基于同义词词林和《知网》的短语主题提取
2015-10-13张东站
曾 聪,张东站
(厦门大学信息科学与技术学院,福建厦门361005)
基于同义词词林和《知网》的短语主题提取
曾 聪,张东站*
(厦门大学信息科学与技术学院,福建厦门361005)
提出了利用主题词存在与否的基于主题词的短语抽取算法,并在其基础上利用社会知识词簇集合作为分类信息,词的相似度作为距离权重,利用改进K最近邻分类算法(KNN)的分类思想,提出基于《知网》词相似度的短语主题抽取算法.并在其基础上提出一种根据中文表达习惯的基于加权主题词的短语主题抽取算法.实验结果表明,后两种算法对短语主题抽取效果良好,平均查全率分别达到78.88%和83.39%,平均查准率达99.06%和99.70%.
短语主题;主题抽取;同义词词林;知网
主题抽取是文本自动处理的基础工作之一,主题抽取通常针对的对象是一篇完整的文章,文章中包含着词、句、段等对文本主题有着不同贡献的信息.而主题抽取则是利用这些信息,对中文文章进行主题抽取.抽取步骤通常应用各种加权算法,有的基于词的绝对频率[1]、相对频率[2]、文中出现的位置[3]进行加权计算,还有的根据文章与文章之间的引用关系[4]进行计算,近年来,国内的学者也对文本主题抽取进行研究[5-8].
短语是搜索引擎的主要输入信息,研究短语的主题可以更好的对用户的搜索意图进行判断,将短语抽象出主题可以将用户输入的查询表层字符信息上升到主题层面,采取不同的主题形式来形式化地表示查询背后的搜索意图,从多个角度理解查询意图,并基于查询意图提供新颖的搜索服务与搜索模式[9].现在的主题抽取算法大都是基于统计和经验的加权体系.由于短语包含的信息与一篇完整的文章相比有着巨大的不同,所以基于统计和经验的加权体系无法直接应用于短语的主题抽取.
短语的主题往往包括在短语的词汇中,它或者是一个主题词或者是某一个主题词的同义词.利用同义词构造分类信息,短语的主题抽取可以转换成短语主题分类.
基于以上思想,本文提出了利用主题词存在与否的基于主题词的短语抽取算法,并在其基础上利用社会知识词簇集合作为分类信息,词的相似度作为距离权重,利用改进K最近邻分类算法(KNN)的分类思想提出基于《知网》词相似度的短语主题抽取算法.并在其基础上提出一种根据中文表达习惯的基于加权主题词的短语主题抽取算法.实验结果表明,后两种算法对短语主题抽取效果良好.
1 基于主题词的短语主题抽取算法(KWPSE)
短语由词汇构成,一个短语可以解释为词汇集合.短语的主题包含于词汇集合中,词语表达形式的多样化导致相同主题的短语所表现的主题词不一样.因此,构造候选主题词集就成为了短语主题抽取的第一部分.
1.1 候选主题词集确定
定义1 定义W表示词的集合,w表示一个词,即w∈W.
定义2 短语P.短语可以看成是词语的集合,短语为词的集合的子集,即短语P⊂W.
定义3 词的主题wt.它表示人们对某个词的一种直观认识.这种认识也是一个词,即:wt∈W.一个词w可能有多个主题.

