基于批量递归最小二乘的自然Actor-Critic算法
2015-10-24王国芳
王国芳,方 舟,李 平
(浙江大学航空航天学院,浙江杭州310027)
基于批量递归最小二乘的自然Actor-Critic算法
王国芳,方 舟,李 平
(浙江大学航空航天学院,浙江杭州310027)
为了减轻Actor-Critic结构中智能体用最小二乘法估计自然梯度时的在线运算负担,提高运算实时性,提出新的学习算法:NAC-BRLS.该算法在Critic中利用批量递归最小二乘法估计自然梯度,根据估计得到的梯度乐观地更新策略.批量递归最小二乘法的引入使得智能体能根据自身运算能力自由调整各批次运算的数据量,即每次策略估计时使用的数据量,在全乐观和部分乐观之间进行权衡,大大提高了NAC-LSTD算法的灵活性.山地车仿真实验表明,与NAC-LSTD算法相比,NAC-BRLS算法在保证一定收敛性能的前提下,能够明显降低智能体的单步平均运算负担.
自然梯度;Actor-Critic;批次更新;递归最小二乘
强化学习(reinforcement learning,RL)是最优控制和人工智能领域倍受关注的方法之一.和常规的监督学习及非监督学习不同,强化学习是将智能体放置于完全未知的环境中,智能体通过与环境相互作用,获得可评估的即时报酬;根据即时报酬来优化自身的行为策略,从而获得能够最大化累积报酬的策略[1].强化学习最明显的优势在于学习与模型无关并且适用于非线性乃至随机控制问题,近年来,在复杂的智能机器人控制领域已获得了可观的应用成果[2-3].
就算法结构而言,强化学习方法大体可以分为3类,即Actor-Only、Critic-Only和Actor-Critic(此处Actor表示动作选择即策略,Critic表示策略评估)[3].Actor-Only结构如REINFORCE法可以处理连续的动作,并且容易证明算法的收敛性,但由于缺乏策略评估过程,得到的策略梯度方差大,收敛速度会较慢[4];Critic-Only结构如Sarsa及Q学习等通过值函数推导出策略,但仅适用于有限动作空间的情况,而且当状态空间连续,值函数需要使用函数近似表示时,收敛性不能得到保证[5];Actor-Critic结构能够结合以上两者的优点,目前研究相对较多,本文即是针对这种结构.
在多数Actor-Critic结构的算法中,Critic使用基于bootstrapping的瞬时差分来计算策略期望报酬[6],然后Actor根据Critic推导出的期望报酬对策略参数的梯度来更新策略.这种方法的运算复杂度相对较低,适合在线学习.在Critic中使用瞬时差分,数据仅利用一次,然后就被遗弃,没能充分挖掘数据包含的信息[7].特别是在某些情况下,获取数据消耗时间或者代价很大(比如飞行器的控制),这需要强化学习算法尽量减少所需的数据量.随着硬件性能的提升,计算机的运算速度不断提高,瞬时差分学习方法在计算效率方面的优势不太明显,这为在计算复杂度和数据有效性之间作出更好的平衡提供了物理实现基础.
Bradtka等[8]提出Critic使用基于线性值函数近似的最小二乘瞬时差分方法来评估策略.随后, Boyan把资格迹(eligibility trace)引入到最小二乘瞬时差分(LSTD)中来提高泛化性能[9].除数据高效利用外,LSTD避免TD学习算法中学习步长设计的困难,因而最小二乘法被认为是最好的策略估计方法之一[10-12].与此同时,为了降低LSTD的计算复杂度,Xu等[13]引入递归最小二乘(RLS)法.
对于Actor,Amari[14]证明在某些情况下更新自然梯度更高效.随后,Peters等[2]把自然梯度引入到Actor-Critic方法中,通过克服期望报酬对策略参数梯度小的困难直接指向最优策略来减少迭代次数,但估计自然梯度的运算复杂度比估计普通梯度大很多.
针对上述问题,本文提出在Critic中使用批量递归最小二乘法来计算自然策略梯度,从而有效地降低智能体单步平均运算复杂度,同时批量的引入可以增大最小二乘法在强化学习中使用的灵活性.智能体能够根据实际运算能力调整每个批次的数据量,批次与批次的数据量不一致亦可,然后全乐观(每个数据后都进行策略更新)或部分乐观(一些数据后进行策略更新)[15]地更新策略,而不是在等得到准确的梯度估计或者完成一个episode之后[2].该方法结合了自然策略梯度的快速收敛和递归最小二乘法的数据高效利用,能够较快地获得最优或次优策略,同时满足智能体运算效率的限制,提高了最小二乘法估计自然梯度的实用性.
1 自然Actor-Critic
1.1 MDP模型
在强化学习中,需要解决的底层控制问题通常是序贯决策问题(sequential decision problem),也称作马尔可夫决策过程(Markov decision process, MDP).MDP问题通常包含(S,A,P,R,γ)5个元素,其中γ表示智能体对报酬进行处理的折扣因子;在t=0时刻,智能体从初始状态s0∈S出发;在离散t时刻,智能体观测当前状态st∈S,然后依据参数化策略π(at|st,θ)选择并执行动作at∈A,系统根据p(st+1|st,at)模型转移到新状态st+1,给出即时报酬rt=r(st,at,st+1)[16].
在实际问题中,状态空间大都是连续的,状态值函数Vπ(s)、状态-动作值函数Qπ(s,a)、优势函数(advantage function)Aπ(s,a)和策略π须使用函数来近似,值函数的线性表示可以定义为


