基于主成分—灰色关联度的农民生活水平评价
2015-10-21童营营金哲植
童营营 金哲植

摘要 首先选择合适的测评经济发展的因素变量,基于全国各省的数据,通过聚类分析,在一个合适的准则下选择8个经济发展水平相近的省份进行进一步的分析。然后利用主成分和灰色关联度相结合的方法,选取评价农民生活水平的指标因素,构建农民生活水平的评价体系,对8个省份的农民生活水平进行分析并排序。最后根据结果分析了这一现状形成的原因,并提出了促进这些省份农民生活水平进一步提高和均衡发展的对策和建议。
关键词 聚类分析;主成分分析;灰色关联度;对比验证
中图分类号 S-9 文献标识码
A 文章编号 0517-6611(2015)03-328-03
Evaluation on Farmers Living Standard Based on Principle ComponentGrey Correlation Degree
TONG Yingying, JIN Zhezhi*
(College of Science, Yanbian University, Yanji, Jilin 133002)
Abstract This paper first to choose the appropriate measurement variable factors of economic development, based on data from the national provinces, through clustering analysis, under a proper criteria to choose eight provinces of similar level of economic development for further analysis. Then using combination method of principal component and grey correlation degree, selecting evaluation index of farmers' living standard, the evaluation system of farmers living standard was constructed. Farmers living standard of eight provinces was analyzed and sorted. analyze the eight provinces of farmers' living standard and sorted. The causes of the formation of the status quo were analyzed, several suggestions and countermeasures for further improving and balancing development of farmers living standard were put forward.
Key words Cluster analysis; Principal component analysis; Grey correlation degree; Comparison validation
基金项目 延边大学科技发展计划项目(2012700602014066)。
作者简介 董营营(1990- ) ,女,吉林延吉人,本科生,专业:统计学。*通讯作者,讲师,博士,从事保险精算、金融数学、应用统计研究。
收稿日期 20141203
近年来,随着“三农”问题的提出和落实,农民的生活水平备受关注。因为区域地理、经济、人文等方面的差异,使得我国各区域各地区农民的生活水平有很大的不同。参考相关参考文献,对生活水平的评价可以从以下几个方面进行考虑[1]。首先是收入指标体系。显而易见,收入的多少是决定生活水平的重要因素。再者是农民消费指标体系。这主要包括消费水平、消费结构、拥有耐用消费品数量、价格水平、恩格尔系数等。然后是储蓄评价指标。最后是反映农民文化生活精神层面以及医疗卫生健康保险方面的指标因素[2]。
在选取最终评价指标时,要兼顾重要性和简洁性,选取一些有代表性的因素。同时,为了分析的合理性,首先通过聚类分析筛选出经济发展水平较为相近,再利用主成分和灰色系统进一步分析农民生活水平的差异,并根据结果分析造成这一现状的原因,同时针对性地提出一些建议。
