湘江流域金属污染的贝叶斯预测实证研究
2015-12-31刘潭秋孙湘海
刘潭秋 孙湘海


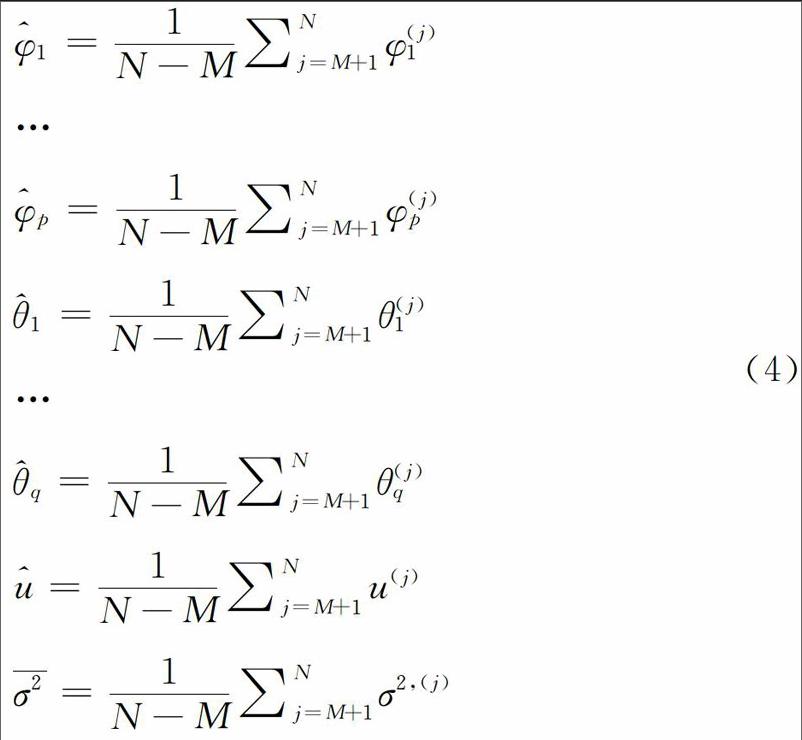
摘要:水环境是一个充满不确定性的复杂巨系统,传统水质模型很难体现重金属污染物在河流中迁移的随机性。本文选择ARIMA模型作为重金属预测模型,运用贝叶斯相关理论进行分析、参数估计和预测,从而不仅获得点预测结果,而且获得区间估计和概率预测结果。实例分析证实,基于贝叶斯方法的ARI-MA模型能够获得很好的点预测和区间表现。
关键词:时间序列模型;贝叶斯理论;河流重金属污染;预测
中图分类号:TP391.9 文献标识码:A
1引言
水环境是一个充满不确定性的复杂巨系统,根据水流流速、污染物的弥散系数、污染物的降解系数与污染物浓度的关系构造的传统水质模型很难体现重金属污染物在河流中迁移的随机性和不确定性。
由Box and Jenkins(1970)提出的自回归整合移动平均(autoregressivintegratedmoving-aver-age,ARIMA)模型作为最典型的时间序列预测技术,已广泛应用于各个领域的时序预测研究,水质管理领域亦不例外。此外,贝叶斯统计学作为处理不确定性的一种恰当方法,自上个世纪九十年代起已广泛被应用于建模。目前,贝叶斯方法广泛被应用于简单集总式概念性水文模型的参数和不确定性估计,但很少有研究应用这些方法去估计其他水文模型不确定性,原因是输入数据和计算时间有限。但是水文研究中,水文建模中的不确定性已经成为一个不可避免的主体。虽然以前只有参数不确定性被关注,但是越来越多的人意识到在建模方法中其它来源不确定性的重要性。
将ARIMA模型与贝叶斯理论相结合,这样既能够充分利用ARIMA模型点预测精度较高的优点,又能运用贝叶斯分析和推断的优势,实现重金属污染的概率预测。概率预测不同于点预测,前者不仅能够给出具体的数值,而且能够给出出现这个数值结果的可能性(概率),以及在给定的可能性(概率)下,预测结果是什么样的数值范围。事实上,自从1969年美国国家气象局开始制作并发布概率降水预测至今,概率水文预测的概念在国外得到了广泛的关注,水文学家对此进行了大量的研究,提出了许多方法与模型,极大地丰富了水文预测不确定性研究的理论与实践,其中贝叶斯预测是一种重要的概率预测方法。
用贝叶斯方法来分析时间序列ARIMA模型,国外己有不少学者做过相关研究,但是将其应用于水质预测,甚或是重金属污染浓度预测,鲜有人涉足。因此,我们将进行尝试性研究,这无疑在理论上和实践上都是一次有益的探索。
2ARIMA模型的贝叶斯推断
2.1ARIMA模型结构
一个ARIMA(p,o,q)模型的一般表达式为:
其中{Xt}是被研究时间序列,u是常数项,φi和θi是待估参数,εi是随机误差项,p和q分别是被研究时间序列和误差项时间序列的滞后阶数且均为正整数。而ARIMA(p,o,q)中“o”表示{Xt}是平稳序列,否则需通过差分处理将其变为平稳序列。
假定被研究变量有T个观察值,记为X=(X1,…,XT)。模型对应的似然函数f(X|ψ)的计算表达式为:
在对模型参数完全未知情况下,可以根据Jeffrey提出的非信息先验分布设定方法,将模型中参数的先验分布都被设置为均匀分布,其中模型方差σ2的非信息先验分布就是f(σ2)∝1/σ2。通常假设模型中各个参数变量是相互独立的,因此这个联合先验密度π(ψ)是各个参数先验密度的乘积,即π(ψ)=π(φ,θ,u,σ2)=π(φ)·π(θ)·π(u)·π(σ2)∝1/∝,其中-∞<φ,θ,u<-∞,0<σ2<∞。
