一种基于位向量流分类算法的改进
2016-01-27贺亚威侯整风吴亮亮
贺亚威, 侯整风, 吴亮亮
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
一种基于位向量流分类算法的改进
贺亚威,侯整风,吴亮亮
(合肥工业大学 计算机与信息学院,安徽 合肥230009)
摘要:在流分类算法中,聚合位向量(ABV)算法分类速度快、并行性好,但内存开销过大;位向量折叠(AFBV)算法对ABV算法进行了改进,降低了运行时内存的消耗,但其冗余计算增加了时间开销。针对上述不足,文章提出一种改进的位向量流分类算法,该算法无需进行位向量聚合,减少了内存开销,并按规则的源/目的IP地址前缀建立分组表,根据表中分组所包含IP地址数目降序排列,使得算法具有良好的时间性能。实验结果表明,本算法在大规模规则库下具有良好的时间和空间效率。
关键词:流分类;聚合位向量(ABV)算法;位向量折叠(AFBV)算法;位向量
流分类技术将数据包按照指定的访问控制规则分类成特定的数据流,广泛应用于流量计费[1]、防火墙包过滤[2]、区分服务[3]、虚拟专用网[4]等。典型的流分类算法包括BV算法、ABV算法、TCAM算法[5]、RFC算法[6-7]等。目前,流分类研究主要集中在多维、大规模规则库下如何提高流分类的时空效率。
文献[8] 提出的BV(bit vector)算法主要解决多维匹配问题,但随着规则数的增加,BV算法的时间性能和空间性能会随之降低;文献[9]在BV算法的基础上,提出了聚合位向量(aggregated bit vector, ABV)算法,通过位图聚合的方式,改善了BV算法在平均情况下的执行时间,但算法运行时的内存消耗依然很大;文献[10]在ABV算法的基础上提出位向量折叠(AFBV)算法,减少了算法的空间开支,但算法的冗余计算降低了时间效率;文献[11]在位向量折叠思想的基础上,提出了元组向量折叠流分类算法,该算法在空间存储和内存读取上都有很大进步,但时间效率依然不理想。
针对ABV和AFBV算法存在的问题,本文提出了一种改进的位向量流分类算法,该算法将规则集按源/目的IP地址的前缀建立前缀分组表,并按分组所包含IP地址数目进行降序排列;再对源/目的端口号字段进行值域划分,建立位向量图;根据数据包包头中所对应字段的值,在前缀分组表和位向量图中分别进行匹配,并将2个匹配结果取交集,得到最终分类结果。相比于ABV和AFBV算法,该算法在大规模规则库下具有良好的时间和空间性能,且能较好地支持规则集的动态更新。
1ABV算法
1.1 ABV算法描述
ABV算法对BV算法进行了改进,属于多维分类方式,通过源IP地址、目的IP地址、源端口、目的端口、协议类型5维字段来构建分类规则库。ABV算法将规则中的每个字段分别与数据包头中的相应字段进行匹配,从而得到分类结果。
二元规则库示例见表1所列。

表1 二元规则库示例
ABV算法对每个字段建立初始位向量图(以下简称位图),位图的长度和规则的个数是相同的,位图的第n位对应规则库的第n条规则,根据预先划分的区间,当该区间的取值与规则有重叠时,则该规则对应位的取值为1,否则为0。对表1的规则,源端口的值域为0~65535,如果将其划分为0~80、81~1023、1024~65535这3个区间,则属于0~80区间的位图为000101,R4、R6均在0~80区间中,所以它们对应位置的值为1。位图长度和规则数相同,都是6。
