电力网络系统中统计特征任务分层的大数据融合模型
2015-12-30刘鑫张瑜
刘鑫,张瑜
(1.湖南铁道职业技术学院,湖南 株洲 412001;2.中国能源建设集团陕西省电力设计院有限公司,陕西 西安 710054)
电力网络系统中统计特征任务分层的大数据融合模型
刘鑫1,张瑜2
(1.湖南铁道职业技术学院,湖南 株洲 412001;2.中国能源建设集团陕西省电力设计院有限公司,陕西 西安 710054)
对嵌入式电力网络系统中的大数据进行融合模型设计提高对频繁任务分层和数据挖掘能力。传统的嵌入式电力网络系统中的大数据融合处理采用非显著特征数据挖掘算法,在嵌入式电力网络系统中的大数据出现离群特征时,数据融合性能不好。提出一种改进的基于嵌入式电力网络系统中统计特征频繁任务分层的大数据融合模型。对嵌入式电力网络系统中数据融合对象数据集提取二维分层空间特征,采用本征匹配方法进行嵌入式电力网络操作系统数据融合总体模型设计,引入统计特征分层融合定位节点谱函数表示数据融合效率,计算样本的密度特征,并抽取高密度区域的点集作为聚类中心,得到嵌入式电力网络系统中闭频繁项域适应度函数,实现融合模型改进。仿真实验表明,采用该算法能有效提高对嵌入式电力网络系统中大数据的分层融合性能,融合密度和精度提高,算法在数据监测概率和任务运行速度上优越于传统算法。
嵌入式电力网络系统;大数据;数据挖掘;融合
在现代信息化社会,数据存在于各个应用研究领域中,表现形式诸如噪声、信号、图像和数字等,对数据的融合,本质就是从海量无规则的信息中提取出有用的潜在的规则的信息,并结合后置分类处理和信号处理,实现对数据的合理有效应用。嵌入式电力网络系统中存在大量的关联规则数据,需要对其进行数据融合和挖掘处理,提高数据的使用和关联特征。大数据嵌入式关联规则融合是数据融合中的一个重要课题,当信息系统中的知识较多时,会得到大量的决策规则,降低了决策的效率,因此,研究大数据嵌入式电力网络系统中的大数据进行融合模型,提高对频繁任务分层和数据挖掘 能力[1]。
目前,国内外学者已提出了很多嵌入式电力网络系统中的大数据融合处理方法,美国Washington大学开发的GLUE[2]、德国Karlsruhe大学开发的FAOM[3]等,具有典型的大数据融合处理性能,采用粗糙集向量数据合并技术进行数据集预处理,实现对冗余数据特征的提取功能,然而,传统的模型设计中,采用不同的元数据规范决定了不同的学习资源本体描述语言,不能解决嵌入式电力网络系统中大数据学习资源本体匹配问题。导致数据挖掘性能不好,针对这些问题,本文提出一种改进的基于嵌入式电力网络系统中统计特征频繁任务分层的大数据融合模型。首先构建了嵌入式任务分析大数据融合模型,在此基础上进行特征匹配和提取,采用统计特征频繁项挖掘方法实现算法改进,仿真实验进行了性能验证,展示了本文算法的优越性能。
1 嵌入式电力网络系统中大数据分层模型构建及问题描述
1.1 系统模型构建及预备知识