强化学习的目标是找到以θ为参数的近似策略π(a|s,θ),使得从初始状态出发,执行该策略能够最大化每个状态的折扣累积报酬值.
1.2 Actor-Critic
在Actor-Critic结构中,如图1所示,策略(Actor)参数θ根据策略期望报酬对于θ的梯度方向进行更新.
假设ρ(π)表示策略π的长远期望报酬,根据策略梯度定理可知,策略对于参数θ的常规或者“vanilla”梯度[17]表示为

式中:φ(s)表示在状态空间中选取的基函数,φsa为状态-动作值的基函数,为简便起见,可以选取:

图1 Actor-Critic框架Fig.1 Actor-Critic Framework

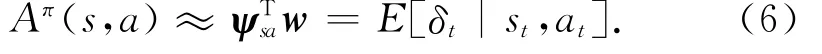
式中:w为近似优势函数的参数.
函数近似的均方差可以通过下式计算:
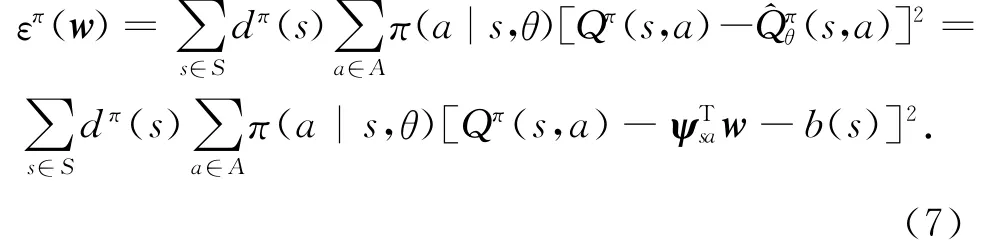
则优势函数可以表示为
Bhatnagar证明:当bπ(s)=V(s)时,均方误差达到最小[5],则参数的梯度可以表示为

将式(6)代入式(8),推导出参数更新公式:

式中:αt、βt为参数更新步长,但两者需要满足一定的条件算法才能收敛.
1.3 自然Actor-Critic(NAC)
根据Peters等[2]所述,Actor-Critic中使用自然梯度更新策略能够加快收敛速度.自然策略梯度是将策略结构信息引入到梯度中,可以通过普通梯度乘以费舍尔信息矩阵获取.
策略的费舍尔信息矩阵定义如下:


式中:

即自然策略梯度是近似优势函数的参数w[5].
最终策略参数更新如下:

2 NAC-BRLS
2.1 基于最小二乘瞬时差分的NAC
在Critic中使用最小二乘瞬时差分来估计自然策略梯度,利用自然策略梯度来更新策略参数.本文只需设计策略参数更新步长,步长的收敛条件降低.
最小二乘估计问题的目标可以记作

式中:zn为资格迹,δn为瞬时差分误差.
使用最小二乘法计算自然梯度,需要把自然梯度参数引入到最小二乘目标函数中.根据贝尔曼等式以及优势函数的定义,可得

将式(1)、(6)代入式(15),可得

在函数近似中,不可能每一点都完全满足等式,因此δ(st,at,st+1)表示误差项.
将瞬时差分误差表示为参数w、v的函数:

将式(17)代入式(14),可以把目标函数表示为以w、v为变量的函数:

式中:

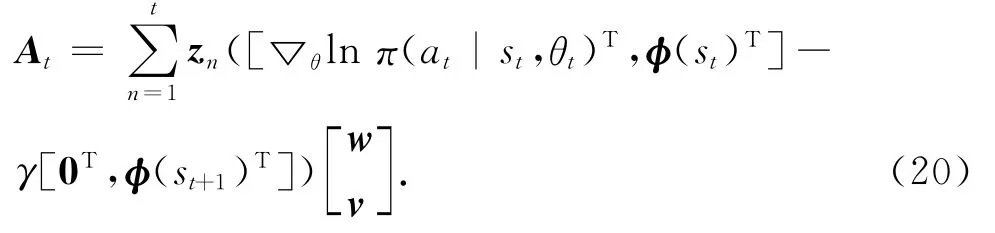
可以计算得到

2.2 基于批量递归最小二乘的NAC
计算矩阵At的逆矩阵需要o(n3)运算复杂度,其中n为矩阵At的阶数.假设状态基函数个数为x,智能体可以采取的动作数为y,则当只需要估计值函数参数v时,n=x;当需要估计自然梯度w时, n=(y+1)x,计算复杂度增大为原来的(y+1)3倍,尤其是当动作空间y比较大的时候,用LSTD在线计算是对智能体实时运算能力的极大考验.
Ljung等[19]的矩阵逆法可以将计算复杂度降为o(n2),将之用于求At[13],能够提高运算实时性.强化学习处理问题,有时数据是批次获取的,因而需要使用矩阵逆法则的拓展形式.
假设每次使用m个数据进行梯度更新,则


此处资格迹为拓展的资格迹,每步更新方法不变:

由于资格迹zt中的遗忘因子λ中已经包含数据的权值因素,本文没有对数据进行重新赋权重.
式(22)~(24)中,假设Ft=,F0=ρI, Kt+1=Ft+1Zt,其中ρ为一个正数,I为单位矩阵.在式(21)中使用矩阵逆法则,可得

Moustakides证明,使用矩阵逆法则的时候,初始方差矩阵F0的额外参数ρ对收敛速度有重要的影响[18],具体初值要根据经验来选取.
随着m的增大,虽然批量最小二乘法的单次运算复杂度相对m较小时有所提高,但批量数据量相对较小时,复杂度的增加不甚明显;由于迭代次数减少,平均单步运算压力明显降低,批量运算的引入使得数据量能够适应智能体运算能力,提高了计算的实时性.
策略更新步长的设置需要合适,过大的话可能发散,过小的话收敛比较慢.单次批量数越大,获得的梯度估计可信度越高,相应策略更新步长可以适度增大,因而尽管迭代次数减少,但是性能基本不受大的影响.
2.3 NAC-BRLS算法的完整流程
1)初始化.设计值函数的基函数φ(s)和随机策略π(a|s,θ),推导出优势函数的基函数ψsa=▽θlogπ(s,a)、参数阵θ=θ0、v=v0、w=w0、折扣因子γ、遗忘因子λ、方差矩阵ρ和收敛误差ε、批次数据量m.
2)选取起始状态s0~p(s0),l=0.
3)选择并执行动作at~π(at|st,θt),观察下一个状态st+1~p(st+1|st,at)和报酬值rt+1=r(st,at, st+1).
4)若s+1是终止状态,则返回2),zt设定为0;否则,式(24)更新资格迹.
若t=(l+1)m,则利用式(25)~(27)计算自然策略梯度,根据式(13)更新策略,l=l+1.否则存储当前状态值,Zt=[Zt,zt+1],


5)若‖θt+1-θt‖≤ε,则结束;否则返回3).
3 模拟验证
山地车(mountain car)上坡问题是强化学习领域常用的验证实例.本文将提出的NAC-BRLS算法应用在山地车的控制学习中进行评估,并与NACLSTD、AC-LSTD和AC-RLS等经典算法进行性能对比.
3.1 山地车上坡问题
在山地车上坡问题中,智能体引导一辆欠驱动的汽车沿着斜坡尽快爬到位于一定高度的目标点,如图2所示[20].
困难之处在于汽车的牵引力不足,在某些位置牵引力分量甚至小于重力分量,因而不能从初始位置开始直接加速爬上山坡,需要先爬到对面的斜坡,然后利用重力加上牵引力来冲上对面更高的位置,如此反复才有可能到达目标位置.
假设选取车的水平位置x和水平速度˙x作为状态空间,则状态属于连续型,值函数以及策略需要使用函数来近似表示.可以选择的动作有3个,分别是a=-0.2、0、0.2,具体数值可能包含幅值为0.04的白噪声.
系统仿真动态模型为

