基于数据关联度的迁移策略研究
2015-12-14张陆军聂瑞华王进宏谭黎立
张陆军,聂瑞华* ,王进宏,谭黎立
(1.华南师范大学计算机学院,广州510631;2. 北明软件股份有限公司,广州510633)
如今,互联网上出现许多公有云服务,如Google的GFS 和Google Apps、IBM 的蓝色云、Amazon 的EC2 等,在海量数据到来时,私有云规模小,需将大部分计算任务分配到公有云上,这就需要解决数据迁移问题.目前普遍采用的数据迁移方法有高低水位法[1]、cache 替换迁移算法[2]、分级存储管理的数据迁移技术[3]和以它们为基础的一些改进算法. 以判断磁盘空间是否饱和来决定数据是否迁移的高低水位法,忽略了数据本身的特征属性.Cache 替换迁移算法主要是参考虚拟内存页面置换方法,常用的有FIFO、LRU 和LFU 等算法,FIFO 和LRU[4-5]算法主要考虑时间因子,将近年来最少使用的数据迁出磁盘,但没有考虑数据集大小.LFU 算法主要考虑数据的访问频率,将访问次数最少的数据迁移出磁盘,缺点是没有考虑到多长时间失效,有可能造成长久未失效的数据滞留磁盘. 分级存储管理的数据迁移技术[5],让数据能在不同级别存储设备上实现自动迁移,同时也能很好地降低数据管理成本,主要适用在不同级别设备之间的访问,使用范围受到限制.文献[6]在混合云存储环境下,研究了适合于云存储环境下海洋数据的迁移算法,延伸了算法的使用范围.但是该算法未考虑在寻找迁移数据前,数据之间有一定的关联性,寻找出数据之间的关联性有助于增加数据迁移前的寻找准确性,能更好地找出需要迁移的数据.文献[7-9]提出了基于价值评估模型的数据迁移方法,考虑了数据之间的相关性,但都是基于用户角度出发寻找数据集的潜在用户量. 由此计算数据预计迁移值,忽略了数据集本身之间的关系.本文结合上述的迁移算法的优点和不足性,根据环境中的数据属性,研究了基于数据关联度的迁移策略.
1 相关描述与介绍

图1 电子政务云服务中心总体规划架构图Figure 1 Overall planning architecture diagram of cloud service center of e-government
图1 为电子政务云服务中心的总体规划架构,电子政务云服务中心由广州市科信局主持总体规划设计,广州市电子政务中心组织实施和管理,2 家资格服务商提供物理层、资源层、云服务层的建设,云平台为委局单位电子政务系统提供全面、高效、安全、稳定的服务.
1.1 大数据生命周期
迁移模型主要围绕电子政务云中大数据的生命周期——数据采集、数据存储、数据处理、数据分析和应用等5个阶段展开研究,与大数据处理和管理紧密联系.图2 为本文研究的数据处理技术架构图.数据采集中心从不同的业务系统中采集数据模块,该模块在采集完数据后也实现对数据的初步预处理,如数据清洗、数据去重、数据压缩、数据转换等.经过数据采集中心的预处理后数据存储到大数据存储中心.数据物流中心主要负责海量数据迁移和数据交换. 数据分析挖掘中心是基于Hadoop/Mahout平台搭建的数据分析和数据挖掘环境. 底层的电子政务云平台是一个面向物联网的云基础设施平台,通过虚拟化计算,以动态、分布式和按需的方式提供计算和存储资源,并且统筹优化.本文所研究的是大数据处理物流中心模块中的数据迁移技术. 针对物流中心模块中的数据迁移进行了深入分析.

图2 数据处理技术实现框架Figure 2 Implementation framework of data processing technology
1.2 面向大数据对象的数据迁移因子分析
文献[7-9]提出了基于价值评估模型的数据迁移方法,在计算价值评估模型时候也考虑了数据的静态和动态因素.本文在数据物流中心中,挖掘数据的静态特征和访问的动态特征,并将其作为数据迁移对象的判断标准.
1.2.1 数据的静态因素 指的是数据集数据的大小S 和数据集的用户数量C[9].对于已达PB 量级的存储系统来说,小且热的数据集更适合存储在性能高且容量有限的高性能磁盘阵列中[7]. 一个数据集被访问的用户数量越多,数据集的价值越高,因为如果一个数据集被多个用户访问,那么该数据集影响因子越高,故而可以得到频繁调度计算的大数据集S 与迁移函数成正比关系,与用户量成反比关系.