然后,ABV算法对初始位图进行聚合,其过程如下:将初始位图按照聚合因子a进行聚合操作,得到聚合位图,聚合因子将初始位图中a个比特位聚合为聚合位图中的1位;如果a位中的位向量至少有1位为1,则聚合之后的结果为1,若全为0,则聚合之后的结果为0。
分类时,先运算聚合位图,找到聚合位图中位置为1的点,再对初始位图所对应的位置进行定点查找,有效地提高了算法的时间性能。
例如,表1的源端口字段中,端口号在0~80区间的初始位图为“000101”,此时若取聚合因子a=3,由于前3位位图中均为0,后3位中存在“1”,那么该初始位图聚合之后的结果则为“01”,比之前长度减小了4位,使得匹配时位图的长度大幅缩短,减少了算法的访存次数。
通过位图聚合的方式,ABV算法减少了读取位图的位数,从而减少了访存次数,提高了算法的时间效率。
1.2 ABV算法的缺点
ABV算法采用聚合位图的方式,提高了算法的时间性能,但在运行过程中,ABV算法不仅要存储初始位图,还需要存储聚合位图,当规则库较多时,聚合位图的层次也会增加,导致存储空间的开销巨大。
设规则库规则数为N,字段的值域区间个数为C,聚合因子为a,聚合位图的层次为m,规则字段个数为k,那么初始位图所占用的空间为kCN;而ABV算法所占用空间为k(CN+CN/a+CN/2a+…+CN/ma)[12]。随着规则数增加,聚合位图的层次m随之增加,ABV算法所占用的空间急剧增大。
2AFBV算法
与ABV算法的聚合思想不同,AFBV对于位向量的处理不是聚合,而是将初始位向量折叠成一个较短的折叠位向量。设折叠位向量长度为f,如果折叠位向量第k位为1,可以计算出初始向量中可能为1的比特位的位置是(if+k)。假设初始位向量有4 096位,折叠长度f为128,则折叠位向量只有128位,存储空间大幅减少了。
AFBV算法使用位向量折叠思想,降低了空间开销。但是在实际应用中,数据包都是多维的,对每一维的位向量都进行多次的折叠和还原需要消耗大量的时间,特别当规则库较大时,位向量折叠方式对算法的时间效率影响尤为明显。
3改进的位向量流分类算法
ABV算法的空间开销大,AFBV算法的时间效率低,针对上述问题,本文提出一种改进的位向量流分类算法,该算法通过构建前缀分组表,无需进行位向量聚合,减少了算法的空间开销,并将前缀分组表按分组所包含IP地址数目降序排列,使得算法具有良好的时间性能。
算法按源/目的IP地址前缀,将所有规则划分成若干个前缀分组,即每个前缀分组所对应规则的源/目的IP地址前缀是相同的,并按前缀分组所包含的IP地址数目大小降序排列,以提高匹配效率;再对源/目的端口号字段进行值域划分,建立位向量图。当数据包到达时,根据其包头中所对应字段的值,分别在前缀分组表和位向量图中匹配,并取2个匹配结果的交集,再根据数据包协议字段的内容与交集中的规则进行匹配,得到最终分类结果。
3.1 算法描述
算法分为如下2个阶段:
(1) 预处理阶段。建立前缀分组表和位向量图,并对前缀分组表进行降序排列。
(2) 数据包分类阶段。当数据包到达时,根据预处理阶段建立的前缀分组和位向量图,对数据包进行分类。
3.1.1预处理过程
(1) 将规则集中,所有规则按照源/目的IP地址映射到前缀分组表中,表中属于同一个分组的规则具有相同的源/目的IP地址前缀;然后,将前缀分组表存储在一个结构体中,并记录分组的前缀和数目。
