基于内容过滤的个性化农业信息推荐模型研究
2015-10-28张启宇等
张启宇等


摘要:针对农业信息化综合服务平台信息过载问题,构建了个性化农业信息推荐模型,重点研究了用户类别兴趣向量、用户特征词喜好向量和文档特征向量,建立了农业专业词典和中英文停用词典;采用遗忘函数按时间对特征词的权重进行更新,并对用户类别兴趣进行更新,实现用户模型的更新;采用余弦相似度进行推荐度计算,提出了个性化服务推荐算法;通过对推荐信息的URL参数统计获知推荐效果,进一步对个性化推荐模型进行修正。结果表明,该模型可根据用户兴趣制定推荐,为用户提供有价值的信息,满足用户个性化需求。
关键词:内容过滤;个性化服务;农业信息;信息推荐
中图分类号:S126;TP391.3 文献标识码:A 文章编号:0439-8114(2015)16-4052-05
DOI:10.14088/j.cnki.issn0439-8114.2015.16.057
Study on Personalization Recommendation Model of Agricultural Information
Based on Content Filtering
ZHANG Qi-yu1,GUO Cheng-kun2,SONG Yao2,CHEN Ying-yi2,WANG Lei3
(1.Yantai Academy, China Agriculture University, Yantai 264670, Shandong, China;
2. College of Information and Electrical Engineering, China Agricultural University, Beijing 100083, China;.
3.Institute of Information Technology, Shandong Academy of Agricultural Sciences, Jinan 250100,China)
Abstract: The personalization recommendation model of agricultural information was constructed in view of information overload on agricultural information service platform. The model focused on three vectors including user category interest vector,user feature words preferences vector and document feature vector,established agricultural professional dictionary and English-Chinese disable dictionary;And then, using forgotten function the model updated weights of feature words, interest items of the user category and user model by time. The last,the model calculated recommended degrees by the cosine similarity,and proposed personalized service recommendation algorithm. Through the URL parameter statistics of recommended information,this model can inform recommendation effect and further correct the model. The results showed that the model can formulate recommendations based on user interest,provide valuable information, and meet the peisonalized needs of users.