1.2.2 数据的动态因素 (1)数据时间长度. 在存储系统中,从数据被创建之后数据每次被访问和修改的时间集合为{t1,t2,…,tn}. 设数据当前一次操作时间是t,随着被访问后,数据集被访问的概率随着未使用的时间越长而变低. 数据集每次被访问距离当前时刻的时间长度为t-t1,t-t2,…,t-tn,记上述的时间长度依次为T1,T2,…,Tn,则数据集D的时间由此,计算数据集的访问频率记为:
(2)数据关联度R(d).数据关联定义即若数据X 在任意时刻被访问前后的短时间内(如10 分钟),数据Y 也会被访问,则认为数据X 和数据Y 是相关联的[7].有些数据是注定相关联的,例如如果用户要访问一个数据,必然先访问它的目录数据,但大部分数据间的关联是不明确的. 数据的关联度参数R(d)的计算方法为在每个时间区间T 标记该区间内有无读写操作,进而获得在T 上每个数据集的一个N 维操作标记向量R,若在任意的第i (i =1,2,…,n)个时间段上有读/写操作就将该向量的第i 维标记为1,否则标记为0,因此每一个数据可得到一个操作标记列向量(1,0,…,0)T,所以操作标记向量都是只有1个位为1、其余位全为0 的形式,这是没考虑数据关联度之前的向量表. 在引入数据关联度时可以根据数据之间相互影响的规则构造出操作矩阵A,这个矩阵是一个方阵,因为数据自己会对自己有影响,所以方阵对角线元素全为1.操作列向量Od是实际进行的读写操作,但由于操作之间相互影响,我们只有一个结果,这个结果就称为效果列向量E,效果列向量等于操作矩阵S 与操作列向量的乘积.只有效果列向量才可以对一个状态起作用,对于2个效果列向量,可以进行群运算,群运算符号用⊗表示.所谓群算,就是按位异或E1⊗E2=E1XORE2,对于一个状态S,E1⊗E2(S)表示对状态S 进行E1⊗E2作用,它表示先对状态S 进行E2作用,然后再做群运算.一个数据经过操作矩阵和操作列向量乘积最后得到结果为1,那么这个数据句柄就与数据X 相关联.Ed为效果列向量,效果列向量等于操作矩阵A 与操作列向量Od的乘积,即AOd=Ed,最后得到的Ed所有1 的总和为数据d 的关联度参数R(d).
在混合云存储的迁移算法[6]中,将公有云存储中的数据中心集合记为文中将电子政务云中心作为公有云存储数据中心,则集合Pubc 的存储空间记为+∞;其使用服务的相关部门记为私有云存储中心,其数据中心集合记为其中Prici表示编号为i 的数据中心,cLi表示数据中心Prici的可存储空间.Li为私有云数据中心i 当前已使用的存储空间大小,则私有云数据中心i 的空间饱和度θi=Li/cLi,当数据中心存储空间饱和度θ >σ,则触发系统执行迁移过程,σ 是数据中心饱和度的阈值.
2 迁移策略模型
文献[6]研究了在混合云存储环境下,适合于云存储环境下海洋数据的迁移算法. 该算法在设计迁移函数时,并未考虑数据关联性这一重要因素.结合迁移因子的研究分析得知,在计算数据迁移函数的时候应该考虑数据集的数据关联度,用于计算预计迁移值的迁移函数和数据存储的时间长度T 和数据的访问频率F 都成正比关系.同时迁移函数同数据集的大小S 和数据集的关联度R(d)也为正比关系,将迁移函数记为M(d),综合考虑得到用于计算数据预迁移的迁移函数为:
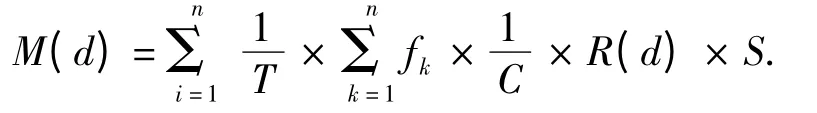
在得到新的数据迁移函数后,根据混合云的迁移算法,本节给出新的适合于电子政务云存储的基于数据关联度的迁移策略模型,其算法迁移步骤如下:
步骤1:建立迁移队列,根据数据存储的要求对数据进行存储,创建迁移线程和候选迁移队列.
