基于团块分析的人数统计
2016-01-22李冬梅黄仁杰赵雪专
李 涛,李冬梅,黄仁杰,赵雪专
(1.电子科技大学 计算机科学与工程学院,四川 成都 611731;
2. 河南广播电视大学 信息工程系,河南 郑州 450008;
3. 中国科学院 成都计算机应用研究所,四川 成都 610041)
基于团块分析的人数统计
李涛1,2,李冬梅2,黄仁杰1,赵雪专3
(1.电子科技大学 计算机科学与工程学院,四川 成都611731;
2. 河南广播电视大学 信息工程系,河南 郑州450008;
3. 中国科学院 成都计算机应用研究所,四川 成都610041)
摘要:为了提高视频监控领域人数统计的准确性,提出一种基于团块分析的人数统计方法.首先通过光流算法获取前景团块的方向及能量强度信息,并结合团块大小等相关信息形成团块特征;然后针对人数统计提出一种新的目标跟踪算法;最后基于SVM对该团块特征进行训练分析,得到人数估计模型.实验结果表明,该方法正确率达到95%以上,能准确实现人数统计.
关键词:光流算法;人数统计;目标跟踪;支持向量机
Received date:2014-10-03
Foundation item:Supported by the Key Scientific and Technological Project of Henan Province (142102210010), the Key Research Project in Science and Technology of the Education Department of Henan Province (14A520028, 14A520052), the Ph.D. Programs Foundation of the Ministry of Education of China (YBXSZC20131031)
Author’s brief:LI Tao(1979-), male, born in Linying of Henan Province, doctor degree candidate of University of Electronic Science and Technology of China, lecturer of Henan Radio & Television University.
0Introduction
With the popularization and development of the computer hardware and monitoring equipment, monitoring and analysis based on video are widely used. People counting based on video is an important application in this field. It is widely applied in a public place, and it plays an important role in the public safety, overflow arrangement, resource allocation, transport disposition, market decisions and so on.
In practical application, the accuracy of people counting is affected by the uncertain factors under unconstrained condition (such as deformation, illumination) and the occlusions between moving human bodies in complex scenes. Vertical camera is used to reduce the disturbance of occlusion in the people counting[1]. In recent years, many approaches are proposed based on video-based techniques in order to solve these problems.
These approaches[2-5]with machine learning based on feature extraction or pixel extraction are proposed. For example, the head profile, color and textural features are proposed to counting people in the video sequences[4-5]. The accuracy of these methods will drop significantly in complex scenes because of too many people with occlusions between each other.
These methods[6-8]utilize the foreground segmentation by Gaussian Mixture Model or Frame Difference to count people. Some of methods can not count the people number accurately in complex scenes, because using semicircular or circular model in the basis of the foreground segmentation can not describe the head profile completely[7-8].
Other methods[9-10]analyze the moving features and distribution of directions according to motion vectors of people in videos to count people. However, the error of the counting result is great in complex scene in which there are many people keeping out each other to mass.
This paper proposes a novel method of people counting that can well solve the problem about the occlusion of people in complex scenes. First, the sizes of moving foreground masses and the histograms of the directions about optical flow of masses by quantizing are obtained to form the feature of mass. Then, the novel method of objects tracking is designed specially to aim at people counting. In the end, by training a support vector machine (SVM) classifier with the input of the feature of mass, the people counting model is obtained. Our main contribution is proposing a novel feature of mass which can characterize the intrinsic energy and size properties accurately and the novel method of objects tracking is also very efficient.
The rest of this paper is organized as follows: How to realize the method of people counting based on the analysis of the mass is introduced in Section 1. Section 2 discusses experimental results of the proposed method. The conclusion is given in Section 3.
1Overview of our method
Fig.1 is the flow chart of our method. The framework of the method is shown in Fig.1. It consists of training section, detecting section. The training section consists of four parts: 1) get the foreground moving mass in the video of cameras by using Gaussian Mixture Model; 2) calculate the direction of the mass using the optical flow method at first, and then segment the people of different directions in the same mass according to the direction information, and complete the mass segmentation; 3) track the segmented mass, and get mass characteristic information related to the number of people (such as the length and width of the mass, the optical flow intensity histogram, the number of the mass pixels), track and select using the inter-frame coverage calculated according to the mass until out of the monitoring area; 4) train the SVM classifier using the obtained mass information, and get the people counting model in mass finally.