1 数据来源与研究方法
1.1 样本选取
1.1.1 衡量经济指标的选取。
参考相关文献,选取衡量经济发展情况的8项指标:生产总值、工业生产总值、固定资本、消费支出、消费指数、平均工资、消费价格指数、商品价格指数。在全国所有省市中,由于台湾省和香港、澳门2个特别行政区以及北京、天津、上海、重庆4个直辖市经济较为特殊,在进行聚类分析时摒弃。
1.1.2 聚类分析及分类准则的选取说明。
运用 SAS程序进行聚类分析[3],由系谱聚类图,选取其中一类:{辽宁,河北,河南,安徽,湖南,四川,浙江,福建}经济发展水平差异不大的8个省份作为进一步分析的样本。
1.2 测度指标的建立和数据处理
在尽可能涵盖收入、消费、储蓄、精神文化医疗保障等指标下,鉴于该研究重点是对农民实际生活水平的评价,在选取指标时侧重消费水平和结构以及住房耐用品的拥有量。这里没有选取储蓄指标的原因有二:一是储蓄指标并不能直接反映农民生活水平;二是在选取了收入和消费这2个指标可以间接反映储蓄指标。选择具体指标并进行变量设定如下:农民纯收入x1、消费总支出x2、食物支出x3、交通通信x4、文教娱乐x5、医疗保健x6、每百户人家拥有耐用消费品数量x7,住房面積x8。
數据列为:
X=x11x12…x18
x21x22…x28
x81x82…x88=(X1,X2,X3,…,X8)
式中,Xj(j=1,2,…,8)是第j个指标的样本集。
为了消除不同量纲的影响,首先对数据进行标准化处理。其中变量x7为每百户人家拥有耐用品数量,包括洗衣机、电冰箱、空调、抽油烟机、移动电话,彩电,计算机等共计12个分类。在数据标准化的基础上,在8各省份水平上对这12个分类取均值后,再标准化。
最后样本数据见表1。
1.3 研究方法
由于选择的变量具有一定程度的相关性,为消除共线性影响因素,采用主成分分析方法进行分析。主成分分析基本思想是将众多的具有一定相关性的指标,重新组合成一组新的互不相关的综合指标来代替原来指标,然后根据方差贡献率选择合适的主成分并计算样品在主成分上的得分。但是,主成分分析也有一定的缺陷,比如说最后得到的主成分特征向量,各变量所占比重以及正负情况都不确定,这样难以对所有指标给出一个确切的综合测度作为综合的信用等级指标进行排序。
表1 样本数据标准化结果
地区x1x2x3x4x5x6x7x8
河北-0.319 77 -0.559 31 -0.959 73 -0.262 11 -0.628 71 0.188 28 -0.643 32 0.377 18
辽宁0.195 95 -0.218 58 -0.331 55 -0.074 77 0.393 64 0.236 59 -1.179 99 -0.357 12
浙江2.242 55 2.281 78 1.810 95 2.344 37 2.177 85 2.136 36 1.906 24 1.870 32
安徽-0.684 46 -0.456 24 -0.486 56 -0.517 45 -0.487 12 -0.136 15 -0.617 26 -0.417 19
福建0.426 99 0.535 41 1.103 62 0.292 72 0.441 49 -1.382 74 0.840 70 0.953 45
河南-0.540 12 -0.737 66 -1.109 62 -0.492 68 -0.704 41 -0.533 29 -0.374 88 -0.489 82
湖南-0.573 69 -0.287 49 0.025 88 -0.619 37 -0.413 31 -0.259 61 0.440 07 -0.839 05
四川-0.747 44 -0.557 92 -0.053 00 -0.670 71 -0.779 43 -0.249 43 -0.371 56 -1.097 76
最大值2.242 55 2.281 78 1.810 95 2.344 37 2.177 85 2.136 36 1.906 24 1.870 32
另一方面,在进行农民生活水平评价时,农民生活水平系统是多种因素作用的结果。该研究选取的因素指标也只是其中的一部分,还有一些信息是未知的。需要对相关的因素进行分析,即分析相关因素对系统的作用程度,这样就需针对灰色系统采用关联度分析的方法来研究。但是这一方法无法解决因素信息重叠,有失准确性。