Key words: content filtering; personalized service; agricultural information; information recommendation
随着互联网和农业信息化的迅速发展,农业网站建设进入了快速发展期。大量的农业技术、供求信息、市场信息、政策法规和农业新闻等信息资源分布在农业网站中,然而由于互联网信息资源具有信息异质、异构、分散、重复现象严重的特点,缺少统一的形式化表达,形成各种各样的“信息孤岛”,很难对农业信息资源进行整合和利用[1]。对农民而言,不会使用搜索引擎,不知道使用什么关键词进行搜索。为此,打造了农业信息化综合服务平台,农业信息化综合服务平台包括农业服务信息搜索引擎系统(针对涉农科技信息、市场行情、市场供求等信息进行定时、定向地自动获取、清洗和分类)、信息展示系统(搜索引擎获取的信息分类显示)、农业专家系统、农业论坛系统(用户提出各种农业问题,由农业专家或其他用户回答,支持短信智能问答)、个性化服务系统(根据用户的兴趣爱好进行信息主动推荐)等。随着信息的不断增长,用户很容易被淹没在信息海洋当中[2],因此个性化服务系统是农业信息化综合服务平台的重要组成部分,可以提取及分析用户个性信息,根据用户兴趣制定推荐,为用户提供有价值的信息,满足用户个性化需求[3]。
个性化服务系统根据其所采用的推荐技术可分为基于规则的系统和信息过滤系统。信息过滤系统又可分为基于内容过滤的系统和协作过滤系统[4]。目前对于基于内容过滤的个性化服务推荐模型的研究主要在搜索引擎[5]、数字图书馆[6-8]、虚拟研究环境[9]、博物馆[10]等领域,对农业领域的研究很少。本研究对基于内容过滤的个性化服务推荐模型进行了研究,提出了适合农业信息化综合服务平台的可更新的个性化服务推荐模型。endprint
1 用户兴趣模型
1.1 用户兴趣的获取
个性化服务推荐模型建立的第一步是建立用户兴趣模型。建立用户兴趣模型首先要获取用户兴趣,用户模型中兴趣的获取主要有用户显式反馈和用户隐式反馈两种[4]。用户显式反馈是指用户回答系统提出的问题,直接参与建模过程,一般通过填表的方式来完成,其优点是获取的信息比较具体、全面、客观,可靠性较高,缺点是灵活性差,浪费用户的时间;用户隐式反馈是指系统在观察用户行为的基础上通过推理来获取用户兴趣知识,可以减少用户不必要的负担。
根据农业信息化综合服务平台的特点,用户兴趣获取的信息包括用户注册时的兴趣爱好、浏览的信息页面、信息查询的关键词、论坛中发布及回复的帖子、短信提问的问题。
1.2 用户兴趣模型的表示
杨艳等[5]提出的将兴趣粒度表示法和向量空间模型表示法结合起来的显隐式结合用户模型,在用户兴趣爱好固定的情况下取得了比较好的效果。但用户的兴趣爱好不是一成不变的,本研究借鉴了该模型的思想,根据农业信息化综合服务平台的特点,构造可更新用户兴趣类别的用户兴趣模型。
农业信息化综合服务平台中的信息是分类显示的,因此把用户的兴趣爱好表现在信息的类别上。把用户的每一个感兴趣的类别和对该类别感兴趣的程度用一个向量表示,称为类别兴趣向量,定义为CI=<(C1,W1),(C2,W2),…,(Cm,Wm)>其中m为用户感兴趣的类别个数,Cj为第j个类别,Wj为对应的权重,并且■Wj=1。