定义4 词的主题集T.词的主题集T是词w的主题wt集合,是属于词w的一个属性,写作T(w).例如对于w=足球,其主题集属性T(w)={体育}.
定义5 词簇C.词簇C是W的一个子集.在C的元素w含有相同主题.
定义6 词簇的主题词ct.ct∈W,对于一个词簇C,对于所有的w∈C,它们的共同主题定义为词簇的主题词.
∀wi∈C:∩T(wi)={ct}≠Ø,|∩T(wi)|=1.
定义7 词的关注度wa.词的关注度wa是词的一种属性,它代表了词语对一篇文章、一个句子或者一个短语的主题影响.例如w=“的”的关注度为零,而w=“原子弹”的关注度则较高.
定义8 词簇的关注度ca,其等同于其主题词ct的关注度wa.
同义词词林[10]本身为一个类义词典,其中含有大量的分类信息.其同一行的词语要么词义相同(有的词义十分接近),要么词义有很强的相关性.对于同一行的词语其含有共同的主题,所以对同一行的词可以把它们聚成一个词簇.特别的对于一些同段(包括多行)的词语,其各词仍然含有相同的主题,故可以将该段聚成一个词簇.
对所有的词簇,选取其中最有代表性的词作为词簇的主题词.通过词林和人工判别,形成了一个基于词林的社会知识词簇集合Cs,以下简称词簇集合.
在词簇集合Cs中,有些关注度较低的词簇则会被删除.删除后剩余的词簇集合即为候选词簇集合cCs,而cCs的主题词的集合称之为候选主题词集c Ts.
1.2 算 法
对于短语P,如果含有候选主题词集c Ts中的元素,即∃w|w∈P∩w∈c Ts,则认为w为短语P所要表达的主题.对于某些短语其含有候选主题词集的元素可能不止一个,此时认为短语包含了多个主题.综上,对应短语P的主题应该是一个主题词集合.
定义9 短语的主题词集合Pt,对于词w,如果w是短语的主题,则w∈Pt.
基于上述思想,可以得到KWPSE.

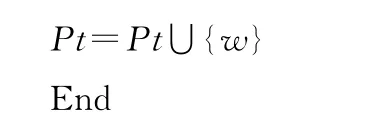
这种算法效率高,时间复杂度低.但如上文所述,词语的多样化表示导致相同主题的短语表现形式不一致,P中主题表现形式w∉c Ts.对于此类的短语P利用KWPSE无法获取其主题信息.
举例说明如下:
给定分词后的短语P如下:(福建警官学院),
P={“福建”,“警官”,“学院”}.
在c Ts中不存在这3个词汇.利用KWPSE无法找到该短语的分类.
而事实上,学院的同义词“学校”∈c Ts,且“福建警官学院”的主题应为“学校”.
2 基于《知网》词相似度的短语主题抽取算法
2.1 抽取原理
KWPSE简单地使用了c Ts,而未考虑候选词簇集合cCs所具有的类义结构含有的分类信息.将所有的候选词簇集合cCs作为训练样本集,将短语的主题抽取归约成短语主题分类.本文利用改进的KNN算法进行短语主题分类.
对于某个词簇Ci,w(w∈Ci)和其主题词cti存在着较大的相似度.
定义10 P的可能主题.记w(w∈P)对应的主题词cti为P的可能主题.
定义11 备选主题词集.短语P中所有可能的主题集合为短语备选主题词集,记为AT(Pi)={at1, at2,…}.
本文采用对于一个短语P,将备选词集AT(P)看成是候选主题词集中距离短语主题最近的K个样本.
定义12 词的相似度.Sim(wi,wj)表示两个词wiwj之间的相似度.
对于一个词w,设它所在的词簇集合为C(w),对于C(w)有

则词w对应的主题词集合为CT(w)={ct|∀ct:ct}是C的主题词∩C∈C(w)}.
Sim(w,cti)(cti∈CT(w))的值越高,则w∈P和cti∈P的关联度越高,所以我们可以把Sim(w,cti)当做P与cti的距离权重,即如果Sim(w,cti)越高则说明P与cti的距离越近.
定义13 主题的影响度.定义一个主题ct对应短语P的影响度为I(ct,P).
综上所述,基于改进的KNN算法可以得到计算I(ct,P)的方法.
对于所有的wi∈P,计算所有的ctj∈CT(wi)与wi的相似度Sim(wi,ctj).
对于ati∈AT(P),其影响度计算方式为

则P的最大影响度主题为
ct=ct:max{I(ct,P)(ct|ct∈AT(P))},而对于某些短语P,其可能存在多个主题,在得到P的最大影响度主题ct后,将其他的候选主题cti与ct相比较,如果满足下列公式则认为cti也可能是P的主题.