故结合以上2种方法,取其长处,规避不合理的地方,对农民生活水平评价体系进行分析、排序。
2 结果与分析
2.1 主成分分析
2.1.1 各指标的相关性检验矩阵。利用SAS软件进行主成分分析[4],得到变量之间的相关系数矩阵见表2。
表2 变量之间的相关系数矩阵
变量x1x2x3x4x5x6x7x8
x110.967 750.818 780.989 780.983 460.700 460.546 380.751 22
x2 10.913 570.974 400.966 700.663 810.527 860.825 60
x310.808 990.850 480.392 600.434 350.876 56
x410.964 020.742 560.550 040.778 94
x510.680 100.511 860.733 59
x610.303 030.396 01
x710.438 42
x81
由表2可知,变量间存在相关性。这说明用主成分方法是完全有必要的。
2.1.2 特征值和主成分形式。
同時,主成分分析结果还给出了相关系数矩阵的特征值、各主成分的方差贡献率以及累计贡献率(Cumulative)。可以看出提取2个主成分,累计方差贡献率就达到93.92%,提取3个达到97.33%。这里取3个主成分见表3。
表3 选取的主成分特征值及方差贡献率
主成分特征值方差贡献率∥%累计贡献率∥%
16.148 2883.3983.39
20.776 6510.5393.92
30.251 103.4197.33
由特征向量可以写出3个主成分的表达形式:
F1=0.394 856x1+0.402 394x2+0.359 105x3+0.397 079x4+0.391 852x5+0.280 968x6+0.214 406x7+0.342 100x8
F2=0.105 915x1-0.058 348x2-0.427 168x3+0.134 217x4+0.075 227x5+0.758 897x6-0.032 994x7+0.449 600x8
F3=-0.324 851x1+0.016 068x2+0.100 240x3-0.148 291x4-0.333 076x5+0.507 350x6-0.351 961x7+0.608 200x8
2.1.3 各省份具体得分。
利用特征向量各分量的值对主成分进行解释,对于第一主成分而言,各变量所占比重相差不大,且均为正数,可以用第一主成分进行排序,结果见表4。
表4 各省第一主成分得分及排序
地区主成分得分排序
河北-1.164 24 5
辽宁-0.389 13 3
浙江5.735 67 1
安徽-1.329 01 6
福建1.093 59 2
河南-1.722 47 8
湖南-0.773 04 4
四川-1.451 37 7
在之后的灰色关联度分析中,对各样本进行排序,是对单纯主成分排序下的一个修正。
2.2 基于主成分的灰色关联分析
2.2.1 原序列和参考序列的说明。
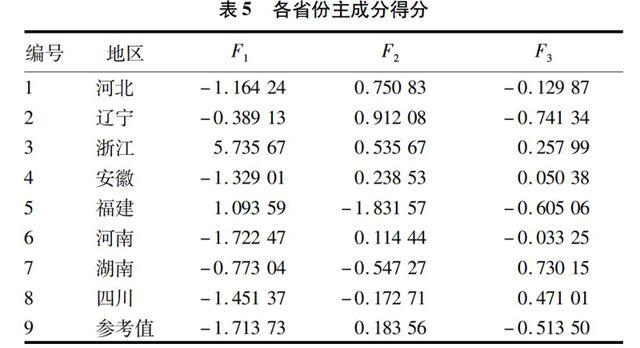
以各地区在各个主成分上的得分作为原序列(表5)。
在原序列的基础上选取理想数据,作为参考序列。这里选取各个样本中各个因素变量的最大值作为理想参考序列[5]。
将原序列和参考序列放在一起,定为矩阵
Y=[Y1,…,Y8,Y9],Yi=[Yi1,Yi2,Yi3](i=1,2,…9)
表5 各省份主成分得分
编号地区F1F2F3
1河北-1.164 240.750 83-0.129 87
2辽宁-0.389 130.912 08-0.741 34
3浙江5.735 670.535 670.257 99
4安徽-1.329 010.238 530.050 38
5福建1.093 59-1.831 57-0.605 06
6河南-1.722 470.114 44-0.033 25
7湖南-0.773 04-0.547 270.730 15
8四川-1.451 37-0.172 710.471 01
9参考值-1.713 730.183 56-0.513 50
2.2.2 关联系数的建立。
矩阵α∈[0,1]Y=[Y1,Y2,…,Y9]可以得价为一个因子集。因数序列Yj∈Y满足使Y为灰关联因子集。