在用户注册时,系统要求用户选择自己感兴趣的类别,并给出喜好程度的度量,以此建立喜好向量i=(i1,i2,…,im),m为用户感兴趣的类别个数,ij=∈[1,5],为用户对类别j喜好程度的度量,值越大,表示喜好程度越高。对向量i进行规范化处理:Wj=ij/■ij。
每一个感兴趣的类别用n个特征词表示,称为特征词喜好向量,定义为Tk=<(t1,w1k),(t2,w2k),…,(tn,wnk)>,k∈[1,m],m为用户感兴趣的类别个数,n为特征词的个数,tj为第j个特征词,wjk为tj在类别Cj的权重,并且■wjk=1。
把用户类别喜好向量和用户特征词喜好向量综合起来可以构成用户兴趣喜好向量,定义为UI=<(C1,W1,T1),(C2,W2,T2),…,(Cm,Wm,Tm)>,其中m为用户感兴趣的类别个数,Cj为第j个类别,wj为对应的权重,并且■Wj=1,Tj为特征词喜好向量,j∈[1,m]。
2 用户兴趣模型的实现
目前,在信息处理方向上,文本的表示主要采用向量空间模型[11]。用空间向量模型表示文本,首先要对文本进行分词,进行特征选择和权重计算,最后形成一个N维空间向量[12]。
2.1 特征词权重的计算
权重的计算有多种方法,主要有布尔函数、频度函数、开根号函数、对数函数、熵函数及TF*IDF函数等,TF*IDF函数因其算法相对简单、有较高的准确率和召回率,一直受到相关研究人员和众多应用领域的青睐[13]。Salton在1973年提出的TF*IDF启发式权重算法计算公式[14]为:
W(fi,d)=TF(fi,d)×DIF(fi)=N(fid)×log(N(fi)/N)(1)
其中,W(fi,d)是特征词fi在文本d中的权重,N(fi)是出现特征词fi的文本数,N是总文本数,N(fid)是文本d中出现fi的次数。
施聪莺等[12]对“考虑类间类内差异的TF*IDF”、“TF*IWF*IWF”、“引入方差的TF*IWF*IWF”及“TF*IDF频率”算法进行测试,“引入方差的TF*IWF*IWF”无论是在开放测试还是在封闭测试中,F1测试值都非常高,反映了方差在抑制干扰方面的作用。本研究采用陈克利等[13]提出的“引入方差的TF*IWF*IWF”权重算法进行计算。
特征词在类别中的权重计算公式:
wij=■×(log(N(ti)/N))2×■ (2)
特征词在文档中的权重计算公式:
wid=■×(log(N(ti)/N))2×■ (3)
其中,Pij=Tij/Lj,Lj是类别Cj含有的所有特征词的次数之和,Tij是特征词ti在类别Cj出现的次数;Pid=Tid/Ld,Ld是文档d含有的所有特征词的次数之和,Tid是特征词ti在文档d 出现的次数;■i=■Pij/m,其中m为类别数;a为正整数;N(ti)是全部文档中出现特征词ti的次数,N是全部文档所有特征词出现次数之和。这里a的取值为3。
借鉴刘华等[14]对不同特征词进行加权的思路,标题中的特征词加权底数为2,查询的特征词加权底数为3,正文中的特征词数按200字分级,每增加一级,在原来系数上相应加1。重新修订公式(2)和(3)中Tij与Tid的计算:
Tid=∑Tic+(3+?姿)∑Tis+(2+?姿)∑Tit (4)
Tij=■Tid (5)
其中,∑Tic表示特征词在正文中的计数,∑Tit表示特征词在标题中的计数,∑Tis表示特征词在查询中的计数,λ=Tic\200(“\”表示整除)。