The first three steps of the training section and detecting section are consistent, and then we put the mass characteristic information into the trained SVM classifier for people counting.
1.1Get foreground mass region
First of all, Gaussian Mixture Model is used for getting the moving foreground mass.
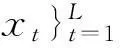
(1)
(2)
1.2The extraction of optical flow information in the mass
According to the mass area of current frame and the mass at the same position of the previous frame, we get the optical flow vector of the current pixel of mass as (u,v), whereuandvrepresent horizontal velocity and vertical velocity respectively in the process of the pixel moving from previous frame to current frame. The process is as follows:
Firstly, we established objective function according to the assumption of the consistency of the gray level and gradient, and then we got the optical flow vector by calculating the minimum of the objective function. The objective function is
(3)
(4)
where Kρis a Gaussian with standard deviationρ, * denotes convolution. We calculated the minimum of Eq.3 (one of w can make the objective function E(u,v) achieve the minimum), the optical flow vector is the corresponding(u,v) when the objective function is minimal. Eq.3 is calculated by Lagrange method as
(5)
Eq.5 is a nonlinear equation, we transfer it to linear equations in order to get a solution. Let us denote byJn mithe component (n,m) of the structure tensor Jρ(3f) in some pixeli. Then a finite difference approximation to the Eq.5 is given by
(6)
We got the unknown quantity (ui,vi) using iteration solution of the Gauss-Seidel method. And we solve the unknown quantity using the Gauss-Seidel iterative method based on grid method[11]for fast convergence. Thekiteration result is shown as Eq.7.
We considered each point in the two-dimensional image as a point on the grid, and then we halved the grid number and increased the grid size into twice in the process of fine-to-coarse. We used the Gauss-Seidel iterative method on the coarse grid to calculate the unknown variable, and then switched to calculate on the fine grid after obtaining the exact value. In the iterative process of the grid method, the conversion of the fine grid into coarse grid used averaging over 2×2 pixels (restriction operator), and the conversion of coarse grid into fine grid used prolongation operator (interpolation method). In the program, we integrate the “V” multi-grid method with nonlinear multi-grid to get the fastest convergence speed without any cost of calculation. If thekdenotes the iteration step, the Gauss-Seidel interactive method can be written as
(7)
where,his the size of the grid,N(i) denotes the number of neighbors of pixelithat belong to the image domain.Mis the size of the coarse grid. In order to simplify the programming,Mis equal to 2h.
Considering each pixel point in moving mass area at the current frame image as a point on the grid, we get the optical flow vector of each pixel in the moving mass area by the iterate conversion of coarse grid into fine grid. Fig.3 is the figure of optical flow vectors in the mass foreground. Optical flow mass vector diagram is shown in Fig.3.
1.3Method of tracking mass
People counting usually get the number by setting a counting line in the monitoring area. Method of mass tracking which is different from the conventional tracking method is designed. Fig.4 is the contrast of the mass tracking method in this paper and the conventional tracking method. As shown in Fig.4, the dotted track line denotes the tracking trajectory before segmentation, the solid track denotes the whole tracking trajectory before and after segmentation, and the pecked track tine shows the difference between the tracking trajectories in this paper.
In traditional tracking object methods, there are two tracking targets respectively when the mass is segmented. One of the new target paths after segmentation started from the segmentation position. However, the start positions of the two targets after the segmentation are consistent in our tracking object method, and they are both the recorded position before segmentation. The advantage is that the two masses all followed the original tracking trajectory, so there are at least two masses in the mass if there is mass separation when across the counting line. In the tracking process, if there is mass merge, such as mass 1, mass 2 and mass 3, we will choose the one which has the longest tracking range (assuming mass 2), and then put mass 1 and mass 3 into the tracking linked list of which has the longest tracking range (mass 2).
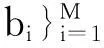
(8)
OR≥αor(αordenotes the threshold of the overlap, and the overlap rate is effective only when it is greater than this), we take the mass which has the largest overlap rate as the target.