步骤2:计算T=Ti第i个数据中心内的饱和度θ,判断是否大于第i个数据中心内的阈值σ.
步骤3:当T =Ti时,计算私有云内第i个服务器中每个数据集j 的预计迁移值M(dj),根据M(dj)值进行排序,并依次将数据存入数据集合S_OUT 中等待迁移.
步骤4:利用数据迁移工具从S_OUT 中选择对M(d)最大的待迁移的数据集,执行数据迁移.
步骤5:计算下一个数据中心的饱和度θ,并判断是否执行了数据迁移,修改各数据中心数据集的属性值.
由上面的分析得出本文的迁移模型的伪代码和数据迁移策略流程图(图3).模型的伪代码如下:
初始化:令私有云数据中心编号i=0,数据中心编号上的数据集编号j=0;
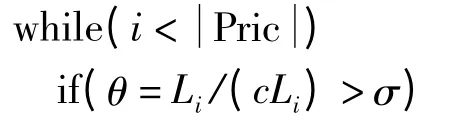

{根据迁移函数对第j个数据集进行计算,求出max(M(dj));j++;}
对M(D)最大的数据集执行数据迁移;
跳出本次循环,i++;
if(执行了数据迁移)

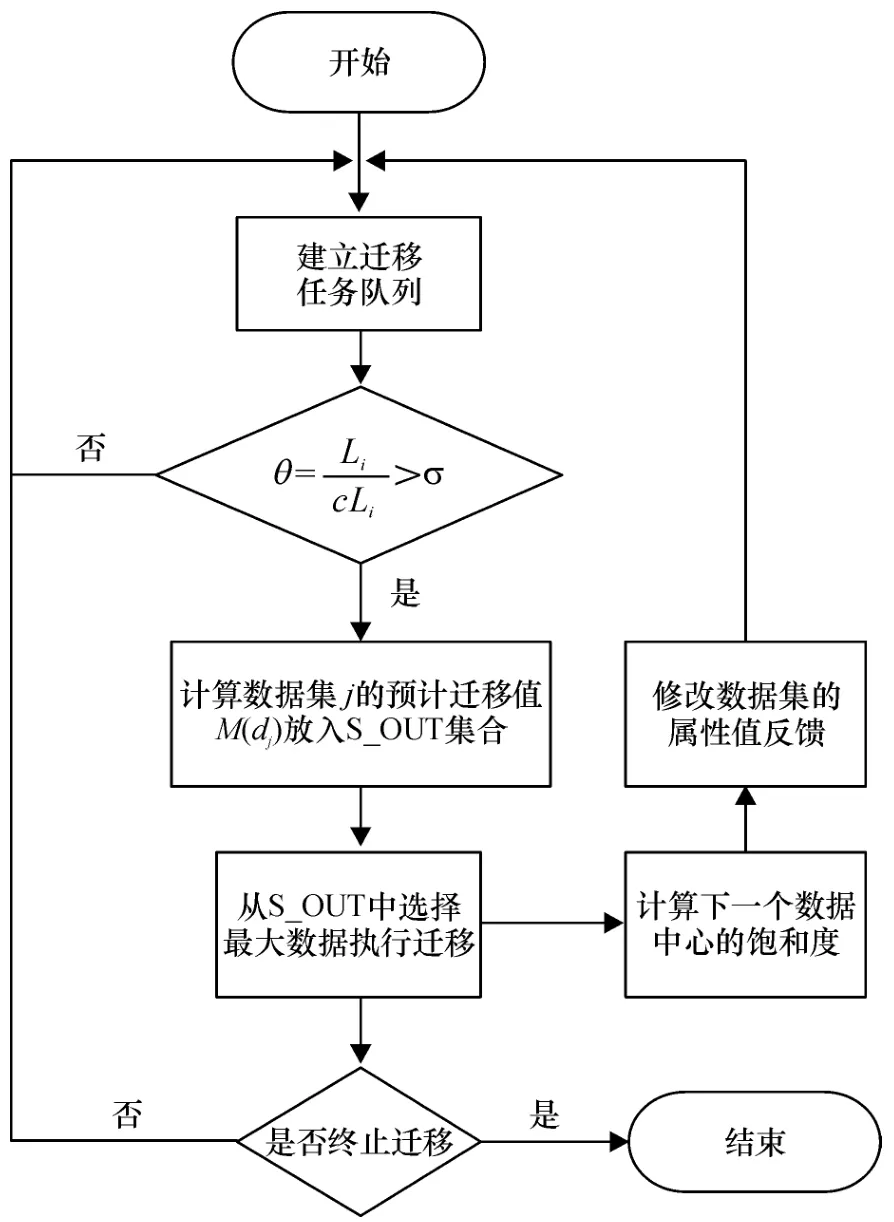
图3 数据迁移策略模型流程图Figure 3 Flow chart of data migration strategy model
3 实验结果与分析
3.1 成本分析
目前,传统的电子政务平台大都基于集中式存储[10],经调研得知采购规模8TB 的服务器需要4 000 美元.按单位存储量计算即0.5 美元/GB,每台服务器的功率为0.6 kW(传统集中式存储一般有2 台服务器,1 台作为备份用),空调平均功率为2 kW,则1 天内,管理成本中耗电量为76.8 kW·h.传统集中式数据存储需要有数据维护人员的开支以及服务器的耗电电费,数据维护人员按照1个月5 000 元算,其他开支忽略不计,按照每度电0.62 元计算,人民币兑美元的汇率为1 美元=6.12 元,则可以计算出传统的管理数据成本.目前,公有云的提供商网上均价为0.1 美元/(GB·月-1). 存储成本的计算结果,利用本文提出的迁移模型与传统的集中式存储方式相比较(表1),可见本文的数据管理能明显降低数据管理成本,且数据量越大,管理成本节省越多.
