,该层并不属于数据挖掘平台,只是属于用户层面的业务应用,是系统的重要参与者。这里的用户指的是业务系统的开发者,其根据具体的业务需求,对数据挖掘平台提供的接口进行调用,进一步的获取大数据存储和挖掘能力,实现对应用层系统的构建。这样设计的优点体现在应用系统无需对底层的实现投入过多精力,只需重点研究系统的业务逻辑即可,使系统的复杂性降到最低,节约了开发投入和维护的成本,同时开发者的效率也得到了显著提升。
其次是服务中间层,该层的作用是承上启下,是基础能力支持层与业务应用层之间的连接桥梁,简单来说,服务中间层的实现是通过封装系统的管理功能和基础服务支持层的能力,通过Restful方式,把服务接口提供给用户使用。从功能上来说,服务中间层包括数据挖掘算法、数据文件管理、用户管理以及权限管理四个模块。
最后是基础能力支持层,在整个系统架构中,基础能力支持层处在最底层,其能力是最基本的大数据处理和存储能力。严格来说,对海量数据的处理和存储使用并不局限在分布式技术上,对于业务应用层的应用而言,基础能力支持层的实现是透明公开的。
1.2 系统平台的功能设计
在通用数据挖掘平台中,目前多设计为数据挖掘、处理和可视化三个功能模块,图2给出了具体的功能模块示意图。
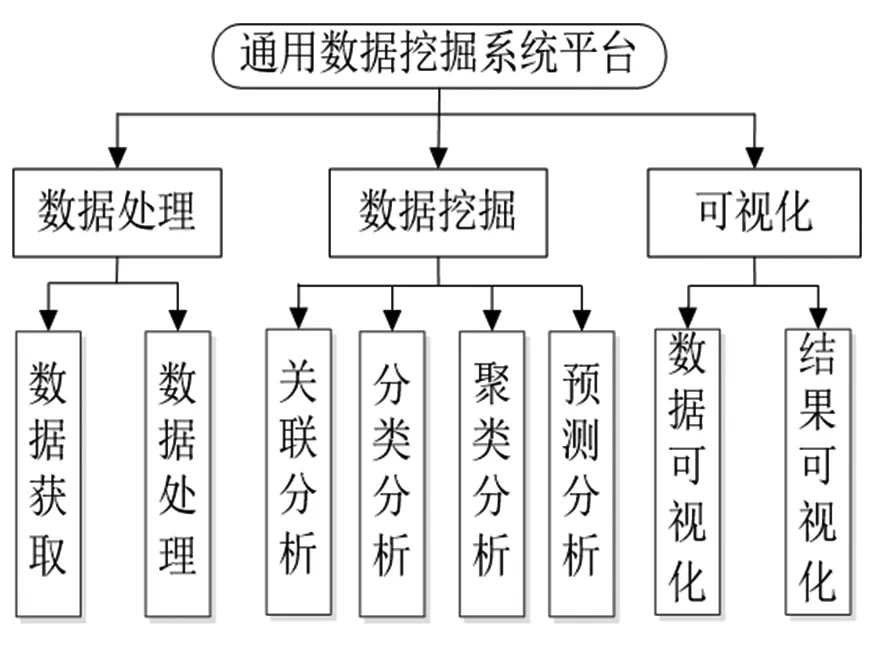
图2 平台功能模块图
图3给出了三个模块之间的关系示意图,三个模块之间通过相互联系、相互制约,形成了一个有机整体。

图3 系统平台功能模块关系图
1.3 平台主要模块设计
首先是数据处理模块,该模块共包含两个子模块,分别负责数据的提取和预处理。数据提取子模块的功能是在数据库服务器中,把外部数据源的数据集成到指定的数据表中。数据预处理子模块的功能是对数据库服务器集成的外部数据源数据进行通用处理,如处理噪声和缺失值等。数据经过处理之后提供给数据挖掘模块使用。
数据挖掘模块是对各类数据挖掘算法的集成,共包含四个子模块,分别为分类分析、聚类分析、预测分析以及关联分析。数据挖掘使用的是数据提取和预处理子模块处理完成的数据。本文研究的重点就是数据挖掘模块,下文会更加详细的介绍该模块。
可视化模块共包含两个子模块,分别为挖掘结果可视化和原始数据可视化。其中原始数据可视化主要是展示在数据库中集成的数据,便于用户对数据特征的了解,使其在对数据挖掘算法进行选择时更具针对性。比如,当我们从散点图上看到呈线性分布的数据时,在建模分析时就可以采用线性回归分析方法[3]。挖掘结果可视化主要是展示具体的数据挖掘结果,便于用户对数据挖掘结果的理解和查看。在结果可视化的设计中,针对数据挖掘算法的不同,可以有针对性的对可视化功能进行设计。
2 平台中的分类技术
在数据挖掘的研究中,分类技术一直是其中的研究热点和重点,并广泛应用在多个领域[4]。在训练数据中,我们把y=f(x1,x2,…,xd)确定为函数模型,其中,分类变量为yi,特征变量为xi,i=1,2,…,d。当分类变量为离散变量时被称为分类,也即是dom(y)={y1,y2,…,yn},目前主要有两种分类观点。
首先是在决策边界基础上的分类,在空间中,yk类的决策区域是指所有存在yk的区域,当在yk类的决策区域内落有一个数据点时,该数据点就相应的属于yk类。采用这种分类观点的代表是决策树分类。
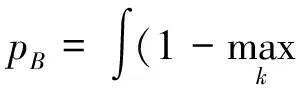