心理学研究认为,人的记忆会随着时间的延续而逐渐遗忘,当环境或场合的改变使得记忆中的某些信息长期不被利用时,这些信息会逐渐被遗忘。根据心理学的记忆遗忘理论,可以认为用户兴趣的改变就是一种记忆遗忘现象[16]。目前对遗忘机制的研究是把时间对兴趣的影响通过遗忘函数或遗忘因子来表示出来,并更新用户的兴趣。遗忘函数或遗忘因子有着不同的公式表示,有指数函数[16-21]、线性函数[22-26]、菲波拉契数列[27]、幂函数[28]、对数函数[29]、分段函数[30]、非线性函数[31-33]等。于洪等[28]用ZGrapher工具对艾宾浩斯遗忘曲线进行拟合,得到符合遗忘曲线的数学函数:endprint
Y=0.318×X-0.125(X>0) (6)
南智敏[30]对艾宾浩斯遗忘曲线拟合出分段函数,其中n为自然数:
g(n)=1,n=00.337,n=10.29-0.006n,2≤n≤60.264 32-0.001 72n,6≤n≤31(7)
百度百科的“遗忘曲线”词条[34]给出了艾宾浩斯记忆遗忘一般规律,得出初次记忆后经过了X小时,记忆率Y近似地满足:
Y=1-0.56×X0.06 (8)
对公式(6)~(8)进行运算,公式(7)最符合艾宾浩斯遗忘曲线,但公式(7)缺少31 d以后的表示。31 d以后的记忆趋于稳定,所以把31 d以后设置为固定值0.211,修改后的公式为公式(9):
g(n)=1,n=00.337,n=10.29-0.006n,2≤n≤60.264 32-0.001 72n,6≤n≤310.211,n>31(9)
但兴趣的改变和遗忘不能完全一样,因此把日期的天数换成日期的区间,以保证兴趣的稳定性,修改后的公式为公式(10):
g(n)=1,0≤n≤t0.337,t≤n≤2t0.29-0.006n,2t≤n≤6t0.264 32-0.001 72n,6t≤n≤31t0.211,n>31t(10)
其中,t为正整数。
采用公式(10)对特征词在类别和文档中的权重进行动态更新。特征词的权重按照公式(2)和(3)进行特征词加权修订后和公式(10)之乘积进行计算。文档中的权重也要计算,因为文档越新,对用户的价值越大,公式(10)对类别和文档进行计算时,t可以取不同的值。
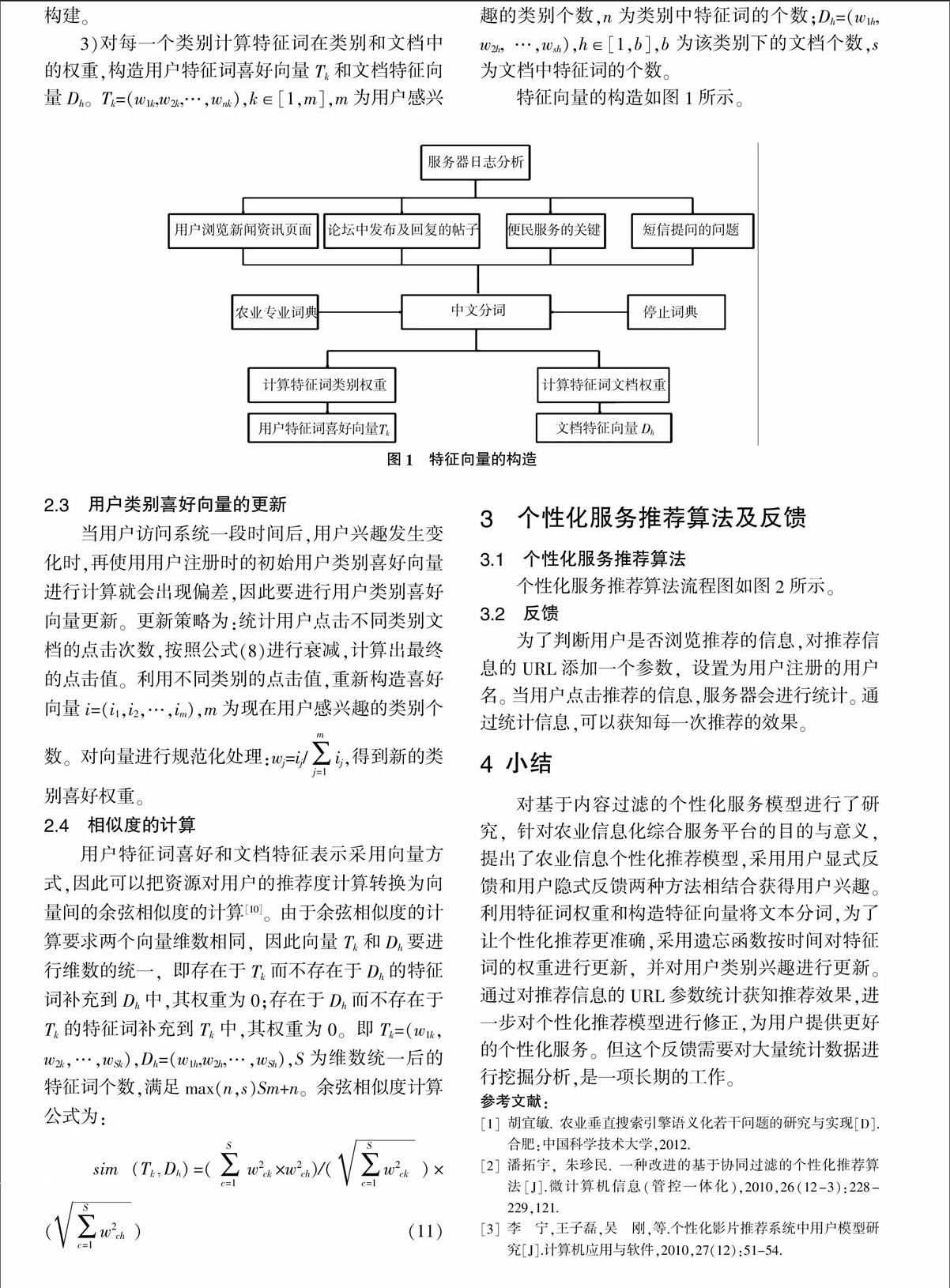
2.2 特征向量的构造
特征向量的构造过程如下:
1)分析服务器日志,去掉与日志无关的信息,如请求失败信息、页面图片请求等等,把用户有效的访问信息保存到数据库中[4]。
2)获取用户浏览的新闻资讯页面、论坛中发布及回复的帖子、便民服务的关键词、短信提问的问题,进行中文分词,去除停用词。对于中文分词采用IK Analyzer 2012。IK Analyzer是一个开源的、基于Java语言开发的轻量级中文分词工具包。在2012版本中,支持通过配置IK Analyzer.cfg.xml文件来扩充专有词典和停止词典,词典的格式为无BOM的UTF-8编码的中文文本文件[35]。农业专业词典可以借助网络上的词库构建,搜狗输入法[36]、百度输入法[37]、QQ输入法[38]等输入法提供了众多的词库供用户下载使用。从“农林牧渔”类挑选词库,整理农业专业词典。停止词典在文献[39]和[40]的基础上构建。
3)对每一个类别计算特征词在类别和文档中的权重,构造用户特征词喜好向量Tk和文档特征向量Dh。Tk=(w1k,w2k,…,wnk),k∈[1,m],m为用户感兴趣的类别个数,n为类别中特征词的个数;Dh=(w1h,w2h,…,wsh),h∈[1,b],b为该类别下的文档个数,s为文档中特征词的个数。
特征向量的构造如图1所示。
2.3 用户类别喜好向量的更新
当用户访问系统一段时间后,用户兴趣发生变化时,再使用用户注册时的初始用户类别喜好向量进行计算就会出现偏差,因此要进行用户类别喜好向量更新。更新策略为:统计用户点击不同类别文档的点击次数,按照公式(8)进行衰减,计算出最终的点击值。利用不同类别的点击值,重新构造喜好向量i=(i1,i2,…,im),m为现在用户感兴趣的类别个数。对向量进行规范化处理:wj=ij/■ij,得到新的类别喜好权重。