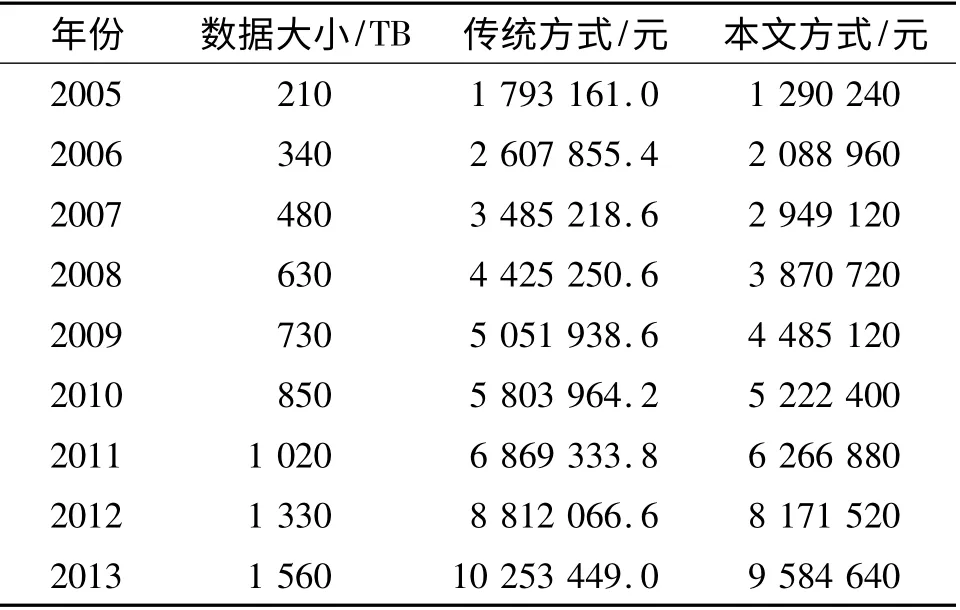
表1 数据管理成本对比表Table 1 Comparison table of data management cost
3.2 模拟实验分析
本实验环境为Windows8.1、64 位操作系统、CPU 为双核2.2 GHz,java 集成开发工具eclipse-jeekepler,仿真软件Matlab7.0R14. 为了检验上述迁移算法的计算预迁移能力及优化能力,本实验用UCI数据库的IrisData 数据集作为实验测试数据,用于计算其在某一时刻数据集的预计迁移值M(d).Iris数据集[11]以鸢尾花的特征作为数据来源,包含150个数据集,分为3 类:setosa、versicolor 和virginica.每类50个数据,每个数据(即每个样本)包含4个属性,实验将样本中的数据作为本文中的迁移属性值来算.实验主要分为2个部分,在访问频率、访问量和访问时间区间都一样的条件下,分别引入数据关联度R 和不引入数据关联度计算数据集的预迁移值M(d)(计算过程中和图中用符号md 表示该值),并加以比较.从结果可以看出,2 种方法都能找出需迁移的数据集,但是引入数据关联度的分析明显会比不引入数据关联度的预数据迁移值更高. 在数据迁移时,预计迁移值越高,找到所需数据的准确率越高,对比分析(图4)可知.引入数据关联度,更加有效计算出迁移值,得到的md 值比没有引入数据关联度的md 值明显偏大,其中,md 值的单位为数量值1.图像中出现的1 ~50 号文件迁移值较小,因为IrisData 数据属性值本身就小,按上述计算方式计算得到的md 值也较小.