一般而言,分类操作包括以下步骤[5]:首先,基于给定的训练集对合适的映射函数进行挑选,也可称为模型训练阶段;其次,通过训练完成的函数模型对大数据的具体类别进行预测,或者通过函数模型的使用,描述数据集中每一类别的数据,生成相应的分类规则。图4给出了具体的分类应用流程示意图。
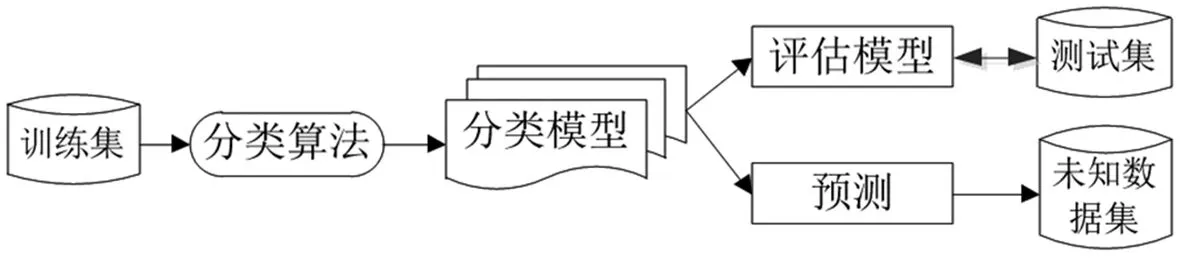
图4 分类的应用程序
3 平台中的聚类算法
在聚类算法中,基于划分的经典算法是K-means算法,其参数为k,对象共有n个,对象划分的k个簇内相似度较高,但是簇间的相似度相对较低[6]。我们用两个对象之间的欧氏距离计算他们的相似度。
K-means算法具有以下流程:从n个对象中随机的对k个对象进行挑选,每个对象默认为该簇的中心。在其余的n-k个对象中,按照簇中心与对象距离的远近进行簇的划分。簇划分完成之后,对每个簇的平均值进行计算,并把计算结果作为簇的新中心。并不断反复以上过程,直至准则函数收敛为止。在计算过程中,该算法使用的准则是平方误差方法,具体的定义为:
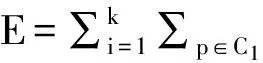
其中,对每一个聚类数据对象求平方误差,对其求和就组成了E,P是给定的数据对象,也可表示为空间点,簇Ci的平均值用mi表示。
K-means算法试图通过k的划分达到平方误差函数值最小的目的。实验结果表明,当簇与簇之间有较明显区别,同时簇是密集的时候,具有较好的应用效果。该算法在大数据的处理过程中,表现出了较高的效率和可伸缩性。
只有在定义了簇的平均值的情况下才能使用K-means算法,对于一些行业来说,这点适用性不强,该算法还有一个缺点就是必须给定一个聚类个数k。K-means算法还不能应用在对大小差异很大以及非凸面形状的簇上。而且K-means面向孤立点和噪声数据的时候敏感性较强,这类数据能极大的影响到数据的平均值,容易导致在出现局部最优解的同时不能实现全局最优解,也即是说在输入同样参数的情况下,不稳定的聚类结果也可能导致出现完全不同的聚类结果。
4 挖掘平台中的关联规则
一些研究者定义了关联规则挖掘问题的概念,这些定义目前也得到了大多数研究者的认可,下面列出了一些具体的定义描述[7]。
事物和项目:把D={T1,T2,…,Tm} Tk={i1,i2,…,in}记为关联规则挖掘的数据集,其中事务就是其中Tk=(k=1,2,…,m),事务数据库为D,项目定义为ip=(p=1,2,…,n)。
项集:D中所有项目的集合设为I=(i1,i2,…,it)是。其中I的子集就是事务Tk包含的项集。按照关联规则分析,一个包含k个项的项集,被称为k-项集。
关联规则:一般用R:X⟹Y表示关联规则,其表达的规律是当出现X中的项目时,Y中的项目也会随之出现。
项集的最小支持度阀值:当项集满足最小支持度阈值时,可以产生关联规则。
关联规则产生的条件是项集必须满足的,最小支持度阀值通常被记作min_sup。支持度大于或等于min_sup的项集称为频繁项集。如果k-项集的支持度大于或等于min_sup,则称其为频繁k-项集,记作Lk。
频繁项集:当项集满足最小支持度阈值时,可以产生关联规则。当最小支持度阈值小于或等于项集时,该项集被称为频繁项集。
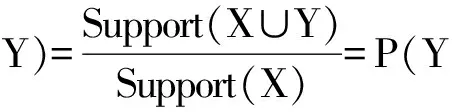