式中:w=0.2 kg表示车的质量,k=0.3为黏滞系数,仿真步长Δt=0.1 s;bound表示限制2个状态的取值范围-1.2≤xt+1≤0.5,-1.5≤≤1.5.当山地车到达左边界时,xt+1不变,重置为0;当山地车到达右边界时,目标达到,周期结束.到达目标点报酬为+1,否则报酬为-0.01.最大化报酬是使山地车能够最快地到达目标位置.

图2 山地车问题Fig.2 Mountain car problem
在二维连续状态空间上可以采用3×4的格子形成12个径向基函数来近似值函数,得到

式中:μ表示径向基函数的12个基准点{-1.2,+0.35,+0.5}×{-1.5,-0.5,+0.5,+1.5}.方差统一选择σ2=1,尽管这不一定是最优选择[21],但是该选择是可行的,并能够由此得到状态-动作值函数和策略.
3.2 模拟结果及分析
分别使用不同批量运算数的NAC-BRLS算法、NAC-LSTD算法、AC-LSTD和AC-RLS算法学习训练山地车,给出相应的仿真结果,并比较学习性能.
在模拟过程中,初始状态s0=[-0.5,0],但包含幅值为0.1的白噪声,折扣系数设为γ=0.99,遗忘因子设为λ=0.4,结束条件设为ε=10-8,初始方差矩阵设为ρ=2.对于NAC-BRLS方法,取批量运算数m=1,2,3,4,5,7,9总共7种情况进行对比,观察性能随m变化的过程,统一设置策略更新步长β=50m/(1000+step+n).NAC-LSTD设定步长为β=50/(1000+step+n),AC-LSTD和AC-RLS设置步长为β=100/(1000+step+n),为了避免出现奇异值并且和递归方法保持一致,LSTD中选取起始At=0.5I,step为在周期内的步数,n为周期的序数.虽然选定的策略更新步长不一定是最优的,通过不断调整可以获取更好的更新步长,但算法的对比是有效的.另外,为了减小偶然性误差,每个算法都运行10次,然后取平均值作为评估性能.
每运行完一个周期后,对所得策略进行评估,获取该策略性能.为了提高仿真效率,除小车到达目的地外,若某个周期模拟超过800步,则认为该策略是失败的,不用再继续进行评估.由于智能体的目标是尽快将山地车引导到某一个高度,可以选择每个周期所需的步数作为策略性能指标,同时报酬函数应和步数一致.
4种学习方法的性能和效率对比如图3~8所示.图中,T为周期,R为报酬,t为耗时.
图3、4给出本文算法(m=1)与较常见算法的性能及报酬对比,2种指标的表示含义基本一致.与NAC-LSTD相比,NAC-BRLS获得的仿真效果相近;与AC-RLS和AC-LSTD相比,尽管NACBRLS的更新步长较小,但收敛速度快很多,这说明自然策略梯度的引入能够明显地加快算法收敛速度.4种方法收敛的稳态基本趋于一致,说明4种方法都是可行的,最终都能够达到相近策略.