(2) 对前缀分组表中的分组,按其源/目的IP地址数目的大小降序排列,使得数据包能更快找到与其相匹配的前缀分组,提高算法分类效率。
(3) 端口号的值域为0~65535,鉴于23、80和1024端口号的特殊性,本算法将端口号的值域区间划分为0~22、23、24~79、80、81~1023、1024~65535这6个区间,以便更快地完成匹配。
(4) 根据上述区间划分,建立与规则库相对应的位向量图。
3.1.2分类过程
设数据包为P(p1,p2,p3,p4,p5),p1~p5字段的顺序为:源地址、目的地址、源端口、目的端口、协议。分类过程如下:
(1) 在前缀分组表中查找与p1、p2相匹配的分组,将这些分组对应的规则保存在集合S1中。
(2) 根据p3、p4所属值域区间,查找并取出其值域区间所对应的位向量图。将p3、p4所属值域区间对应的位向量图进行逻辑与操作,将操作结果中为1的位所对应的规则保存在集合S2中。
(3) 对S1和S2规则集进行交集运算,并将结果保存在集合S3中。
(4) 将S3中所有规则的协议字段和P中的协议字段S5进行匹配,得到P的最终分类结果。
3.2 算法示例
规则表见表2所列。

表2 规则表
由表2中的规则,建立源/目的地址前缀分组表,并按分组前缀所包含IP地址数目降序排列,见表3所列。

表3 源/目的地址前缀分组表
表3的分组中,源/目的地址数目较大的排在前面,以便分类时能更快地找到与数据包所匹配的前缀分组,提高算法的分类效率。
类似于ABV算法,本算法按源/目的端口号的值域划分,建立与表2所列规则库对应的位图,如图1所示。
设数据包为P(10100,10110,8080,8080,TCP),分类过程如下:
(1) 在表3中查找符合P的前缀分组,找到符合条件的分组为ed3,所对应规则为R11、R12。
(2)P的源端口号为8080,属于1024~65535区间,在图1a上查找符合P信息的位图为010010001011;P的目的端口也为8080,在图1b上查找符合P信息的位图为111110001111,将2个位图逻辑与,可得位图为010010001011,其所对应的规则有R2、R5、R9、R11、R12。
(3) 取上面2个集合的交集,得到规则R11、R12,然后将R11、R12的协议字段和P进行匹配,得到分类结果为R12。
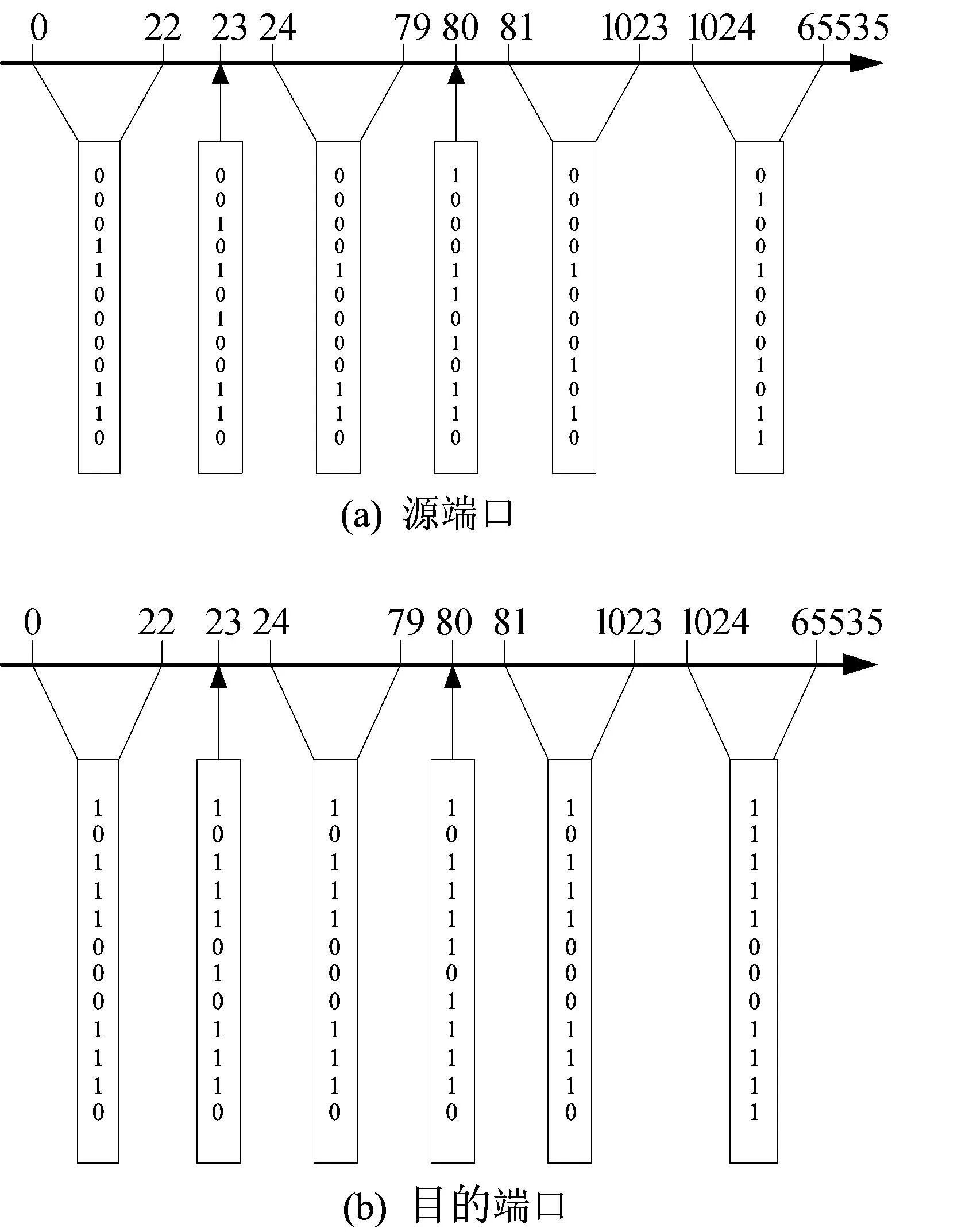
图1 源端口、目的端口值域区间位图
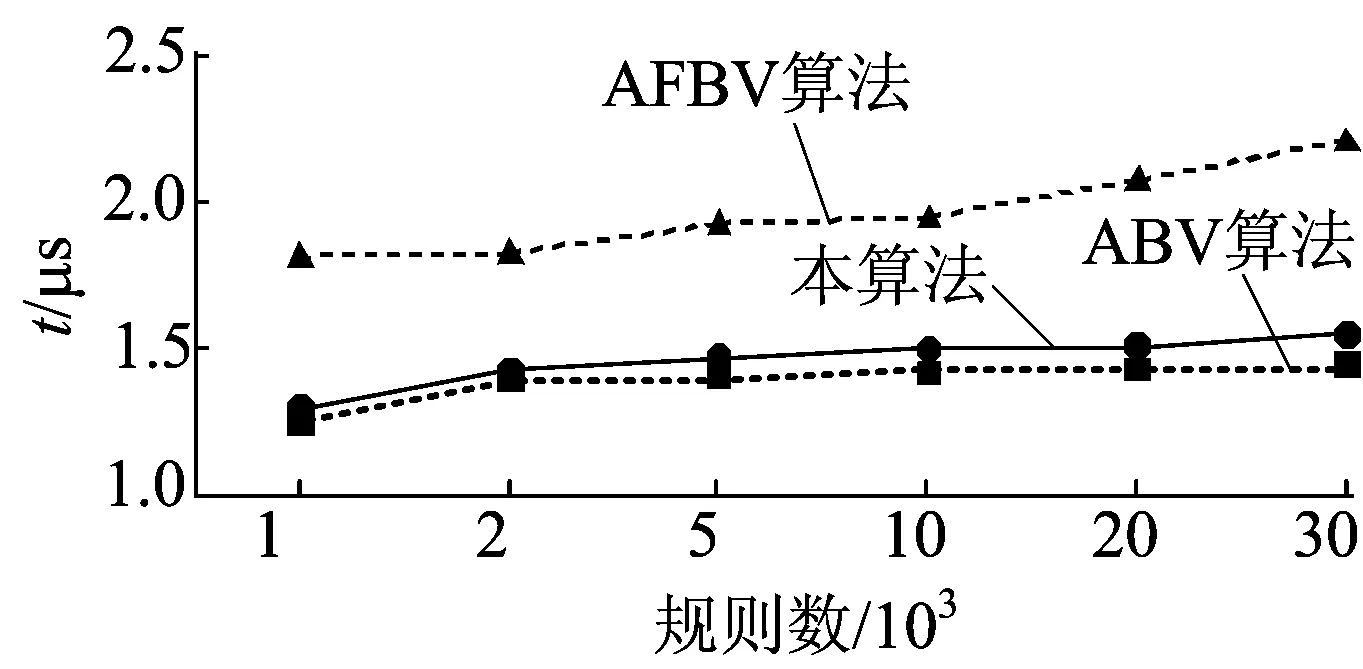
4算法比较
假设规则库规则数为N,规则的维数为k,聚合因子为a,折叠数目为f,聚合层次为m,字段值域区间个数为C。
(1) 空间性能。ABV算法所占空间为k(CN+CN/a+CN/2a+…+CN/ma)[12],因ABV算法需要存储聚类位图,当规则数较多时,需要存储多层聚类位图,所耗空间巨大;AFBV算法所占空间为kf[13];本文算法中前缀分组表所占用空间为N,位向量图所占空间为N (k-1)/2,总共占用空间为N+N (k-1)/2=N(k+1)/2。故本文算法在空间性能上优于ABV算法,与AFBV算法相当。