根据贝叶斯定理,待估参数的后验密度为:
π(ψ|X)∝f(X|ψ)·π(ψ) (3)
将每个参数的均匀分布式代入上式,就形成模型参数的联合后验分布。
在具体的推断实施过程中,这里采了用Gelf andan dSmith(1990)提出的Gibbs取样方法,逐一从与各个参数相联系的满条件分布取样。具体步骤为:
6)这样,就获得全部参数的第1次完整抽样,重复上述1)-5)步骤,获得全部参数的第2次完整抽样,然后再多次重复上述1)-5)步骤,直至获得全部参数的第N次完整抽样。这样,就形成这个ARIMA模型参数的样本点序列{φ1(j),…,φp(j),θ1(j),…,θq(j),μ(j),σ2,(j)}jN=1。
在实施上述抽样步骤中,同时监控和检验马尔可夫链的收敛,以确保样本是从平稳分布抽取。目前在实际操作中对于马尔可夫链收敛与否的常用监测方法是样本图形分析法、追踪图法、自相关图法,以及一些正式收敛测试法,例如Geweke测试法,Gelman-Rubin测试法等。
2.2ARIMA模型的贝叶斯估计
在完成上述迭代抽样之后,直接采用如下公式获得模型参数的均值估计值:
其中,N表示迭代总次数,M表示马尔可夫链收敛前的样本点。为了避免初始值对最终估计结果的影响,这前M个样本点必须被抛弃,而这些被抛弃的抽样迭代部分被称作燃烧阶段。此外,为了保证模型参数贝叶斯估计的准确性,N-M必须是一个足够大的正整数值,以确保该马尔可夫链收敛。
ARIMA模型的贝叶斯估计,不仅能够通过4)式获得模型参数的均值估计值,而且能够获得参数其他统计特征值,例如百分位数、标准差等。
2.3ARIMA模型的贝叶斯预测
在贝叶斯方法中,预测是基于所研究变量未来值向量XF的一个概率分布的构建,并且以过去(被观察到的)值X向量为条件,并考虑这个预测模型参数ψ的后验分布。后验预测密度表达式是:
f(XF|X)=∫f(XF|X,ψ)π(ψ|X)dψ (5)
其中f(XF|X,ψ)是条件预测密度。这个后验预测密度的MCMC解为:
其中,{ψ(i)}Gi=1,是从参数的满条件分布抽样获得,G是马尔可夫链的迭代次数。
这个后验预测密度f(XF|X)能够被解释为来自条件预测分布f(XF|X,ψ)的一次平均,权重值是这些参数的后验概率。贝叶斯预测结果就是预测的可信区间,其反映了所研究现象的不确定性。
3湘江流域重金属污染的贝叶斯预测实证研究
3.1样本数据与ARIMA模型的确定
以湘江中下游某个重金属监测点获得的一组镉污染浓度数据为样本进行实证分析。这组镉浓度数据是2007-2010年期问每个月固定某个时点镉在水中浓度的均值,而不是镉污染浓度随时间变化的均值,共计40个样本数据。这些观测值是等时间间隔连续被记录的,时间间隔单位是月。选择前35个样本数据对神经网络模型进行训练,后5个样本数据则用于与预测结果进行比较,从而验证模型的预测能力。本次研究所使用的数据与笔者前期开展的使用ARIMA模型来预测重金属污染浓度研究所使用的数据相同,这样选择样板数据也是便于将本次研究与之前研究工作进行对比。
根据前期研究可知,ARIMA模型的具体表达式为一个ARIMA(1,0,1)模型:
Xt=u+φ1Xt-1+θ1εt-1+εt (7)
其中,Xt表示第t时刻的镉污染浓度,u是常数项,εt是模型残差项且服从均值为0且方差为常数的学生t分布,φ1和θ1是模型需要被估计的参数,这个模型被记为服从学生t分布的ARIMA(1,0,1)模型,或称为服从学生t分布的ARMA(1,1)模型,建模过程详见文献。