嵌入式电力网络操作系统作为一种新型的网络操作系统,在发展过程中产生复合型数据融合问题,大数据嵌入式电力网络系统中的大数据进行融合模型设计提高对频繁任务分层和数据挖掘能力[4]。对数据融合对象数据集提取二维特征空间,采用本征匹配方法进行嵌入式电力网络操作系统数据融合总体模型设计,如图1所示,图中实线流程代表数据状态提取流程,虚线流程代表嵌入式闭频繁项模型状态提取模式流程。
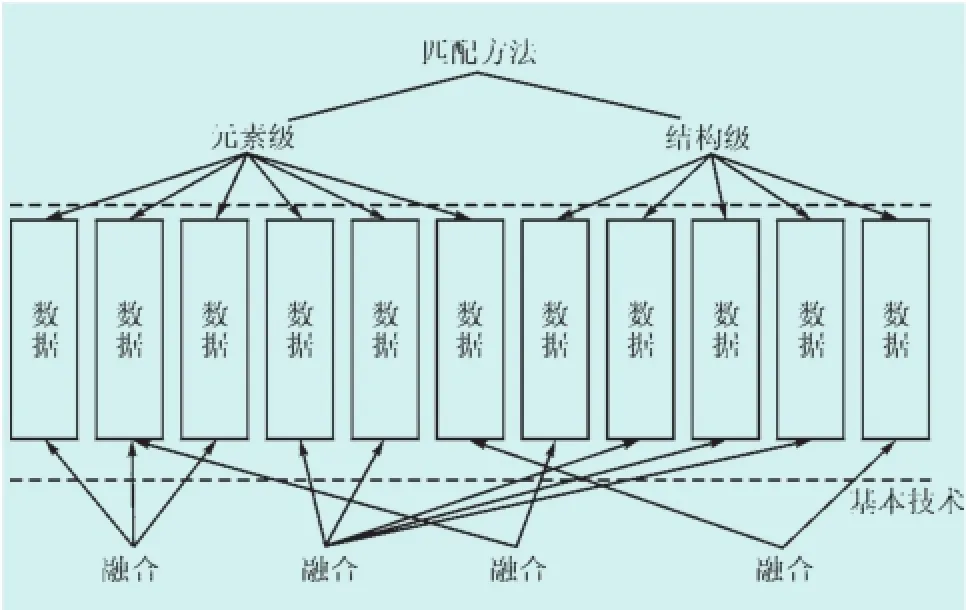
图1 电力网络操作系统数据融合总体模型设计Fig.1 Design of the overall model of power network operating system data fusion
建立了管理系统大数据融合管理多域之间的联系,统计特征分层高阶扩散模糊决策变换的性质则说明了模糊决策域改变引起其在统计特征分层高阶扩散模糊决策变换域的变换[5]。统计特征分层高阶扩散模糊决策相关决策在它们之间表示为:

计算与评价2个模糊决策之间的模糊度,嵌入式分层融合统一的系统模糊决策结果定义为:
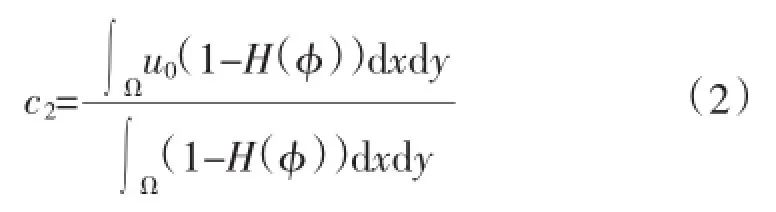
式中:c1为统计特征分层高阶扩散模糊决策模糊化原始输数模糊因子;c2为统计特征分层高阶扩散模糊决策模糊化分析函数决策因子;H(φ)为统计特征分层高阶扩散模糊决策系统决策量,xy为公共模糊域。由此实现了决策数据模型状态提取和总体模型构建,为进行大数据融合提供数据基础。
1.2 嵌入式电力网络系统中统计特征分层融合
在决策数据模型状态提取过程中,将训练样本输入特征数据伴随跟踪状态识别器,产生数据伴随状态序列集,导入数据特征伴随状态验证器进行状态识别验证,最后输出,判断是否作为有用特征。构建嵌入式电力网络系统中统计特征分层融合模型,如图2所示。

图2 嵌入式电力网络系统中统计特征分层融合模型Fig.2 Layered statistical characteristic fusion model in the embedded power network system
根据嵌入式电力网络系统闭频繁项概率正则训练迁移法则,得到嵌入式电力网络系统闭频繁项网络节点最近时刻获得的数据集有效特征概率最大值1,假定xm+1决策属性取值为dm+1=d1,得到扩充的论域U′。则间隔时间越长的能获得有效特征值的概率对当前的影响越小,引入电力网络系统中统计特征分层融合定位节点间距的倒数表示网络效率,即电力网络系统中统计特征分层融合节点i到定位节点j的间距为dij其效率定义如下:

电力网络系统中任意两个统计特征分层融合定位节点的平均距离代表了云计算非线性差分的输出最小适应度函数值,大数据在Javascript程序内部经过变量赋值、传递,字符编码和过滤,实现参数进入函数的过程。向量空间模型中的嵌入式电力网络系统中统计特征分层大数据融合VC和VC′的关系结构可用电力网络系统中统计特征分层融合活性度进行表征为:
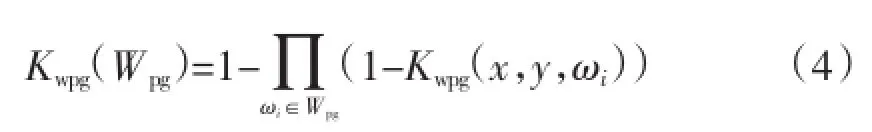
综上所述,向量空间模型中的嵌入式电力网络系统中统计特征分层大数据融合是由C和C′直接相连接的模糊概念以及实例组成,通过线性差分融合,进行电力网络系统中统计特征分层融合,得到任务调度分配链路中的比例分值,有效反映出嵌入式电力网络系统中统计特征分层大数据融合的结构特征。
2 改进的大数据融合模型设计
在上述进行特征分解和分析的基础上,进行大数据融合处理改进设计,传统的嵌入式电力网络系统中的大数据融合处理采用非显著特征数据挖掘算法,在嵌入式电力网络系统中的大数据出现离群特征时,数据融合性能不好。提出一种改进的基于嵌入式电力网络系统中统计特征频繁任务分层的大数据融合模型。
在大数据环境下,嵌入式电力网络系统中任务进程管理处理机pi执行任务nj所能获得的直接回报DR(pi,nj)定义为:

通过非线性差分相点融合估计,实现融合大数据环境下资源负荷的嵌入式电力网络系统中统计特征分层大数据融合策略。在进行时间跨度时,在脚本注入模块中已经提到要插入标签或属性等作为测试脚本,以测试脚本为基础的数据状态方程,实现对时间跨度数据补齐,调用eval()等函数,得到统计特征分层融合的调度函数为:
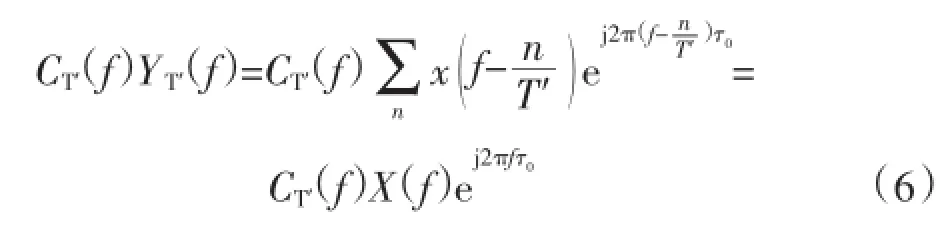
式中:X(f)为带宽受限的嵌入式电力网络系统中统计特征频谱;YT′(f)为采样的数据信息频谱。得到满足HSP的序列经过IFFT之后得到统计大数据融合模型为:
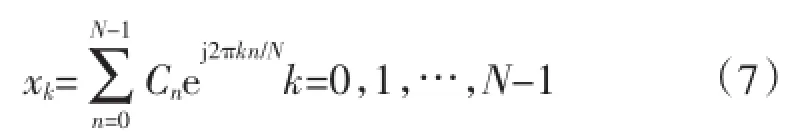
式中:区间[xmin,j,xmax,j]为大数据融合编码过滤时存在逻辑回溯变量区间,实现大数据环境下的统计特征分层融合算法设计。
定义2嵌入式电力网络系统中闭频繁项模型。给定信息系统S=(U,A,V,f),其中,U为非空有限论域,A为对论域中目标进行描述的属性集,设Θ为识别框架,函数m:2Θ→[0,1],当且仅当满足下列条件:

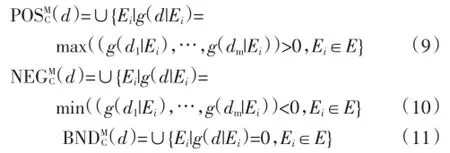
计算样本的密度,并抽取高密度区域的点集作为聚类中心集合S,取其最大值si作为第一个聚类中心z1,通过上述对粗糙集向量数据合并处理技术,数据集中粗糙集向量数据通过关联度伴随跟踪,实现了基于嵌入式电力网络系统中统计特征频繁任务分层的大数据融合模型改进设计。
3 仿真实验与性能验证
为了测试本文算法在实现嵌入式大数据融合中的性能,进行仿真实验。实验基于Hadoop平台,构成JDkl.6,alGbps交换网,设计嵌入式电力网络系统结果,嵌入式电力网络系统共有8个计算节点,包括一个主节点(NameNode)和7个数据节点(DataNode),进行任务分层设计。