决策技术应用分析与验证
2015-12-24王亿,徐伟
王 亿,徐 伟
(黑龙江职业学院,哈尔滨 150080)
一、模糊决策树技术应用分析
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。构造决策树的过程为:首先寻找初始分裂。决定哪个属性域作为目前最好的分类指标。一般的做法是穷尽所有的属性域,对每个属性域分裂的好坏做出量化,计算出最好的一个分裂。建决策树,就是根据记录字段的不同取值建立树的分支,以及在每个分支子集中重复建立下层结点和分支。
由于现实世界中某些事物的属性是很相近的,如果按照清晰的标准把它们分到不同的类别,可能会造成信息的丢失。例如:当“车载重量”低于100时,认为是“轻”,而高于100低于200时,则认为是“中”,那么当重量是临界值的时候,用模糊的方法更适合。模糊综合评判的过程包括:综合考虑各种属性,建立被评判对象的因素集;建立评判集,即评价的等级和评语;建立单因素评判,即对实际对象的因素集中的属性运用评判集进行评价;根据实际情况,赋予不同因素以不同的权重;根据权重和单因素评判结果得出综合评判的结果。
清晰算法是一种典型的决策树归纳算法,这种算法在假定示例的属性值和分类值是确定的前提下,使用信息熵作为启发式建立一棵清晰的决策树。针对现实世界中存在的不确定性,人们提出了另一种决策树归纳算法,即模糊决策树算法,它是清晰决策树算法的一种推广。这两种算法在实际应用中各有自己的优劣之处,针对一个具体问题的知识获取过程,选取哪一种算法目前还没有一个较明确的依据。
(一)生成决策树的优缺点
清晰决策树(CDT)知识表示可理解性差,没有考虑现实中分类的不确定性,生成树概括能力差,对空间的划分过于细致,不易推广。产生的知识具有一定的偏差,易受噪音影响,易产生过于适合现象。模糊决策树(FDT)知识表示可理解性强,充分考虑现实中分类的不确定性,生成树的概括能力强,对空间划分适中,易于推广。产生的知识表达较为准确,抗噪音能力强,避免产生过于适合现象。
(二)适用范围
CDT适用于符号值属性和分类较清晰、噪音小的中小型数据库。FDT适用于各种情况的数据库,特别是对属性和类模糊性强,有噪音的数据库。对模糊决策树算法的评价决策树对比神经元网络的优点在于可以生成一些规则。当进行一些决策时,还需要相应的理由的时候,使用神经元网络就不行了。
总之,在决策树的算法当中,模糊决策树更符合现实世界,具有更广泛的应用空间。
二、模型准确性评估
(一)解释评估标准
在完成一个挖掘算法之后,常常会获得成百上千的模式或规则。显然这些规则中会有一小部分是有实际应用价值的。那么如何对数据挖掘所获得的挖掘结果进行有效地评估,以便最终能够获得有价值的模式(规则)知识,这就给数据挖掘提出了许多需要解决的问题。
1.使一个模式有价值的因素是什么?评估一个模式(知识)是否有意义通常依据以下四条标准:一是易于用户理解;二是对新数据或测试数据能够确定有效程度;三是具有潜在价值;四是新奇的。一个有价值的模式就是知识。
2.一个数据挖掘算法能否产生所有有价值的模式(知识)?这是指数据挖掘算法的完全性。期望数据挖算法能够产生所有可能模式是不现实的。实际上一个模式搜索方法可以利用有趣性评价标准来帮助缩小模式的搜索范围。因此通常只需要保证挖掘算法的完全性就可以了。