图3 不同方法的性能对比Fig.3 Performance comparison of different methods
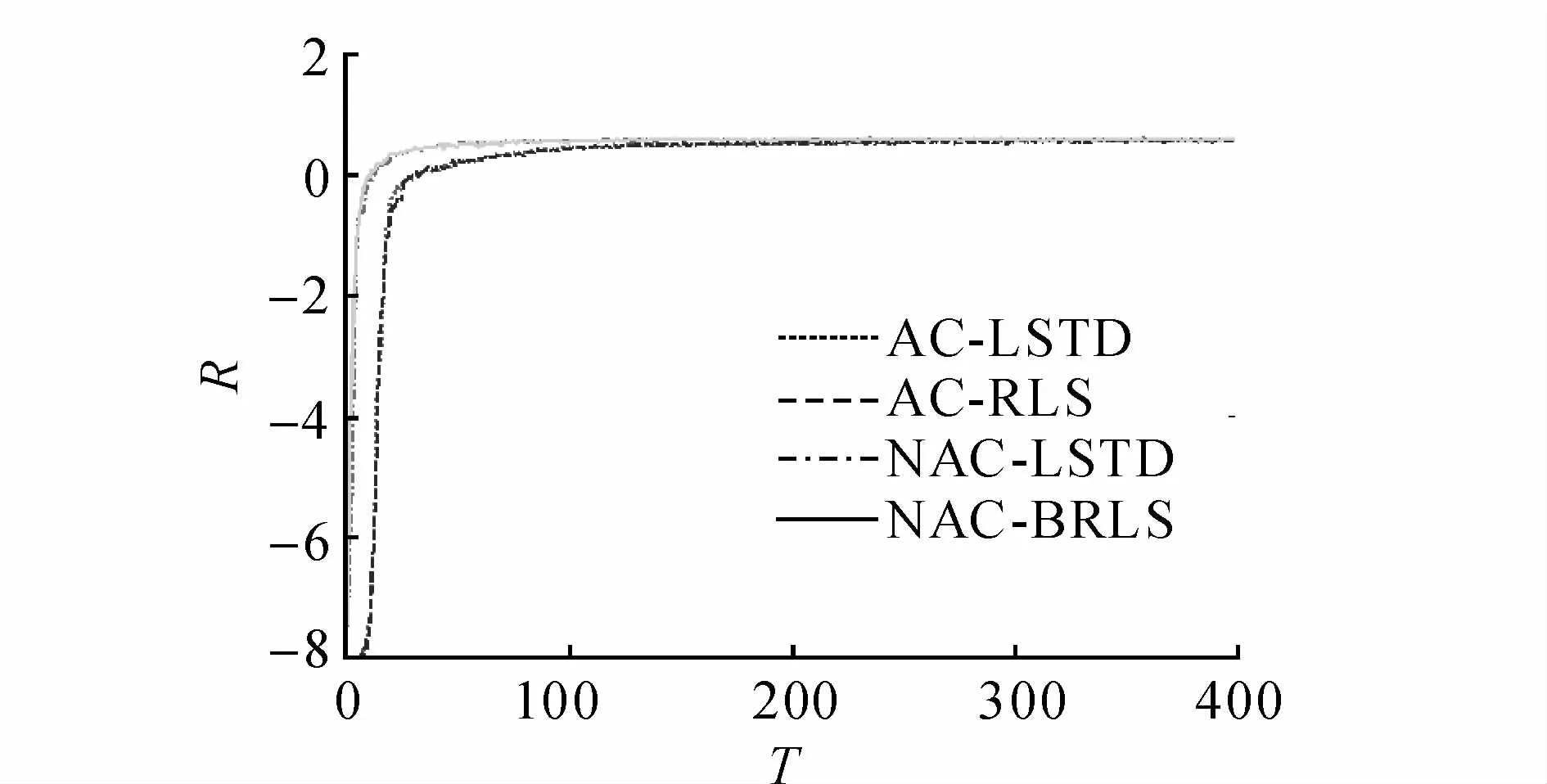
图4 不同方法的报酬对比Fig.4 Rewards comparison of different methods
在性能上,NAC-BRLS与NAC-LSTD的效果相近,图5对比了图3、4所示方法的单步运行时间(单步运算时间来表示智能体的运算复杂度,此处时间是在i7处理器的电脑中matlab2012运行的结果),批量递归引入的优势很明显.自然策略梯度的引入,使得最小二乘法即NAC-LSTD的单步运行时间较长,是AC-LSTD的2倍多,特别是当动作空间增大时,运算复杂度更大,实时性大大降低,对于高频率的控制可能不适用,而NAC-BRLS能够明显降低单步平均运算耗时,提高了运算实时性.在ACLSTD中引入递归最小二乘,单步平均运算时间降低不明显,原因在于求逆矩阵本身阶次较低,因而策略更新等其他步骤的耗时相对较多.
算法的运行性能及报酬随m变化的效果如图6、7所示.以设定的策略更新步长来学习,当m较小时,收敛速度较快,但学习进行400周期之后,性能趋于一致.这说明批量递归最小二乘的性能对m变化的鲁棒性较强,尤其是最终的收敛性能基本一致.
图8给出NAC-BRLS中不同情况下的单步运行时间,即实时性的对比可知,AC-LSTD中使用LSTD估计普通梯度时阶次低,运算时间相对较短,实时性高;虽然现在很多研究都已经引入递归最小二乘法,但运算时间降低不明显.