实验中,用D#T#C#的形式来描述实验数据集,其中D表示事务的长度,即维数,T表示事务的数目,大数据信号采集来哦子3个传感器,分别为c1,c2,c3,c1返回3种信号,即c1值域为Vcl={1,2,3},c2值域为Vc2={1,2,3},c3值域为Vc3={1,2,3},得到各准则下划分D1的正域基于上述参数和仿真实验环境,进行嵌入式电力网络系统中任意大数据融合仿真,提取嵌入式电力网络系统中大数据任务的统计特征,实现数据融合,通过仿真,研究大数据嵌入式电力网络系统中的大数据进行融合模型,提高对频繁任务分层和数据挖掘能力。首先仿真实验得到嵌入式电力网络系统中分层大数据融合前特征分析结果和融合后的结果如图3和图4所示。
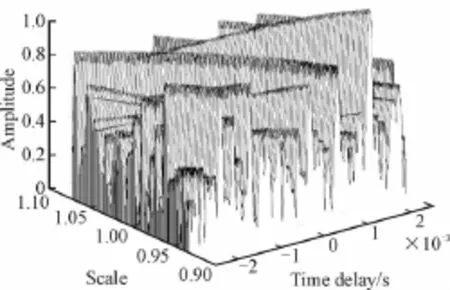
图3 嵌入式电力网络系统中分层大数据融合前特征分析结果Fig.3 The analysis result of characteristics before the layered big data data fusion in the embedded power network system

图4 嵌入式电力网络系统中分层大数据融合后特征分析结果Fig.4 The analysis result of characteristics after the layered big data data fusion in the embedded power network system
分析上述结果可知,采用本文算法,能有效提高对嵌入式大数据的分层融合性能,随着任务规模的指数上升,权重调整的影响越来越小,融合密度提高,为了定量对比算法性能,采用本文算法和经典的显著特征数据融合算法进行对比,以嵌入式电力网络系统中分层数据准确检测概率为测试指标,得到本文算法进行大数据融合处理后的检测概率比传统算法提高39%,而计算机运行时间缩短12%,展示了本文算法在计算精度和速度上有优越性。
4 结论
本文研究嵌入式电力网络系统中的数据融合和准确检测问题,嵌入式电力网络系统中存在大量的关联规则数据,需要对其进行数据融合和挖掘处理,提高数据的使用和关联特征提取性能,大数据嵌入式关联规则融合是数据融合中的一个重要课题,当信息系统中的知识较多时,会得到大量的决策规则,降低了决策的效率,因此,研究大数据嵌入式电力网络系统中的大数据进行融合模型,提高对频繁任务分层和数据挖掘能力。本文提出一种改进的基于嵌入式电力网络系统中统计特征频繁任务分层的大数据融合模型。研究得出,采用本文算法,能有效提高对嵌入式电力网络系统中大数据的分层融合性能,融合密度提高,本文算法在计算精度和速度上优越于传统算法。
[1]王慧娟,胡峰松,陈灿.数据网格环境下副本淘汰策略的研究[J].计算机工程与设计,2012(19):4147-4149,4164. WANG Huijuan,HU Fengsong,CHEN Can.A copy of the data grid environment selection strategy research[J]. Computer Engineering and Design,2012(19):41-47(in Chinese).