为了更好的对关联规则的置信度和支持度进行阐述,我们给出了一个具体的商品购买实例加以说明和分析。假设在某一个关联规则中,X4为条件项集,Y为结果项集,支持度是对X和Y一起出现的概率进行计算,置信度是对X中含有Y概率的计算。
表1给出了具体的购买记录,表2是与其对应的商品购买二维表。
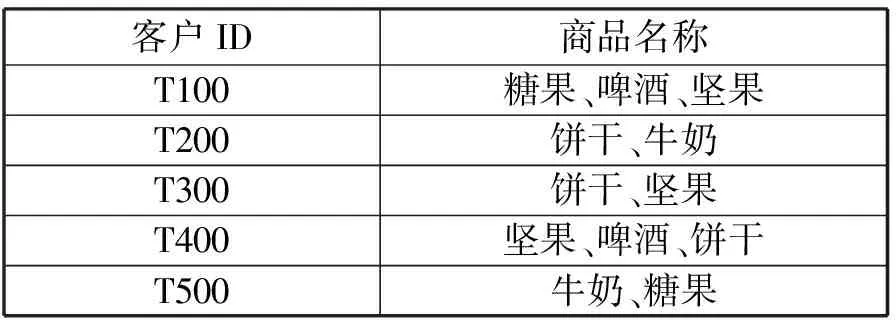
表1 商品举例

表2 商品购买二维表

综上所述,在数据挖掘过程中使用关联规则其实就是在给定的数据库中,找出用户设定关联规则中置信度和支持度的最小值,也被称为强关联规则。
5 结论
本文通过对大数据环境下数据挖掘平台的设计及平台中应用的典型技术和算法的研究,有效缓解了当前海量数据对人们有效信息收索工作的冲击。平台通过先进的挖掘算法和可视化的显示技术,使人们能够更快速、准确、直观的获取所需信息。
[1] 邵峰晶,于忠清,王金龙,等.数据挖掘原理与算法(第二版)[M].北京:科学出版社,2009.
[2]林霞,等.一种数据挖掘系统的设计与实现[J].电脑知识与技术,2010:1293-1295.
[3]王熙照,等.学习特征权值对K-均值聚类算法的优化[J].计算机研究与发展,2003(06):869-873.
[4]Yang Lai,Shi Zhong Zhiusing Java Persistence API,Information Technology,An Efficient Data Mining Framework on Hadoop IEEE International Conference on Computer and2011,156-159.
[5]Wang C, Ren K, Yu S, et al. Achieving usable and privacy-assured similarity search over outsourced cloud data [C]//INFOCOM,2012 Proceedings IEEE.IEEE,2012,451-459.
[6]Xue,G.,Lin,C.,Yang,Q.,etal. Scalable collabor Ativecluster-based smoothing[C].In:Proceedings of the ACM SIGIRpp.114-121.filtering usingConference 2005.
[7]Ruoing Jin. Ge Parallelization of Yang Gagan Mining Agrawal. gorithmsemer. Shared Memory Data Techniques. Programming Interface. And Performance[J].Engineering.2005.17(1).71-89IEEE Transactions on Knowledge and Data.
[责任编辑:张怀涛]
2016-05-26
2014省质量工程“软件工程综合实践教育中心”(项目号:2014SXZX021);2013校级质量工程项目:《新华—达内科技校企合作实践教学基地》(项目编号:2013xqjdx02)
孙马莉(1981-),女,安徽蚌埠人,讲师,研究方向为数据挖掘。
TP311
A
1671-5330(2016)05-0105-04