3.2模型的贝叶斯分析
基于上述模型的残差项分布设定,模型的似然函数为:
鉴于本次实证研究对象应用本文所讨论方法的相关研究很少,这里采用Jeffrey提出的非信息先验分布设定方法,在使用传统ARIMA建模方法获得参数估计结果基础上,可将模型的非信息先验分布设定如下:
π(φ)~Uniform(0,1)
π(θ)~Uniform(-1,0) (9)
π(σ2)~Uniform(0,160)
根据贝叶斯定理,给定数据,模型参数的联合后验分布正比于参数联合先验分布密度与似然函数的乘积。按照上述对这个ARIMA(1,0,1)模型参数先验分布的设定,以及显然这些先验分布密度相互独立,因此模型参数的联合后验密度就直接正比于模型的似然函数与每个参数先验密度的乘积,如等式(3)所示。
相应地,参数φ的满条件分布为:
显然,这个满条件分布不服从某个标准的概率统计分布,因此在实施σ2取样时可采用Metropolis-Hastings算法(参见文献)。
3.3贝叶斯估计结果
在对所构建的镉污染浓度预测模型实施完贝叶斯分析后,采用OpenBUGS软件对模型实施贝叶斯估计。在估计过程中,燃烧期长度选择为5000次(即,M=5000),观察自相关图和追踪图可以发现,所有参数的马尔可夫链都很好地收敛了。为了保证估计值的准确性,在燃烧期之后又迭代取样50000次(即,N=50000)所获得的样本点用于(7)式以计算每个参数的马尔可夫积分,即参数均值估计值。具体结果见表10
3.4贝叶斯预测结果
利用已经完成参数估计的ARIMA(1,0,1)模型来进行预测。首先需要计算预测值的后验预测密度,根据等式(5),模型的后验预测密度为
显然直接对上式积分是很困难的,同样需要采用MCMC方法来获得模型的预测结果,即贝叶斯概率预测结果,这样就很容易预测未来湘江流域镉污染浓度变化范围,以及发生可能性,甚至能够预测极端事件发生的概率。其中贝叶斯均值预测值是通过等式(4)计算得到,其中为了保证马尔可夫链的收敛,G取值了一个相当大的值,即50000。具体预测结果如下一系列表。
由表2可知:贝叶斯概率预测结果表明,在百分位5到百分位95之间所对应的90%可信区间内包含了真实值;贝叶斯概率预测的均值预测结果与ARIMA模型采用传统建模方法所获得的点预测结果非常接近真实值,但第二个预测点除外,这也能够从图1直观地感受到。采用常用衡量预测精度的统计量——误差百分比绝对值均值(MAPE)来进行对比,我们发现贝叶斯均值预测和ARIMA模型的传统点预测结果所对应的MAPE值分别为0.0542和0.0813,显然在单个值预测上ARIMA传统预测方法似乎更优。然而,贝叶斯预测的最大优势在于其不断改进的能力,即将实践经验不断融入先验信息从而不断改进贝叶斯预测结果,这是传统ARIMA模型预测所缺乏的。鉴于本研究在应用领域的开创性,因此缺乏相关经验积累,所以本次贝叶斯预测中所使用的先验分布采用非信息先验分布,这是导致这一结果产生的原因。因此,为了进一步改进模型的贝叶斯预测能力,需要在以后的实践工作中不断总结预测结果,不断改进模型参数信息先验分布的设定,使其不断逼近真实统计分布。
4结论
将贝叶斯理论和方法与重金属时间序列预测ARIMA模型相耦合,并对该模型所对应的贝叶斯分析、参数估计和预测理论进行了探讨,并在此基础上实施湘江重金属污染浓度贝叶斯预测。实例预测结果表明,获得了较好的均值预测结果和区间预测,而对于现有预测结果的改进有赖于模型参数先验分布选择,这需要在预测实践基础上不断改进。