1.4Analysis of mass by using SVM
As a supervised learning method, SVM (support vector machines)[12]is widely applied in many fields. It can not only enable to learn in high dimensional spaces, but also obtain high performance with limited training samples. It also can avoid the structure selection and local minimum point problem of the neural network. Therefore, we use the linear SVM to analysis the feature of the mass, and then get the number of people in mass.
We extract the feature of each mass as the input vector. The variableli denotes the width of the mass andhi denotes the height of the mass. The variableni denotes the number of the mass pixel andHi denotes the mass flow histogram with an eight dimensional vector (The value of the pixel optical flow intensity is normalized to [0,1], and divided into eight bins. Then we record the value of optical flow intensity of each pixel in the mass, and form an eight dimensional data). As a training sample, each mass correspond with a eleven dimension feature vectorsi is given by
(9)
where, the three variables (hi,li,ni) have been serious affected by the distance from the camera to objects. The variable α denotes the weight of liand hiof the mass and niof the mass, and is directly proportional to the distance from the camera to objects.
The relation of corresponding features (hi,li,ni) and the distance from the camera is described by the ratio of the foreground mass size of a single pedestrian in different locations and the largest foreground mass of the pedestrian in the fixed scene. The weight α is obtained as follows:
(1) The Ajdenotes the foreground size of a single pedestrian for thejareas (1≤j≤n,n denotes the number of areas in the scene) in the fixed scene, and the maximum foreground mass size of a single pedestrianAis equal to max{Aj}.
(2) The weightαin different areas can be represented as follows
(10)
(3) The feature vectorsi in training is finally represented as:
(11)
In our method, we utilize SVM to fit the feature vector si(si∈Rd,d=11) and the number of people in the mass yi(yi∈R).
First of all, linear regression function f(x)=w*s+b is considered to solve the problem of fitting data {xi,yi}, i=1,…,n,and all training data is assumed to use linear function fitting under the precisionεwithout error, that is given by
(12)
(13)
The optimization goal becomes the minimization of the term as follows
(14)

(15)
We get the regression function
(16)
At last, the result of counting people is obtained through the functionf(x).
2Experimental results
In this section, we verify the validity and availability of the people counting method in this paper. The proposed framework is evaluated on one public datasets Crowd-PETS09[13], and the other videos are collected from the internet and our shooting. The experiments are performed inCon a 2.3 GHz Pentium with a 2 G memory. We realize this program using VC and OPENCV programming for the test of many different type videos including scenes with occlusion (including the same and different directions). The frame rate is 33 fps·s-1, and the resolution is 720*576 in the set of videos.
2.1Discussion of feature selection
In this section, the experimental result shows the influence about the feature of the mass as the SVM input to the result of people counting.
As shown in Fig.5, the videos are obtained according to the different views of camera. The first line of a figure in Fig.5 records the mass and optical flow distribution in the same and different directions. Similarly, the second line a figure or b figure records the mass and optical flow distribution in the same direction from the different views of camera.
When the moving directions are different, the people of different directions are in the same large mass as shown in the first line of a figure, which is a binary image. As shown in the first line (left) the optical flow in a figure is used to get internal movement direction in the mass, the mass segmentation is completed through the direction difference, and the large mass is segmented into two masses. The second line of a figure and all of b figure show the condition of the same direction, and the mass do not need to be segmented in this condition. Because there are two conditions in same direction: 1) many people with long distance, there are many masses; 2) many people with closer distance, although it is a mass in this condition, but we can put the mass characteristic information into the trained people counting model based on SVM in this paper directly, so we can still get an accurate number of people. As shown in Fig.5, there is direct relation with the mass area and the distances between the foreground mass and the camera. In general, the large foreground mass contains more people than the little one in the same distance. The change in the size of the mass is relation with the distance of the foreground mass and the camera is shown in a figure and b figure. We also can see in Fig.5 that the strength of the optical flow information from different distances also directly reflects the number of people, because the speed of people is similar in the scenes in the same distance. The energy of optical flow about mass can reflect the people number in mass indirectly.