(2) 时间性能。设聚合位图中1的个数为M,折叠位图中1的个数为L,所以ABV算法需要读取源位图的次数为M,ABV算法的访存次数为k(N/a+Ma)[12];AFBV算法由于折叠之后的冗余计算,所以时间性能较差,分类时的访存次数为kLN[13];本文算法的访存次数为(k-1)N。一般情况下M (3) 规则动态更新。当有新规则加入时,ABV算法需要对原来区间上对应字段的区间聚合位图进行重建,AFBV算法需要重新生成折叠向量图,而本文算法只需将新加入的规则映射到前缀集分组表和源/目的端口号区间位图中即可。 5算法性能测试 本测试是对本文算法、ABV算法以及AFBV算法的分类速度和占用空间进行对比,规则库的规则由程序生成,每条规则由源/目的IP地址、源/目的端口号以及协议类型5元组组成。 测试是在研华FWA-6500多核网络安全平台 (Intel Xeon 5500系列双/四核处理器) 上进行的,操作系统为Ubuntu10.04(系统内核为linux-2.6.32);测试软件为Webserver Stress Tool,该软件可模拟用户浏览网页,通过设置用户的数量与点击网页链接的频率,使得数据流多样化。 测试平台如图2所示,网络安全平台中安装了流分类器,分别采用本文算法、ABV算法和AFBV算法进行测试,客户机上安装了Webserver Stress Tool软件,数据包经过网络安全平台防火墙中流分类器进行分类处理后发送到下面的PC机上。 图2 测试平台示意图 Webserver Stress Tool的用户数量设置为100,即每台客户端同时模拟100个IP用户。在测试中客户端不断地提出网页请求,服务器持续地向客户端发送数据包,数据包经过网络安全平台中的流分类器进行分类处理。 规则库规则数分别取1 000、2 000、5 000、10 000、20 000、30 000条,分别测试本算法、ABV算法、AFBV算法的平均分类时间和空间消耗。 (1) 空间性能。本文算法、ABV算法以及AFBV算法的空间消耗如图3所示。 图3 算法的空间消耗 由图3可知,随着规则数的增加,ABV算法的内存占用量急剧增大,而AFBV算法和本算法涨幅较为缓和;当规则库规模为30 000条时,本文算法消耗仅为ABV算法的1/10左右。本文算法在空间性能上明显优于ABV算法,略好于AFBV算法。 (2)时间性能。本文算法、ABV算法以及AFBV算法的时间性能对比如图4所示。 图4 算法的平均分类时间 由图4可以看出,本文算法在时间性能上与ABV算法相差不大,明显好于AFBV算法。 6结束语 针对ABV算法和AFBV算法存在的问题,本文提出了一种改进的位向量流分类算法。改进的算法无需进行位向量聚合,减少了内存开销,并对前缀分组表按分组的IP地址数目降序排列,提高了其匹配效率。实验结果表明,当规则集中所包含的规则较多时,ABV算法需要占用庞大的内存空间,AFBV算法则时间效率较低,而本算法在各个方面的性能相对均衡,有一定的应用前景。 [参考文献] [1]汤小波,龚俭,孙毅.基于 NetFlow 的网络流量实时计算模型[J].