[2]匡桂娟,曾国荪.一种基于时分复用的云资源管理方法[J].同济大学学报:自然科学版,2014,42(5):782-789. KUANG Guijuan,ZENG Guosun.A cloud resource management method based on time division multiplexing[J]. Journal of tongji university(natural science edition),2014,42(5):782-789(in Chinese).
[3]曾志,王晋,杜震洪,等.一种云格环境下可计算资源与服务高效调配机制[J].浙江大学学报:理学版,2014,41(3):353-357. ZENG Zhi,WANG Jin,DU Zhenhong,et al.A cloud can compute resources,environment and service efficiently allocate mechanism[J].Journal of zhejiang university:science edition,2014,41(3):353-357(in Chinese).
[4]BALASANGAMESHWARA J,RAJU N.A hybrid policy mrfaulttolerantload balancing in grid computing environments[J].Journal of Network and Computer App-1ications,2012,35(1):412-22.
[5]刘建余,于立娟.短距离室外MIMO-OFDM数字传输系统研究[J].科学技术与工程,2013,13(3):744-748. LIU Jianyu,YU 1ijuan.Short outdoor MIMO-OFDM digital transmission system research[J].Science,technology and engineering,2013,13(3):744-748(in Chinese).
Fusion Model of the Hierarchical Big Data of Characteristics Task in Electric Power Network System
LIU Xin1,ZHANG Yu2
(1.Hunan Railway Professional Technology College,Zhuzhou 412001,Hunan,China;2.China Energy Construction Group of Shaanxi electric Power Design Institute Co.,Ltd,Xi’an 710054,Shaanxi,China)
The fusion model of the bid data of the embedded power network system is designed to enhance frequent tasks 1ayering and data mining ability.Since the dig data fusion processing in the traditional embedded electric power network system adopts non salient feature data mining algorithm,the fusion performance is not good when the big data wanders off. This paper proposes an improved method of the big data fusion model based on statistical characteristics of the 1ayered frequent tasks in the embedded electric power network system.The twodimensional 1ayered space feature is extracted for the objective data set,and the eigen matching is used for the overall model design.The statistical characteristics 1ayered fusion positioning node spectrum efficiency function is introduced to present data fusion ratio and the density characteristics of the sample is calculated and the the point set of high density area is extracted as the clustering center to obtain closed frequent itemset domain fitness function,and realize improvement of the fusion model.The simulation experiments show that the proposed algorithm can effectively improve the big data fusion performance of 1ayered embedded electric power network system,and the integration density and accuracy get improved,and the algorithm is superior to the traditional algorithm in the probability of data monitoring and tasks running speed.
2015-03-21。
刘 鑫(1982),男,硕士,讲师、工程师,主要研究方向为信息系统项目管理,软件工程,大数据分析等。
(编辑 徐花荣)
1674-3814(2015)08-0036-04
TP393
A
KEY W0RDS:Embedded electric power network system;big data;data mining;fusion