2.2The evaluation of experiments
The experiment analyzes the confusion matrix[14]to evaluate the method performance. TP is the correct number of the system. FN represents the number that is not counted and FP represents the number that is wrong counting. The confusion matrix is used to estimate the precision and recalled as follows
(17)
(18)
The measureFwhich called the weight harmonic mean is a way to combine PR and RE for obtaining a general quality measure
F=2PR·RE/(PR+RE).
(19)
Fig.5 is the influence of the optical flow distribution to the segmentation. In experiment, our method and a classic people counting method[10]are tested with multiple videos, some of which are presented in Fig.5. Tab.1 is the result of people counting (the result of our method/the result of the paper [10]). As shown in Tab.1, the accuracy in 1-4th videos is 100% when the interference is not serious in our method, but the method[10]counts the wrong number of people with optical flow because it neglects the size of mass. In 5-6th videos, the results of experiment dropped by using our method and the method[10]because there lies severe disruption in scenes (such as people keep walking around, the mass overlap each other is too much, and the illuminance and the shadow are stronger). These factors cause some error in optional flow foreground extraction and interference with the mass area information which causes the deterioration of method precision.
3Conclusion
The novel method for people counting is proposed in complex scenarios. We integrate the optional flow intensity information of moving people and the size of the mass area to form the feature of mass, and a novel method of tracking object is proposed. We put the feature into the SVM for people counting analysis.
The results show that, the energy and shape information of mass are adequately considered in the method, so the accuracy is close to 100%.The method still has some error detection and leak detection in complex scenarios. In the later study, we will consider joining foreground analysis strategies without shadow to the method for mass information, in order to improve the detection rate.
References:
[1]Antic B, Letic D, Culibrk D, et al. K-means based segmentation for real-time zenithal people counting[C]//International Conference on Image Processing (ICIP),2009:2565-2568.
[2]Chan A B, Liang Z S J, Vasconcelos N. Privacy preserving crowd monitoring: Counting people without people models or tracking[C]//2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,IEEE,2008:1-7.
[3]Rabaud V, Belongie S. Counting crowded moving objects[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,IEEE,2006:705-711.
[4]Zeng C B, Ma H D. Robust thead-shoulder detection by PCA-based multilevel HOG-LBP detector for people counting[C]//20th International Conference on Pattern Recognition, Istanbul, 2010:2069-2072.
[5]Zhang Z, Gunes H, Piccardi M. Head detection for video surveillance based on categorical hair and skin colour models[C]//2009 IEEE International Conference on Image Processing(ICIP),Cairo, 2009:1137-1140.
[6]Kim J W, Choi K S, Park W S, et al. Robust real-time people tracking system for security[J]. IBS Journal, 2002,2(3):184-190.
[7]Jaijing K, Kaewtrakulpong P, Siddhichai S. Object detection and modeling algorithm for automatic visual people counting system[C]//6th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Pattaya, honburi, 2009:1062-1065.
[8]Gardel A, Bravo I, Jimenez P, et al. Real time head detection for embedded vision modules[C]//IEEE International Symposium on Intelligent Signal Processing, IEEE, 2007:1-6.
[9]Cong Y,Gong H F, Zhu S C, et al. Flow mosaicking: real-time pedestrian counting without scene-specific learning[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Miami,USA, 2009:1093-1100.
[10]Benabbas Y, Ihaddadene N, Yahiaoui T,et al. Spatio-temporal optical flow analysis for people counting [C]//7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, USA, 2010:212-217.
[11]Andres B,Joachim W, Christian F, et al. Real-time optic flow computation with variational methods[J].Computer Science,2003,2756:222-229.
[12]Vapnik V. Statistical learning theory[M]. New York:Springer,1995.
[13]Chan A B, Vasconcelos N. Counting people with low-level features and Bayesian regression[J]. Image Processing, IEEE Transactions, 2012,21(4):2160-2177.
[14]Barandiaran J, Murguia B, Fernando B. Real-time people counting using multiple lines[C]//9th International Workshop on Image Analysis for Multimedia Interactive Services, Klagenfurt, Austria,2008:159-162.
(责任编辑郑小虎)