图5 单步耗时对比Fig.5 Time cost comparison of per step

图6 不同批量数的性能对比Fig.6 Performance comparison of different batches

图7 不同批量数的报酬对比Fig.7 Rewards comparison of different batches

图8 不同批量数的时间对比Fig.8 Time comparison of different batches
Critic中使用LSTD估计自然梯度,运算时间显著增大,更显出使用递归的必要性.随着m的增大,智能体单步平均耗时下降,实时性提高.特别是当m较小时,效果更明显,但m增大,时间的降低效果不再明显,甚至趋平.这是由于批量递归运算同样引入了求矩阵逆运算,即m阶矩阵求逆,当m较小时,运算复杂度o(m3)相对o(n2)较小,因此整体运算复杂度增加不大,但运算次数减少,平均单步耗时的降低比较明显,当m=2时,单步运算复杂度已经低于AC-RLS.当m过大时,m阶矩阵求逆的计算复杂度大大增加,在远超过n的时候,批量运算压力可能会更大,这一点有待验证.
3.3 合适批量数的讨论
表1用数字对比了不同m值情况下算法的耗时、收敛性能及总报酬.当刚开始m增大时,单步耗时降低明显,但对性能影响不大;随着m的增大,收敛速度减慢比较明显,但是时间上降低不多.若智能体运算能力差,则选取较大的批量值m,虽然收敛性能上有所降低,但能够保证运算的实时性,实现在线学习,这是一种运算效率和收敛性能之间的平衡,需要根据具体情况选择批量数.若AC-RLS可以在线学习,但需引入自然梯度来加快学习速度,则可以选取批量数m=2,其单步运行时间已经低于AC-RLS算法,因而NAC-RLS算法能够在线运行.