2.4 相似度的计算
用户特征词喜好和文档特征表示采用向量方式,因此可以把资源对用户的推荐度计算转换为向量间的余弦相似度的计算[10]。由于余弦相似度的计算要求两个向量维数相同,因此向量Tk和Dh要进行维数的统一,即存在于Tk而不存在于Dh的特征词补充到Dh中,其权重为0;存在于Dh而不存在于Tk的特征词补充到Tk中,其权重为0。即Tk=(w1k,w2k,…,wSk),Dh=(w1h,w2h,…,wSh),S为维数统一后的特征词个数,满足max(n,s)Sm+n。余弦相似度计算公式为:
sim(Tk,Dh)=(■w2ck×w2ch)/(■)×(■) (11)
3 个性化服务推荐算法及反馈
3.1 个性化服务推荐算法
个性化服务推荐算法流程图如图2所示。
3.2 反馈
为了判断用户是否浏览推荐的信息,对推荐信息的URL添加一个参数,设置为用户注册的用户名。当用户点击推荐的信息,服务器会进行统计。通过统计信息,可以获知每一次推荐的效果。
4 小结
对基于内容过滤的个性化服务模型进行了研究,针对农业信息化综合服务平台的目的与意义,提出了农业信息个性化推荐模型,采用用户显式反馈和用户隐式反馈两种方法相结合获得用户兴趣。利用特征词权重和构造特征向量将文本分词,为了让个性化推荐更准确,采用遗忘函数按时间对特征词的权重进行更新,并对用户类别兴趣进行更新。通过对推荐信息的URL参数统计获知推荐效果,进一步对个性化推荐模型进行修正,为用户提供更好的个性化服务。但这个反馈需要对大量统计数据进行挖掘分析,是一项长期的工作。
参考文献:
[1] 胡宜敏.农业垂直搜索引擎语义化若干问题的研究与实现[D].合肥:中国科学技术大学,2012.
[2] 潘拓宇,朱珍民.一种改进的基于协同过滤的个性化推荐算法[J].微计算机信息(管控一体化),2010,26(12-3):228-229,121.
[3] 李 宁,王子磊,吴 刚,等.个性化影片推荐系统中用户模型研究[J].计算机应用与软件,2010,27(12):51-54.endprint
[4] 曾 春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
[5] 杨 艳,邱艳丽.新的基于日志分析的用户个性化模型[J].计算机科学与探索,2012,6(4):333-342.
[6] 余 侠,朱 林.根据用户反馈建立和更新数字图书馆用户兴趣模型[J].情报杂志,2004(11):21-22.
[7] 张 帆,杨炳儒.基于文本过滤的数字图书馆个性化服务技术[J].计算机工程与应用,2006(31):206-208.
[8] 赵银春,付关友,朱征宇.基于Web浏览内容和行为相结合的用户兴趣挖掘[J].计算机工程,2005,31(12):93-94,198.
[9] 李 永,徐德智,张 勇,等.VRE中基于内容过滤的论文推荐算法[J].计算机应用研究,2007,24(9):58-60,89.
[10] 周珊丹,周兴社,王海鹏,等.智能博物馆环境下的个性化推荐算法[J].计算机工程与应用,2010,46(19):224-226.
[11] 赵丰年,刘 林,商建云.基于概念的文本过滤模型[J].计算机工程与应用,2006,42(4):186-188.
[12] 施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(6):167-170,180.
[13] 陈克利,宗成庆,王 霞.基于大规模真实文本的平衡语料分析与文本分类方法[A].孙茂松,陈群秀.语言计算与基于内容的文本处理——全国第七届计算语言学联合学术会议论文集[C].北京:清华大学出版社,2003.