图4 数据集预迁移值引入数据关联度前后对比Figure 4 Comparison of the migration of expected value before and after data relevance introduced into the data sets
4 结束语
本文在电子政务云平台下,研究了数据的迁移算法,总结影响数据迁移的若干因素.从静态因素和动态因素两方面提出了改进的数据迁移模型,以实现数据在云平台的动态迁移.经过实验分析,运用本文的算法,和传统的迁移集中式管理相比大大减少了数据的管理成本.在引入数据关联度后,在计算数据预计迁移值时具有明显的优越性,能够得到较准确的数据迁移预计值. 未来可以在数据间关联规则方面进行作进一步的研究.如果数据大,需深入挖掘数据间的相互关联性规律,以更好地找出所需要的预计迁移的数据,提高数据迁移前命中率.
[1]Lugar J. Hierarchical storage management:Leveraging new capabilities[J]. IT Professional,2001,3(2):53-55.
[2]Maguluri S T,Srikant R,Lei Y. Stochastic models of load balancing and scheduling in cloud computing clusters[C]∥INFOCOM,Proceedings IEEE. Orlando,FL,2012:702-710.
[3]He D S,Zhang X B,Du D H C,et al.Coordinating parallel hierarchical storage management in object-based cluster file system[EB/OL].[2014- 12- 28]. http:∥www.dtc.umn.edu/publications/reports/2006-13.pdf.
[4]Smitha,Reddy A L N.LRU-RED:An active queue management scheme to contain high bandwidth flows at congested routers[C]∥proceeding of the global telecommunications conference. San Antonio,TX,2001:2311-2315.
[5]Modha D,Megiddo N. Outperforming LRU with an adaptive replacement cache algorithm[J]. Computer,2004,37(4):58-65.
[6]黄冬梅,杜艳玲,贺琪,等. 混合云存储中海洋大数据迁移算法的研究[J]. 计算机研究与发展,2014,51(1):199-205.Huang D M,Du Y L,He Q,et al. Big ocean data migration algorithm in the hybrid cloud storage research[J].Journal of Computer Research and Development,2014,51(1):199-205.
[7]吕帅,刘光明,徐凯,等.海量信息分级存储数据迁移策略研究[J]. 计算机工程与科学,2009,31(S1):163-167.Lv S,Liu G M,Xu K,et al. Massive information storage of data migration strategy study[J]. Computer Engineering and Science,2009,31(S1):163-167.
[8]刘国杨.基于价值评估的卫星遥感数据迁移方法探讨[J].航天器工程,2008,17(4):114-117.Liu G Y. Based on the evaluation of satellite remote sensing data migration method[J]. Journal of Spacecraft Engineering,2008(4):114-117.
[9]江菲,汤小春,张晓,等. 基于价值评估的数据迁移策略研究[J].电子设计工程,2011,19(7):11-13.Jiang F,Tang X C,Zhang X,et al. Based on the evaluation of data migration strategy research[J]. Journal of Electronic Design Engineering,2011,19(7):11-13.
[10]吴彦华.基于云计算的电子政务应用研究——以青岛市电子政务云平台为例[D]. 北京:首都经济贸易大学,2014.Wu Y H. E-government application based on cloud computing research:In Qingdao e-government cloud platform,for example[D].Beijing:Capital University of Economics and Business,2014.
[11]宋丽.基于决策树的组合分类器的研究[D].西安:西安电子科技大学,2012.Song L.Research on classifier ensemble based on decision tree[D].Xi'an:Xidian University,2012.