其中α为可接受参数,表示在允许的范围内接受cti作为P的主题,反应了多主题短语占所有短语的比例.本文取值为0.03.
将符合条件的cti和ct合并后得到短语的主题词集合Pt.
2.2 算法实现
基于《知网》词相似度的短语主题抽取算法(word similarity based on hownet phrase subject extraction algorithm,WSPSE)的具体实现流程如下

图1 短语主题抽取算法Fig.1 Phrase subject extraction algorithm
本文采用中国科学院研发的NLPIR分词系统,该系统分词速度快,准确率高[11].
“我爱北京天安门”分词结果如例子所示,去掉分词性标注后的结果在下一行给出.
例:我/r 爱/v 北京/ns 天安门/ns./w
我爱北京天安门.
目前中文词的相似度计算有基于同义词词林和基于《知网》的词语相似度计算.考虑到《知网》的词语信息比同义词词林的含义更加完备,故在计算词的相似度时本文采用的是刘群和李素建的方法计算词的相似度[12-13].
对于两个汉语词语W1和W2,如果W1有n个义项(概念):S11,S12,…,S1n,W2有m个义项(概念): S21,S22,…,S2m,我们规定,W1和W2的相似度为W1和W2对应的各个概念的相似度之最大值,也就是说:

两个义原在这个层次体系中的路径距离为d,可以得到这两个义原之间的语义距离:

其p1和p2表示两个义原,d是p1、p2在义原层次体系结构中的路径长度,α是可调节参数.α的含义是当相似度为0.5时的词语距离值.
对于实词概念的语义表达式,将其分成4个部分:
第一独立义原描述式:将两个概念的这一部分的相似度记为Sim1(S1,S2);
其他独立义原描述式:语义表达式中除第一独立义原以外的所有其他独立义原(或具体词),将两个概念的这一部分的相似度记为Sim2(S1,S2);
关系义原描述式:语义表达式中所有的用关系义原描述式,将两个概念的这一部分的相似度记为Sim3(S1,S2);
符号义原描述式:语义表达式中所有的用符号义原描述式,将两个概念的这一部分的相似度记为Sim4(S1,S2).
于是,两个概念语义表达式的整体相似度记为:
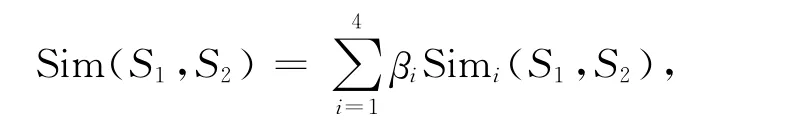
其中,βi(1≤i≤4)是可调节的参数,且有:β1+β2+β3 +β4=1,β1≥β2≥β3≥β4.
根据文献[14],取β1=0.5,β2=0.2,β3=0.17,β4 =0.13.
计算词的相似的算法如下:


基于上述,算法WSPSE如下:

举例说明如下:
给定分词后的短语P如下:(福建警官学院),
P={“福建”,“警官”,“学院”}.
根据词簇集合可以求出P的候选主题词集
AT(P)={“行政区划”,“军官”,“警察”,“学校”},
其中w1=“福建”,CT(w1)={“行政区划”},Sim(w1,“行政区别”)=0.3.
w2=“警官”,CT(w2)={“军官”,“警察”},Sim (w2,“军官”)=0.952,Sim(w2,“警察”)=0.933.
w3=“学院”,其CT(w3)={“学校”},Sim(w3,“学校”)=1.
得到影响度I(ct,P)(ct|ct∈AT(P))的集合为{“0.3”,“0.952”,“0.933”,“1”}.
所以P的最大影响度主题ct=“学校”,而其他主题词与其的比值不满足公式(1),故认为其的主题为{“学校”}.
3 基于加权主题词的短语主题抽取算法(WKWPSE)
3.1 算法思想
短语中还有词性信息和位置信息也是短语主题抽取所参考的信息,而WSPSE算法没有考虑这部分的信息.
定义14 词的权重.对于所有的w∈P,定义Weight(w)为对应词w的权重.
根据不同的研究方向,对于不同的词性信息和位置信息给予不同的权重.
3.2 动名词类主题权值算法
本文研究短语主题的目的是用于搜索意图判断,故针对的短语为百度的搜索热词集合.通过对这些短语的研究,发现这些短语大部分具有与偏正短语(如, XX学校,XX国家等)、动宾短语(如,学习C语言等)、主谓短语(如XX是、XX怎么样)相同的结构.
本文抽取的短语主题主要针对动名词类主题,故认为关注度较高的词簇往往都是名词或者动词.形成候选词簇集合cCs的词簇都为名词或者动词.
基于上述考虑,名词和动词是需要重点考虑的词簇,故给予一定的权重值.而形容词和副词则给予一个较低的权重,然后每个名词和动词的权重再加上用来修饰它的形容词或者副词的权重,这样所有的需要考虑的名词和动词都有了一定的权重.
根据语言书写习惯,较长的定语后置,而较短的定语前置.本文研究的短语集合一般较短,我们认为名词或动词之前出现的定语都是用于修饰该动词或名词.例如,“最美的大学”短语,“最”和“美”都是用于修饰后面的大学.
基于上述分析,本文针对动名词类的加权算法如下:


3.3 算法实现
基于上述想法,对WSPSE进行加权改进后形成了WKWPSE.

举例说明如下:
给定分词后的短语P如下:(厦门制服),
P={“厦门”,“制服”}.
根据词簇集合可以求出P的候选主题词集.
两个词都为名词,故其权重都为1.而“厦门”也作为“制服”的定语,故“制服”的权重再加0.5.由此得出两个词的权重W(“厦门”)=1,W(“制服”)=1.5.
AT(P)={“城市”,“衣服”},
其中w1=“厦门”,其CT(w1)={“城市”},Sim(w1,“城市”)=0.57.
w2=“制服”,其CT(w2)={“衣服”},Sim(w2,“衣服”)=0.44.
得到影响度I(ct,P)(ct|ct∈AT(P))的集合为{“0.57”,“0.44”}.
乘以相应的权重后,P的最大影响度主题ct=“衣服”.
而其他主题词与其的比值不满足公式(1),故认为其的主题为{“衣服”}.
4 实验结果
4.1 实验数据
本次实验采用的数据是从百度搜索引擎上截取的关于“学校”、“疾病”、“衣服”、“工厂”、“商店”、“戏剧”、“乐器”、“书籍”、“婴儿”这9个主题的用户热门搜索短语1 198个.利用人工对这1 198个短语进行主题提取,其中学校相关402个,商店相关146个,疾病相关134个,衣服相关105个,工厂相关69个,戏剧相关50个,乐器相关37个,书籍相关117个,婴儿相关138个.
将文献[2]中的算法用于短语主题抽取,且将提取出的关键词在词簇中寻找主题用于表示主题,记为词频算法.
利用上述3种算法和词频算法分别对这1 198个短语进行主题提取.分类效果评估指标使用常用的查准率、查全率以及F1测试值.
查准率=主题抽取的正确短语数/主题抽取属于
该主题的短语数,
查全率=主题抽取的正确短语数/属于该主题的
短语数,

4.2 实验结果分析和比较
从结果(表1)可以看出,词频算法直接应用于短语主题抽取,虽然其查准率较高,但查全率较低,基本与随机从短语选择主题的概率一致,故词频算法无法直接应用于短语主题抽取.而利用WSPSE和WKWPSE质量较好,且对于大多数主题的结果来说,WKWPSE对WSPSE有所改进.对于乐器主题的短语,由于专有名词较多,分词词库中收录的名词并非十分全面,故其分词效果不佳,导致结果较差.而对于戏剧主题短语,其戏剧名实时更新,无法完全收录词库,不仅在分词时效果不佳,在基于同义词词林基础上形成的词簇集合也无法识别戏剧名,只能将戏剧名拆分识别导致效果较差.

表1 4种算法实验结果对比表Tab.1 The contrast table of the result of four algorithms
4.3 多类短语实验结果和分析
从百度搜索引擎上截取部分具有多主题信息的短语,利用WSPSE和WKWPSE进行主题抽取,其实验结果如表2.