表1 不同m值对应的时间和性能对比Tab.1 Comparison of time and performance by different m value
4 结 语
本文针对Actor-Critic结构的强化学习,提出在Critic中使用批量递归最小二乘法来估计自然策略梯度.利用自然策略梯度乐观地更新策略,这样可以在充分利用数据包含的信息前提下,降低平均单步运算耗时,提高运算实时性,同时提高了最小二乘法计算策略梯度的灵活性,这也可以看作是Peters[2]所提出的eNAC方法的拓展变形.山地车仿真实验结果表明,本文算法在性能上对最小二乘法的影响不大,但单步运算时间降低明显,并且能够根据具体的运算能力选择合适的数据批量,从而使得该类方法适用于实际问题.
NAC-BRLS算法的收敛性没有从理论上严格证明,特别是乐观地更新策略导致策略非平稳.同时,计算自然梯度的运算复杂度随状态和动作空间的增大而迅速增加,把方法应用到更大状态和动作空间下的效果有待尝试.此外,每次进行迭代的数据量智能体可以根据实际的计算能力来自主选择.
[1]SUTTON R S,BARTO A G.Introduction to reinforcement learning[M].Cambridge:MIT,1998.
[2]PETERS J,SCHAAL S.Natural actor-critic[J].Neurocomputing,2008,71(7):1180- 1190.
[3]GRONDMAN I,BUSONIU L,LOPES G A D,et al.A survey of actor-critic reinforcement learning:standard and natural policy gradients[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C:Applications and Reviews,2012,42(6):1291- 1307.
[4]程玉虎,冯涣婷,王雪松.基于参数探索的期望最大化策略搜索[J].自动化学报,2012,38(1):38- 45.
CHENG Yu-hu,FENG Huan-ting,WANG Xue-song.Expectation-maximization policy search with parameterbased exploration[J].Acta Automatica Sinica,2012,38(1):38- 45.
[5]BHATNAGAR S,SUTTON R S,GHAVAMZADEH M,et al.Natural actor:critic algorithms[J].Automatica,2009,45(11):2471- 2482.
[6]SUTTON R S.Learning to predict by the methods of temporal differences[J].Machine Learning,1988, 3(1):9- 44.
[7]ADAM S,BUSONIU L,BABUSKA R.Experience replay for real-time reinforcement learning control[J].IEEE Transactions on Systems,Man,and Cybernetics, Part C:Applications and Reviews,2012,42(2):201- 212.
[8]BRADTKE SJ,BARTO A G.Linear least-squares algorithms for temporal difference learning[J].Machine Learning,1996,22(1/2/3):33- 57.
[9]BOYAN J A.Technical update:least-squares temporal difference learning[J].Machine Learning,2002,49(2/3):233- 246.
[10]DANN C,NEUMANN G,PETERS J.Policy evaluation with temporal differences:a survey and comparison[J].The Journal of Machine Learning Research, 2014,15(1):809- 883.
[11]GEIST M,PIETQUIN O.Revisiting natural actor-critics with value function approximation[M]//Modeling Decisions for Artificial Intelligence.Berlin:Springer,2010:207- 218.
[12]CHENG Yu-hu,FENG Huan-ting,WANG Xue-song.Efficient data use in incremental actor:critic algorithms[J].Neurocomputing,2013,116(10):346- 354.
[13]XU Xin,HE Han-gen,HU De-wen.Efficient reinforcement learning using recursive least-squares methods[J].Journal of Artificial Intelligence Research, 2002,16(1):259- 292.
[14]AMARI S I.Natural gradient works efficiently in learning[J].Neural computation,1998,10(2):251- 276.
[15]BUSONIU L,ERNST D,SCHUTTER B D,et al.Online least-squares policy iteration for reinforcement learning control[C]//American Control Conference(ACC).Baltimore:IEEE,2010:486- 491.
[16]郝钏钏,方舟,李平.采用经验复用的高效强化学习控制方法[J].华南理工大学学报:自然科学版,2012, 40(6):70- 75.
HAO Chuan-chuan,FANG Zhou,LI Ping.Efficient reinforcement-learning control algorithm using experience reuse[J].Journal of South China University of Technology:Natural Science Edition,2012,40(6):70- 75.
[17]SUTTON R S,MCALLESTER D A,SINGH S P,et al.Policy gradient methods for reinforcement learning with function approximation[C]//Advances in Neural Information Processing Systems(NIPS).Denver:MIT, 1999,99:1057- 1063.
[18]MOUSTAKIDES G V.Study of the transient phase of the forgetting factor RLS[J].IEEE Transactions on Signal Processing,1997,45(10):2468- 2476.
[19]LJUNG L,S¨ODERSTR¨OM T.Theory and practice of recursive identification[M].Cambridge:MIT,1983.
[20]HACHIYA H,AKIYAMA T,SUGIAYMA M,et al.Adaptive importance sampling for value function approximation in off-policy reinforcement learning[J].Neural Networks,2009,22(10):1399- 1410.
[21]HUANG Zhen-hua,XU Xin,ZUO Lei.Reinforcement learning with automatic basis construction based on isometric feature mapping[J].Information Sciences, 2014,286(1):209- 227.
Natural Actor-Critic based on batch recursive least-squares
WANG Guo-fang,FANG Zhou,LI Ping
(School of Aeronautics and Astronautics,Zhejiang University,Hangzhou 310027,China)
The algorithm called natural actor-critic based on batch recursive least-squares(NAC-BRLS)was proposed in order to reduce the online computation burden of the agent and improve the real-time operation.The algorithm employed batch recursive least-squares in Critic to evaluate the natural gradient,and performed optimistic update in Actor by the estimated natural gradient.The use of batch recursive leastsquares enables the agent to adjust the date size of every batch according to its operational capability.A trade-off between fully optimistic and partially optimistic was made,improving the flexibility of NACLSTD.Simulation results in mountain car show that NAC-BRLS largely reduces the computational complexity without obviously affecting the convergence property compared with NAC-LSTD.
natural gradient;Actor-Critic;batch update;recursive least-squares
10.3785/j.issn.1008-973X.2015.07.019
TP 18
A
1008- 973X(2015)07- 1335- 08
2014- 12- 19. 浙江大学学报(工学版)网址:www.journals.zju.edu.cn/eng
国家自然科学基金资助项目(61004066);浙江省自然科学基金资助项目(LY15F030005).
王国芳(1989-),男,博士生,从事强化学习、迁移学习的研究.ORCID:0000-0002-8331-5643.E-mail:gfwang89@zju.edu.cn
方舟,男,副教授.ORCID:0000-0002-0733-958X.E-mail:zfang@zju.edu.cn
下期论文摘要预登