中国教育网络,2008 (Z1):101-104. [2]Morandi O, Risso F, Baldi M, et al. Enabling flexible packet filtering through dynamic code generation[C]//ICC2008.Beijing:IEEE,2008:5849-5856. [3]Chen R R,Khorasani K. A guaranteed cost congestion control strategy for a network of multi-agent systems subject to differentiated services traffic[C]//Proceedings of the 2011 Chinese Control and Decision Conference.Mianyang:IEEE,2011:734-741. [4]Khamket T, Chomsiri T, Sripara P, et al. Designing the network access control using reverse VPN[C]//Proceedings of 2011 1st International Conference on Network and Electronics Engineering.Tokyo:ICNEE,2011. 2011:27-34. [5]Shah D, Gupta P. Fast updating algorithms for TCAM[J]. Micro IEEE,2001,21(1):36-47. [6]Gupta P, McKeown N. Packet classification on multiple fields[J]. ACM SIGCOMM Computer Communication Review, 1999, 29(4): 147-160. [7]孙毅,刘彤,蔡一兵,等.报文分类算法研究[J].计算机应用研究,2007,24(4):5-11. [8]Lakshman T V, Stiliadis D. High-speed policy-based packet forwarding using efficient multi-dimensionalrange matching[J]. ACM SIGCOMM Computer Communication Review,1998, 28(4): 203-214. [9]Baboescu F, Varghese G. Scalable packet classification[J].ACM SIGCOMM Computer Communication Review. ACM, 2001, 31(4): 199-210. [10]Li J, Liu H,Sollingns K.Scalable packet classification using bit vector aggregating and folding,MA02139[R].Cambridge:MIT Laboratory for Computer Science,2003. [11]王学光.位并行多维数据包分类算法研究[J].计算机工程,2007,33(14):46-48. [12]胡茂福,侯整风,韩江洪,等.基于交叉位图的多维流分类算法[J].计算机应用研究,2010,27(8):3060-3063. [13]侯整风,江鹏.对基于元组向量折叠的包分类算法的改进[J].