表2 多主题短语实验结果Tab.2 The result of multi-subject phrases
从表2的结果可以看出多主题短语实验结果基本符合人们主观的分主题结果,而多主题的主题抽取很大程度上依赖于社会知识词簇集合.如果社会知识词簇集合不包含该主题信息,如上述短语中,如果“鲁迅”无法被社会知识词簇集合识别,则无法得到上述结果,只能得到“书籍”这一结果.
5 总 结
对搜索引擎的主要输入源短语进行主题提取可以更好地对用户的搜索意图进行判断,将短语抽象出主题可以将用户输入的查询表层字符信息上升到主题层面,采取不同的主题形式来形式化地表示查询背后的搜索意图,从多个角度理解查询意图,并基于查询意图提供新颖的搜索服务与搜索模式.
本文提出了对短语主题提取的算法,其中WSPSE和WKWPSE实际上是基于语义的主题提取算法.本文实验使用的1 198个短语是当前热度比较高的,且具有很强的代表性,这表明本文提出的算法对短语主题提取具有积极的推进作用.
[1] Luhn H P.A statistical approach to mechanized encoding and searching of literary information[J].IBM Journal of Research and Development,1957,1(4):309-317.
[2] Luhn H P.The automatic creation of literature abstract [J].IBM Journal of Research and Development,1958,2 (2):159-165.
[3] Edmundson H P,Oswald V A,Wyllys R E.Automatic indexing and abstracting of contents of documents[R].Los Angeles:Planning Research Corp,1959.
[4] Stevens M E.Automatic indexing:a state-of-the-art report[EB/OL].[2014-10-29].http:∥digital.library.unt. edu/ark:/67531/metadc171070/.
[5] 马颖华,王永成,苏贵洋,等.一种基于字同现频率的汉语文本主题抽取方法[J].计算机研究与发展,2003,6: 874-878.
[6] 杨洁,季铎,蔡东风,等.基于联合权重的多文档关键词抽取技术[J].中文信息学报,2008,22(6):75-79.
[7] 李素建,王厚峰,俞士汶,等.关键词自动标引的最大熵模型应用研究[J].计算机学报,2004,27(9):1192-1197.
[8] 李鹏,王斌,石志伟,等.Tag-Text Rank:一种基于Tag的网页关键词抽取方法[J].计算机研究与发展,2012,11: 2344-2351.
[9] 宋巍.基于主题的查询意图识别研究[D].哈尔滨:哈尔滨工业大学,2013.
[10] Che W X,Li Z H,Liu T.LTP:a Chinese language technology platform[C]∥Proceedings of the Coling 2010: Demonstrations.Beijing,China:[s.n.],2010:13-16.
[11] 中国科学院.ICTCLAS汉语分词系统[EB/OL].[2010-12-21].http:∥www.ictclas.org.
[12] 董振东,董强.知网(How Net)[EB/OL].[1999-06-01]. http:∥www.keenage.com.
[13] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].中文计算语言学,2002,7(2):59-76.
Phrase Subject Extraction Based on Synonyms and HowNet
ZENG Cong,ZHANG Dong-zhan*
(School of Information Science and Engineering,Xiamen University,Xiamen 361005,China)
Key word phrase subject extraction algorithm(KWPSE),which is based on the judgment whether phrases include the topic words is constructed.On the basis of KWPSE,by using a WordsSet of social knowledge as classified information,the word similarity as distance weight,and the improved KNN method the word similarity based on How Net phrase subject extraction algorithm (WSPSE)is presented.Finally,on this basis of WSPSE and with the addition of the weight to the words′position that is based on Chinese custom,the WKWPSE algorithm is proposed.The average recall rates reach 78.88%and 83.39%,and average precision rates increase to 99.06%and 99.70%.
phrase subject;subject extraction;synonyms;How Net
10.6043/j.issn.0438-0479.2015.02.019
TP 391
A
0438-0479(2015)02-0263-07
2014-04-29 录用日期:2014-08-25
国家自然科学基金(61303004);福建省自然科学基金(2013J05099)
*通信作者:zdz@xmu.edu.cn
曾聪,张东站.基于同义词词林和《知网》的短语主题提取[J].厦门大学学报:自然科学版,2015,54(2):263-269.
:Zeng Cong,Zhang Dongzhan.Phrase subject extraction based on synonyms and How Net[J].Journal of Xiamen University:Natural Science,2015,54(2):263-269.(in Chinese)