以Yj(1≤j≤9)为参数序列,Yi∈Y为比较序列,比較序列对参数序列在第k(k=1,2,3)主成分上的灰关联为:
rij(k)=r(Yi(k),Yj(k))
=miniminj
minkΔij(k)+αmaxi
maxjmaxkΔij(k)Δij(k)+α
maximaximaxkΔij(k)
式中,Δij(k)=|Yi(k)-Yj(k)|;j=9,Y9为参考序列。
常数α=0.5∈[0,1]为分辨率系数,这里取α=0.5计算可得miniminj
Δij(k)=0.008 747 158;
miniminjΔij(k)=7.449 396 307。
可得关联系数矩阵见表6。
表6 各省份关联系数矩阵
编号地区r[Yi(1),Y9(1)]r[Yi(1),Y9(1)]r[Yi(3),Y9(3)]
1河北1.551 830 0021.569 615 722 1.385 979 628
2辽宁6.543 247 3341.730 859 754 1.230 189 366
3浙江4.225 872 364 1.354 456 8161.773 839 494
4安徽1.387 061 2261.057 314 0841.566 228 899
5福建3.809 660 3463.017 478 5791.093 906 269
6河南1.011 095 5791.071 468 1111.482 607 026
7湖南1.943 038 5041.733 187 0352.246 004 826
8四川1.264 708 8131.358 627 7461.986 858 830
2.2.3 对关联度计算并排序。
设各主成分的方差贡献率为pk,灰关联度计算公式为:
ri=nk=1pkr[Yi(k),Y9(k)]
式中,ri为比较数列Yi与参考数列Yj的关联度。
根据数据可得各关联度,由高到低排序依次为:辽宁、浙江、福建、湖南、河北、安徽、四川、河南。具体数值表7。
由结果可知,根据关联度进行排序的结果和依据主成分
得分结果进行排序的不同,但二者差异性不大。
表7 各省份关联度数值及排序
地区关联度排序
河北1.506 65
辽宁5.680 61
浙江3.727 12
安徽1.321 4 6
福建3.531 93
河南1.006 58
湖南1.879 44
四川1.265 57
3 结论与建议
该研究针对农民生活水平进行评价,根据聚类分析选择经济发展水平较为相近的8个省份,对其农民生活水平进行分析评价。在选取的8个省份中,辽宁省属于东北区域,河北、河南,安徽,湖南,四川属于内陆省份,而且河北、河南、安徽、湖南是中部6省中的4个,浙江、福建属于东南沿海省份。
由主成分得分排序可知,浙江省农民生活水平排在第一位,第二是福建省,再然后是辽宁省。在灰色关联度下,排在前3位的分别是辽宁省、浙江省、福建省。而其余省份在两种排序中名次相同。
虽然这里没有将所有的东北省份、沿海省份、内陆省份一一做比较,但是在现有的样本中,在经济发展水平相当的8个省份农民生活水平及质量的比较中,东北地区和沿海地区农民生活水平比内陆地区更高。
由灰色关联分析结果可知,辽宁省农民平均生活水平最高,其次是浙江、福建这2个沿海省份,再者是湖南、河北、安徽、四川、河南。
河南省是人口大省,在人口压力以及一些固有观念的影响下,农民享受生活的观念不是很强。国家在实施中部崛起战略举措的同时更应该加强“三农”问题的解决,不至于经济与生活不相当,切实使农民的现实生活好起来。四川地理位置特殊,经常受到自然灾害的侵袭,国家应给予一定程度的政策倾斜。在内陆省份中,湖南、河北、安徽农民生活水平相对较高。
参考文献
[1]
张羽琴.浅议城镇居民生活水平评价统计指标体系的设置[M].贵州社会科学,2000(2):18-21.
[2] 罗萍,殷燕敏,张学军,等.国内生活质量指标体系研究现状评析[J].武汉大学学报:人文社会科学版,2000,53(5):645-649.
[3] 汪远征,徐雅静.SAS软件与统计应用教程[M].北京:机械工业出版社,2011.
[4] 高惠璇.实用统计方法与SAS系统[M].北京:北京大学出版社,2001.
[5] 赵文英.基于主成分-灰色关联度的黑龙江省城镇化水平综合评价[J].数学的实践与认识,2014,44(6): 43-50.