合肥工业大学学报:自然科学版,2009,32(8):1132-1136. (责任编辑胡亚敏) 侯整风(1958-),男,安徽和县人,合肥工业大学教授,硕士生导师. An improved flow classification algorithm based on bit vector HE Ya-wei,HOU Zheng-feng,WU Liang-liang (School of Computer and Information, Hefei University of Technology, Hefei 230009, China) Abstract:In view of flow classification, aggregated bit vector(ABV) algorithm is faster and has good parallelism, but the memory overhead is too large.The aggregated and folded bit vector(AFBV) algorithm improves ABV algorithm with less run-time memory consumption, but its redundant computation increases time overhead. An improved flow classification algorithm based on bit vector is proposed, which does not require bit vector aggregation, reduces memory overhead, establishes prefix grouped table according to the source/destination IP address prefix of rules, and makes the descending order by the number of IP addresses contained in the groups of table, so that the algorithm can have good time performance. The experimental results show that the algorithm has good time and space efficiency for large-scale rule base. Key words:flow classification; aggregated bit vector(ABV) algorithm; aggregated and folded bit vector(AFBV) algorithm; bit vector(BV) 中图分类号:TP393.0 文献标识码:A 文章编号:1003-5060(2015)03-0331-05 doi:10.3969/j.issn.1003-5060.2015.03.009 作者简介:贺亚威(1989-),男,安徽滁州人,合肥工业大学硕士生; 基金项目:安徽省自然科学基金资助项目(11040606M138) 收稿日期:2014-02-18;修回日期:2014-04-105.1 实验环境

5.2 实验结果