[14] 刘 华,张 普.面向词典编纂的词汇聚类研究[A].2004年辞书与数字化研讨会论文集[C].上海:上海辞书出版社,2004.
[15] 颜端武.面向知识服务的智能推荐系统研究[D].南京:南京理工大学,2007.
[16] 蒋 萍,崔志明.智能搜索引擎中用户兴趣模型分析与研究[J].微电子学与计算机,2004,21(11):24-26.
[17] ZHANG Y C, LIU Y Z. A collaborative filtering algorithm based on time period partition[A].In:Proceeding of the 3rd international symposium on intelligent information technology and security informatics[C].USA:IEEE,2010.
[18] 张红卫.基于科技文献的时序主题链构建方法研究[D].辽宁大连:大连理工大学,2013.
[19] 邓 娟,陈西曲.基于用户兴趣变化的协同过滤推荐算法[J].武汉工业学院学报,2013,32(4):48-51.
[20] 邓 攀,钟 将.基于推荐的抗攻击电子商务信任模型[J].计算机应用,2013,33(12):3490-3493,3502.
[21] 李克潮,梁正友.适应用户兴趣变化的指数遗忘协同过滤算法[J].计算机工程与应用,2011,47(13):154-156.
[22] 石 晶,龚震宇,裘杭萍,等.基于用户兴趣模型的智能信息检索系统技术与实现[J].情报学报,2003,22(3):282-286.
[23] 宋丽哲,牛振东,余正涛,等.一种基于混合模型的用户兴趣漂移方法[J].计算机工程,2006,32(1):4-6,89.
[24] 李 宁,王子磊,吴 刚,等.个性化影片推荐系统中用户模型研究[J].计算机应用与软件,2010,27(12):51-53.
[25] 邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[26] 郑充林.协同过滤的服装推荐算法的改进研究[D].上海:东华大学,2013.
[27] 张守志,许 彦.一个个性化服务系统的设计与实现[J].小型微型计算机系统,2003,24(12):2155-2158.
[28] 于 洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报(自然科学),2010,46(5):520-527.
[29] 朱 祎,和 莉,王小军.基于关联反馈技术的用户兴趣模型的建立与自适应更新[J].金陵科技学院学报,2011,27(4):35-39.
[30] 南智敏.基于网页兴趣度的用户兴趣模型体系研究[D].上海:复旦大学,2012.
[31] 申倩倩.基于本体和情境感知的信息个性化服务关键技术研究[D].西安:西安工程大学,2011.
[32] 李志浩,聂文汇,成 鹏,等.基于分页缓存模型的用户兴趣跟踪方法[J].计算机工程与科学,2012,34(10):32-37.
[33] 郑先荣,汤泽滢,曹先彬.适应用户兴趣变化的非线性逐步遗忘协同过滤算法[J].计算机辅助工程,2007,16(2):69-73.
[34] 遗忘曲线[EB/OL].http://baike.baidu.com/link?url=V3FKH3Uhy
yA_I4qK7-cgYuoy7-Rsy_y1PwE1_CXFLFeBcArJ3StBEgSh9Ezg
Bqr9,2014-03-04/2014-04-20.
[35] IKAnalyzer中文分词器V2012使用手册[EB/OL].http://code.google.com/p/ik-analyzer/downloads/detail name AD%E6%96%87%E5%88%86%E8%AF%8D%E5%99%A8V2012%E4%BD%BF%E7%94%A8%E6%89%8B%E5%86%8C.pdf&can=2&q=,2012-03-07/2014-04-20.
[36] 搜狗细胞词库_词库下载_词典_输入法字典[EB/OL].http://pinyin.sogou.com/dict/.
[37] 百度输入法-词库首页[EB/OL].http://shurufa.baidu.com/dict-list.html.
[38] QQ输入法分类词库[EB/OL].http://dict.py.qq.com/.
[39] 张启宇.基于贝叶斯算法的垃圾邮件过滤系统的研究与设计[D].山东曲阜:曲阜师范大学,2006.
[40] 应晓敏.面向Internet个性化服务的用户建模技术研究[D].长沙:国防科学技术大学,2003.endprint