3.一个数据挖掘算法能否只产生有价值的模式?解释评估所挖掘模式的趣味性标准对于有效挖掘出具有应用价值的模式知识是十分重要的。这些标准可以直接帮助指导挖掘算法,获取有实际应用价值的模式知识,以及摒弃无意义的模式。更为重要的是这些模式评估标准将积极指导整个知识发现过程,通过及时清除无前途的搜索路径,提高挖掘的有效性。判断分类的好坏一般可从如下指标进行考虑:预测准确率、速度、创建速度、使用速度、处理噪声和丢失值、伸缩性、对磁盘驻留数据的处理能力、可解释性、对模型的可理解性、规则好坏的评价、决策树的大小和分类规则的简明性。
(二)二分法交叉验证评估的实现方法
其中预测准确度是用得最多的一种比较尺度,特别是对于预测分类任务而言,目前公认的方法是分层交叉验证的损失函数方法。交叉验证是一种模型评估方法。分类是有监督学习,通过学习可以对未知的数据进行预测。在训练过程开始之前,将一部分数据予以保留,在训练之后,利用这部分数据对学习的结果进行验证,这种模型评估方法为交叉验证。两分法是交叉验证最易用的方法,数据集被分为两个独立的子集,称为训练集及测试集,有时也称为正集与反集,二分法交叉验证工作原理如图1所示。
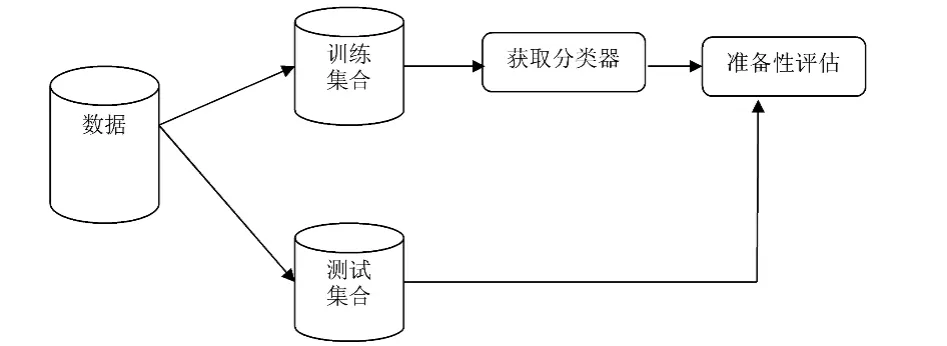
图1 二分法交叉验证工作原理
通过二分法交叉验证,生成验证过后的有意义的决策树数据表,以备知识表示的相对正确性。
以上各步的目的就是利用生成的规则来预测测试集中的未知数据是属于哪一分类,并通过测试结果与实际情况相吻合的准确率来判断该决策树是否有效,如果准确率达到或超过预先确定的阈值,则认为所建立的决策树模型是有效的,能够应用于实际工作,否则该模型的分类效果不好,需要重新选定训练集生成新的决策树,并继续利用准确率来判断该决策树模型的优劣,直到准确率达到预定的阈值为止。本模型准确性评估如图2所示。

图2 模型准确性评估的示意图
在研究的过程中,经过调研及专业分析,确定的准确率阈值为84%,经过对模型测试,其准确率达到了89%,超过预定的准确率阈值,能够满足用户需求。
三、解决问题的方法
1.确定挖掘对象、目标。清晰地定义出挖掘对象,明确目标是数据挖掘的重要一步。明确目标就是定义分析的目的,要弄清所分析的现象并不总是容易的。一般情况下,各个系统的目标是明确的,但是潜在的问题很难转化为分析需要的具体目标。对问题和目标的明确描述是正确建立分析的先决条件,此时确定的目标决定后面的方法如何组织,因此挖掘的对象和目标一定要明确。
2.数据的收集。根据确定的数据分析对象抽象出在数据分析中所需要的特征信息,然后选择合适的信息收集方法,将收集的信息存入到数据库中。
3.数据预处理。对收集的数据进行清理。因为在数据库中的数据一般是不完整的、含噪声的、不一致的,因此在这个阶段中需要对数据库中的数据进行清理,对数据进行检查,保证数据的完整性和数据的一致性,除去噪声,填补丢失的域,删除无效数据等,将完整、正确、一致的数据信息存入到数据库中。
4.数据转换。将选取的数据转换成一个分析模型,建立一个真正适合挖掘算法的分析模型,不同的挖掘算法可能采用不同的分析数据模型。
5.分类挖掘知识和信息。目的是根据系统要实现的功能和任务来确定挖掘的分类模型。选择合适的数据挖掘技术及算法,并使用适当的程序设计语言来实现该算法,在净化和转换过的数据集上进行挖掘,得到有用的分析信息。
6.知识的表示——生成分类规则。将数据挖掘得到的分析信息进行解释和评价,生成分类规则呈现出来。
7.知识的应用。将分析得到的规则应用到日常管理中,管理人员可以利用所得到的知识改进管理方法,调整管理策略,提高管理水平。
